檩鶮жПРз§Ї√Ч
жВ®е•љпЉМзЩїељХеРОжЙНиГљдЄЛиЃҐеНХеУ¶пЉБ
еѓЖз†БзЩїељХ√Ч
зЩїељХж≥®еЖМ√Ч
зВєеЗї зЩїељХж≥®еЖМ еН≥и°®з§ЇеРМжДПгАКдЇњйАЯдЇСзФ®жИЈжЬНеК°жЭ°жђЊгАЛ
зФ®жИЈзЩїељХ√Ч
жВ®е•љпЉМзЩїељХеРОжЙНиГљдЄЛиЃҐеНХеУ¶пЉБ
жЬђзѓЗеЖЕеЃєдїЛзїНдЇЖвАЬPythonзЉЦиѓСзїУжЮЬдєЛе¶ВдљХзРЖиІ£codeеѓєи±°дЄОpycжЦЗдїґвАЭзЪДжЬЙеЕ≥зЯ•иѓЖпЉМеЬ®еЃЮйЩЕж°ИдЊЛзЪДжУНдљЬињЗз®ЛдЄ≠пЉМдЄНе∞СдЇЇйГљдЉЪйБЗеИ∞ињЩж†ЈзЪДеЫ∞еҐГпЉМжО•дЄЛжЭ•е∞±иЃ©е∞ПзЉЦеЄ¶йҐЖе§ІеЃґе≠¶дє†дЄАдЄЛе¶ВдљХе§ДзРЖињЩдЇЫжГЕеЖµеРІпЉБеЄМжЬЫе§ІеЃґдїФзїЖйШЕиѓїпЉМиГље§Яе≠¶жЬЙжЙАжИРпЉБ
дЄОjavaз±їдЉЉпЉМPythonе∞Ж.pyзЉЦиѓСдЄЇе≠ЧиКВз†БпЉМзДґеРОйАЪињЗиЩЪжЛЯжЬЇжЙІи°МгАВзЉЦиѓСињЗз®ЛдЄОиЩЪжЛЯжЬЇжЙІи°МињЗз®ЛеЭЗеЬ®python25.dllдЄ≠гАВPythonиЩЪжЛЯжЬЇжѓФjavaжЫіжКљи±°пЉМз¶їеЇХе±ВжЫіињЬгАВ
зЉЦиѓСињЗз®ЛдЄНдїЕзФЯжИРе≠ЧиКВз†БпЉМињШи¶БеМЕеРЂеЄЄйЗПгАБеПШйЗПгАБеН†зФ®ж†ИзЪДз©ЇйЧіз≠ЙпЉМPytonдЄ≠зЉЦиѓСињЗз®ЛзФЯжИРcodeеѓєи±°PyCodeObjectгАВе∞ЖPyCodeObjectеЖЩеЕ•дЇМињЫеИґжЦЗдїґпЉМеН≥.pycгАВ

жЬЙењЕи¶БеИЩеЖЩеЕ•A.pycжМЗзЪДжШѓиѓ•.pyжШѓеР¶еП™ињРи°МдЄАжђ°пЉМе¶ВжЮЬimportзЪДж®°еЭЧпЉМиВѓеЃЪдЉЪзФЯжИР.pycгАВ
PythonиІ£йЗКеЩ®е∞Ж.pyз®ЛеЇПзЉЦиѓСдЄЇPyCodeObjectеѓєи±°пЉМеЕЈдљУињЗз®ЛдЄОзЉЦиѓСеОЯзРЖз±їдЉЉгАВ
typedef struct { PyObject_HEAD int co_argcount; // Code BlockзЪДеПВжХ∞зЪДдЄ™жХ∞пЉМжѓФе¶ВиѓідЄАдЄ™еЗљжХ∞зЪДеПВжХ∞ int co_nlocals; // Code BlockдЄ≠е±АйГ®еПШйЗПзЪДдЄ™жХ∞ int co_stacksize; // жЙІи°Миѓ•жЃµCode BlockйЬАи¶БзЪДж†Из©ЇйЧі int co_flags; // N/A PyObject *co_code; // Code BlockзЉЦиѓСжЙАеЊЧзЪДbyte codeпЉМдї•PyStringObjectзЪД嚥еЉПе≠ШеЬ® PyObject *co_consts; // PyTupleObjectеѓєи±°пЉМдњЭе≠ШCode BlockдЄ≠зЪДеЄЄйЗП PyObject *co_names; // PyTupleObjectеѓєи±°пЉМдњЭе≠ШCode BlockдЄ≠зЪДжЙАжЬЙзђ¶еПЈ PyObject *co_varnames; // Code BlockдЄ≠е±АйГ®еПШйЗПеРНйЫЖеРИ PyObject *co_freevars; // еЃЮзО∞йЧ≠еМЕжЙАйЬАдЄЬи•њ PyObject *co_cellvars; // Code BlockеЖЕйГ®еµМе•ЧеЗљжХ∞жЙАеЉХзФ®зЪДе±АйГ®еПШйЗПеРНйЫЖеРИ PyObject *co_filename; // Code BlockжЙАеѓєеЇФзЪД.pyжЦЗдїґзЪДеЃМжХіиЈѓеЊД PyObject *co_name; // Code BlockзЪДеРНе≠ЧпЉМйАЪеЄЄжШѓеЗљжХ∞еРНжИЦз±їеРН int co_firstlineno; // Code BlockеЬ®еѓєеЇФзЪД.pyжЦЗдїґдЄ≠зЪДиµЈеІЛи°М PyObject *co_lnotab; // byte codeдЄО.pyжЦЗдїґдЄ≠source codeи°МеПЈзЪДеѓєеЇФеЕ≥з≥їпЉМдї•PyStringObjectзЪД嚥еЉПе≠ШеЬ® void *co_zombieframe; PyObject *co_weakreflist; } PyCodeObject;дЄАдЄ™Code BlockзФЯжИРдЄАдЄ™PyCodeObjectпЉМињЫеЕ•дЄАдЄ™еРНе≠Чз©ЇйЧіжИРдЄЇињЫеЕ•дЄАдЄ™Code BlockгАВе¶ВдЄЛ.pyжЦЗдїґзЉЦиѓСеЃМжИРеРОдЉЪзФЯжИРдЄЙдЄ™PyCodeObjectпЉМдЄАдЄ™еѓєеЇФжХідЄ™.pyжЦЗдїґдЄАдЄ™еѓєеЇФClass AпЉМдЄАдЄ™еѓєеЇФdef FunгАВеЃЮйЩЕињЩдЄЙдЄ™codeеѓєи±°жШѓеµМе•ЧзЪДпЉМеРОдЄ§дЄ™codeеѓєи±°дљНдЇОзђђдЄАдЄ™codeеѓєи±°зЪДco_constsе±ЮжАІдЄ≠гАВеЕґеЃЮпЉМе≠ЧиКВз†БдљНдЇОco_codeдЄ≠гАВ
class A: pass def Fun(): pass a = A() Fun()
pycжЦЗдїґеМЕжЛђдЄЙйГ®еИЖпЉЪ
пЉИ1пЉЙеЫЫе≠ЧиКВзЪДMagic intпЉМи°®з§ЇpycзЙИжЬђдњ°жБѓ
пЉИ2пЉЙеЫЫе≠ЧиКВзЪДintпЉМжШѓpycдЇІзФЯжЧґйЧіпЉМиЛ•дЄОpyжЦЗдїґжЧґйЧідЄНеРМдЉЪйЗНжЦ∞зФЯжИР
пЉИ3пЉЙеЇПеИЧеМЦдЇЖзЪДPyCodeObjectеѓєи±°гАВ
еЖЩеЕ•pycжЦЗдїґзЪДеЗљжХ∞еМЕжЛђдї•дЄЛеЗ†дЄ™ж≠•й™§пЉЪ
PyMarshal_WriteLongToFile(pyc_magic, fp, Py_MARSHAL_VERSION); // еЖЩеЕ•зЙИжЬђдњ°жБѓ PyMarshal_WriteLongToFile(0L, fp, Py_MARSHAL_VERSION); // еЖЩеЕ•жЧґйЧідњ°жБѓ PyMarshal_WriteObjectToFile((PyObject *)co, fp, Py_MARSHAL_VERSION); // еЖЩеЕ•PyCodeObjectеѓєи±°
еЕ≥йФЃеЬ®дЇОcodeеѓєи±°зЪДеЖЩеЕ•пЉЪ
{ WFILE wf; wf.fp = fp; вА¶вА¶ w_object(x, &wf); }зФ®еИ∞дЇЖдЄАдЄ™WFILEзїУжЮДдљУпЉМеПѓдї•иЃ§дЄЇжШѓеѓєFILE *fp зЪДдЄАдЄ™е∞Би£ЕпЉЪ
