Download as PDF, PPTX


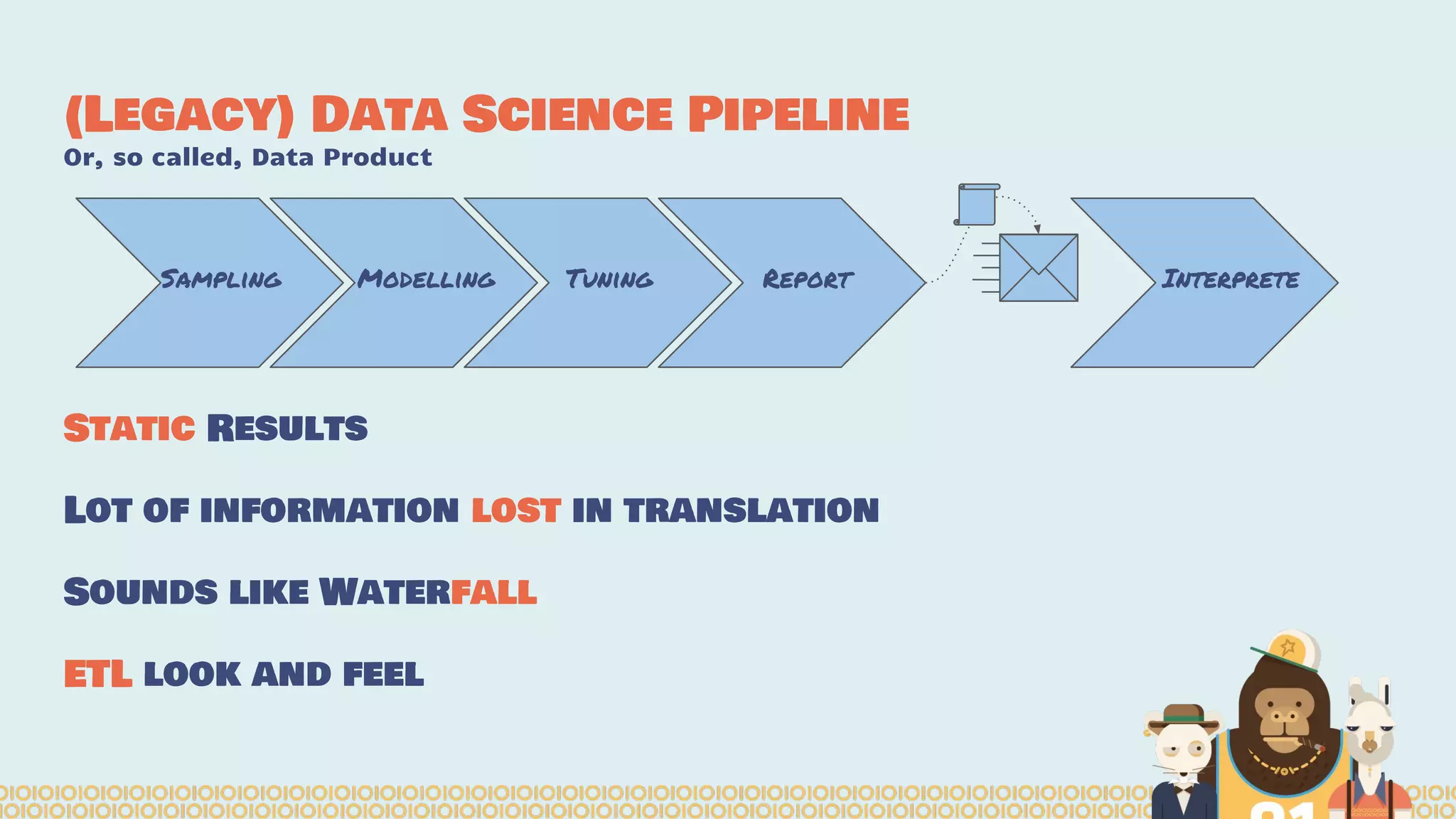
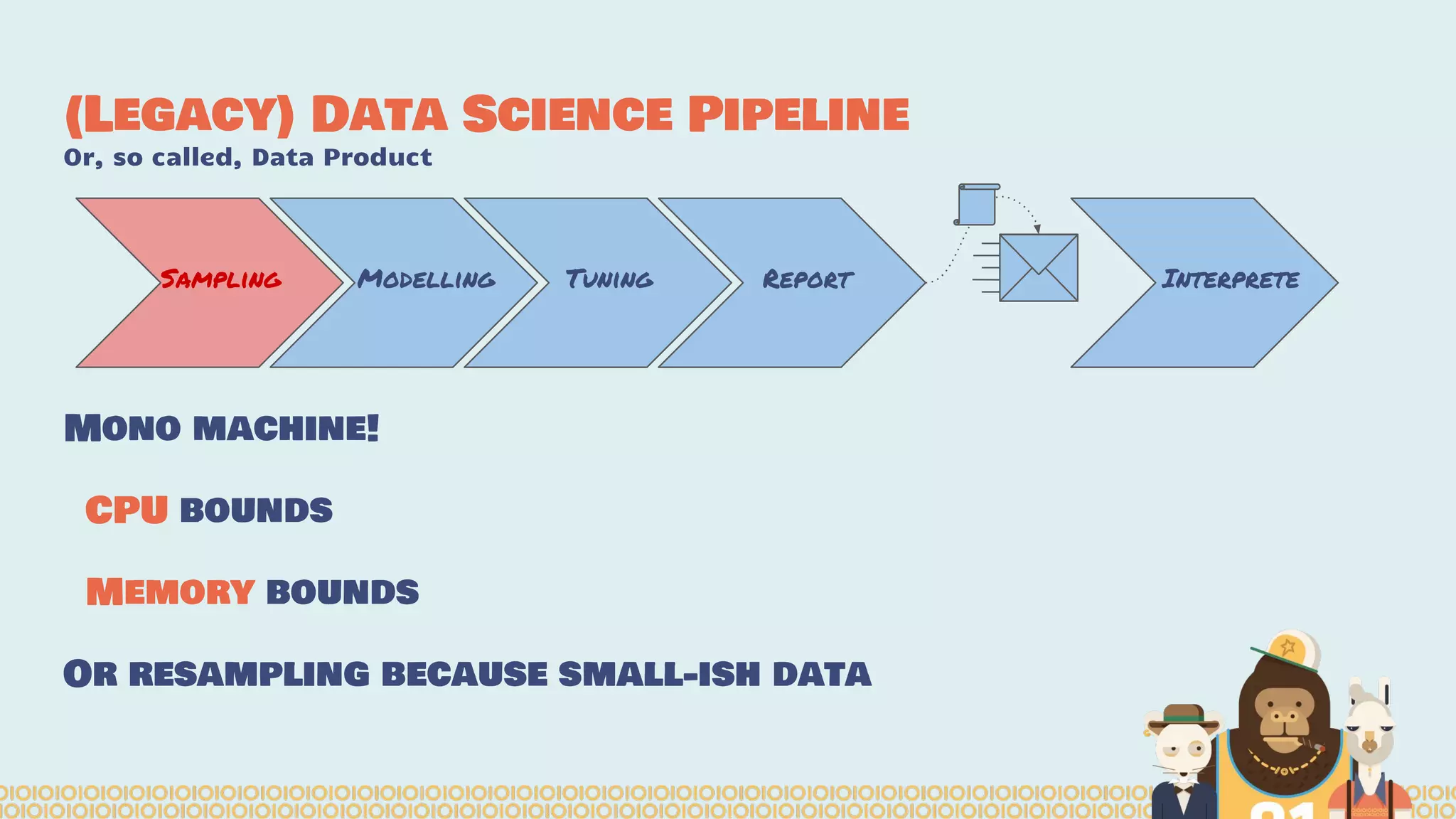

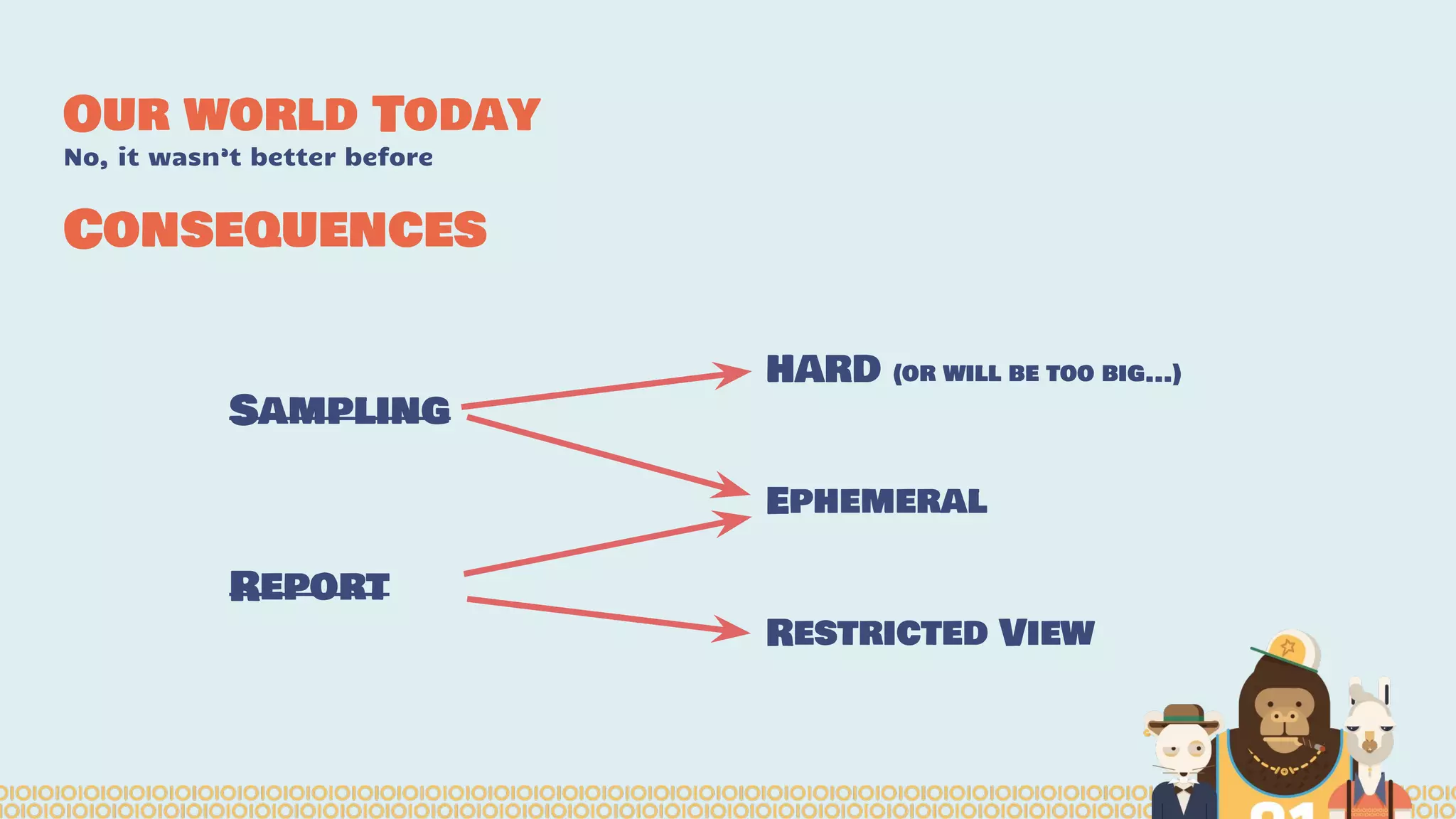












