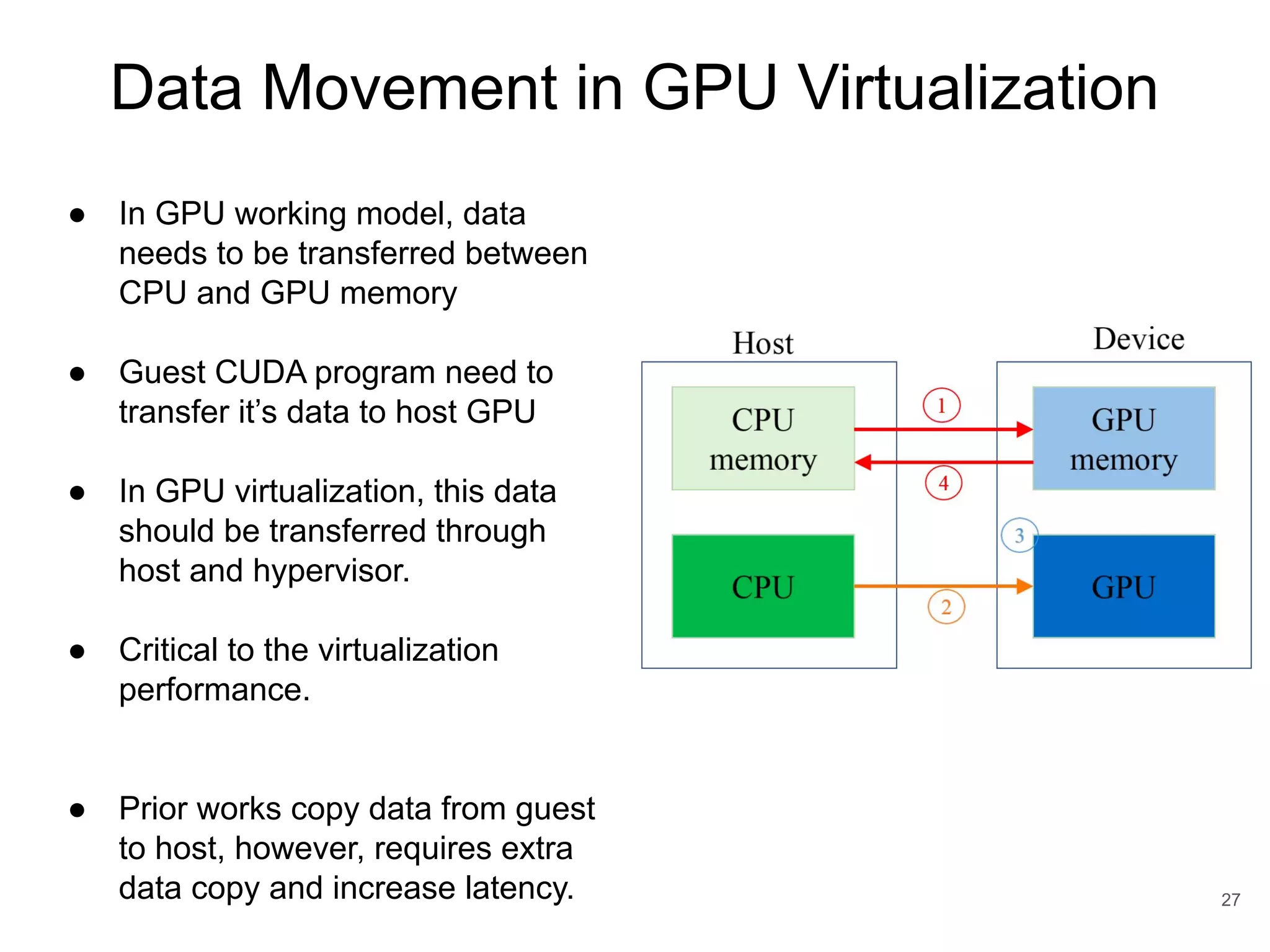
