жё©йҰЁжҸҗзӨәГ—
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•Г—
зҷ»еҪ•жіЁеҶҢГ—
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
з”ЁжҲ·зҷ»еҪ•Г—
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
жҳҜиҝҷж ·зҡ„пјҢд№ӢеүҚд№°иҪҰйҖҒзҡ„еһғеңҫи®°еҪ•д»ӘдёҚиғҪз”ЁдәҶпјҢиҝҷдёӨеӨ©зӢ еҝғд№°дәҶеҘҪзӮ№зҡ„и®°еҪ•д»ӘпјҢеёҰеҜјиҲӘгҖҒйҹід№җгҖҒи“қзүҷгҖҒ4GзӯүеҠҹиғҪпјҢеҜ»жҖқпјҢ既然жңүиҝҷдәӣеҠҹиғҪе°ұеҲ©з”Ёиө·жқҘпјҢз”Ё4Gеҗ¬жӯҢжңүзӮ№еҘўдҫҲпјҢе°ұеҮҶеӨҮеҺ»й…·зӢ—дёӢзӮ№жӯҢеҗ¬пјҢеұ…然йғҪжҳҜйңҖиҰҒеҠһдјҡе‘ҳжүҚиғҪдёӢиҪҪпјҢиҖҢдё”vipдёҖжңҲеҸӘиғҪдёӢиҪҪ300йҰ–пјҢжҲ‘иҝҷд№Ҳз©·еҸҲиҝҷд№ҲжҠ жҖҺд№ҲеҸҜиғҪеҶІдјҡе‘ҳпјҢдәҺжҳҜзҷҫеәҰжҗңдәҶдёӢжҖҺд№Ҳе…Қиҙ№дёӢиҪҪпјҢйғҪжҳҜpythonзҲ¬еҸ–пјҢиҷҪ然д№ҹдјҡдёҖзӮ№пјҢдҪҶжҳҜз”өи„‘дёҠжІЎе®үиЈ…pythonпјҢеҶҚе®үиЈ…еҶҚз ”з©¶ж„ҹи§үжңүзӮ№иҙ№еҠІпјҢдәҺжҳҜе°ұиҠұдәҶеҚҠе°Ҹж—¶еҒҡдәҶиҝҷдёӘзҲ¬иҷ«пјҢжҠҖжңҜдёҖиҲ¬пјҢеҸӘи®°еҪ•еҲҶжһҗе®һзҺ°иҝҮзЁӢпјҢеӨ§зүӣиҜ·з»•иЎҢгҖӮе…¶дёӯз”ЁеҲ°дәҶдёҖдәӣеә“пјҢеҢ…жӢ¬пјҡjsoupгҖҒHttpClientгҖҒnet.sf.jsonеӨ§е®¶еҸҜд»ҘиҮӘиЎҢеҺ»дёӢиҪҪjarеҢ…
1гҖҒеҲҶжһҗжҳҜеҗҰиғҪиҺ·еҫ—TOP500жӯҢеҚ•
йҰ–е…ҲпјҢжү“ејҖй…·зӢ—йҰ–йЎөжҹҘзңӢй…·зӢ—TOP500пјҢиҜҙеҘҪзҡ„500йҰ–пјҢжҖҺд№Ҳе°ұеҸӘжңү22йҰ–е‘ўпјҢ
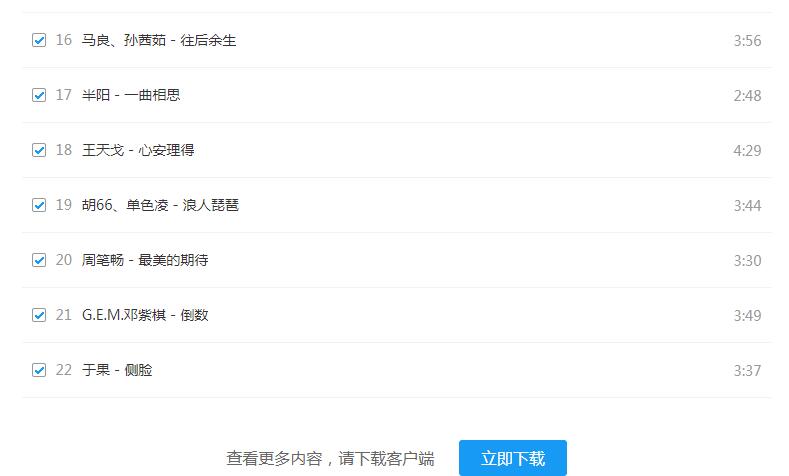
жҳҜзңҹзҡ„еҸӘи®©зңӢиҝҷдәӣиҝҳжҳҜиғҪжүҫеҲ°е…¶дҪҷзҡ„е‘ўпјҢдәҺжҳҜжҲ‘е°ұзңӢдәҶдёӢиҝҷTOP500зҡ„й“ҫжҺҘ
https://www.kugou.com/yy/rank/home/1-8888.html?from=rank
еҸҜд»ҘзңӢзҡ„еҮәhomeеҗҺиҫ№жңүдёӘ1пјҢйҡҫйҒ“иҝҷжҳҜ代表第дёҖйЎөзҡ„ж„ҸжҖқпјҹдәҺжҳҜжҲ‘е°ұжҠҠ1ж”№жҲҗ2пјҢиҝӣе…ҘпјҢжһң然иҝӣе…ҘдәҶ第дәҢйЎөпјҢиҮіжӯӨеҸҜд»ҘзҹҘйҒ“жҲ‘们еҸҜд»ҘеңЁзҪ‘йЎөйҮҢиҺ·еҸ–иҝҷ500йҰ–зҡ„жӯҢеҚ•гҖӮ
2.еҲҶжһҗжүҫеҲ°зңҹжӯЈзҡ„mp3дёӢиҪҪең°еқҖпјҲиҝҷдёӘжңүзӮ№з»•пјү
зӮ№дёҖдёӘжӯҢжӣІиҝӣе…Ҙж’ӯж”ҫйЎөйқўпјҢдҪҝз”Ёи°·жӯҢжөҸи§ҲеҷЁзҡ„жҺ§еҲ¶еҸ°зҡ„ElementsпјҢжҗңдёҖдёӢmp3пјҢеҫҲиҪ»жқҫе°ұе®ҡдҪҚеҲ°дәҶMP3зҡ„дҪҚзҪ®пјҢ
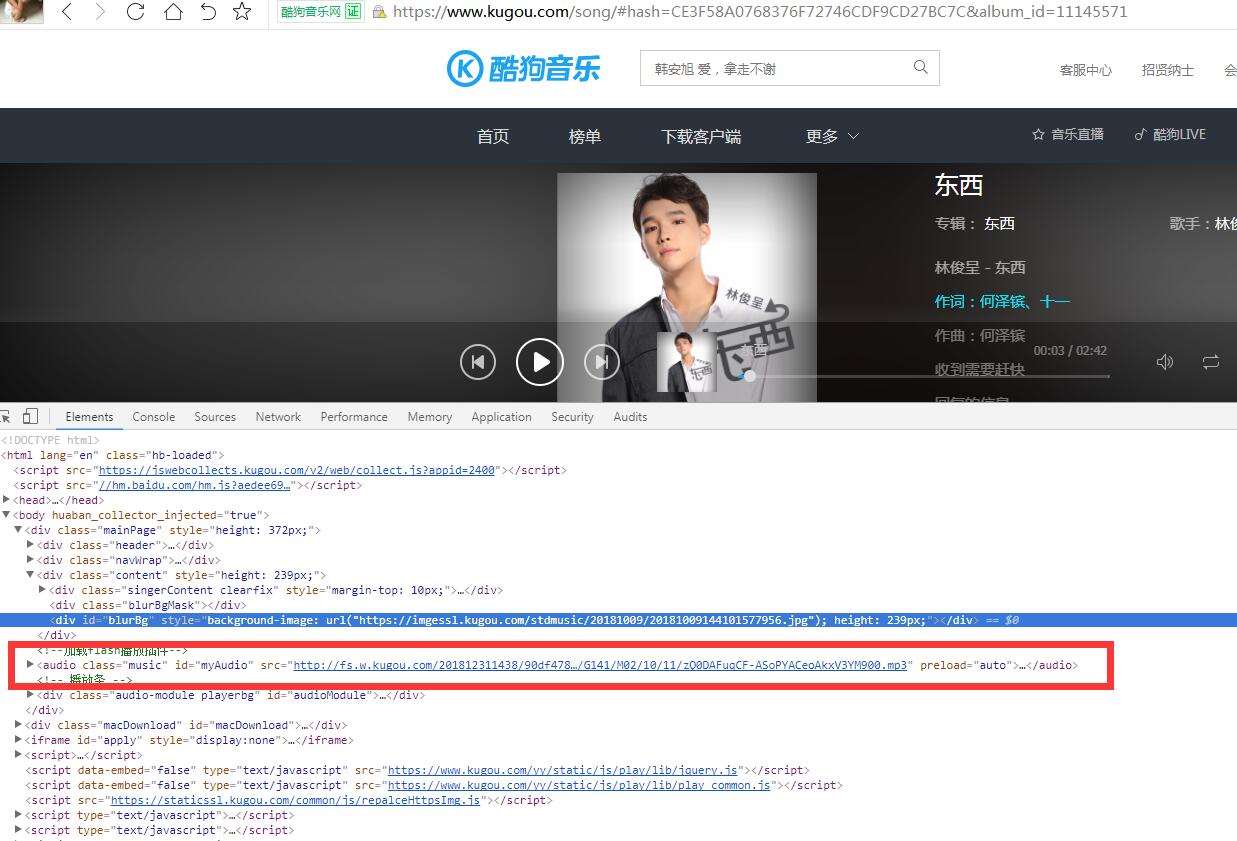
