本篇文章为大家展示了Python+Tensorflow+CNN实现车牌识别,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
import os import cv2 as cv import numpy as np from math import * from PIL import ImageFont from PIL import Image from PIL import ImageDraw index = {"京": 0, "沪": 1, "津": 2, "渝": 3, "冀": 4, "晋": 5, "蒙": 6, "辽": 7, "吉": 8, "黑": 9, "苏": 10, "浙": 11, "皖": 12, "闽": 13, "赣": 14, "鲁": 15, "豫": 16, "鄂": 17, "湘": 18, "粤": 19, "桂": 20, "琼": 21, "川": 22, "贵": 23, "云": 24, "藏": 25, "陕": 26, "甘": 27, "青": 28, "宁": 29, "新": 30, "0": 31, "1": 32, "2": 33, "3": 34, "4": 35, "5": 36, "6": 37, "7": 38, "8": 39, "9": 40, "A": 41, "B": 42, "C": 43, "D": 44, "E": 45, "F": 46, "G": 47, "H": 48, "J": 49, "K": 50, "L": 51, "M": 52, "N": 53, "P": 54, "Q": 55, "R": 56, "S": 57, "T": 58, "U": 59, "V": 60, "W": 61, "X": 62, "Y": 63, "Z": 64} chars = ["京", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "皖", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z"] def AddSmudginess(img, Smu): """ 模糊处理 :param img: 输入图像 :param Smu: 模糊图像 :return: 添加模糊后的图像 """ rows = r(Smu.shape[0] - 50) cols = r(Smu.shape[1] - 50) adder = Smu[rows:rows + 50, cols:cols + 50] adder = cv.resize(adder, (50, 50)) img = cv.resize(img,(50,50)) img = cv.bitwise_not(img) img = cv.bitwise_and(adder, img) img = cv.bitwise_not(img) return img def rot(img, angel, shape, max_angel): """ 添加透视畸变 """ size_o = [shape[1], shape[0]] size = (shape[1]+ int(shape[0] * cos((float(max_angel ) / 180) * 3.14)), shape[0]) interval = abs(int(sin((float(angel) / 180) * 3.14) * shape[0])) pts1 = np.float32([[0, 0], [0, size_o[1]], [size_o[0], 0], [size_o[0], size_o[1]]]) if angel > 0: pts2 = np.float32([[interval, 0], [0, size[1]], [size[0], 0], [size[0] - interval, size_o[1]]]) else: pts2 = np.float32([[0, 0], [interval, size[1]], [size[0] - interval, 0], [size[0], size_o[1]]]) M = cv.getPerspectiveTransform(pts1, pts2) dst = cv.warpPerspective(img, M, size) return dst def rotRandrom(img, factor, size): """ 添加放射畸变 :param img: 输入图像 :param factor: 畸变的参数 :param size: 图片目标尺寸 :return: 放射畸变后的图像 """ shape = size pts1 = np.float32([[0, 0], [0, shape[0]], [shape[1], 0], [shape[1], shape[0]]]) pts2 = np.float32([[r(factor), r(factor)], [r(factor), shape[0] - r(factor)], [shape[1] - r(factor), r(factor)], [shape[1] - r(factor), shape[0] - r(factor)]]) M = cv.getPerspectiveTransform(pts1, pts2) dst = cv.warpPerspective(img, M, size) return dst def tfactor(img): """ 添加饱和度光照的噪声 """ hsv = cv.cvtColor(img,cv.COLOR_BGR2HSV) hsv[:, :, 0] = hsv[:, :, 0] * (0.8 + np.random.random() * 0.2) hsv[:, :, 1] = hsv[:, :, 