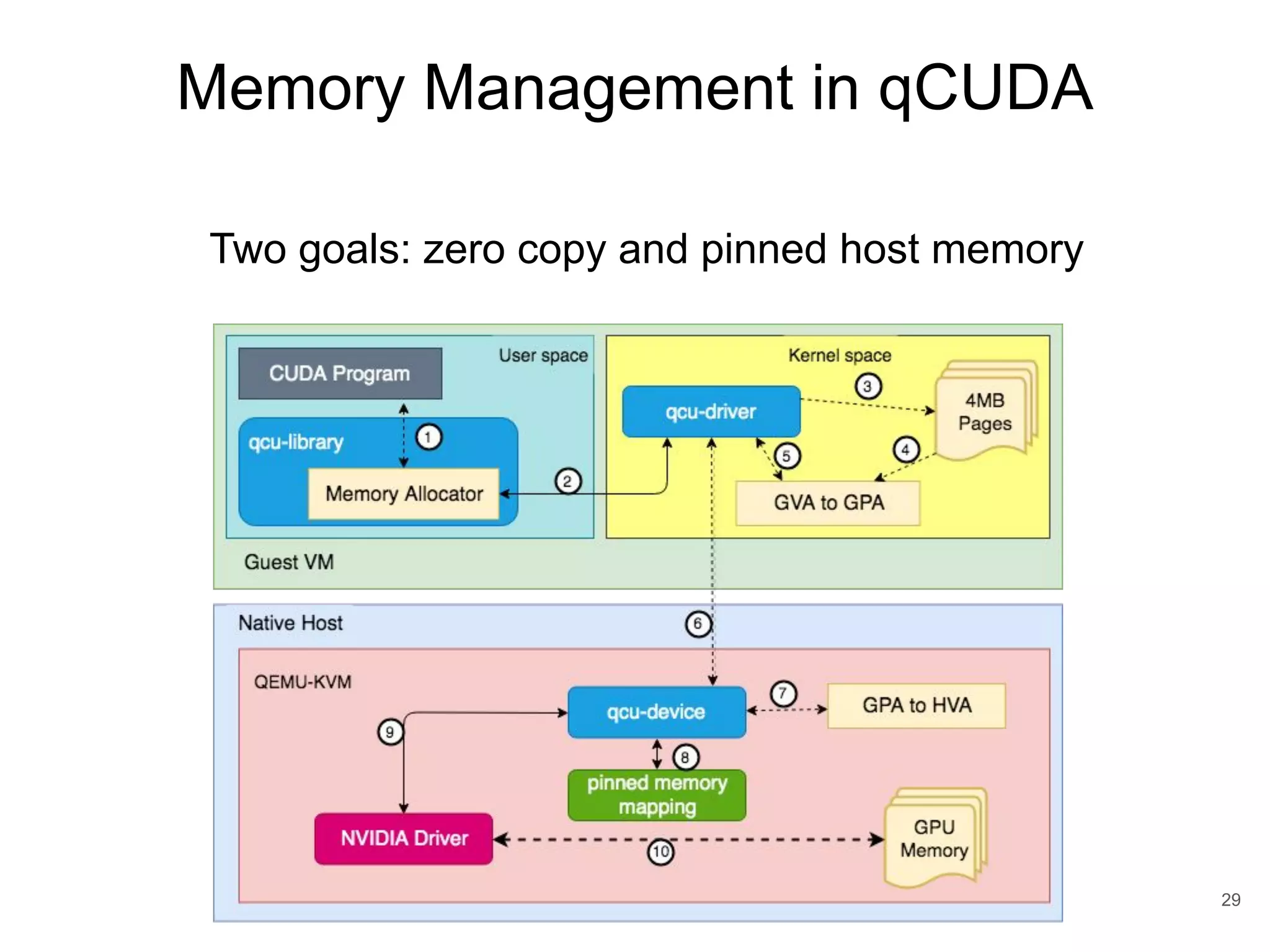
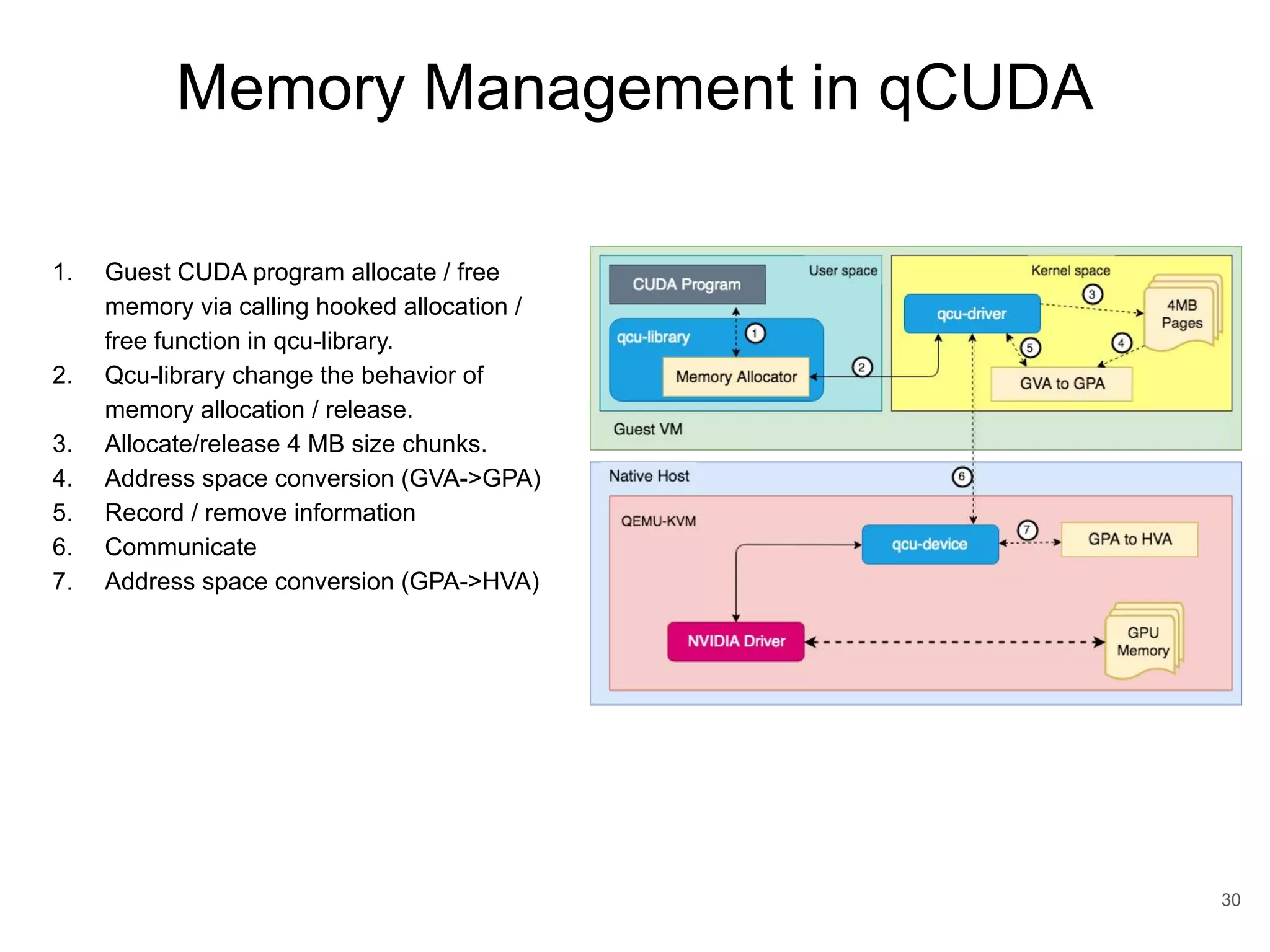
