Add Bfloat16 optimizer with Kahan summation option for high precision updates #52
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,182 @@ | ||
| # Copyright (c) Meta Platforms, Inc. and affiliates. | ||
| # All rights reserved. | ||
| # | ||
| # This source code is licensed under the BSD-style license found in the | ||
| # LICENSE file in the root directory of this source tree. | ||
| | ||
| # AnyPrecisionAdamW: a flexible precision AdamW optimizer | ||
| # with optional Kahan summation for high precision weight updates. | ||
| # Allows direct control over momentum, variance and auxiliary compensation | ||
| # buffer dtypes. | ||
| # Optional Kahan summation is used to offset precision reduction for | ||
| # the weight updates. This allows full training in BFloat16 (equal or | ||
| # better than FP32 results in many cases) due to high precision weight upates. | ||
| | ||
| import torch | ||
| from torch.optim.optimizer import Optimizer | ||
| | ||
| | ||
| class AnyPrecisionAdamW(Optimizer): | ||
| def __init__( | ||
| self, | ||
| params, | ||
| lr=1e-3, | ||
| betas=(0.9, 0.999), | ||
| eps=1e-8, | ||
| weight_decay=0.0, | ||
| use_kahan_summation=False, | ||
| momentum_dtype=torch.float32, | ||
| variance_dtype=torch.bfloat16, | ||
| compensation_buffer_dtype=torch.bfloat16, | ||
| ): | ||
| """ | ||
| Args: | ||
| params (iterable): iterable of parameters to optimize or dicts defining | ||
| parameter groups | ||
| lr (float, optional): learning rate (default: 1e-3) | ||
| betas (Tuple[float, float], optional): coefficients used for computing | ||
| running averages of gradient and its square (default: (0.9, 0.999)) | ||
| eps (float, optional): term added to the denominator to improve | ||
| numerical stability (default: 1e-8) | ||
| weight_decay (float, optional): weight decay coefficient (default: 1e-2) | ||
| | ||
| # Any Precision specific | ||
| use_kahan_summation = creates auxiliary buffer to ensure high precision | ||
| model param updates (default: False) | ||
| momentum_dtype = dtype for momentum (default: BFloat32) | ||
| variance_dtype = dtype for uncentered variance (default: BFloat16) | ||
| compensation_buffer_dtype = dtype for Kahan summation | ||
| buffer (default: BFloat16) | ||
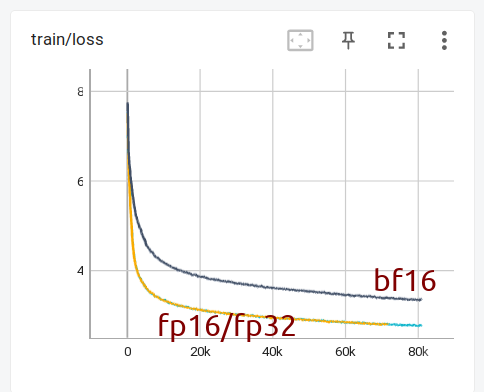
| There was a problem hiding this comment. why is the default bf16 and not fp16? won't it be more precise than bf16? Thanks! Contributor Author There was a problem hiding this comment. Hi @stas00 - BF16 is a drop in replacement for FP32 b/c it has the same dynamic range. Technically FP16 does have greater precision, but the fact that the range of it is so poor means you need to rescale in order to effectively use. (hence all the grad_scaler you see, and the reason many have given up on FP16 for LLM training). Thus, I use BF16 here since it is a drop in replacement (though yes with lower precision than FP16 and FP32) for FP32, and no rescaling (aka guessing) needed. There was a problem hiding this comment. Thank you for the follow up, Less But the compensation buffer is to save the error that didn't get added up. If the error is smaller than what bf16 can handle, aren't we getting "an error" on "an error" here? I mean the compensation buffer could get zero'ed out as well in such cases. And of course you're right that the compensation buffer is also used in this code to add the big numbers - fp16 could easily overflow - yes. Perhaps only the error should be stored in a higher precision format and be added and not be added to? Would it be a "safer" default to use fp32? And let the user decide if they want the error to be not fully carried over. On the other hand if the grads are in bfloat16 then there will be no loss if the compensation buffer is in bf16 I think. Contributor Author There was a problem hiding this comment. Hi Stas, I could test out some different alternatives to try and compare impact - do you have one or two recommended models/training examples that would be representative of your users most typical use cases? There was a problem hiding this comment. Thank you for sharing the background story, Less I don't have any specific examples at the moment. But I have just trained from scratch OPT-1.3b in fp16/fp32/bf16 - mixed precision for non-fp32 - using the exact same setup otherwise. As you can see bf16 gives a much much slower loss curve.
