| Yanhong Zeng 曾艳红 Yanhong Zeng is currently a researcher working on Generative AI in Ant Group, working with Yujun Shen. Before that, she led a small effort in advancing image/video generation in Shanghai AI Lab, working with Kai Chen. She obtained her computer science Ph.D. degree in the joint doctoral program between Sun Yat-sen University and Microsoft Research Asia (MSRA) in 2022, working with Jianlong Fu, supervised by Prof. Hongyang Chao and Dr. Baining Guo. 💗 Her research interest is advancing high-quality and controllable generative models and systems across media including images, videos, and audio. Her passion lies in democratizing creativity by transforming ideas into compelling and shareable contents.
💗 Happy to talk about any possible ways we can work together! |  |
News
|
Selected Publications |
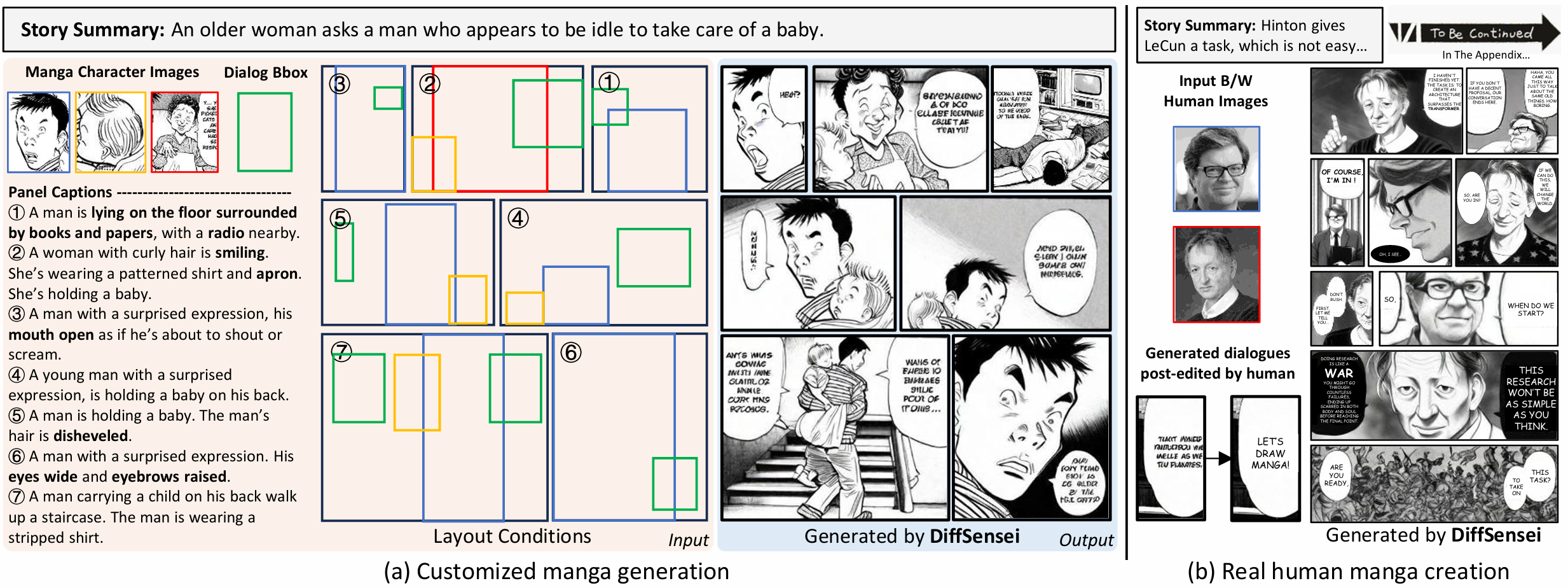 | DiffSensei: Bridging Multi-Modal LLMs and Diffusion Models for Customized Manga Generation Jianzong Wu, Chao Tang, Jingbo Wang, Yanhong