檩鶮жПРз§Ї√Ч
жВ®е•љпЉМзЩїељХеРОжЙНиГљдЄЛиЃҐеНХеУ¶пЉБ
еѓЖз†БзЩїељХ√Ч
зЩїељХж≥®еЖМ√Ч
зВєеЗї зЩїељХж≥®еЖМ еН≥и°®з§ЇеРМжДПгАКдЇњйАЯдЇСзФ®жИЈжЬНеК°жЭ°жђЊгАЛ
зФ®жИЈзЩїељХ√Ч
жВ®е•љпЉМзЩїељХеРОжЙНиГљдЄЛиЃҐеНХеУ¶пЉБ
ињЩзѓЗжЦЗзЂ†дЄїи¶БдїЛзїНжКУеПЦжЈШеЃЭMMзЪДжЦєж≥ХпЉМжЦЗдЄ≠дїЛзїНзЪДйЭЮеЄЄиѓ¶зїЖпЉМеЕЈжЬЙдЄАеЃЪзЪДеПВиАГдїЈеАЉпЉМжДЯеЕіиґ£зЪДе∞ПдЉЩдЉідїђдЄАеЃЪи¶БзЬЛеЃМпЉБ
жЬђзѓЗзЫЃж†З
1.жКУеПЦжЈШеЃЭMMзЪДеІУеРНпЉМе§іеГПпЉМеєійЊД
2.жКУеПЦжѓПдЄАдЄ™MMзЪДиµДжЦЩзЃАдїЛдї•еПКеЖЩзЬЯеЫЊзЙЗ
3.жККжѓПдЄАдЄ™MMзЪДеЖЩзЬЯеЫЊзЙЗжМЙзЕІжЦЗдїґе§єдњЭе≠ШеИ∞жЬђеЬ∞
4.зЖЯжВЙжЦЗдїґдњЭе≠ШзЪДињЗз®Л
1.URLзЪДж†ЉеЉП
еЬ®ињЩйЗМжИСдїђзФ®еИ∞зЪДURLжШѓ http://mm.taobao.com/json/request_top_list.htm?page=1пЉМйЧЃеПЈеЙНйЭҐжШѓеЯЇеЬ∞еЭАпЉМеРОйЭҐзЪДеПВжХ∞pageжШѓдї£и°®зђђеЗ†й°µпЉМеПѓдї•йЪПжДПжЫіжНҐеЬ∞еЭАгАВзВєеЗїеЉАдєЛеРОпЉМдЉЪеПСзО∞жЬЙдЄАдЇЫжЈШеЃЭMMзЪДзЃАдїЛпЉМеєґйЩДжЬЙиґЕйУЊжО•йУЊжО•еИ∞дЄ™дЇЇиѓ¶жГЕй°µйЭҐгАВ
жИСдїђйЬАи¶БжКУеПЦжЬђй°µйЭҐзЪДе§іеГПеЬ∞еЭАпЉМMMеІУеРНпЉМMMеєійЊДпЉМMMе±ЕдљПеЬ∞пЉМдї•еПКMMзЪДдЄ™дЇЇиѓ¶жГЕй°µйЭҐеЬ∞еЭАгАВ
2.жКУеПЦзЃАи¶Бдњ°жБѓ
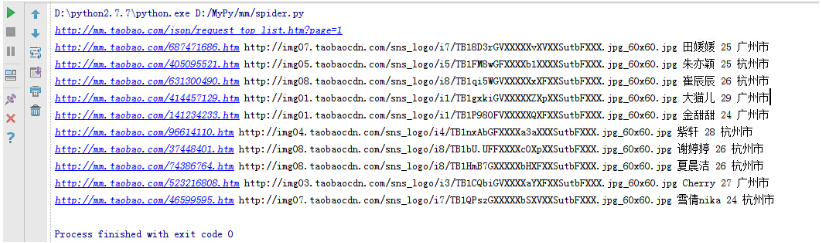
зЫЄдњ°е§ІеЃґзїПињЗдЄКеЗ†жђ°зЪДеЃЮжИШпЉМеѓєжКУеПЦеТМжПРеПЦй°µйЭҐзЪДеЬ∞еЭАеЈ≤зїПйЭЮеЄЄзЖЯжВЙдЇЖпЉМињЩйЗМж≤°жЬЙдїАдєИйЪЊеЇ¶дЇЖпЉМжИСдїђй¶ЦеЕИжКУеПЦжЬђй°µйЭҐзЪДMMиѓ¶жГЕй°µйЭҐеЬ∞еЭАпЉМеІУеРНпЉМеєійЊДз≠Йз≠ЙзЪДдњ°жБѓжЙУеН∞еЗЇжЭ•пЉМзЫіжО•иіідї£з†Бе¶ВдЄЛ
__author__ = 'CQC' # -*- coding:utf-8 -*- import urllib import urllib2 import re class Spider: def __init__(self): self.siteURL = 'http://mm.taobao.com/json/request_top_list.htm' def getPage(self,pageIndex): url = self.siteURL + "?page=" + str(pageIndex) print url request = urllib2.Request(url) response = urllib2.urlopen(request) return response.read().decode('gbk') def getContents(self,pageIndex): page = self.getPage(pageIndex) pattern = re.compile('<div class="list-item".*?pic-word.*?<a href="(.