дҪҶжҳҜдҪҝз”Ёjavaи®ҝй—®зҡ„ж—¶еҖҷзҲ¬еҸ–зҡ„htmlйҮҢеҚҙжІЎжңүиҜҘmp3зҡ„ж–Ү件ең°еқҖпјҢйӮЈд№ҲиҝҷиӮҜе®ҡжҳҜеңЁиҜҘйЎөйқўзҡ„дҪҚзҪ®дҪҝз”ЁдәҶjsжқҘеҠ иҪҪmp3пјҢйӮЈд№ҲеҲ·ж–°дёӢзҪ‘йЎөпјҢзңӢзҪ‘йЎөеҠ иҪҪдәҶе“ӘдәӣдёңиҘҝпјҢеҠ иҪҪзҡ„дёңиҘҝжңүзӮ№еӨҡпјҢзқҖйҮҚзңӢдёҖдёӢjsгҖҒphpзҡ„иҜ·жұӮпјҢдё»иҰҒжҳҜзңӢйҮҢйқўжңүжІЎжңүmp3зҡ„ең°еқҖпјҢеҲҶжһҗз»ҶиҠӮе°ұдёҚз”ЁиҜҙдәҶпјҢ
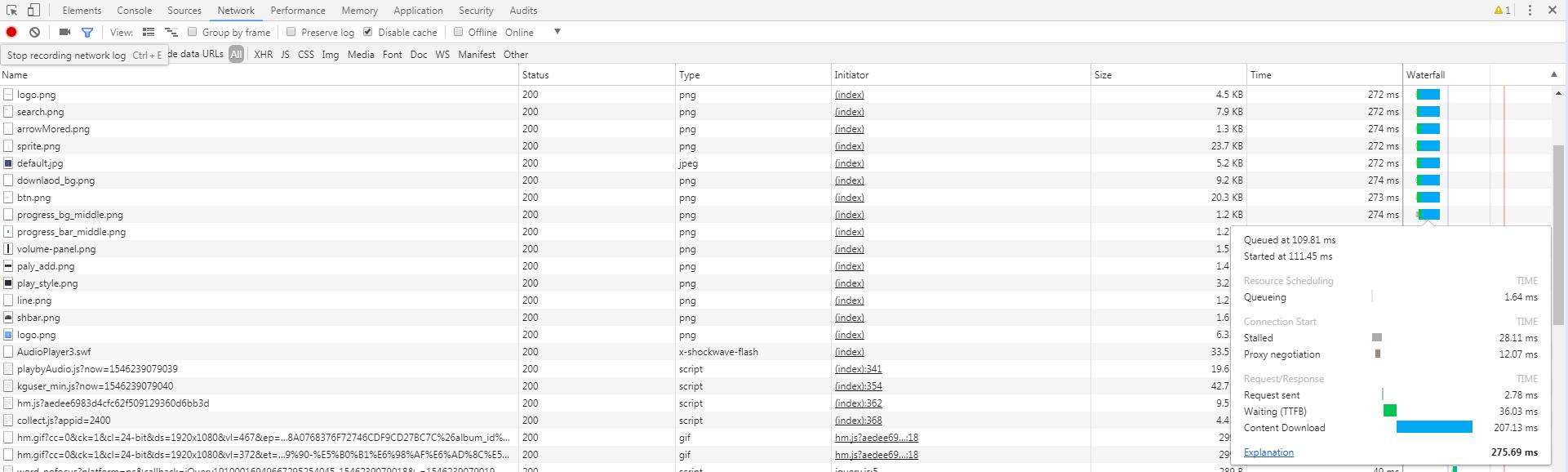
жңҖз»ҲжҲ‘еңЁеҲ—иЎЁзҡ„
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery191027067069941080546_1546235744250&hash=667939C6E784265D541DEEE65AE4F2F8&album_id=0&_=1546235744251
иҝҷдёӘиҜ·жұӮйҮҢеҸ‘зҺ°дәҶmp3зҡ„е®Ңж•ҙең°еқҖпјҢ
"play_url": "http:\/\/fs.w.kugou.com\/201812311325\/dcf5b6449160903c6ee48035e11434bb\/G128\/M08\/02\/09\/IIcBAFrZqf2ANOadADn94ubOmaU995.mp3",
йӮЈиҝҷдёӘjsжҳҜжҖҺд№ҲеҲӨж–ӯжҳҜе“ӘйҰ–жӯҢзҡ„е‘ўпјҢйӮЈд№ҲеҸӘеҸҜиғҪжҳҜhashиҝҷдёӘеҸӮж•°жқҘеҶіе®ҡжӯҢжӣІзҡ„пјҢ然еҗҺеҲ°ж’ӯж”ҫйЎөйқўйҮҢжүҫеҲ°иҝҷдёӘhashзҡ„дҪҚзҪ®пјҢжҳҜеңЁдёӢйқўзҡ„jsйҮҢ
var dataFromSmarty = [{"hash":"667939C6E784265D541DEEE65AE4F2F8","timelength":"237051","audio_name":"\u767d\u5c0f\u767d - \u6700\u7f8e\u5a5a\u793c","author_name":"\u767d\u5c0f\u767d","song_name":"\u6700\u7f8e\u5a5a\u793c","album_id":0}],//еҪ“еүҚйЎөйқўжӯҢжӣІдҝЎжҒҜ playType = "search_single";//еҪ“еүҚж’ӯж”ҫ </script> еңЁеҺ»javaзҲ¬еҸ–иҜҘзҪ‘йЎөпјҢжҹҘзңӢиғҪеҗҰзҲ¬еҲ°иҝҷдёӘhashпјҢжһң然пјҢзҲ¬еҸ–зҡ„htmlйҮҢжңүиҝҷж®өjsпјҢеҲ°зҺ°еңЁmp3зҡ„ең°еқҖд№ҹжүҫеҲ°дәҶпјҢжӯҢеҚ•д№ҹжүҫеҲ°дәҶпјҢйӮЈд№ҲдёӢдёҖжӯҘе°ұз”ЁзЁӢеәҸе®һзҺ°е°ұеҸҜд»ҘдәҶгҖӮ
3.javaе®һзҺ°зҲ¬еҸ–й…·зӢ—mp3
е…ҲзңӢдёҖдёӢзҲ¬еҸ–з»“жһң
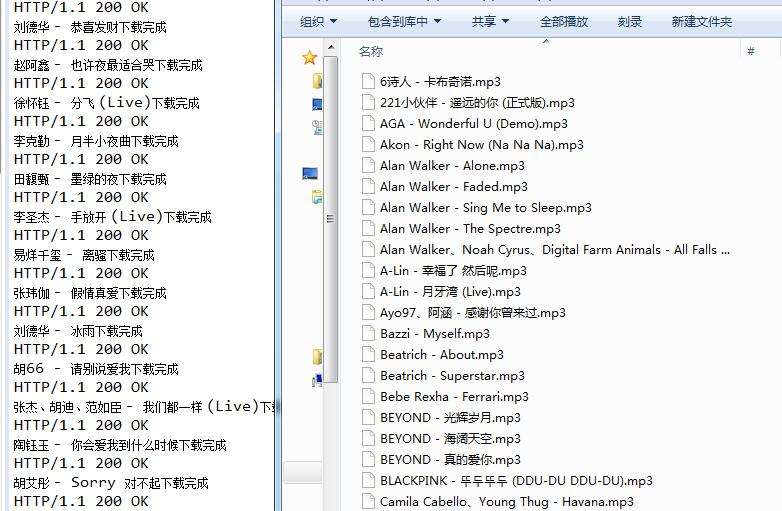
жүҫеҲ°дәҶиө„жәҗпјҢзЁӢеәҸе®һзҺ°е°ұеҘҪиҜҙдәҶпјҢе…¶дёӯдҪҝз”ЁеҲ°дәҶиҮӘе·ұеҶҷзҡ„еҮ дёӘе·Ҙе…·зұ»пјҢиҮӘе·ұж•ҙзҗҶзӮ№иҮӘе·ұзҡ„е·Ҙе…·зұ»иҝҳжҳҜжңүеҘҪеӨ„зҡ„пјҢд»ҘеҗҺйҒҮеҲ°д»Җд№Ҳй—®йўҳе°ұжІЎеҝ…иҰҒйҮҚж–°еҶҷдәҶпјҢзӣҙжҺҘжӢҝжқҘз”Ёе°ұеҸҜд»ҘдәҶгҖӮжІЎд»Җд№ҲеҘҪиҜҙзҡ„дәҶпјҢдёӢйқўзӣҙжҺҘиҙҙеҮәжәҗз Ғ
