Snowflake key concepts and architecture¶
Snowflake is powered by an advanced data platform that is provided to you as a self-managed service. Snowflake’s data platform brings together data storage, processing, and analytic solutions that are faster, easier to use, and far more flexible than traditional offerings.
Snowflake combines a completely new SQL query engine with an innovative architecture that is natively designed for the cloud. It offers full enterprise analytic database functionality, and unique features and capabilities.
Data platform as a self-managed service¶
Als selbstverwalteter Dienst bietet Snowflake die folgenden Vorteile:
There is no hardware (virtual or physical) for you to select, install, configure, or manage.
There is virtually no software for you to install, configure, or manage.
Laufende Wartung, Verwaltung, Aktualisierung und Anpassung werden von Snowflake übernommen.
Snowflake nutzt öffentliche Cloudinfrastruktur, um virtuelle Computeinstanzen und persistente Datenspeicher zu hosten. Snowflake verwaltet Software-Updates und die Infrastruktur, sodass Sie sich nicht darum kümmern müssen. Sie können Snowflake nicht lokal oder in privaten Cloudinfrastrukturen installieren und ausführen, weder On-Premises noch gehostet.
Snowflake architecture¶
Snowflake’s architecture is a hybrid of traditional shared-disk and shared-nothing database architectures. Similar to shared-disk architectures, Snowflake uses a central data repository for persisted data that is accessible from all compute nodes in the platform. But similar to shared-nothing architectures, Snowflake processes queries using massively parallel processing (MPP) compute clusters, where each node in the cluster stores a portion of the entire data set locally. This hybrid architecture, which is shown in the following diagram, offers the data management simplicity of a shared-disk architecture, but with the performance and scale-out benefits of a shared-nothing architecture:
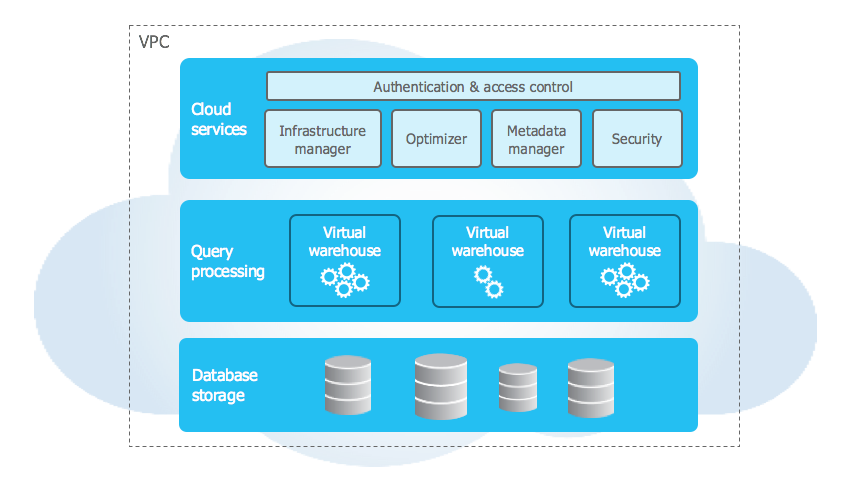
Snowflake’s unique architecture has the following key layers:
Database storage¶
Snowflake unterstützt die folgenden Arten von Daten:
Strukturierte Daten – wie Zeilen und Spalten in einer Tabelle: Folgt einem strengen tabellarischen Schema.
Semistrukturierte Daten – wie JSON-Datei oder eine XML-Datei: Hat ein flexibles Schema.
Unstrukturierte Daten – wie Dokumente, Bild- oder Audiodateien: Hat kein inhärentes Schema.
Snowflake unterstützt mehrere Arten von Tabellen für die Datenspeicherung, darunter die folgenden Tabellentypen:
Snowflake tables¶
When data is loaded into a Snowflake table, Snowflake reorganizes that data into its internally optimized, compressed, columnar format. Snowflake stores this optimized data in cloud storage. Snowflake tables are ideal for data warehouses.
Snowflake verwaltet alle Aspekte der Speicherung dieser Daten – einschließlich Organisation, Dateigröße, Struktur, Komprimierung, Metadaten und Statistiken. Alle Daten in Snowflake-Tabellen werden automatisch in Mikropartitionen unterteilt, bei denen es sich um zusammenhängende Speichereinheiten handelt. Mikropartitionen verbessern die Effizienz und bieten noch weitere Vorteile.
