
数据,是有保质期的。正如冰箱里的牛奶,今天新鲜,明天可能就有点酸,后天直接倒掉。数据的价值,也会随着时间的推移而递减。
过去那些“老派”的 OLAP 系统,只能批量处理账目,对实时性要求高的“流水账”就力不从心了。它们在面对高并发实时写入和复杂的分析查询时,常常会露出疲态,数据延迟、查询性能、并发处理和数据更新等问题层出不穷。
当所有人都焦虑于如何让数据“快”起来的时候,Apache Doris 在底层逻辑上进行了一系列颠覆性的技术迭代,能快速接入各种数据源,并且拥有强大的实时更新能力,让你的数据从产生的那一刻起,就具备了“快”的生命力。
到底 Doris 是怎么做到,让数据流动得如此低延迟?这正是我们接下来要深挖的“冰山之下”。
实时更新的挑战
在实现实时更新的过程中,系统需要应对多个方面的挑战,这些挑战直接关系到系统在实际业务场景中的稳定性与性能表现:
- 数据延迟:实时更新的核心在于“快”。数据从产生到可查询的过程必须尽可能短,实际生产中要求在 5-10 秒可见,理想情况下甚至要求低于 1 秒可见。同时,还需具备足够的写入吞吐能力,保证在并发写入场景下也能稳定运行。
- 查询性能:一边持续高频地接收数据更新,一边还能保持百毫秒级别的查询响应,对底层系统架构提出了极高要求。如何在更新密集的情况下,仍然提供快速、稳定的查询体验,是实时 OLAP 系统必须解决的问题。
- 并发处理:实时分析场景多面向终端用户,不仅查询操作需要支持高并发,同时写入也常常是并发的。传统的表或者分区级别的写冲突处理机制影响范围较大,会影响数据写入效率与业务体验。理想状态下,系统应允许用户制定冲突处理策略,从而提高数据接入的灵活性与可控性。
- 数据流维护与易用性保障:实时数据流的维护受多项复杂因素的影响,例如 TP 系统通过 CDC 捕获的删除操作以及 Schema 变更带来的下游兼容性问题。同时,在链路重启或容灾恢复时,如何确保数据既不重复和不丢失,这对数据一致性的要求非常高。
这些挑战正是评估一个 OLAP 系统是否真正具备实时更新能力的关键指标。
常见方案对比
在面临数据更新的上述挑战时,市面上的常用方案通常涉及三个关键点,分别是表达方式、更新实现和冲突解决,这些方案各有其适用场景。
在表达方式上, Snowflake、Redshift、Iceberg、Databricks 和 Hudi 通常使用 MERGE INTO 来处理数据更新,这要求变更数据必须先落盘成为 MERGE 的数据源,因此可能带来一定的数据延迟和额外的 I/O 开销。相比之下,Doris 和 ClickHouse 采用更加轻量的方式,通过特定列值表示删除操作,使得写入和删除可以统一在同一数据流中处理,更加契合实时处理需求,尤其适用于 OLTP 类事务变更、订单或账单状态更新等场景。
在更新实现方面, 业界常见的方案有四种:

- **Copy on Write**:在写入时找出需要更新的文件,读取并结合新的更新,生成新文件再写入。这种方式优化了读取性能,但在写入时会显著增加 I/O 开销,特别是在随机更新情况下,会引发大量读写 I/O,限制了实时更新能力。此方案的典型产品包括 Redshift、ClickHouse、Snowflake、Iceberg 和 Hudi。 - **Merge on Read**:在写入时仅需添加新数据,读取时再合并新旧数据,类似于 LSM Tree。这种方式优化了写入性能,但查询效率较低,难以满足某些实时场景的查询延迟要求,典型产品包括 Iceberg、Hudi 和 Doris Merge on Read Unique 表。 - **Delete bitmap / deletion vector:** 标记删除的实现方案。在写入时标记文件中被删除的数据,并写入删除标记及新数据,查询时跳过删除标记的数据行。此方式既能避免 Copy on Write 的 I/O 放大效应,也获得了 Copy on Write 的查询性能。但是对于没有主键索引的实现,生成删除标记(Delete Bitmap / Delete Vector)时 I/O 和 CPU 消耗较大,效率低下,难以满足高频实时写入场景。 - **Delete bitmap / deletion vector + primary index:** 标记删除与主键索引结合的方式。主键索引能够降低标记删除时的查询 I/O 和 CPU 消耗,使高频实时更新成为可能。Doris 的 Merge on Write Unique 表采用了这种实现方式。 - 在冲突解决方面, 经典的写写冲突会导致写入无法并行,从而显著降低写入吞吐量。Doris 提供了基于业务语义的冲突机制,可很好避免该问题(参考文档)。而 Redshift、Snowflake、Iceberg 和 Hudi 等则采用了文件级别的冲突处理,因而不具备实时更新的能力。
Apache Doris 作为一款为实时分析场景打造的高性能 MPP 分析型数据库,具备强大的数据写入能力、亚秒级查询性能以及出色的并发处理能力,因此成为构建面向用户的实时数据服务的优选方案。基于上述常见方案,本文将详细拆解 Apache Doris 实时更新技术的核心设计,揭示其如何实现“极低延迟”的数据流动性。
为什么 Apache Doris 实时更新更具优势?
