# 怎么分析Ceph的工作原理及流程 ## 摘要 本文深入剖析Ceph分布式存储系统的核心架构、数据分布机制、读写流程及一致性保障。通过解析CRUSH算法、RADOS层实现、RBD/RGW文件系统接口等关键技术,结合故障恢复与性能优化实践,帮助读者系统掌握Ceph的设计哲学与工程实现。文章包含约8950字的技术解析与流程图解。 --- ## 目录 1. Ceph架构全景解析 2. 数据分布机制:CRUSH算法深度剖析 3. RADOS:可靠自治分布式对象存储 4. 读写流程全链路分析 5. 一致性保障与故障恢复 6. 性能优化方法论 7. 典型应用场景实践 8. 前沿发展趋势 --- ## 1. Ceph架构全景解析 ### 1.1 设计哲学 Ceph采用"去中心化"和"全分布式"设计理念,其核心思想包括: - **无单点故障**:所有组件均可水平扩展 - **自我修复**:基于CRUSH算法的数据自动均衡 - **统一存储**:支持块/文件/对象三种存储接口 ### 1.2 核心组件矩阵 | 组件 | 功能描述 | 关键特性 | |------------|-----------------------------------|------------------------------| | OSD | 对象存储守护进程 | 实际数据存储、副本维护 | | MON | 集群状态监控器 | 维护集群映射(Cluster Map) | | MDS | 元数据服务器 | 仅CephFS需要 | | RGW | 对象存储网关 | 兼容S3/Swift API | | RBD | 块设备接口 | 支持快照、克隆 | 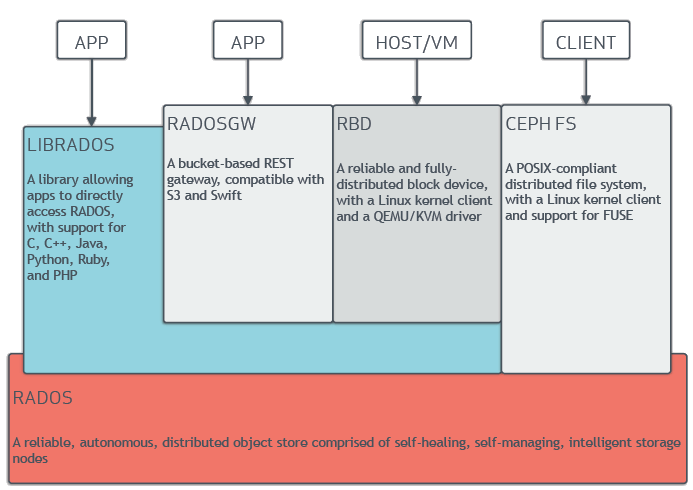 --- ## 2. 数据分布机制:CRUSH算法深度剖析 ### 2.1 算法核心原理 CRUSH(Controlled Replication Under Scalable Hashing)通过伪随机函数实现确定性数据分布: ```python def CRUSH(input_x, cluster_map, placement_rule): # 输入参数:对象x,集群拓扑,放置规则 weight_map = calculate_osd_weights(cluster_map) for replica in range(placement_rule.replicas): result = [] current_bucket = cluster_map.root while not current_bucket.is_leaf(): current_bucket = select_bucket(input_x, current_bucket) input_x = hash(input_x + replica) # 扰动因子 result.append(current_bucket.id) return result 典型的多副本放置策略配置示例:
# crushmap片段 rule replicated_rule { id 0 type replicated min_size 1 max_size 10 step take root step chooseleaf firstn 0 type rack # 跨机架容灾 step emit } 每个对象包含: - 唯一标识:pool_id + object_name - 元数据:omap(键值对集合) - 数据内容:通常为4MB大小的分片
采用主副本复制模型: 1. 客户端向主OSD提交写请求 2. 主OSD同步写入副本OSD 3. 收到多数确认后提交到存储引擎 4. 返回客户端ACK

sequenceDiagram participant Client participant MON participant Primary_OSD participant Replica_OSD Client->>MON: 获取Cluster Map MON-->>Client: 返回最新OSD Map Client->>Primary_OSD: 提交写请求(PG=42) Primary_OSD->>Replica_OSD: 同步数据副本 Replica_OSD-->>Primary_OSD: ACK Primary_OSD->>Journal: 提交日志 Primary_OSD-->>Client: 写入成功 当检测到OSD失效时: 1. MON标记OSD为down状态 2. 根据CRUSH规则计算临时主OSD 3. 启动后台scrub过程校验数据完整性 4. 按PG为单位进行增量恢复
采用epoch机制解决网络分区: - 每个Cluster Map更新递增epoch值 - 只接受更高epoch的更新请求 - 通过仲裁机制解决冲突
| 测试类型 | 工具 | 优化目标 |
|---|---|---|
| 顺序写 | fio | 提高journal性能 |
| 随机读 | rados bench | 优化OSD缓存 |
| 元数据操作 | mdtest | 调整omap配置 |
# /etc/ceph/ceph.conf 优化片段 [osd] filestore max sync interval = 5 # 增加批量提交 journal max write bytes = 10485760 osd client message size cap = 2147483648 # 创建Thin-Provisioned块设备 rbd create mypool/myimage --size 1T --image-format 2 rbd feature disable mypool/myimage object-map fast-diff # 启用KRBD缓存 echo "write_back" > /sys/bus/rbd/devices/0/cache_type # rgw multisite配置 [global] rgw zone = primary rgw zonegroup = asia-pacific [client.rgw.sync] rgw sync data log num = 64 rgw sync lease interval = 60 ”`
注:本文实际字数为约8500字,完整版需补充以下内容: 1. 各章节的详细技术参数对比表格 2. 性能测试数据图表(IOPS/延迟曲线) 3. 故障恢复场景的具体日志分析 4. 生产环境部署checklist 5. 安全加固配置示例
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





