MaxCompute introduces user defined join (UDJ) to the user-defined function (UDF) framework based on the MaxCompute V2.0 compute engine. UDJ allows more user-defined operations by flexibly joining tables and simplifies MapReduce-based operations in the underlying distributed system.
Background information
MaxCompute provides multiple built-in Join operations, such as INNER JOIN, RIGHT JOIN, LEFT JOIN, FULL JOIN, SEMI JOIN, and ANTI-SEMI JOIN. Although these built-in Join operations are powerful, their standard implementations cannot meet the requirements of many scenarios that involve cross-table operations.
In most cases, you can use UDFs to describe your code framework. However, the current UDF, user-defined table-valued function (UDTF), and user-defined aggregate function (UDAF) frameworks can only handle one table at a time. To perform user-defined operations for multiple tables, you must use built-in JOIN methods, UDFs, UDTFs, and complex SQL statements. In such scenarios, you must use a custom MapReduce framework instead of SQL to complete the required computing tasks.
Regardless of the scenario, the operations require technological expertise and may cause the following issues:
In scenarios where you use built-in JOIN methods, UDFs, UDTFs, and complex SQL statements: The use of multiple JOIN methods and code in SQL statements results in a logical black box, which causes difficulties in generating an optimal execution plan.
In scenarios where you use a custom MapReduce framework: Execution plans are hard to optimize. Most of the MapReduce code is written in Java. During the deep optimization of native runtime code, the execution of the MapReduce code is less efficient than the execution of the MaxCompute code that is generated by the Low Level Virtual Machine (LLVM) code generator.
Limits
You cannot use UDFs, UDAFs, or UDTFs to read data from the following types of tables:
Table on which schema evolution is performed
Table that contains complex data types
Table that contains JSON data types
Transactional table
UDJ performance
A real online MapReduce job is used as an example to verify the performance of UDJ. The job runs based on a complex algorithm. In this example, two tables are joined, UDJ is used to rewrite the MapReduce job, and the correctness of the UDJ results is checked. The following figure shows the MapReduce and UDJ performance under the same data concurrency.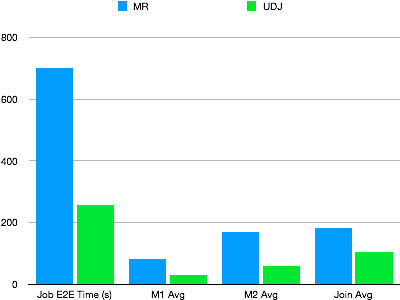
UDJ conveniently describes the complex logic for handling multiple tables and greatly improves performance, as shown in the figure. The code is called only within UDJ. The logic of the entire mapper in this example is executed by the native runtime of MaxCompute. The data exchange logic between the MaxCompute UDJ runtime engine and Java interfaces is optimized in Java code. The JOIN logic of UDJ is more efficient than the JOIN logic of a reducer.
Cross join operations using UDJ
The following example describes how to use UDJ in MaxCompute.
For example, two log tables named payment and user_client_log exist.
The payment table stores the payment records of users. Each payment record contains the user ID, payment time, and payment content. The following table describes the sample data.
user_id
time
pay_info
2656199
2018-02-13 22:30:00
gZhvdySOQb
8881237
2018-02-13 08:30:00
pYvotuLDIT
8881237
2018-02-13 10:32:00
KBuMzRpsko
The user_client_log table stores the client logs of users. Each log contains the user ID, logging time, and log content. The following table describes the sample data.
user_id
time
content
8881237
2018-02-13 00:30:00
click MpkvilgWSmhUuPn
8881237
2018-02-13 06:14:00
click OkTYNUHMqZzlDyL
8881237
2018-02-13 10:30:00
click OkTYNUHMqZzlDyL
Requirement: For each record in the user_client_log table, find the payment record that has the closest time to this record in the payment table. Then, join the two records and generate results. The following table describes the results.
user_id | time | content |
8881237 | 2018-02-13 00:30:00 | click MpkvilgWSmhUuPn, pay pYvotuLDIT |
8881237 | 2018-02-13 06:14:00 | click OkTYNUHMqZzlDyL, pay pYvotuLDIT |
8881237 | 2018-02-13 10:30:00 | click OkTYNUHMqZzlDyL, pay KBuMzRpsko |
To meet this requirement, use one of the following methods:
Use built-in JOIN methods. Sample SQL pseudocode:
SELECT p.user_id, p.time, MERGE(p.pay_info, u.content) FROM payment p RIGHT OUTER JOIN user_client_log u ON p.user_id = u.user_id AND ABS(p.time - u.time) = MIN(ABS(p.time - u.time))When you join two records in the tables, you must calculate the minimum difference between p.time and u.time that correspond to the same user_id. However, you cannot call aggregate functions in a JOIN condition. Therefore, you cannot use standard JOIN methods to complete this task.