SpiderKugou.java
package com.bing.spider; import java.io.IOException; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import com.bing.download.FileDownload; import com.bing.html.HtmlManage; import com.bing.http.HttpGetConnect; import net.sf.json.JSONObject; public class SpiderKugou { public static String filePath = "F:/music/"; public static String mp3 = "https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery191027067069941080546_1546235744250&" + "hash=HASH&album_id=0&_=TIME"; public static String LINK = "https://www.kugou.com/yy/rank/home/PAGE-8888.html?from=rank"; //"https://www.kugou.com/yy/rank/home/PAGE-23784.html?from=rank"; public static void main(String[] args) throws IOException { for(int i = 1 ; i < 23 ; i++){ String url = LINK.replace("PAGE", i + ""); getTitle(url); //download("https://www.kugou.com/song/mfy6je5.html"); } } public static String getTitle(String url) throws IOException{ HttpGetConnect connect = new HttpGetConnect(); String content = connect.connect(url, "utf-8"); HtmlManage html = new HtmlManage(); Document doc = html.manage(content); Element ele = doc.getElementsByClass("pc_temp_songlist").get(0); Elements eles = ele.getElementsByTag("li"); for(int i = 0 ; i < eles.size() ; i++){ Element item = eles.get(i); String title = item.attr("title").trim(); String link = item.getElementsByTag("a").first().attr("href"); download(link,title); } return null; } public static String download(String url,String name) throws IOException{ String hash = ""; HttpGetConnect connect = new HttpGetConnect(); String content = connect.connect(url, "utf-8"); HtmlManage html = new HtmlManage(); String regEx = "\"hash\":\"[0-9A-Z]+\""; // зј–иҜ‘жӯЈеҲҷиЎЁиҫҫејҸ Pattern pattern = Pattern.compile(regEx); Matcher matcher = pattern.matcher(content); if (matcher.find()) { hash = matcher.group(); hash = hash.replace("\"hash\":\"", ""); hash = hash.replace("\"", ""); } String item = mp3.replace("HASH", hash); item = item.replace("TIME", System.currentTimeMillis() + ""); System.out.println(item); String mp = connect.connect(item, "utf-8"); mp = mp.substring(mp.indexOf("(") + 1, mp.length() - 3); JSONObject json = JSONObject.fromObject(mp); String playUrl = json.getJSONObject("data").getString("play_url"); System.out.print(playUrl + " == "); FileDownload down = new FileDownload(); down.download(playUrl, filePath + name + ".mp3"); System.out.println(name + "дёӢиҪҪе®ҢжҲҗ"); return playUrl; } } HttpGetConnect.java
package com.bing.http; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.security.NoSuchAlgorithmException; import java.security.cert.CertificateException; import java.security.cert.X509Certificate; import javax.net.ssl.SSLContext; import javax.net.ssl.TrustManager; import javax.net.ssl.X509TrustManager; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.apache.http.HttpEntity; import org.apache.http.client.ClientProtocolException; import org.apache.http.client.HttpClient; import org.apache.http.client.ResponseHandler; import org.apache.http.client.config.RequestConfig; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.conn.ClientConnectionManager; import org.apache.http.conn.scheme.Scheme; import org.apache.http.conn.scheme.SchemeRegistry; import org.apache.http.conn.ssl.SSLSocketFactory; import org.apache.http.impl.client.BasicResponseHandler; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.DefaultHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.impl.conn.BasicHttpClientConnectionManager; import