1] * (0.3 + np.random.random() * 0.7) hsv[:, :, 2] = hsv[:, :, 2] * (0.2 + np.random.random() * 0.8) img = cv.cvtColor(hsv, cv.COLOR_HSV2BGR) return img def random_envirment(img, noplate_bg): """ 添加自然环境的噪声, noplate_bg为不含车牌的背景图 """ bg_index = r(len(noplate_bg)) env = cv.imread(noplate_bg[bg_index]) env = cv.resize(env, (img.shape[1], img.shape[0])) bak = (img == 0) bak = bak.astype(np.uint8) * 255 inv = cv.bitwise_and(bak, env) img = cv.bitwise_or(inv, img) return img def GenCh(f, val): """ 生成中文字符 """ img = Image.new("RGB", (45, 70), (255, 255, 255)) draw = ImageDraw.Draw(img) draw.text((0, 3), val, (0, 0, 0), font=f) img = img.resize((23, 70)) A = np.array(img) return A def GenCh2(f, val): """ 生成英文字符 """ img =Image.new("RGB", (23, 70), (255, 255, 255)) draw = ImageDraw.Draw(img) draw.text((0, 2), val, (0, 0, 0), font=f) # val.decode('utf-8') A = np.array(img) return A def AddGauss(img, level): """ 添加高斯模糊 """ return cv.blur(img, (level * 2 + 1, level * 2 + 1)) def r(val): return int(np.random.random() * val) def AddNoiseSingleChannel(single): """ 添加高斯噪声 """ diff = 255 - single.max() noise = np.random.normal(0, 1 + r(6), single.shape) noise = (noise - noise.min()) / (noise.max() - noise.min()) noise *= diff # noise= noise.astype(np.uint8) dst = single + noise return dst def addNoise(img): # sdev = 0.5,avg=10 img[:, :, 0] = AddNoiseSingleChannel(img[:, :, 0]) img[:, :, 1] = AddNoiseSingleChannel(img[:, :, 1]) img[:, :, 2] = AddNoiseSingleChannel(img[:, :, 2]) return img class GenPlate: def __init__(self, fontCh, fontEng, NoPlates): self.fontC = ImageFont.truetype(fontCh, 43, 0) self.fontE = ImageFont.truetype(fontEng, 60, 0) self.img = np.array(Image.new("RGB", (226, 70),(255, 255, 255))) self.bg = cv.resize(cv.imread("data\\images\\template.bmp"), (226, 70)) # template.bmp:车牌背景图 self.smu = cv.imread("data\\images\\smu2.jpg") # smu2.jpg:模糊图像 self.noplates_path = [] for parent, parent_folder, filenames in os.walk(NoPlates): for filename in filenames: path = parent + "\\" + filename self.noplates_path.append(path) def draw(self, val): offset = 2 self.img[0:70, offset+8:offset+8+23] = GenCh(self.fontC, val[0]) self.img[0:70, offset+8+23+6:offset+8+23+6+23] = GenCh2(self.fontE, val[1]) for i in range(5): base = offset + 8 + 23 + 6 + 23 + 17 + i * 23 + i * 6 self.img[0:70, base:base+23] = GenCh2(self.fontE, val[i+2]) return self.img def generate(self, text): if len(text) == 7: fg = self.draw(text) # decode(encoding="utf-8") fg = cv.bitwise_not(fg) com = cv.bitwise_or(fg, self.bg) com = rot(com, r(60)-30, com.shape,30) com = rotRandrom(com, 10, (com.shape[1], com.shape[0])) com = tfactor(com) com = random_envirment(com, self.noplates_path) com = AddGauss(com, 1+r(4)) com = addNoise(com) return com @staticmethod def genPlateString(pos, val): """ 生成车牌string,存为图片 生成车牌list,存为label """ plateStr = "" plateList=[] box = [0, 0, 0, 0, 0, 0, 0] if pos != -1: box[pos] = 1 for unit, cpos in zip(box, range(len(box))): if unit == 1: plateStr += val plateList.append(val) else: if cpos == 0: plateStr += chars[r(31)] plateList.append(plateStr) elif cpos == 1: plateStr += chars[41 + r(24)] plateList.append(plateStr) else: plateStr += chars[31 + r(34)] plateList.append(plateStr) plate = [plateList[0]] b = [plateList[i][-1] for i in range(len(plateList))] plate.extend(b[1:7]) return plateStr, plate @staticmethod def genBatch(batchsize, outputPath, size): """ 将生成的车牌图片写入文件夹,对应的label写入label.txt :param batchsize: 批次大小 :param outputPath: 输出图像的保存路径 :param size: 输出图像的尺寸 :return: None """ if not os.path.exists(outputPath): os.mkdir(outputPath) outfile = open('data\\plate\\label.txt', 'w', encoding='utf-8') for i in range(batchsize): plateStr, plate = G.genPlateString(-1, -1) # print(plateStr, plate) img = G.generate(plateStr) img = cv.resize(img, size) cv.imwrite(outputPath + "\\" + str(i).zfill(2) + ".jpg", img) outfile.write(str(plate) + "\n") if __name__ == '__main__': G = GenPlate("data\\font\\platech.ttf", 'data\\font\\platechar.ttf', "data\\NoPlates") G.genBatch(101, 'data\\plate', (272, 72))生成的车牌图像尺寸尽量不要超过300,本次尺寸选取:272 * 72
生成车牌所需文件:
字体文件:中文‘platech.ttf',英文及数字‘platechar.ttf'
背景图:来源于不含车牌的车辆裁剪图片
车牌(蓝底):template.bmp
噪声图像:smu2.jpg
车牌生成后保存至plate文件夹,示例如下:

三、数据导入
from genplate import * import matplotlib.pyplot as plt # 产生用于训练的数据 class OCRIter: def __init__(self, batch_size, width, height): super(OCRIter, self).__init__() self.genplate = GenPlate("data\\font\\platech.ttf", 'data\\font\\platechar.ttf', "data\\NoPlates") self.batch_size = batch_size self.height = height self.width = width def iter(self): data = [] label = [] for i in range(self.batch_size): img, num = self.gen_sample(self.genplate, self.width, self.height) data.append(img) label.append(num) return np.array(data), np.array(label) @staticmethod def rand_range(lo, hi): return lo + r(hi - lo) def gen_rand(self): name = "" label = list([]) label.append(self.rand_range(0, 31)) #产生车牌开头32个省的标签 label.append(self.rand_range(41, 65)) #产生车牌第二个字母的标签 for i in range(5): label.append(self.rand_range(31, 65)) #产生车牌后续5个字母的标签 name += chars[label[0]] name += chars[label[1]] for i in range(5): name += chars[label[i+2]] return name, label def gen_sample(self, genplate, width, height): num, label = self.gen_rand() img = genplate.generate(num) img = cv.resize(img, (height, width)) img = np.multiply(img, 1/255.0) return img, label #返回的label为标签,img为车牌图像 ''' # 测试代码 O = OCRIter(2, 272, 72) img, lbl = O.iter() for im in img: plt.imshow(im, cmap='gray') plt.show() print(img.shape) print(lbl) '''四、CNN模型构建
import tensorflow as tf def cnn_inference(images, keep_prob): W_conv = { 'conv1': tf.Variable(tf.random.truncated_normal([3, 3, 3, 32], stddev=0.1)), 'conv2': tf.Variable(tf.random.truncated_normal([3, 3, 32, 32], stddev=0.1)), 'conv3': tf.Variable(tf.random.truncated_normal([3, 3, 32, 64], stddev=0.1)), 'conv4': tf.Variable(tf.random.truncated_normal([3, 3, 64, 64], stddev=0.1)), 'conv5': tf.Variable(tf.random.truncated_normal([3, 3, 64, 128], stddev=0.1)), 'conv6': tf.Variable(tf.random.truncated_normal([3, 3, 128, 128], stddev=0.1)), 'fc1_1': tf.Variable(tf.random.truncated_normal([5*30*128, 65], stddev=0.01)), 'fc1_2': tf.Variable(tf.random.truncated_normal([5*30*128, 65], stddev=0.01)), 'fc1_3': tf.Variable(tf.random.truncated_normal([5*30*128, 65], stddev=0.01)), 'fc1_4': tf.Variable(tf.random.truncated_normal([5*30*128, 65], stddev=0.01)), 'fc1_5': tf.Variable(tf.random.truncated_normal([5*30*128, 65], stddev=0.01)), 'fc1_6': tf.Variable(tf.random.truncated_normal([5*30*128, 65], stddev=0.01)), 'fc1_7': tf.Variable(tf.random.truncated_normal([5*30*128, 65], stddev=0.01)), } b_conv = { 'conv1': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[32])), 'conv2': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[32])), 'conv3': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[64])), 'conv4': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[64])), 'conv5': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[128])), 'conv6': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[128])), 'fc1_1': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[65])), 'fc1_2': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[65])), 'fc1_3': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[65])), 'fc1_4': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[65])), 'fc1_5': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[65])), 'fc1_6': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[65])), 'fc1_7': tf.Variable(tf.constant(0.1, dtype=tf.float32, shape=[65])), } # 第1层卷积层 conv1 = tf.nn.conv2d(images, W_conv['conv1'], strides=[1,1,1,1], padding='VALID') conv1 = tf.nn.bias_add(conv1, b_conv['conv1']) conv1 = tf.nn.relu(conv1) # 第2层卷积层 conv2 = tf.nn.conv2d(conv1, W_conv['conv2'], strides=[1,1,1,1], padding='VALID') conv2 = tf.nn.bias_add(conv2, b_conv['conv2']) conv2 = tf.nn.relu(conv2) # 第1层池化层 pool1 = tf.nn.max_pool2d(conv2, ksize=[1,2,2,1], strides=[1,2,2,1], padding='VALID') # 第3层卷积层 conv3 = tf.nn.conv2d(pool1, W_conv['conv3'], strides=[1,1,1,1], padding='VALID') conv3 = tf.nn.bias_add(conv3, b_conv['conv3']) conv3 = tf.nn.relu(conv3) # 第4层卷积层 conv4 = tf.nn.conv2d(conv3, W_conv['conv4'], strides=[1,1,1,1], padding='VALID') conv4 = tf.nn.bias_add(conv4, b_conv['conv4']) conv4 = tf.nn.relu(conv4) # 第2层池化层 pool2 = tf.nn.max_pool2d(conv4, ksize=[1,2,2,1], strides=[1,2,2,1], padding='VALID') # 第5层卷积层 conv5 = tf.nn.conv2d(pool2, W_conv['conv5'], strides=[1,1,1,1], padding='VALID') conv5 = tf.nn.bias_add(conv5, b_conv['conv5']) conv5 = tf.nn.relu(conv5) # 第4层卷积层 conv6 = tf.nn.conv2d(conv5, W_conv['conv6'], strides=[1,1,1,1], padding='VALID') conv6 = tf.nn.bias_add(conv6, b_conv['conv6']) conv6 = tf.nn.relu(conv6) # 第3层池化层 pool3 = tf.nn.max_pool2d(conv6, ksize=[1,2,2,1], strides=[1,2,2,1], padding='VALID') #第1_1层全连接层 # print(pool3.shape) reshape = tf.reshape(pool3, [-1, 5 * 30 * 128]) fc1 = tf.nn.dropout(reshape, keep_prob) fc1_1 = tf.add(tf.matmul(fc1, W_conv['fc1_1']), b_conv['fc1_1']) #第1_2层全连接层 fc1_2 = tf.add(tf.matmul(fc1, W_conv['fc1_2']), b_conv['fc1_2']) #第1_3层全连接层 fc1_3 = tf.add(tf.matmul(fc1, W_conv['fc1_3']), b_conv['fc1_3']) #第1_4层全连接层 fc1_4 = tf.add(tf.matmul(fc1, W_conv['fc1_4']), b_conv['fc1_4']) #第1_5层全连接层 fc1_5 = tf.add(tf.matmul(fc1, W_conv['fc1_5']), b_conv['fc1_5']) #第1_6层全连接层 fc1_6 = tf.add(tf.matmul(fc1, W_conv['fc1_6']), b_conv['fc1_6']) #第1_7层全连接层 fc1_7 = tf.add(tf.matmul(fc1, W_conv['fc1_7']), b_conv['fc1_7']) return fc1_1, fc1_2, fc1_3, fc1_4, fc1_5, fc1_6, fc1_7 def calc_loss(logit1, logit2, logit3, logit4, logit5, logit6, logit7, labels): labels = tf.convert_to_tensor(labels, tf.int32) loss1 = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits( logits=logit1, labels=labels[:, 0])) tf.compat.v1.summary.scalar('loss1', loss1) loss2 = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits( logits=logit2, labels=labels[:, 1])) tf.compat.v1.summary.scalar('loss2', loss2) loss3 = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits( logits=logit3, labels=labels[:, 2])) tf.compat.v1.summary.scalar('loss3', loss3) loss4 = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits( logits=logit4, labels=labels[:, 3])) tf.compat.v1.summary.scalar('loss4', loss4) loss5 = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits( logits=logit5, labels=labels[:, 4])) tf.compat.v1.summary.scalar('loss5', loss5) loss6 = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits( logits=logit6, labels=labels[:, 5])) tf.compat.v1.summary.scalar('loss6', loss6) loss7 = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits( logits=logit7, labels=labels[:, 6])) tf.compat.v1.summary.scalar('loss7', loss7) return loss1, loss2, loss3, loss4, loss5, loss6, loss7 def train_step(loss1, loss2, loss3, loss4, loss5, loss6, loss7, learning_rate): optimizer1 = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate) train_op1 = optimizer1.minimize(loss1) optimizer2 = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate) train_op2 = optimizer2.minimize(loss2) optimizer3 = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate) train_op3 = optimizer3.minimize(loss3) optimizer4 = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate) train_op4 = optimizer4.minimize(loss4) optimizer5 = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate) train_op5 = optimizer5.minimize(loss5) optimizer6 = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate) train_op6 = optimizer6.minimize(loss6) optimizer7 = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate) train_op7 = optimizer7.minimize(loss7) return train_op1, train_op2, train_op3, train_op4, train_op5, train_op6, train_op7 def pred_model(logit1, logit2, logit3, logit4, logit5, logit6, logit7, labels): labels = tf.convert_to_tensor(labels, tf.int32) labels = tf.reshape(tf.transpose(labels), [-1]) logits = tf.concat([logit1, logit2, logit3, logit4, logit5, logit6, logit7], 0) prediction = tf.nn.in_top_k(logits, labels, 1) accuracy = tf.reduce_mean(tf.cast(prediction, tf.float32)) tf.compat.v1.summary.scalar('accuracy', accuracy) return accuracy五、模型训练
import os import time import datetime import numpy as np import tensorflow as tf from input_data import OCRIter import model os.environ["TF_CPP_MIN_LOG_LEVEL"] = '3' img_h = 72 img_w = 272 num_label = 7 batch_size = 32 epoch = 10000 learning_rate = 0.0001 logs_path = 'logs\\1005' model_path = 'saved_model\\1005' image_holder = tf.compat.v1.placeholder(tf.float32, [batch_size, img_h, img_w, 3]) label_holder = tf.compat.v1.placeholder(tf.int32, [batch_size, 7]) keep_prob = tf.compat.v1.placeholder(tf.float32) def get_batch(): data_batch = OCRIter(batch_size, img_h, img_w) image_batch, label_batch = data_batch.iter() return np.array(image_batch), np.array(label_batch) logit1, logit2, logit3, logit4, logit5, logit6, logit7 = model.cnn_inference( image_holder, keep_prob) loss1, loss2, loss3, loss4, loss5, loss6, loss7 = model.calc_loss( logit1, logit2, logit3, logit4, logit5, logit6, logit7, label_holder) train_op1, train_op2, train_op3, train_op4, train_op5, train_op6, train_op7 = model.train_step( loss1, loss2, loss3, loss4, loss5, loss6, loss7, learning_rate) accuracy = model.pred_model(logit1, logit2, logit3, logit4, logit5, logit6, logit7, label_holder) input_image=tf.compat.v1.summary.image('input', image_holder) summary_op = tf.compat.v1.summary.merge(tf.compat.v1.get_collection(tf.compat.v1.GraphKeys.SUMMARIES)) init_op = tf.compat.v1.global_variables_initializer() with tf.compat.v1.Session() as sess: sess.run(init_op) train_writer = tf.compat.v1.summary.FileWriter(logs_path, sess.graph) saver = tf.compat.v1.train.Saver() start_time1 = time.time() for step in range(epoch): # 生成车牌图像以及标签数据 img_batch, lbl_batch = get_batch() start_time2 = time.time() time_str = datetime.datetime.now().isoformat() feed_dict = {image_holder:img_batch, label_holder:lbl_batch, keep_prob:0.6} _1, _2, _3, _4, _5, _6, _7, ls1, ls2, ls3, ls4, ls5, ls6, ls7, acc = sess.run( [train_op1, train_op2, train_op3, train_op4, train_op5, train_op6, train_op7, loss1, loss2, loss3, loss4, loss5, loss6, loss7, accuracy], feed_dict) summary_str = sess.run(summary_op, feed_dict) train_writer.add_summary(summary_str,step) duration = time.time() - start_time2 loss_total = ls1 + ls2 + ls3 + ls4 + ls5 + ls6 + ls7 if step % 10 == 0: sec_per_batch = float(duration) print('%s: Step %d, loss_total = %.2f, acc = %.2f%%, sec/batch = %.2f' % (time_str, step, loss_total, acc * 100, sec_per_batch)) if step % 5000 == 0 or (step + 1) == epoch: checkpoint_path = os.path.join(model_path,'model.ckpt') saver.save(sess, checkpoint_path, global_step=step) end_time = time.time() print("Training over. It costs {:.2f} minutes".format((end_time - start_time1) / 60))六、训练结果展示
训练参数:
batch_size = 32
epoch = 10000
learning_rate = 0.0001
在tensorboard中查看训练过程
accuracy :
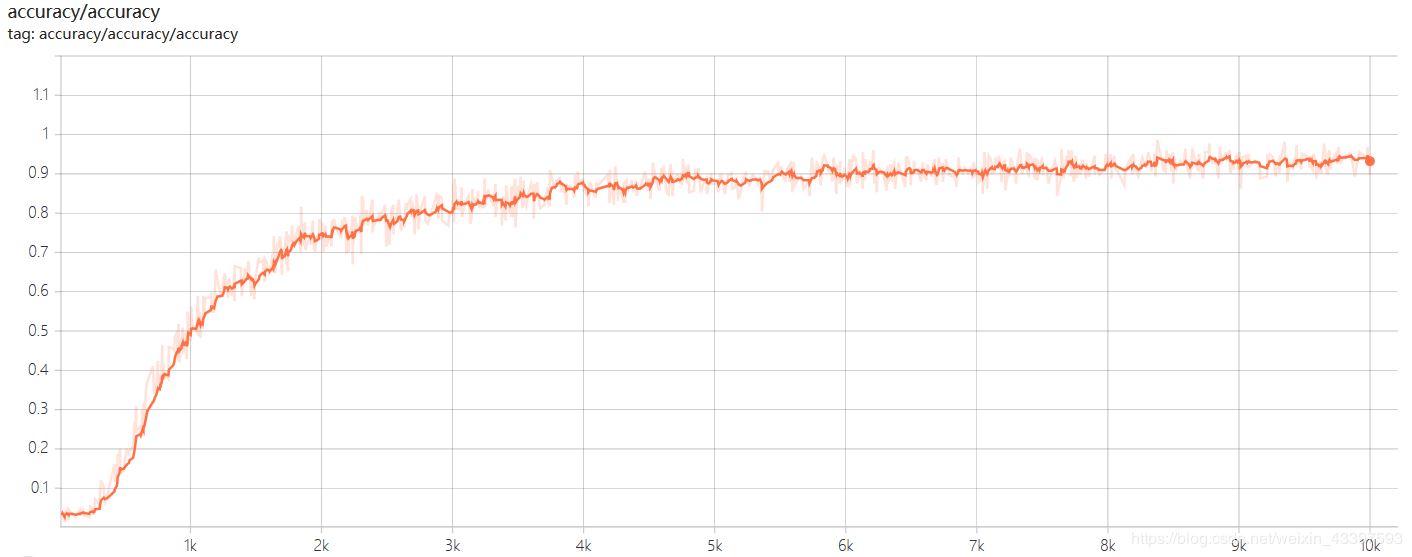 accuracy
accuracy
曲线在epoch = 10000左右时达到收敛,最终精确度在94%左右
loss :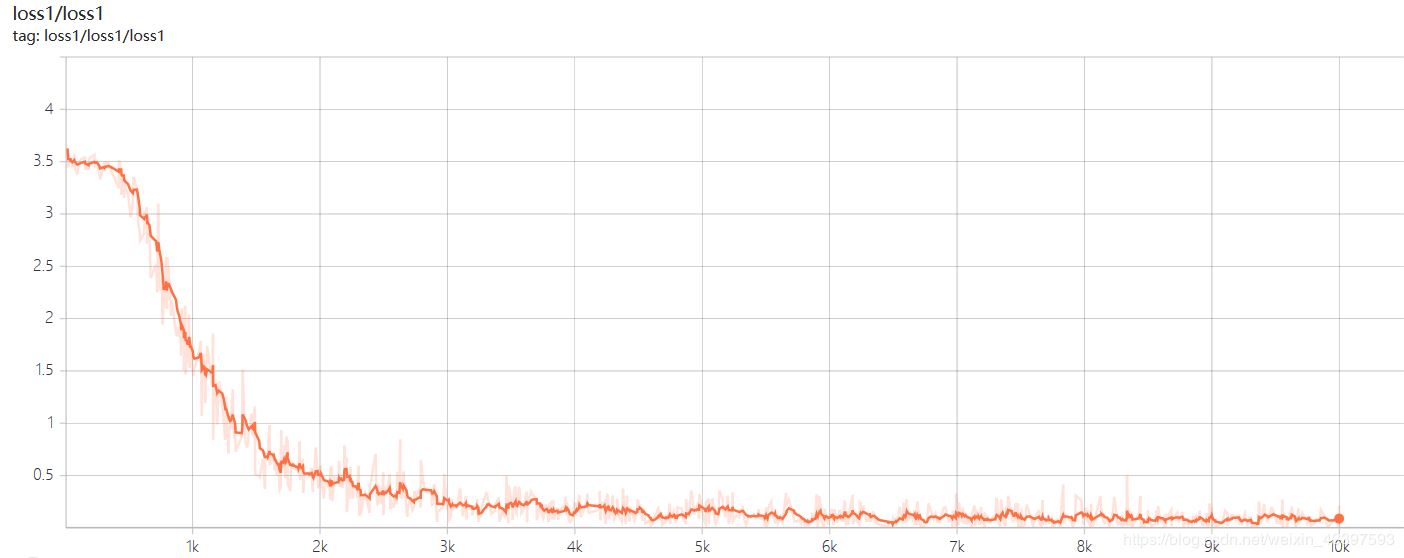
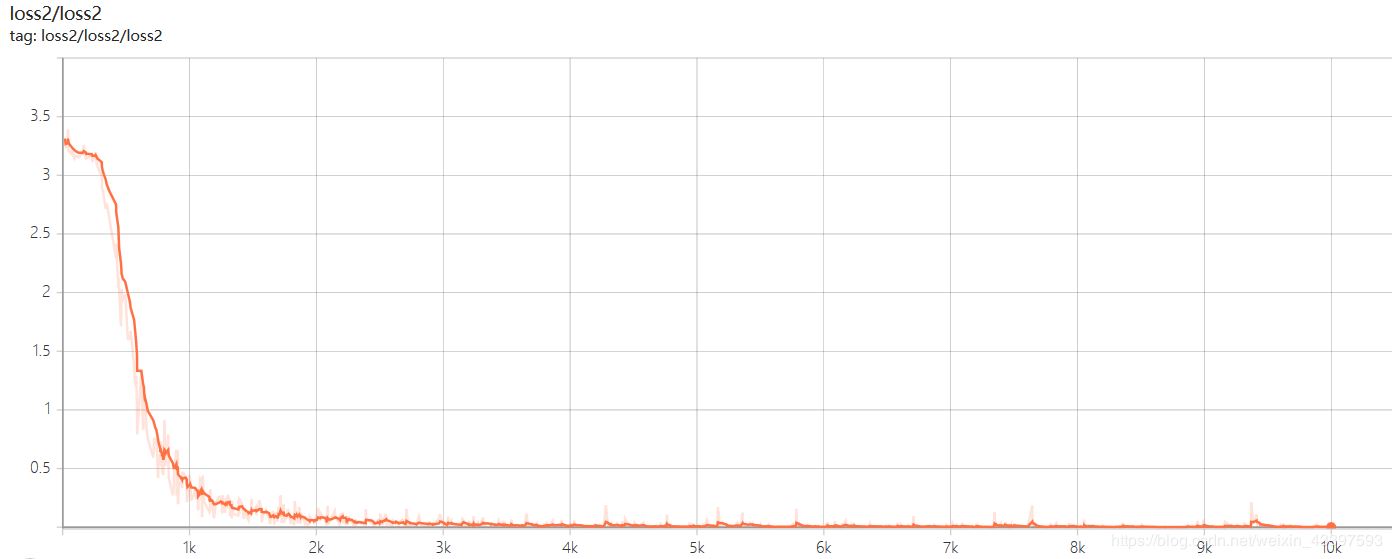
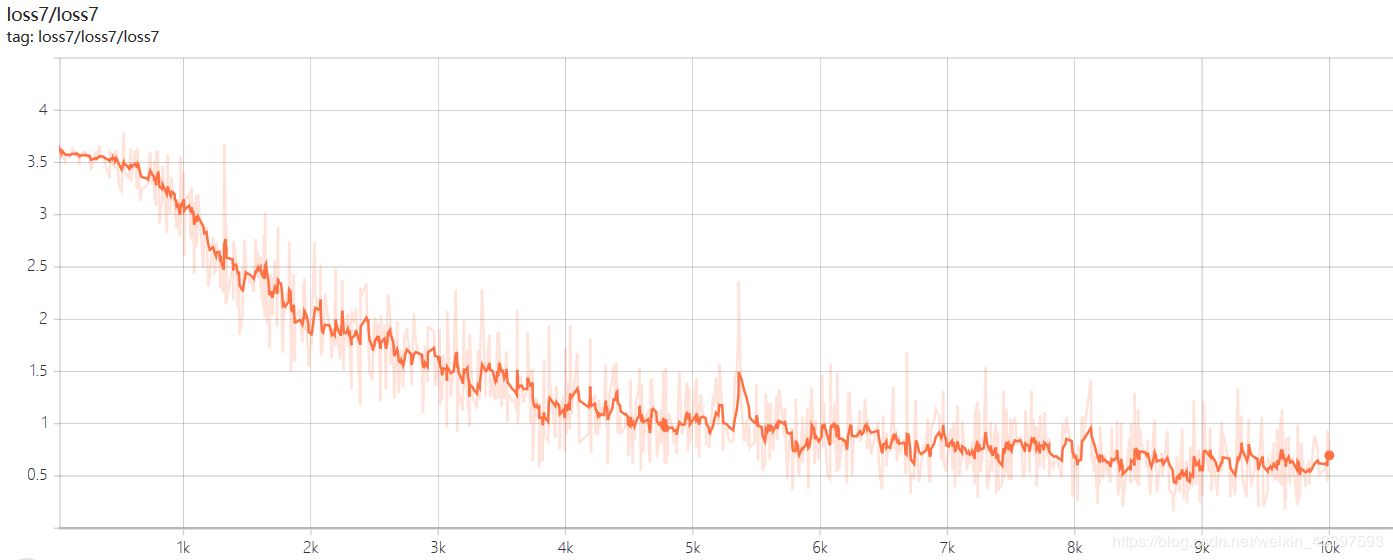
以上三张分别是loss1,loss2, loss7的曲线图像,一号位字符是省份简称,识别相对字母数字较难,loss1=0.08左右,二号位字符是字母,loss2稳定在0.001左右,但是随着字符往后,loss值也将越来越大,7号位字符loss7稳定在0.6左右。
七、预测单张车牌