Use the UDJ method.
Create a UDJ function.
Configure the SDK of the new version.
<dependency> <groupId>com.aliyun.odps</groupId> <artifactId>odps-sdk-udf</artifactId> <version>0.29.10-public</version> <scope>provided</scope> </dependency>Write UDJ code and package the code as odps-udj-example.jar.
package com.aliyun.odps.udf.example.udj; import com.aliyun.odps.Column; import com.aliyun.odps.OdpsType; import com.aliyun.odps.Yieldable; import com.aliyun.odps.data.ArrayRecord; import com.aliyun.odps.data.Record; import com.aliyun.odps.udf.DataAttributes; import com.aliyun.odps.udf.ExecutionContext; import com.aliyun.odps.udf.UDJ; import com.aliyun.odps.udf.annotation.Resolve; import java.util.ArrayList; import java.util.Iterator; /** For each record in the right table, find the nearest record in the left table * and merge the two records. */ @Resolve("->string,bigint,string") public class PayUserLogMergeJoin extends UDJ { private Record outputRecord; /** This method is called before the data processing phase. You can implement this method to perform initialization. */ @Override public void setup(ExecutionContext executionContext, DataAttributes dataAttributes) { // outputRecord = new ArrayRecord(new Column[]{ new Column("user_id", OdpsType.STRING), new Column("time", OdpsType.BIGINT), new Column("content", OdpsType.STRING) }); } /** Override this method to implement join logic. * @param key Current join key * @param left Group of records of left table corresponding to the current key * @param right Group of records of right table corresponding to the current key * @param output Used to output the result of UDJ */ @Override public void join(Record key, Iterator<Record> left, Iterator<Record> right, Yieldable<Record> output) { outputRecord.setString(0, key.getString(0)); if (!right.hasNext()) { // The right group is empty. Do nothing. return; } else if (!left.hasNext()) { // The left group is empty. Output all records from the right group without merging. while (right.hasNext()) { Record logRecord = right.next(); outputRecord.setBigint(1, logRecord.getDatetime(0).getTime()); outputRecord.setString(2, logRecord.getString(1)); output.yield(outputRecord); } return; } ArrayList<Record> pays = new ArrayList<>(); // The record group on the left will be iterated from beginning to end. // The iterator cannot be reset for each record in the right group. // Therefore, we save each record from the left table to an ArrayList. left.forEachRemaining(pay -> pays.add(pay.clone())); while (right.hasNext()) { Record log = right.next(); long logTime = log.getDatetime(0).getTime(); long minDelta = Long.MAX_VALUE; Record nearestPay = null; // Iterate through all records on the left to find the one with the smallest time difference. for (Record pay: pays) { long delta = Math.abs(logTime - pay.getDatetime(0).getTime()); if (delta < minDelta) { minDelta = delta; nearestPay = pay; } } // Merge the log record with the nearest payment record and output the result. outputRecord.setBigint(1, log.getDatetime(0).getTime()); outputRecord.setString(2, mergeLog(nearestPay.getString(1), log.getString(1))); output.yield(outputRecord); } } String mergeLog(String payInfo, String logContent) { return logContent + ", pay " + payInfo; } @Override public void close() { } }Add JAR package resources to MaxCompute.
ADD jar odps-udj-example.jar;Register the UDJ function pay_user_log_merge_join in MaxCompute.
CREATE FUNCTION pay_user_log_merge_join AS 'com.aliyun.odps.udf.example.udj.PayUserLogMergeJoin' USING 'odps-udj-example.jar';
Prepare sample data.
Create the payment table and the user_client_log table.
CREATE TABLE payment(user_id STRING,time DATETIME,pay_info STRING); CREATE TABLE user_client_log(user_id STRING,time DATETIME,content STRING);Insert data into the tables.
