This ports DoubleToNum and supporting code to be a managed implementation. #19999
Conversation
| Looking at the perf gaps, some of it is just things that the C++ Compiler gives you for free, that we don't have enabled quite yet (like combined DivMod) or where the native code was using a more optimized algorithm (like These should, however, be easy enough to fix up. For example: Native Managed |

| _length = (upper == 0) ? 1 : 2; | ||
| } | ||
| | ||
| public static uint BitScanReverse(uint mask) |
There was a problem hiding this comment.
Native code just calls the intrinsic instead.
| private int _length; | ||
| private BlocksBuffer _blocks; | ||
| | ||
| public BigInteger(uint value) |
There was a problem hiding this comment.
Native code can configure the default constructor to efficiently initialize this, rather than requiring us to specialize case value == 0
| _length += (int)(blocksToShift); | ||
| | ||
| // Zero the remaining low blocks | ||
| Buffer.ZeroMemory((byte*)(_blocks.GetPointer()), (blocksToShift * sizeof(uint))); |
There was a problem hiding this comment.
This was not being done properly in native code (size was blocksToShift, rather than blocksToShift * sizeof(uint)).
Without Grisu3 enabled as the first code-path, the Roslyn RealParser tests exposed this issue.
| | ||
| public void Multiply(ref DiyFp rhs) | ||
| { | ||
| ulong lf = _f; |
There was a problem hiding this comment.
This is just a 64x64=128 multiply, so using an intrinsic is possible.
| decimalExponent = CachedPowerDecimalExponents[index]; | ||
| } | ||
| | ||
| private static bool DigitGen(ref DiyFp mp, int precision, char* digits, out int length, out int k) |
There was a problem hiding this comment.
This is the function that is causing the most perf diff between the managed and native implementations.
We could likely close the gap by caching some field/properties we lookup multiple times (into locals), and by using Math.DivRem (or better, a proper intrinsic), rather than independent divide and remainder operations.
|
|
| After a small cleanup to |
| CC. @danmosemsft, @jkotas |
| Do you propose we commit this as is or work to close the gap further? I suggest the latter? |
| } | ||
| | ||
| [StructLayout(LayoutKind.Sequential, Size = (MaxBlockCount * sizeof(uint)))] | ||
| private struct BlocksBuffer |
There was a problem hiding this comment.
fixed uint _buffer[MaxBlockCount] ?
There was a problem hiding this comment.
Won't that cause a perf hit due to UnsafeValueTypeAttribute?
There was a problem hiding this comment.
You can measure it.
You are using unsafe stackallocated buffers, so you do want to pay for the GS cookie checks. I assume that the C/C++ code paid for them too.
There was a problem hiding this comment.
We should move to a C# 7.3 compiler version (we are still on 2.8.0-beta4 right now) so that we can index a fixed-buffer without pinning: https://docs.microsoft.com/en-us/dotnet/csharp/whats-new/csharp-7-3#indexing-fixed-fields-does-not-require-pinning
There was a problem hiding this comment.
There was a problem hiding this comment.
This is blocked more generally on: #19878 (comment).
The regression is relatively small (~10%, depends on how you measure it). I think it is fine to take this into master since this moves us in the right direction, and unblocks other work. (And it is paying back the shortcut that was made during implementation of the faster number float formatting algorithms earlier.) |
| Fixing up |
sounds good to me |
| BitScanReverse and BitScanReverse64 are now dead in pal.h |
Removed. |
| The current numbers, with everything currently up in this PR (5.68% regression): |

| Everything except for moving |
| @tannergooding what do you plan to do about tests? You found at least one bug we weren't catching. Does it make sense to port the Roslyn ones into CoreFX? |
Until |
| @jkotas, are you fine with this being merged and with me logging a bug/following up with a second PR to move to fixed-sized buffers after the build-tools change (bringing in C# 7.3 support) goes in, or would you rather this just wait and be done all at once? |
| I would add a unused Otherwise, I am fine with this being merged and logging bug/following up with second PR later. |
Fixed. |
| | ||
| private static long ExtractFractionAndBiasedExponent(double value, out int exponent) | ||
| { | ||
| long fraction = GetMantissa(value); |
There was a problem hiding this comment.
You are likely losing some cycles by converting double to long twice in a row.
There was a problem hiding this comment.
Fixed.
-- I wish we had the ability to specify a function was const so that the JIT could just do the right/expected thing here.
| @jkotas, any other feedback you would like me to address? I think I've gotten it all at this point. |
| _e = e; | ||
| } | ||
| | ||
| public ulong f |
There was a problem hiding this comment.
Nit: There is no value in these being properties. Just makes the JIT to work harder.
There was a problem hiding this comment.
I'll track this is part of the fixed buffer cleanup after the build-tools update.
There was a problem hiding this comment.
| Do the perf numbers still look good with all the feedback incorporated? |
Yes. The current run shows the best numbers so far (only a 3.93% regression from the original 61.02s):
|