传统 OLAP 数据库主要用于批量分析,数据更新周期通常以小时甚至天为单位,适合以报表为主的内部系统。然而,随着业务及数据服务的多样化发展,越来越多的分析应用开始面向终端用户,要求亚秒级的查询延迟和秒级的数据更新。 在此背景下,要求实时分析数据库能够应对高速写入数据(每秒百万级别的数据导入)、并在大规模场景下提供实时查询。Apache Doris 凭借其主键模型、数据延迟、查询性能、并发处理、易用性等多方面特性的表现,在分析领域展现了独特的实时更新能力。
01 主键模型
Doris 提供了主键表,确保数据主键的唯一性,支持基于主键的 upsert 语义。以下是一个以 user_id 主键的表的创建示例:
CREATE TABLE IF NOT EXISTS example_tbl_unique ( user_id LARGEINT NOT NULL, user_name VARCHAR(50) NOT NULL, city VARCHAR(20), age SMALLINT, sex TINYINT ) UNIQUE KEY(user_id) DISTRIBUTED BY HASH(user_id) BUCKETS 10; 在这个表中,初始数据包括四行: 101、102、103、104 。当新写入 101、102 之后,表中的数据仍然保持是四行,但原先 101 和 102 的数据会被更新。
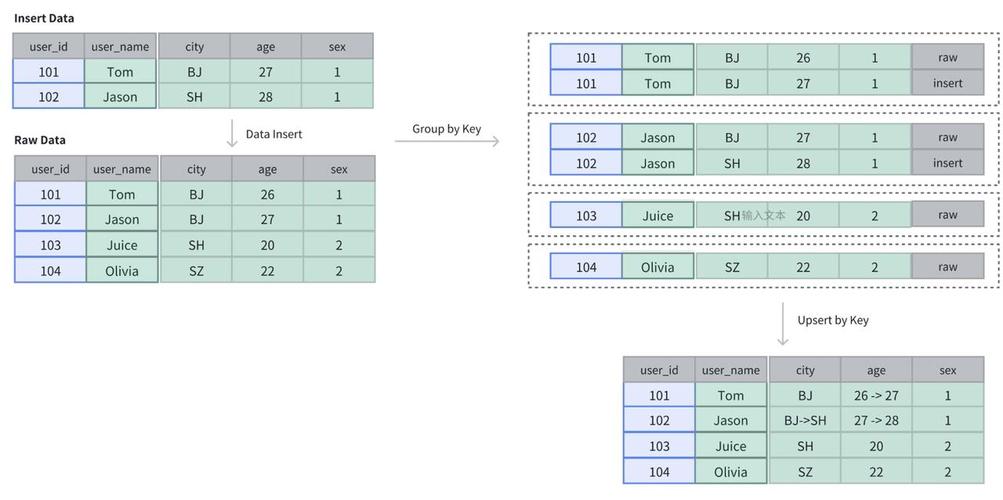
参考文档:主键模型的导入更新
02 数据延迟
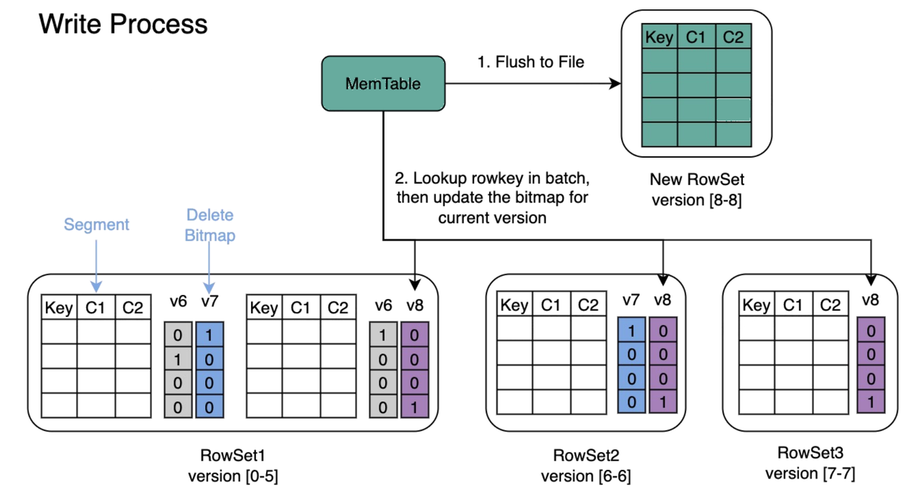
Doris 提供强一致性语义,确保数据写入后立即可见,从而满足低延迟的实时数据更新需求。数据组织使用 LSM tree 的方式组织,写入操作采用删除标记(Delete Bitmap)方式,相较于传统的 Copy-on-Write 机制,能够显著减少 I/O 操作,提高写入效率。这一设计不仅降低了存储空间的浪费,还减轻了系统的负担,从而提供了更高效的数据处理能力。
此外,Doris 利用主键索引优化了在更新数据时定位和检索相历史数据的性能,进一步提升了写入速度并降低了资源消耗。通过这些设计,Doris 实现了综合性的低延迟数据更新,能够提供 1s 以下的数据延迟,满足高效实时分析和快速数据响应的需求。
03 查询性能
在更新场景下,Doris 采用标记删除(Delete Bitmap)方式加速查询性能。与 Merge-on-Read 的实现相比,标记删除能够避免在查询时进行大量的删除逻辑计算,从而减少查询延迟并提升整体性能,确保查询响应时间低于百毫秒,并支持高并发访问。

此外,Doris 基于以下几项技术,进一步提升了查询性能:
- 分区和分桶裁剪技术: 智能跳过无关数据,进一步优化数据扫描过程,减少不必要的数据读取,显著提高查询效率。
- 向量化技术: 在处理大规模数据时,通过批量化处理多个数据操作,减少 CPU 的上下文切换,显著提升数据处理速度,尤其适用于大数据量的查询场景。
- 优化器: 通过智能的查询计划选择和执行,自动根据查询条件调整最佳执行路径,避免不必要的计算开销,进一步提高查询响应速度。
- 丰富的索引:包括点查索引和跳数索引。点查索引常用于加速点查,包括前缀索引和倒排索引,原理是通过索引定位到满足 WHERE 条件的有哪些行,直接读取那些行。跳数索引常用于加速分析,包括 ZoneMap 索引、BloomFilter 索引、NGram BloomFilter 索引,原理是通过索引确定不满足 WHERE 条件的数据块,跳过这些不满足条件的数据块,只读取可能满足条件的数据块并再进行一次逐行过滤,最终得到满足条件的行。