Sie können Snowflake-Tabellen verwenden, um strukturierte und semistrukturierte Daten zu speichern. Sie können auch die Datentyp FILE für unstrukturierte Daten verwenden.
For more information about Snowflake tables, see Grundlegendes zu Tabellenstrukturen in Snowflake.
Apache Iceberg™-Tabellen¶
Apache Iceberg™-Tabellen für Snowflake kombinieren die Leistung und Abfrage-Semantik typischer Snowflake-Tabellen mit externem Cloud-Speicher, den Sie verwalten. Sie eignen sich ideal für bestehende Data Lakes und Data Lakehouses, die Sie nicht in Snowflake speichern können oder möchten.
Iceberg-Tabellen speichern ihre Daten- und Metadaten-Dateien an einem externen Cloudspeicherort, z. B. Amazon S3, Google Cloud Storage oder Microsoft Azure Storage. Der externe Speicher ist nicht Teil von Snowflake.
Sie können Iceberg-Tabellen verwenden, um strukturierte und semistrukturierte Daten zu speichern.
For more information, see Apache Iceberg™-Tabellen.
Hybridtabellen¶
Hybridtabellen sind für niedrige Latenzen und hohen Durchsatz optimiert, indem indexbasierte zufällige Lese- und Schreiboperationen verwendet werden. Hybridtabellen unterstützen Zeilensperren und setzen eindeutige und referenzielle Integritätseinschränkungen durch, die für transaktionale Workloads entscheidend sind. Sie können eine Hybridtabelle zusammen mit anderen Snowflake-Tabellen und -Features verwenden, um Unistore-Workloads zu verarbeiten, die transaktionale und analytische Daten in einer einzigen Plattform zusammenführen.
Sie können Hybridtabellen verwenden, um strukturierte und semistrukturierte Daten zu speichern.
For more information, see Hybridtabellen.
Compute¶
Ein virtuelles Warehouse ist ein Cluster, der aus Computeressourcen besteht. Virtuelle Warehouses verarbeiten SQL-Anweisungen und führen mit Snowpark Code in Sprachen wie Java, Python und Scala aus. Mit Snowpark Connect für Spark können Sie auch Apache Spark™-Workloads in virtuellen Warehouses ausführen.
Each virtual warehouse is an independent compute cluster that doesn’t share compute resources with other virtual warehouses. As a result, each virtual warehouse has no effect on the performance of other virtual warehouses.
Weitere Informationen dazu finden Sie unter Virtuelle Warehouses.
Cloud services¶
The cloud services layer is a collection of services that coordinate activities across Snowflake. These services tie together all of the different components of Snowflake in order to process user requests, from sign-in to query dispatch. The cloud services layer also runs on compute instances that are provisioned by Snowflake from the cloud provider.
Services managed in this layer include the following:
Integrierte Features für Ihre Workloads¶
Anstatt Daten in verschiedene Systeme zu verschieben, damit unterschiedliche Teams bestimmte Vorgänge und Aufgaben ausführen können, können Sie alle Ihre Workloads mit einem integrierten Set an Features direkt auf ihre Daten übertragen.
Diese Features unterstützen die folgenden umfassenden Bereiche der Datenintegration und Entwicklung:
Data Engineering¶
Snowflake trennt Speicher und Verarbeitungsleistung, was einige bisherige Herausforderungen beim Data Engineering vereinfacht, wie z. B. das Infrastrukturmanagement und die Leistungsoptimierung. Data Engineers können sich auf die Implementierung von Pipelines konzentrieren, die Daten aufnehmen, umwandeln und bereitstellen.
Snowflake bietet verschiedene Möglichkeiten, Daten zu erfassen, darunter z. B. die folgenden Optionen:
COPY INTO <Tabelle>-Befehl – Lädt Daten aus Dateien in eine Tabelle.
Snowpipe – Lädt Daten aus Dateien, sobald sie in einem Stagingbereich verfügbar sind.
Snowpipe Streaming – Lädt Daten auf Zeilenebene kontinuierlich und mit geringer Latenz unter Verwendung der Snowflake-SDKs oder einer REST-API direkt in Snowflake-Tabellen und von Snowflake verwaltete Iceberg-Tabellen, anstatt Daten aus Dateien zu laden.
Openflow-Konnektoren – Erfasst Daten aus bestimmten Quellen mithilfe von Konnektoren auf Basis von NiFi, wie z. B. Microsoft Sharepoint und Google Drive.