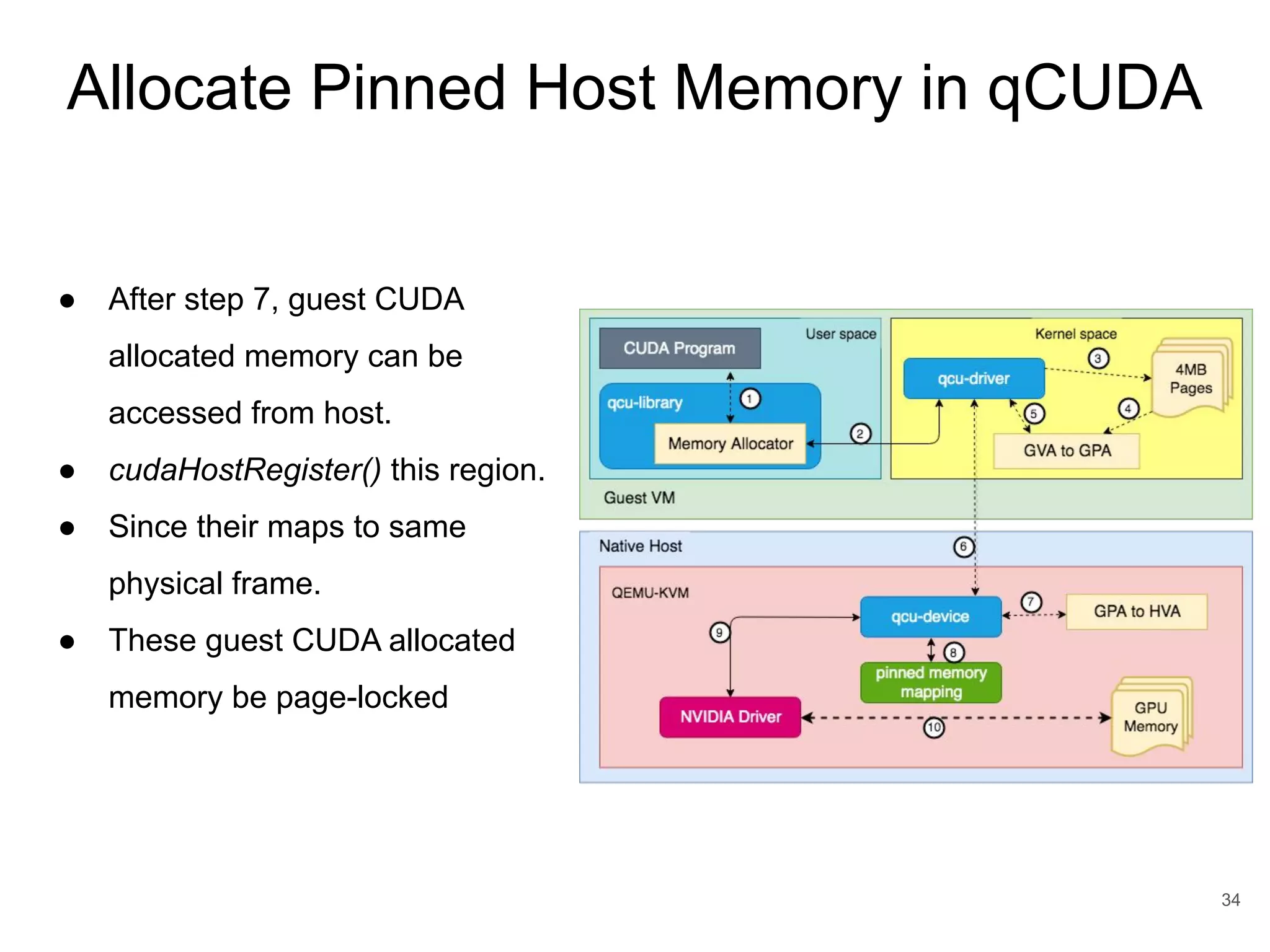
