Background information
The exponential growth in parameters for Large Language Models (LLMs), with some open-source models like DeepSeekV3-671B exceeding 700 GB, has made model loading time a critical bottleneck for efficient inference. This challenge is especially pronounced in two key scenarios:
Elastic Scale-out: Model loading time directly impacts service scaling agility.
Multi-instance deployments: When multiple instances concurrently pull a model from remote storage, such as Object Storage Service (OSS), Apsara File Storage NAS (NAS), or Cloud Parallel File System (CPFS), it causes network bandwidth contention, which further slows down model loading.
To address these challenges, Platform for AI (PAI) Inference Service introduces the Model Weight Service (MoWS). MoWS uses several core technologies:
Distributed caching architecture: Uses node memory to build a weight cache pool.
High-speed transport: Achieves low-latency data transfer using RDMA-based interconnects.
Intelligent sharding: Supports parallel data sharding with integrity checks.
Memory sharing: Enables zero-copy weight sharing among multiple processes on a single machine.
Intelligent prefetching: Proactively loads model weights during idle periods.
Efficient caching: Ensures model shards are load-balanced across instances.
In practice, this solution delivers significant performance gains in large-scale cluster deployments:
Improves scaling speed by 10x compared to traditional pull-based methods.
Increases bandwidth utilization by over 60%.
Reduces service cold start times to seconds.
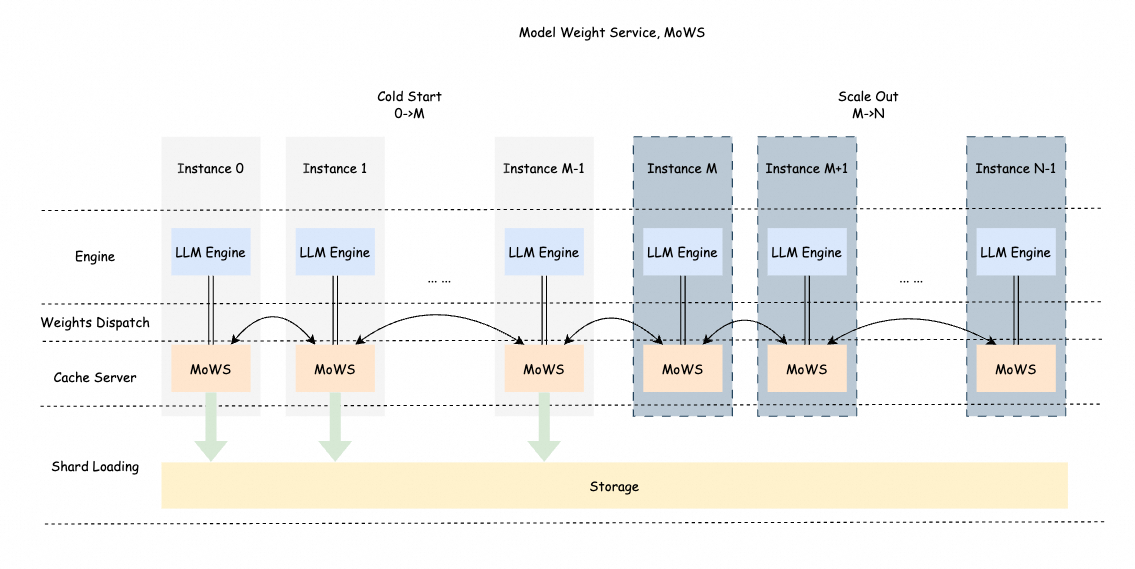
By fully utilizing the bandwidth resources among multiple instances, MoWS enables fast and efficient model weight transport. It not only caches model weights locally but also shares them across instances. For scenarios involving large-parameter models and large-scale instance deployments, MoWS significantly improves service scaling efficiency and startup speed.
Usage
Log on to the PAI console. Select a region on the top of the page. Then, select the desired workspace and click Elastic Algorithm Service (EAS).
Click Deploy Service, then Custom Deployment.
On the Custom Deployment page, configure the following key parameters. For more information about other parameters, see Parameters for custom deployment in the console.
