жё©йҰЁжҸҗзӨәГ—
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•Г—
зҷ»еҪ•жіЁеҶҢГ—
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
з”ЁжҲ·зҷ»еҪ•Г—
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
Pythonеӯ—з¬ҰдёІвҖ”вҖ”дёҖдёӘжңүеәҸеӯ—з¬Ұзҡ„йӣҶеҗҲпјҢз”ЁдәҺеӯҳеӮЁе’ҢиЎЁзҺ°еҹәдәҺж–Үжң¬зҡ„дҝЎжҒҜгҖӮ
PythonдёӯжІЎжңүеҚ•дёӘеӯ—з¬Ұзҡ„зұ»еһӢпјҢеҸӘжңүдҪҝз”ЁдёҖдёӘеӯ—з¬Ұзҡ„еӯ—з¬ҰдёІгҖӮ
еӯ—з¬ҰдёІиў«еҲ’еҲҶдёәдёҚеҸҜеҸҳеәҸеҲ—пјҢж„Ҹе‘ізқҖиҝҷдәӣеӯ—з¬ҰдёІжүҖеҢ…еҗ«зҡ„еӯ—з¬ҰеӯҳеңЁд»Һе·ҰеҫҖеҸізҡ„дҪҚзҪ®зЁӢеәҸпјҢ并且дёҚеҸҜд»ҘеңЁеҺҹеӨ„дҝ®ж”№гҖӮ
еёёи§Ғеӯ—з¬ҰдёІеёёйҮҸе’ҢиЎЁиҫҫејҸпјҡ
#
пҒ¬ еҚ•еј•еҸ·пјҡ'Yert"s'
пҒ¬ еҸҢеј•еҸ·пјҡ"Yert's"
пҒ¬ дёүеј•еҸ·пјҡ"....................Yert................................"
пҒ¬ иҪ¬д№үеӯ—з¬ҰпјҡвҖҷ\tpвҖҷ
пҒ¬ Rawеӯ—з¬ҰдёІпјҡr"C:w\test.com"
пҒ¬ Python3.0дёӯзҡ„Byteеӯ—з¬ҰдёІпјҡbвҖҷsp\x01
пҒ¬ еҸӘеңЁPython2.6еҮәзҺ°зҡ„Unicodeеӯ—з¬ҰдёІпјҡuвҖҷegg\suuвҖҷ
еҚ•еҸҢеј•еҸ·зҡ„дҪңз”ЁзӣёеҗҢпјҡ
>>> 'Yert',"Yert" ('Yert', 'Yert') PythonиҮӘеҠЁеҗҲ并зӣёйӮ»зҡ„еӯ—з¬ҰдёІеёёйҮҸпјҡ
>>> title="The truth " 'of' "life" >>> >>> title 'The truth oflife' дёүйҮҚеј•еҸ·зј–еҶҷеӨҡиЎҢеӯ—з¬ҰдёІеқ—пјҡ
>>> >>> longfile=''' ... ... ... a ... a ... a ... a ... a ... ''' >>> >>> >>> longfile '\n\n\na\na\na\na\na\n' >>> >>> print(longfile) a a a a a >>> иҪ¬д№үеӯ—з¬ҰеәҸеҲ—пјҡ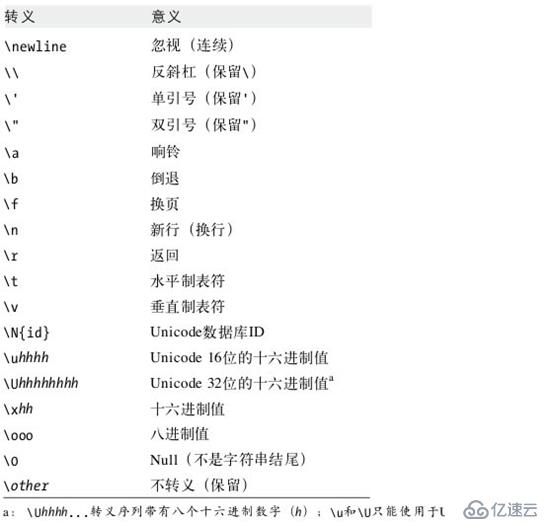
йҖҡиҝҮеҸҚж–ңжқ иҪ¬д№үеӯ—з¬ҰеөҢе…Ҙеј•еҸ·пјҡ
>>> 'today\'s',"yesterday\"s" ("today's", 'yesterday"s') иҪ¬д№үеәҸеҲ—жҸ’е…Ҙз»қеҜ№зҡ„дәҢиҝӣеҲ¶еҖјпјҡ
>>> >>> s = 'a\0b\0c' >>> >>> s 'a\x00b\x00c' >>> >>> len(s) 5 >>> PythonдјҡеңЁеҶ…еӯҳдёӯдҝқжҢҒдәҶж•ҙдёӘеӯ—з¬ҰдёІзҡ„й•ҝеәҰе’Ңж–Үжң¬пјҢPythonжІЎжңүеӯ—з¬Ұдјҡз»“жқҹдёҖдёӘеӯ—з¬ҰдёІгҖӮ