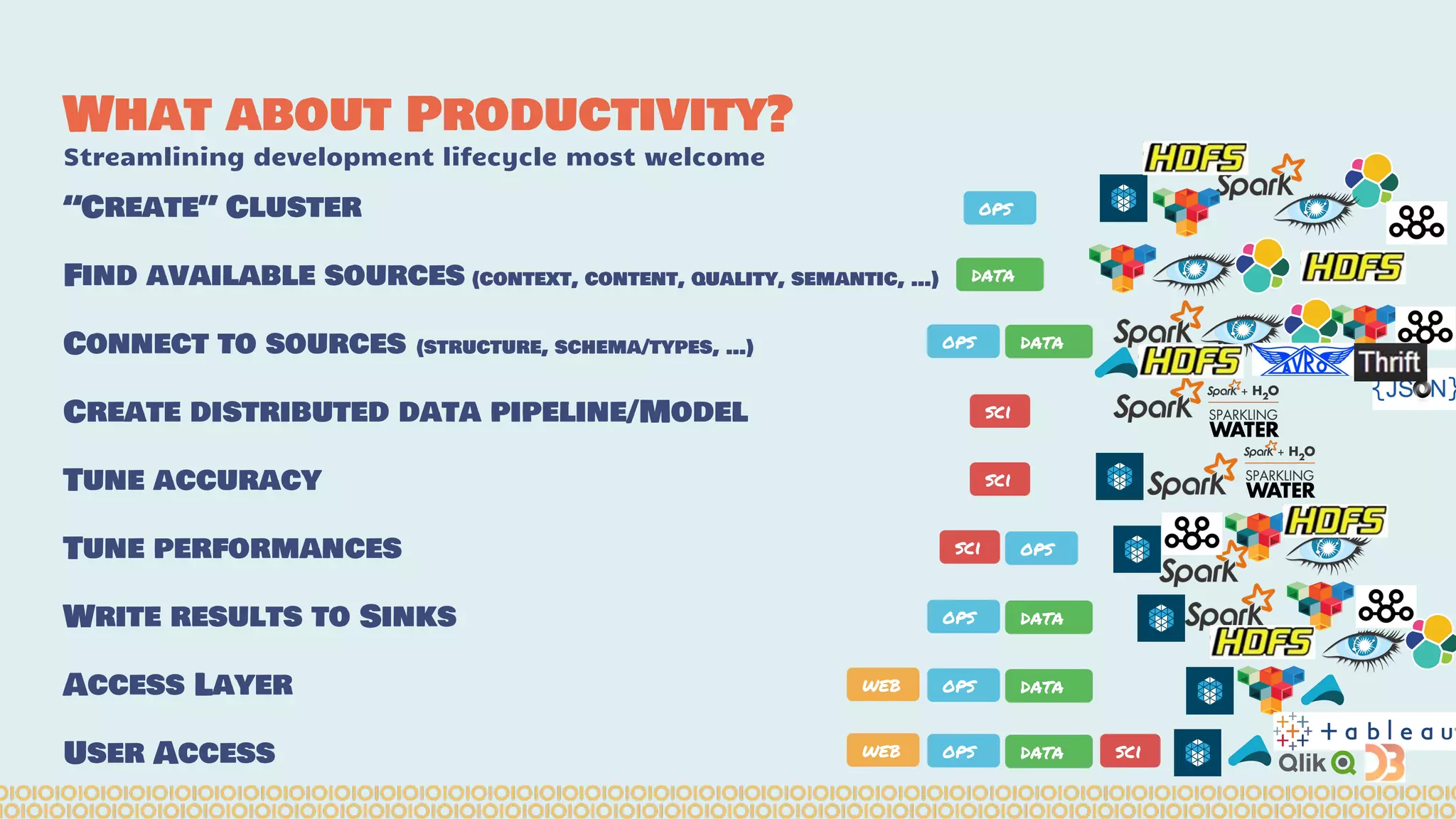
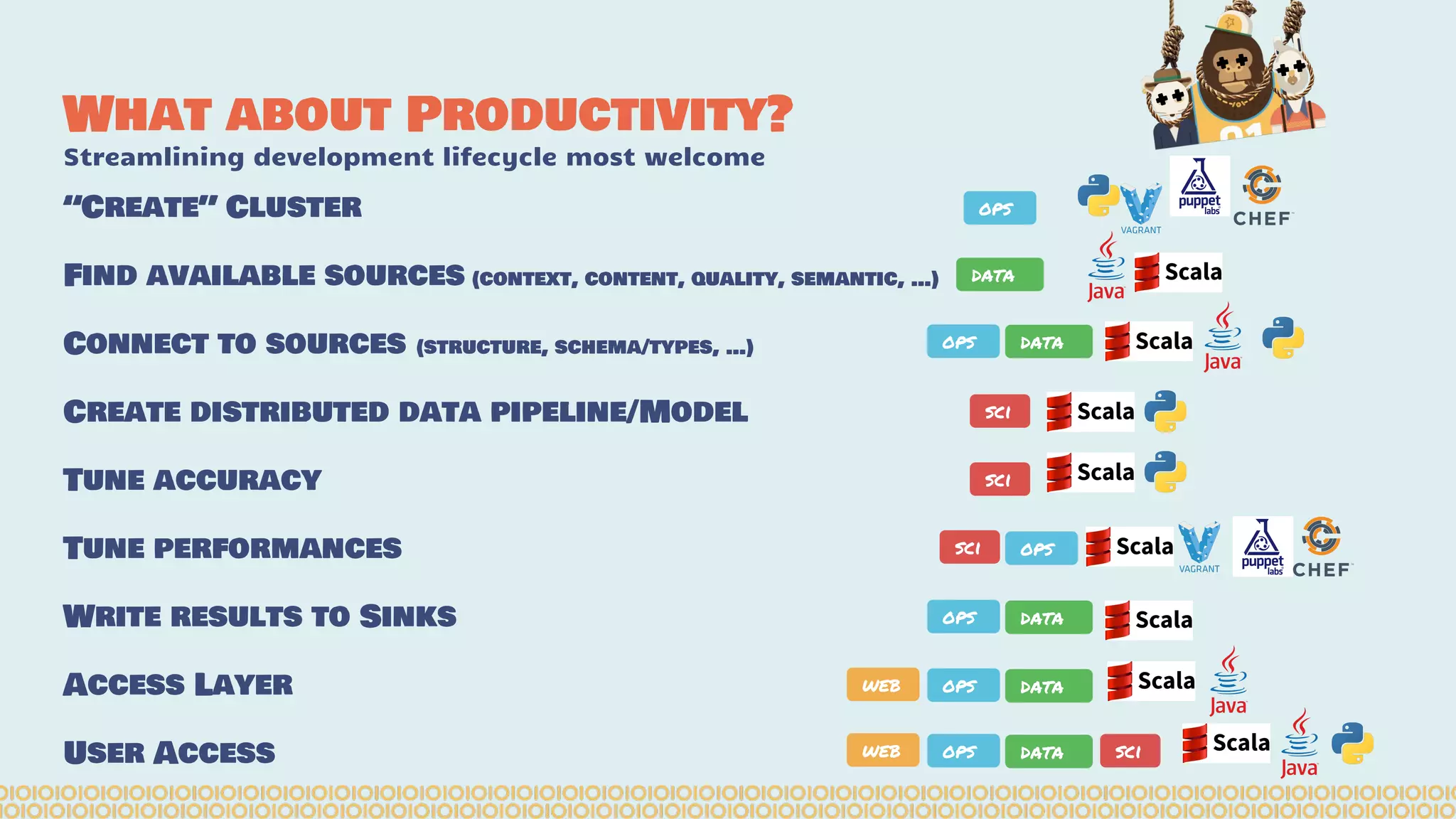





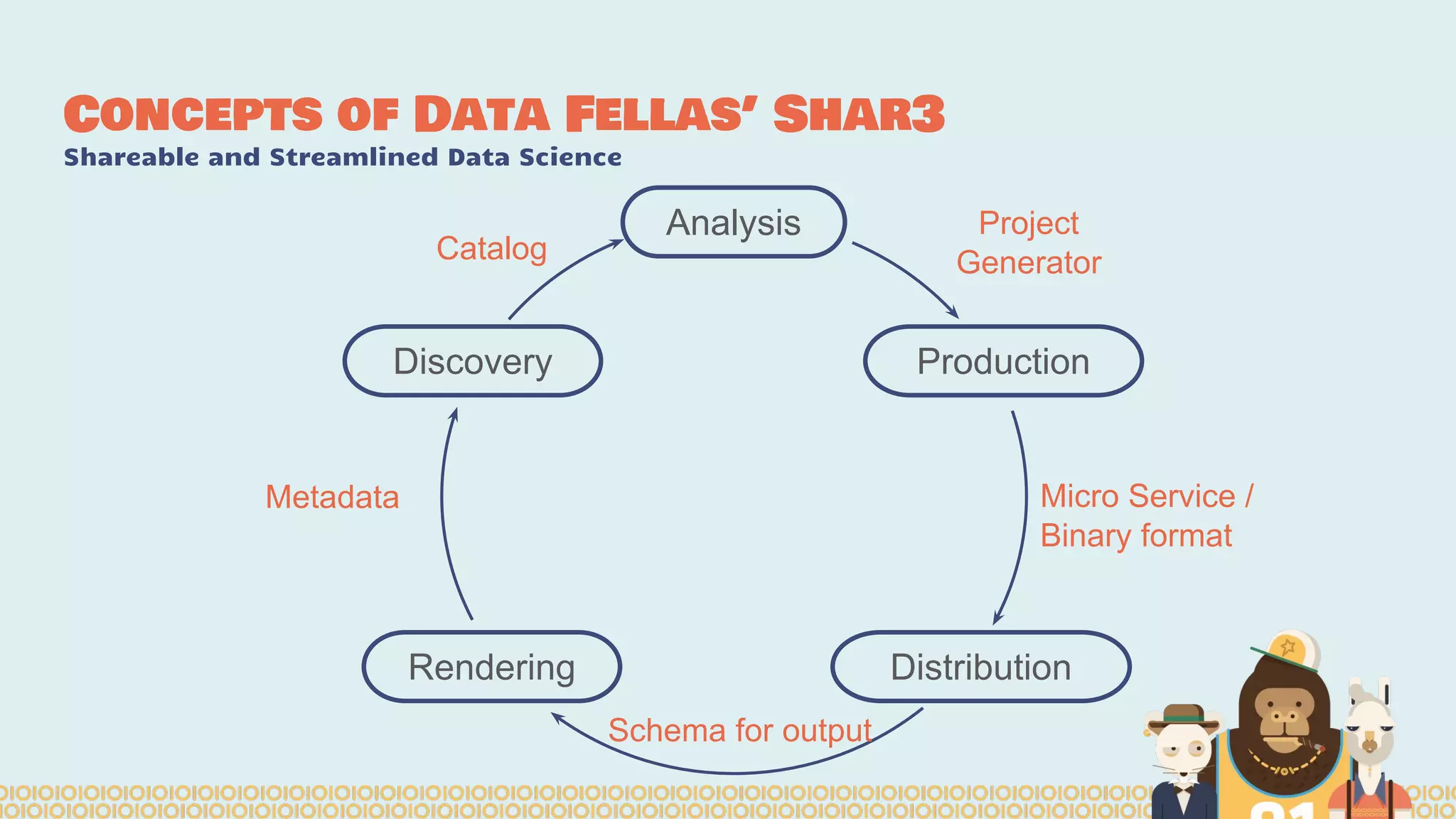




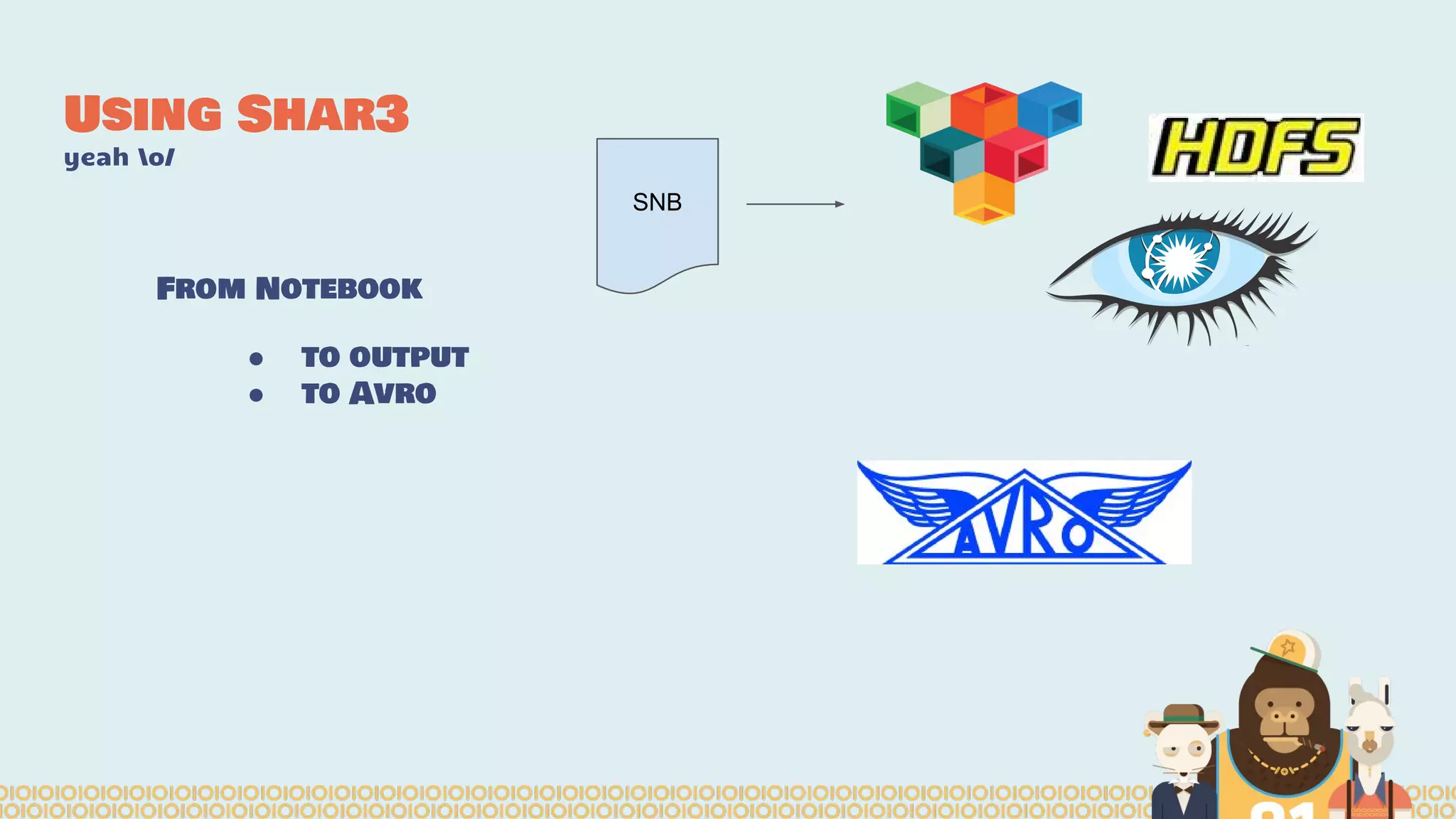
