This document shows you how to enable Lightning Engine to accelerate Serverless for Apache Spark batch workloads and interactive sessions.
Overview
Lightning Engine is a high-performance query accelerator powered by a multi-layer optimization engine that performs customary optimization techniques, such as query and execution optimizations, as well as curated optimizations in the file system layer and data access connectors.
As shown in the following illustration, Lightning Engine accelerates Spark query execution performance on a TPC-H-like workload (10 TB dataset size).
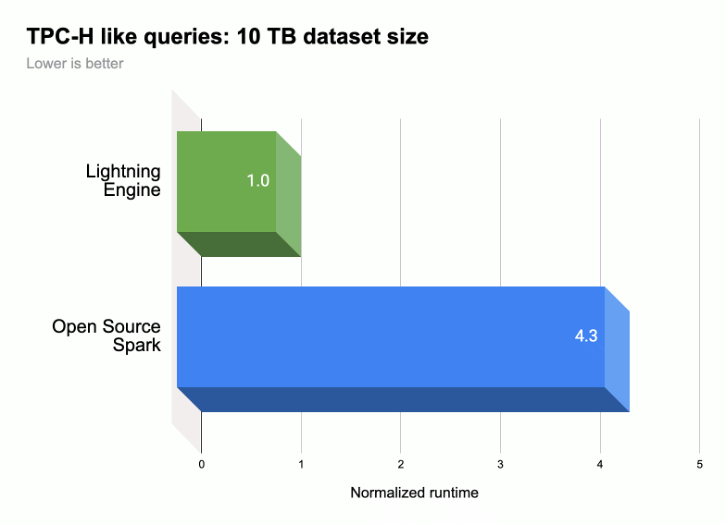
For more information: see Introducing Lightning Engine — the next generation of Apache Spark performance.
Lightning Engine availability
- Lightning Engine is available for use with supported Serverless for Apache Spark runtimes that are in General Availability (currently runtimes
1.2,2.2, and2.3; not available in Spark runtime3.0). - Lightning Engine is available only with the Serverless for Apache Spark premium pricing tier.
- Batch workloads: Lightning Engine is automatically enabled for batch workloads on the premium tier. No action is required.
- Interactive sessions: Lightning Engine is not enabled by default for interactive sessions. To enable it, see Enable Lightning Engine.
- Session templates: Lightning Engine is not enabled by default for session templates. To enable it, see Enable Lightning Engine.
Enable Lightning Engine
The following sections show you how to enable Lightning engine on a Serverless for Apache Spark batch workload, session template, and interactive session.
Batch workload
Enable Lightning Engine on a batch workload
You can use the Google Cloud console, Google Cloud CLI, or Dataproc API to enable Lightning Engine on a batch workload.
Console
Use the Google Cloud console to enable Lightning Engine on a batch workload.
In the Google Cloud console:
- Go to Dataproc Batches.
- Click Create to open the Create batch page.
Select and fill in the following fields:
- Container:
- Runtime version: Select
1.2,2.2,2.3, or latermajor.minorversion number. See Supported Serverless for Apache Spark runtime versions.
- Runtime version: Select
Tier Configuration:
- Select
Premium. This automatically enables and checks "Enable LIGHTNING ENGINE to accelerate Spark performance".
When you select the premium tier, the Driver Compute Tier and the Executor Compute Tier are set to
Premium. These automatically set premium tier compute settings can't be overridden for batches using runtimes prior to3.0.You can configure the Driver Disk Tier and the Executor Disk Tier to
Premiumor leave them at their defaultStandardtier value. If you choose a premium disk tier, you must select the disk size. For more information, see resource allocation properties.- Select
Properties: Optional: Enter the following
Key(property name) andValuepair if you want to select the Native Query Execution runtime:Key Value spark.dataproc.lightningEngine.runtimenative
- Container:
Fill in, select, or confirm other batch workloads settings. See Submit a Spark batch workload.
Click Submit to run the Spark batch workload.
gcloud
Set the following gcloud CLI gcloud dataproc batches submit spark command flags to enable a Lightning Engine on a batch workload.
gcloud dataproc batches submit spark \ --project=PROJECT_ID \ --region=REGION \ --properties=dataproc.tier=premium \ OTHER_FLAGS_AS_NEEDED
Notes:
- PROJECT_ID: Your Google Cloud project ID. Project IDs are listed in the Project info section on the Google Cloud console Dashboard.
- REGION: An available Compute Engine region to run the workload.
