Download to read offline









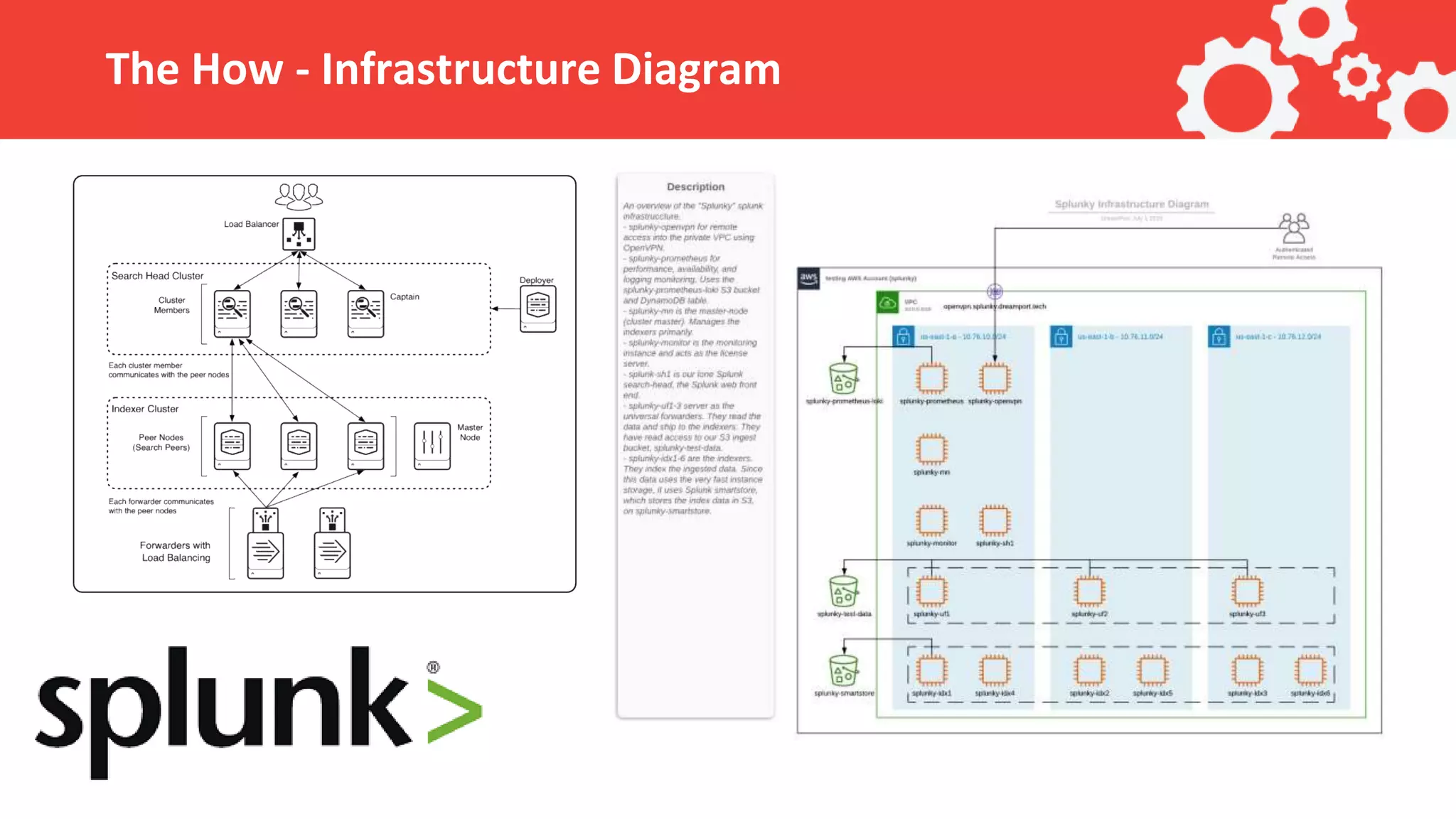





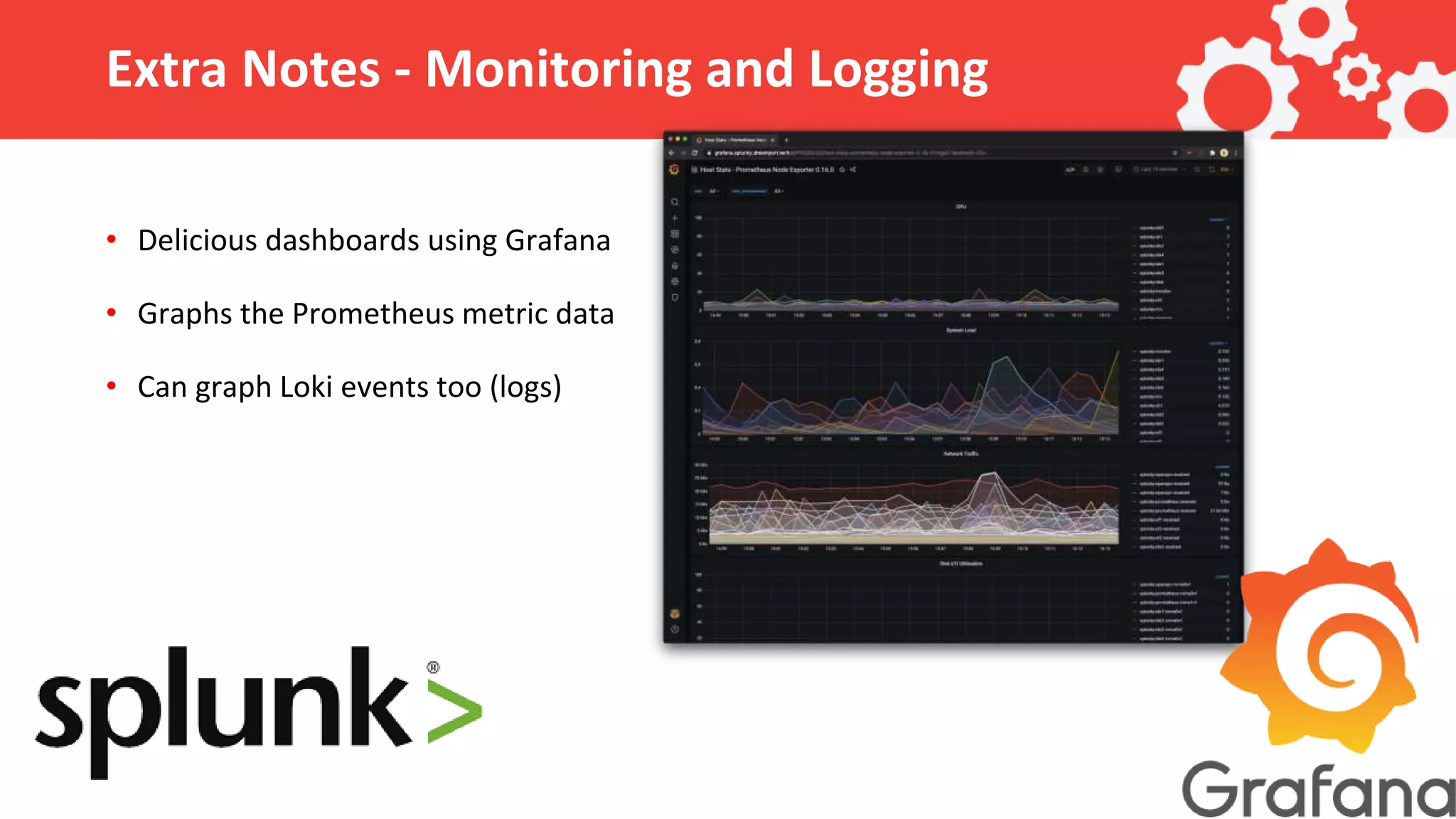

The document outlines the use of AWS, Terraform, and Ansible in automating the management of a Splunk cluster for analyzing machine learning capabilities on a 9TB dataset. Key topics include project management by Dreamport, configuration setup, and automation of deployment and ingestion processes. It emphasizes the importance of programmatic configuration and efficient data handling to minimize errors during ingestion.