>>> >>> s = '\001\002\003' >>> >>> s '\x01\x02\x03' >>> >>> len(s) 3 >>> еҰӮжһңPythonжІЎжңүдҪңдёәдёҖдёӘеҗҲжі•зҡ„иҪ¬д№үзј–з ҒиҜҶеҲ«еҮәеңЁвҖң\вҖқеҗҺзҡ„еӯ—з¬ҰпјҢе®ғе°ұзӣҙжҺҘеңЁжңҖз»Ҳзҡ„еӯ—з¬ҰдёІдёӯдҝқз•ҷеҸҚж–ңжқ гҖӮ
>>> x = "C:\py\code" >>> >>> x 'C:\\py\\code' rawеӯ—з¬ҰдёІжҠ‘еҲ¶иҪ¬д№ү
Rawеӯ—з¬ҰдёІпјҡеҰӮжһңеӯ—жҜҚrпјҲеӨ§еҶҷжҲ–е°ҸеҶҷпјүеҮәзҺ°еңЁеӯ—з¬ҰдёІзҡ„第дёҖеј•еҸ·зҡ„еүҚйқўпјҢе®ғе°Ҷдјҡе…ій—ӯиҪ¬д№үжңәеҲ¶гҖӮPythonе°ҶеҸҚж–ңжқ дҪңдёәеёёйҮҸжқҘдҝқжҢҒпјҢе°ұеғҸжҷ®йҖҡеӯ—з¬ҰдёІпјҢдёәдәҶйҒҝе…Қй”ҷиҜҜпјҢеңЁWindowsзі»з»ҹдёӯеҝ…йЎ»еўһеҠ еӯ—жҜҚrгҖӮ
>>> myfile=open(r'D:test\test.txt','w') >>> >>> text="I'm Yert,the word would been wroten in text." >>> >>> myfile.write(text) 44 >>> >>> myfile.close() зҙўеј•е’ҢеҲҶзүҮпјҡ
зҙўеј•пјҡ
еӯ—з¬ҰдёІеңЁPythonдёӯиў«е®ҡд№үдёәеӯ—з¬Ұзҡ„жңүеәҸйӣҶеҗҲпјҢеҸҜд»ҘйҖҡиҝҮдҪҚзҪ®еҒҸ移еҖјиҺ·еҸ–еӯ—з¬ҰгҖӮеңЁPythonдёӯпјҢеӯ—з¬ҰдёІдёӯзҡ„еӯ—з¬ҰжҳҜйҖҡиҝҮзҙўеј•пјҲйҖҡиҝҮеңЁеӯ—з¬ҰдёІд№ӢеҗҺзҡ„ж–№жӢ¬еҸ·дёӯжҸҗдҫӣжүҖйңҖиҰҒзҡ„е…ғзҙ зҡ„ж•°еӯ—еҒҸ移йҮҸпјүжҸҗеҸ–зҡ„гҖӮ
Pythonзҡ„еҒҸ移йҮҸжҳҜд»Һ0ејҖе§ӢпјҢ并жҜ”еӯ—з¬ҰдёІзҡ„й•ҝеәҰе°Ҹ1пјҢиҝҳж”ҜжҢҒеңЁеӯ—з¬ҰдёІдёӯдҪҝз”ЁиҙҹеҒҸ移зҡ„ж–№жі•д»ҺеәҸеҲ—дёӯиҺ·еҸ–еӣ зҙ гҖӮд»ҺжҠҖжңҜдёҠи®ІпјҢдёҖдёӘиҙҹеҒҸ移дёҺиҝҷдёӘеӯ—з¬ҰдёІй•ҝеәҰзӣёеҠ еҸҜд»Ҙеҫ—еҲ°е®ғзҡ„жӯЈеҒҸ移еҖјгҖӮ
>>> S='YertAlan' >>> >>> S[0] 'Y' >>> S[-1] 'n' >>> >>> len(S) 8 >>> S[len(S)-1] 'n' еҲҶзүҮпјҡ
еҪ“дҪҝз”ЁдёҖеҜ№д»ҘеҶ’еҸ·еҲҶйҡ”зҡ„еҒҸ移жқҘзҙўеј•еӯ—з¬ҰдёІж—¶пјҢPythonе°Ҷдјҡиҝ”еӣһдёҖдёӘж–°зҡ„еҜ№иұЎпјҢе…¶дёӯеҢ…еҗ«дәҶд»ҘиҝҷеҜ№еҒҸ移жүҖж ҮиҜҶзҡ„иҝһз»ӯеҶ…е®№гҖӮ
