檩鶮жПРз§Ї√Ч
жВ®е•љпЉМзЩїељХеРОжЙНиГљдЄЛиЃҐеНХеУ¶пЉБ
еѓЖз†БзЩїељХ√Ч
зЩїељХж≥®еЖМ√Ч
зВєеЗї зЩїељХж≥®еЖМ еН≥и°®з§ЇеРМжДПгАКдЇњйАЯдЇСзФ®жИЈжЬНеК°жЭ°жђЊгАЛ
зФ®жИЈзЩїељХ√Ч
жВ®е•љпЉМзЩїељХеРОжЙНиГљдЄЛиЃҐеНХеУ¶пЉБ
жЬђзѓЗжЦЗзЂ†дЄЇе§ІеЃґе±Хз§ЇдЇЖspringbootдЄ≠жАОдєИеЉХеЕ•druidжХ∞жНЃжЇРпЉМеЖЕеЃєзЃАжШОжЙЉи¶БеєґдЄФеЃєжШУзРЖиІ£пЉМзїЭеѓєиГљдљњдљ†зЬЉеЙНдЄАдЇЃпЉМйАЪињЗињЩзѓЗжЦЗзЂ†зЪДиѓ¶зїЖдїЛзїНеЄМжЬЫдљ†иГљжЬЙжЙАжФґиОЈгАВ
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.5</version> </dependency>
#жХ∞жНЃжЇРйЕНзљЃ spring.datasource.url=jdbc:mysql://192.168.0.131:3306/hongone?useAffectedRows=true&serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8 spring.datasource.username=root spring.datasource.password=123456 spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver #druidињЮжΕ汆 spring.datasource.type=com.alibaba.druid.pool.DruidDataSource # ињЮжΕ汆зЪДйЕНзљЃдњ°жБѓ # еИЭеІЛеМЦе§Іе∞ПпЉМжЬАе∞ПпЉМжЬАе§І spring.datasource.initialSize=5 spring.datasource.minIdle=5 spring.datasource.maxActive=20 # йЕНзљЃиОЈеПЦињЮжО•з≠ЙеЊЕиґЕжЧґзЪДжЧґйЧі spring.datasource.maxWait=30000 # йЕНзљЃйЧійЪФе§ЪдєЕжЙНињЫи°МдЄАжђ°ж£АжµЛпЉМж£АжµЛйЬАи¶БеЕ≥йЧ≠зЪДз©ЇйЧ≤ињЮжО•пЉМеНХдљНжШѓжѓЂзІТ spring.datasource.timeBetweenEvictionRunsMillis=60000 # йЕНзљЃдЄАдЄ™ињЮжО•еܮ汆дЄ≠жЬАе∞ПзФЯе≠ШзЪДжЧґйЧіпЉМеНХдљНжШѓжѓЂзІТ spring.datasource.minEvictableIdleTimeMillis=300000 spring.datasource.validationQuery=SELECT 1 FROM DUAL spring.datasource.testWhileIdle=true spring.datasource.testOnBorrow=false spring.datasource.testOnReturn=false # жЙУеЉАPSCacheпЉМеєґдЄФжМЗеЃЪжѓПдЄ™ињЮжО•дЄКPSCacheзЪДе§Іе∞П spring.datasource.poolPreparedStatements=true spring.datasource.maxPoolPreparedStatementPerConnectionSize=20 # йЕНзљЃзЫСжОІзїЯиЃ°жЛ¶жИ™зЪДfiltersпЉМеОїжОЙеРОзЫСжОІзХМйЭҐsqlжЧ†ж≥ХзїЯиЃ°пЉМ'wall'зФ®дЇОйШ≤зБЂеҐЩ spring.datasource.filters=stat,wall # йАЪињЗconnectPropertiesе±ЮжАІжЭ•жЙУеЉАmergeSqlеКЯиГљпЉЫжЕҐSQLиЃ∞ељХ spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=2000
ж≥®жДП : ињЩйЗМзЪДйЕНзљЃж†єжНЃй°єзЫЃйЬАи¶БеОїињЫи°МиЗ™еЃЪдєЙпЉМжѓФе¶В иґЕжЧґињЮжО•жЧґйЧі гАБжЕҐ sql жߕ胥жЧґйЧі з≠Й
