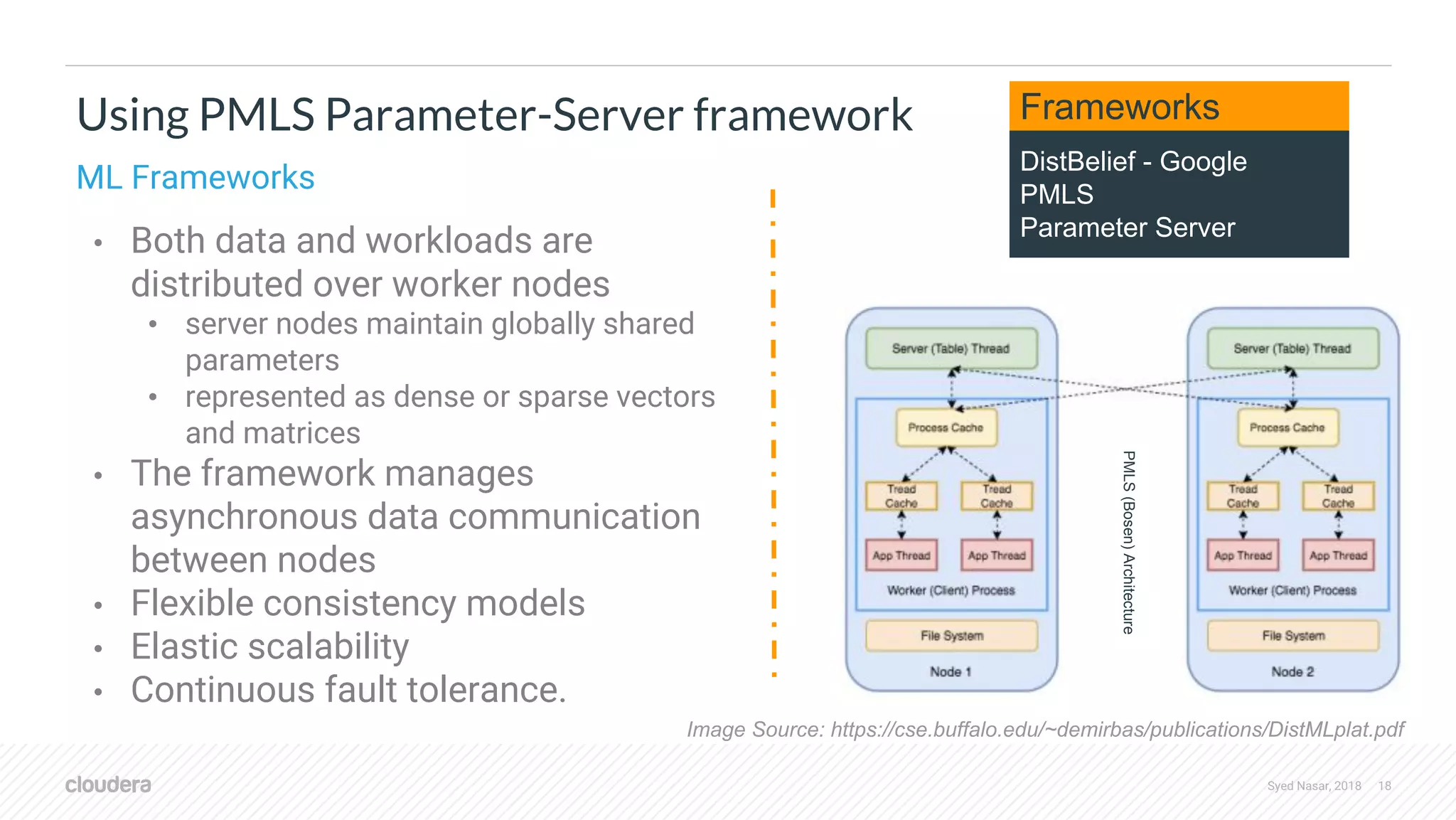
Downloaded 12 times









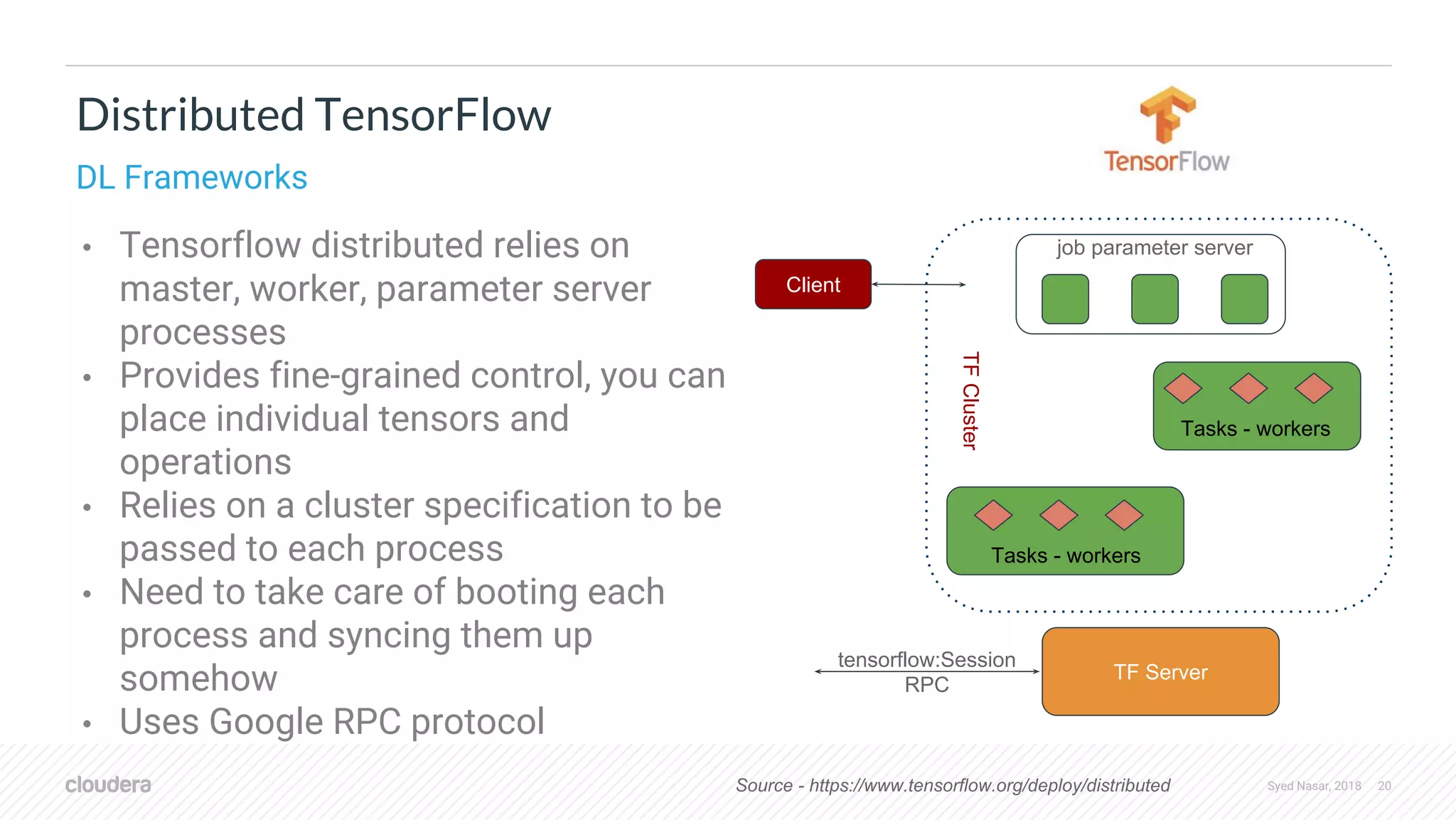
![Syed Nasar, 2018 21 Distributed TensorFlow tf.train.ClusterSpec({ "worker": [ "worker0.example.com:2222", "worker1.example.com:2222", "worker2.example.com:2222" ], "ps": [ "ps0.example.com:2222", "ps1.example.com:2222" ]}) # In task 0: cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]}) server = tf.train.Server(cluster, job_name="local", task_index=0) # In task 1: cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]}) server = tf.train. Server(cluster, job_name="local", task_index=1) tf.train.ClusterSpec tf.train.Server](https://image.slidesharecdn.com/stratadata2018-sparkanddeeplearningframeworkswithdistributedworkloads-linkedin-180914145229/75/Spark-and-Deep-Learning-frameworks-with-distributed-workloads-21-2048.jpg)
![Syed Nasar, 2018 22 • Has a distributed package that provides MPI style primitives for distributing work • Has interface for exchanging tensor data across multi-machine networks • Currently supports four backends (tcp, gloo, mpi, nccl - CPU/GPU) • Only recently incorporated • Not a lot of documentation PyTorch (torch.distributed) DL Frameworks import torch import torch.distributed as dist dist.init_process_group(backend="nccl", init_method="file:///distributed_test", world_size=2, rank=0) tensor_list = [] for dev_idx in range(torch.cuda.device_count()): tensor_list.append(torch.FloatTensor([1]).cuda(dev_idx )) dist.all_reduce_multigpu(tensor_list)Multi-GPU collective functions](https://image.slidesharecdn.com/stratadata2018-sparkanddeeplearningframeworkswithdistributedworkloads-linkedin-180914145229/75/Spark-and-Deep-Learning-frameworks-with-distributed-workloads-22-2048.jpg)


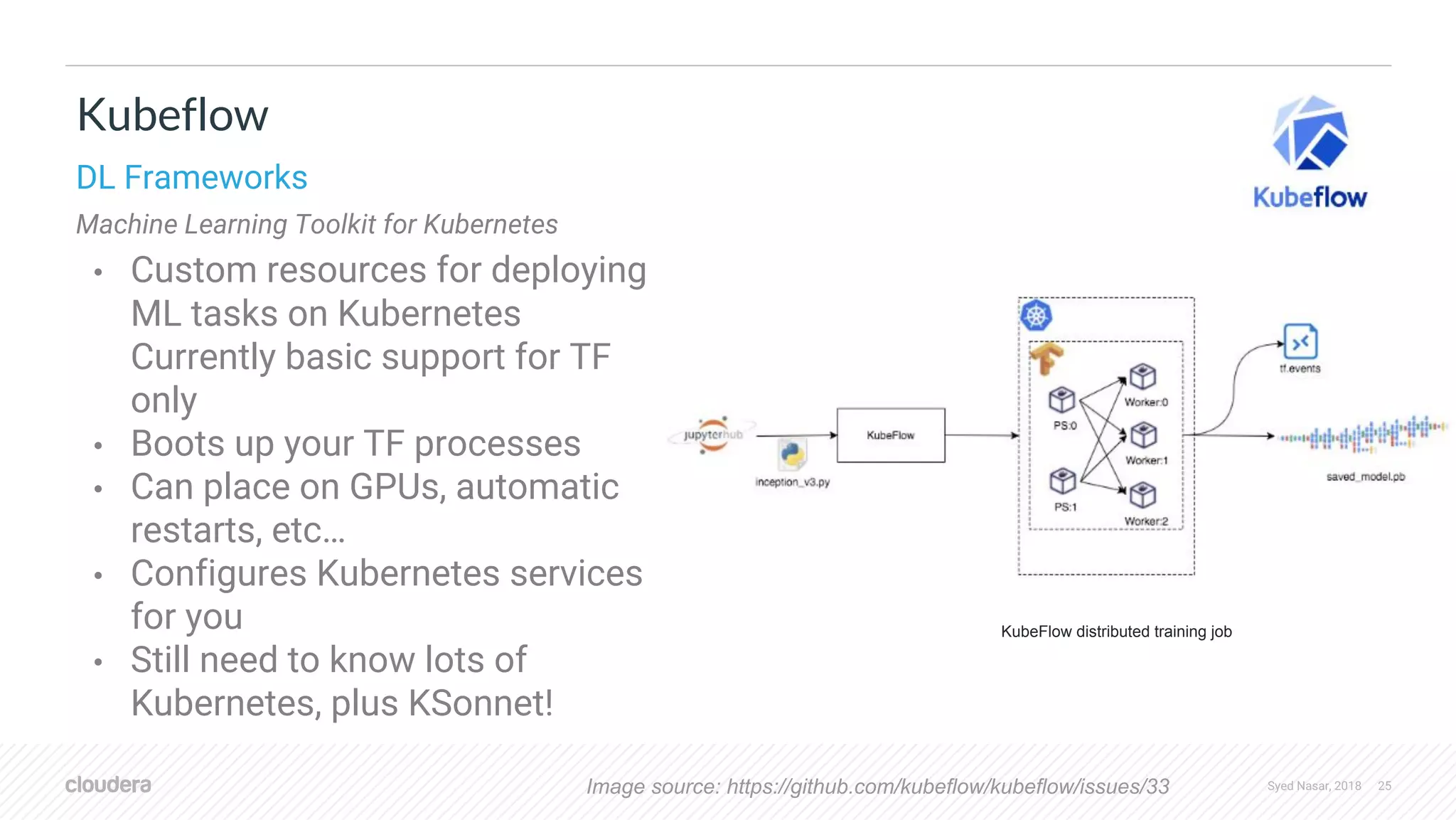


![Syed Nasar, 2018 29 • Released by Databricks for doing Transfer Learning and Inference as a Spark pipeline stage • Good for simple use cases • Relies on Databricks’ Tensorframes Spark DL Pipelines Tensorframes featurizer = DeepImageFeaturizer(inputCol="image", outputCol="features", modelName="InceptionV3") lr = LogisticRegression(maxIter=20, regParam=0.05, elasticNetParam=0.3, labelCol="label") p = Pipeline(stages=[featurizer, lr]) For technical preview only](https://image.slidesharecdn.com/stratadata2018-sparkanddeeplearningframeworkswithdistributedworkloads-linkedin-180914145229/75/Spark-and-Deep-Learning-frameworks-with-distributed-workloads-29-2048.jpg)

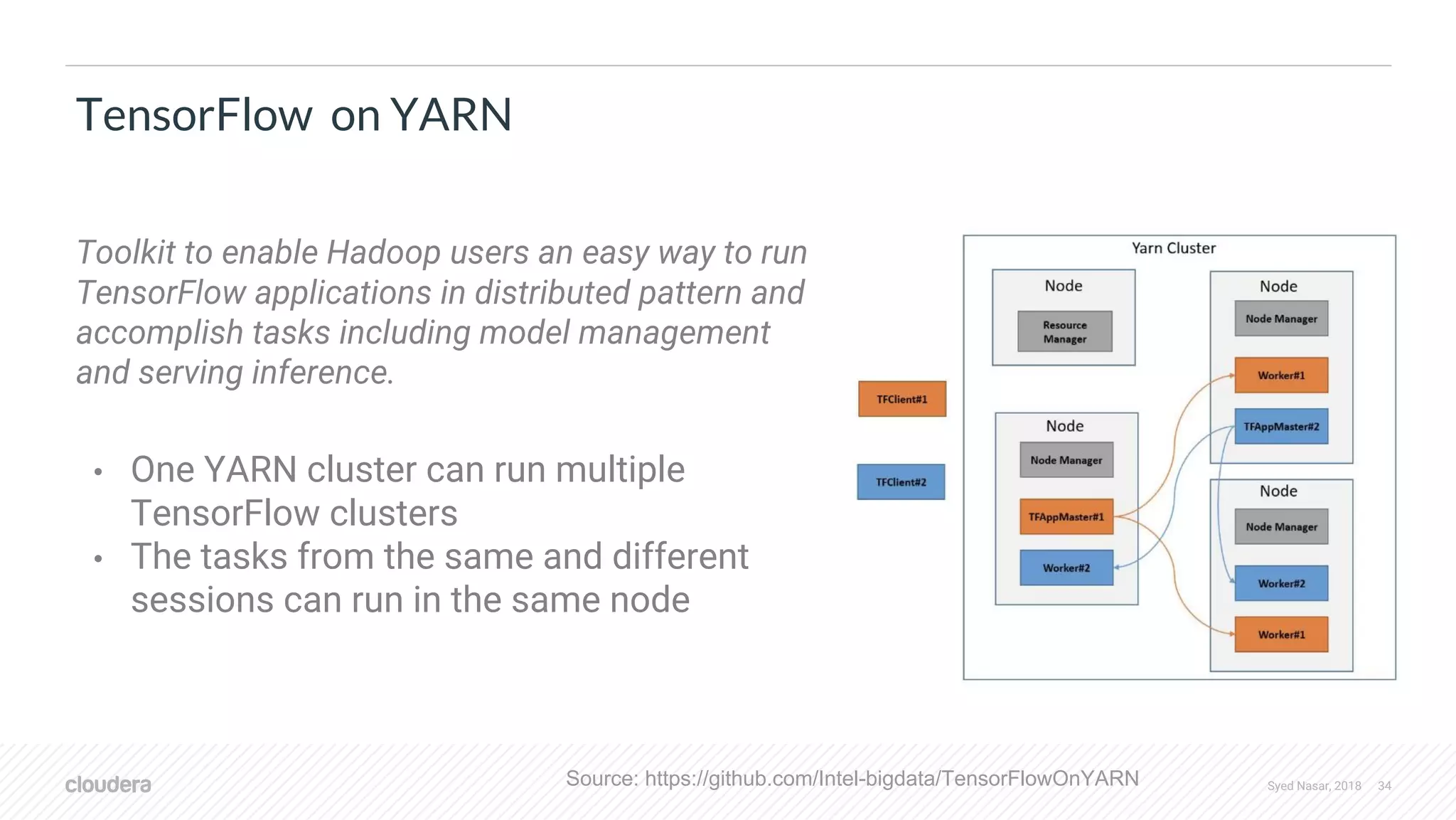
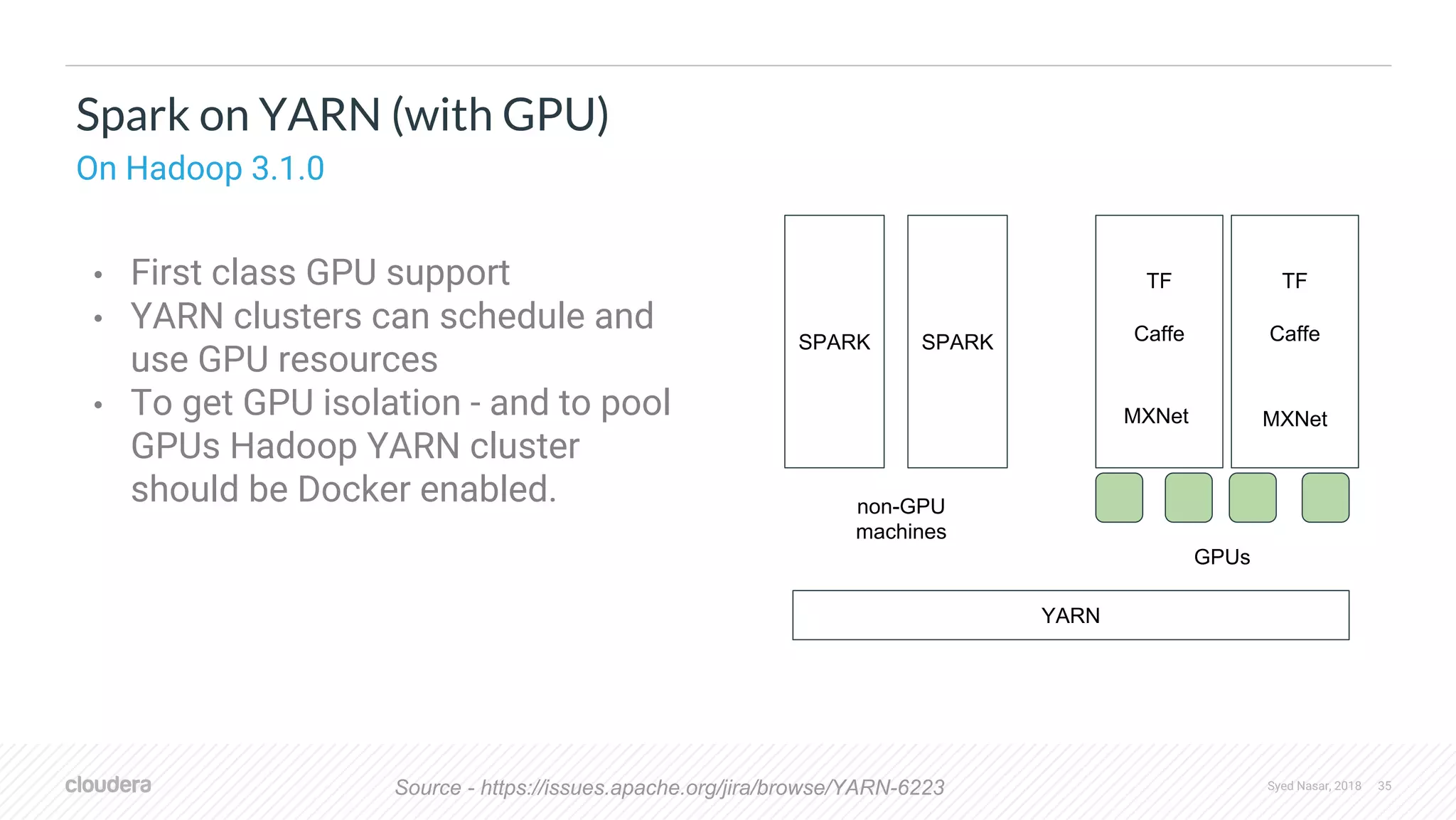





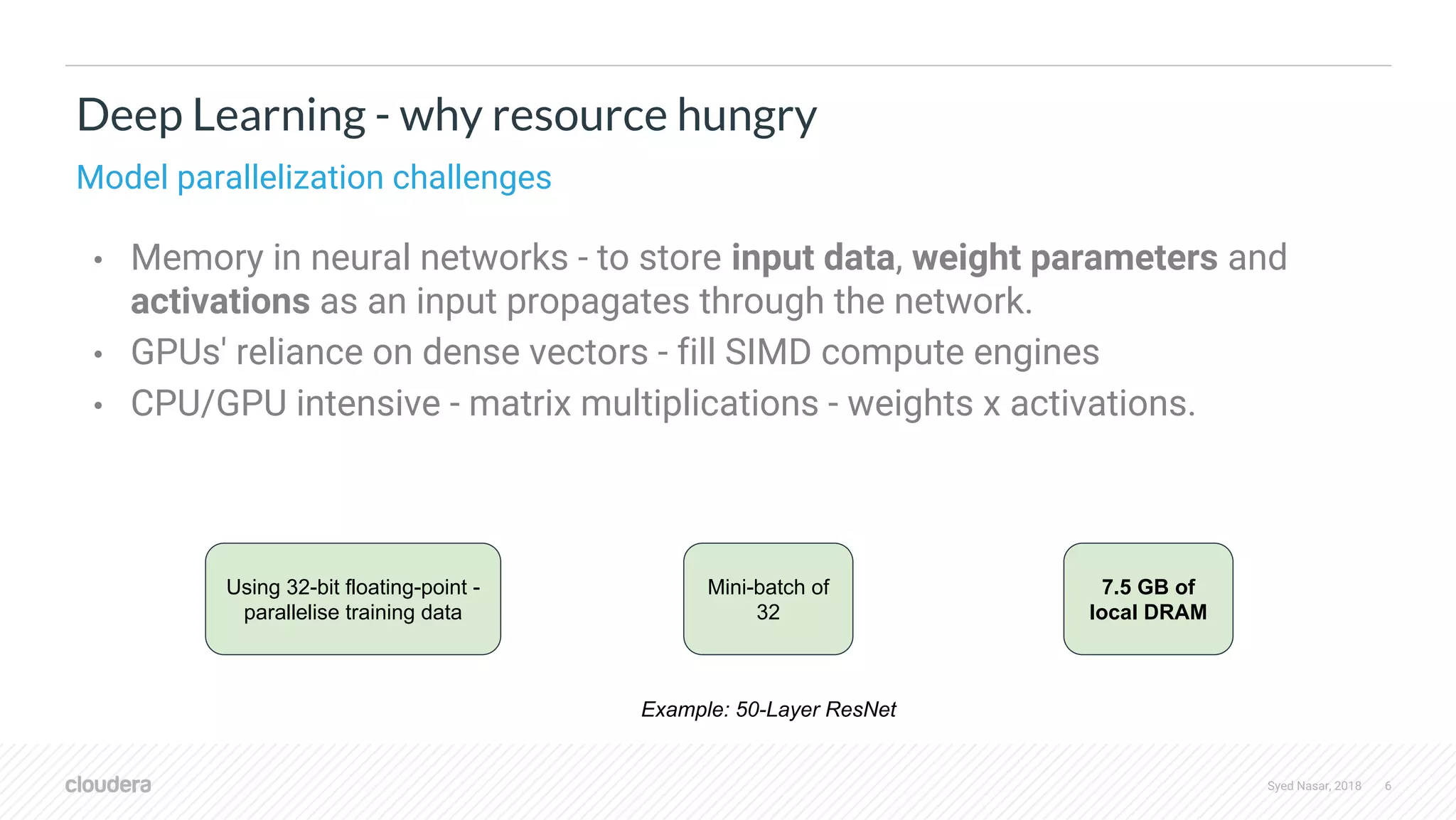
The document discusses the utilization of machine learning (ML) and deep learning (DL) on scalable infrastructures, comparing the performance of CPUs and GPUs and examining distribution challenges of ML pipelines. It highlights various frameworks used for distributed ML and DL, detailing architecture, training processes, and tools like TensorFlow and PyTorch. Additionally, it covers advancements in resource management with technologies like YARN and their support for GPUs, focusing on improvements in handling deep learning workloads.