жё©йҰЁжҸҗзӨәГ—
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•Г—
зҷ»еҪ•жіЁеҶҢГ—
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
з”ЁжҲ·зҷ»еҪ•Г—
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
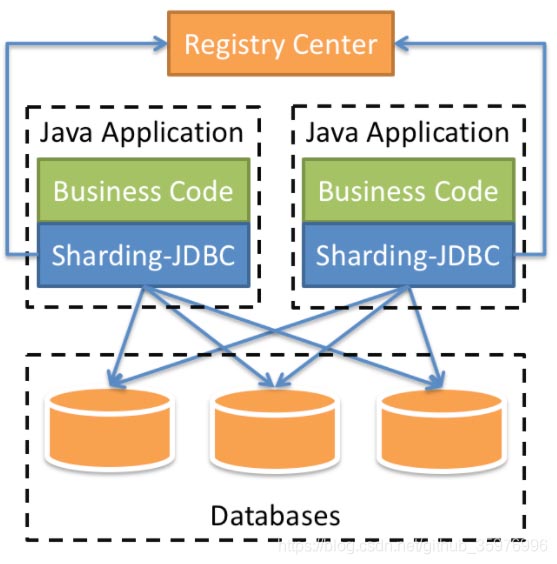
еҰӮдҪ•дҪҝз”ЁSharding-JDBCеҜ№ж•°жҚ®иҝӣиЎҢеҲҶзүҮеӨ„зҗҶпјҢеҫҲеӨҡж–°жүӢеҜ№жӯӨдёҚжҳҜеҫҲжё…жҘҡпјҢдёәдәҶеё®еҠ©еӨ§е®¶и§ЈеҶіиҝҷдёӘйҡҫйўҳпјҢдёӢйқўе°Ҹзј–е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§ЈпјҢжңүиҝҷж–№йқўйңҖжұӮзҡ„дәәеҸҜд»ҘжқҘеӯҰд№ дёӢпјҢеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
Sharding-JDBCжҳҜShardingSphereзҡ„第дёҖдёӘдә§е“ҒпјҢд№ҹжҳҜShardingSphereзҡ„еүҚиә«гҖӮ
е®ғе®ҡдҪҚдёәиҪ»йҮҸзә§JavaжЎҶжһ¶пјҢеңЁJavaзҡ„JDBCеұӮжҸҗдҫӣзҡ„йўқеӨ–жңҚеҠЎгҖӮе®ғдҪҝз”Ёе®ўжҲ·з«Ҝзӣҙиҝһж•°жҚ®еә“пјҢд»ҘjarеҢ…еҪўејҸжҸҗдҫӣжңҚеҠЎпјҢж— йңҖйўқеӨ–йғЁзҪІе’Ңдҫқиө–пјҢеҸҜзҗҶи§ЈдёәеўһејәзүҲзҡ„JDBCй©ұеҠЁпјҢе®Ңе…Ёе…је®№JDBCе’Ңеҗ„з§ҚORMжЎҶжһ¶гҖӮ
йҖӮз”ЁдәҺд»»дҪ•еҹәдәҺJavaзҡ„ORMжЎҶжһ¶пјҢеҰӮпјҡJPA, Hibernate, Mybatis, Spring JDBC TemplateжҲ–зӣҙжҺҘдҪҝз”ЁJDBCгҖӮ
еҹәдәҺд»»дҪ•з¬¬дёүж–№зҡ„ж•°жҚ®еә“иҝһжҺҘжұ пјҢеҰӮпјҡDBCP, C3P0, BoneCP, Druid, HikariCPзӯүж”ҜжҢҒд»»ж„Ҹе®һзҺ°JDBC规иҢғзҡ„ж•°жҚ®еә“гҖӮ
зӣ®еүҚж”ҜжҢҒMySQLпјҢOracleпјҢSQLServerе’ҢPostgreSQLгҖӮ
Sharding-JDBCзҡ„дҪҝз”ЁйңҖиҰҒжҲ‘们еҜ№йЎ№зӣ®иҝӣиЎҢдёҖдәӣи°ғж•ҙпјҡз»“жһ„еҰӮдёӢ
ShardingSphereж–ҮжЎЈең°еқҖ
иҝҷйҮҢдҪҝз”Ёзҡ„жҳҜspringBootйЎ№зӣ®ж”№йҖ
<!-- иҝҷйҮҢдҪҝз”ЁдәҶdruidиҝһжҺҘжұ --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.9</version> </dependency> <!-- sharding-jdbc еҢ… --> <dependency> <groupId>com.dangdang</groupId> <artifactId>sharding-jdbc-core</artifactId> <version>1.5.4</version> </dependency> <!-- иҝҷйҮҢдҪҝз”ЁдәҶйӣӘиҠұз®—жі•з”ҹжҲҗз»„е»әпјҢиҝҷдёӘз®—жі•зҡ„е®һзҺ°зҡ„иҮӘе·ұеҶҷзҡ„д»Јз ҒпјҢеҗ„дҪҚе®ўе…іиҖҒзҲ·еҸҜд»Ҙдҝ®ж”№дёәиҮӘе·ұзҡ„idз”ҹжҲҗзӯ–з•Ҙ --> <dependency> <groupId>org.kcsm.common</groupId> <artifactId>kcsm-idgenerator</artifactId> <version>3.0.1</version> </dependency>
#еҗҜеҠЁжҺҘеҸЈ server: port: 30009 spring: jpa: database: mysql show-sql: true hibernate: # дҝ®ж”№дёҚиҮӘеҠЁжӣҙж–°иЎЁ ddl-auto: none #ж•°жҚ®жәҗ0е®ҡд№үпјҢиҝҷйҮҢеҸӘжҳҜз”ЁдәҶдёҖдёӘж•°жҚ®жәҗпјҢеҗ„дҪҚе®ўе®ҳеҸҜд»Ҙж №жҚ®иҮӘе·ұзҡ„йңҖжұӮе®ҡд№үеӨҡдёӘж•°жҚ®жәҗ database0: databaseName: database0 url: jdbc:mysql://kcsm-pre.mysql.rds.aliyuncs.com:3306/dstest?characterEncoding=utf8&useUnicode=true&useSSL=false&serverTimezone=Hongkong username: root password: kcsm@111 driverClassName: com.mysql.jdbc.Driver
package com.lzx.code.codedemo.config; import com.alibaba.druid.pool.DruidDataSource; import lombok.Data; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.stereotype.Component; import javax.sql.DataSource; /** * жҸҸиҝ°:ж•°жҚ®жәҗ0е®ҡд№ү * * @Auther: lzx * @Date: 2019/9/9 15:19 */ @Data @ConfigurationProperties(prefix = "database0") @Component public class Database0Config { private String url; private String username; private String password; private String driverClassName; private String