package com.hone.system.utils.druid; import com.alibaba.druid.pool.DruidDataSource; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.Primary; import javax.sql.DataSource; import java.sql.SQLException; @Configuration public class DruidDBConfig{ private Logger logger = LoggerFactory.getLogger(DruidDBConfig.class); @Value("${spring.datasource.url}") private String dbUrl; @Value("${spring.datasource.username}") private String username; @Value("${spring.datasource.password}") private String password; @Value("${spring.datasource.driver-class-name}") private String driverClassName; @Value("${spring.datasource.initialSize}") private int initialSize; @Value("${spring.datasource.minIdle}") private int minIdle; @Value("${spring.datasource.maxActive}") private int maxActive; @Value("${spring.datasource.maxWait}") private int maxWait; @Value("${spring.datasource.timeBetweenEvictionRunsMillis}") private int timeBetweenEvictionRunsMillis; @Value("${spring.datasource.minEvictableIdleTimeMillis}") private int minEvictableIdleTimeMillis; @Value("${spring.datasource.validationQuery}") private String validationQuery; @Value("${spring.datasource.testWhileIdle}") private boolean testWhileIdle; @Value("${spring.datasource.testOnBorrow}") private boolean testOnBorrow; @Value("${spring.datasource.testOnReturn}") private boolean testOnReturn; @Value("${spring.datasource.poolPreparedStatements}") private boolean poolPreparedStatements; @Value("${spring.datasource.maxPoolPreparedStatementPerConnectionSize}") private int maxPoolPreparedStatementPerConnectionSize; @Value("${spring.datasource.filters}") private String filters; @Value("{spring.datasource.connectionProperties}") private String connectionProperties; /** * @Bean е£∞жШОпЉМDataSource еѓєи±°дЄЇ Spring еЃєеЩ®жЙАзЃ°зРЖ; * @Primary и°®з§ЇињЩйЗМеЃЪдєЙзЪДDataSourceе∞Жи¶ЖзЫЦеЕґдїЦжЭ•жЇРзЪДDataSourceгАВ * StatFilterпЉМзФ®дЇОзїЯиЃ°зЫСжОІдњ°жБѓгАВStatFilterзЪДеИЂеРНжШѓstatгАВ * зїЯиЃ°SQLдњ°жБѓпЉМеРИеєґзїЯиЃ°гАВmergeStatжШѓзЪДMergeStatFilterзЉ©еЖЩгАВ * йАЪињЗ DataSource зЪДе±ЮжАІ<property name="filters" value="mergeStat" /> жИЦиАЕ * connectPropertiesе±ЮжАІжЭ•жЙУеЉАmergeSqlеКЯиГљ <property name="connectionProperties" value="druid.stat.mergeSql=true" /> * StatFilterе±ЮжАІslowSqlMillisзФ®жЭ•йЕНзљЃSQLжЕҐзЪДж†ЗеЗЖ * * @return */ @Bean @Primary public DataSource dataSource() { DruidDataSource datasource = new DruidDataSource(); datasource.setUrl(dbUrl); datasource.setDriverClassName(driverClassName); datasource.setUsername(username); datasource.setPassword(password); //configuration datasource.setInitialSize(initialSize); datasource.setMinIdle(minIdle); datasource.setMaxActive(maxActive); datasource.setMaxWait(maxWait); datasource.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis); datasource.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis); datasource.setValidationQuery(validationQuery); datasource.setTestWhileIdle(testWhileIdle); datasource.setTestOnBorrow(testOnBorrow); datasource.setTestOnReturn(testOnReturn); datasource.setPoolPreparedStatements(poolPreparedStatements); datasource.setMaxPoolPreparedStatementPerConnectionSize(maxPoolPreparedStatementPerConnectionSize); try { /** * иЃЊзљЃStatFilterпЉМзФ®дЇОзїЯиЃ°зЫСжОІдњ°жБѓгАВ * StatFilterзЪДеИЂеРНжШѓstat * */ datasource.setFilters(filters); } catch (SQLException e) { logger.error("druid configuration initialization filter : {0}",e); } datasource.setConnectionProperties(connectionProperties); return datasource; } }import com.alibaba.druid.support.http.StatViewServlet; import javax.servlet.annotation.WebInitParam; import javax.servlet.annotation.WebServlet; /** * StatViewServletзФ®дЇОе±Хз§ЇDruidзЪДзїЯиЃ°дњ°жБѓгАВ * жПРдЊЫзЫСжОІдњ°жБѓе±Хз§ЇзЪДhtmlй°µйЭҐ * жПРдЊЫзЫСжОІдњ°жБѓзЪДJSON API * * еЖЕзљЃзЫСжОІй°µйЭҐзЪДй¶Цй°µжШѓ/druid/index.html * * loginUsernameгАБloginPassword зЩїељХзФ®жИЈеРНеТМеѓЖз†Б */ /** * @Webservlet * жЬЙдЄ§дЄ™е±ЮжАІеПѓдї•зФ®жЭ•и°®з§ЇServletзЪДиЃњйЧЃиЈѓеЊДпЉМеИЖеИЂжШѓvalueеТМurlPatternsгАВvalueеТМurlPatternsйГљжШѓжХ∞зїД嚥еЉПпЉМ * и°®з§ЇжИСдїђеПѓдї•жККдЄАдЄ™ServletжШ†е∞ДеИ∞е§ЪдЄ™иЃњйЧЃиЈѓеЊДпЉМдљЖжШѓvalueеТМurlPatternsдЄНиГљеРМжЧґдљњзФ®гАВ * */ @WebServlet( urlPatterns = {"/druid/*"}, initParams = { @WebInitParam(name = "loginUsername", value = "admin"), @WebInitParam(name = "loginPassword", value = "admin"), @WebInitParam(name = "resetEnable", value = "false") } ) public class DruidStatViewServlet extends StatViewServlet { }import com.alibaba.druid.support.http.WebStatFilter; import javax.servlet.annotation.WebFilter; import javax.servlet.annotation.WebInitParam; /** * WebStatFilterзФ®дЇОйЗЗйЫЖweb-jdbcеЕ≥иБФзЫСжОІзЪДжХ∞жНЃгАВ * е±ЮжАІfilterNameе£∞жШОињЗжї§еЩ®зЪДеРНзІ∞,еПѓйАЙ * е±ЮжАІurlPatternsжМЗеЃЪи¶БињЗжї§ зЪДURLж®°еЉП,дєЯеПѓдљњзФ®е±ЮжАІvalueжЭ•е£∞жШО.(жМЗеЃЪи¶БињЗжї§зЪДURLж®°еЉПжШѓењЕйАЙе±ЮжАІ) */ @WebFilter( urlPatterns = "/*", initParams = { @WebInitParam(name = "exclusions",value = "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*") } ) public class DruidStatFilter extends WebStatFilter { }@SpringBootApplication @MapperScan("com.hone.dao") //еЉАеРѓmapperжЙЂжПП @ServletComponentScan //еЉАеРѓservletжЙЂжПП public class HongoneApplication {.....}жЬАеРОпЉМеРѓеК®й°єзЫЃињЫи°МжµЛиѓХ еЬ®жµПиІИеЩ®дЄ≠иЊУеЕ• http://localhost:8080/druid/index.html
пЉИж≥®жДПпЉЪ е¶ВжЮЬдљ†зЪДй°єзЫЃиЃЊзљЃдЇЖиЃњйЧЃеЙНзЉА пЉМ иЃњйЧЃеЬ∞еЭАйЧЃ http://localhost:8080/иЃњйЧЃеЙНзЉА/druid/index.html )
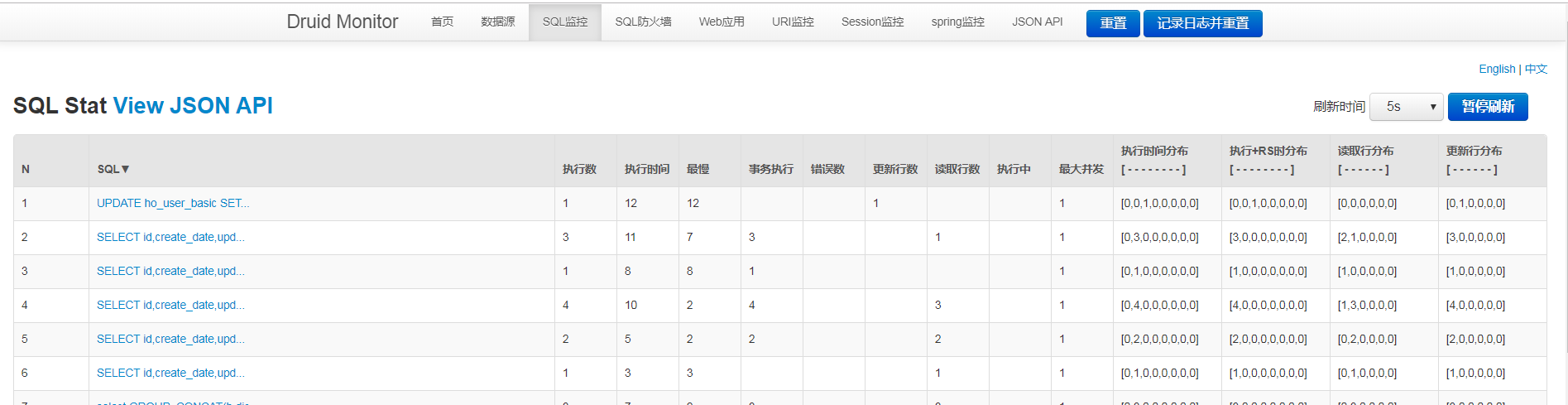
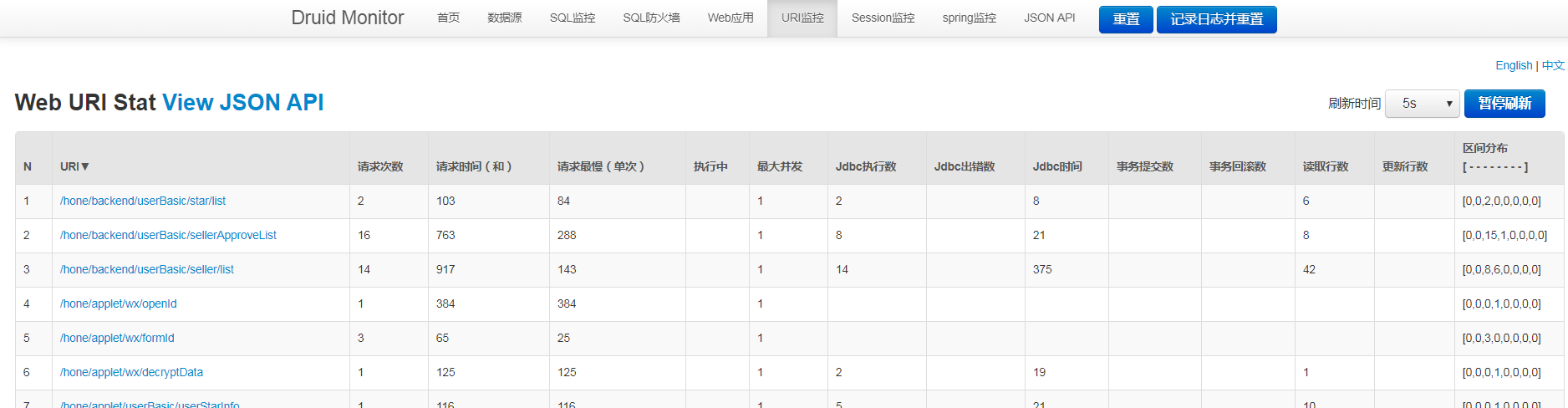
дЄКињ∞еЖЕеЃєе∞±жШѓspringbootдЄ≠жАОдєИеЉХеЕ•druidжХ∞жНЃжЇРпЉМдљ†дїђе≠¶еИ∞зЯ•иѓЖжИЦжКАиГљдЇЖеРЧпЉЯе¶ВжЮЬињШжГ≥е≠¶еИ∞жЫіе§ЪжКАиГљжИЦиАЕдЄ∞еѓМиЗ™еЈ±зЪДзЯ•иѓЖеВ®е§ЗпЉМ搥ињОеЕ≥ж≥®дЇњйАЯдЇСи°МдЄЪиµДиЃѓйҐСйБУгАВ
еЕНиі£е£∞жШОпЉЪжЬђзЂЩеПСеЄГзЪДеЖЕеЃєпЉИеЫЊзЙЗгАБиІЖйҐСеТМжЦЗе≠ЧпЉЙдї•еОЯеИЫгАБиљђиљљеТМеИЖдЇЂдЄЇдЄїпЉМжЦЗзЂ†иІВзВєдЄНдї£и°®жЬђзљСзЂЩзЂЛеЬЇпЉМе¶ВжЮЬжґЙеПКдЊµжЭГиѓЈиБФз≥їзЂЩйХњйВЃзЃ±пЉЪis@yisu.comињЫи°МдЄЊжК•пЉМеєґжПРдЊЫзЫЄеЕ≥иѓБжНЃпЉМдЄАзїПжЯ•еЃЮпЉМе∞ЖзЂЛеИїеИ†йЩ§жґЙеЂМдЊµжЭГеЖЕеЃєгАВ

дЇњйАЯдЇСеЕђдЉЧеПЈ

жЙЛжЬЇзљСзЂЩдЇМзїіз†Б



