The Container Storage Interface (CSI) components include csi-plugin and csi-provisioner. These components allow you to dynamically create, attach, and detach volumes.
Component introduction
When you create a cluster, the following CSI components are installed by default:
Component | Description | Deployment type |
csi-plugin | Mounts, unmounts, and formats volumes. | DaemonSet |
csi-provisioner | Dynamically creates and scales out volumes, and creates snapshots. By default, it supports the creation of Elastic Block Storage, NAS, and OSS volumes. | Deployment |
Note When you create a new cluster, the managed version of csi-provisioner is installed by default. Alibaba Cloud is responsible for the operations and maintenance (O&M) of managed components, so you cannot see the related pods in your cluster.
Upgrade csi-plugin and csi-provisioner
You can view the versions of the csi-plugin and csi-provisioner components and upgrade them in the console.
Important If you are using the csi-compatible-controller component to migrate FlexVolume to CSI and the migration is not complete, you cannot automatically upgrade the csi-plugin and csi-provisioner components. You must complete the migration before you upgrade the components. Alternatively, you can manually upgrade the CSI components during the migration. For more information, see Upgrade components.
Log on to the ACK console. In the navigation pane on the left, click Clusters.
On the Clusters page, find the one you want to manage and click its name. In the navigation pane on the left, click Add-ons.
Click the Storage tab. In the csi-plugin and csi-provisioner sections, check for available upgrades and then upgrade the components.
FAQ
Component issues
The CSI component fails to start, the image pull fails, and an exec /usr/bin/plugin.csi.alibabacloud.com: exec format error error occurs
Symptom
The csi-plugin container in the pod of the csi-plugin component reports an exec /usr/bin/plugin.csi.alibabacloud.com: exec format error error.
Cause
By default, csi-plugin supports both amd64 and arm64 architectures. If the pod runs on a node with an amd64 or arm64 architecture, this error may occur because the image pull is incomplete. An incomplete image pull means that the image metadata exists, but the image was not successfully pulled. This makes the binary invalid. An image pull can fail if the node is forcibly shut down during the process. You can check the ActionTrail logs for the ECS instance to determine whether a shutdown command was executed.
Solution
Scale out the cluster by adding a new node, and then drain the current node.
If you do not want to add a new node, perform the following steps:
Drain the applications from the current node and then remove the node from the cluster.
Log on to the node and delete all containers, if any.
Delete all files in the /var/lib/containerd directory.
Add the node back to the cluster.
Out-of-memory (OOM) issues caused by storage components
The sidecar container in the pod of the csi-provisioner component caches information such as pods, persistent volumes (PVs), and PersistentVolumeClaims (PVCs). This can cause an out-of-memory (OOM) error as the cluster size increases.
If you use the managed version of the csi-provisioner component, submit a ticket for assistance.
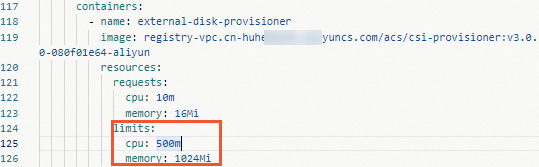
If you use the self-managed version of the csi-provisioner component and an OOM error occurs, you must adjust the memory limit based on your cluster size. Perform the following steps:
Log on to the ACK console. In the navigation pane on the left, click Clusters.
On the Clusters page, find the one you want to manage and click its name. In the navigation pane on the left, click Add-ons.
On the Component Management page, find the csi-provisioner component, click the  icon, and select View YAML.
icon, and select View YAML.
Modify the component's YAML file to adjust the memory limit based on your cluster size.
High network traffic is observed for the csi-plugin pod
Symptom
Pod monitoring shows high network traffic for the csi-plugin pod.
Cause
The csi-plugin component is responsible for mounting NAS volumes on nodes, which generates network traffic. When a pod on a node uses a NAS volume, the NAS request traffic from that pod passes through the csi-plugin namespace. This traffic is then recorded by cluster monitoring, which reports high network traffic for the csi-plugin pod.
Solution
No action is required. This traffic is only recorded by the monitoring component. It is not duplicated and does not consume extra network bandwidth.
The csi-provisioner component log shows a failed to renew lease xxx timed out waiting for the condition error
Symptom
When you run the kubectl logs csi-provisioner-xxxx -n kube-system command to view the CSI logs, you may find a failed to renew lease xxx timed out waiting for the condition error.