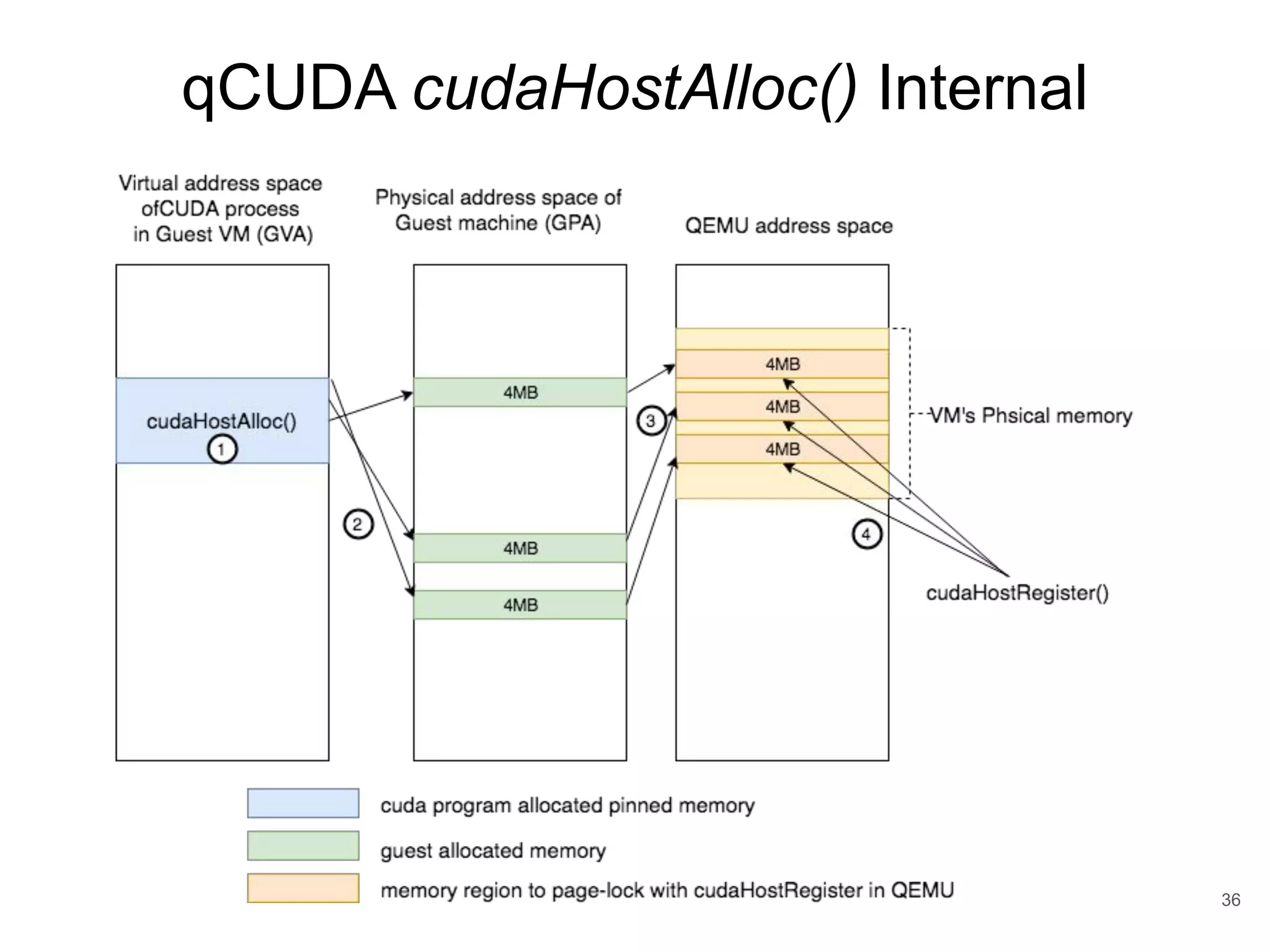
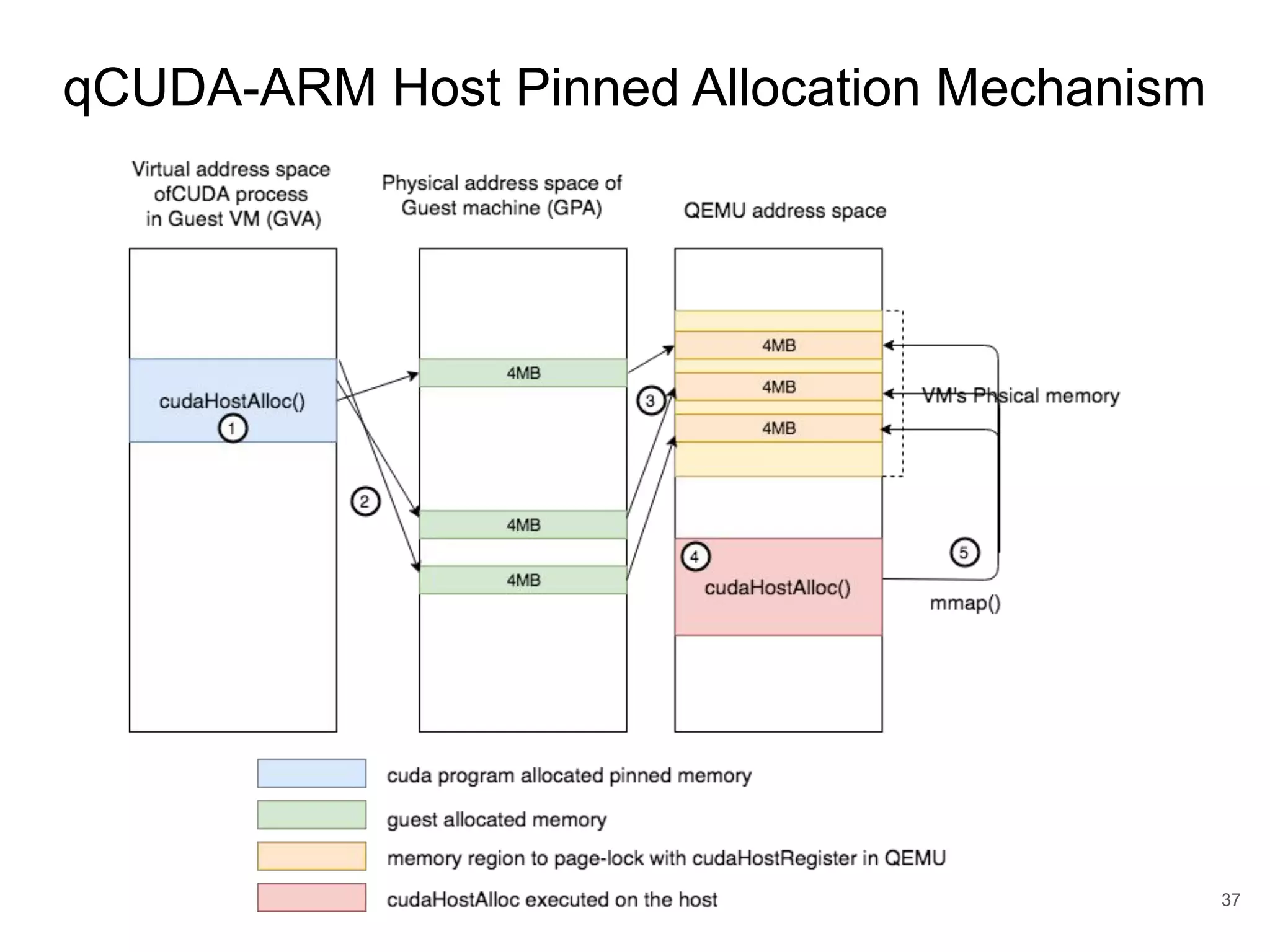