--properties=dataproc.tier=premium. Setting the premium tier automatically sets the following properties on the batch workload:spark.dataproc.engine=lightningEngineselects Lightning Engine for the batch workload.spark.dataproc.driver.compute.tierandspark.dataproc.executor.compute.tierare set topremium(see resource allocation properties). These automatically set premium tier compute settings can't be overridden for batches using runtimes prior to3.0.
Other properties
Native Query Engine:
spark.dataproc.lightningEngine.runtime=nativeAdd this property if you want to select the Native Query Execution runtime.Disk tiers and sizes: By default, driver and executor disk sizes are set to
standardtiers and sizes. You can add properties to selectpremiumdisk tiers and sizes (in multiples of375 GiB).
For more information, see resource allocation properties.
OTHER_FLAGS_AS_NEEDED: See Submit a Spark batch workload.
API
To enable Lightning Engine on a batch workload, add "dataproc.tier":"premium" to RuntimeConfig.properties as part of your batches.create request. Setting the premium tier automatically sets the following properties on the batch workload:
spark.dataproc.engine=lightningEngineselects Lightning Engine for the batch workload.spark.dataproc.driver.compute.tierandspark.dataproc.executor.compute.tierare set topremium(see resource allocation properties). These automatically set premium tier compute settings can't be overridden for batches using runtimes prior to3.0.
Other RuntimeConfig.properties:
Native Query Engine:
spark.dataproc.lightningEngine.runtime:native. Add this property if you want to select the Native Query Execution runtime.Disk tiers and sizes: By default, driver and executor disk sizes are set to
standardtiers and sizes. You can add properties to selectpremiumtiers and sizes (in multiples of375 GiB).
For more information, see resource allocation properties.
See Submit a Spark batch workload to set other batch workload API fields.
Session template
Enable Lightning Engine on a session template
You can use the Google Cloud console, Google Cloud CLI, or Dataproc API to enable Lightning Engine on a session template for a Jupyter or Spark Connect session.
Console
Use the Google Cloud console to enable Lightning Engine on a batch workload.
In the Google Cloud console:
- Go to Dataproc Session Templates.
- Click Create to open the Create session template page.
Select and fill in the following fields:
- Session template info:
- Select "Enable Lightning Engine to accelerate Spark performance".
- Execution Configuration:
- Runtime version: Select
1.2,2.2,2.3, or latermajor.minorversion number. See Supported Serverless for Apache Spark runtime versions.
- Runtime version: Select
Properties: Enter the following
Key(property name) andValuepairs to select the Premium tier:Key Value dataproc.tierpremium spark.dataproc.enginelightningEngine Optional: Enter the following
Key(property name) andValuepair to select the Native Query Execution runtime:Key Value spark.dataproc.lightningEngine.runtimenative
- Session template info:
Fill in, select, or confirm other session template settings. See Create a session template.
Click Submit to create the session template.
gcloud
You can't directly create a Serverless for Apache Spark session template using the gcloud CLI. Instead, you can use the gcloud beta dataproc session-templates import command to import an existing session template, edit the imported template to enable the Lightning Engine and optionally the Native Query runtime, and then export the edited template using the gcloud beta dataproc session-templates export command.
API
To enable Lightning Engine on a session template, add "dataproc.tier":"premium" and "spark.dataproc.engine":"lightningEngine" to RuntimeConfig.properties as part of your sessionTemplates.create request.
Other RuntimeConfig.properties:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime:native: Add this property to RuntimeConfig.properties to select the Native Query Execution runtime.
See Create a session template to set other session template API fields.
Interactive session
Enable Lightning Engine on an interactive session
You can use the Google Cloud CLI or Dataproc API to enable Lightning Engine on a Serverless for Apache Spark interactive session. You can also enable Lightning Engine in an interactive session in a BigQuery Studio notebook.
gcloud
Set the following gcloud CLI gcloud beta dataproc sessions create spark command flags to enable Lightning Engine on an interactive session.
gcloud beta dataproc sessions create spark \ --project=PROJECT_ID \ --location=REGION \ --properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine \ OTHER_FLAGS_AS_NEEDED
Notes:
- PROJECT_ID: Your Google Cloud project ID. Project IDs are listed in the Project info section on the Google Cloud console Dashboard.
- REGION: An available Compute Engine region to run the workload.
--properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine. These properties enable Lightning Engine on the session.Other properties:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime=native: Add this property to select the Native Query Execution runtime.
- Native Query Engine:
OTHER_FLAGS_AS_NEEDED: See Create an interactive session.
API
To enable Lightning Engine on a session, add "dataproc.tier":"premium" and "spark.dataproc.engine":"lightningEngine" to RuntimeConfig.properties as part of your sessions.create request.