org.apache.http.params.HttpParams; /** * @иҜҙжҳҺпјҡ * @author: gaoll * @CreateTime:2014-11-13 * @ModifyTime:2014-11-13 */ public class HttpGetConnect { /** * иҺ·еҸ–htmlеҶ…е®№ * @param url * @param charsetName UTF-8гҖҒGB2312 * @return * @throws IOException */ public static String connect(String url,String charsetName) throws IOException{ BasicHttpClientConnectionManager connManager = new BasicHttpClientConnectionManager(); CloseableHttpClient httpclient = HttpClients.custom() .setConnectionManager(connManager) .build(); String content = ""; try{ HttpGet httpget = new HttpGet(url); RequestConfig requestConfig = RequestConfig.custom() .setSocketTimeout(5000) .setConnectTimeout(50000) .setConnectionRequestTimeout(50000) .build(); httpget.setConfig(requestConfig); httpget.setHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"); httpget.setHeader("Accept-Encoding", "gzip,deflate,sdch"); httpget.setHeader("Accept-Language", "zh-CN,zh;q=0.8"); httpget.setHeader("Connection", "keep-alive"); httpget.setHeader("Upgrade-Insecure-Requests", "1"); httpget.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"); //httpget.setHeader("Hosts", "www.oschina.net"); httpget.setHeader("cache-control", "max-age=0"); CloseableHttpResponse response = httpclient.execute(httpget); int status = response.getStatusLine().getStatusCode(); if (status >= 200 && status < 300) { HttpEntity entity = response.getEntity(); InputStream instream = entity.getContent(); BufferedReader br = new BufferedReader(new InputStreamReader(instream,charsetName)); StringBuffer sbf = new StringBuffer(); String line = null; while ((line = br.readLine()) != null){ sbf.append(line + "\n"); } br.close(); content = sbf.toString(); } else { content = ""; } }catch(Exception e){ e.printStackTrace(); }finally{ httpclient.close(); } //log.info("content is " + content); return content; } private static Log log = LogFactory.getLog(HttpGetConnect.class); } HtmlManage.java