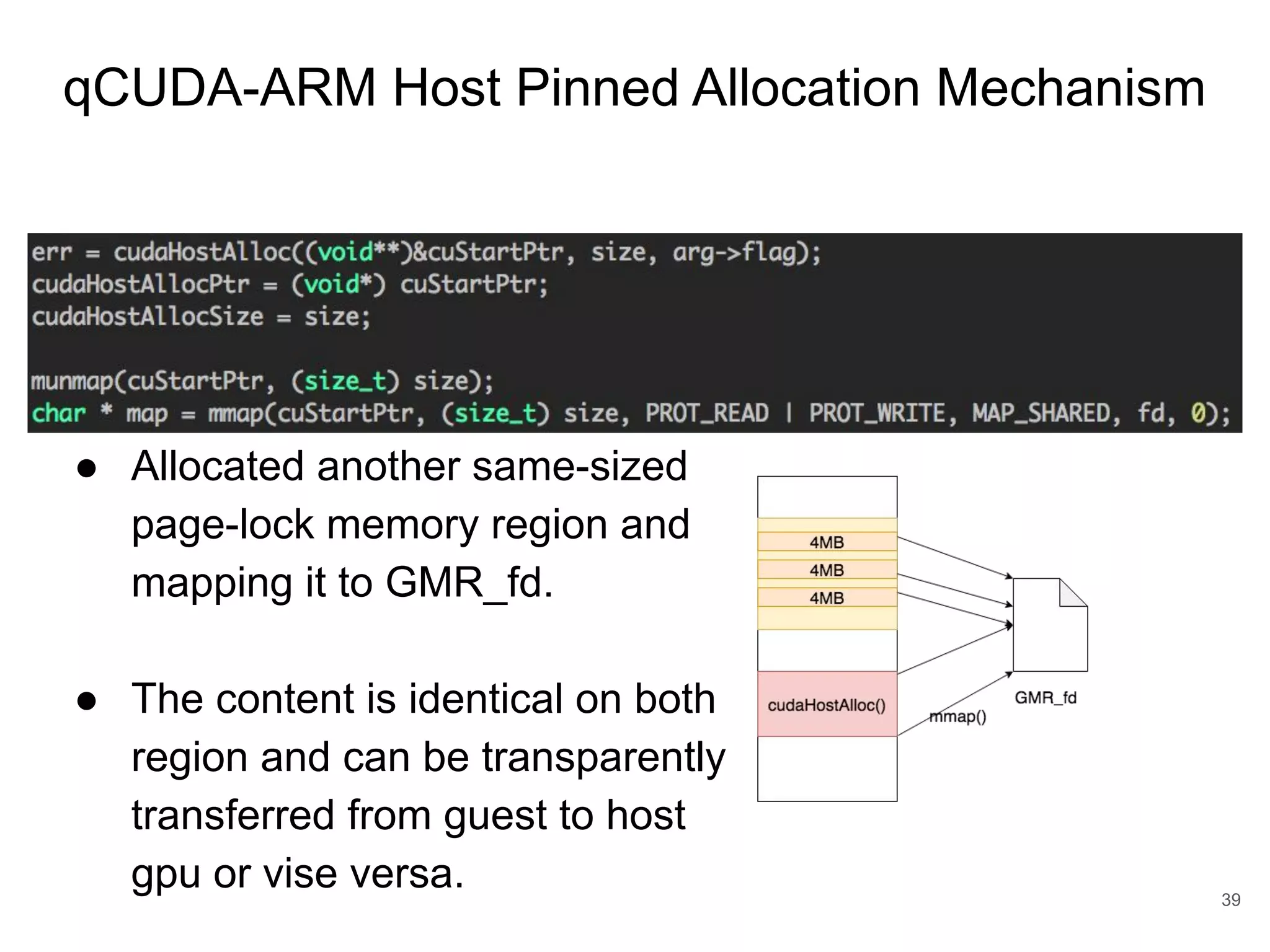