Zeng, Xiangtai Li, Yunhai Tong CVPR, 2025 project page / arXiv / dataset / demo / code  MangaZero is a new large-scale manga dataset containing 43K manga pages and 427K annotated panels. DiffSensei is the first model that can generate manga images with high-quality and controllable multiple characters with complex scenes. |
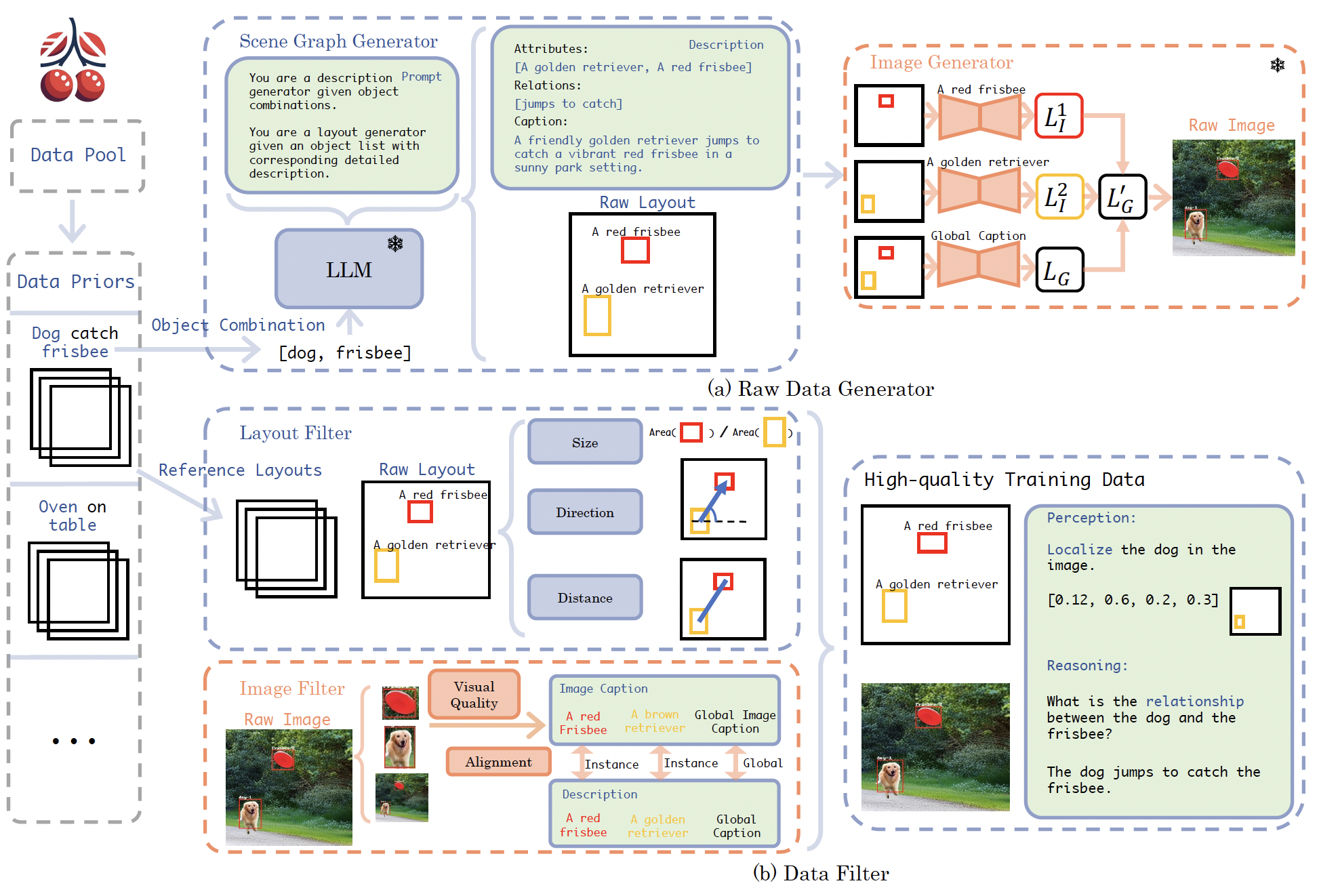 | Auto Cherry-Picker: Learning from High-quality Generative Data Driven by Language Yicheng Cheng, Xiangtai Li, Yining Li, Yanhong Zeng, Jianzong Wu, Xiangyu Zhao, Kai Chen CVPR, 2025 project page / arXiv / code /  Auto Cherry-Picker is designed to synthesize training samples for both perception and multi-modal reasoning tasks from a simple object list in natural language. It employs a nowly designed metric, CLIS, to ensure the quality of the synthetic data. |
 | MotionBooth: Motion-Aware Customized Text-to-Video Generation Jianzong Wu, Xiangtai Li, Yanhong Zeng, Jiangning Zhang, Qianyu Zhou, Yining Li, Yunhai Tong, Kai