typedef struct { FILE *fp; int error; int depth; PyObject *strings; // е≠ШеВ®е≠Чзђ¶дЄ≤пЉМеЖЩеЕ•жЧґдї•dict嚥еЉПпЉМиѓїеЗЇжЧґдї•list嚥еЉП } WFILE;еЕ≥йФЃеЬ®дЇОw_object()еЗљжХ∞пЉЪ
static void w_object(PyObject *v, WFILE *p){ if (v == NULL) вА¶вА¶ else if (PyInt_CheckExact(v)) вА¶вА¶ else if (PyFloat_CheckExact(v)) вА¶вА¶ else if (PyString_CheckExact(v)) вА¶вА¶ else if (PyList_CheckExact(v)) вА¶вА¶ }w_codeеЃЮиі®дЄЇж†єжНЃдЄНеРМзЪДеѓєи±°з±їеЮЛйАЙеПЦдЄНеРМзЪДз≠ЦзХ•пЉМдЊЛе¶Вtupleеѓєи±°пЉЪ
else if (PyTuple_CheckExact(v)) { w_byte(TYPE_TUPLE, p); n = PyTuple_Size(v); W_SIZE(n, p); for (i = 0; i < n; i++) w_object(PyTuple_GET_ITEM(v, i), p);иАМжЙАжЬЙз±їеЮЛжЬАзїИеПѓеИЖиІ£дЄЇеЖЩеЕ•жХ∞еАЉдЄОеЖЩеЕ•е≠Чзђ¶дЄ≤дЄ§зІНжУНдљЬпЉМжґЙеПКдї•дЄЛеЗ†йГ®еИЖпЉЪ
#define w_byte(c, p) putc((c), (p)->fp) // зФ®дЇОеЖЩеЕ•з±їеЮЛ static void w_long(long x, WFILE *p){ // зФ®дЇОеЖЩеЕ•жХ∞е≠Ч w_byte((char)( x & 0xff), p); // еЃЮиі®дЄЇзФ®еЫЫдЄ™е≠ЧиКВе≠ШеВ®дЄАдЄ™жХ∞е≠Ч w_byte((char)((x>> 8) & 0xff), p); w_byte((char)((x>>16) & 0xff), p); w_byte((char)((x>>24) & 0xff), p); } static void w_string(char *s, int n, WFILE *p){ //зФ®дЇОеЖЩеЕ•е≠Чзђ¶дЄ≤ fwrite(s, 1, n, p->fp); }зФ±дЇОеЇПеИЧеМЦеЖЩеЕ•жЦЗдїґеРО䪥姱дЇЖзїУжЮДдњ°жБѓпЉМжХЕеЖЩеЕ•жѓПдЄ™еѓєи±°жЧґеЖЩеЕ•з±їеЮЛдњ°жБѓw_byteпЉЪ
#define TYPE_INT 'i' #define TYPE_LIST '[' #define TYPE_DICT '{' #define TYPE_CODE 'c'зФ±дЇОPythonзЪЖеѓєи±°пЉМw_object(PyObject*)дЊњеПѓйТИеѓєдЄНеРМз±їеЮЛйАЙеПЦдЄНеРМеЖЩеЕ•жЦєж≥ХпЉМдЄНжЦ≠зїЖеИЖпЉМжЬАзїИеИЖиІ£дЄЇPyInt_ObjectжИЦPyString_ObjectпЉМеИ©зФ®w_longжИЦw_stringеЖЩеЕ•гАВ
жХ∞е≠ЧжѓФиЊГзЃАеНХпЉЪ
else if (PyInt_CheckExact(v)) { w_byte(TYPE_INT, p); w_long(x, p); }е≠Чзђ¶дЄ≤еИЩжѓФиЊГе§НжЭВпЉЪ