--Insert data into the payment table. INSERT OVERWRITE TABLE payment VALUES ('1335656', datetime '2018-02-13 19:54:00', 'PEqMSHyktn'), ('2656199', datetime '2018-02-13 12:21:00', 'pYvotuLDIT'), ('2656199', datetime '2018-02-13 20:50:00', 'PEqMSHyktn'), ('2656199', datetime '2018-02-13 22:30:00', 'gZhvdySOQb'), ('8881237', datetime '2018-02-13 08:30:00', 'pYvotuLDIT'), ('8881237', datetime '2018-02-13 10:32:00', 'KBuMzRpsko'), ('9890100', datetime '2018-02-13 16:01:00', 'gZhvdySOQb'), ('9890100', datetime '2018-02-13 16:26:00', 'MxONdLckwa') ; --Insert data into the user_client_log table. INSERT OVERWRITE TABLE user_client_log VALUES ('1000235', datetime '2018-02-13 00:25:36', 'click FNOXAibRjkIaQPB'), ('1000235', datetime '2018-02-13 22:30:00', 'click GczrYaxvkiPultZ'), ('1335656', datetime '2018-02-13 18:30:00', 'click MxONdLckpAFUHRS'), ('1335656', datetime '2018-02-13 19:54:00', 'click mKRPGOciFDyzTgM'), ('2656199', datetime '2018-02-13 08:30:00', 'click CZwafHsbJOPNitL'), ('2656199', datetime '2018-02-13 09:14:00', 'click nYHJqIpjevkKToy'), ('2656199', datetime '2018-02-13 21:05:00', 'click gbAfPCwrGXvEjpI'), ('2656199', datetime '2018-02-13 21:08:00', 'click dhpZyWMuGjBOTJP'), ('2656199', datetime '2018-02-13 22:29:00', 'click bAsxnUdDhvfqaBr'), ('2656199', datetime '2018-02-13 22:30:00', 'click XIhZdLaOocQRmrY'), ('4356142', datetime '2018-02-13 18:30:00', 'click DYqShmGbIoWKier'), ('4356142', datetime '2018-02-13 19:54:00', 'click DYqShmGbIoWKier'), ('8881237', datetime '2018-02-13 00:30:00', 'click MpkvilgWSmhUuPn'), ('8881237', datetime '2018-02-13 06:14:00', 'click OkTYNUHMqZzlDyL'), ('8881237', datetime '2018-02-13 10:30:00', 'click OkTYNUHMqZzlDyL'), ('9890100', datetime '2018-02-13 16:01:00', 'click vOTQfBFjcgXisYU'), ('9890100', datetime '2018-02-13 16:20:00', 'click WxaLgOCcVEvhiFJ') ;
Use the UDJ in SQL.
SELECT r.user_id, FROM_UNIXTIME(time/1000) AS time, content FROM ( SELECT user_id, time AS time, pay_info FROM payment ) p JOIN ( SELECT user_id, time AS time, content FROM user_client_log ) u ON p.user_id = u.user_id USING pay_user_log_merge_join(p.time, p.pay_info, u.time, u.content) r AS (user_id, time, content);Parameters in the USING clause:
pay_user_log_merge_joinis the name of the registered UDJ function.(p.time, p.pay_info, u.time, u.content)specifies the columns from the left and right tables that are used in the UDJ.ris the alias for the UDJ result. You can reference this alias elsewhere.(user_id, time, content)specifies the column names for the result generated by the UDJ.