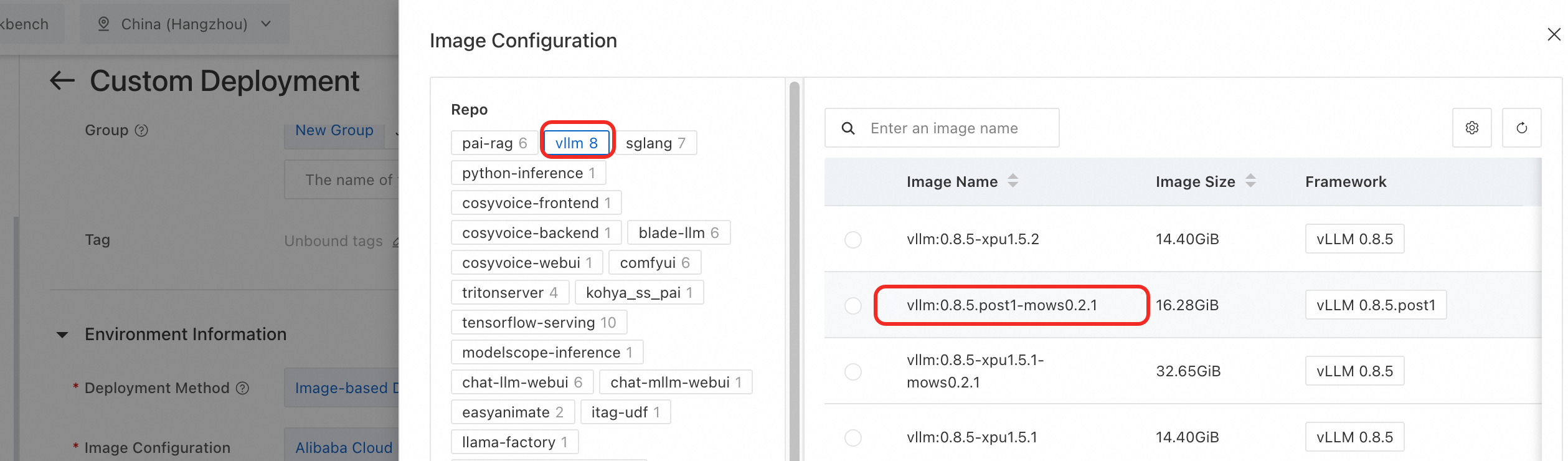
Under Environment Information > Image Configuration, select Alibaba Cloud Image and choose an image version with the mows identifier from the vllm image repository.
In the Resource Information section, select EAS Resource Group or Resource Quota as the resource type.
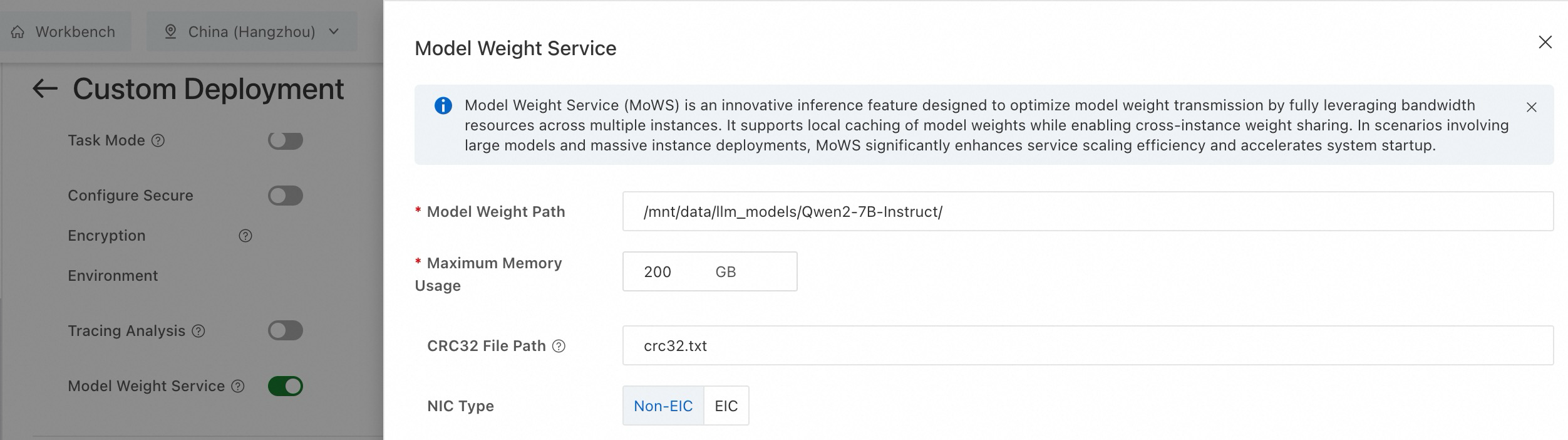
In the Features section, enable the Model Weight Service (MoWS) feature and configure the following parameters.