Other RuntimeConfig.properties:
spark.dataproc.lightningEngine.runtime:native: Add this property to RuntimeConfig.properties if you want to select the Native Query Execution runtime. See Create an interactive session to set other session template API fields.
BigQuery notebook
You can enable Lightning Engine when you create a session in a BigQuery Studio PySpark notebook.
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session session = Session() # Enable Lightning Engine. session.runtime_config.properties["dataproc.tier"] = "premium" session.runtime_config.properties["spark.dataproc.engine"] = "lightningEngine" # Enable THE Native Query Execution runtime. session.runtime_config.properties["spark.dataproc.lightningEngine.runtime"] = "native" # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate()) # Add Spark application code here: Verify Lightning Engine settings
You can use the Google Cloud console, Google Cloud CLI, or Dataproc API to verify Lightning Engine settings on a batch workload, session template, or interactive session.
Batch workload
To verify the batch tier is set to
premiumand engine is set toLightning Engine:- Google Cloud console: On the Batches page, see the Tier and Engine columns for the batch. You can click The Batch ID to also view these settings on the batch details page.
- gcloud CLI: Run the
gcloud dataproc batches describecommand. - API: Issue a
batches.getrequest.
Session template
To verify engine is set to
Lightning Enginefor a session template:- Google Cloud console: On the Session Templates page, see the Engine column for your template. You can click the session template Name to also view this setting on the session template details page.
- gcloud CLI: Run the
gcloud beta dataproc session-templates describecommand. - API: Issue a
sessionTemplates.getrequest.
Interactive session
To the engine is set to
Lightning Enginefor an interactive session:- Google Cloud console: On the Interactive Sessions page, see the Engine column for the template. You can click the Interactive Session ID to also view this setting on the session template details page.
- gcloud CLI: Run the
gcloud beta dataproc sessions describecommand. - API: Issue a
sessions.getrequest.
Native Query Execution
Native Query Execution (NQE) is an optional Lightning Engine feature that enhances performance through a native implementation based on Apache Gluten and Velox that is designed for Google hardware.
The Native Query Execution runtime includes unified memory management for dynamic switching between off-heap and on-heap memory without requiring changes to existing Spark configurations. NQE includes expanded support for operators, functions and Spark data types, as well as intelligence to automatically identify opportunities to use the native engine for optimal pushdown operations.
Identify Native query execution workloads
Use Native Query Execution in the following scenarios:
Spark Dataframe APIs, Spark Dataset APIs, and Spark SQL queries that read data from Parquet and ORC files. The output file format doesn't affect Native Query Execution performance.
Workloads recommended by the Native Query Execution qualification tool.
Native query execution is not recommended with for workloads with inputs of the following data types:
- Byte: ORC and Parquet
- Timestamp: ORC
- Struct, Array, Map: Parquet
Native Query Execution limitations
Enabling Native Query Execution in the following scenarios can cause exceptions, Spark incompatibilities, or workload fallback to the default Spark engine.
Fallbacks
Native Query Execution in the following the execution can result in workload fallback to the Spark execution engine, resulting in regression or failure.
ANSI: If ANSI mode is enabled, execution falls back to Spark.
Case-sensitive mode: Native Query Execution supports the Spark default case-insensitive mode only. If case-sensitive mode is enabled, incorrect results can occur.
Partitioned table scan: Native Query Execution supports the partitioned table scan only when the path contains the partition information, otherwise the workload falls back to the Spark execution engine.
Incompatible behavior
Incompatible behavior or incorrect results can result when using Native query execution in the following cases:
JSON functions: Native Query Execution supports strings surrounded by double quotes, not single quotes. Incorrect results occur with single quotes. Using "*" in the path with the
get_json_objectfunction returnsNULL.Parquet read configuration:
- Native Query Execution treats
spark.files.ignoreCorruptFilesas set to the defaultfalsevalue, even when set totrue. - Native Query Execution ignores
spark.sql.parquet.datetimeRebaseModeInRead, and returns only the Parquet file contents. Differences between the legacy hybrid (Julian Gregorian) calendar and the Proleptic Gregorian calendar are not considered. Spark results can differ.
- Native Query Execution treats
NaN: Not supported. Unexpected results can occur, for example, when usingNaNin a numeric comparison.Spark columnar reading: A fatal error can occur due since the Spark columnar vector is incompatible with Native Query Execution.
Spill: When shuffle partitions are set to a large number, the spill-to-disk feature can trigger an
OutOfMemoryException. If this occurs, reducing the number of partitions can eliminate this exception.