*?)".*?<img src="(.*?)".*?<a class="lady-name.*?>(.*?)</a>.*?<strong>(.*?)</strong>.*?<span>(.*?)</span>',re.S) items = re.findall(pattern,page) for item in items: print item[0],item[1],item[2],item[3],item[4] spider = Spider() spider.getContents(1)ињРи°МзїУжЮЬе¶ВдЄЛпЉЪ
2.жЦЗдїґеЖЩеЕ•зЃАдїЛ
еЬ®ињЩйЗМпЉМжИСдїђжЬЙеЖЩеЕ•еЫЊзЙЗеТМеЖЩеЕ•жЦЗжЬђдЄ§зІНжЦєеЉП
1пЉЙеЖЩеЕ•еЫЊзЙЗ
#дЉ†еЕ•еЫЊзЙЗеЬ∞еЭАпЉМжЦЗдїґеРНпЉМдњЭе≠ШеНХеЉ†еЫЊзЙЗ def saveImg(self,imageURL,fileName): u = urllib.urlopen(imageURL) data = u.read() f = open(fileName, 'wb') f.write(data) f.close()
2пЉЙеЖЩеЕ•жЦЗжЬђ
def saveBrief(self,content,name): fileName = name + "/" + name + ".txt" f = open(fileName,"w+") print u"ж≠£еЬ®еБЈеБЈдњЭе≠Ше•єзЪДдЄ™дЇЇдњ°жБѓдЄЇ",fileName f.write(content.encode('utf-8'))3пЉЙеИЫеїЇжЦ∞зЫЃељХ
#еИЫеїЇжЦ∞зЫЃељХ def mkdir(self,path): path = path.strip() # еИ§жЦ≠иЈѓеЊДжШѓеР¶е≠ШеЬ® # е≠ШеЬ® True # дЄНе≠ШеЬ® False isExists=os.path.exists(path) # еИ§жЦ≠зїУжЮЬ if not isExists: # е¶ВжЮЬдЄНе≠ШеЬ®еИЩеИЫеїЇзЫЃељХ # еИЫеїЇзЫЃељХжУНдљЬеЗљжХ∞ os.makedirs(path) return True else: # е¶ВжЮЬзЫЃељХе≠ШеЬ®еИЩдЄНеИЫеїЇпЉМеєґжПРз§ЇзЫЃељХеЈ≤е≠ШеЬ® return False
3.дї£з†БеЃМеЦД
дЄїи¶БзЪДзЯ•иѓЖзВєеЈ≤зїПеЬ®еЙНйЭҐйГљжґЙеПКеИ∞дЇЖпЉМе¶ВжЮЬе§ІеЃґеЙНйЭҐзЪДзЂ†иКВйГљеЈ≤зїПзЬЛдЇЖпЉМеЃМжИРињЩдЄ™зИђиЩЂдЄНеЬ®иѓЭдЄЛпЉМеЕЈдљУзЪДиѓ¶жГЕеЬ®ж≠§дЄНеЖНиµШињ∞пЉМзЫіжО•еЄЦдї£з†БеХ¶гАВ
spider.py
__author__ = 'CQC' # -*- coding:utf-8 -*- import urllib import urllib2 import re import tool import os #жКУеПЦMM class Spider: #й°µйЭҐеИЭеІЛеМЦ def __init__(self): self.siteURL = 'http://mm.taobao.com/json/request_top_list.htm' self.tool = tool.Tool() #иОЈеПЦ糥еЉХй°µйЭҐзЪДеЖЕеЃє def getPage(self,pageIndex): url = self.siteURL + "?page=" + str(pageIndex) request = urllib2.Request(url) response = urllib2.urlopen(request) return response.read().decode('gbk') #иОЈеПЦ糥еЉХзХМйЭҐжЙАжЬЙMMзЪДдњ°жБѓпЉМlistж†ЉеЉП def getContents(self,pageIndex): page = self.getPage(pageIndex) pattern = re.compile('<div class="list-item".