| @tannergooding CoreCLR/CoreFX convention is to merge using "Squash and Merge". https://github.com/dotnet/corefx/blob/master/Documentation/project-docs/contributing.md#merging-pull-requests-for-contributors-with-write-access (next time...) |
Can we set that to be the default then? We have multiple repos across dotnet and many of them do not agree on this behavior. As such, I normally just use whatever the default merge option is configured for (which is currently |
| Where do you set it as default? |
| It should be under |
| Right, that let's you choose what is allowed, not what should be the default. |
This ports the rest of the formatting code to be written in managed code. It is, currently, mostly a naive port of the native code and only has a few minor fix ups to the code.
I locally ran the Roslyn RealParser suite, as well as did a basic benchmark on both float and double, covering 267,386,880 values in the input range (including both denormal and normal inputs).
Benchmarking was done with Tiered Jitting disabled.
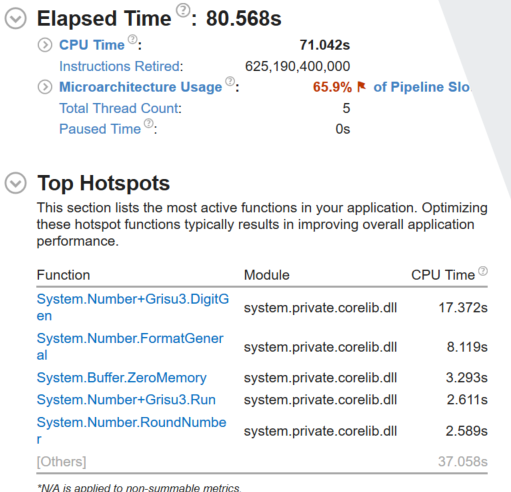
For the Roslyn Real Parser Tests
This was mostly to validate that I didn't mess up any code during the port. Their own parsing code takes up the majority in each, but overall has a 1.52% regression in elapsed time.
Native
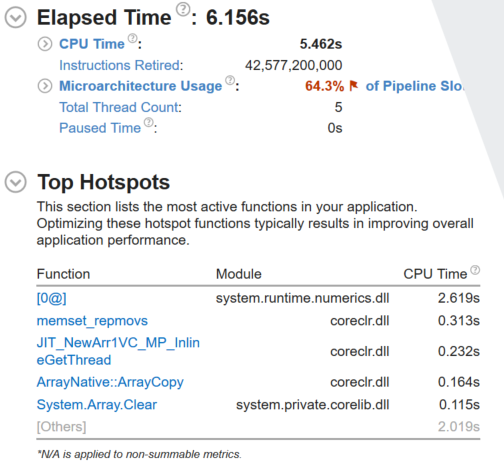
Managed

