This topic describes common issues and solutions that you may encounter when you use the node autoscaling feature.
Index
Category | Subcategory | Link |
Scale-out and scale-in behavior of node autoscaling | ||
Custom scaling behavior | ||
cluster-autoscaler component | ||
Known limitations
Cannot estimate available node resources with 100% accuracy
The underlying system of an ECS instance consumes some resources. This means the available memory of an instance is less than what is defined in its instance type specifications. For more information, see Why is the memory size different from the instance type specification after I purchase an instance?. Because of this constraint, the schedulable resources of a node estimated by the cluster-autoscaler component may be greater than the actual schedulable resources. The estimation cannot be 100% accurate. Note the following when you configure pod requests.
When you configure pod request values, the total requested resources, including CPU, memory, and disk, must be less than the instance type specifications. The total requests should not exceed 70% of the node resources.
When the cluster-autoscaler component checks whether a node has sufficient resources, it considers only Kubernetes pod resources, including pending pods and DaemonSet pods. If a node has static pods that are not part of a DaemonSet, you must reserve resources for these pods in advance.
If a pod requests a large amount of resources, such as more than 70% of the node resources, you should test and confirm in advance that the pod can be scheduled to a node of the same instance type to ensure feasibility.
Supports limited scheduling policies
The cluster-autoscaler component supports only a limited set of scheduling policies to determine whether an unschedulable pod can be scheduled to a node pool where autoscaling is enabled. For more information, see What scheduling policies does the cluster-autoscaler component use to determine whether an unschedulable pod can be scheduled to a node pool where autoscaling is enabled?.
Only supports resource policies of the resource type
When you use a resource policy to customize the priority of elastic resources, only policies of the resource type are supported. For more information, see Customize the scheduling priority of elastic resources.
apiVersion: scheduling.alibabacloud.com/v1alpha1 kind: ResourcePolicy metadata: name: nginx namespace: default spec: selector: app: nginx units: - resource: ecs - resource: eciDoes not support scaling out a specific instance type for a node pool configured with multiple instance types
If your node pool is configured with multiple instance types, you cannot specify an instance type for a scale-out. The cluster-autoscaler component uses the minimum value across all instance types for each resource dimension as the baseline for resource calculation. For more information, see If a scaling group is configured with multiple instance types, how are the resources of this scaling group calculated during autoscaling?.
Pods that must run in a specific zone cannot trigger scale-outs for multi-zone node pools
If your node pool is configured for multiple zones and you have pods that must run in a specific zone, the cluster-autoscaler component may not be able to create a node in the required zone. For example, a pod might use a persistent volume (PV) that is located in a specific zone, or a pod might have a nodeSelector for a specific zone. For more scenarios in which the cluster-autoscaler component cannot create nodes, see Why does the node autoscaling component fail to create nodes?.
Scale-out behavior
What scheduling policies does the cluster-autoscaler component use to determine whether an unschedulable pod can be scheduled to a node pool where autoscaling is enabled?
The cluster-autoscaler component uses the following scheduling policies.
PodFitsResources
GeneralPredicates
PodToleratesNodeTaints
MaxGCEPDVolumeCount
NoDiskConflict
CheckNodeCondition
CheckNodeDiskPressure
CheckNodeMemoryPressure
CheckNodePIDPressure
CheckVolumeBinding
MaxAzureDiskVolumeCount
MaxEBSVolumeCount
ready
NoVolumeZoneConflict
What resources can the cluster-autoscaler component simulate and check?
The cluster-autoscaler component supports the simulation and checking of the following resources:
cpu memory sigma/eni ephemeral-storage aliyun.com/gpu-mem (shared GPUs only) nvidia.com/gpuIf you need other resource types, see How do I configure custom resources for a node pool where autoscaling is enabled?.
Why does the node autoscaling component fail to create nodes?
Check whether any of the following scenarios apply:
Node autoscaling works only for node pools for which autoscaling is configured. Make sure that the node autoscaling feature is enabled and that the scaling mode for the node pool is set to automatic. For more information, see Enable node autoscaling.