package com.bing.html; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import com.bing.http.HttpGetConnect; /** * @иҜҙжҳҺпјҡ * @author: gaoll * @CreateTime:2014-11-13 * @ModifyTime:2014-11-13 */ public class HtmlManage { public Document manage(String html){ Document doc = Jsoup.parse(html); return doc; } public Document manageDirect(String url) throws IOException{ Document doc = Jsoup.connect( url ).get(); return doc; } public List<String> manageHtmlTag(Document doc,String tag ){ List<String> list = new ArrayList<String>(); Elements elements = doc.getElementsByTag(tag); for(int i = 0; i < elements.size() ; i++){ String str = elements.get(i).html(); list.add(str); } return list; } public List<String> manageHtmlClass(Document doc,String clas ){ List<String> list = new ArrayList<String>(); Elements elements = doc.getElementsByClass(clas); for(int i = 0; i < elements.size() ; i++){ String str = elements.get(i).html(); list.add(str); } return list; } public List<String> manageHtmlKey(Document doc,String key,String value ){ List<String> list = new ArrayList<String>(); Elements elements = doc.getElementsByAttributeValue(key, value); for(int i = 0; i < elements.size() ; i++){ String str = elements.get(i).html(); list.add(str); } return list; } private static Log log = LogFactory.getLog(HtmlManage.class); } FileDownload.java