Chen NeurIPS, 2024 (Spotlight) project page / video / arXiv / code  MotionBooth is designed for animating customized subjects with precise control over both object and camera movements. |
 | HumanVid: Demystifying Training Data for Camera-controllable Human Image Animation Zhenzhi Wang, Yixuan Li, Yanhong Zeng, Yuwei Guo, Youqing Fang, Wenran Liu, Jing Tan, Kai Chen, Tianfan Xue, Bo Dai, Dahua Lin NeurIPS, 2024 (D&B Track) project page / arXiv / code  HumanVid is the first large-scale high-quality dataset tailored for human image animation, which combines crafted real-world and synthetic data. |
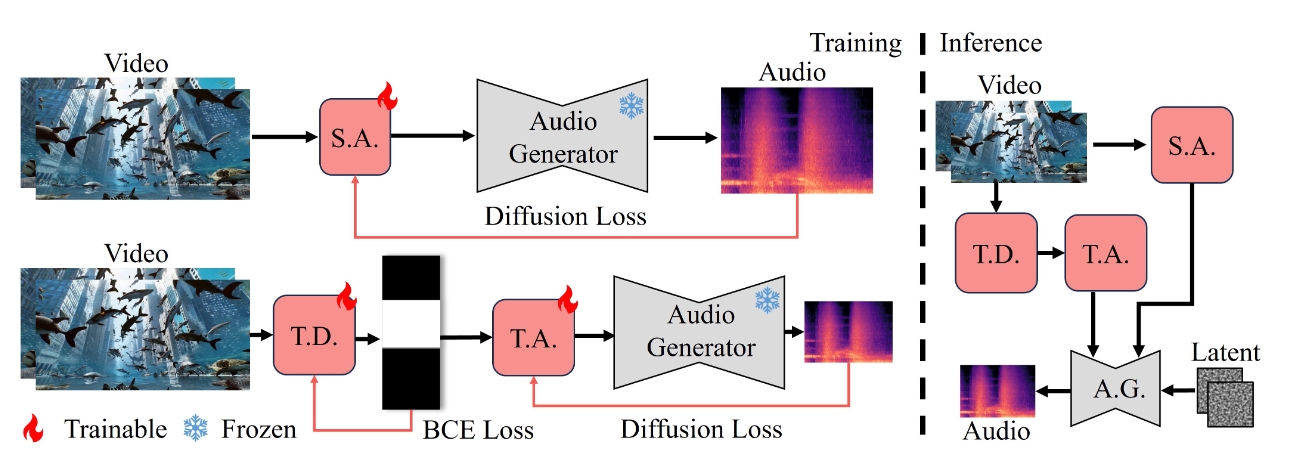 | FoleyCrafter: Bring Silent Videos to Life with Lifelike and Synchronized Sounds Yiming Zhang, Yicheng Gu, Yanhong Zeng ♦, Zhening Xing, Yuancheng Wang, Zhizheng Wu, Kai Chen Arxiv, 2024 project page / video / arXiv / demo / code  FoleyCrafter is a text-based video-to-audio generation framework which can generate high-quality audios that are semantically relevant and temporally synchronized with the input videos. |