The instance types in the scaling group cannot meet the pod's resource requests. The resource size specified for an ECS instance type is its sales specification. In reality, ACK reserves some node resources for kube components and system processes to ensure the normal operation of the OS kernel, system services, and Kubernetes daemon processes. This causes a difference between the total resource capacity of a node and its allocatable resources.
When the cluster-autoscaler component makes a scale-out decision, its built-in resource reservation policy is consistent across all ACK cluster versions. It uses the resource reservation policy for versions 1.28 and earlier.
To apply the resource reservation policy for versions 1.28 and later, we recommend that you switch to real-time node scaling, which has a new resource reservation algorithm for versions 1.28 and later. Alternatively, you can manually configure and maintain custom resources for the node pool by defining and maintaining resource reservation values in the node pool.
During instance creation, some resources are consumed by virtualization and the operating system. For more information, see Why is the memory size different from the instance type specification after I purchase an instance?.
Some node resources are required to run components such as kubelet, kube-proxy, Terway, and Container Runtime. For more information, see Node resource reservation policy.
By default, system components are installed on nodes. The resources requested by a pod must be less than the instance specifications.
A pod with zone constraints cannot trigger a scale-out for a node pool that is configured for multiple zones.
Check whether the authorization steps were fully completed. Authorization is performed at the cluster level and must be completed for each cluster. For more information about authorization, see the prerequisites in Prerequisites.
The following exceptions occurred in the node pool where autoscaling is enabled.
The instance fails to join the cluster and times out.
The node is NotReady and times out.
To ensure future scaling accuracy, the autoscaling component handles exceptions with a damping mechanism. It does not perform scale-outs or scale-ins until the exceptional nodes are handled.
There are no nodes in the cluster, so the cluster-autoscaler component cannot run. You should configure at least two nodes when you create a node pool to ensure the normal operation of cluster components.
If your scenario involves scaling out from zero nodes or scaling in to zero nodes, use real-time node scaling. For more information, see Enable real-time node scaling.
If a scaling group is configured with multiple instance types, how are the resources of this scaling group calculated during autoscaling?
For a scaling group configured with multiple instance types, the autoscaling component uses the minimum value across all instance types for each resource dimension as the baseline for resource calculation.
For example, if a scaling group is configured with two instance types, one with 4 CPU cores and 32 GB of memory, and the other with 8 CPU cores and 16 GB of memory, the autoscaling component assumes that the scaling group can guarantee a scale-out of an instance with 4 CPU cores and 16 GB of memory. Therefore, if the requests of a pending pod exceed 4 cores or 16 GB, a scale-out will not occur.
If you have configured multiple instance types and need to consider resource reservation, see Why does the node autoscaling component fail to create nodes?.
During autoscaling, how does the system choose among multiple node pools where autoscaling is enabled?
When a pod is unschedulable, it triggers the simulation logic of the autoscaling component. The component makes a decision based on the labels, taints, and instance types configured for the scaling group. When a configured scaling group can simulate scheduling the pod, it is selected to create a node. If multiple node pools with autoscaling enabled meet the simulation conditions at the same time, the node autoscaling component uses the least-waste principle by default. This means it selects the node pool that will have the fewest remaining resources after the new node is created.
How do I configure custom resources for a node pool where autoscaling is enabled?
You can configure ECS tags with a specific prefix for a node pool where autoscaling is enabled. This allows the autoscaling component to identify the custom resources available in the node pool or the exact values of specified resources.
k8s.io/cluster-autoscaler/node-template/resource/{resource_name}:{resource_size}Example:
k8s.io/cluster-autoscaler/node-template/resource/hugepages-1Gi:2GiWhy does enabling auto scaling for a node pool fail?
Possible reasons are as follows:
The node pool is the default node pool, which does not support the node autoscaling feature.
The node pool already contains manually added nodes. You must remove the manually added nodes first. We recommend that you create a new node pool with autoscaling enabled.
The node pool contains subscription instances. The node autoscaling feature does not support subscription nodes.
Scale-in behavior
Why does the cluster-autoscaler component fail to scale in nodes?
Check whether any of the following scenarios apply:
The resource request threshold for the node's pods is higher than the configured scale-in threshold.
The node is running pods from the kube-system namespace.
