Then you would need to load the inputs in a transposed fashion. Alternatively you could apply it to comp2 and get the output as transposed matrix (and the inputs as they currently are).
I did come up with it before, but unfortunately, I’m utilizing sparse tensor core, which requires the order of matmul to be fixed (i.e., I cannot make any other transpose to the computations).
So A has to be sparse, and B may not? And C (as it is computed) not at all? And D is sparse?
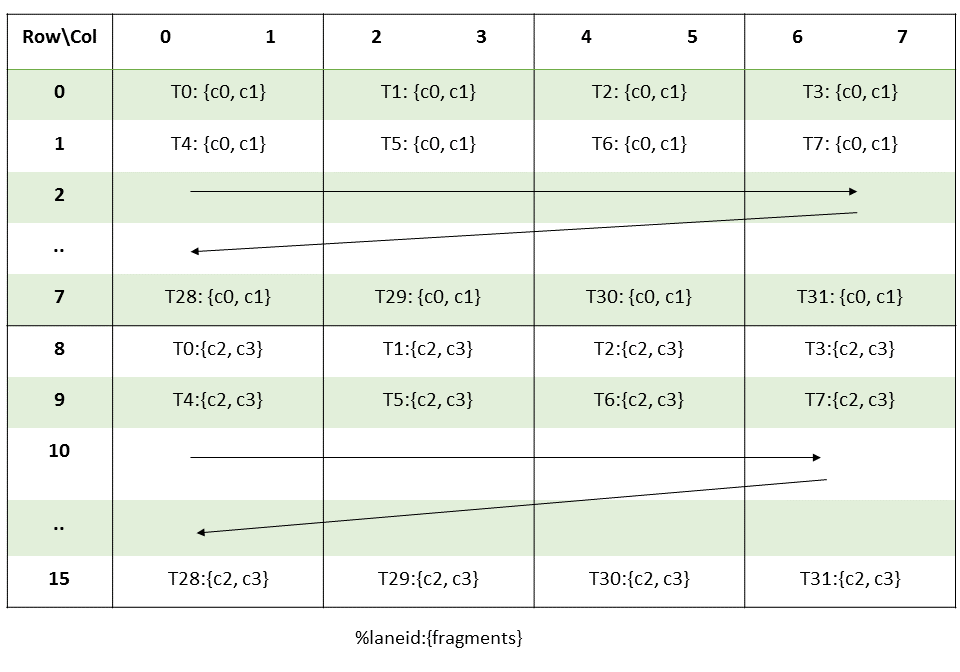
Otherwise two movmatrix calls should work (as one does 8x8 at a time).
That is 4 operations (1 mma + 2 movmatrix + 1 mma).
I am not sure about the performance impact. Perhaps in the end it is faster to change either comp1 or comp2 to two dense operations (as those have half the matrix size) instead.
Yuh I think multiple movmatrix might be the only ideal way to address the issue in this scenario, or otherwise use shuffle commands to simulate one like in llama.cpp/ggml.
For FP16 x FP16 → FFP16, the consumer class GPUs (assumed you use those) can do 128 actual (dense) FMAs per cycle/partition or 512 per SM.
The m16n8k16 sparse matrices need 1024 FMAs each, that is 2048 for comp1+comp2 using 4 cycles.
The two movmatrix probably together need 2 cycles from the MIO pipeline.
So depending on whether you also load input or store output from/in shared memory (e.g. 2 cycles to load B, 2 cycles to store E), either tensor cores or shared memory will be the limiting factor.
If it is shared memory I would reconsider making one computation dense to save those 2 cycles. If it is tensor cores, what you envisioned is the fastest way.
If you can choose 6/4 or 4/6 for tc/mio cycles, do both and get 5 cycles.
I’m currently working on a consumer-class GPU and eventually aiming for industrial-class GPUs. In that case, I think the computation might take even fewer cycles (for A100, I assume it takes 2 cycles for each comp since 256 FMAs/cycle) and make the movmatrix overhead more observable.
You are absolutely right that I also need to load/store to/from smem, which might be the bottleneck. Making one of them dense can save the movmatrix cycle, but it also increases gmem and smem access (given a fixed global matrix size). So I guess I might have to try different combinations and compare them to see the results.