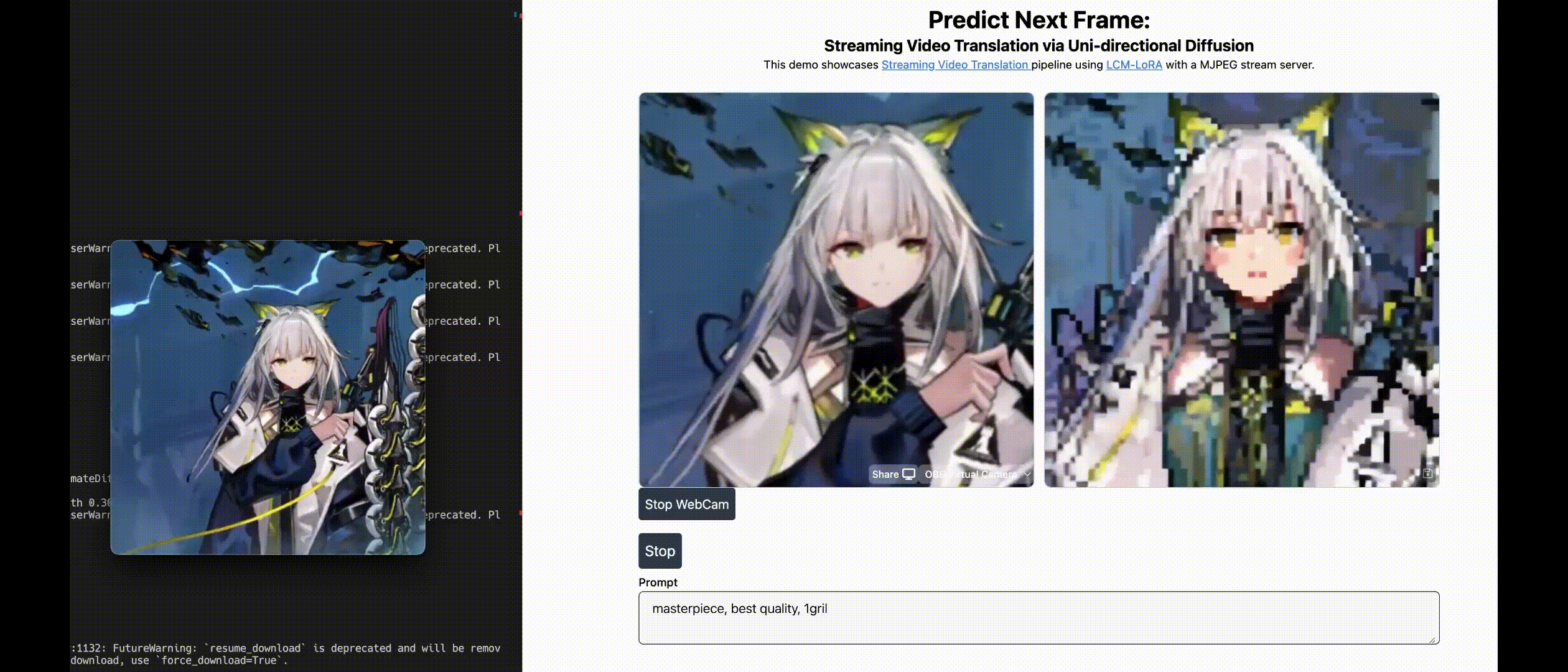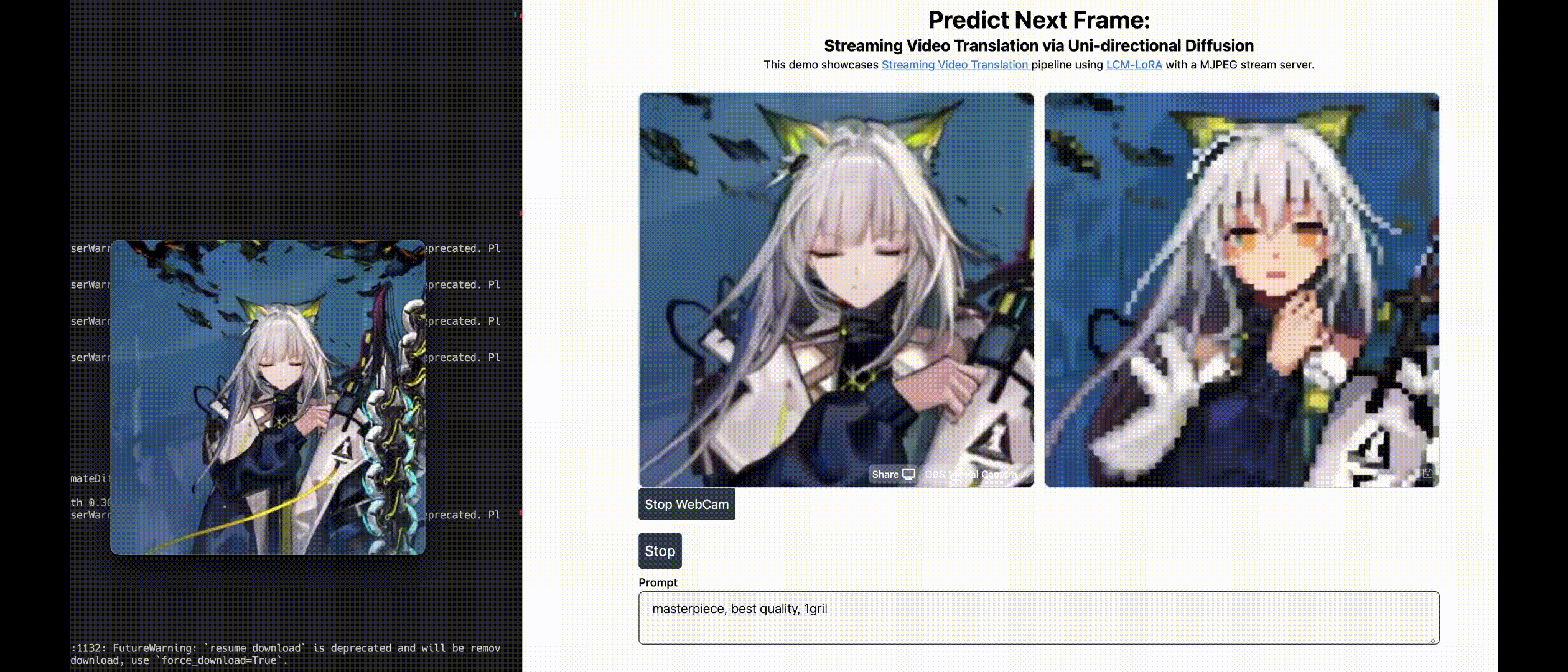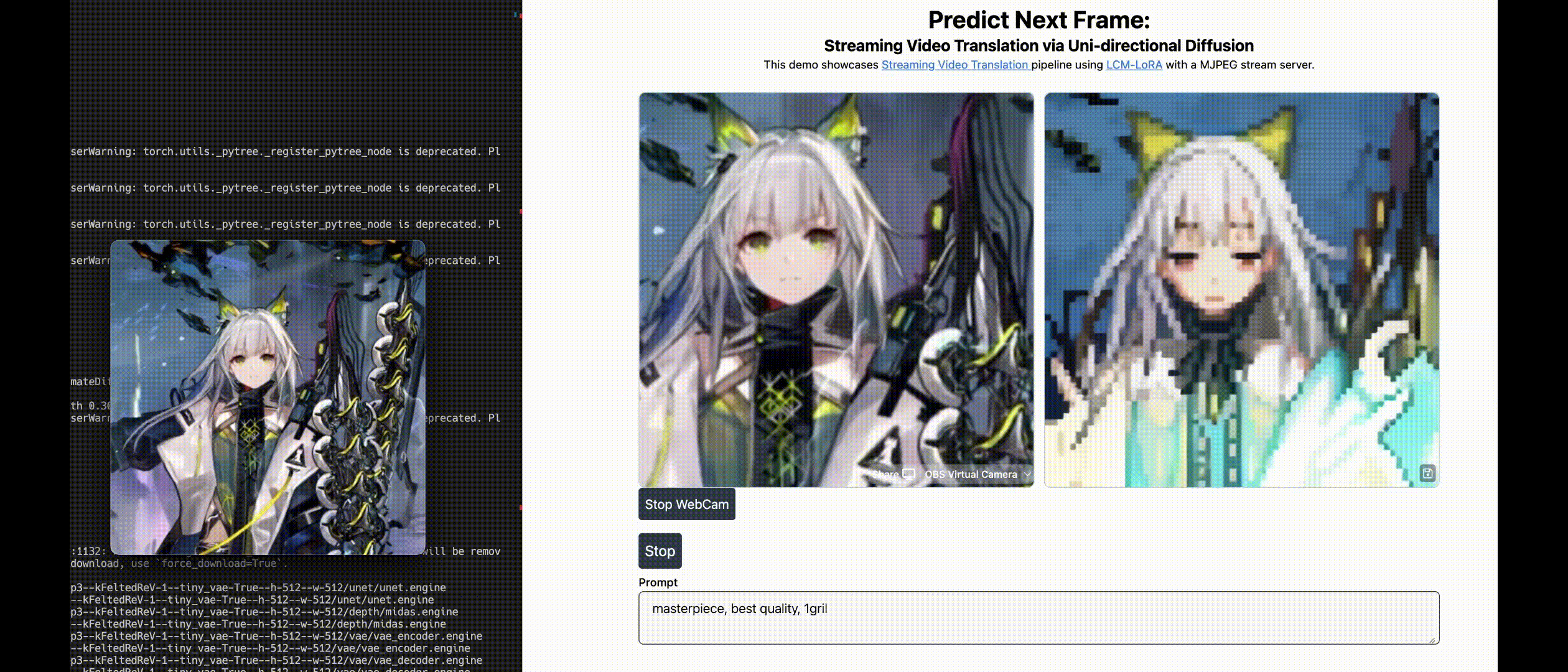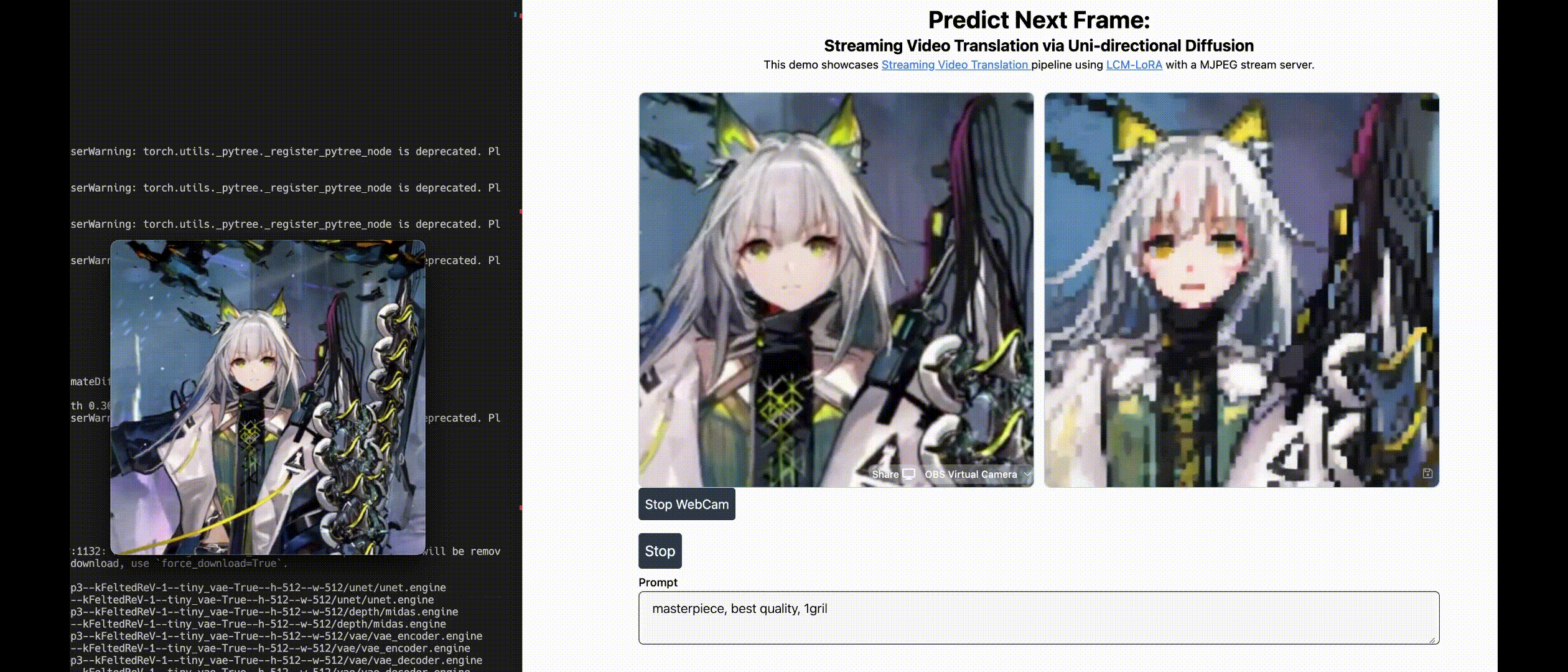 | Live2Diff: Live Stream Translation via Uni-directional Attention in Video Diffusion Models Zhening Xing, Gereon Fox, Yanhong Zeng, Xingang Pan, Mohamed Elgharib, KChristian Theobalt , Kai Chen Arxiv, 2024 project page / video / arXiv / demo / code  Live2Diff is the first attempt that enables uni-directional attention modeling to video diffusion models for live video steam processing, and achieves 16FPS on RTX 4090 GPU. |
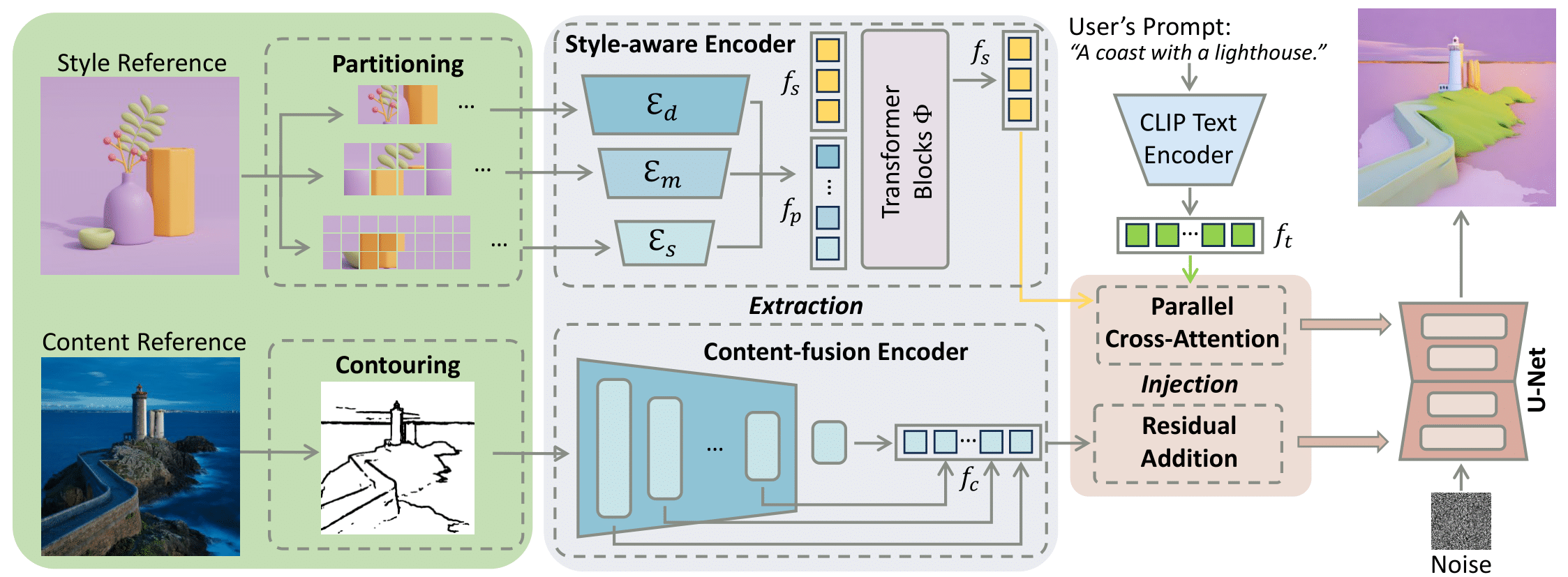 | StyleShot: A SnapShot on Any Style Junyao Guo, Yanchen Liu, Yanan Sun, Yinhao Tang, Yanhong Zeng, Kai Chen, Cairong Zhao, Arxiv, 2024 project page / video / arXiv / demo / code  StyleShot is a style transfer model that excels in text and image-driven style transferring without test-time style-tuning. |
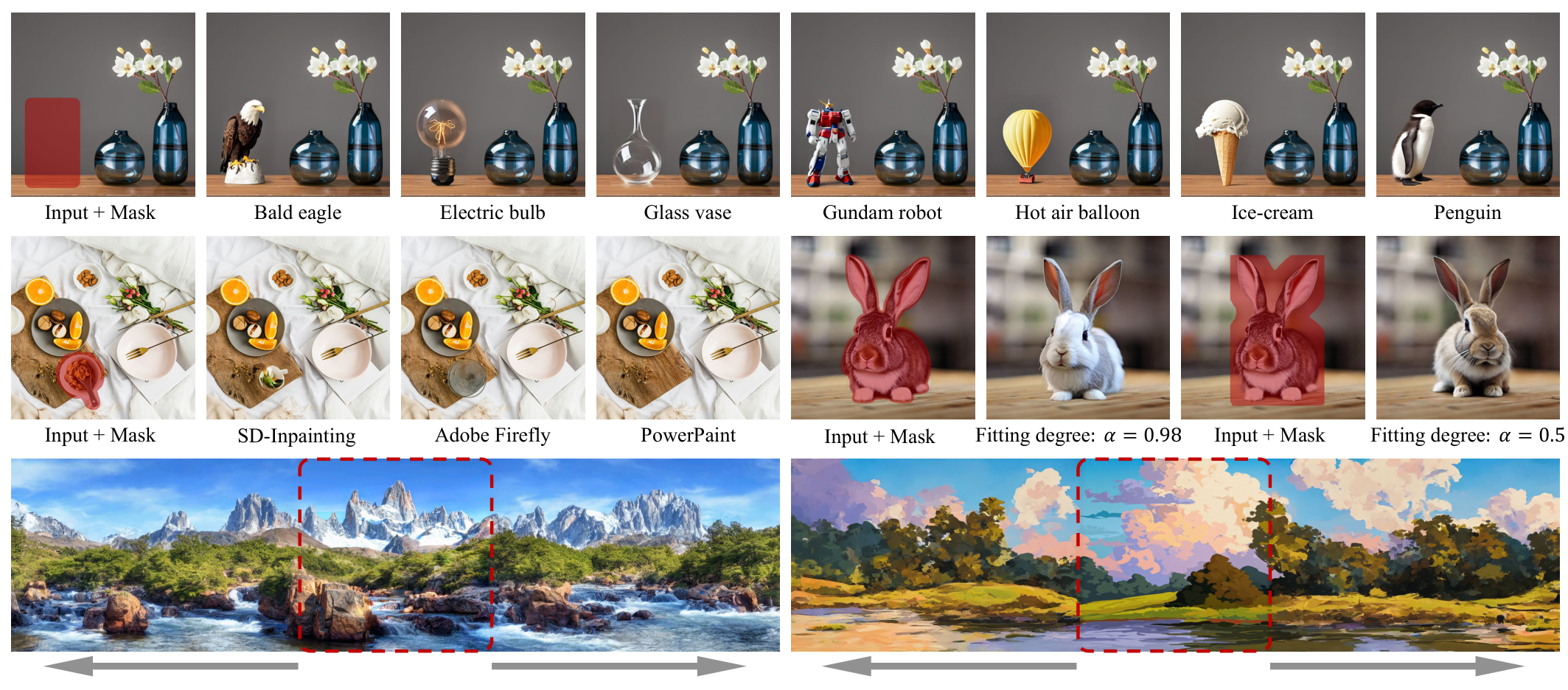 | A Task is Worth One Word: Learning with Task Prompts for High-Quality Versatile Image Inpainting Junhao Zhuang, Yanhong Zeng ♦, Wenran Liu, Chun Yuan, Kai Chen ECCV, 2024 project page / video / arXiv / demo / code  PowerPaint is the first versatile inpainting model that achieves SOTA in text-guided and shape-guided object inpainting, object removal, outpainting, etc. |
 | PIA: Your Personalized Image Animator via Plug-and-Play Modules in Text-to-Image Models Yiming Zhang*, Zhening Xing*, Yanhong Zeng ♦, Youqing Fang, Kai Chen CVPR, 2024 project page / video / arXiv / demo / code  PIA can animate any images from personalized models by text while preserving high-fidelity details and unique styles. |
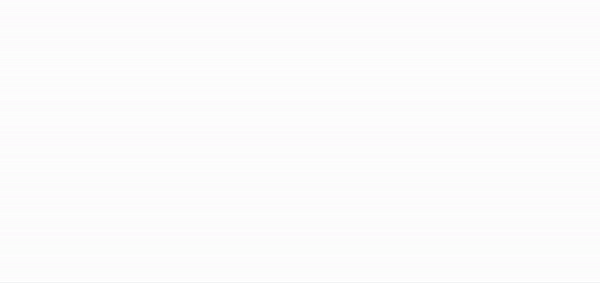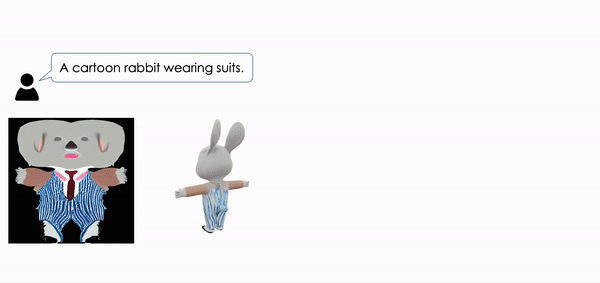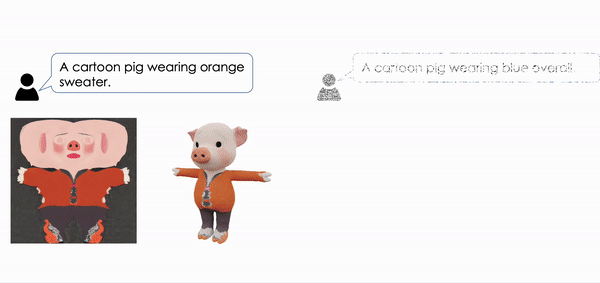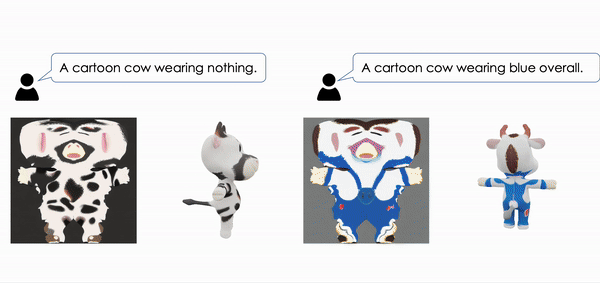 | Make-It-Vivid: Dressing Your Animatable Biped Cartoon Characters from Text Junshu