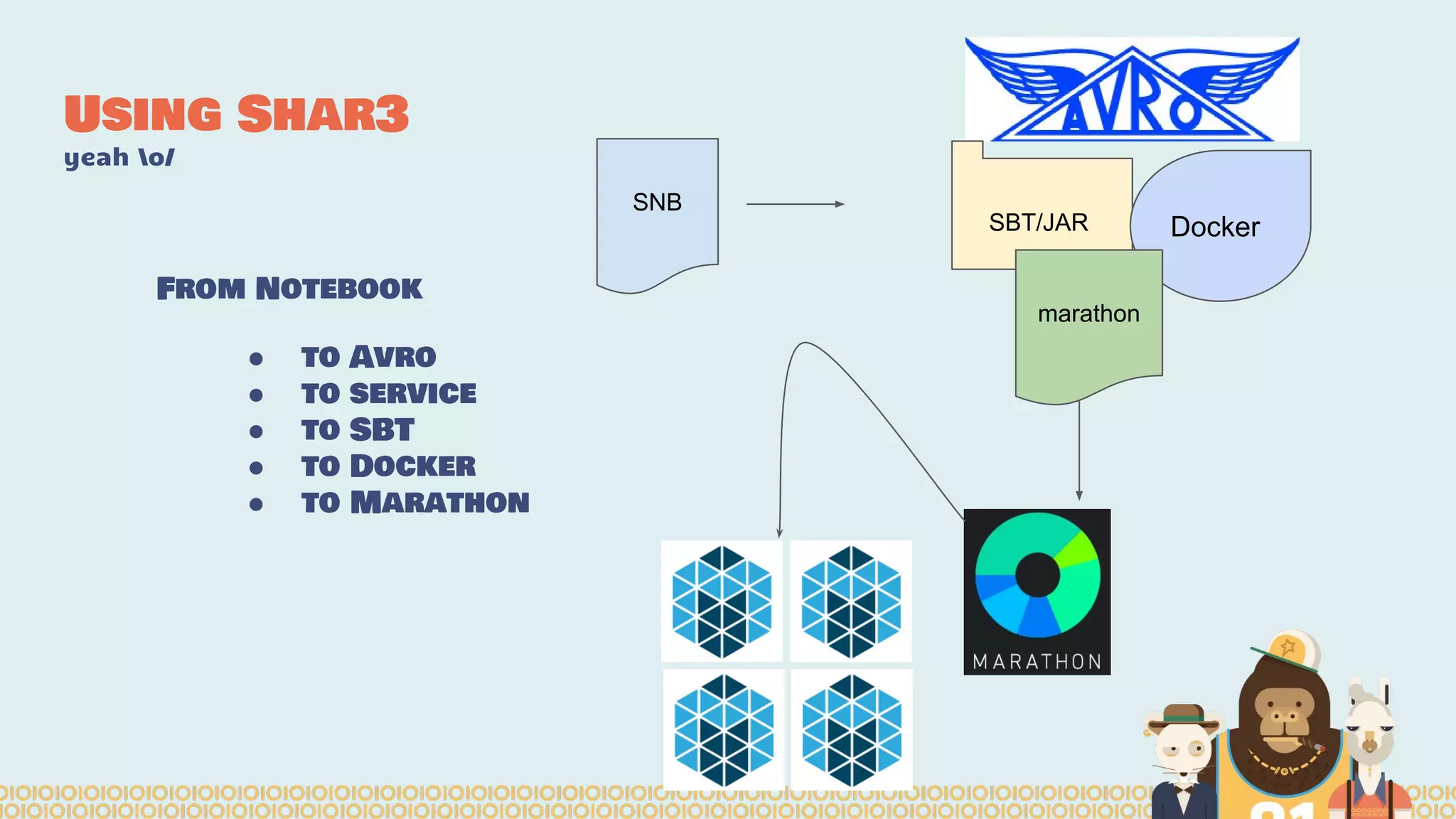
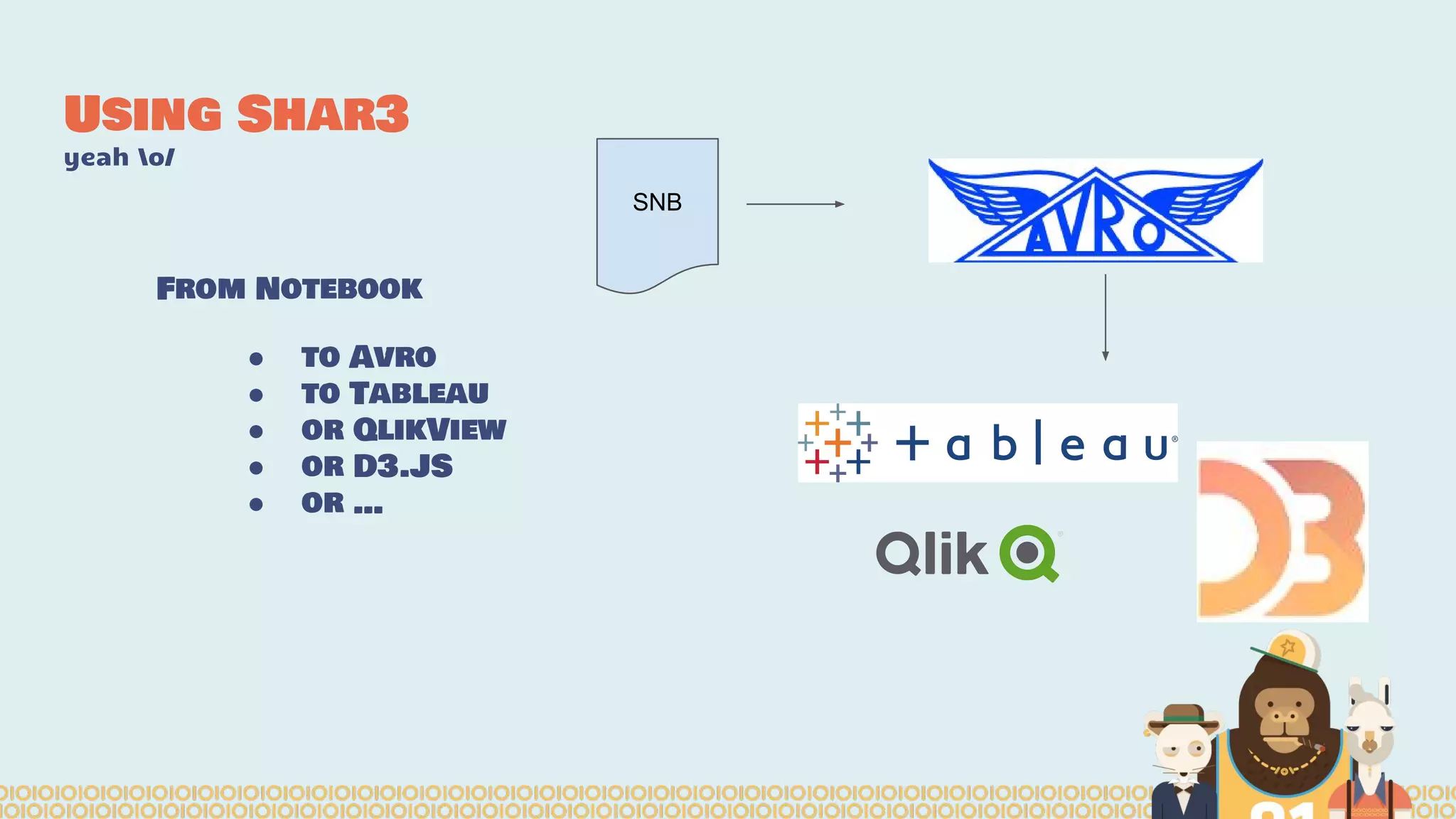

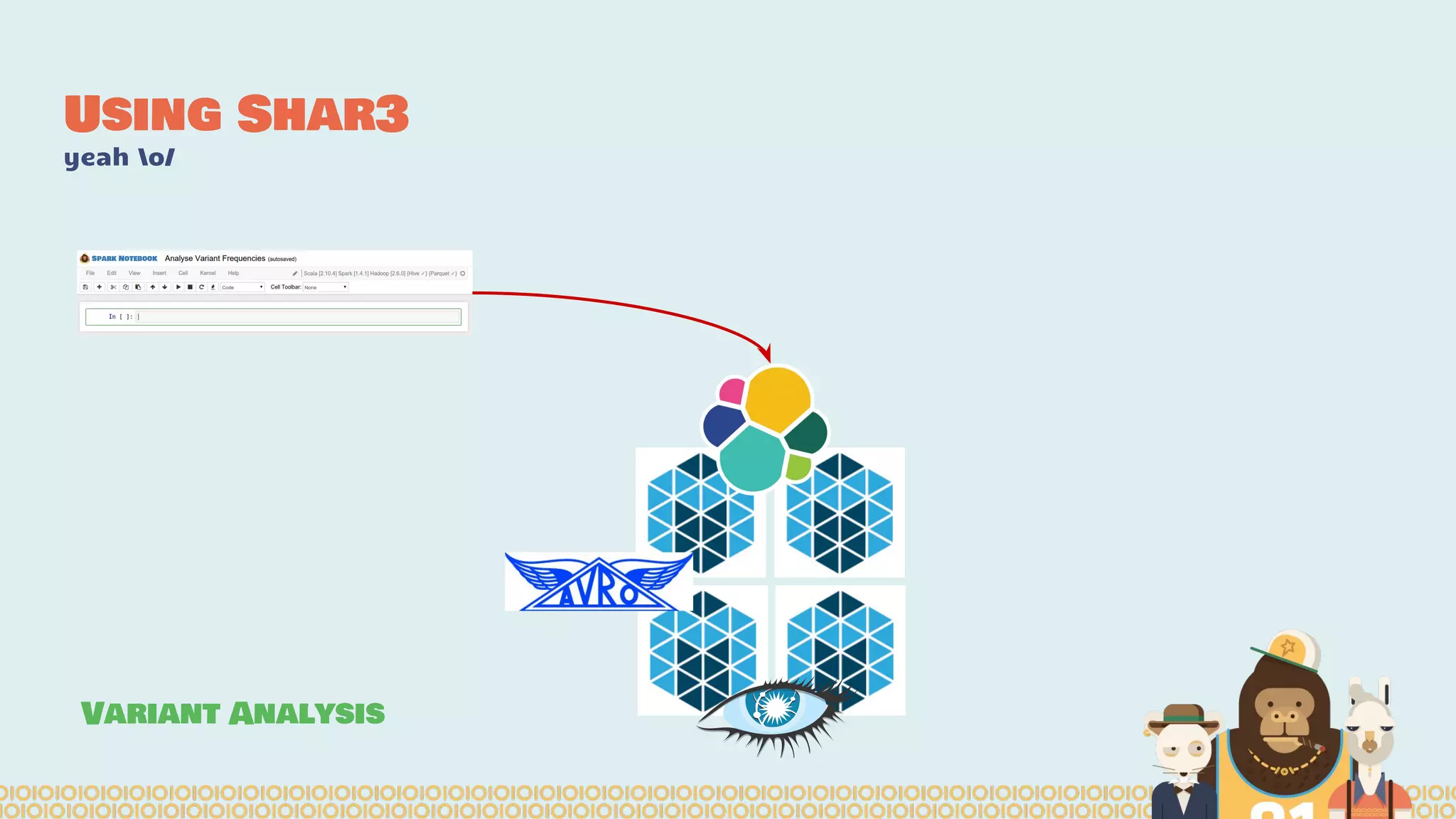
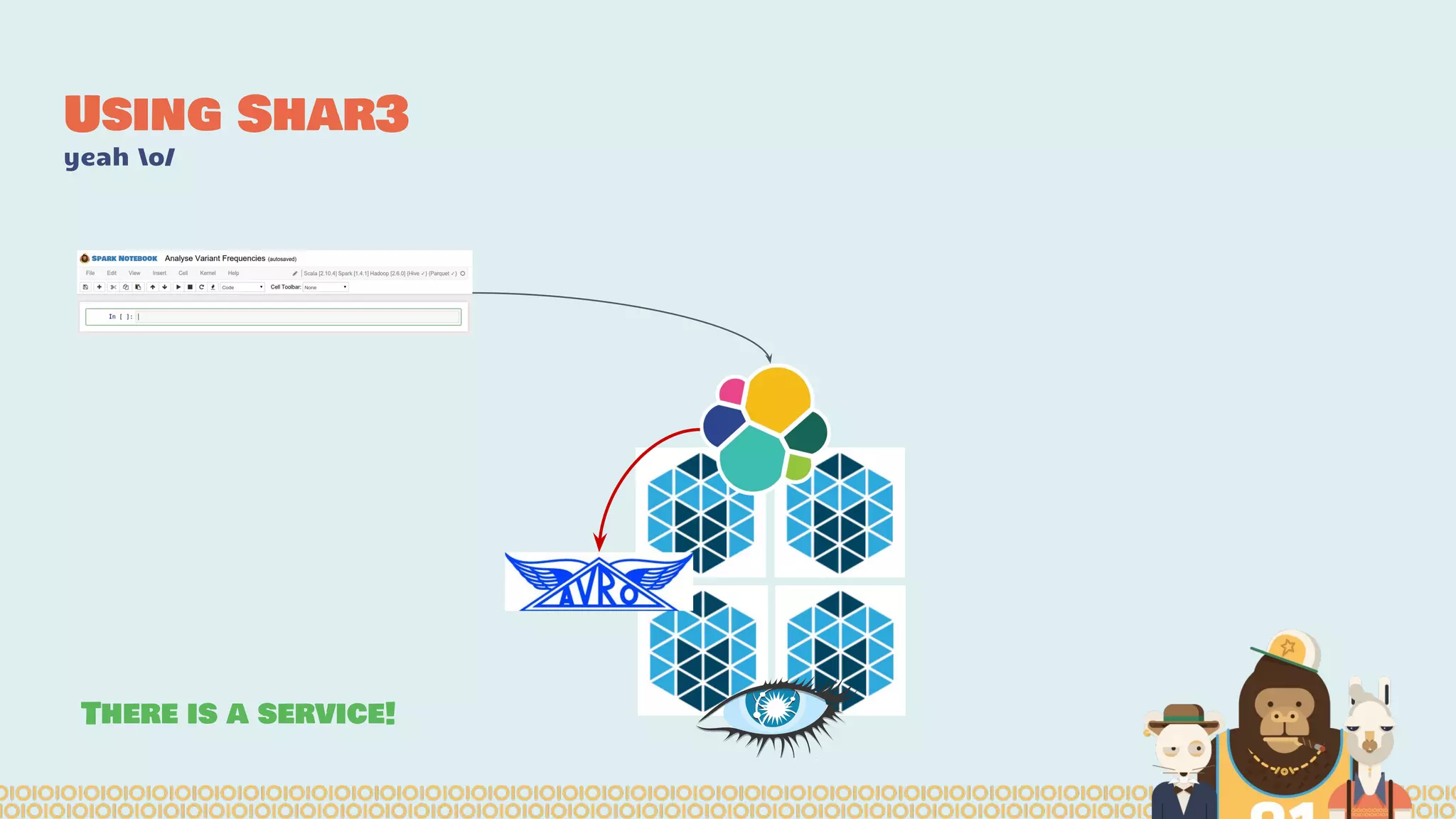