package com.bing.download; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.File; import java.io.FileOutputStream; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.apache.http.client.config.RequestConfig; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; /** * @иҜҙжҳҺпјҡ * @author: gaoll * @CreateTime:2014-11-20 * @ModifyTime:2014-11-20 */ public class FileDownload { /** * ж–Ү件дёӢиҪҪ * @param url й“ҫжҺҘең°еқҖ * @param path иҰҒдҝқеӯҳзҡ„и·Ҝеҫ„еҸҠж–Ү件еҗҚ * @return */ public static boolean download(String url,String path){ boolean flag = false; CloseableHttpClient httpclient = HttpClients.createDefault(); RequestConfig requestConfig = RequestConfig.custom().setSocketTimeout(2000) .setConnectTimeout(2000).build(); HttpGet get = new HttpGet(url); get.setConfig(requestConfig); BufferedInputStream in = null; BufferedOutputStream out = null; try{ for(int i=0;i<3;i++){ CloseableHttpResponse result = httpclient.execute(get); System.out.println(result.getStatusLine()); if(result.getStatusLine().getStatusCode() == 200){ in = new BufferedInputStream(result.getEntity().getContent()); File file = new File(path); out = new BufferedOutputStream(new FileOutputStream(file)); byte[] buffer = new byte[1024]; int len = -1; while((len = in.read(buffer,0,1024)) > -1){ out.write(buffer,0,len); } flag = true; break; }else if(result.getStatusLine().getStatusCode() == 500){ continue ; } } }catch(Exception e){ e.printStackTrace(); flag = false; }finally{ get.releaseConnection(); try{ if(in != null){ in.close(); } if(out != null){ out.close(); } }catch(Exception e){ e.printStackTrace(); flag = false; } } return flag; } private static Log log = LogFactory.getLog(FileDownload.class); } еҲ°иҝҷе°ұз»“жқҹдәҶпјҢжңүеҸҜиғҪжңүдәӣд»Јз ҒжІЎиҙҙе…ЁпјҢдё»иҰҒд»Јз Ғе·Із»Ҹе·®дёҚеӨҡпјҢеә”иҜҘеҸҜд»Ҙи·‘иө·жқҘпјҢеӨҡеӨҡжҢҮж•ҷгҖӮ
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ

дәҝйҖҹдә‘е…¬дј—еҸ·

жүӢжңәзҪ‘з«ҷдәҢз»ҙз Ғ