Tang, Yanhong Zeng, Ke Fan, Xuheng Wang, Bo Dai, Lizhuang Ma, Kai Chen CVPR, 2024 project page / video / arXiv / code  We present Make-it-Vivid, the first attempt that can create plausible and consistent texture in UV space for 3D biped cartoon characters from text input within few seconds. |
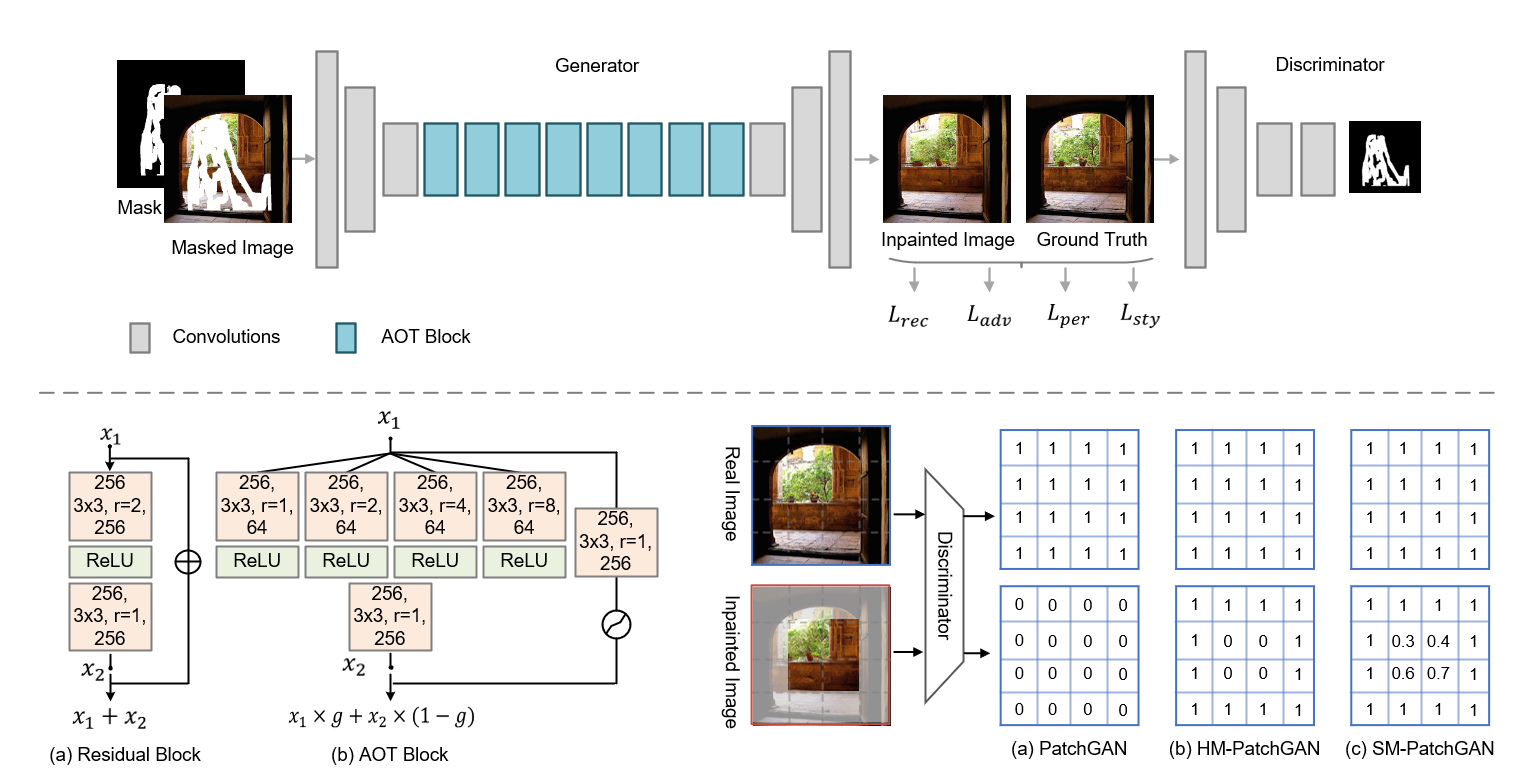 | Aggregated Contextual Transformations for High-Resolution Image Inpainting Yanhong Zeng, Jianlong Fu, Hongyang Chao, Baining Guo TVCG, 2023 project page / arXiv / video 1 / video 2 / code  In AOT-GAN, we propose aggregated contextual transformations and a novel mask-guided GAN training strategy for high-resolution image inpaining. |
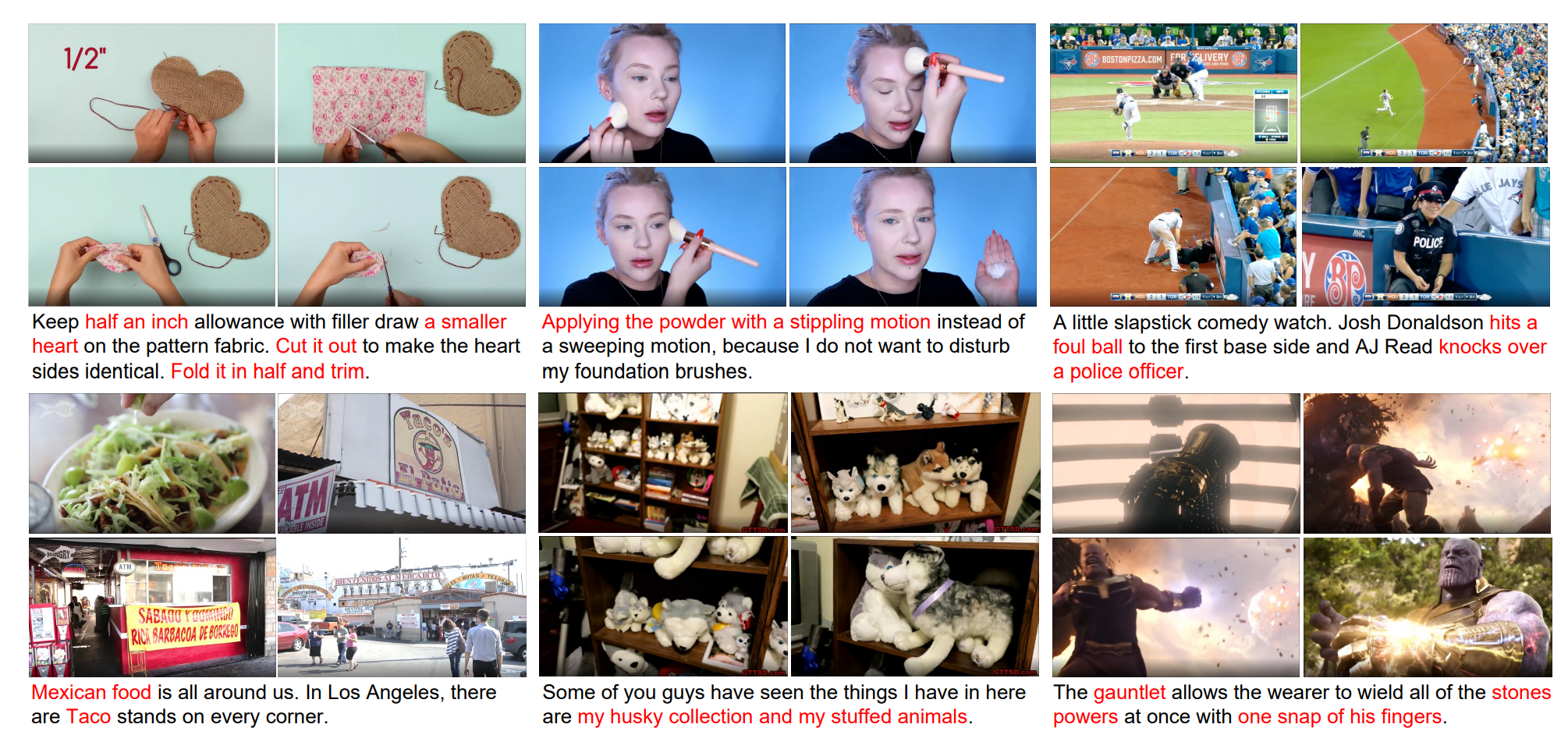 | Yanhong Zeng*, Hongwei Xue*, Tiankai Hang*, Yuchong Sun*, Bei Liu, Huan Yang, Jianlong Fu, Baining Guo CVPR, 2022 arXiv / video / code  We collect a large dataset which is the first high-resolution dataset including 371.5k hours of 720p videos and the most diversified dataset covering 15 popular YouTube categories. |