这些技术的结合使得 Doris 在高并发环境下能够保持稳定的低延迟,确保其在秒级和毫秒级查询性能上表现出色,满足实时数据处理的严格要求。
04 并发处理
Doris 主键表支持应用语义处理冲突,在高并发乱序写入时能够保证数据的最终一致性。建表时,可以通过指定 SEQUENCE COLUMN 来自定义 MVCC 的冲突处理逻辑,Doris 的写入负载均衡机制优先选择 SEQUENCE 列较大的行。这一机制不仅适用于写入冲突,还同样适用于存量数据。
CREATE TABLE test.test_table ( user_id bigint, date date, group_id bigint, modify_date date, keyword VARCHAR(128) ) UNIQUE KEY(user_id, date, group_id) DISTRIBUTED BY HASH (user_id) BUCKETS 32 PROPERTIES( "function_column.sequence_col" = 'modify_date', "replication_num" = "1", "in_memory" = "false" ); 例如,在 OLTP 表中,modify_date 字段每次更新时都会设置为当前时间。在将 OLTP 数据库的 CDC 同步到 Doris 时,可以将 modify_date 指定为 SEQUENCE 列。这样,具有较大 modify_date 的数据行将生效,而如果后写入的数据 modify_date 较小,则存量数据不会被更新。这一机制使得实时数据同步的冲突处理变得非常简单,同时不影响写入效率。
参考文档:主键模型的更新并发控制
05 易用性
- 首先,Doris 确保每次数据写入的一致性和完整性,保证在高并发和实时更新环境中,数据始终保持一致并立即可见。结合标记删除机制,Doris 使数据更新更加高效,减少了存储开销,并提升了查询性能。
- 其次,Doris 还支持在线 Schema 变更,允许动态调整表结构,从而简化数据流的维护,避免复杂的数据迁移过程。同时,灵活的列更新功能使数据更新更为高效,特别是在频繁更新部分数据时,避免了全表更新带来的性能开销。
- 最后,Doris 支持隐藏列标记删除方式,即为每个 Unique 表生成隐藏的
DORIS_DELETE_SIGN列,利用该标志直接进行删除操作,避免了传统的复杂删除步骤,提升了系统性能。同时,Doris 还支持将 SEQUENCE 列与删除标志结合使用,确保过期数据的删除不会影响新数据,简化了实时数据流中的更新与删除操作。
受益于写入原子性、强一致性语义,以及灵活的在线 Schema 变更和列更新机制等机制,Doris 能够在高并发和实时更新场景中高效处理数据,简化开发工作,并提升系统的响应速度和可靠性。
参考文档:基于导入的批量删除
生态融合
Doris 提供丰富的 API 和连接器,方便与现有的数据处理工具和框架(如 Spark、Flink、Kafka)进行集成,增强了生态灵活性,使得 Doris 能够为用户提供更加强大的数据处理能力,适应多样化的业务需求和技术环境。
01 Kafka
Kafka Connect 是一款可扩展、可靠的在 Apache Kafka 和其他系统之间进行数据传输的工具,可以定义 Connectors 将大量数据迁入迁出 Kafka,并通过 Doris Kafka Connector 将上游 topic 中的数据读取后写入到 Doris 中。
在 Kafka Connect 集群上新增一个 Doris Sink 的 Connector,示例如下:
详细步骤参考文档
