RyuJIT: Optimize simple comparisons into branchless expressions #32716
Conversation
| Quite popular pattern this PR fixes in BCL: sharplab.io (e.g. here) |
| I suppose this also improves this? runtime/src/libraries/System.Private.CoreLib/src/System/String.cs Lines 464 to 466 in 9a08506 |
It won't change anything for |
src/coreclr/tests/src/JIT/opt/InstructionCombining/CondToBranchlessExpr.cs Outdated Show resolved Hide resolved
src/coreclr/tests/src/JIT/opt/InstructionCombining/CondToBranchlessExpr.cs Show resolved Hide resolved
src/coreclr/tests/src/JIT/opt/InstructionCombining/CondToBranchlessExpr.cs Outdated Show resolved Hide resolved
| What's the status of this PR? Should it be merged? |
| @dotnet/jit-contrib What do you think? |
 sandreenko left a comment
sandreenko left a comment
There was a problem hiding this comment.
The optimization and the implementation look correct. However, I am worried about compilation time impact: without tiering I would vote against that, with tiering enabled it could be worth doing.
It is linear in terms of blocks without additional memory, but could you estimate what percentage of methods it will affect if you support all 4 cases? It is like 1% or 0.1%?
Can it be combined with the existing logic to optimize branches like GT_TRUE(1,1)?
| #ifndef TARGET_64BIT | ||
| if ((typ == TYP_INT) && (addValue == INT_MIN)) | ||
| { | ||
| continue; |
There was a problem hiding this comment.
Does it protect from ? INT_MIN:INT_MIN+1 case? What is the problem with it?
| // TODO: implement for GT_ASG | ||
| (trueBb->bbJumpKind != BBJ_RETURN) || (falseBb->bbJumpKind != BBJ_RETURN) || | ||
| // give up if these blocks are used by someone else | ||
| (trueBb->countOfInEdges() != 1) || (falseBb->countOfInEdges() != 1) || |
There was a problem hiding this comment.
// give up if these blocks are used by someone else
why?
There was a problem hiding this comment.
Need to check but I think there will be regressions (in terms of size, not performance)
There was a problem hiding this comment.
The transformation will be invalid, because those return blocks can be reached under other conditions.
There was a problem hiding this comment.
The transformation will be invalid
Why? We don't delete these blocks, we only remove the edges from block to trueBb and falseBb. trueBb and falseBb are staying alive for other preds.
| } | ||
| | ||
| // unlink both blocks | ||
| fgRemoveRefPred(trueBb, block); |
There was a problem hiding this comment.
Do we just remove the edges? Does unreachable code elimination delete the blocks?
There was a problem hiding this comment.
yeah, the blocks are eliminated, will check at what moment exactly.
| continue; | ||
| } | ||
| | ||
| Statement* firstStmt = block->lastStmt(); |
There was a problem hiding this comment.
why the last statement is called first?
There was a problem hiding this comment.
This is how I skip possible leading GT_ASG statements
| (trueBb->bbJumpKind != BBJ_RETURN) || (falseBb->bbJumpKind != BBJ_RETURN) || | ||
| // give up if these blocks are used by someone else | ||
| (trueBb->countOfInEdges() != 1) || (falseBb->countOfInEdges() != 1) || | ||
| (trueBb->bbFlags & BBF_DONT_REMOVE) || (falseBb->bbFlags & BBF_DONT_REMOVE)) |
There was a problem hiding this comment.