Cause
The csi-provisioner component is a high availability (HA) component that runs multiple replicas. The pods use the Kubernetes Lease object for leader election. During this process, a pod must access the API server to acquire a specific lease. The pod that acquires the lease becomes the leader and provides services to the cluster. This error occurs when a csi-provisioner pod fails to access the API server.
Solution
Check whether the cluster network and the API server are functioning normally. If the issue persists, submit a ticket for assistance.
Component upgrade failures
The csi-plugin component pre-check fails
If your cluster does not use disk, NAS, or OSS volumes, or if the cluster is a test environment, you can manually update the image to upgrade the csi-plugin component.
The following is a sample command. Replace <image url> with the URL of the image for the new version. For more information, see csi-plugin.
kubectl set image -n kube-system daemonset/csi-plugin csi-plugin=<image url>
If your cluster uses disk, NAS, or OSS volumes and contains critical business data, submit a ticket to request assistance with a manual upgrade.
The csi-plugin component pre-check passes, but the upgrade fails
The csi-plugin component is a DaemonSet. The upgrade fails if the cluster contains nodes that are in the NotReady state or any state other than Running. You must manually fix the faulty nodes and then try the upgrade again.
If you cannot determine the cause, submit a ticket to request assistance with a manual upgrade.
The console shows the csi-plugin component but not the csi-provisioner component
Earlier versions of csi-provisioner (1.14 and earlier) were deployed as a StatefulSet. If a csi-provisioner StatefulSet exists in your cluster, run the kubectl delete sts csi-provisioner command to delete it. Then, reinstall the csi-provisioner component.
If an error occurs, submit a ticket to request assistance with a manual upgrade.
The csi-provisioner component pre-check fails
If your cluster does not use dynamically provisioned volumes of the disk, NAS, or OSS type that were created using a StorageClass, or if the cluster is a test environment, you can manually update the image to upgrade the csi-provisioner component.
The following is a sample command. Replace <image url> with the URL of the image for the new version. For more information, see csi-provisioner.
kubectl set image -n kube-system deployment/csi-provisioner csi-provisioner=<image url>
If your cluster uses dynamically provisioned volumes of the disk, NAS, or OSS type that were created using a StorageClass and the cluster contains critical business data, submit a ticket to request assistance with a manual upgrade.
The csi-provisioner component pre-check passes, but the upgrade fails
submit a ticket to request assistance with a manual upgrade.
The csi-provisioner component upgrade fails because the number of cluster nodes does not meet requirements
Symptoms
Symptom 1: The csi-provisioner component pre-check fails with an error indicating that the number of cluster nodes does not meet the requirements.
Symptom 2: The csi-provisioner component pre-check and upgrade succeed, but the component's pod enters the CrashLoopBackOff state. The log shows an error similar to the following 403 Forbidden message.
time="2023-08-05T13:54:00+08:00" level=info msg="Use node id : <?xml version=\"1.0\" encoding=\"iso-8859-1\"?>\n<!DOCTYPE html PUBLIC \"-//W3C//DTD XHTML 1.0 Transitional//EN\"\n \"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd\">\n<html xmlns=\"http://www.w3.org/1999/xhtml\" xml:lang=\"en\" lang=\"en\">\n <head>\n <title>403 - Forbidden</title>\n </head>\n <body>\n <h1>403 - Forbidden</h1>\n </body>\n</html>\n"
Causes
Cause of Symptom 1: To ensure high availability, csi-provisioner runs primary and secondary pods that must be deployed on different nodes. The component upgrade fails if the cluster has only one node.
Cause of Symptom 2: Security hardening is enabled on the node where the csi-provisioner pod is running. This mode blocks access to the metadata server on the node, which causes the error.
Solutions
The csi-provisioner component upgrade fails due to changes in StorageClass properties
Symptom
The csi-provisioner component pre-check fails with an error indicating that the StorageClass properties do not meet expectations.
Cause
The properties of the default StorageClass were changed. This can happen if you delete and then recreate a StorageClass with the same name. StorageClass properties are immutable. If you change them, the component upgrade fails.
Solution
You must delete the default StorageClasses in the cluster, such as alicloud-disk-essd, alicloud-disk-available, alicloud-disk-efficiency, alicloud-disk-ssd, and alicloud-disk-topology. This deletion does not affect existing applications. After you delete the StorageClasses, try to reinstall the csi-provisioner component. After the installation is complete, the system automatically recreates the StorageClasses. No further action is required.
Important If you need a custom StorageClass, create a new one with a different name. Do not modify the default StorageClasses.