本篇内容主要讲解“Java读取PDF中的表格的方法是什么”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Java读取PDF中的表格的方法是什么”吧!
一、概述
二、环境配置
1. 手动导入
2. Maven仓库下载导入
三、读取PDF中的表格
本文以Java示例展示读取PDF中的表格的方法。这里导入Spire.PDF for Javah中的jar包,并使用其提供的相关及方法来实现获取表格中的文本内容。下表中整理了本次代码使用到的主要类、方法及解释,供参考:
| 类型 | 描述 |
| PdfDocument Class | Represents a pdf document model. |
| PdfDocument. loadFromFile (string filename) Method | Loads a PDF document. |
| PdfTableExtractor Class | Represents the PDF table extractor. |
| PdfTable Class | Defines a PDF table. |
| PdfTableExtractor. extractTable (int pageIndex) Method | Extracts table from page. |
| PdfTable.getText(int rowIndex,int columnIndex) Method | Gets Text in cell. |
| FileWriter. write() Method | Saves extracted text in table to a .txt file. |
IntelliJ IDEA 2018(JDK 1.8.0)
PDF 测试文档
PDF Jar包:Spire.PDF for Java Version: 4.10.2
Jar包的两种导入方法:
将jar包下载到本地,解压。然后执行如下步骤来手动导入:
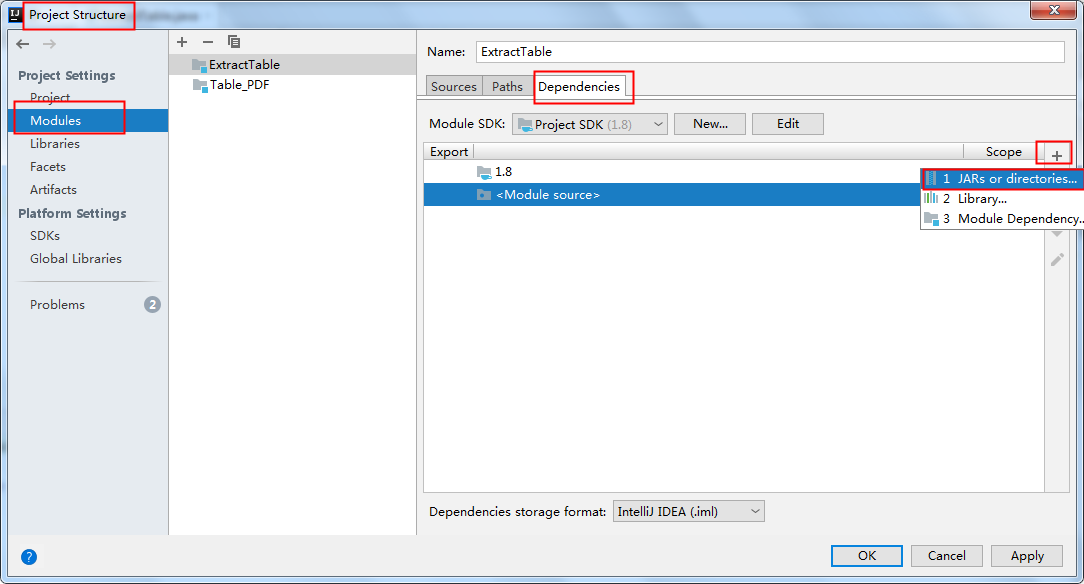
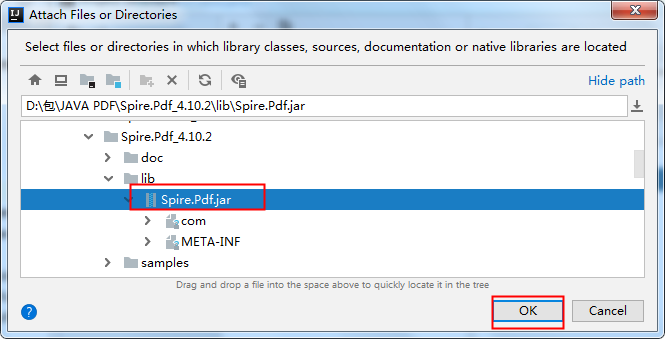
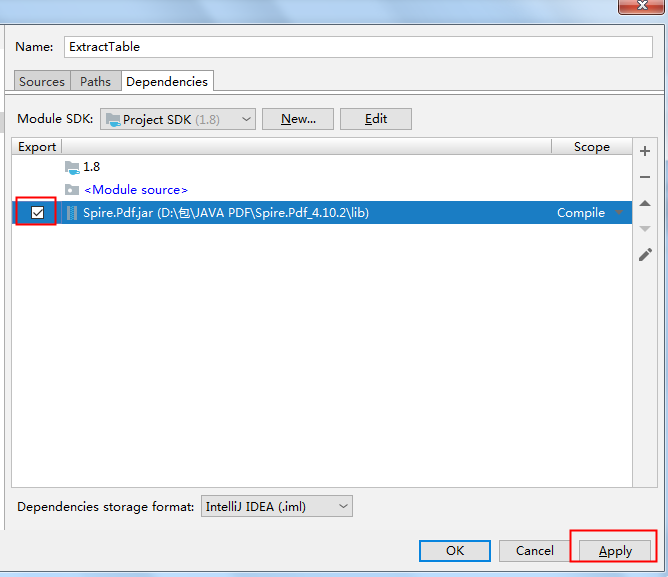
如果使用maven,需在pom.xml中配置maven路径,指定依赖,如下:
<repositories> <repository> <id>com.e-iceblue</id> <url>https://repo.e-iceblue.cn/repository/maven-public/</url> </repository> </repositories> <dependencies> <dependency> <groupId>e-iceblue</groupId> <artifactId>spire.pdf</artifactId> <version>4.10.2</version> </dependency> </dependencies>