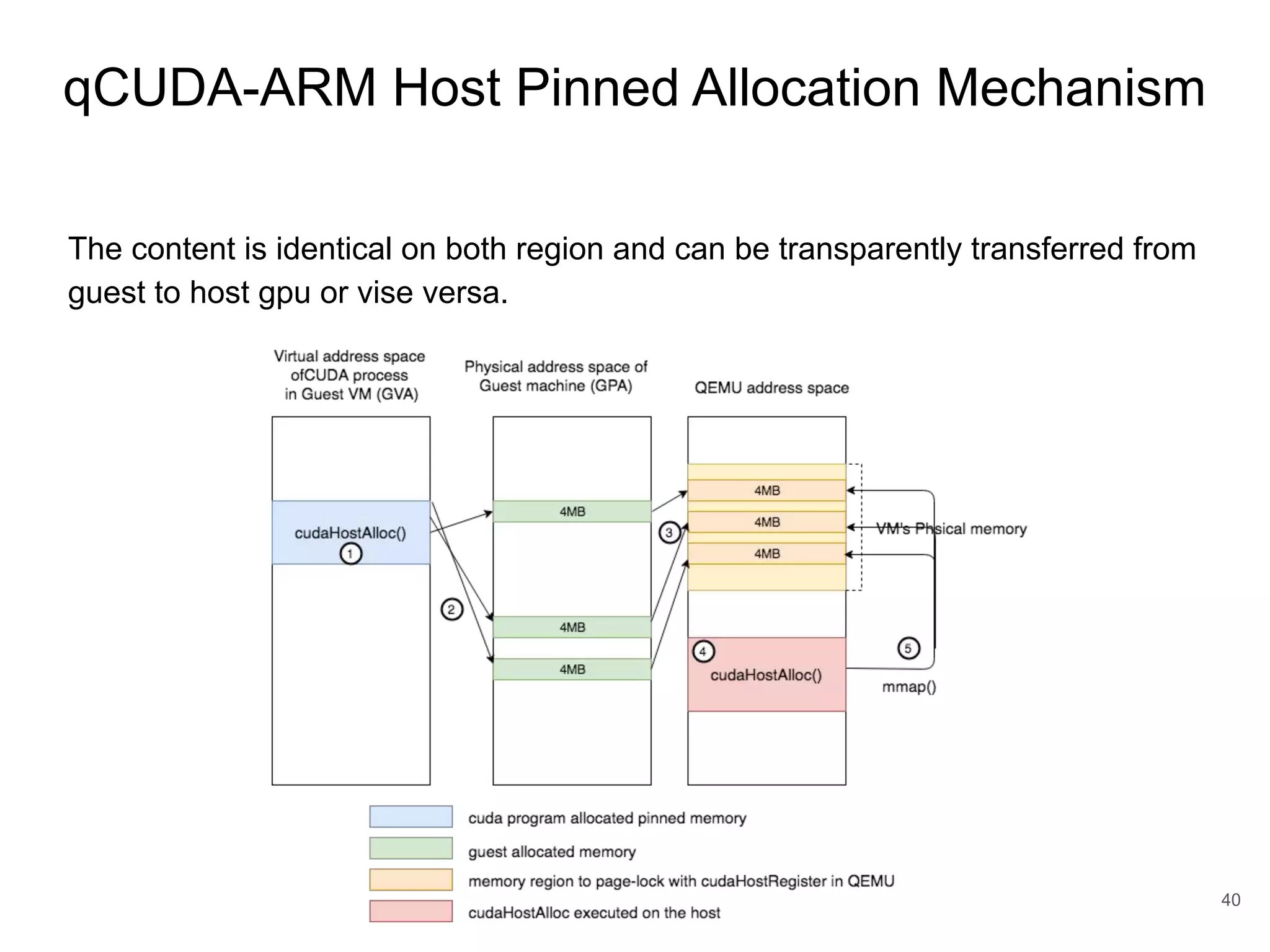