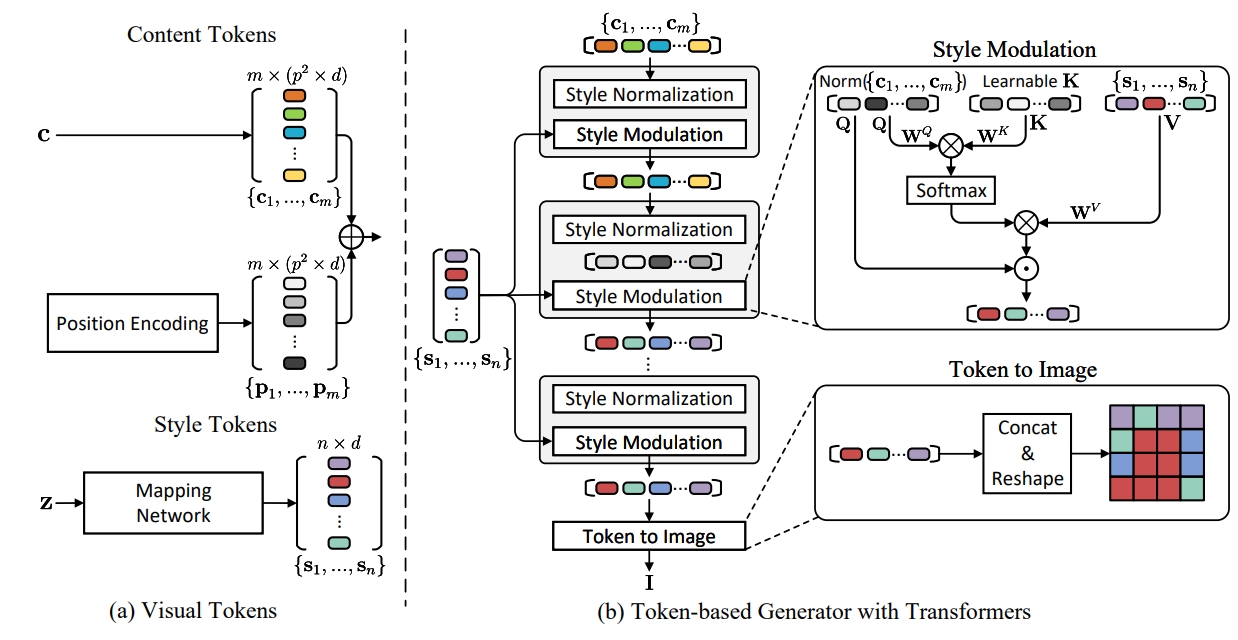 | Yanhong Zeng, Huan Yang, Hongyang Chao, Jianbo Wang, Jianlong Fu NeurIPS, 2021 arXiv We propose a token-based generator with Transformers for image synthesis. We present a new perspective by viewing this task as visual token generation, controlled by style tokens. |
 | Yanhong Zeng, Hongyang Chao, Jianlong Fu ECCV, 2020 project page / arXiv / video 1 / more results / code  We propose STTN, the first transformer-based model for high-quality image inpainting, setting a new state-of-the-art performance. |
 | Yanhong Zeng, Hongyang Chao, Jianlong Fu, Baining Guo CVPR, 2019 project page / arXiv / video / code  We propose PEN-Net, the first work that is able to conduct both semantic and texture inpainting. To achieve this, we propose cross-layer attention transfer and pyramid filling strategy. |