Configuration Item
Description
Example
Model Weight Path
Required. The path of the model weights. The path can be an OSS, NAS, or CPFS mount path.
/mnt/data/llm_models/Qwen2-7B-Instruct/Maximum Memory Usage
Required. The memory resources used by MoWS for a single instance. Unit: GB.
200
CRC32 File Path
Optional. Specifies the crc32 file for data verification during model loading. The path is relative to the Model Weight Path.
The file format is [crc32] [relative_file_path].
Default value: "crc32.txt".
crc32.txt
The content is as follows:
3d531b22 model-00004-of-00004.safetensors 1ba28546 model-00003-of-00004.safetensors b248a8c0 model-00002-of-00004.safetensors 09b46987 model-00001-of-00004.safetensorsNIC Type
Select EIC if your instance uses EIC-accelerated hardware.
Non-EIC NIC
Performance benefits
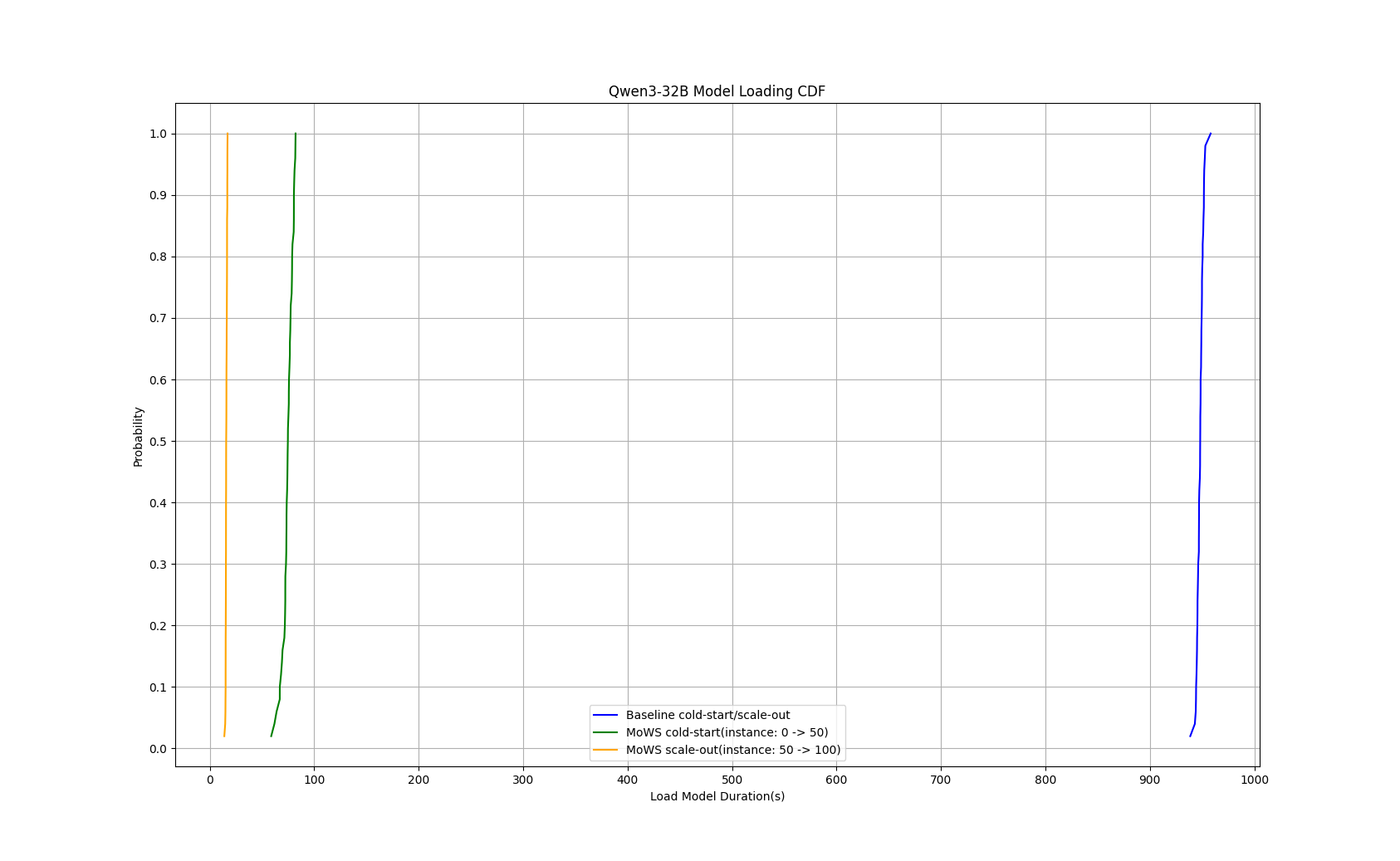
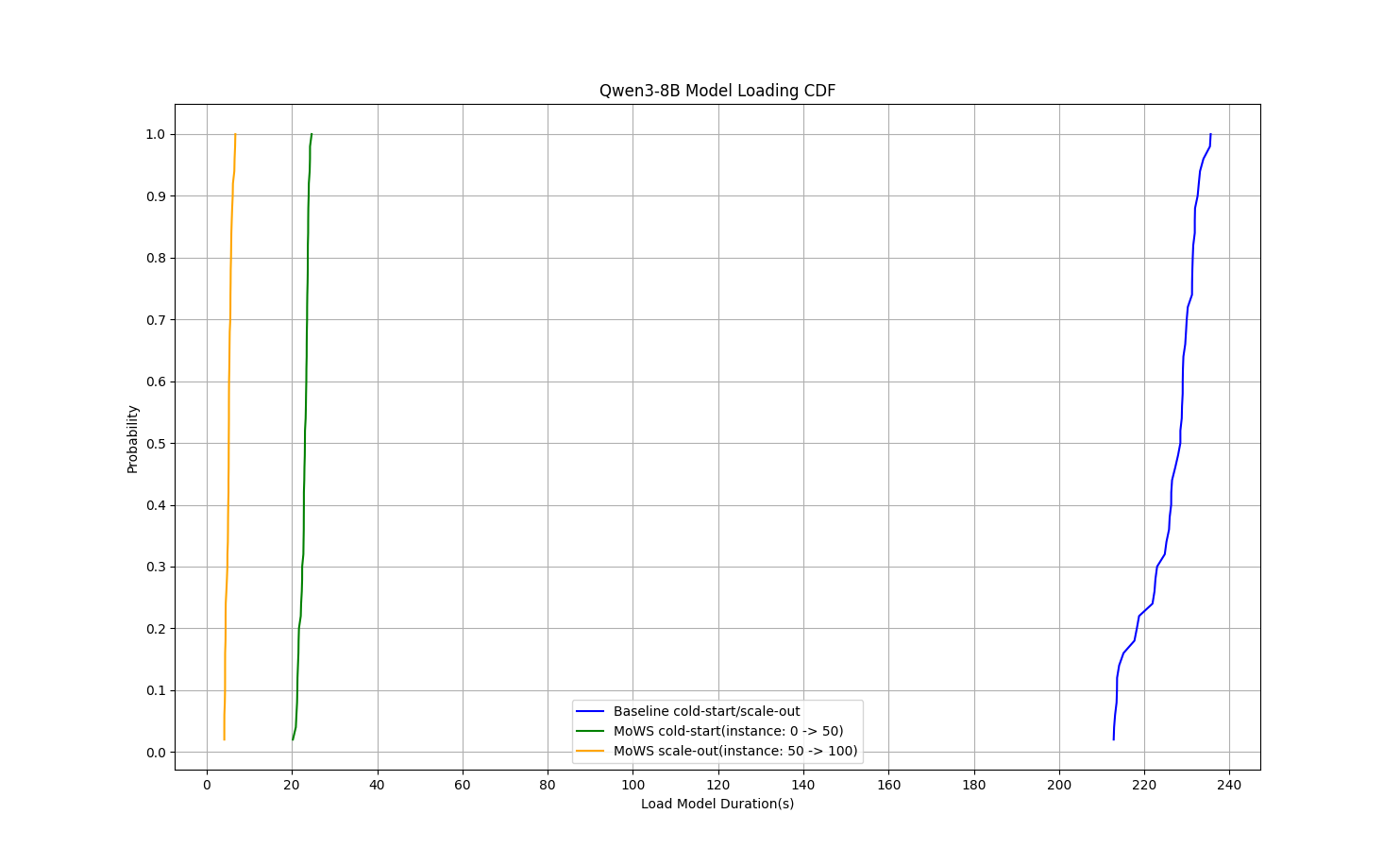
In a performance test with the Qwen3-8B model, MoWS reduced the P99 cold start time for the inference service from 235 seconds to 24 seconds — a reduction of 89.8% — and cut instance scaling time to 5.7 seconds, a 97.6% reduction.
In a performance test with the Qwen3-32B model, MoWS reduced the cold start time from 953 seconds to 82 seconds — a 91.4% reduction — and cut instance scaling time to 17 seconds, a 98.2% reduction.