Downloaded 30 times
































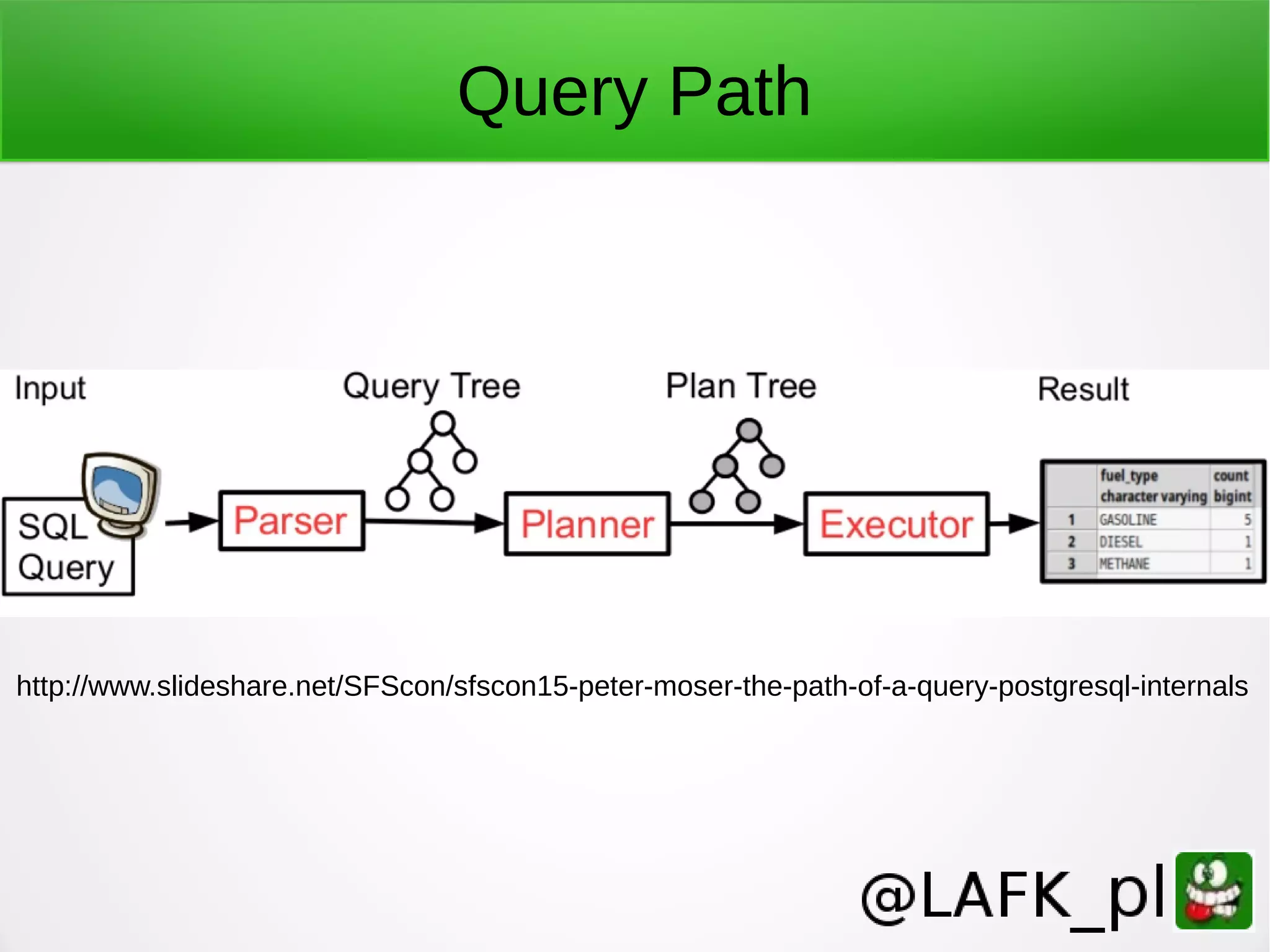

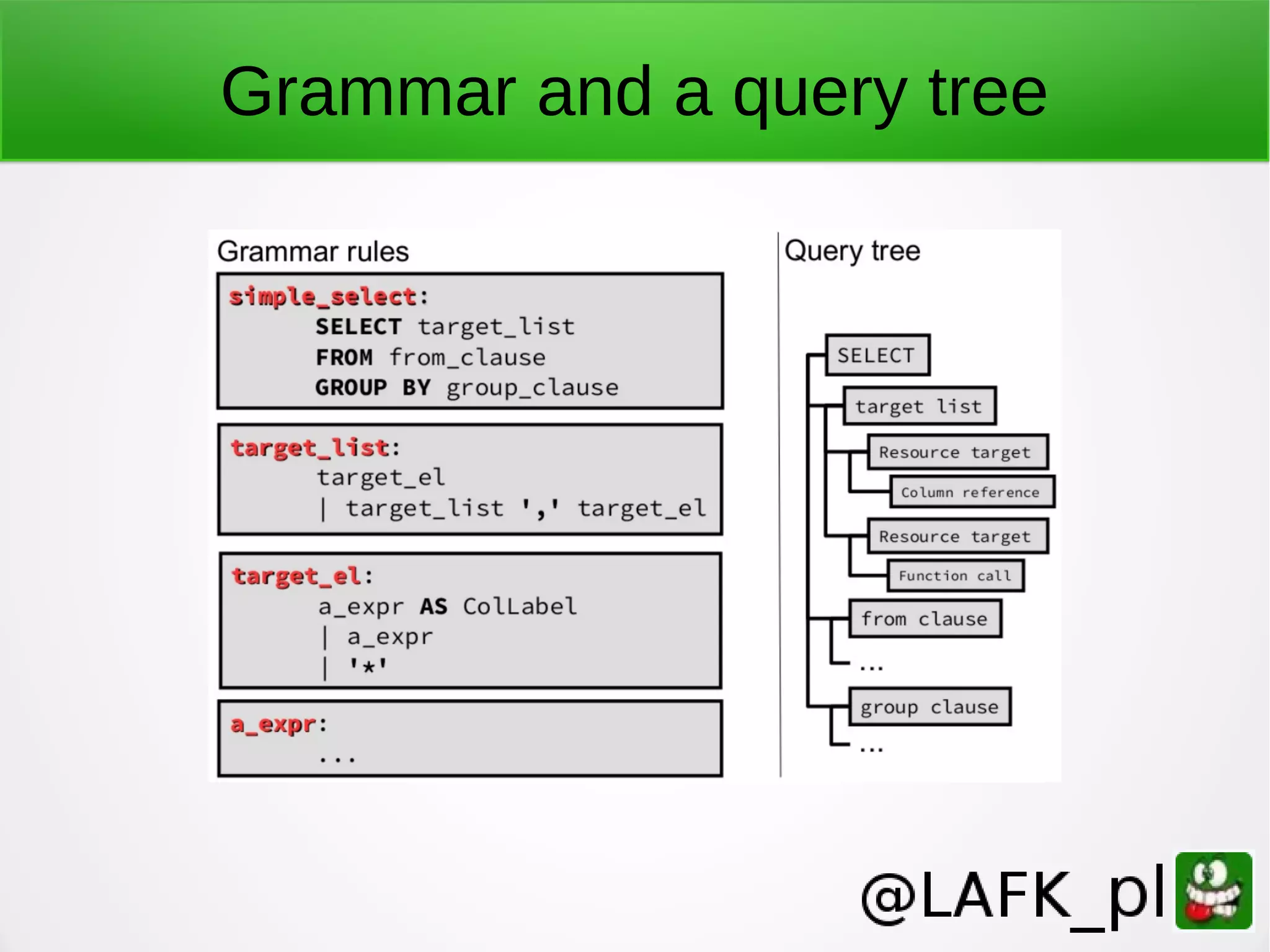

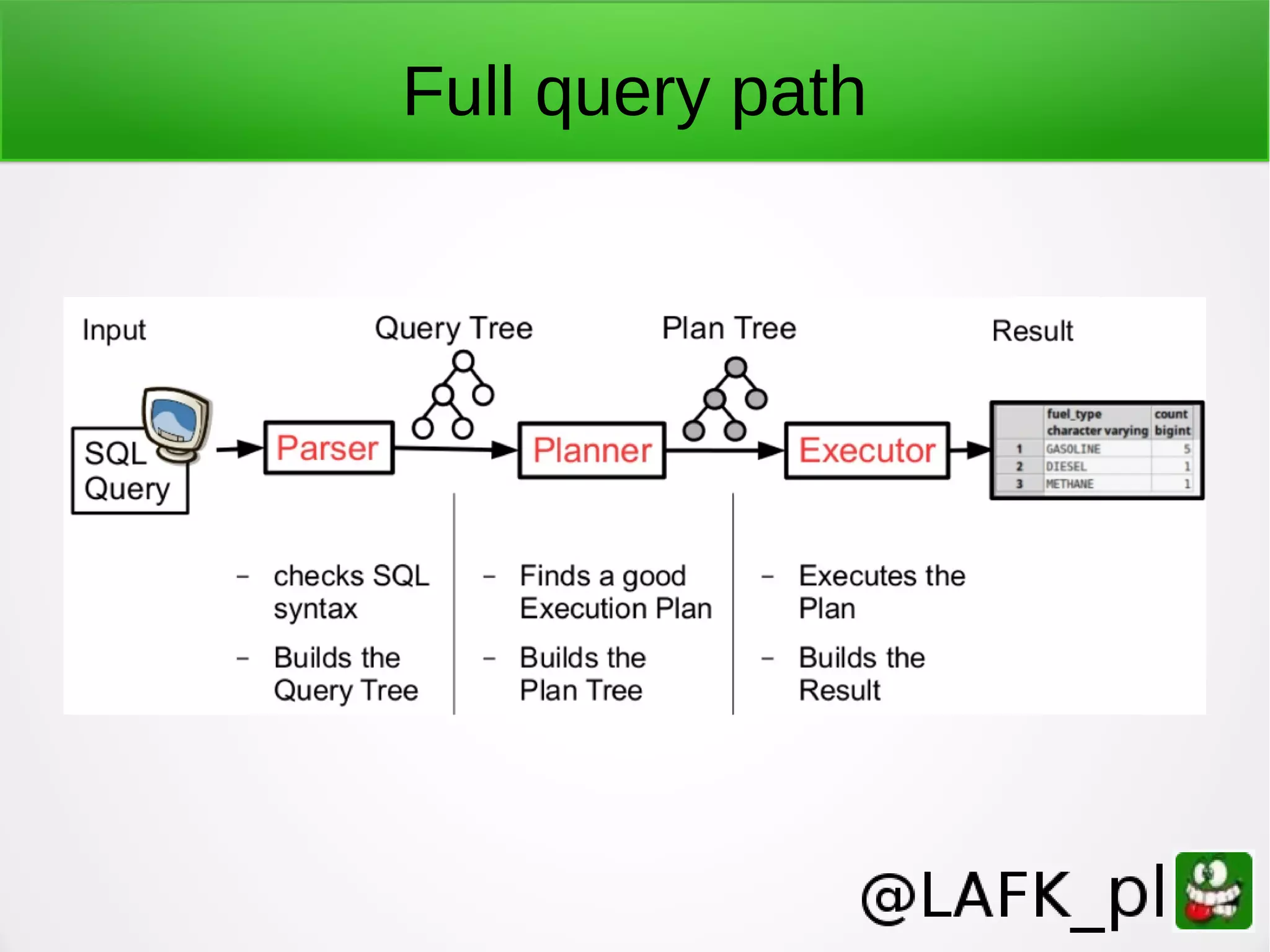

















