# zookeeper集群
# 创建hadoop
sudo groupadd hadoop sudo useradd -m -g hadoop -s /bin/bash hadoop sudo passwd hadoop id hadoop su - hadoop # ssh登录
ssh-keygen -t rsa cd ~/.ssh/ cp id_rsa.pub authorized_keys chmod 700 .ssh/ chmod 600 .ssh/* ssh localhost # ssh登录
#slave1 slave2 slave3 cat ~/.ssh/id_rsa.pub | ssh hadoop@master 'cat >> ~/.ssh/authorized_keys' #master scp -r authorized_keys hadoop@slave1:~/.ssh/ scp -r authorized_keys hadoop@slave2:~/.ssh/ scp -r authorized_keys hadoop@slave3:~/.ssh/ ssh master ssh slave1 ssh slave2 ssh slave3 # jdk
sudo usermod -aG sudo hadoop su - hadoop sudo whoami sudo apt install openjdk-8-jdk java -version vi ~/.bashrc export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export PATH=$JAVA_HOME/bin:$PATH source ~/.bashrc # zookeeper
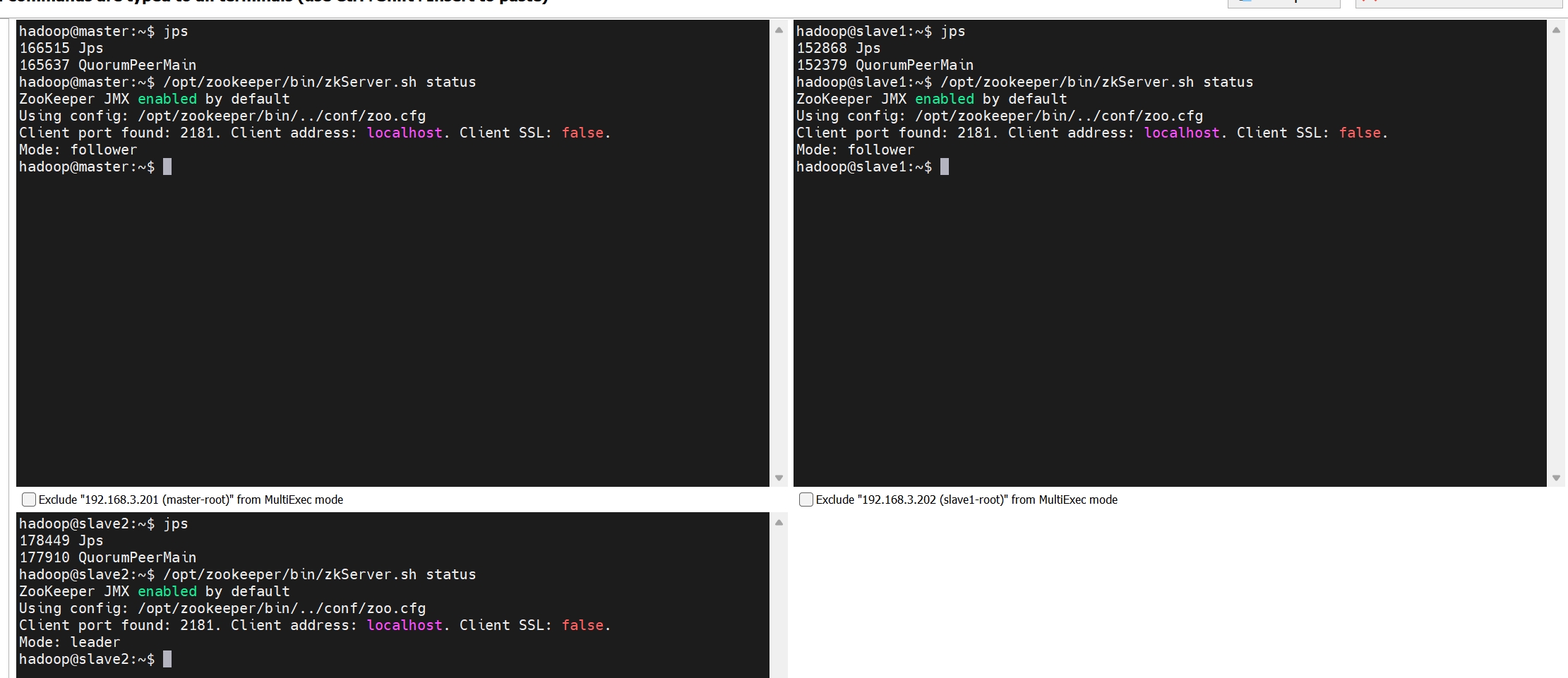
wget https://downloads.apache.org/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz tar -zxvf apache-zookeeper-3.8.4-bin.tar.gz sudo mv apache-zookeeper-3.8.4-bin /opt/zookeeper sudo mkdir -p /var/lib/zookeeper sudo mkdir -p /var/log/zookeeper sudo chown -R hadoop:hadoop /var/lib/zookeeper sudo chown -R hadoop:hadoop /var/log/zookeeper vi /opt/zookeeper/conf/zoo.cfg tickTime=2000 dataDir=/var/lib/zookeeper dataLogDir=/var/log/zookeeper clientPort=2181 initLimit=5 syncLimit=2 server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:3888 #master echo "1" | sudo tee /var/lib/zookeeper/myid #slave1 echo "2" | sudo tee /var/lib/zookeeper/myid #slave2 echo "3" | sudo tee /var/lib/zookeeper/myid sudo vi /etc/systemd/system/zookeeper.service [Unit] Description=Zookeeper Documentation=https://zookeeper.apache.org After=network.target [Service] Type=simple User=hadoop ExecStart=/opt/zookeeper/bin/zkServer.sh start-foreground /opt/zookeeper/conf/zoo.cfg ExecStop=/opt/zookeeper/bin/zkServer.sh stop /opt/zookeeper/conf/zoo.cfg Restart=on-abnormal [Install] WantedBy=multi-user.target sudo systemctl daemon-reload sudo systemctl enable zookeeper sudo systemctl start zookeeper sudo systemctl status zookeeper sudo systemctl stop zookeeper /opt/zookeeper/bin/zkServer.sh start /opt/zookeeper/conf/zoo.cfg /opt/zookeeper/bin/zkServer.sh stop /opt/zookeeper/conf/zoo.cfg /opt/zookeeper/bin/zkServer.sh start-foreground /opt/zookeeper/conf/zoo.cfg /opt/zookeeper/bin/zkServer.sh status /opt/zookeeper/bin/zkCli.sh -server master:2181 /opt/zookeeper/bin/zkCli.sh -server localhost:2181 # 错误