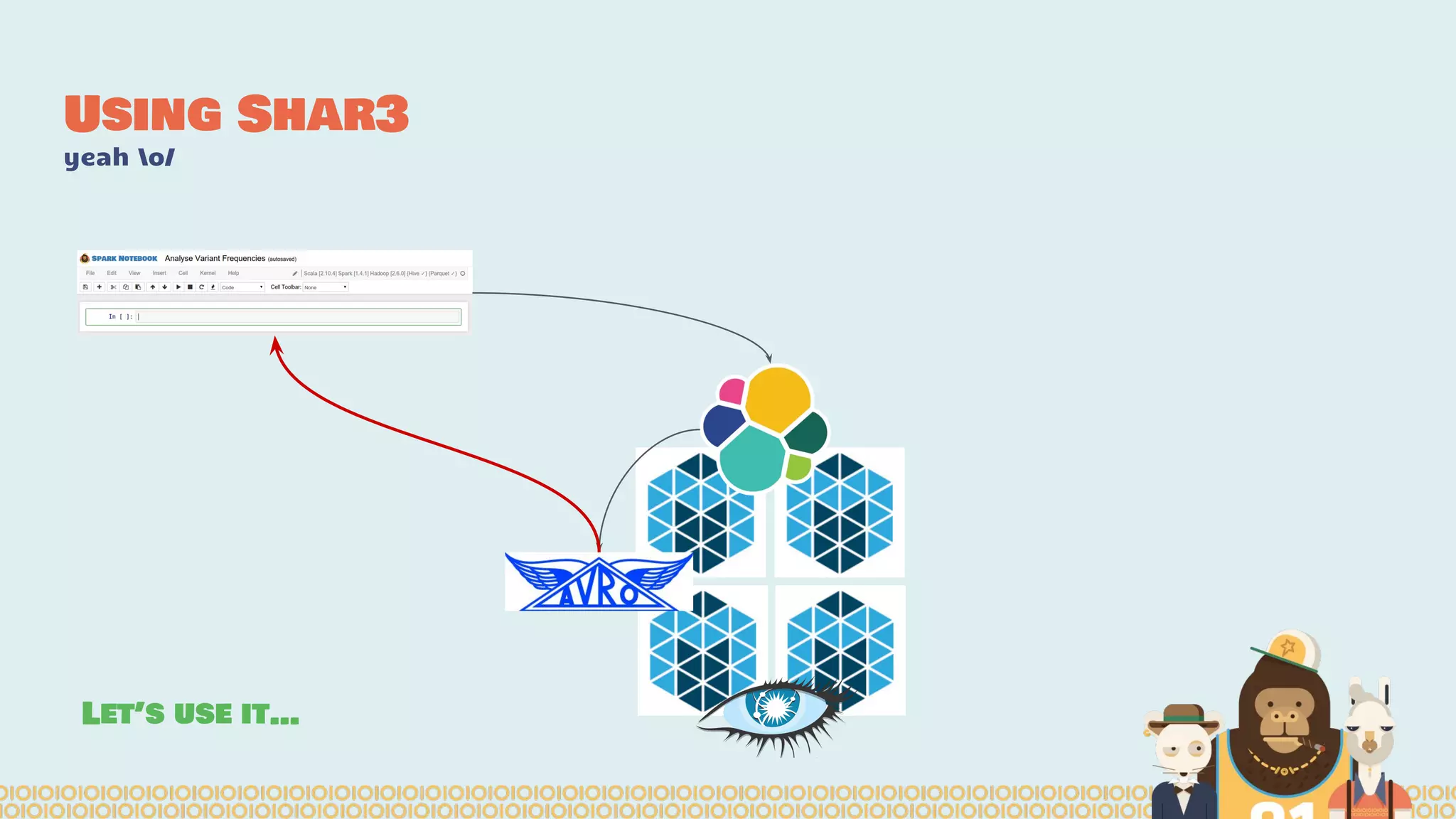
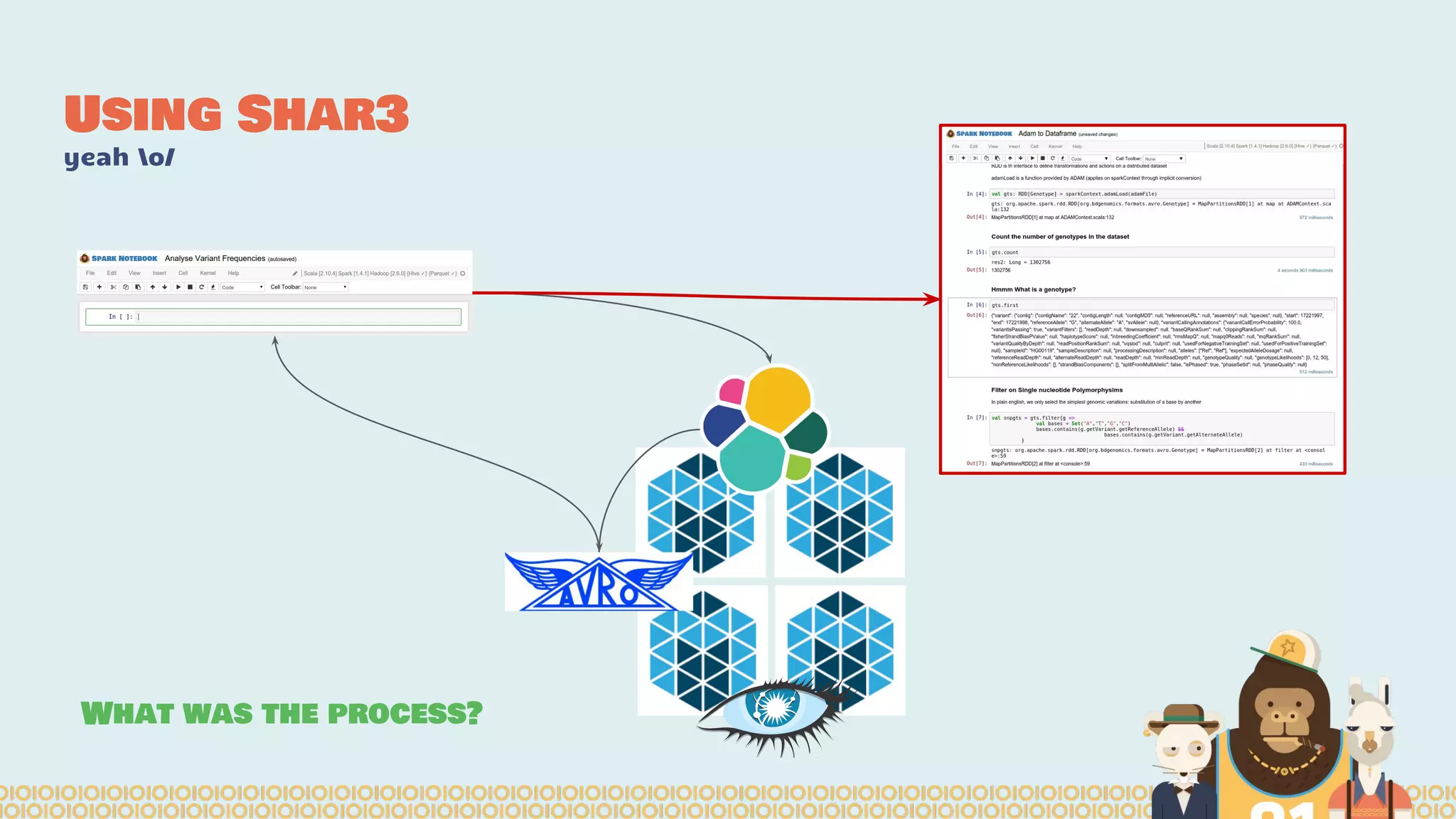
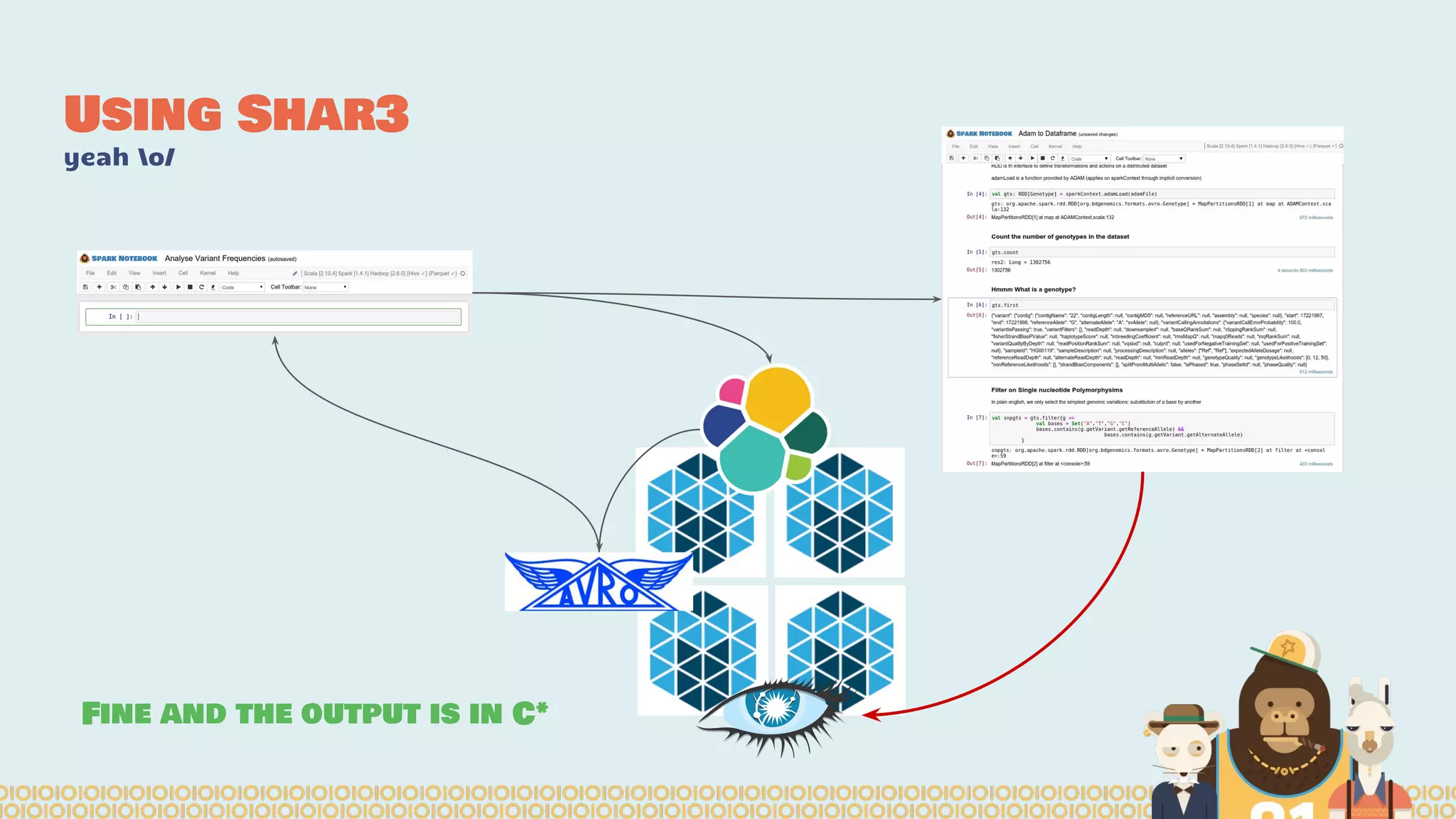
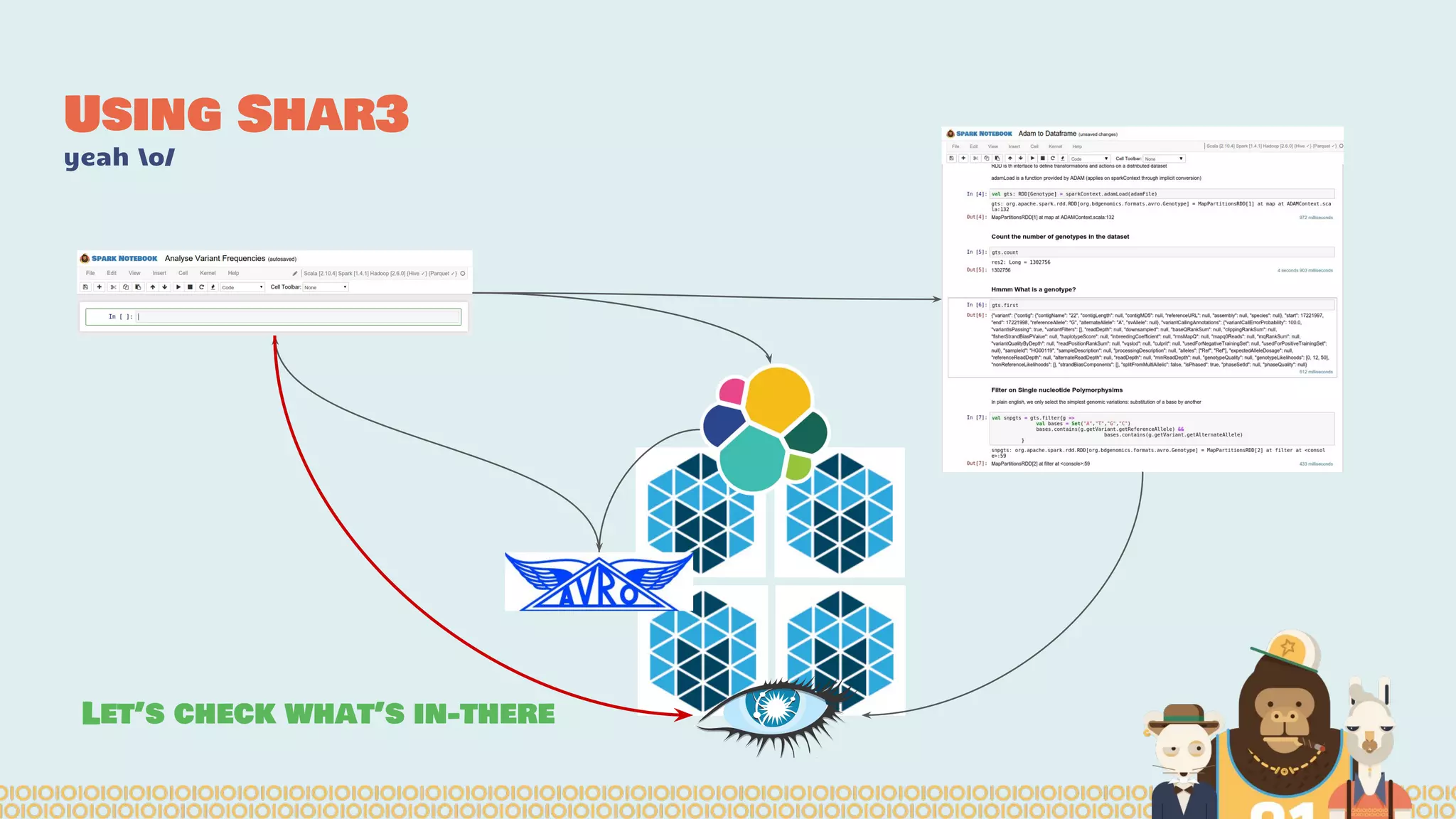