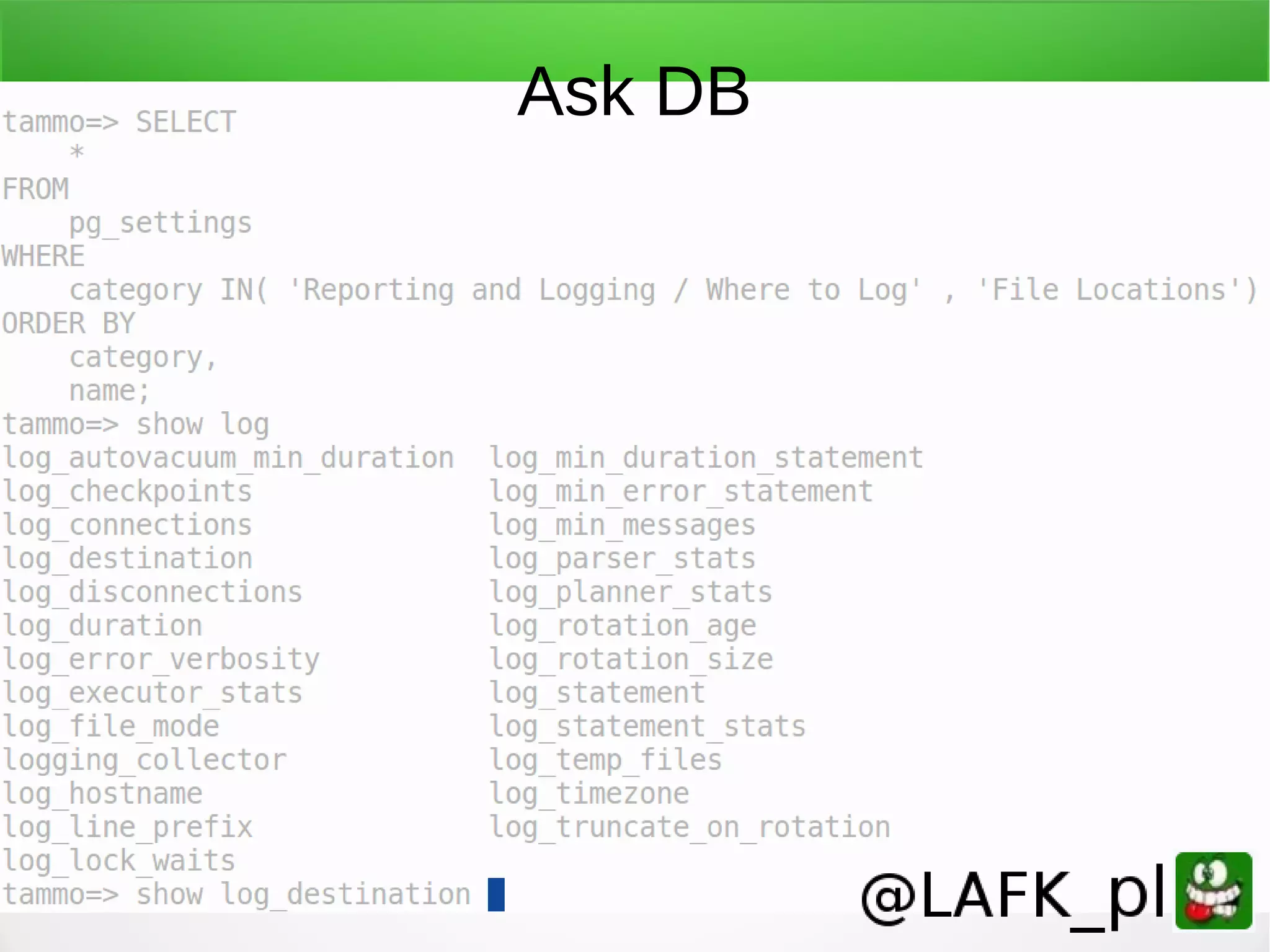
![Logging, turn it on ● Default is to stderr only ● In PG: logging_collector = on log_filename = strftime-patterned filename [log_destination = [stderr|syslog|csvlog] ] log_statement = [none|ddl|mod|all] // all log_min_error_statement = ERROR log_line_prefix = '%t %c %u ' # time sessionid user](https://image.slidesharecdn.com/teachingpostgrestonewpeople-161102104838/75/Teaching-PostgreSQL-to-new-people-60-2048.jpg)













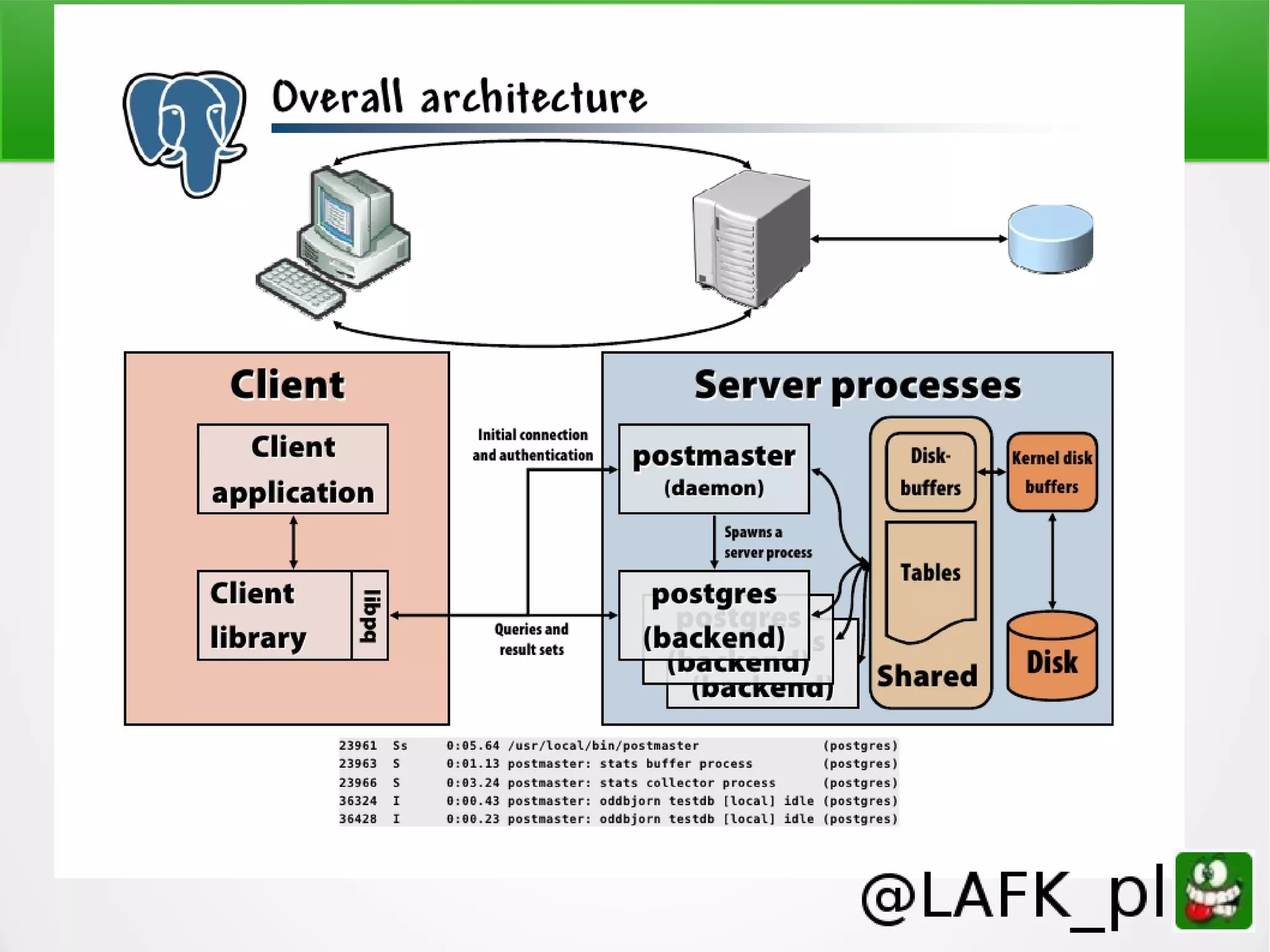
