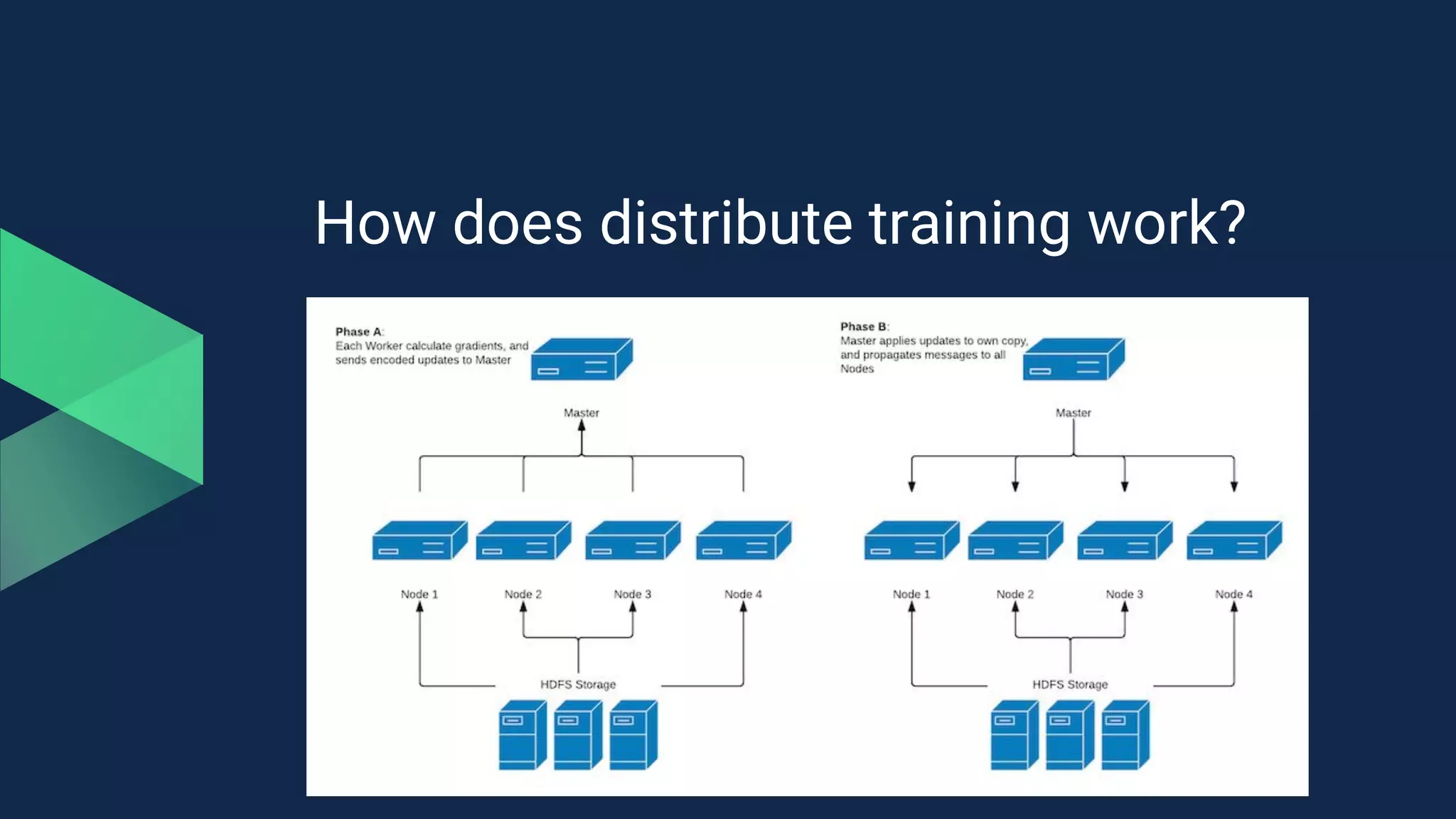
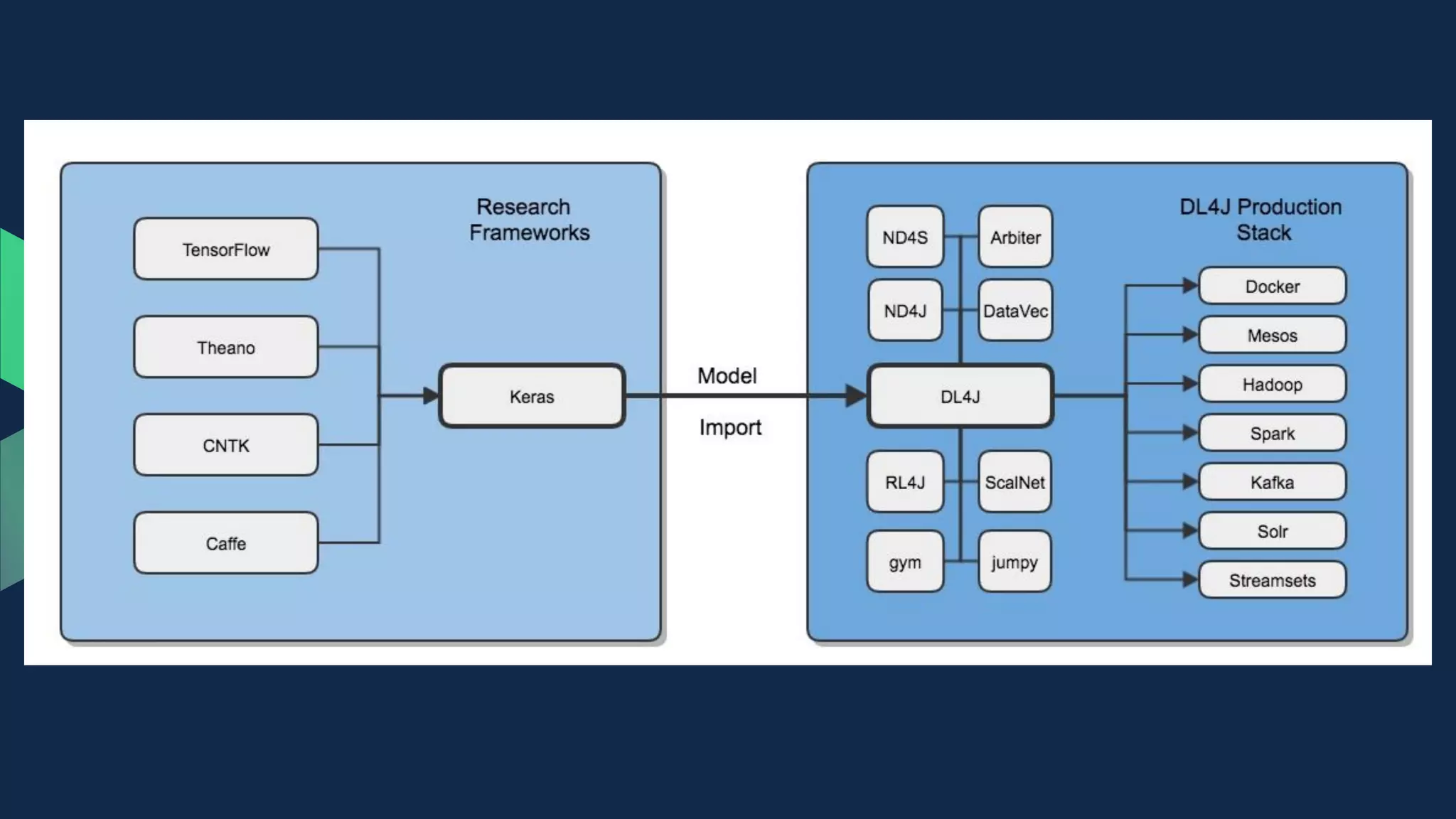
The document outlines the purposes and features of the deeplearning4j (DL4J) architecture, which include building, deploying, and serving machine learning models, with a focus on maximizing business KPIs. It describes the capabilities of the ND4J library for fast computations and distributed training, as well as various record readers and data transformation tools provided by DataVec. Additionally, it mentions potential training options on Spark and references current model accuracy benchmarks from the Zalando Fashion-MNIST dataset.