# CLIP模型
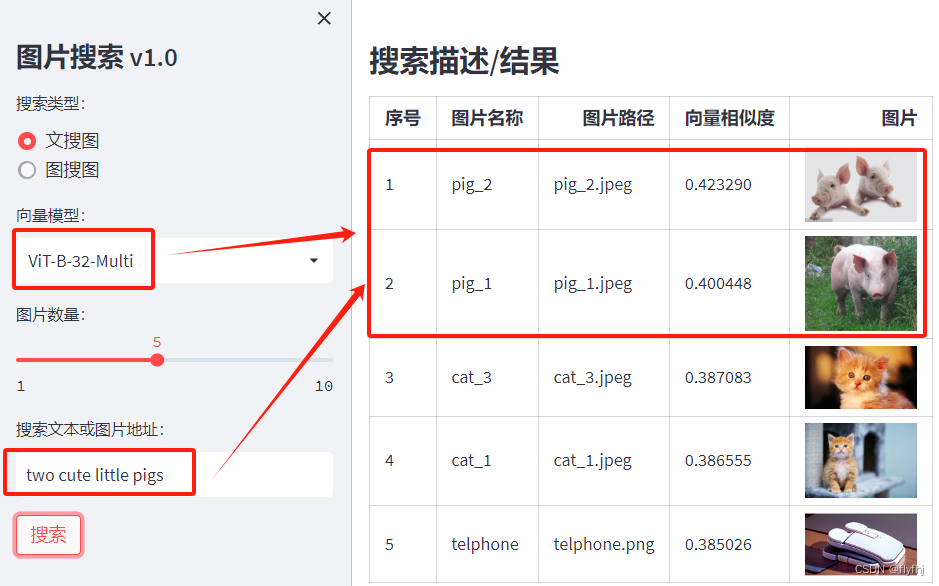
# 简介
CLIP(全称 Contrastive Language-Image Pre-Training)是一种在大量 (图像,文本)对 上训练的神经网络。 它可以通过自然语言指令,根据输入的图像,预测最相关的文本描述,而不需要针对具体任务进行专门优化——这与 GPT-2 和 GPT-3 的零样本(zero-shot)能力 类似。 研究结果表明,CLIP 在 ImageNet 零样本分类 中的表现 与原始的 ResNet50 相当,而且 完全没有使用 ImageNet 的 128 万个带标签样本,从而克服了计算机视觉领域的多个重大挑战。
# 安装
# Maven
在项目的 pom.xml 中添加以下依赖,详细引入方式参考 Maven 引入。
如需引入全部功能,请使用 【不推荐 ❌】 all 模块。
<dependency> <groupId>cn.smartjavaai</groupId> <artifactId>vision</artifactId> <version>1.0.27</version> </dependency> # 获取CLIP模型
ClsModelConfig config = new ClsModelConfig(); config.setModelEnum(ClsModelEnum.YOLOV8); config.setModelPath("yolo11m-cls.onnx"); config.setDevice(device); config.setThreshold(0.5f); ClsModel clsModel = ClsModelFactory.getInstance().getModel(config); # ClsModelConfig参数说明
| 字段名称 | 字段类型 | 默认值 | 说明 |
|---|---|---|---|
| modelEnum | ClsModelEnum | 无 | 模型枚举 |
| modelPath | String | 模型路径 | |
| allowedClasses | List<String> | 允许的分类列表 | |
| threshold | double | 0.3 | 置信度阈值,分数低于这个值的结果将被过滤掉。值越高越严格,越低越宽松 |
| device | DeviceEnum | CPU | 指定运行设备,支持 CPU/GPU |
| gpuId | int | 0 | gpu设备ID 当device为GPU时生效 |
| predictorPoolSize | int | 默认为cpu核心数 | 模型预测器线程池大小 |
| customParams | Map<String, Object> | 无 | 个性化配置(按模型类型动态解析) |
初始化模型:
模型支持从 JAR 包中加载。请将模型文件及其附带资源打包为一个 ZIP 文件,并放置在 JAR 包内的指定目录(默认路径为 META-INF/models)。 如需自定义目录,可自行修改路径配置。 代码中指定模型路径时,请使用以下格式: modelPath = "jar:/META-INF/models/clip.zip"
# CLIP模型
| 模型名称 | 引擎 |
|---|---|
| OPENAI | PyTorch |
# ClsModel API 方法说明
# 图像特征提取
Image图片源请查看文档Image使用说明
R<float[]> extractImageFeatures(Image image); R<float[]> extractImageFeatures(String imagePath); # 文本特征提取
R<float[]> extractTextFeatures(String inputs); # 图片特征比较
scale 参数用于对模型计算得到的相似度结果进行缩放,例如设置为 1.2 表示将相似度结果放大 20%,用于根据实际需求微调比对结果的敏感度。
默认缩放比例是 1.0,不缩放
R<Float> compareImage(Image image1, Image image2); R<Float> compareImage(Image image1, Image image2, float scale); R<Float> compareImage(String imagePath1, String imagePath2, float scale); # 文本特征比较
scale 参数用于对模型计算得到的相似度结果进行缩放,例如设置为 1.2 表示将相似度结果放大 20%,用于根据实际需求微调比对结果的敏感度。
默认缩放比例是 1.0,不缩放
R<Float> compareText(String input1, String input2); R<Float> compareText(String input1, String input2, float scale); # 图片与文本特征比较
R<Float> compareTextAndImage(Image image, String text); # 特征比较
scale 参数用于对模型计算得到的相似度结果进行缩放,例如设置为 1.2 表示将相似度结果放大 20%,用于根据实际需求微调比对结果的敏感度。
默认缩放比例是 1.0,不缩放
R<Float> compareFeatures(float[] feature1, float[] feature2, float scale); # 模型下载
百度网盘:https://pan.baidu.com/s/15vcuQQz2zL2id7J_01vbdQ?pwd=1234 提取码: 1234
# 完整示例代码
本项目在 examples 文件夹下提供了多个示例工程,用于演示各功能模块的使用方法:
vision-example:通用视觉检测示例:目标检测、目标分割、图像分类等
# 运行方式
如果你只想运行某个示例,请按以下方式操作:
打开 IDEA(或你喜欢的 IDE)
选择 “Open”,然后仅导入
examples目录下对应的示例项目,例如:examples/vision-exampleIDEA 会自动识别并加载依赖。若首次导入,请等待 Maven 下载依赖完成。
请从我们提供的 百度网盘 中下载模型及其附带文件,并在示例代码中将模型路径修改为您本地的实际路径。
可通过查看每个 Java 文件顶部的注释了解对应功能,或参考 README 文件中对各 Java 文件功能的说明,运行相应的测试方法进行体验。