Service announcements Stay organized with collections Save and categorize content based on your preferences.
Learn about Vision changes such as backward incompatible API changes, product or feature deprecations, mandatory migrations, or potentially disruptive maintenance.
An improved model is now available for Text Detection (OCR). The new model can be used with TEXT_DETECTION and DOCUMENT_TEXT_DETECTION features. The same model is used for requests sent to both features.
With the new model, the distribution of confidence scores of responses will change. More information below.
Please note that you have 90 days from today to test the new model by specifying "builtin/latest" in the model field of the Feature object. At the end of that period, it will be promoted to the default model accessible as "builtin/stable". After that event, the original models will still be available for another 90 days using "builtin/legacy".
If you encounter problems with this upgrade, please contact the Vision API engineering team by submitting a ticket in the private issue tracker.
October 01, 2021
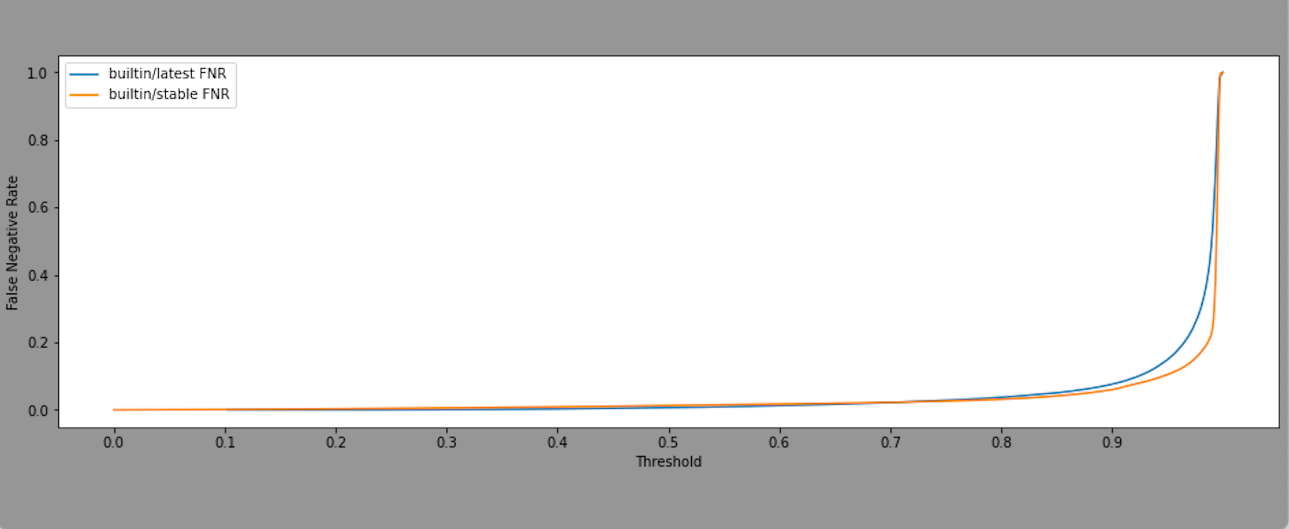
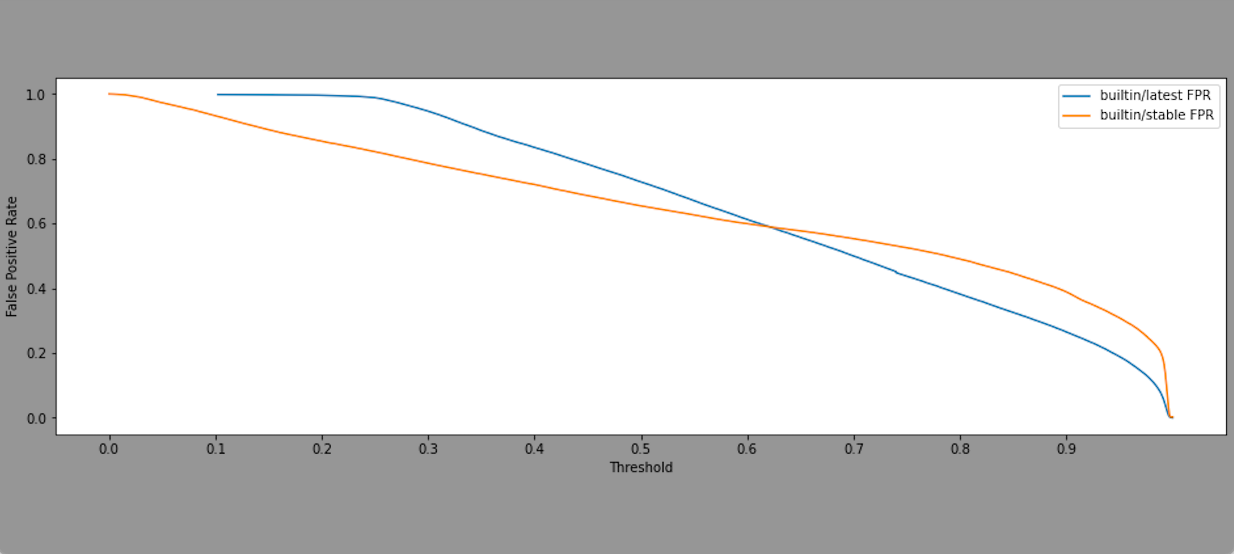
Differences in the distribution of confidence scores of responses ("builtin/latest" vs. "builtin/stable").
FNR (False Negative Ratio): The ratio of correct symbol predictions with confidence score less than the threshold.
FPR (False Positive Ratio): The ratio of incorrect symbol predictions with confidence score greater than or equal to the threshold.
[[["Easy to understand","easyToUnderstand","thumb-up"],["Solved my problem","solvedMyProblem","thumb-up"],["Other","otherUp","thumb-up"]],[["Hard to understand","hardToUnderstand","thumb-down"],["Incorrect information or sample code","incorrectInformationOrSampleCode","thumb-down"],["Missing the information/samples I need","missingTheInformationSamplesINeed","thumb-down"],["Other","otherDown","thumb-down"]],["Last updated 2025-12-09 UTC."],[],[]]