>>> S[1:3] 'er' >>> S[1:] 'ertAlan' >>> >>> S[::] 'YertAlan' >>> >>> S[-4:-1] 'Ala' >>> >>> S[:-2] 'YertAl' жӢ“еұ•еҲҶзүҮпјҡ第дёүдёӘйҷҗеҲ¶еҖј
еҲҶзүҮиЎЁиҫҫејҸеўһеҠ дёҖдёӘеҸҜйҖүзҡ„第дёүдёӘзҙўеј•пјҢз”ЁдҪңжӯҘиҝӣгҖӮжӯҘиҝӣж·»еҠ еҲ°жҜҸдёӘжҸҗеҸ–зҡ„е…ғзҙ зҡ„зҙўеј•дёӯгҖӮе®ҢГ—Г—Г—ејҸзҡ„еҲҶзүҮдёәstring[X:Y:Z]пјҢиЎЁзӨәвҖңзҙўеј•еӯ—з¬ҰдёІstringеҜ№иұЎдёӯзҡ„е…ғзҙ пјҢд»ҺеҒҸ移XзӣҙеҲ°еҒҸ移дёәY-1пјҢжҜҸйҡ”Zе…ғзҙ зҙўеј•дёҖж¬ЎвҖқгҖӮ第дёүдёӘйҷҗеҲ¶жІЎдәәдёә1пјҢжүҖд»ҘйҖҡеёёеңЁдёҖдёӘеҲҮзүҮдёӯд»Һе·ҰиҮіеҸіжҸҗеҸ–жҜҸдёҖдёӘе…ғзҙ зҡ„еҺҹеӣ гҖӮ
>>> string='ABCDEFGHIJKLMNOPQRST' >>> >>> string[1:8] 'BCDEFGH' >>> >>> string[1:8:2] 'BDFH' >>> >>> string[1:12] 'BCDEFGHIJKL' >>> string[1:12:3] 'BEHK' иҙҹж•°жӯҘиҝӣпјҡ
>>> string[1:10] 'BCDEFGHIJ' >>> >>> string[1:10:-1] '' >>> string[10:1:-1] 'KJIHGFEDC' >>> >>> string[10:1] '' >>> string[10:1:-2] 'KIGEC' еӯ—з¬ҰдёІиҪ¬жҚўе·Ҙе…·
>>>#е°Ҷд»Ҙеӯ—з¬ҰдёІеҪўејҸеҮәзҺ°зҡ„ж•°еӯ—иҝӣиЎҢиҪ¬жҚўпјҡ >>> int('55'),str(55) (55, '55') >>> repr(55) '55' жіЁж„ҸпјҡReprеҮҪж•°еҸҜд»Ҙе°ҶдёҖдёӘеҜ№иұЎиҪ¬жҚўдёәе…¶еӯ—з¬ҰдёІеҪўејҸпјҢ然иҖҢиҝҷдәӣиҝ”еӣһзҡ„еҜ№иұЎдҪңдёәд»Јз Ғзҡ„еӯ—з¬ҰдёІпјҢеҸҜд»ҘйҮҚж–°еҲӣе»әеҜ№иұЎгҖӮ
>>> print(str('Yert'),repr('Yert')) Yert 'Yert' >>>#жө®зӮ№ж•°иҪ¬жҚўеӯ—з¬ҰдёІпјҡ >>> str(3.1415),float("1.5") ('3.1415', 1.5) >>> >>> text="1.234E-10" >>> >>> float(text) 1.234e-10 еӯ—з¬ҰдёІд»Јз ҒиҪ¬жҚўпјҡ
еҚ•дёӘеӯ—з¬ҰеҸҜд»ҘйҖҡиҝҮе°Ҷе…¶дј з»ҷеҶ…зҪ®зҡ„ordеҮҪж•°иҪ¬жҚўдёәе…¶еҜ№еә”зҡ„ASCIIз ҒвҖ”вҖ”еҲҷдёӘеҮҪж•°е®һйҷ…иҝ”еӣһзҡ„жҳҜиҝҷдёӘеӯ—з¬ҰеңЁеҶ…еӯҳдёӯеҜ№еә”зҡ„еӯ—з¬Ұзҡ„дәҢиҝӣеҲ¶еҖјгҖӮиҖҢchrеҮҪж•°е°Ҷдјҡжү§иЎҢзӣёеҸҚзҡ„ж“ҚдҪңпјҢиҺ·еҸ–ASCIIз Ғ并е°Ҷе…¶иҪ¬жҚўдёәеҜ№еә”зҡ„еӯ—з¬Ұпјҡ