*?pic-word.*?<a href="(.*?)".*?<img src="(.*?)".*?<a class="lady-name.*?>(.*?)</a>.*?<strong>(.*?)</strong>.*?<span>(.*?)</span>',re.S) items = re.findall(pattern,page) contents = [] for item in items: contents.append([item[0],item[1],item[2],item[3],item[4]]) return contents #иОЈеПЦMMдЄ™дЇЇиѓ¶жГЕй°µйЭҐ def getDetailPage(self,infoURL): response = urllib2.urlopen(infoURL) return response.read().decode('gbk') #иОЈеПЦдЄ™дЇЇжЦЗе≠ЧзЃАдїЛ def getBrief(self,page): pattern = re.compile('<div class="mm-aixiu-content".*?>(.*?)<!--',re.S) result = re.search(pattern,page) return self.tool.replace(result.group(1)) #иОЈеПЦй°µйЭҐжЙАжЬЙеЫЊзЙЗ def getAllImg(self,page): pattern = re.compile('<div class="mm-aixiu-content".*?>(.*?)<!--',re.S) #дЄ™дЇЇдњ°жБѓй°µйЭҐжЙАжЬЙдї£з†Б content = re.search(pattern,page) #дїОдї£з†БдЄ≠жПРеПЦеЫЊзЙЗ patternImg = re.compile('<img.*?src="(.*?)"',re.S) images = re.findall(patternImg,content.group(1)) return images #дњЭе≠Ше§ЪеЉ†еЖЩзЬЯеЫЊзЙЗ def saveImgs(self,images,name): number = 1 print u"еПСзО∞",name,u"еЕ±жЬЙ",len(images),u"еЉ†зЕІзЙЗ" for imageURL in images: splitPath = imageURL.split('.') fTail = splitPath.pop() if len(fTail) > 3: fTail = "jpg" fileName = name + "/" + str(number) + "." + fTail self.saveImg(imageURL,fileName) number += 1 # дњЭе≠Ше§іеГП def saveIcon(self,iconURL,name): splitPath = iconURL.split('.') fTail = splitPath.pop() fileName = name + "/icon." + fTail self.saveImg(iconURL,fileName) #дњЭе≠ШдЄ™дЇЇзЃАдїЛ def saveBrief(self,content,name): fileName = name + "/" + name + ".txt" f = open(fileName,"w+") print u"ж≠£еЬ®еБЈеБЈдњЭе≠Ше•єзЪДдЄ™дЇЇдњ°жБѓдЄЇ",fileName