databaseName; public DataSource createDataSource() { DruidDataSource result = new DruidDataSource(); result.setDriverClassName(getDriverClassName()); result.setUrl(getUrl()); result.setUsername(getUsername()); result.setPassword(getPassword()); return result; } }package com.lzx.code.codedemo.config; import com.dangdang.ddframe.rdb.sharding.api.ShardingValue; import com.dangdang.ddframe.rdb.sharding.api.strategy.database.SingleKeyDatabaseShardingAlgorithm; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Component; import java.util.ArrayList; import java.util.Collection; import java.util.List; /** * жҸҸиҝ°:ж•°жҚ®жәҗеҲҶй…Қз®—жі• * * иҝҷйҮҢжҲ‘们еҸӘз”ЁдәҶдёҖдёӘж•°жҚ®жәҗпјҢжүҖд»ҘжүҖжңүзҡ„йғҪеҸӘиҝ”еӣһдәҶж•°жҚ®жәҗ0 * * @Auther: lzx * @Date: 2019/9/9 15:27 */ @Component public class DatabaseShardingAlgorithm implements SingleKeyDatabaseShardingAlgorithm { @Autowired private Database0Config database0Config; /** * = жқЎд»¶ж—¶еҖҷиҝ”еӣһзҡ„ж•°жҚ®жәҗ * @param collection * @param shardingValue * @return */ @Override public String doEqualSharding(Collection collection, ShardingValue shardingValue) { return database0Config.getDatabaseName(); } /** * IN жқЎд»¶иҝ”еӣһзҡ„ж•°жҚ®жәҗ * @param collection * @param shardingValue * @return */ @Override public Collection<String> doInSharding(Collection collection, ShardingValue shardingValue) { List<String> result = new ArrayList<String>(); result.add(database0Config.getDatabaseName()); return result; } /** * BETWEEN жқЎд»¶ж”ҫеӣһзҡ„ж•°жҚ®жәҗ * @param collection * @param shardingValue * @return */ @Override public Collection<String> doBetweenSharding(Collection collection, ShardingValue shardingValue) { List<String> result = new ArrayList<String>(); result.add(database0Config.getDatabaseName()); return result; } }package com.lzx.code.codedemo.config; import com.dangdang.ddframe.rdb.sharding.api.ShardingValue; import com.dangdang.ddframe.rdb.sharding.api.strategy.table.SingleKeyTableShardingAlgorithm; import com.google.common.collect.Range; import org.springframework.stereotype.Component; import java.util.Collection; import java.util.LinkedHashSet; /** * жҸҸиҝ°: ж•°жҚ®иЎЁеҲҶй…Қз®—жі•зҡ„е®һзҺ° * * @Auther: lzx * @Date: 2019/9/9 16:19 */ @Component public class TableShardingAlgorithm implements SingleKeyTableShardingAlgorithm<Long> { /** * = жқЎд»¶ж—¶еҖҷиҝ”еӣһзҡ„ж•°жҚ®жәҗ * @param collection * @param shardingValue * @return */ @Override public String doEqualSharding(Collection<String> collection, ShardingValue<Long> shardingValue) { for (String eaach:collection) { Long value = shardingValue.getValue(); value = value >> 22; if(eaach.endsWith(value%10+"")){ return eaach; } } throw new IllegalArgumentException(); } /** * IN жқЎд»¶иҝ”еӣһзҡ„ж•°жҚ®жәҗ * @param tableNames * @param shardingValue * @return */ @Override public Collection<String> doInSharding(Collection<String> tableNames, ShardingValue<Long> shardingValue) { Collection<String> result = new LinkedHashSet<>(tableNames.size()); for (Long value : shardingValue.getValues()) { for (String tableName : tableNames) { value = value >> 22; if (tableName.endsWith(value % 10 + "")) { result.add(tableName); } } } return result; } /** * BETWEEN жқЎд»¶ж”ҫеӣһзҡ„ж•°жҚ®жәҗ * @param tableNames * @param shardingValue * @return */ @Override public Collection<String> doBetweenSharding(Collection<String> tableNames, ShardingValue<Long> shardingValue) { Collection<String> result = new LinkedHashSet<>(tableNames.size()); Range<Long> range = shardingValue.getValueRange(); for (Long i = range.lowerEndpoint(); i <= range.upperEndpoint(); i++) { for (String each : tableNames) { Long value = i >> 22; if (each.endsWith(i % 10 + "")) { result.add(each); } } } return result; } }package com.lzx.code.codedemo.config; import com.dangdang.ddframe.rdb.sharding.api.ShardingDataSourceFactory; import com.dangdang.ddframe.rdb.sharding.api.rule.DataSourceRule; import com.dangdang.ddframe.rdb.sharding.api.rule.ShardingRule; import com.dangdang.ddframe.rdb.sharding.api.rule.TableRule; import com.dangdang.ddframe.rdb.sharding.api.strategy.database.DatabaseShardingStrategy; import com.dangdang.ddframe.rdb.sharding.api.strategy.table.TableShardingStrategy; import com.dangdang.ddframe.rdb.sharding.keygen.DefaultKeyGenerator; import com.dangdang.ddframe.rdb.sharding.keygen.KeyGenerator; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import javax.sql.DataSource; import java.sql.SQLException; import java.util.Arrays; import java.util.HashMap; import java.util.Map; /** * жҸҸиҝ°:ж•°жҚ®жәҗй…ҚзҪ® * * @Auther: lzx * @Date: 2019/9/9 15:21 */ @Configuration public class DataSourceConfig { @Autowired private Database0Config database0Config; @Autowired private DatabaseShardingAlgorithm databaseShardingAlgorithm; @Autowired private TableShardingAlgorithm tableShardingAlgorithm; @Bean public DataSource getDataSource() throws SQLException { return buildDataSource(); } private DataSource buildDataSource() throws SQLException { //еҲҶеә“и®ҫзҪ® Map<String, DataSource> dataSourceMap = new HashMap<>(2); //ж·»еҠ дёӨдёӘж•°жҚ®еә“database0е’Ңdatabase1 dataSourceMap.put(database0Config.getDatabaseName(), database0Config.createDataSource()); //и®ҫзҪ®й»ҳи®Өж•°жҚ®еә“ DataSourceRule dataSourceRule = new DataSourceRule(dataSourceMap, database0Config.getDatabaseName()); //еҲҶиЎЁи®ҫзҪ®пјҢеӨ§иҮҙжҖқжғіе°ұжҳҜе°ҶжҹҘиҜўиҷҡжӢҹиЎЁGoodsж №жҚ®дёҖе®ҡ规еҲҷжҳ е°„еҲ°зңҹе®һиЎЁдёӯеҺ» TableRule orderTableRule = TableRule.builder("user") .actualTables(Arrays.asList("user_0", "user_1", "user_2", "user_3", "user_4", "user_5", "user_6", "user_7", "user_8", "user_9")) .dataSourceRule(dataSourceRule) .build(); //еҲҶеә“еҲҶиЎЁзӯ–з•Ҙ ShardingRule shardingRule = ShardingRule.builder() .dataSourceRule(dataSourceRule) .tableRules(Arrays.asList(orderTableRule)) .databaseShardingStrategy(new