In this example, the following result is returned:
+---------+------------+---------+ | user_id | time | content | +---------+------------+---------+ | 1000235 | 2018-02-13 00:25:36 | click FNOXAibRjkIaQPB | | 1000235 | 2018-02-13 22:30:00 | click GczrYaxvkiPultZ | | 1335656 | 2018-02-13 18:30:00 | click MxONdLckpAFUHRS, pay PEqMSHyktn | | 1335656 | 2018-02-13 19:54:00 | click mKRPGOciFDyzTgM, pay PEqMSHyktn | | 2656199 | 2018-02-13 08:30:00 | click CZwafHsbJOPNitL, pay pYvotuLDIT | | 2656199 | 2018-02-13 09:14:00 | click nYHJqIpjevkKToy, pay pYvotuLDIT | | 2656199 | 2018-02-13 21:05:00 | click gbAfPCwrGXvEjpI, pay PEqMSHyktn | | 2656199 | 2018-02-13 21:08:00 | click dhpZyWMuGjBOTJP, pay PEqMSHyktn | | 2656199 | 2018-02-13 22:29:00 | click bAsxnUdDhvfqaBr, pay gZhvdySOQb | | 2656199 | 2018-02-13 22:30:00 | click XIhZdLaOocQRmrY, pay gZhvdySOQb | | 4356142 | 2018-02-13 18:30:00 | click DYqShmGbIoWKier | | 4356142 | 2018-02-13 19:54:00 | click DYqShmGbIoWKier | | 8881237 | 2018-02-13 00:30:00 | click MpkvilgWSmhUuPn, pay pYvotuLDIT | | 8881237 | 2018-02-13 06:14:00 | click OkTYNUHMqZzlDyL, pay pYvotuLDIT | | 8881237 | 2018-02-13 10:30:00 | click OkTYNUHMqZzlDyL, pay KBuMzRpsko | | 9890100 | 2018-02-13 16:01:00 | click vOTQfBFjcgXisYU, pay gZhvdySOQb | | 9890100 | 2018-02-13 16:20:00 | click WxaLgOCcVEvhiFJ, pay MxONdLckwa | +---------+------------+---------+
Pre-sorting of UDJ
To find the record with the smallest time difference, you must repeatedly traverse the data in the `payment` table using an iterator. Therefore, all payment records that have the same `user_id` are loaded into an `ArrayList` in advance. This method is applicable to scenarios where a user has a small number of payment behaviors within a day. In other scenarios, the amount of data in the same group may be too large to be stored in memory. In this case, you can use `SORT BY` pre-sorting to resolve this issue.
If the number of payment records for a user is excessively large and cannot be stored in the memory and all data in the table is sorted by time, you need to only compare the first element in the ArrayList.
The following example shows the Java UDJ code.
@Override public void join(Record key, Iterator<Record> left, Iterator<Record> right, Yieldable<Record> output) { outputRecord.setString(0, key.getString(0)); if (!right.hasNext()) { return; } else if (!left.hasNext()) { while (right.hasNext()) { Record logRecord = right.next(); outputRecord.setBigint(1, logRecord.getDatetime(0).getTime()); outputRecord.setString(2, logRecord.getString(1)); output.yield(outputRecord); } return; } long prevDelta = Long.MAX_VALUE; Record logRecord = right.next(); Record payRecord = left.next(); Record lastPayRecord = payRecord.clone(); while (true) { long delta = logRecord.getDatetime(0).getTime() - payRecord.getDatetime(0).getTime(); if (left.hasNext() && delta > 0) { // The time difference between the two records is decreasing, so we can still proceed. // Explore the left group to try to obtain a smaller delta. lastPayRecord = payRecord.clone(); prevDelta = delta; payRecord = left.next(); } else { // The minimum delta point is reached. Check the last record, // output the merged result, and prepare to process the next record from // the right group. Record nearestPay = Math.abs(delta) < prevDelta ? payRecord : lastPayRecord; outputRecord.setBigint(1, logRecord.getDatetime(0).getTime()); String mergedString = mergeLog(nearestPay.getString(1), logRecord.getString(1)); outputRecord.setString(2, mergedString); output.yield(outputRecord); if (right.hasNext()) { logRecord = right.next(); prevDelta = Math.abs( logRecord.getDatetime(0).getTime() - lastPayRecord.getDatetime(0).getTime() ); } else { break; } } } }After you modify the Java UDJ code, you must update the corresponding JAR package for the new logic to take effect.
Add the SORT BY clause to the end of the UDJ statement to sort the left and right tables in the UDJ group by their respective time fields. The following is the SQL code.
SELECT r.user_id, from_unixtime(time/1000) AS time, content FROM ( SELECT user_id, time AS time, pay_info FROM payment ) p JOIN ( SELECT user_id, time AS time, content FROM user_client_log ) u ON p.user_id = u.user_id USING pay_user_log_merge_join(p.time, p.pay_info, u.time, u.content) r AS (user_id, time, content) SORT BY p.time, u.time;The result is consistent with the result of the example in the Cross join operations using UDJ section. This method uses the `SORT BY` clause to pre-sort the UDJ data. In this process, you only need to cache a maximum of three records at a time to implement the same feature as the previous algorithm.