import os import cv2 as cv import numpy as np import tensorflow as tf import matplotlib.pyplot as plt from PIL import Image import model os.environ["TF_CPP_MIN_LOG_LEVEL"] = '3' # 只显示 Error index = {"京": 0, "沪": 1, "津": 2, "渝": 3, "冀": 4, "晋": 5, "蒙": 6, "辽": 7, "吉": 8, "黑": 9, "苏": 10, "浙": 11, "皖": 12, "闽": 13, "赣": 14, "鲁": 15, "豫": 16, "鄂": 17, "湘": 18, "粤": 19, "桂": 20, "琼": 21, "川": 22, "贵": 23, "云": 24, "藏": 25, "陕": 26, "甘": 27, "青": 28, "宁": 29, "新": 30, "0": 31, "1": 32, "2": 33, "3": 34, "4": 35, "5": 36, "6": 37, "7": 38, "8": 39, "9": 40, "A": 41, "B": 42, "C": 43, "D": 44, "E": 45, "F": 46, "G": 47, "H": 48, "J": 49, "K": 50, "L": 51, "M": 52, "N": 53, "P": 54, "Q": 55, "R": 56, "S": 57, "T": 58, "U": 59, "V": 60, "W": 61, "X": 62, "Y": 63, "Z": 64} chars = ["京", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "皖", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z"] def get_one_image(test): """ 随机获取单张车牌图像 """ n = len(test) rand_num =np.random.randint(0,n) img_dir = test[rand_num] image_show = Image.open(img_dir) plt.imshow(image_show) # 显示车牌图片 image = cv.imread(img_dir) image = image.reshape(72, 272, 3) image = np.multiply(image, 1 / 255.0) return image batch_size = 1 x = tf.compat.v1.placeholder(tf.float32, [batch_size, 72, 272, 3]) keep_prob = tf.compat.v1.placeholder(tf.float32) test_dir = 'data\\plate\\' test_image = [] for file in os.listdir(test_dir): test_image.append(test_dir + file) test_image = list(test_image) image_array = get_one_image(test_image) logit1, logit2, logit3, logit4, logit5, logit6, logit7 = model.cnn_inference(x, keep_prob) model_path = 'saved_model\\1005' saver = tf.compat.v1.train.Saver() with tf.compat.v1.Session() as sess: print ("Reading checkpoint...") ckpt = tf.train.get_checkpoint_state(model_path) if ckpt and ckpt.model_checkpoint_path: global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1] saver.restore(sess, ckpt.model_checkpoint_path) print('Loading success, global_step is %s' % global_step) else: print('No checkpoint file found') pre1, pre2, pre3, pre4, pre5, pre6, pre7 = sess.run( [logit1, logit2, logit3, logit4, logit5, logit6, logit7], feed_dict={x:image_array, keep_prob:1.0}) prediction = np.reshape(np.array([pre1, pre2, pre3, pre4, pre5, pre6, pre7]), [-1, 65]) max_index = np.argmax(prediction, axis=1) print(max_index) line = '' result = np.array([]) for i in range(prediction.shape[0]): if i == 0: result = np.argmax(prediction[i][0:31]) if i == 1: result = np.argmax(prediction[i][41:65]) + 41 if i > 1: result = np.argmax(prediction[i][31:65]) + 31 line += chars[result]+" " print ('predicted: ' + line) plt.show()上述内容就是Python+Tensorflow+CNN实现车牌识别,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