DatabaseShardingStrategy("ID", databaseShardingAlgorithm)) .tableShardingStrategy(new TableShardingStrategy("ID", tableShardingAlgorithm)).build(); DataSource dataSource = ShardingDataSourceFactory.createDataSource(shardingRule); return dataSource; } @Bean public KeyGenerator keyGenerator() { return new DefaultKeyGenerator(); } }package com.lzx.code.codedemo.entity; import com.fasterxml.jackson.annotation.JsonIgnoreProperties; import com.fasterxml.jackson.databind.annotation.JsonSerialize; import com.fasterxml.jackson.databind.ser.std.ToStringSerializer; import lombok.*; import org.hibernate.annotations.GenericGenerator; import javax.persistence.*; /** * жҸҸиҝ°: з”ЁжҲ· * * @Auther: lzx * @Date: 2019/7/11 15:39 */ @Entity(name = "USER") @Getter @Setter @ToString @JsonIgnoreProperties(ignoreUnknown = true) @AllArgsConstructor @NoArgsConstructor public class User { /** * дё»й”® */ @Id @GeneratedValue(generator = "idUserConfig") @GenericGenerator(name ="idUserConfig" ,strategy="org.kcsm.common.ids.SerialIdGeneratorSnowflakeId") @Column(name = "ID", unique = true,nullable=false) @JsonSerialize(using = ToStringSerializer.class) private Long id; /** * з”ЁжҲ·еҗҚ */ @Column(name = "USER_NAME",length = 100) private String userName; /** * еҜҶз Ғ */ @Column(name = "PASSWORD",length = 100) private String password; }package com.lzx.code.codedemo.dao; import com.lzx.code.codedemo.entity.User; import org.springframework.data.jpa.repository.JpaRepository; import org.springframework.data.jpa.repository.JpaSpecificationExecutor; import org.springframework.data.rest.core.annotation.RepositoryRestResource; /** * жҸҸиҝ°: з”ЁжҲ·daoжҺҘеҸЈ * * @Auther: lzx * @Date: 2019/7/11 15:52 */ @RepositoryRestResource(path = "user") public interface UserDao extends JpaRepository<User,Long>,JpaSpecificationExecutor<User> { }package com.lzx.code.codedemo; import com.lzx.code.codedemo.dao.RolesDao; import com.lzx.code.codedemo.dao.UserDao; import com.lzx.code.codedemo.entity.Roles; import com.lzx.code.codedemo.entity.User; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; @RunWith(SpringRunner.class) @SpringBootTest public class CodeDemoApplicationTests { @Autowired private UserDao userDao; @Autowired private RolesDao rolesDao; @Test public void contextLoads() { User user = null; Roles roles = null; for(int i=0;i<1000;i++){ user = new User( null, "lzx"+i, "123456" ); roles = new Roles( null, "и§’иүІ"+i ); rolesDao.save(roles); userDao.save(user); try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } } } }
зңӢе®ҢдёҠиҝ°еҶ…е®№жҳҜеҗҰеҜ№жӮЁжңүеё®еҠ©е‘ўпјҹеҰӮжһңиҝҳжғіеҜ№зӣёе…ізҹҘиҜҶжңүиҝӣдёҖжӯҘзҡ„дәҶи§ЈжҲ–йҳ…иҜ»жӣҙеӨҡзӣёе…іж–Үз« пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўжӮЁеҜ№дәҝйҖҹдә‘зҡ„ж”ҜжҢҒгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ

дәҝйҖҹдә‘е…¬дј—еҸ·

жүӢжңәзҪ‘з«ҷдәҢз»ҙз Ғ