Cannot open channel to 2 at election address
https://www.cnblogs.com/tocode/p/10693715.html (opens new window)
server.1=0.0.0.0:2888:3888 本机器上ip地址改成0.0.0.0
# 启动成功
# hadoop
# 架构图
+-----------------+ | Zookeeper | | Ensemble | | | | master:2181 | | slave1:2181 | | slave2:2181 | +--------+--------+ | | +----------------+------------------+ | | | | | | +---------+------+ +-------+---------+ +------+---------+ | master | | slave1 | | slave2 | | 192.168.3.201 | | 192.168.3.202 | | 192.168.3.203 | | | | | | | | +-------------+ | | +-------------+ | | +-------------+| | |NameNode (nn1)| | |NameNode (nn2)| | | DataNode || | |ResourceManager| | |ResourceManager| | | NodeManager || | |JournalNode | | |JournalNode | | | JournalNode || | |DataNode | | |DataNode | | | || | |NodeManager | | |NodeManager | | | || | +-------------+ | | +-------------+ | | +-------------+| | HDFS | | HDFS | | HDFS | | High Availability | High Availability | Data Storage | +-----------------+ +-----------------+ +----------------+ # chatgpt提示词
已知环境: 本实验所用的3台机器版本号为:Ubuntu 22.04.4 LTS,机器规划如下: | Hostname | IP Address | User | |----------|-----------------|------| | master | 192.168.3.201 | hadoop | | slave1 | 192.168.3.202 | hadoop | | slave2 | 192.168.3.203 | hadoop | 三台机器hadoop用户登录,已经配置好ssh免密访问,三台机器的/etc/hosts如下: 192.168.3.201 master 192.168.3.202 slave1 192.168.3.203 slave2, 并且可以通过机器名称访问 三台机器java已经安装好,其中JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64, 可以跳过 三台机器zookeeper集群已经安装好,zookeeper安装目录如下/opt/zookeeper/,可以跳过 要求: hadoop用户下,安装hadoop 3.4.0集群,其中/opt/hadoop为hadoop安装路径,包括配置hdfs ha和yarn ha, 集群角色如下: master:NameNode (nn1) ResourceManager JournalNode NodeManager DataNode slave1:NameNode (nn2) ResourceManager JournalNode NodeManager DataNode slave2: JournalNode NodeManager DataNode # 在所有节点安装hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz tar -xzvf hadoop-3.4.0.tar.gz sudo mv hadoop-3.4.0 /opt/hadoop sudo chown -R hadoop:hadoop /opt/hadoop # ~/.bashrc export HADOOP_HOME=/opt/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop source ~/.bashrc # 配置core-site.xml
在所有节点的 /opt/hadoop/etc/hadoop/core-site.xml 文件中添加以下内容:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>master:2181,slave1:2181,slave2:2181</value> </property> </configuration> # 配置hdfs-site.xml
在所有节点的 /opt/hadoop/etc/hadoop/hdfs-site.xml 文件中添加以下内容:
<configuration> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>master:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>slave1:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>master:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>slave1:9870</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value> </property> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>shell(/bin/true)</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/hadoop/journal</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hadoop/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration> # 配置workers
在所有节点的 /opt/hadoop/etc/hadoop/workers 文件中,添加以下内容:
master slave1 slave2 # 在所有节点的start journalnode
hdfs --daemon start journalnode # master节点设置namenode
hdfs namenode -format hdfs zkfc -formatZK hdfs namenode # slave1节点设置namenode
hdfs namenode -bootstrapStandby 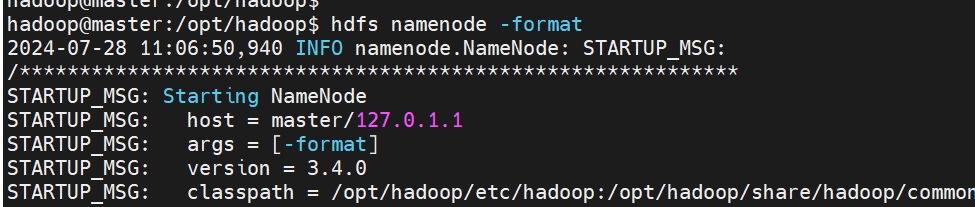
error分析
