A web app that summarizes and answers questions about PDF documents in multiple languages. It can condense complex texts such as lecture notes, textbooks, or research papers into concise summaries, providing clear insights in the original language of the document.
As it runs locally, your data is 100% safe
try the app here: Study Copilot
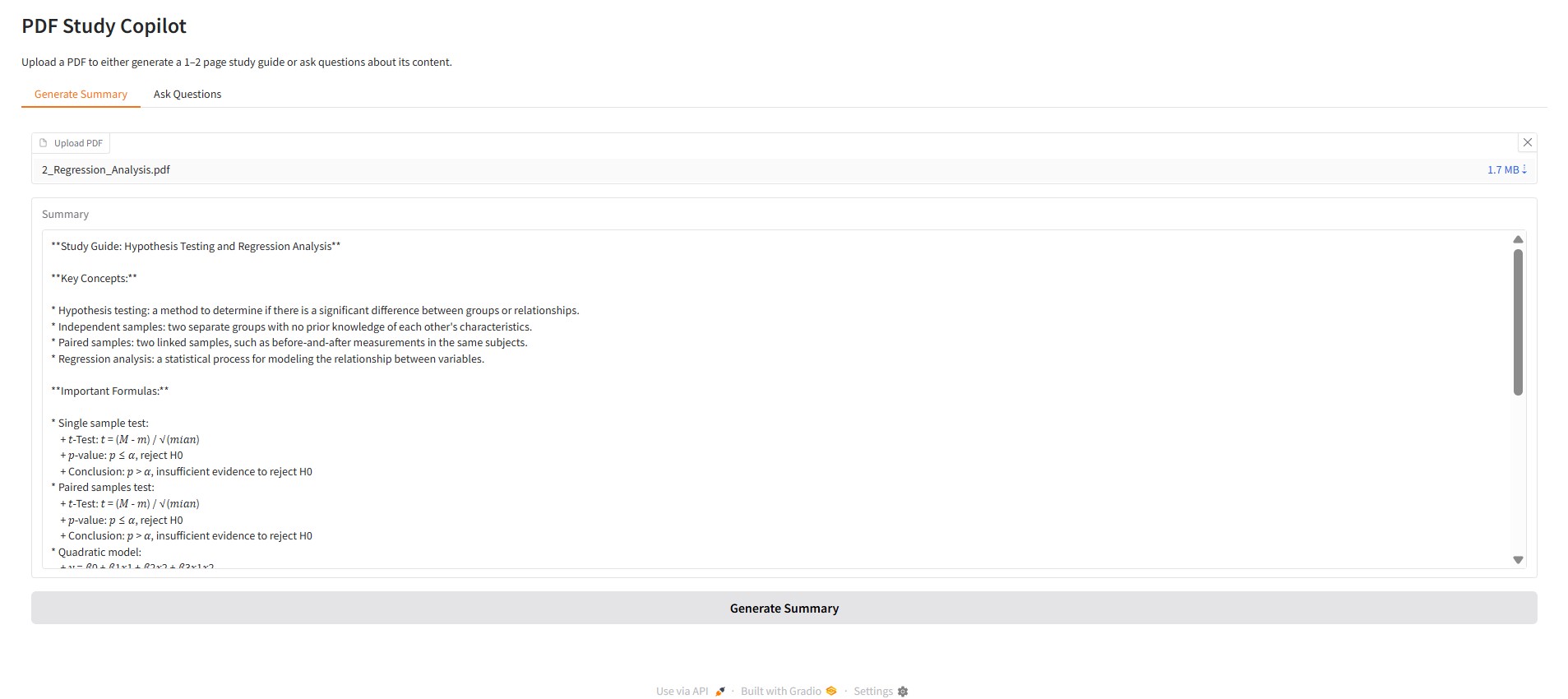
- Upload PDFs in any language and get summaries or answers in the same language.
- Ask questions about the PDF content and receive accurate responses.
- Summarizes complex topics into clear, digestible text.
- Powered by LangChain, Ollama LLM, and HuggingFace embeddings.
- Multilingual support for global usage.
- PDF Processing: Splits the uploaded PDF into manageable text chunks.
- Embedding Generation: Converts each chunk into vector embeddings using HuggingFace.
- Retrieval: Chroma vector store retrieves the most relevant chunks for your query.
- LLM Response: Ollama LLM generates concise answers or summaries based solely on the PDF content.
- Python 3.10+
- Virtual environment recommended
Install dependencies:
pip install -r requirements.txt- Clone or download the project.
- Activate a virtual environment:
python -m venv .venv source .venv/bin/activate # macOS/Linux .venv\Scripts\activate # Windows- Install dependencies:
pip install -r requirements.txt- Run the app:
python app.py-
Open the Gradio interface in your browser:
- Upload a PDF.
- Enter a question about the content.
- Receive summaries or answers instantly in the PDF's language.
- Upload a PDF in French about statistical methods.
- Ask: "Quels sont les principaux coefficients de régression?"
- Receive a concise answer or summary in French.
- Answers and summaries are strictly based on the uploaded content; the tool does not generate information outside the PDF.
- Supports any language recognized by the underlying LLM.
- Gradio – Web interface
- LangChain – LLM orchestration
- LangChain Ollama – LLM backend
- HuggingFace Embeddings – Embedding generation
- Chroma – Vector store for retrieval
- pypdf – PDF parsing