>>> ord('s') 115 >>> >>> chr(115) 's' >>>#жү§иЎҢеҹәдәҺеӯ—з¬ҰдёІзҡ„ж•°еӯҰиҝҗз®—пјҡ >>> S='a' >>> S=chr(ord(S)+1) >>> S 'b' >>> S=chr(ord(S)+1) >>> >>> S 'c' >>> int('5') 5 >>> >>> ord('5') - ord('0') 5 дёҺеҫӘзҺҜиҜӯеҸҘз»“еҗҲпјҢиҝӣиЎҢж•ҙж•°зҡ„еӨ„зҗҶпјҡ
е°ҶдәҢиҝӣеҲ¶еӯ—з¬ҰдёІиҪ¬жҚўдёәж•ҙж•°пјҢ并е°ҶеҪ“еүҚеҖјд№ҳд»Ҙ2пјҢ并еҠ дёҠдёӢдёҖдҪҚж•°еӯ—еҖјгҖӮ
>>> B = '1101' >>> I = 0 >>> while B != '': ... I = I * 2 + (ord(B[0])-ord('0')) ... B = B[1:] ... >>> >>> I 13 >>> дҝ®ж”№еӯ—з¬ҰдёІ
>>>#дҪҝз”ЁеҗҲ并гҖҒеҲҶзүҮпјҡ >>> S='Yert' >>> >>> S = 'Yert' >>> S = S + 'Alan' >>> S 'YertAlan' >>> S = S[:4] + 'В·DВ·' + S[4:] #Dд№ӢдёҖж—Ҹ >>> >>> S 'YertВ·DВ·Alan' дҪҝз”ЁreplaceеҮҪж•°дҝ®ж”№пјҲзҙўеј•еҲ°еӯ—з¬ҰдёІпјҢе°Ҷе…¶ж”№дёәжҢҮе®ҡеӯ—з¬ҰдёІпјүпјҡ
>>> S=S.replace('Alan','King') >>> S 'YertВ·DВ·King' йҖҡиҝҮеӯ—з¬ҰдёІж јејҸеҢ–иЎЁиҫҫејҸжқҘеҲӣе»әж–°еӯ—з¬ҰдёІпјҡ
>>> "March %sst,I'm a apple,I'm have a %s" % (1,'pencil') "March 1st,I'm a apple,I'm have a pencil" >>> >>> "March {0}st,I'm a apple,I'm have a {1}".format(1,'pencil') "March 1st,I'm a apple,I'm have a pencil" дҪҝз”Ёfindж–№жі•иҝӣиЎҢдҝ®ж”№пјҡ
>>> S = '13658934230' #е®һзҺ°дҝ®ж”№еҸ·з ҒпјҢдҝқжҠӨйҡҗз§Ғ >>> >>> node = S.find('5893') >>> >>> node 3 >>> S = S[:node] + 'XXXX' + S[(node+4):] >>> >>> S '136XXXX4230' дҪҝз”ЁеҗҲ并ж“ҚдҪңе’Ңreplaceж–№жі•жҜҸж¬ЎиҝҗиЎҢдә§з”ҹж–°зҡ„еӯ—з¬ҰдёІеҜ№иұЎпјҢдјҡж¶ҲиҖ—жҖ§иғҪпјҢжүҖд»ҘеңЁеҜ№и¶…й•ҝж–Үжң¬иҝӣиЎҢеӨҡеӨ„дҝ®ж”№ж—¶пјҢйңҖиҰҒе°Ҷеӯ—з¬ҰдёІиҪ¬жҚўдёәдёҖдёӘж”ҜжҢҒеҺҹеӨ„дҝ®ж”№зҡ„еҜ№иұЎгҖӮ
>>> S = 'yert' >>> >>> L = list(S) >>> >>> L ['y', 'e', 'r', 't'] еҶ…зҪ®зҡ„listеҮҪж•°пјҲжҲ–дёҖдёӘеҜ№иұЎжһ„йҖ еҮҪж•°и°ғз”Ёпјүд»Ҙд»»ж„ҸеәҸеҲ—дёӯзҡ„е…ғзҙ еҲӣз«ӢдёҖдёӘж–°зҡ„еҲ—иЎЁпјҢеҸҜд»Ҙе°Ҷеӯ—з¬ҰдёІдёӯзҡ„еӯ—з¬ҰеҲҶи§ЈдёәдёҖдёӘеҲ—иЎЁгҖӮ