In order to catch up with fp16/fp32 I need to feed 10x more batchsize to bf16 setup. This of course isn't the same situation, but it's quite telling how bf16, while really helpful at avoiding instabilities when training huge models, is a much much slower training regime otherwise. Hence the concerns of having it as the default. There was a problem hiding this comment. and so the goal is to show that bf16-pure/anyprecision(bf16) trains as fast as fp16/amp/adamw - which currently isn't the case (at least with opt-1.3) Contributor Author There was a problem hiding this comment. I tried on a larger server but still each card is A10 23GB...seems you are expecting A100s and 40GB? Not sure what the trainer is doing exactly but this would easily run with FSDP. There was a problem hiding this comment. You can see the details here: #52 (comment) As I suggested let's switch to opt-125m instead There was a problem hiding this comment. I updated the instructions here: huggingface/transformers#21312 to include 125m - 10x smaller - should fit into 24GB card no problem. There was a problem hiding this comment. Hi @lessw2020 - we are still interested in your suggestion that you were able to train pure bf16 faster than fp16/amp. how do I reproduce it? | ||
| | ||
| # Usage | ||
| This optimizer implements optimizer states, and Kahan summation | ||
| for high precision updates, all in user controlled dtypes. | ||
| Defaults are variance in BF16, Momentum in FP32. | ||
| This can be run in FSDP mixed precision, amp, or full precision, | ||
| depending on what training pipeline you wish to work with. | ||
| | ||
| Setting to use_kahan_summation = False, and changing momentum and | ||
| variance dtypes to FP32, reverts this to a standard AdamW optimizer. | ||
| | ||
| """ | ||
| defaults = dict( | ||
| lr=lr, | ||
| betas=betas, | ||
| eps=eps, | ||
| weight_decay=weight_decay, | ||
| use_kahan_summation=use_kahan_summation, | ||
| momentum_dtype=momentum_dtype, | ||
| variance_dtype=variance_dtype, | ||
| compensation_buffer_dtype=compensation_buffer_dtype, | ||
| ) | ||
| | ||
| super().__init__(params, defaults) | ||
| | ||
| @torch.no_grad() | ||
| def step(self, closure=None): | ||
| """Performs a single optimization step. | ||
| Args: | ||
| closure (callable, optional): A closure that reevaluates the model | ||
| and returns the loss. | ||
| """ | ||
| | ||
| if closure is not None: | ||
| with torch.enable_grad(): | ||
| # to fix linter, we do not keep the returned loss for use atm. | ||
| closure() | ||
| | ||
| for group in self.param_groups: | ||
| | ||
| beta1, beta2 = group["betas"] | ||
| lr = group["lr"] | ||
| weight_decay = group["weight_decay"] | ||
| eps = group["eps"] | ||
| use_kahan_summation = group["use_kahan_summation"] | ||
| | ||
| momentum_dtype = group["momentum_dtype"] | ||
| variance_dtype = group["variance_dtype"] | ||
| compensation_buffer_dtype = group["compensation_buffer_dtype"] | ||
| | ||
| for p in group["params"]: | ||
| if p.grad is None: | ||
| continue | ||
| | ||
| if p.grad.is_sparse: | ||
| raise RuntimeError( | ||
| "AnyPrecisionAdamW does not support sparse gradients" | ||
| ) | ||
| | ||
| state = self.state[p] | ||
| | ||
| # State initialization | ||
| if len(state) == 0: | ||
| | ||
| state["step"] = torch.tensor(0.0) | ||
| | ||
| # momentum - EMA of gradient values | ||
| state["exp_avg"] = torch.zeros_like( | ||
| p, | ||
| dtype=momentum_dtype, | ||
| ) | ||
| | ||
| # variance uncentered - EMA of squared gradient values | ||
| state["exp_avg_sq"] = torch.zeros_like( | ||
| p, | ||
| dtype=variance_dtype, | ||
| ) | ||
| | ||
| # optional Kahan summation - accumulated error tracker | ||
| if use_kahan_summation: | ||
| state["compensation"] = torch.zeros_like( | ||
lessw2020 marked this conversation as resolved. Show resolved Hide resolved | ||
| p, | ||
| dtype=compensation_buffer_dtype, | ||
| ) | ||
| | ||
| # main processing ------------------------- | ||
| | ||
| # update the steps for each param group update | ||
| state["step"] += 1 | ||
| step = state["step"] | ||
| | ||
| exp_avg = state["exp_avg"] | ||
| exp_avg_sq = state["exp_avg_sq"] | ||
| | ||
| grad = p.grad | ||
| | ||
| # weight decay, AdamW style | ||
| if weight_decay: | ||
| p.data.mul_(1 - lr * weight_decay) | ||
| | ||
| # update momentum | ||
| exp_avg.mul_(beta1).add_(grad, alpha=1 - beta1) | ||
| | ||
| # update uncentered variance | ||
| exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=1 - beta2) | ||
| | ||
| # adjust using bias1 | ||
| bias_correction1 = 1 - beta1**step | ||
| | ||
| step_size = lr / bias_correction1 | ||
| | ||
| # adjust using bias2 | ||
| denom_correction = (1 - beta2**step) ** 0.5 # avoids math import | ||
| | ||
| centered_variance = (exp_avg_sq.sqrt() / denom_correction).add_( | ||
| eps, alpha=1 | ||
| ) | ||
| | ||
| # lr update to compensation | ||
| if use_kahan_summation: | ||
| compensation = state["compensation"] | ||
| | ||
| compensation.addcdiv_(exp_avg, centered_variance, value=-step_size) | ||
| | ||
| # update weights with compensation (Kahan summation) | ||
| # save error back to compensation for next iteration | ||
| temp_buffer = p.detach().clone() | ||
| p.data.add_(compensation) | ||
| compensation.add_(temp_buffer.sub_(p.data)) | ||
| | ||
| else: | ||
| # usual AdamW updates | ||
| p.data.addcdiv_(exp_avg, centered_variance, value=-step_size) | ||
lessw2020 marked this conversation as resolved. Show resolved Hide resolved | ||
Uh oh!
There was an error while loading. Please reload this page.