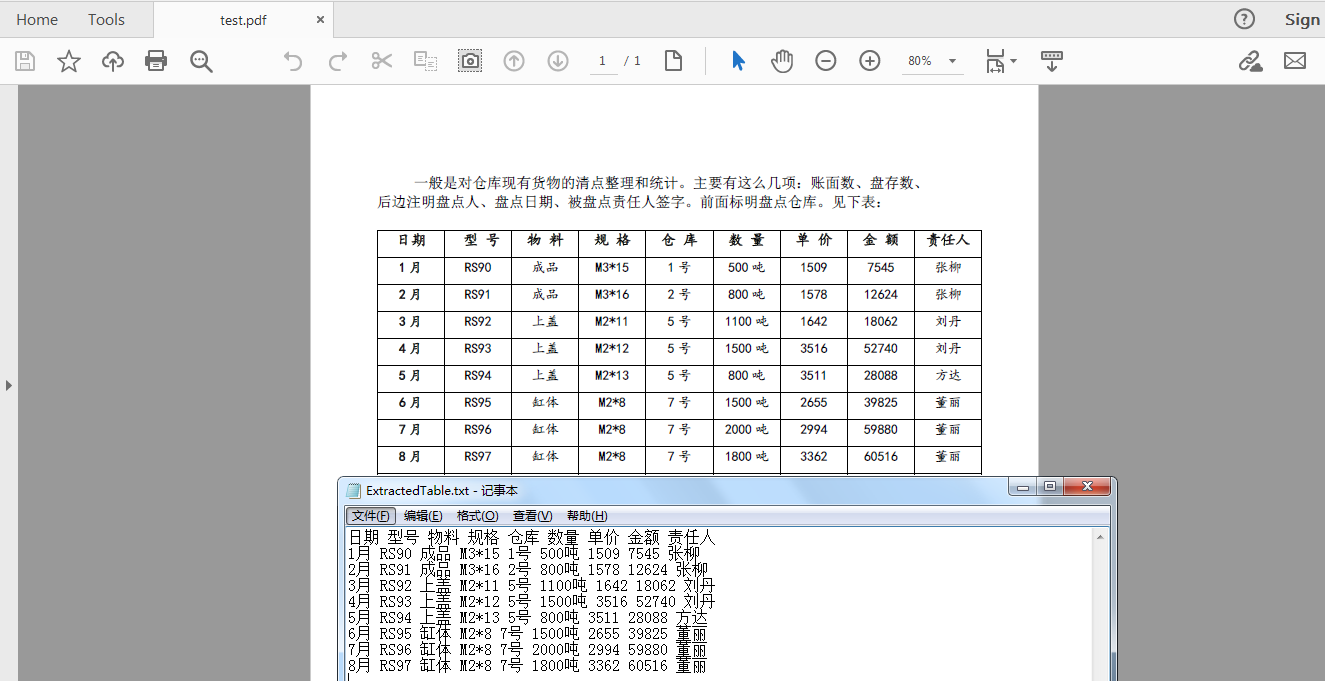
import com.spire.pdf.*; import com.spire.pdf.utilities.PdfTable; import com.spire.pdf.utilities.PdfTableExtractor; import java.io.FileWriter; import java.io.IOException; public class ExtractTable { public static void main(String[] args)throws IOException { //加载PDF文档 PdfDocument pdf = new PdfDocument(); pdf.loadFromFile("test.pdf"); //创建StringBuilder类的实例 StringBuilder builder = new StringBuilder(); //抽取表格 PdfTableExtractor extractor = new PdfTableExtractor(pdf); PdfTable[] tableLists ; for (int page = 0; page < pdf.getPages().getCount(); page++) { tableLists = extractor.extractTable(page); if (tableLists != null && tableLists.length > 0) { for (PdfTable table : tableLists) { int row = table.getRowCount(); int column = table.getColumnCount(); for (int i = 0; i < row; i++) { for (int j = 0; j < column; j++) { String text = table.getText(i, j); builder.append(text+" "); } builder.append("\r\n"); } } } } //将提取的表格内容写入txt文档 FileWriter fileWriter = new FileWriter("ExtractedTable.txt"); fileWriter.write(builder.toString()); fileWriter.flush(); fileWriter.close(); } }表格内容读取结果:
注意事项:
1. 注意使用的PDF Jar包版本为4.10.2,低于此版本的jar包不支持读取表格;
2. 代码中的文件路径为 F:\IDEAProject\Table_PDF\test.pdf 和 F:\IDEAProject\Table_PDF\ExtractedTable.txt , 文件路径可自定义为其他路径。
到此,相信大家对“Java读取PDF中的表格的方法是什么”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