For float.ToString() on 267,386,880 values between float.MinValue and float.MaxValue
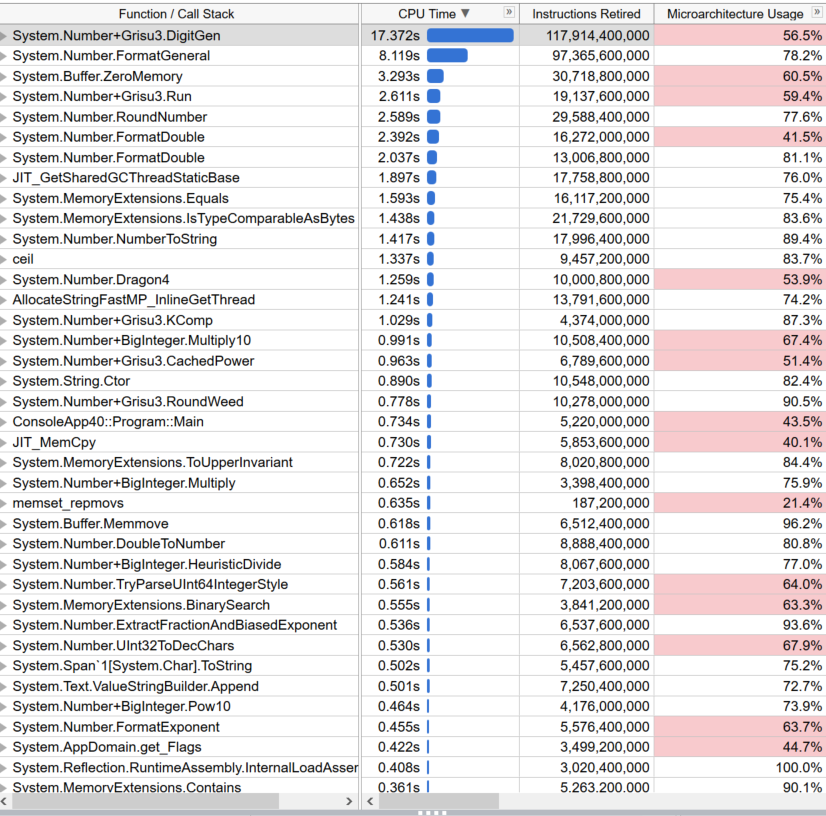
Grisu3.DigitGen is the major player in both here. This showed a 9.89% regression in elapsed time.
float.ToString()will default to 7 digits.Native
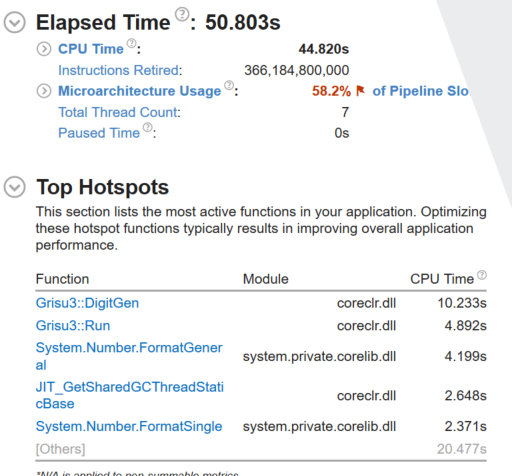
Managed

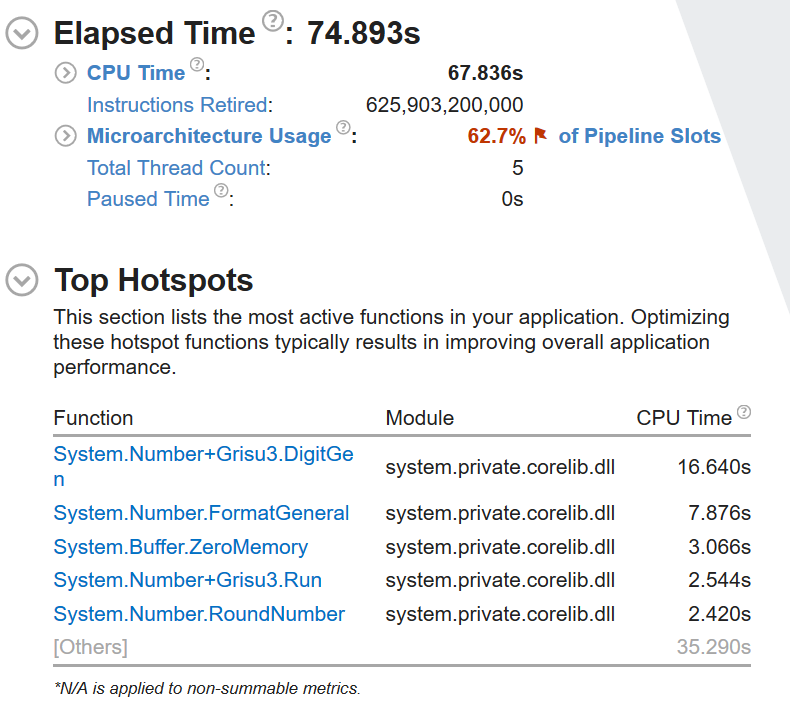
For double.ToString() on 267,386,880 values between double.MinValue and double.MaxValue
Grisu3.DigitGen is again the major time taker here. This showed a 16.43% regression in elapsed time.
double.ToString()will default to 15 digits.Native

Managed