ha.BootstrapStandby: Unable to fetch namespace information from any remote NN. Possible NameNodes: [RemoteNameNodeInfo [nnId=nn1, ipcAddress=master/192.168.3.201:8020, httpAddress=http://master:9870]] 删除127.0.0.1 master 删除127.0.0.1 slave1 删除127.0.0.1 slave2
https://cloud.tencent.com/developer/article/1913706 (opens new window)
# 在所有节点stop journalnode
hdfs --daemon stop journalnode # 在所有节点设置hadoop-env.sh
/opt/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export HADOOP_HOME=/opt/hadoop # master节点启动集群
start-dfs.sh hdfs dfsadmin -report # 启动成功
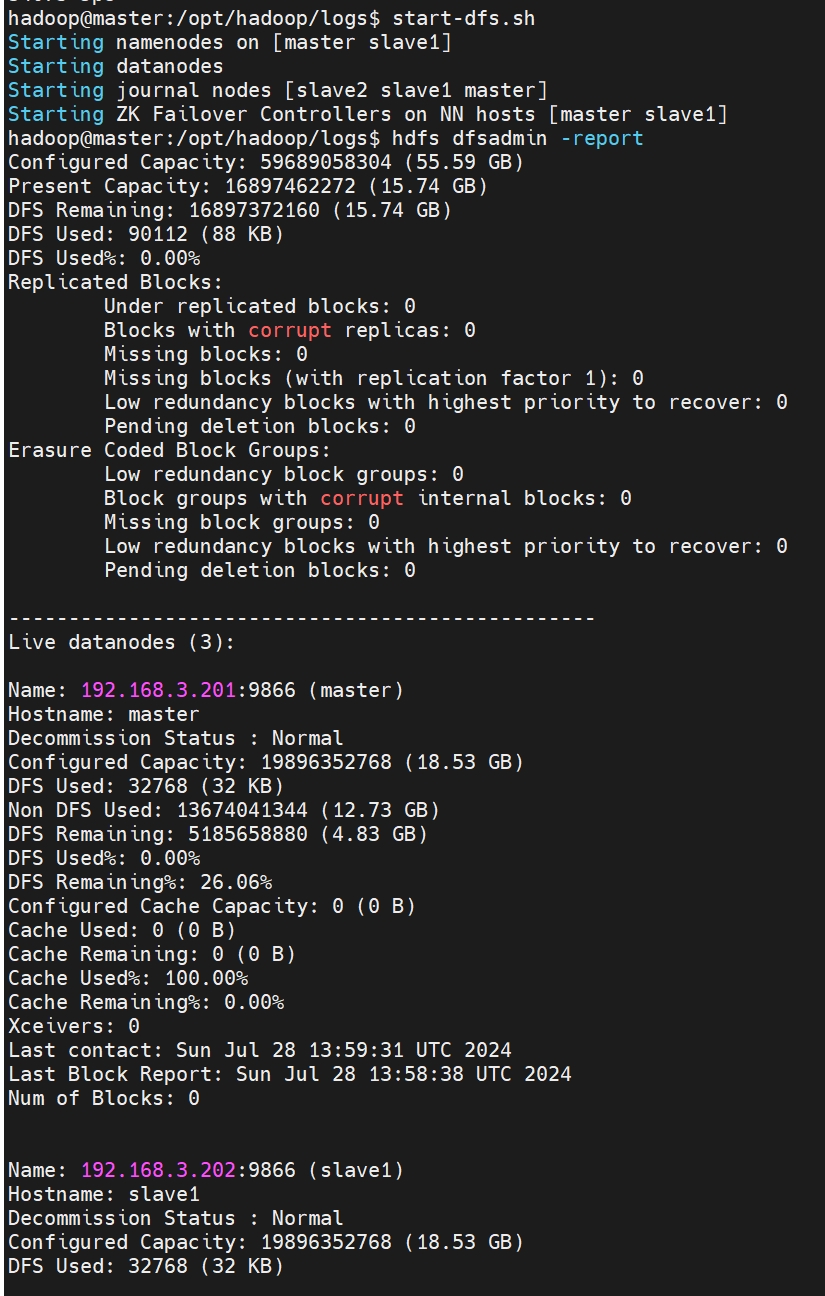
# web访问
http://192.168.3.201:9870 (opens new window) 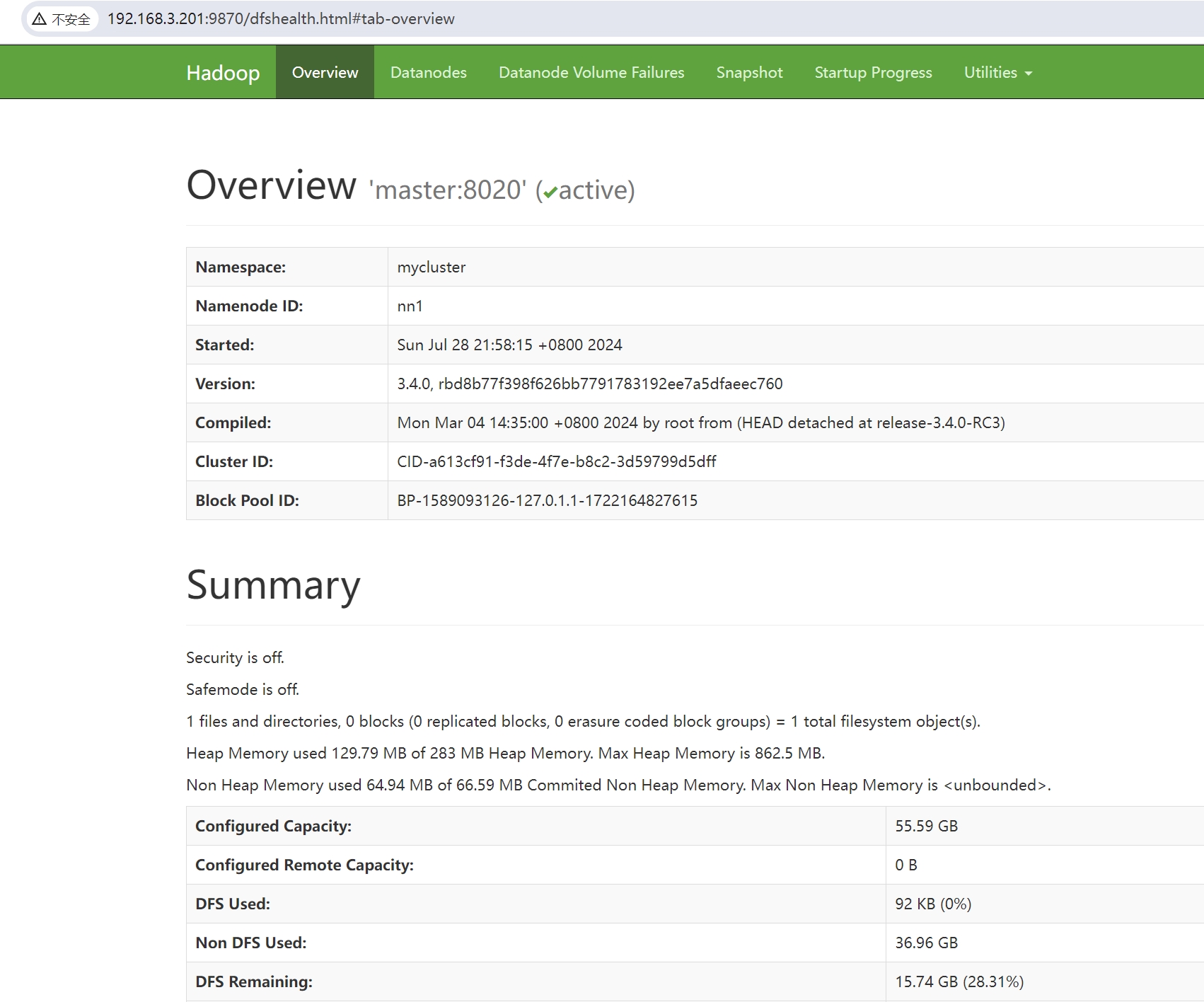
http://192.168.3.202:9870 (opens new window) 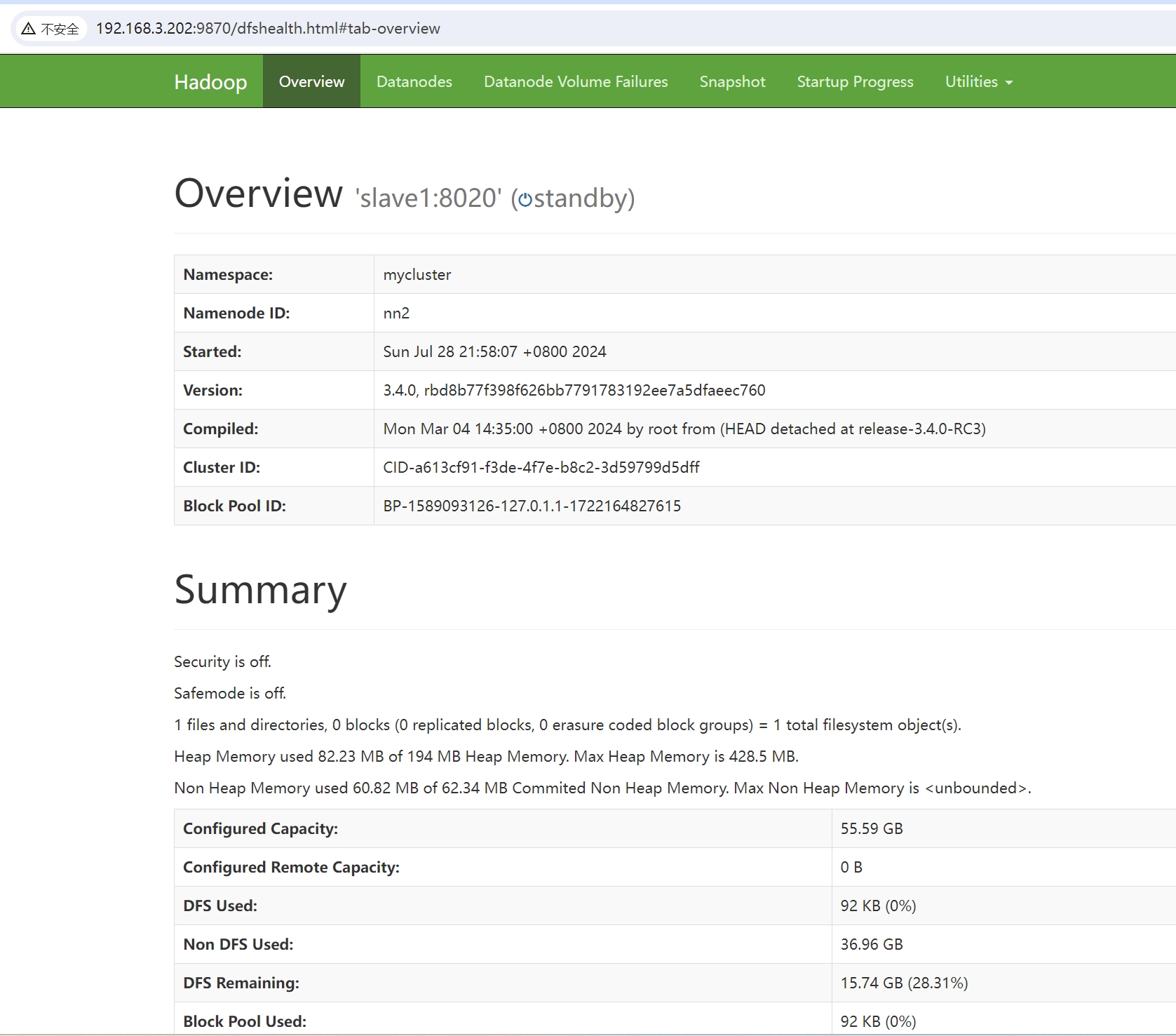
# 上传文件
vi myfile.txt hdfs dfs -mkdir /test hdfs dfs -put myfile.txt /test hdfs dfs -ls /test # 配置mapred-site
在所有节点的 /opt/hadoop/etc/hadoop/mapred-site.xml 文件中添加以下内容:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/opt/hadoop</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/opt/hadoop</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/opt/hadoop</value> </property> </configuration> # 配置yarn-site