f.write(content.encode('utf-8')) #дЉ†еЕ•еЫЊзЙЗеЬ∞еЭАпЉМжЦЗдїґеРНпЉМдњЭе≠ШеНХеЉ†еЫЊзЙЗ def saveImg(self,imageURL,fileName): u = urllib.urlopen(imageURL) data = u.read() f = open(fileName, 'wb') f.write(data) print u"ж≠£еЬ®жВДжВДдњЭе≠Ше•єзЪДдЄАеЉ†еЫЊзЙЗдЄЇ",fileName f.close() #еИЫеїЇжЦ∞зЫЃељХ def mkdir(self,path): path = path.strip() # еИ§жЦ≠иЈѓеЊДжШѓеР¶е≠ШеЬ® # е≠ШеЬ® True # дЄНе≠ШеЬ® False isExists=os.path.exists(path) # еИ§жЦ≠зїУжЮЬ if not isExists: # е¶ВжЮЬдЄНе≠ШеЬ®еИЩеИЫеїЇзЫЃељХ print u"еБЈеБЈжЦ∞еїЇдЇЖеРНе≠ЧеПЂеБЪ",path,u'зЪДжЦЗдїґе§є' # еИЫеїЇзЫЃељХжУНдљЬеЗљжХ∞ os.makedirs(path) return True else: # е¶ВжЮЬзЫЃељХе≠ШеЬ®еИЩдЄНеИЫеїЇпЉМеєґжПРз§ЇзЫЃељХеЈ≤е≠ШеЬ® print u"еРНдЄЇ",path,'зЪДжЦЗдїґе§єеЈ≤зїПеИЫеїЇжИРеКЯ' return False #е∞ЖдЄАй°µжЈШеЃЭMMзЪДдњ°жБѓдњЭе≠ШиµЈжЭ• def savePageInfo(self,pageIndex): #иОЈеПЦзђђдЄАй°µжЈШеЃЭMMеИЧи°® contents = self.getContents(pageIndex) for item in contents: #item[0]дЄ™дЇЇиѓ¶жГЕURL,item[1]е§іеГПURL,item[2]еІУеРН,item[3]еєійЊД,item[4]е±ЕдљПеЬ∞ print u"еПСзО∞дЄАдљНж®°зЙє,еРНе≠ЧеПЂ",item[2],u"иК≥йЊД",item[3],u",е•єеЬ®",item[4] print u"ж≠£еЬ®еБЈеБЈеЬ∞дњЭе≠Ш",item[2],"зЪДдњ°жБѓ" print u"еПИжДПе§ЦеЬ∞еПСзО∞е•єзЪДдЄ™дЇЇеЬ∞еЭАжШѓ",item[0] #дЄ™дЇЇиѓ¶жГЕй°µйЭҐзЪДURL detailURL = item[0] #еЊЧеИ∞дЄ™дЇЇиѓ¶жГЕй°µйЭҐдї£з†Б detailPage = self.getDetailPage(detailURL) #иОЈеПЦдЄ™дЇЇзЃАдїЛ brief = self.getBrief(detailPage) #иОЈеПЦжЙАжЬЙеЫЊзЙЗеИЧи°® images = self.getAllImg(detailPage) self.mkdir(item[2]) #дњЭе≠ШдЄ™дЇЇзЃАдїЛ self.saveBrief(brief,item[2]) #дњЭе≠Ше§іеГП self.saveIcon(item[1],item[2]) #дњЭе≠ШеЫЊзЙЗ self.saveImgs(images,item[2]) #дЉ†еЕ•иµЈж≠Ґй°µз†БпЉМиОЈеПЦMMеЫЊзЙЗ def savePagesInfo(self,start,end): for i in range(start,end+1): print u"ж≠£еЬ®еБЈеБЈеѓїжЙЊзђђ",i,u"дЄ™еЬ∞жЦєпЉМзЬЛзЬЛMMдїђеЬ®дЄНеЬ®" self.savePageInfo(i) #дЉ†еЕ•иµЈж≠Ґй°µз†БеН≥еПѓпЉМеЬ®ж≠§дЉ†еЕ•дЇЖ2,10,и°®з§ЇжКУеПЦзђђ2еИ∞10й°µзЪДMM spider = Spider() spider.savePagesInfo(2,10)tool.py
__author__ = 'CQC' #-*- coding:utf-8 -*- import re #е§ДзРЖй°µйЭҐж†Зз≠Њз±ї class Tool: #еОїйЩ§imgж†Зз≠Њ,1-7дљНз©Їж†Љ, removeImg = re.compile('<img.