curl -i http://127.0.0.1:8083/connectors -H "Content-Type: application/json" -X POST -d '{ "name":"test-doris-sink-cluster", "config":{ "connector.class":"org.apache.doris.kafka.connector.DorisSinkConnector", "topics":"topic_test", "doris.topic2table.map": "topic_test:test_kafka_tbl", "buffer.count.records":"50000", "buffer.flush.time":"120", "buffer.size.bytes":"5000000", "doris.urls":"10.10.10.1", "doris.user":"root", "doris.password":"", "doris.http.port":"8030", "doris.query.port":"9030", "doris.database":"test_db", "key.converter":"org.apache.kafka.connect.storage.StringConverter", "value.converter":"org.apache.kafka.connect.json.JsonConverter" } }' 02 Flink
Apache Flink 是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态的计算。可以使用 Flink Doris Connector 将上游的数据,比如 Kafka、MySQL 等产生的数据,实时写入至 Doris。
使用 Flink 自带的 DataGen 模拟数据写入 Doris 中,示例如下:
具体步骤参考文档
SET 'execution.checkpointing.interval' = '30s'; CREATE TABLE student_source ( id INT, name STRING, age INT ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '1', 'fields.name.length' = '20', 'fields.id.min' = '1', 'fields.id.max' = '100000', 'fields.age.min' = '3', 'fields.age.max' = '30' ); -- doris sink CREATE TABLE student_sink ( id INT, name STRING, age INT ) WITH ( 'connector' = 'doris', 'fenodes' = '127.0.0.1:8030', 'table.identifier' = 'test.student', 'username' = 'root', 'password' = 'password', 'sink.label-prefix' = 'doris_label' ); INSERT INTO student_sink SELECT * FROM student_source; 03 Spark Structured Streaming
Structured Streaming 是一个构建在 Spark SQL 引擎之上的可扩展、容错的流处理引擎。借助 Structured Streaming,可以高效地读取上游数据源,并通过 Spark Doris Connector ,以 Stream Load 的方式将数据实时写入 Doris,实现端到端的流式数据处理流程。