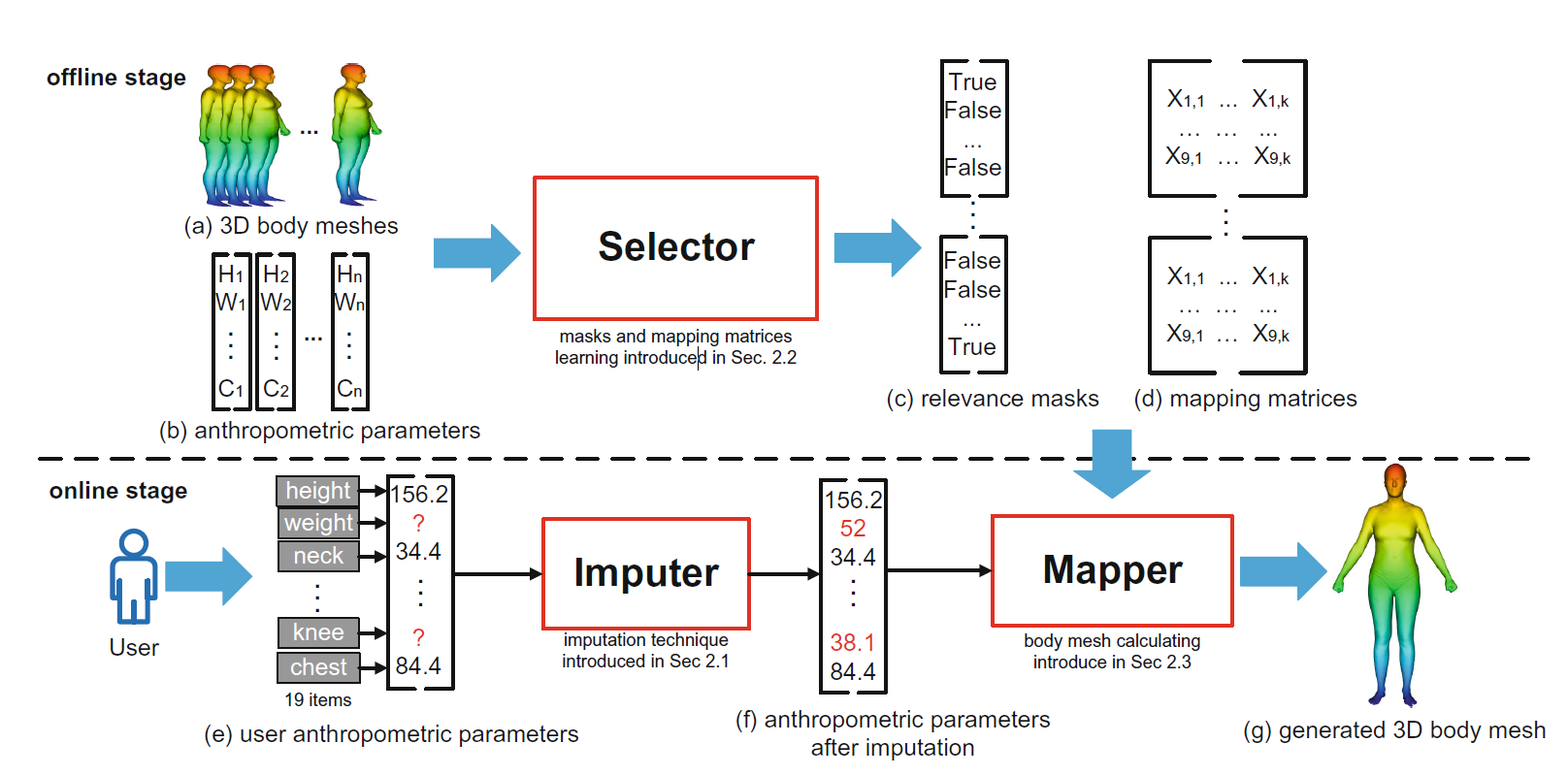 | Yanhong Zeng, Hongyang Chao, Jianlong Fu ICIMCS, 2017 project page / arXiv / video / code  We design a 3D human body reshaping system. It can take as input user's anthropometric measurements (e.g., height and weight) and generate a 3D human shape for the user. |
Working Experience |
 | Ant Group Researcher, 2025.04 ~ present |
 | Shanghai AI Laboratory Researcher, 2022.07 ~ 2025.03 |
 | Microsoft Research Asia (MSRA) Research Intern, 2018.06 ~ 2021.12 Research Intern, 2016.06 ~ 2017.06 |
Projects |
 | MagicMaker Project Owner, 2023.04 ~ 2024.09 MagicMaker is a user-friendly AI platform that enables seamless image generation, editing, and animation. It empowers users to transform their imagination into captivating cinema and animations with ease. |
 | OpenMMLab/MMagic  Lead Core Maintainer, 2022.07 ~ 2023.08 OpenMMLab Multimodal Advanced, Generative, and Intelligent Creation Toolbox. Unlock the magic 🪄: Generative-AI (AIGC), easy-to-use APIs, awesome model zoo, diffusion models, for text-to-image generation, image/video restoration/enhancement, etc. |
Miscellanea |