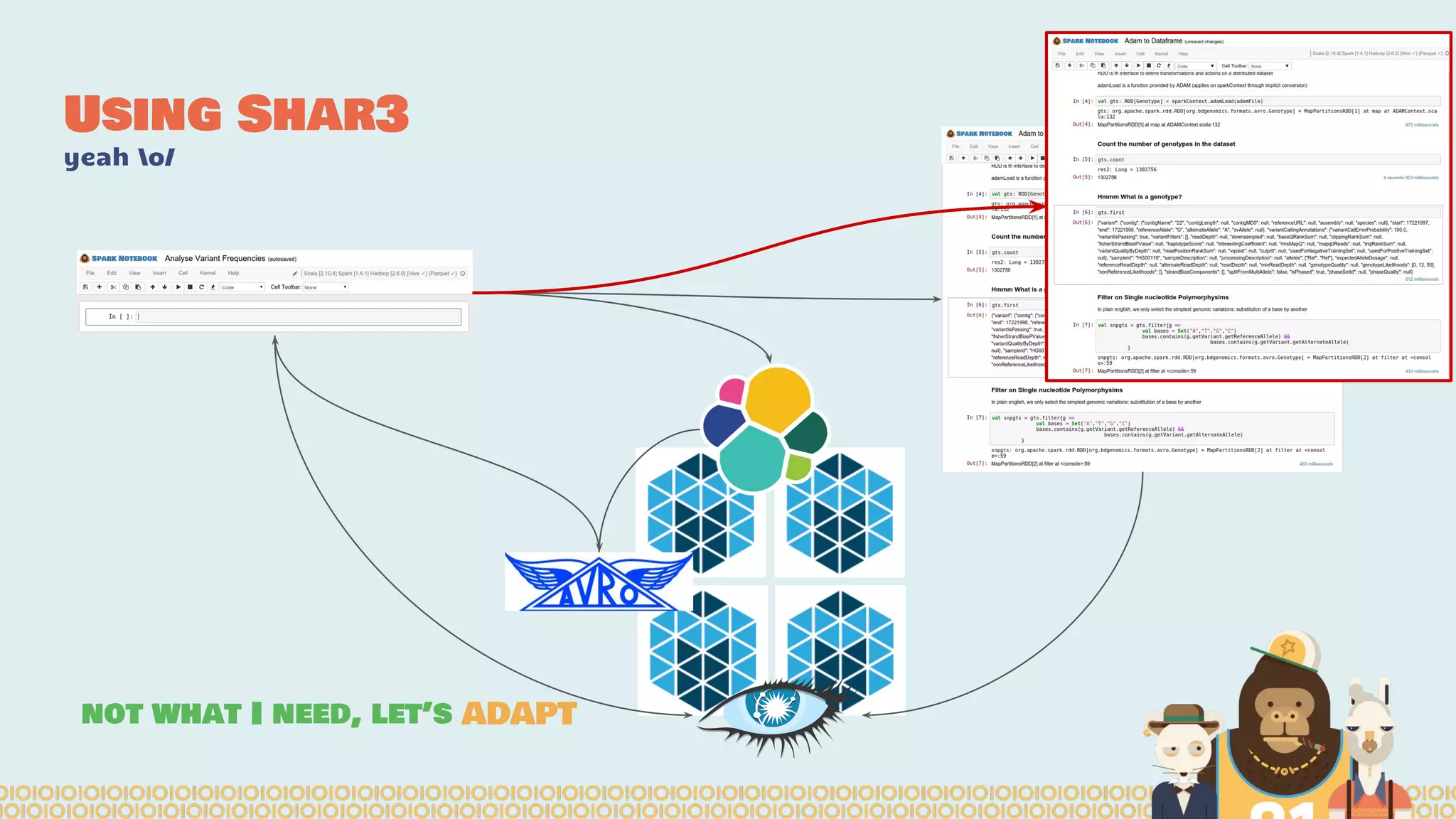
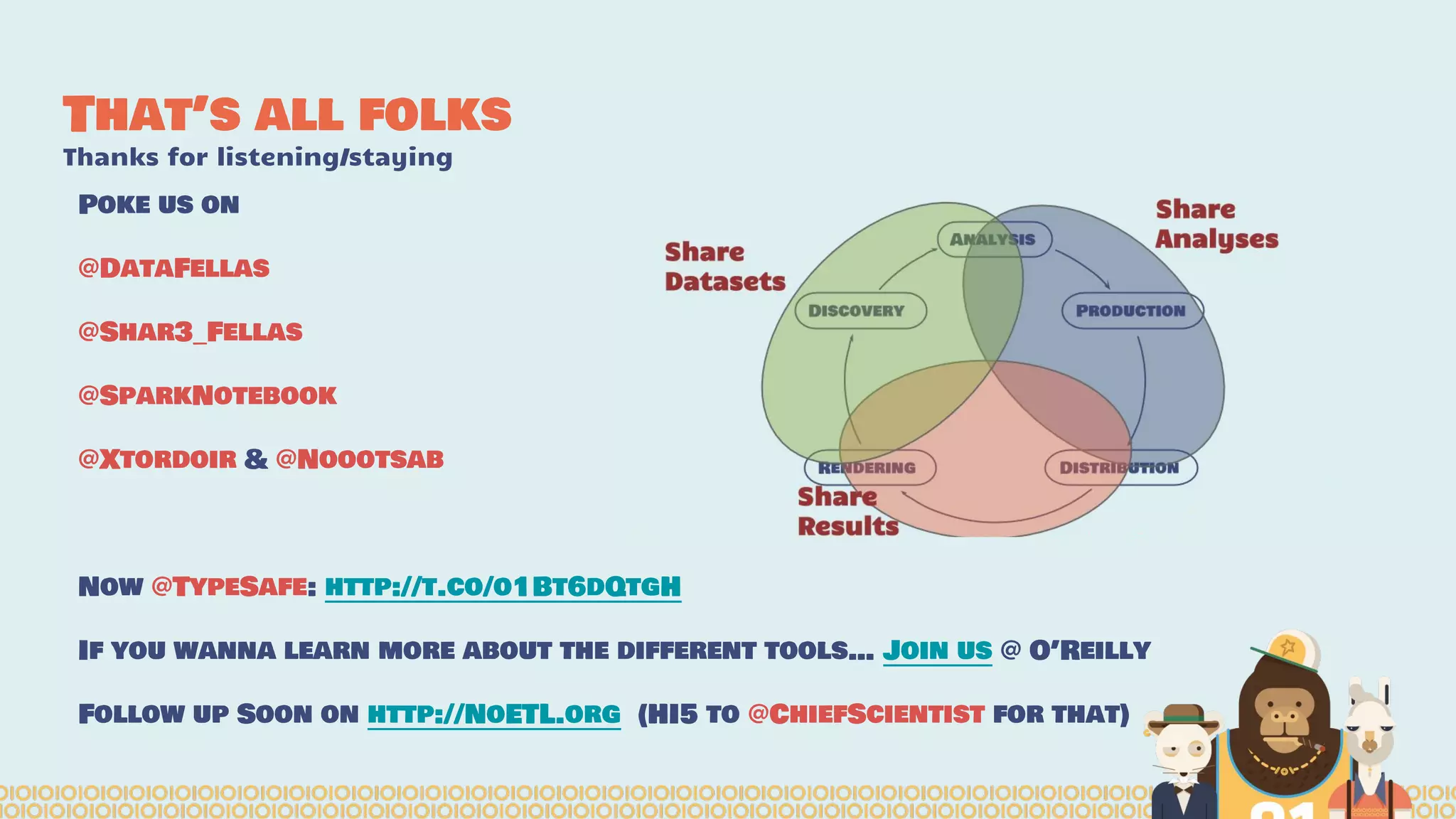

The document discusses the evolution of distributed data science pipelines using Apache Spark and emphasizes the shift from traditional, static data products to more dynamic, distributed approaches that better manage the increasing volume and speed of data. It outlines the necessary components for establishing effective distributed data science systems, including cluster creation and model tuning, while also focusing on the need for interactivity and reactivity in data analysis. Additionally, the document highlights the role of tools like 'shar3' to streamline and enhance productivity in data science workflows.