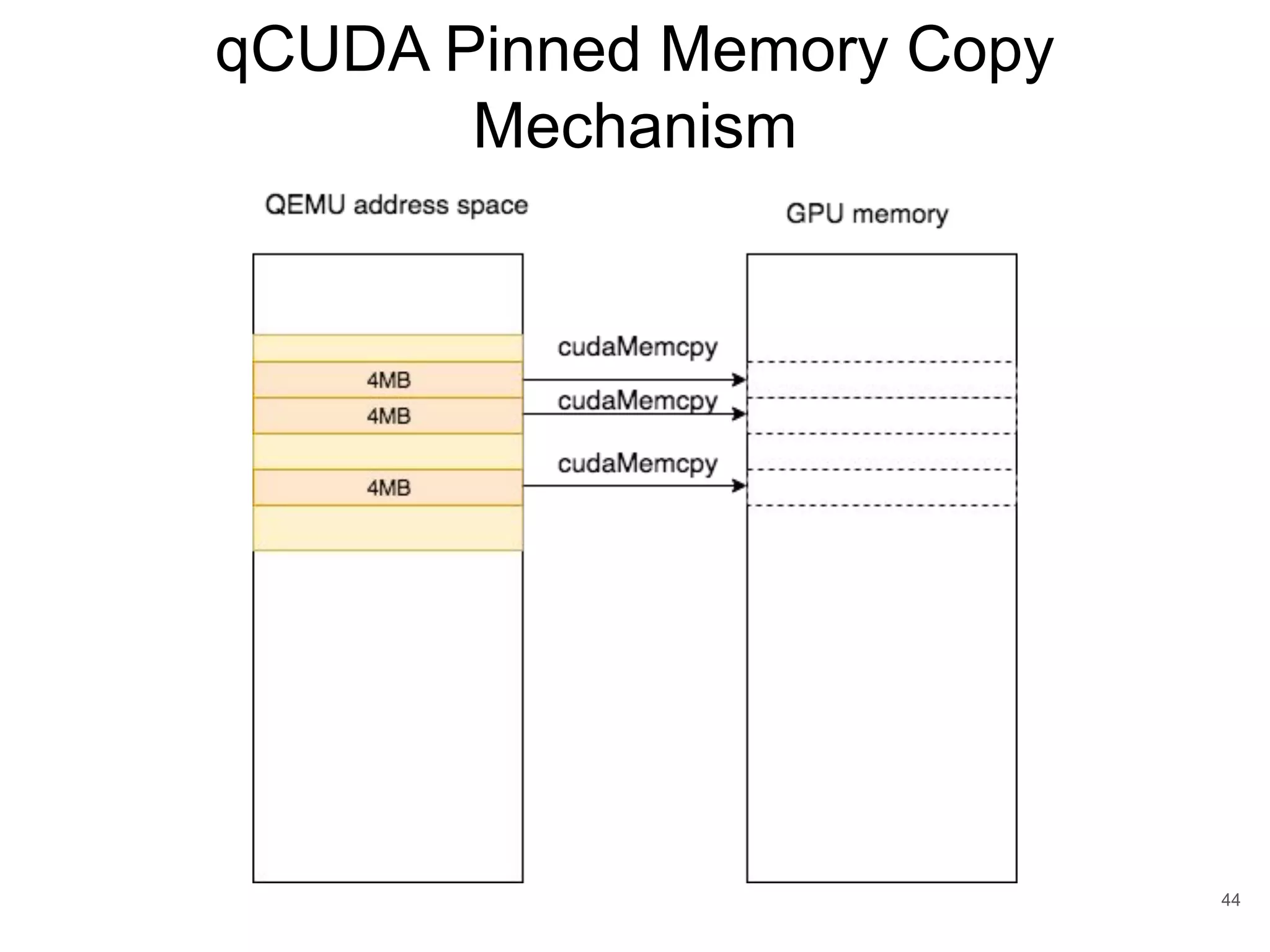
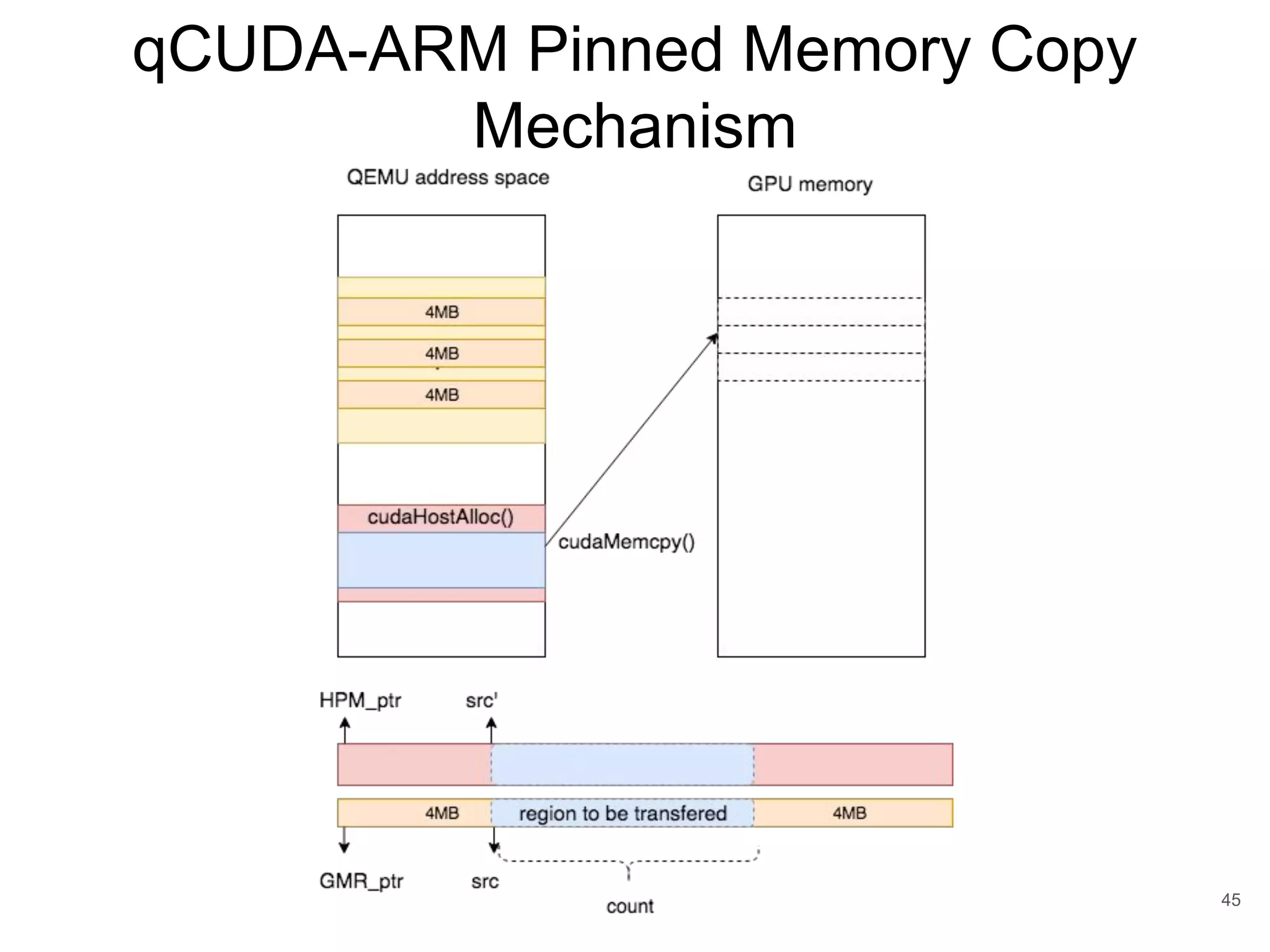