JoinеҮҪж•°еҸҜд»Ҙе°ҶеҲ—иЎЁеҗҲжҲҗдёәдёҖдёӘеӯ—з¬ҰдёІпјҡ
>>> D = ''.join(L) >>> >>> D 'yert' е…¶д»–еӯ—з¬ҰдёІж–№жі•пјҡ
>>>#йҖҡиҝҮеҲҶзүҮзҡ„ж–№ејҸе°Ҷж•°жҚ®д»ҺеҺҹе§Ӣеӯ—з¬ҰдёІдёӯеҲҶзҰ»пјҢз§°дёәи§ЈжһҗгҖӮ >>> S 'yert' >>> >>> J = S[1:3] >>> >>> J 'er' >>>#еҰӮжһңеҲҶйҡ”з¬ҰеҲҶејҖдәҶж•°жҚ®з»„件пјҢеҸҜд»ҘдҪҝз”Ёsplitж–№жі•жҸҗеҸ–组件гҖӮ >>> date = 'My name is Yert' >>> >>> cols = date.split() >>> >>> cols ['My', 'name', 'is', 'Yert'] >>> >>> long_str = 'My name is Yert, I am a computer engineer,I am studing Python' >>> >>> cols = long_str.split(',') >>> >>> cols ['My name is Yert', ' I am a computer engineer', 'I am studing Python'] >>> line = 'The dog is Sam which it is yellow ! \n' >>>#жё…йҷӨжҜҸиЎҢжң«е°ҫз©әзҷҪ >>> line.rstrip() 'The dog is Sam which it is yellow !' >>>#е…ЁйғЁиҪ¬жҚўеӨ§еҶҷ >>> line.upper() 'THE DOG IS SAM WHICH IT IS YELLOW ! \n' >>>#жөӢиҜ•еҶ…е®№ >>> line.isalpha() False >>> >>>#жЈҖжөӢжң«е°ҫеҶ…е®№еӯ—з¬ҰдёІ >>> line.endswith('! \n') True >>>#жЈҖжөӢејҖе§ӢеҶ…е®№еӯ—з¬ҰдёІ >>> line.startswith('The') True >>> line[-len('! \n'):] == '! \n' True >>> >>> line[:len('The ')] == 'The ' True еӯ—з¬ҰдёІж јејҸеҢ–иЎЁиҫҫејҸ
ж јејҸеҢ–еӯ—з¬ҰдёІпјҡ
>>> '%d years later,I have became a %s!' % (3,'engineer') '3 years later,I have became a engineer!' й«ҳзә§еӯ—з¬ҰдёІж јејҸеҢ–иЎЁиҫҫејҸпјҡ
иҪ¬жҚўзӣ®ж ҮйҖҡз”Ёз»“жһ„пјҡ
%[ (name) ] [flags] [width] [.precision] typecode