Pods on the node have mandatory scheduling policies that prevent them from running on other nodes.
Pods on the node have a PodDisruptionBudget, and the minimum number of pods required by the PodDisruptionBudget has been reached.
For more frequently asked questions and answers about the node autoscaling component, see the open source community documentation.
How do I enable or disable eviction for a specific DaemonSet?
The cluster-autoscaler component decides whether to evict DaemonSet pods based on the Drain DaemonSet Pods configuration. This configuration is cluster-wide and applies to all DaemonSet pods in the cluster. For more information, see Step 1: Enable node autoscaling for the cluster. To specify whether a particular DaemonSet pod should be evicted, add the annotation "cluster-autoscaler.kubernetes.io/enable-ds-eviction": "true" to that DaemonSet pod.
Similarly, if a DaemonSet pod has the annotation "cluster-autoscaler.kubernetes.io/enable-ds-eviction": "false", the cluster-autoscaler is explicitly forbidden from evicting that DaemonSet pod.
If draining of DaemonSet pods is disabled, this annotation is effective only for DaemonSet pods on non-empty nodes. To enable it for DaemonSet pods on empty nodes, you must first enable draining of DaemonSet pods.
This annotation must be specified on the DaemonSet pod, not on the DaemonSet object itself.
This annotation has no effect on pods that do not belong to any DaemonSet.
By default, the cluster-autoscaler evicts DaemonSet pods in a non-blocking mode. This means it proceeds to the next step without waiting for the DaemonSet pod eviction to complete. If you need the cluster-autoscaler to wait for a specific DaemonSet pod to be evicted before proceeding with the scale-in, add the annotation
"cluster-autoscaler.kubernetes.io/wait-until-evicted": "true"to the pod in addition to the enablement configuration.
What types of pods can prevent the cluster-autoscaler component from removing a node?
The cluster-autoscaler component might be prevented from removing a node if the pod was not created by a native Kubernetes controller, such as a deployment, ReplicaSet, job, or StatefulSet, or if pods on the node cannot be safely terminated or migrated. For more information, see What types of pods can prevent CA from removing a node?.
Extension support
Does the cluster-autoscaler component support CRDs?
The cluster-autoscaler component currently supports only standard Kubernetes objects and does not support Kubernetes CRDs.
Control scaling behavior using pods
How do I delay the scale-out response time of the cluster-autoscaler component for unschedulable pods?
You can set a scale-up delay for each pod using the annotation cluster-autoscaler.kubernetes.io/pod-scale-up-delay. If Kubernetes does not schedule the pod by the end of this delay, the cluster-autoscaler may consider scaling up for it. Example annotation: "cluster-autoscaler.kubernetes.io/pod-scale-up-delay": "600s".
How do I use pod annotations to affect node scale-ins by the cluster-autoscaler component?
You can specify whether a pod should prevent a node from being scaled in by the cluster-autoscaler component.
To prevent a node from being scaled in, add the annotation
"cluster-autoscaler.kubernetes.io/safe-to-evict": "false"to the pod.To allow a node to be scaled in, add the annotation
"cluster-autoscaler.kubernetes.io/safe-to-evict": "true"to the pod.
Control scaling behavior using nodes
How do I prevent a node from being scaled in by the cluster-autoscaler component?
To prevent a target node from being scaled in by the cluster-autoscaler, you can configure the annotation "cluster-autoscaler.kubernetes.io/scale-down-disabled": "true" for the node. The following is an example command to add the annotation.
kubectl annotate node <nodename> cluster-autoscaler.kubernetes.io/scale-down-disabled=truecluster-autoscaler component related
How do I upgrade the cluster-autoscaler component to the latest version?
For clusters where autoscaling is enabled, you can upgrade the cluster-autoscaler component as follows:
Log on to the ACK console. In the navigation pane on the left, click Clusters.
On the Clusters page, find the cluster to manage and click its name. In the left-side navigation pane, choose .
Click Edit to the right of Node Scaling. In the panel that appears, click OK to upgrade the component to the latest version.
What operations trigger automatic updates of the cluster-autoscaler component?
To ensure that the configuration of the cluster-autoscaler component is up-to-date and compatible with the cluster, the following operations trigger an automatic update of the cluster-autoscaler component:
Updating the autoscaling configuration.