在所有节点的 /opt/hadoop/etc/hadoop/yarn-site.xml 文件中添加以下内容:
<configuration> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.embedded</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-cluster</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>master</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>slave1</value> </property> <property> <name>yarn.resourcemanager.address.rm1</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>slave1:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>slave1:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>slave1:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm1</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm2</name> <value>slave1:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>master:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>slave1:8088</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>master:2181,slave1:2181,slave2:2181</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.zk-state-store.parent-path</name> <value>/rmstore</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration> # 启动yarn
在 master 节点上
start-yarn.sh yarn --daemon stop resourcemanager yarn --daemon start resourcemanager 启动日志
hadoop@master:~$ start-yarn.sh Starting resourcemanagers on [ master slave1] Starting nodemanagers 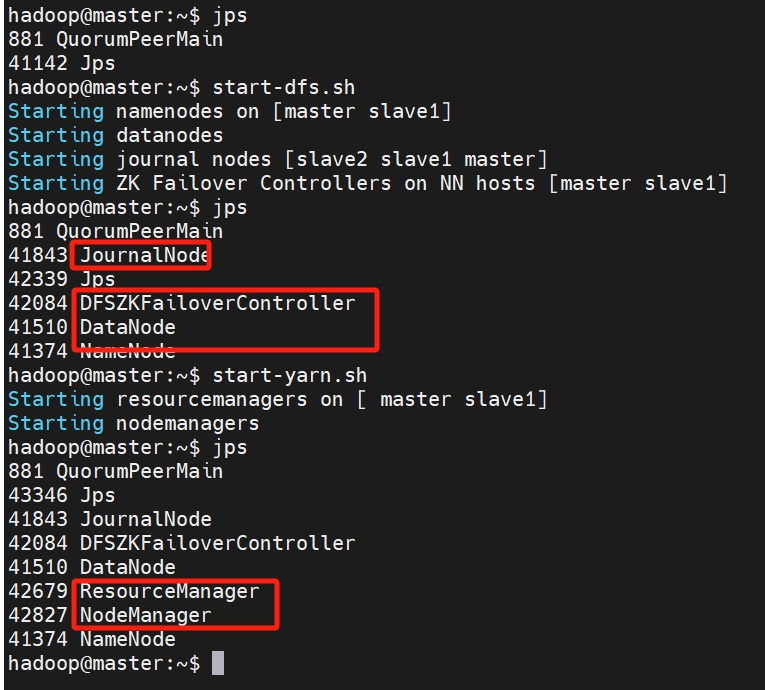
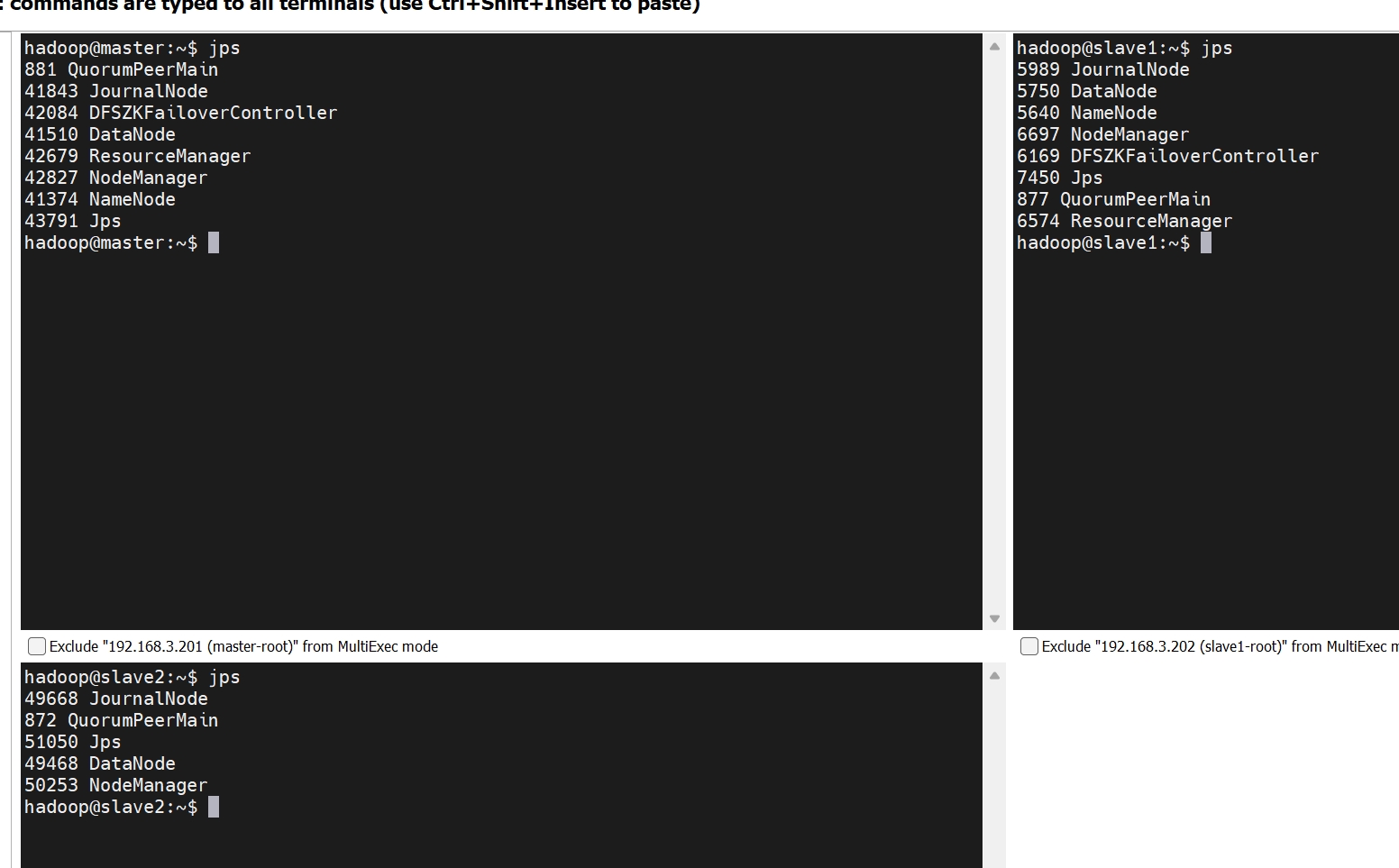
# web访问
http://192.168.3.201:8088 (opens new window) 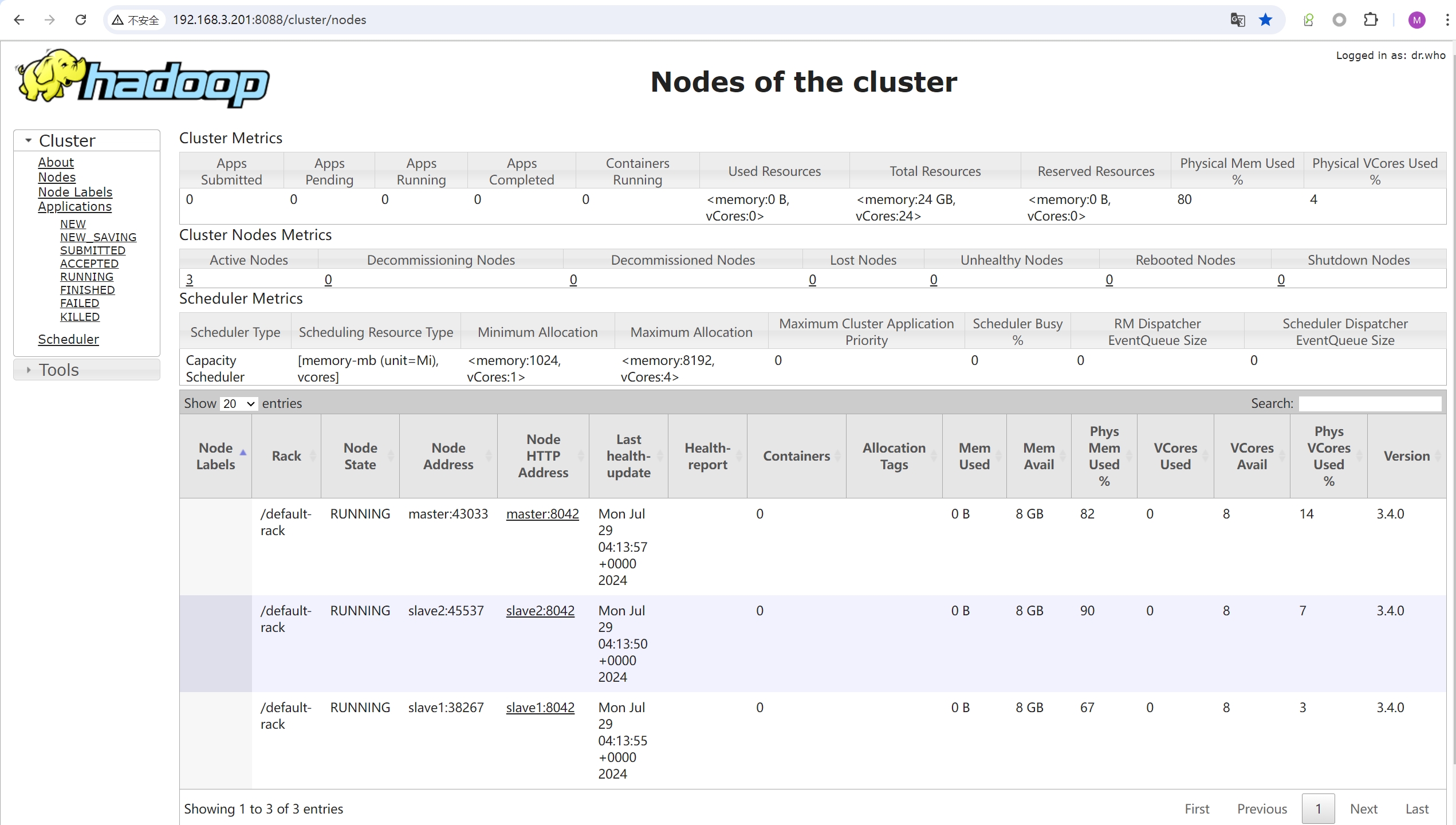
http://192.168.3.202:8088 (opens new window) 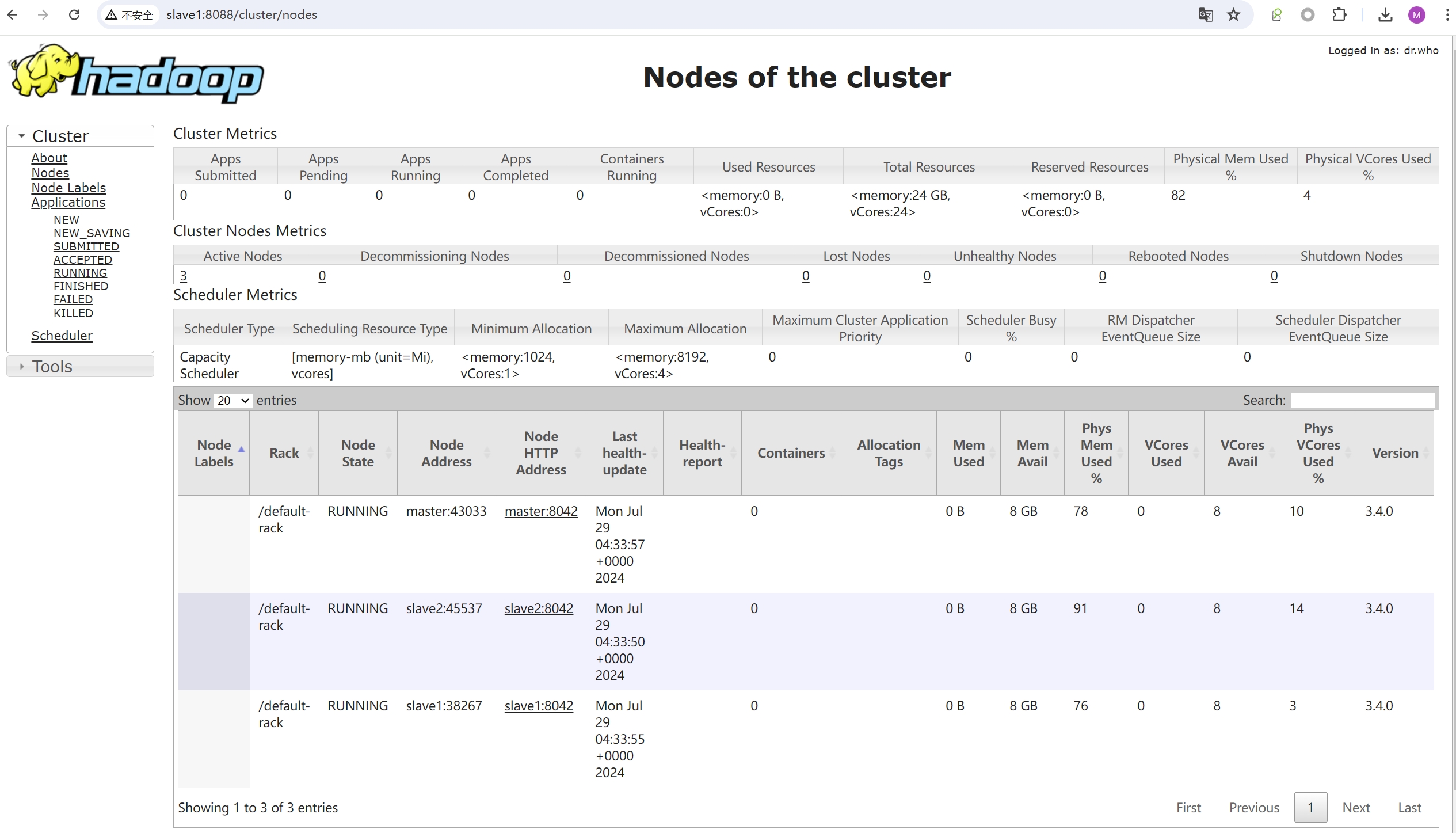
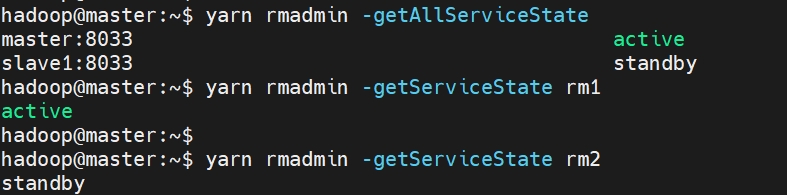
备注: 在 YARN 高可用配置中,只有处于 active 状态的 ResourceManager 的 Web 界面通常是完全可访问的。处于 standby 状态的 ResourceManager 可能会限制 Web 界面的访问。
# wordcount单词统计
vi wordcount.txt
hadoop crudapi1 hadoop crudapi2 hadoop crudapi3 hadoop crudapi4 yarn zookeeper hdfs yarn zookeeper hdfs hdfs dfs -mkdir /mpdata hdfs dfs -mkdir /mpdata/input hdfs dfs -put wordcount.txt /mpdata/input hdfs dfs -ls /mpdata/input hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.0.jar wordcount /mpdata/input/wordcount.txt /mpdata/output 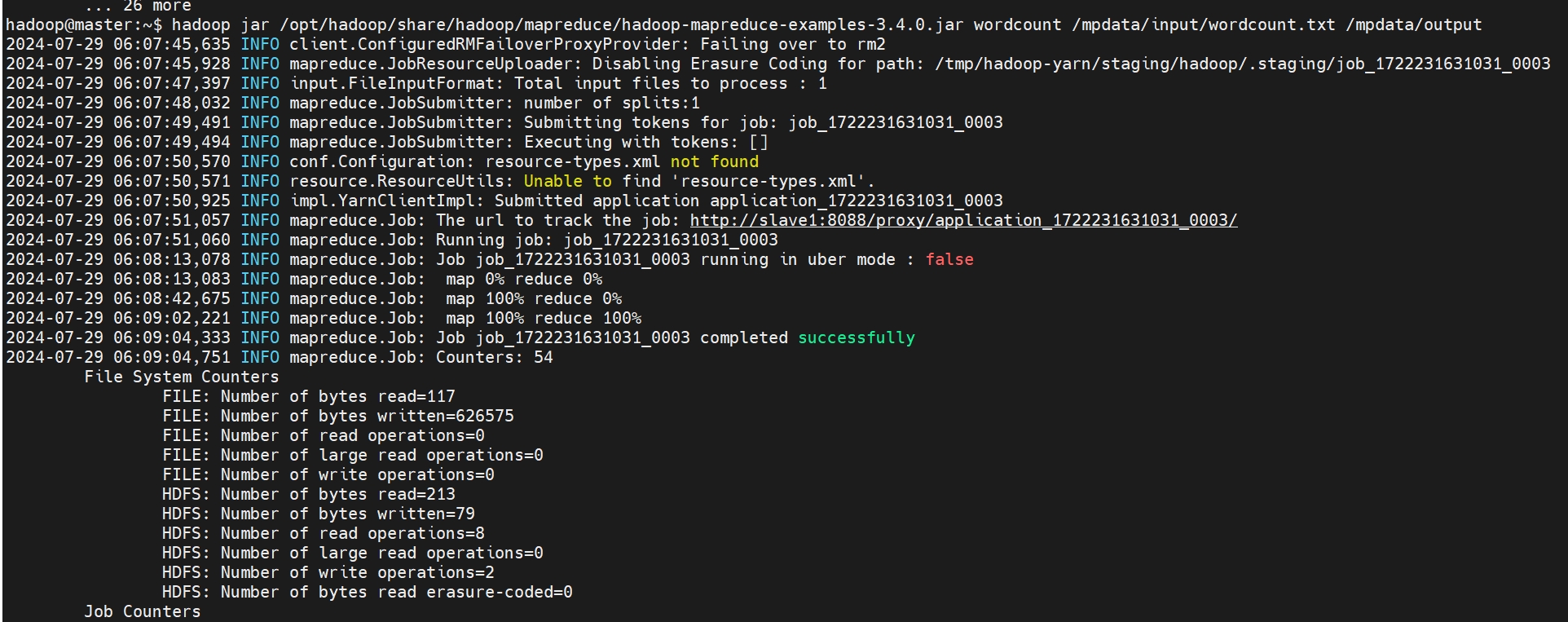
检查任务 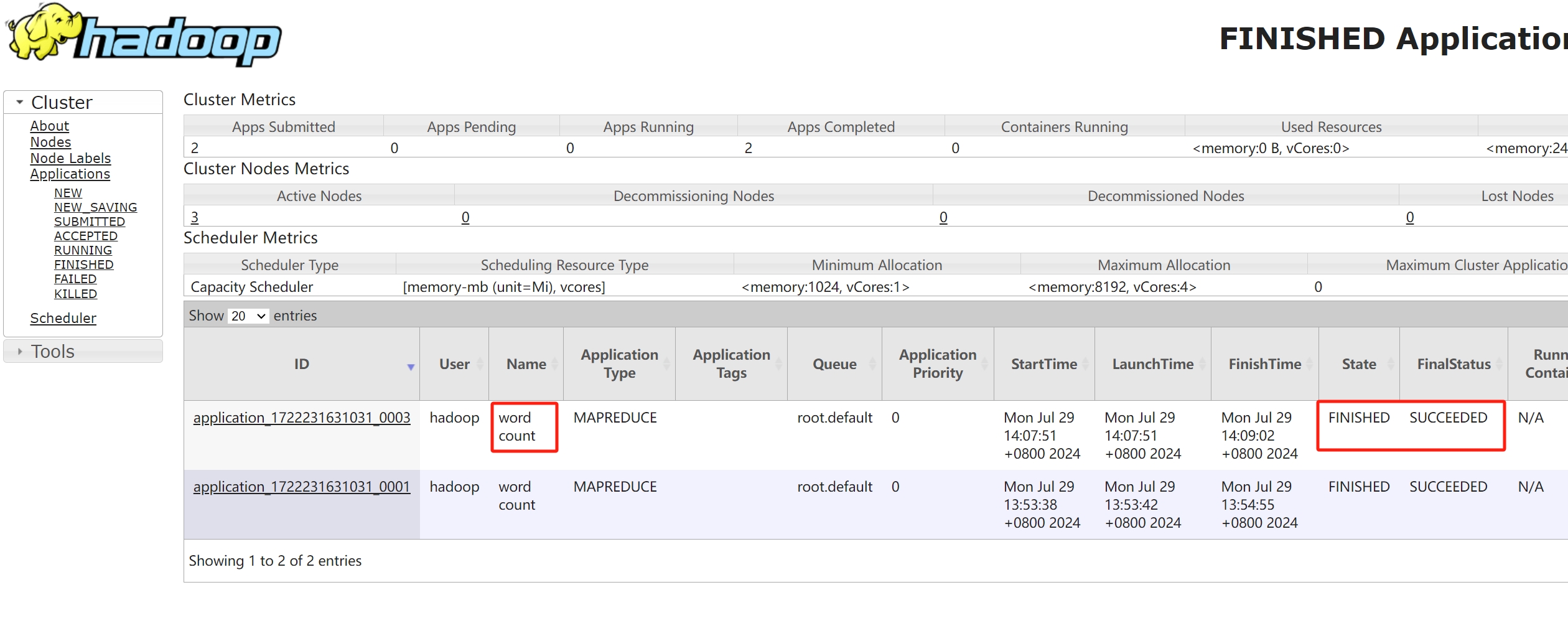
检查输出, 结果正确 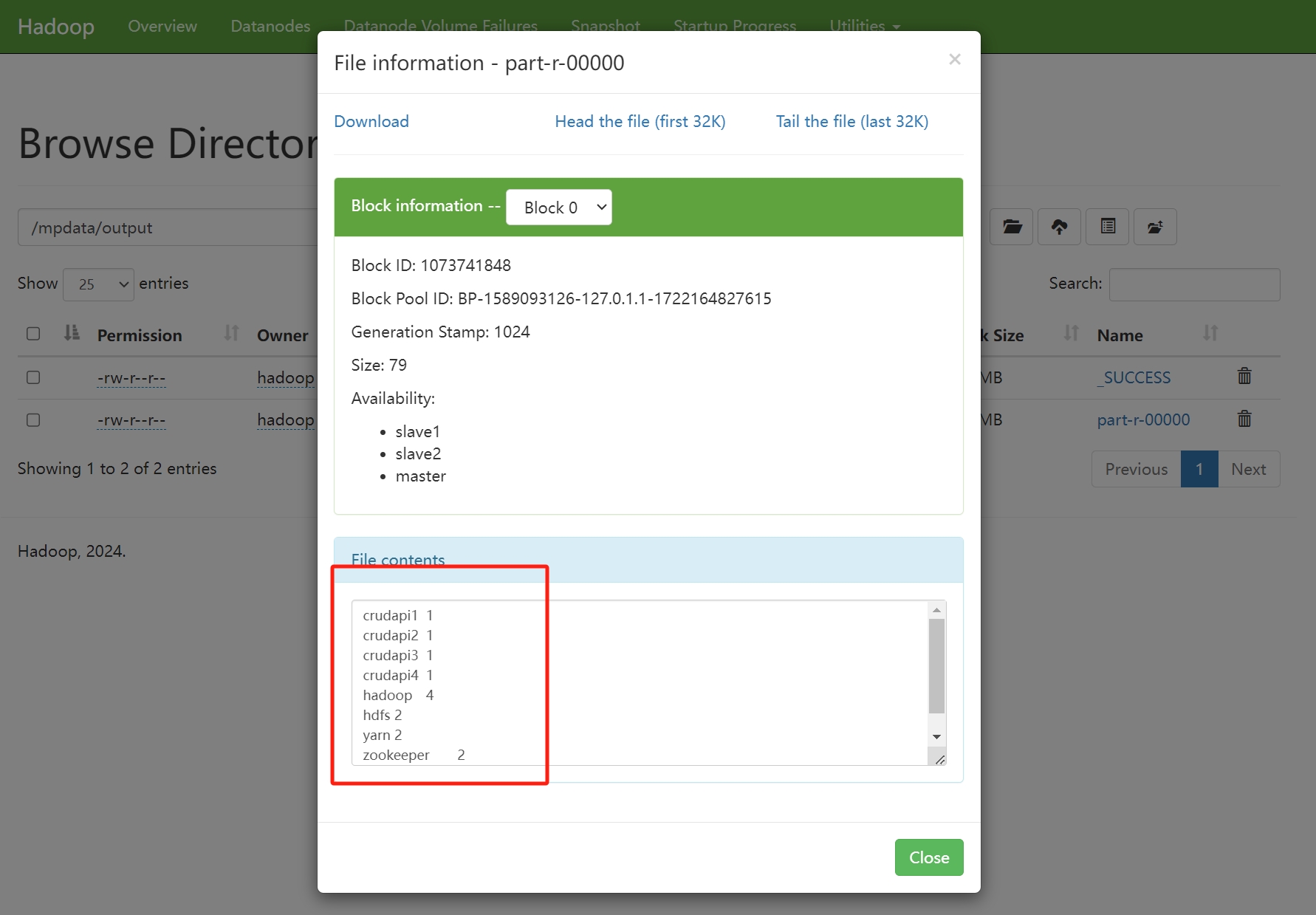
crudapi1 1 crudapi2 1 crudapi3 1 crudapi4 1 hadoop 4 hdfs 2 yarn 2 zookeeper 2