使用 Spark 自带的 rate 数据源模拟数据写入 Doris 中,示例如下:
val spark = SparkSession.builder() .appName("RateSourceExample") .master("local[1]") .getOrCreate() val rateStream = spark.readStream .format("rate") .option("rowsPerSecond", 10) .load() rateStream.writeStream .format("doris") .option("checkpointLocation", "/tmp/checkpoint") .option("doris.table.identifier", "db.table") .option("doris.fenodes", "127.0.0.1:8030") .option("user", "root") .option("password", "") .start() .awaitTermination() spark.stop(); 实时数据分析最佳实践
用户案例 1:中通快递
随着中通快递业务的持续增长,昔日双 11 的业务高峰现已成为每日常态,原有数据架构在数据时效性、查询效率、与维护成本方面,均面临着较大的挑战。为此,中通快递引入 SelectDB,借助其高效的数据更新、低延时的实时写入与优异的查询性能,在快递业务实时分析场景、BI 报表与离线分析场景、高并发分析场景中均进行了应用实践。
在实时分析场景中,基于 SelectDB 灵活丰富的 SQL 函数公式、高吞吐量的计算能力,实现了结果表的查询加速, 能够达到每秒上 2K+ 数量级的 QPS 并发查询,数据报表更新及时度大大提高。
SelectDB 的引入满足了复杂与简单的实时分析需求。目前,SelectDB 日处理数据超过 6 亿条,数据总量超过 45 亿条,字段总量超过 200 列,并实现服务器资源节省 2/3、查询时长从 10 分钟降至秒级的数十倍提升。
用户案例 2:招联金融
招联金融(全称“招联消费金融股份有限公司”)旗下拥有“好期贷”“信用付”两大消费金融产品体系,为用户提供全线上、免担保、低利率的普惠消费信贷服务。早期采用 Lambda 架构,包含 ClickHouse、Spark、Impala、Hive、Kudu、Vertica 等,受限于运维依赖性高、资源利用率低、数据时效性低、并发能力弱等诸多问题。引入 Apache Doris 进行架构升级后,实现了高效实时分析、架构简化、混合部署与弹性伸缩等多项目标。
在客群筛选分析场景中,之前使用 Vertica 计算引擎处理 2.4 亿条数据耗时 30-60 分钟,替换为 Doris 后用时降至 5 分钟,性能提升 6 倍以上,并且 Doris 作为开源数据库,相比商业化产品 Vertica 有显著的成本优势。
结束语
以上就是 Apache Doris 在分析领域的实时更新能力详细介绍。在主键表方面,Doris 支持易用的 UPSERT 语义,结合主键索引和标记删除机制,确保了优异的写入性能和低延迟的查询性能。此外,用户自定义的冲突解决机制进一步提升了实时写入的并发能力,快速的 Schema 变更功能则避免了实时数据流的中断。列更新及灵活的列更新选项为更广泛的实时场景提供了便捷支持。
展望未来,我们将在以下几方面重点投入:
- 降低数据可见性延迟,以实现更加实时的数据访问体验;
- 提升生态工具在自动调整 Schema 方面的能力,并扩展 Light Schema 的适用范围;
- 更加灵活的列更新,为用户提供更加高效、灵活的数据管理能力。