| (trueBb->bbFlags & BBF_DONT_REMOVE) || (falseBb->bbFlags & BBF_DONT_REMOVE)) | |
| ((trueBb->bbFlags & BBF_DONT_REMOVE) != 0) || ((falseBb->bbFlags & BBF_DONT_REMOVE) != 0)) |
| At the very least we should measure the throughput cost of this, e,g., by using pin-tool and crossgen-ing SPC. It's not a full walk of the IR (it only looks at most at one statement per basic block) so it may not be too costly. Still, I would prefer to know the CQ benefit (and throughput cost) once the missing cases are added. Depending on the throughput results we may consider adding this optimization into one of the existing phases. |
| Note we also already do return block merging for identical constant return values during |
| @EgorBo, are you still working on this? |
| @stephentoub yes, sorry |
| @AndyAyersMS @erozenfeld @sandreenko I think It's time to introduce CMOV**-based optimizations, especially because now we're able to collect profile data and will be able to avoid perf regressions (see this godbolt sample). So ideally, there must be an optimization like in this PR to collapse if-else blocks back into ternary operators where needed PS: regarding the JIT-throughput and |
|
static int Test1(int x) { return x == 42 ? 1000 : 2000; } static int Test2(int x, int a, int b) { return x == 42 ? a : b; }; Method Tests:Test1(int):int G_M56601_IG01: G_M56601_IG02: 83F92A cmp ecx, 42 B8E8030000 mov eax, 0x3E8 BAD0070000 mov edx, 0x7D0 0F45C2 cmovne eax, edx G_M56601_IG03: C3 ret ; Total bytes of code: 17 ; Method Tests:Test2(int,int,int):int G_M50938_IG01: G_M50938_IG02: 83F92A cmp ecx, 42 8BC2 mov eax, edx 410F45C0 cmovne eax, r8d G_M50938_IG03: C3 ret ; Total bytes of code: 10Works better with PGO 🙂: |

| I think we may focus on this during .NET 6 -- as you note, not only do we have to figure out how to represent conditional instructions in the IR, but we also need to have the right heuristics to decide when to use them. |
@EgorBo, do you think its worth opening a proposal for |
Honestly not sure, I'd expect jit to handle it since with PGO jumps could be better (https://github.com/xiadz/cmov) |
This PR optimizes simple conditions (

BBJ_COND+ twoBBJ_RETURN) into a single branchlessBBJ_RETURNblockE.g.
Current codegen:
New codegen:
The new codegen is branchless and is more compact. In theory, it can be slower in some benchmarks where we constantly take the same branch over and over and the branch-prediction + speculative execution may perform better but it seems GCC doesn't really care. If you want I can add a sort of "IsHotBlock" check (if it makes sense with the current PGO state)
Jit-diff (-f -pmi):
This PR handles only Case 1 for now (as a start):
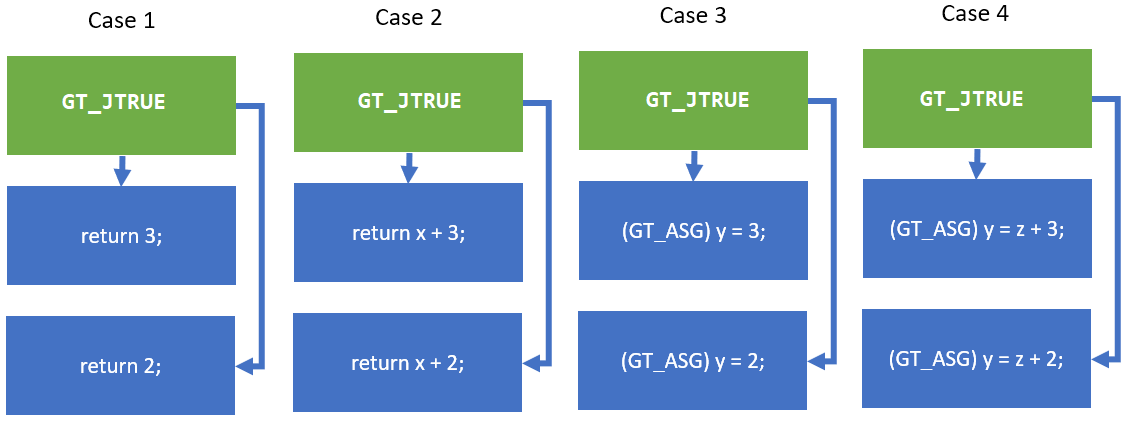
and the jit-diff already looks promising, I think the GT_ASG ones should produce even bigger diffs.
Also, see #32632 cc @lpereira
(can I use GT_LEA here to handle even more cases?)