*?>| {1,7}| ') #еИ†йЩ§иґЕйУЊжО•ж†Зз≠Њ removeAddr = re.compile('<a.*?>|</a>') #жККжНҐи°МзЪДж†Зз≠ЊжНҐдЄЇ\n replaceLine = re.compile('<tr>|<div>|</div>|</p>') #е∞Жи°®ж†ЉеИґи°®<td>жЫњжНҐдЄЇ\t replaceTD= re.compile('<td>') #е∞ЖжНҐи°Мзђ¶жИЦеПМжНҐи°Мзђ¶жЫњжНҐдЄЇ\n replaceBR = re.compile('<br><br>|<br>') #е∞ЖеЕґдљЩж†Зз≠ЊеЙФйЩ§ removeExtraTag = re.compile('<.*?>') #е∞Же§Ъи°Мз©Їи°МеИ†йЩ§ removeNoneLine = re.compile('\n+') def replace(self,x): x = re.sub(self.removeImg,"",x) x = re.sub(self.removeAddr,"",x) x = re.sub(self.replaceLine,"\n",x) x = re.sub(self.replaceTD,"\t",x) x = re.sub(self.replaceBR,"\n",x) x = re.sub(self.removeExtraTag,"",x) x = re.sub(self.removeNoneLine,"\n",x) #strip()е∞ЖеЙНеРОе§ЪдљЩеЖЕеЃєеИ†йЩ§ return x.strip()дї•дЄКдЄ§дЄ™жЦЗдїґе∞±жШѓжЙАжЬЙзЪДдї£з†БеЖЕеЃєпЉМињРи°МдЄАдЄЛиѓХиѓХзЬЛпЉМйВ£еПЂдЄАдЄ™йЕЄзИљеХК

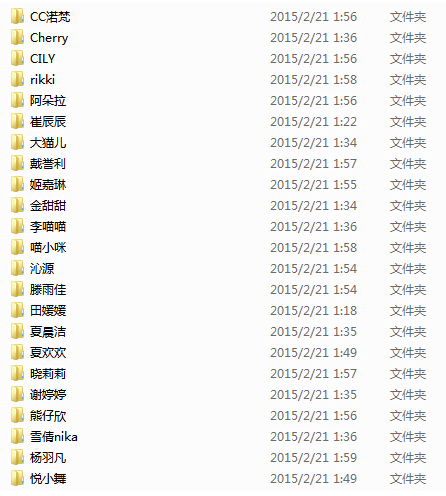
зЬЛзЬЛжЦЗдїґе§єйЗМйЭҐжЬЙдїАдєИеПШеМЦ
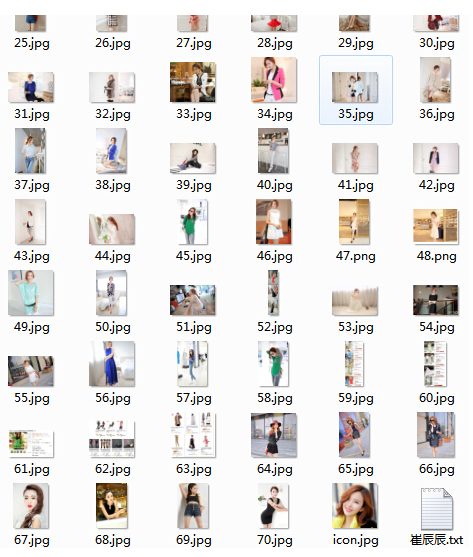
дЄНзЯ•дЄНиІЙпЉМжµЈйЗПзЪДMMеЫЊзЙЗеЈ≤зїПињЫеЕ•дЇЖдљ†зЪДзФµиДСпЉМињШдЄНењЂењЂеОїиѓХиѓХзЬЛпЉБпЉБ
дї•дЄКжШѓжКУеПЦжЈШеЃЭMMзЪДжЦєж≥ХзЪДжЙАжЬЙеЖЕеЃєпЉМжДЯи∞ҐеРДдљНзЪДйШЕиѓїпЉБеЄМжЬЫеИЖдЇЂзЪДеЖЕеЃєеѓєе§ІеЃґжЬЙеЄЃеК©пЉМжЫіе§ЪзЫЄеЕ≥зЯ•иѓЖпЉМ搥ињОеЕ≥ж≥®дЇњйАЯдЇСи°МдЄЪиµДиЃѓйҐСйБУпЉБ
еЕНиі£е£∞жШОпЉЪжЬђзЂЩеПСеЄГзЪДеЖЕеЃєпЉИеЫЊзЙЗгАБиІЖйҐСеТМжЦЗе≠ЧпЉЙдї•еОЯеИЫгАБиљђиљљеТМеИЖдЇЂдЄЇдЄїпЉМжЦЗзЂ†иІВзВєдЄНдї£и°®жЬђзљСзЂЩзЂЛеЬЇпЉМе¶ВжЮЬжґЙеПКдЊµжЭГиѓЈиБФз≥їзЂЩйХњйВЃзЃ±пЉЪis@yisu.comињЫи°МдЄЊжК•пЉМеєґжПРдЊЫзЫЄеЕ≥иѓБжНЃпЉМдЄАзїПжЯ•еЃЮпЉМе∞ЖзЂЛеИїеИ†йЩ§жґЙеЂМдЊµжЭГеЖЕеЃєгАВ

дЇњйАЯдЇСеЕђдЉЧеПЈ

жЙЛжЬЇзљСзЂЩдЇМзїіз†Б