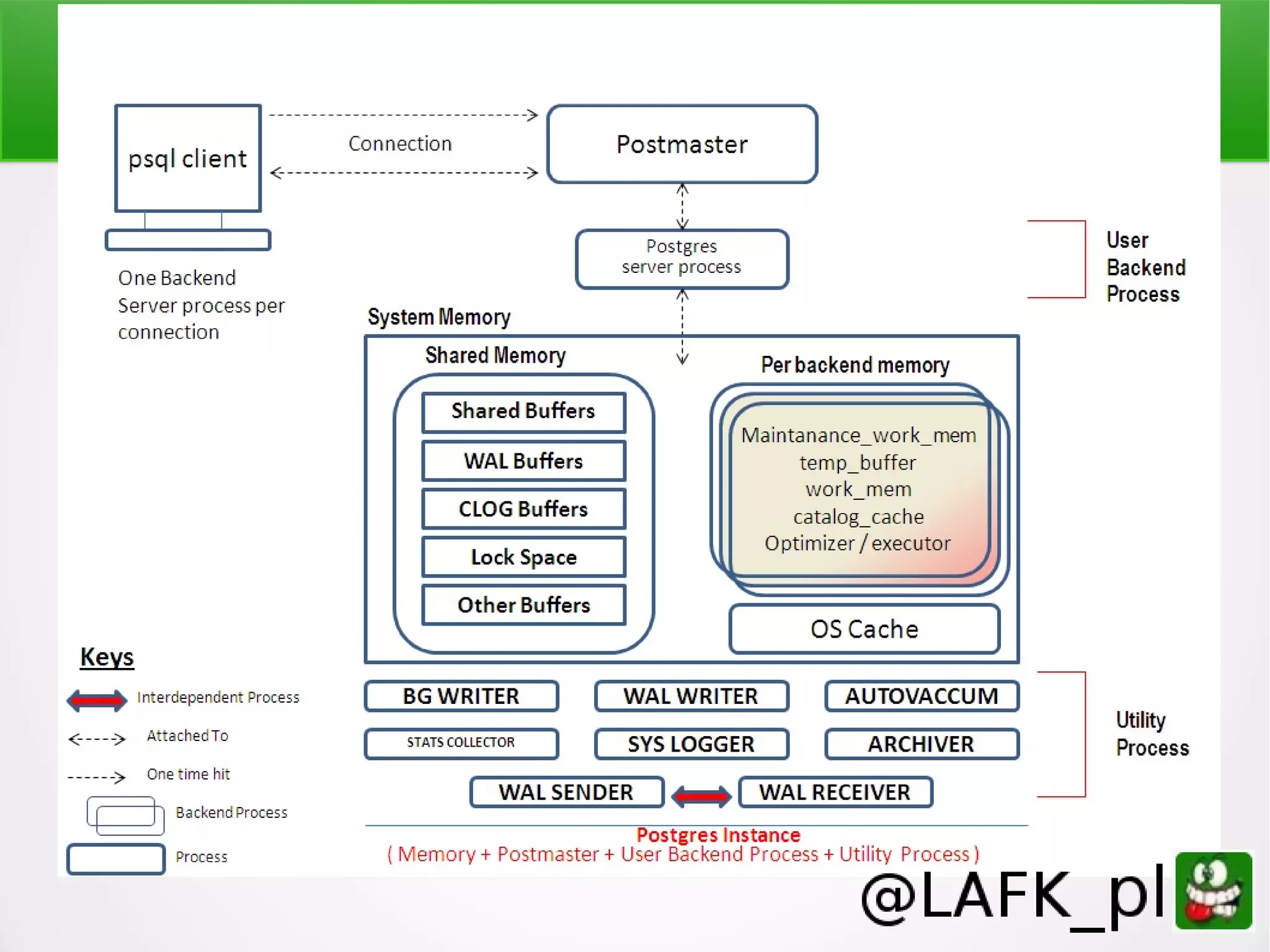

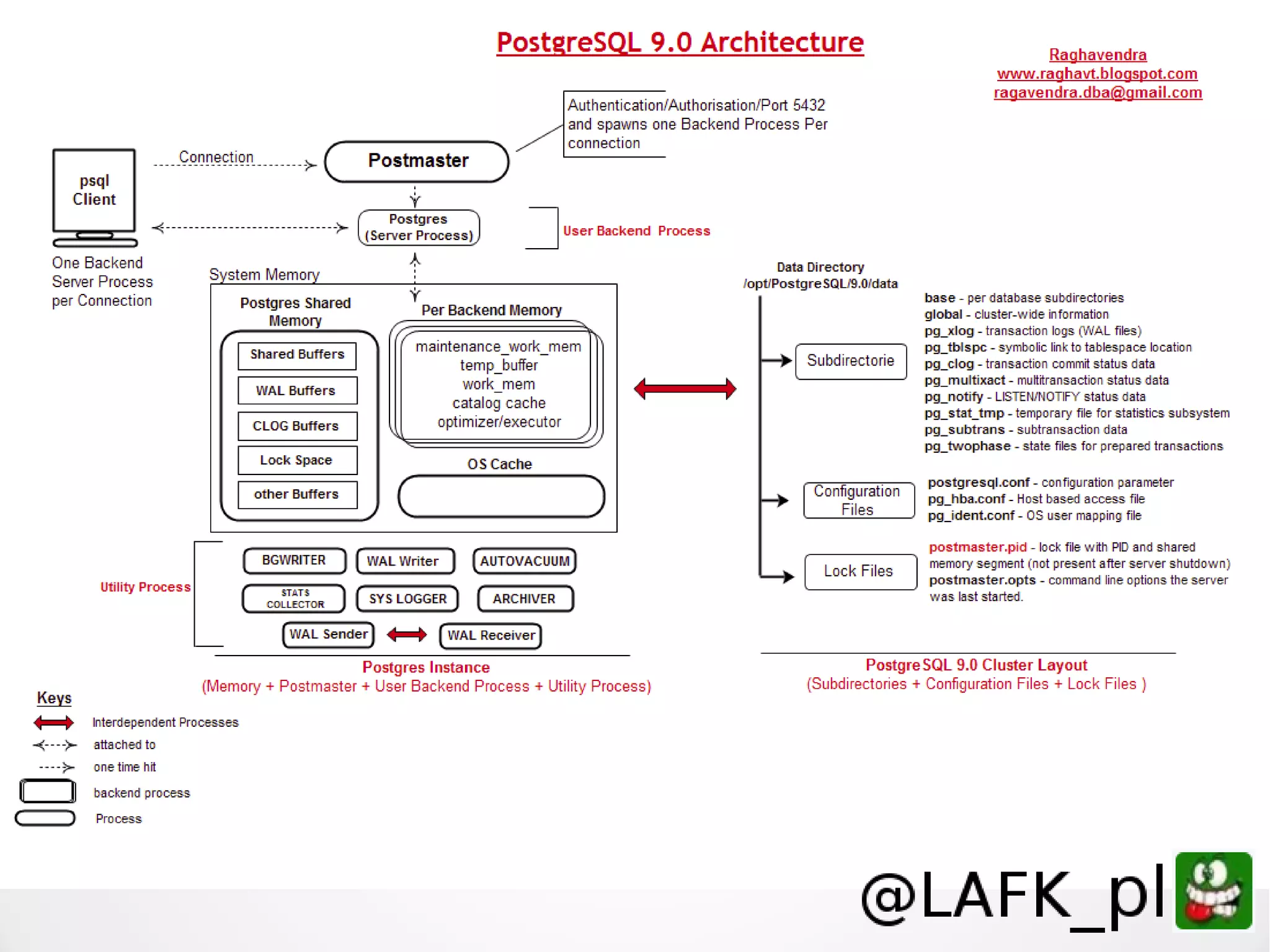








Tomasz Borek discusses teaching PostgreSQL to various audiences, emphasizing the importance of understanding learners' backgrounds and comfort zones. The presentation covers effective teaching strategies, learning styles, and various features of PostgreSQL that can enhance knowledge retention and practical application. Key topics include error reporting, stored procedures, and JSON/XML support, with an emphasis on making learning accessible and engaging.