Creating, deleting, or updating a node pool where autoscaling is enabled.
Successfully upgrading the cluster.
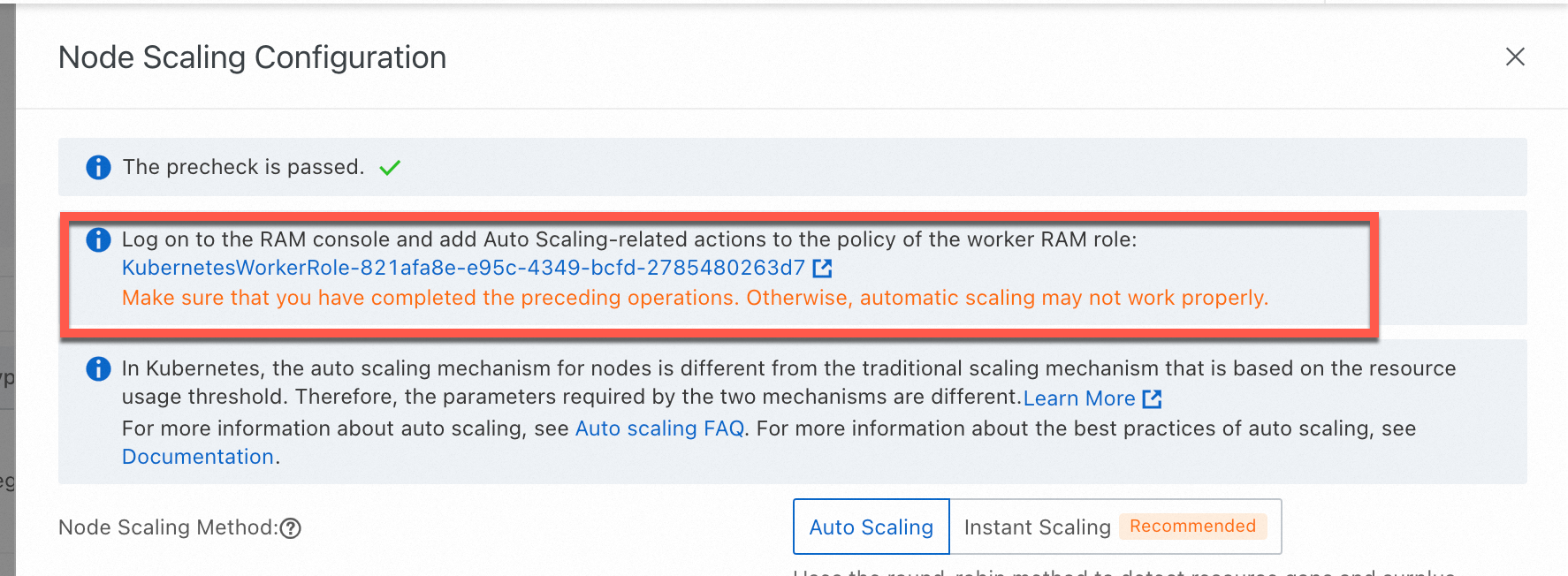
Role authorization for an ACK managed cluster is complete, but node scaling activities still do not work. Why?
This may be because the secret addon.aliyuncsmanagedautoscalerrole.token does not exist in the kube-system namespace. By default, ACK uses the WorkerRole to implement related features. Follow the procedure below to grant the AliyunCSManagedAutoScalerRolePolicy permission to the WorkerRole for a dedicated cluster.
On the Clusters page, click the name of the target cluster. In the navigation pane on the left, choose Cluster Information.
On the Clusters page, find the cluster to manage and click its name. In the left-side navigation pane, choose .
On the Node Pools page, click Configure to the right of Node Scaling.

Follow the on-screen instructions to grant permissions for the KubernetesWorkerRole role and the AliyunCSManagedAutoScalerRolePolicy system policy. The entry points are shown in the figure.
Manually restart the cluster-autoscaler deployment (node autoscaling) or the ack-goatscaler deployment (real-time node scaling) in the kube-system namespace for the permissions to take effect immediately.