Snowflake-Konnektoren – Verbinden externe Anwendungen und Systeme und streamen Daten in Snowflake.
Snowflake bietet auch verschiedene Möglichkeiten, Daten zu transformieren, darunter z. B. die folgenden Optionen:
Dynamische Tabellen – Definition von Tabellen, die automatisch auf der Grundlage der Aktualität des Ziels und einer Abfrage, die Datentransformationen durchführt, aktualisiert werden.
Streams und Aufgaben – Erfassung von Änderungen an Basisobjekten mit Streams und Definition von Aufgaben zur Durchführung von Datentransformationen.
Snowpark – Durchführung komplexerer Transformationen unter Verwendung von Programmiersprachen wie Python, Java und Scala.
dbt – Verwendung eines Open-Source-Datentransformationstools und -Frameworks zum Definieren, Testen und Bereitstellen von SQL-Transformationen.
Darüber hinaus kann SnowConvert AI Daten erfassen und umwandeln, und Snowpark Migration Accelerator kann Code von verschiedenen Plattformen in Snowflake konvertieren.
For more information, see Übersicht zum Laden von Daten.
Analytik¶
Mit Snowflake können Sie Workloads dynamisch und bedarfsabhängig skalieren, auf verschiedene Arten von Daten zugreifen – einschließlich strukturierter, semistrukturierter und unstrukturierter Daten – und Daten auf einfache Weise freigeben. Mit diesen Features können Sie in Snowflake gespeicherte Daten analysieren, um aussagekräftige Erkenntnisse, Muster und Trends für analytische Anwendungsfälle zu extrahieren, wie z. B. Business Intelligence oder Vorhersagemodellierung.
Snowflake bietet verschiedene Möglichkeiten, Daten zu analysieren, einschließlich der folgenden Optionen:
Systemfunktionen und SQL-Konstrukte – Durchführung von Berechnungen und statistischer Analysen mit den folgenden Snowflake-Systemfunktionen und SQL-Konstrukten:
Aggregatfunktionen – Zusammenfassung von Daten, indem Berechnungen für mehrere zusammengehörige Zeilen durchgeführt und ein einzelner Wert zurückgegeben werden.
Fensterfunktionen – Durchführung von Berechnungen für mehrere zusammengehörige Zeilen in Partitionen für fortlaufende Vorgänge auf Teilmengen der Zeilen in jeder Partition, z. B. Berechnungen einer laufenden Summe oder eines gleitenden Durchschnitts.
Allgemeine Tabellenausdrücke (Common Table Expressions, CTEs) – Verbessern die Lesbarkeit und Wiederverwendbarkeit komplexer Abfragen, die ggf. mehrere Schritte der Datentransformation erfordern.
Snowflake Cortex AISQL – Ausführung unstrukturierter Analysen für Text und Bilder mit großen Sprachmodellen (Large Language Models, LLMs) von OpenAI, Anthropic, Meta, Mistral AI und DeepSeek.
Semantische Ansichten – Speicherung semantischer Geschäftskonzepte direkt in der Datenbank, um Geschäftsmetriken zu definieren und Geschäftsentitäten und deren Beziehungen zu modellieren.
AI und ML¶
Snowflake vereinfacht den Einsatz von Funktionen, die auf künstlicher Intelligenz (AI) und maschinellem Lernen (ML) basieren, sodass Sie AI- und ML-basiertes Feature-Engineering, Training und Inferencing mit Ihren Snowflake-Daten ausführen können. Modelle können auf Ihre aktuellen Daten in einer sicheren Umgebung zugreifen. Mit Snowflake können Sie die Kosten und Komplexität vermeiden, Ihre Daten auf eine separate Plattform für AI-und ML-Aufgaben zu verschieben.
Snowflake bietet AI- und ML-Funktionen in zwei umfassenden Suites an:
Snowflake Cortex: AI-Features, die LLMs verwenden, um unstrukturierte Daten zu verstehen, Freiform-Fragen zu beantworten und intelligente Unterstützung bereitzustellen. AISQL-Funktionen kann Routineaufgaben automatisieren, wie z. B. einfache Zusammenfassungen und schnelle Übersetzungen.
Snowflake ML: Features, die Sie verwenden können, um Ihre eigenen Modelle zu erstellen. ML-Funktionen ermöglichen Ihnen automatische Vorhersagen und Einblicke in Ihre Daten mithilfe von ML. Snowflake ML ist eine einheitliche Umgebung für die ML-Entwicklung.