else if (PyString_CheckExact(v)) { if (p->strings && PyString_CHECK_INTERNED(v)) { PyObject *o = PyDict_GetItem(p->strings, v); // иОЈеПЦеЬ®stringsдЄ≠зЪДеЇПеПЈ if (o) { // interеѓєи±°зЪДйЭЮй¶Цжђ°еЖЩеЕ• long w = PyInt_AsLong(o); w_byte(TYPE_STRINGREF, p); w_long(w, p); goto exit; } else { // internеѓєи±°зЪДй¶Цжђ°еЖЩеЕ• int ok; ok = o && PyDict_SetItem(p->strings, v, o) >= 0; Py_XDECREF(o); w_byte(TYPE_INTERNED, p); } } else { // еЖЩеЕ•жЩЃйАЪstring w_byte(TYPE_STRING, p); } n = PyString_GET_SIZE(v); W_SIZE(n, p); w_string(PyString_AS_STRING(v), n, p); }пЉИ1пЉЙиЛ•еЖЩеЕ•жЩЃйАЪе≠Чзђ¶дЄ≤пЉМеЖЩеЕ•е≠Чзђ¶дЄ≤з±їеЮЛдњ°жБѓ"S"пЉМзДґеРОеЖЩеЕ•е≠Чзђ¶дЄ≤йХњеЇ¶еПКstringеАЉгАВ
пЉИ2пЉЙиЛ•еЖЩеЕ•interе≠Чзђ¶дЄ≤пЉМеЕИеИ∞WFILEзЪДstringsдЄ≠жЯ•жЙЊпЉЪ
пЉИaпЉЙиЛ•жЙЊеИ∞пЉМеИЩеЖЩеЕ•еЉХзФ®з±їеЮЛдњ°жБѓ"R"пЉМзДґеРОеЖЩеЕ•еЇПеПЈ
пЉИbпЉЙиЛ•жЬ™жЙЊеИ∞пЉМеИЫеїЇеѓєи±°жФЊеЕ•stringsпЉМеєґеЖЩеЕ•internз±їеЮЛдњ°жБѓ"t"пЉМзДґеРОеЖЩеЕ•е≠Чзђ¶дЄ≤йХњеЇ¶еПКstringеАЉгАВ
иЛ•дЊЭжђ°еЖЩеЕ•"efei"гАБ"snow"гАБ"efei"пЉМеИЩдЉЪе¶ВдЄЛпЉЪ
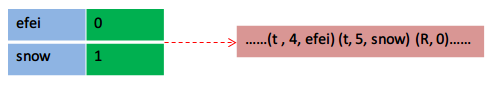
дїОpycжЦЗдїґиѓїеЕ•жЧґпЉМдЊЭйЭ†listпЉМйВ£дєИеЇПеПЈе∞±еПѓдї•еИ©зФ®дЄКдЇЖгАВ
вАЬPythonзЉЦиѓСзїУжЮЬдєЛе¶ВдљХзРЖиІ£codeеѓєи±°дЄОpycжЦЗдїґвАЭзЪДеЖЕеЃєе∞±дїЛзїНеИ∞ињЩйЗМдЇЖпЉМжДЯи∞Ґе§ІеЃґзЪДйШЕиѓїгАВе¶ВжЮЬжГ≥дЇЖиІ£жЫіе§Ъи°МдЄЪзЫЄеЕ≥зЪДзЯ•иѓЖеПѓдї•еЕ≥ж≥®дЇњйАЯдЇСзљСзЂЩпЉМе∞ПзЉЦе∞ЖдЄЇе§ІеЃґиЊУеЗЇжЫіе§ЪйЂШиі®йЗПзЪДеЃЮзФ®жЦЗзЂ†пЉБ
еЕНиі£е£∞жШОпЉЪжЬђзЂЩеПСеЄГзЪДеЖЕеЃєпЉИеЫЊзЙЗгАБиІЖйҐСеТМжЦЗе≠ЧпЉЙдї•еОЯеИЫгАБиљђиљљеТМеИЖдЇЂдЄЇдЄїпЉМжЦЗзЂ†иІВзВєдЄНдї£и°®жЬђзљСзЂЩзЂЛеЬЇпЉМе¶ВжЮЬжґЙеПКдЊµжЭГиѓЈиБФз≥їзЂЩйХњйВЃзЃ±пЉЪis@yisu.comињЫи°МдЄЊжК•пЉМеєґжПРдЊЫзЫЄеЕ≥иѓБжНЃпЉМдЄАзїПжЯ•еЃЮпЉМе∞ЖзЂЛеИїеИ†йЩ§жґЙеЂМдЊµжЭГеЖЕеЃєгАВ

дЇњйАЯдЇСеЕђдЉЧеПЈ

жЙЛжЬЇзљСзЂЩдЇМзїіз†Б



