Hide sensitive credentials in Spark History #1633
Description
What kind an issue is this?
- Bug report. If you’ve found a bug, please provide a code snippet or test to reproduce it below.
The easier it is to track down the bug, the faster it is solved. - Feature Request. Start by telling us what problem you’re trying to solve.
Often a solution already exists! Don’t send pull requests to implement new features without
first getting our support. Sometimes we leave features out on purpose to keep the project small.
Feature description
We are trying to connect Spark 3.0.1 with Elasticsearch using the Elastic-hadoop library 7.12.0. Everything works fine.
However, we are using Spark History server to track jobs. Having a look at the SQL upper tab and seeing the explain details shows the following:
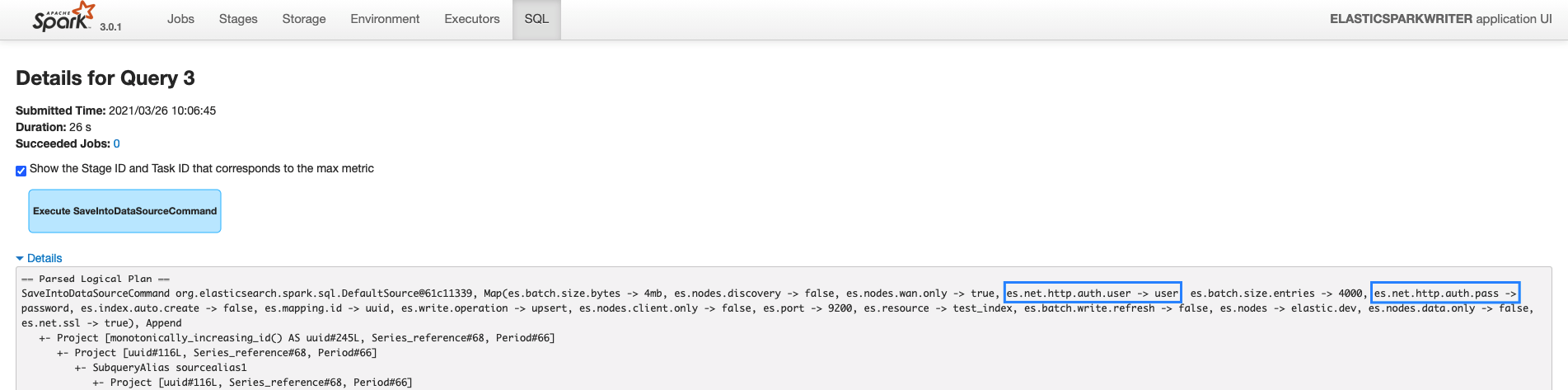
As you can see, it is showing the user and password which is not very safe 😐
We know it is possible to use a keystore: https://www.elastic.co/guide/en/elasticsearch/hadoop/current/security.html#keystore
But we are retrieving at runtime those credentials. So, we cannot generate the keystore before running the job in Kubernetes.
I think that the Map that is printed in the Spark History shouldn't show user, password, and any other field that can be added to the keystore, since they are sensitive data.