For more information, see KI und ML in Snowflake.
Anwendungen und Zusammenarbeit¶
Snowflake bietet zahlreiche Möglichkeiten, Anwendungen zu erstellen und sie für Ihre Teams, Partner und Kunden freizugeben. Wenn Sie Snowflake für die gemeinsame Nutzung von Daten verwenden, kontrollieren Sie den Zugriff auf die Daten und vermeiden Sie die Herausforderungen, die mit der Synchronisierung der Daten an verschiedenen Orten verbunden sind.
Die folgende Liste zeigt einige der Tools und Dienste, die Sie zum Erstellen, Bereitstellen und Verwalten von Anwendungen in Snowflake nutzen können:
Streamlit – Verwenden Sie eine Open-Source-Python-Bibliothek, um kundenspezifische Web-Apps mit einer interaktiven Benutzeroberfläche (UI) für ML und Data Science zu erstellen und freizugeben.
Snowpark Container Services – Ermöglichen das Bereitstellen, Verwalten und Skalieren von containerisierten Anwendungen direkt aus Snowflake heraus.
Snowflake Native Apps Framework – Erstellen Sie Anwendungen, die die Möglichkeiten bestimmter Snowflake-Features erweitern, indem Daten und zugehörige Geschäftslogik für andere Snowflake-Konten freigeben werden. Die Geschäftslogik einer Anwendung kann eine Streamlit-App, gespeicherte Prozeduren und Funktionen umfassen, die mit der Snowpark-API, JavaScript und SQL geschrieben wurden. Eine Snowflake Native App kann auch Container-Workloads mit Snowpark Container Services ausführen.
Snowflake unterstützt die folgenden Arten der Zusammenarbeit:
Secure Data Sharing – Ermöglicht die Freigabe ausgewählter Objekte einer Datenbank Ihres Kontos für andere Snowflake-Konten.
Freigabeangebote – Sie können anderen Snowflake-Benutzenden Daten und andere Informationen zur Verfügung stellen oder auf Daten und andere Informationen zugreifen, die von Snowflake-Anbietern freigegeben wurden. Sie können Freigabeangebote durchsuchen, auf Freigabeangebote zugreifen und Freigabeangebote für Verbrauchende privat und auf dem Snowflake Marketplace bereitstellen.
Data Clean Rooms – Legen sie fest, welche Analysen auf den freigegebenen Daten ausgeführt werden können. Dies ermöglicht es Verbrauchenden, Erkenntnisse aus den Daten zu gewinnen, ohne uneingeschränkten Zugriff auf diese Daten zu haben.
Snowgrid¶
Snowgrid ist die regions- und cloudübergreifende Technologieschicht von Snowflake. Mit Snowgrid können Sie die folgenden Ziele erreichen:
Verbinden eines Daten-Ökosystems über verschiedene Regionen und Anbieter hinweg – wie z. B. Amazon Web Services (AWS), Microsoft Azure und Google Cloud – mithilfe von Freigabeangeboten und anderen Features für die Zusammenarbeit
Konsistente Anwendung von Sicherheits- und Governance-Richtlinien über Clouds und Regionen hinweg
Fähigkeiten zur Notfallwiederherstellung und Geschäftskontinuität in allen Regionen durch Einsatz von Replikation
Weitere Informationen finden Sie unter Snowgrid.
Verbinden mit Snowflake¶
Snowflake supports multiple ways for you to connect to the service:
Snowsight, a web-based UI that you can use to access all aspects of managing and using Snowflake can be accessed.
Command-line clients that you can also use to access all aspects of managing and using Snowflake; for example, Snowflake CLI.
Native APIs, mit denen Sie Snowflake-Ressourcen programmgesteuert erstellen und verwalten können, z. B. Snowflake-Python-APIs und Snowflake-REST-APIs
Treiber, die andere Anwendungen für die Verbindung zu Snowflake verwenden können, z. B. JDBC und ODBC
Native connectors that you can use to develop applications for connecting to Snowflake; for example, Apache Kafka and Apache Spark.
Technologien von Drittanbietern, die Sie verwenden können, um Anwendungen mit Snowflake zu verbinden, z. B. ETL-Tools (Extrahieren, Transformieren, Laden) wie Informatica sowie und BI-Tools (Business Intelligence) wie ThoughtSpot
Weitere Informationen dazu finden Sie unter Anmelden bei Snowflake.