иЎЁдёӯзҡ„еӯ—иҠӮз ҒеҮәзҺ°еңЁзӣ®ж Үеӯ—з¬ҰдёІзҡ„е°ҫйғЁпјҢеңЁ%е’Ңеӯ—з¬Ұз ҒеҸӘй—ҙпјҡеҸҜд»Ҙж”ҫзҪ®дёҖдёӘеӯ—е…ёзҡ„й”®пјӣзҪ—еҲ—еҮәе·ҰеҜ№йҪҗпјҲ-пјүгҖҒжӯЈиҙҹеҸ·пјҲ+пјүе’ҢиЎҘйӣ¶пјҲ0пјүзҡ„ж Үеҝ—дҪҚпјӣз»ҷеҮәж•°еӯ—зҡ„ж•ҙдҪ“й•ҝеәҰе’Ңе°Ҹж•°зӮ№еҗҺзҡ„дҪҚж•°зӯүгҖӮWidthе’ҢprecisionйғҪеҸҜзј–з ҒдёәдёҖдёӘ*пјҢд»ҘжҢҮе®ҡе®ғ们еә”иҜҘд»Һиҫ“е…ҘеҖјзҡ„дёӢдёҖйЎ№дёӯеҸ–еҖјгҖӮ
>>>#%dеҜ№ж•ҙж•°иҝӣиЎҢй»ҳи®ӨпјҢ%-6dиҝӣиЎҢ6дҪҚзҡ„е·ҰеҜ№йҪҗж јејҸеҢ–пјҢ%06dиҝӣиЎҢ6дҪҚиЎҘйӣ¶зҡ„ж јејҸеҢ– >>> M = 24 >>> >>> resu = "result: %d %-6d %06d" % (M,M,M) >>> >>> resu 'result: 24 24 000024' >>>#еҸҜд»ҘеңЁж јејҸеҢ–еӯ—з¬ҰдёІдёӯз”ЁдёҖдёӘ*жқҘжҢҮе®ҡйҖҡиҝҮи®Ўз®—еҫ—еҮәwidthе’ҢprecisionпјҢд»ҺиҖҢиҝ«дҪҝе®ғ们зҡ„еҖјд»Һ%иҝҗз®—з¬ҰеҸіиҫ№зҡ„иҫ“еҮәдёӯзҡ„дёӢдёҖйЎ№иҺ·еҸ–пјҢе…ғз»„дёӯзҡ„4жҢҮе®ҡдёәprecisionгҖӮ >>> '%f,%.2f,%.*f' % (1/3.0,1/3.0,4,1/3.0) '0.333333,0.33,0.3333' еҹәдәҺеӯ—е…ёеӯ—з¬ҰдёІж јејҸеҢ–
>>>#йҖҡиҝҮеӯ—е…ёзҡ„й”®жқҘжҸҗеҸ–еҜ№еә”зҡ„еҖјпјҡ >>> "%(a)d %(x)s" % {'a':1,'x':'Yert'} '1 Yert' >>>#Formatж–№жі•ж јејҸеҢ–еӯ—з¬ҰдёІпјҡ >>> date = '{0},{1} and {2}' >>> >>> date.format('Python','PHP','Go') 'Python,PHP and Go' >>> >>> date = '{a},{b} and {c}' >>> >>> date.format(a='Python',b='PHP',c='Go') 'Python,PHP and Go' >>> >>> >>> date = '{a},{0} and {c}' >>> >>> date.format('PHP',a='Python',c='Go') 'Python,PHP and Go' ж јејҸеҢ–еӯ—з¬ҰдёІеҸҜд»ҘжҢҮе®ҡеҜ№иұЎеұһжҖ§е’Ңеӯ—е…ёй”®гҖӮ
>>> import sys >>> >>> 'The machine {1[name]} runs {0.platform}'.format(sys,{'name':'Yert'}) 'The machine Yert runs win32' >>> >>> 'The machine {config[name]} runs {sys.platform}'.format(sys=sys,config={'name':'Yert'}) 'The machine Yert runs win32' е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ

дәҝйҖҹдә‘е…¬дј—еҸ·

жүӢжңәзҪ‘з«ҷдәҢз»ҙз Ғ