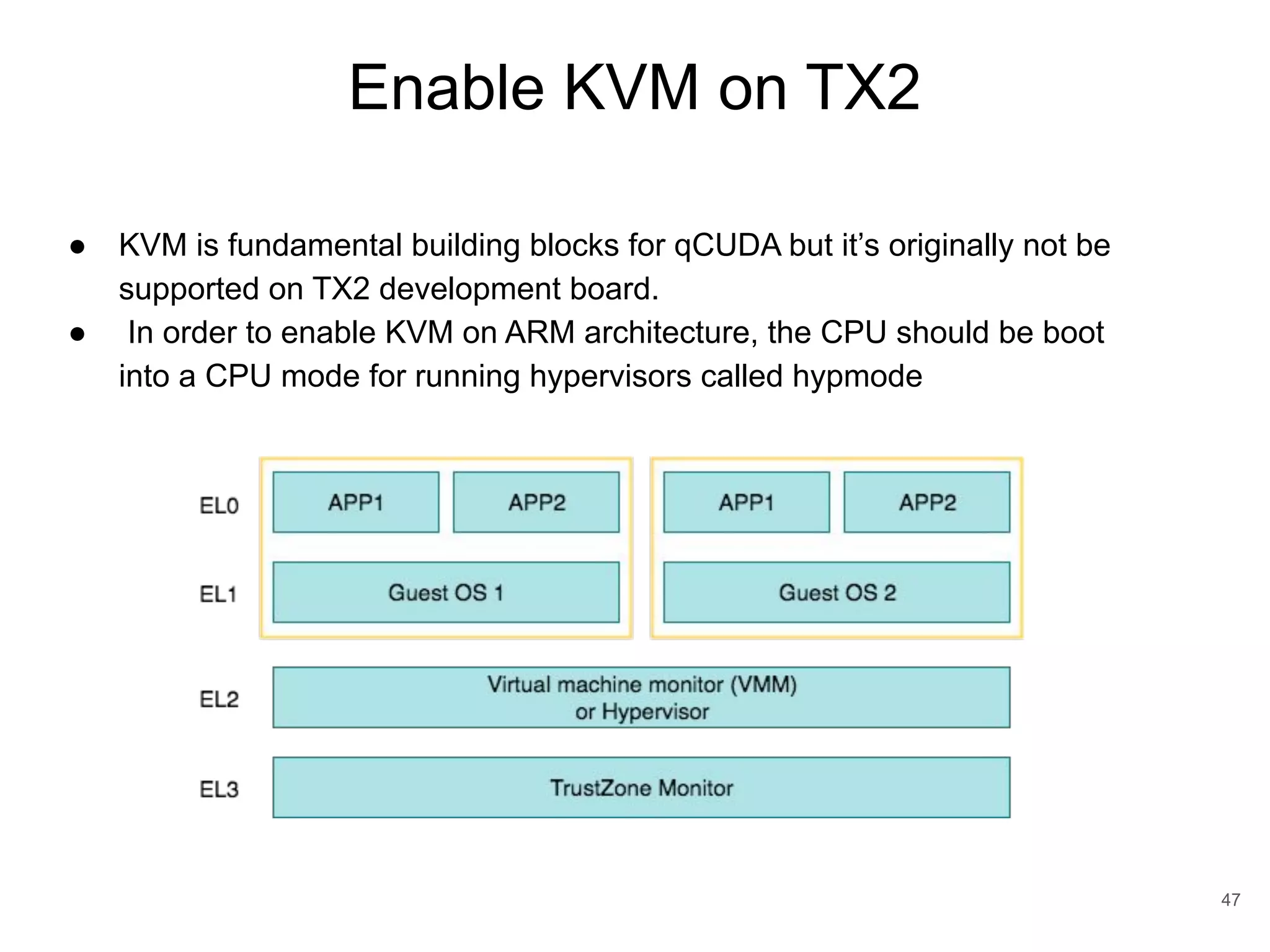
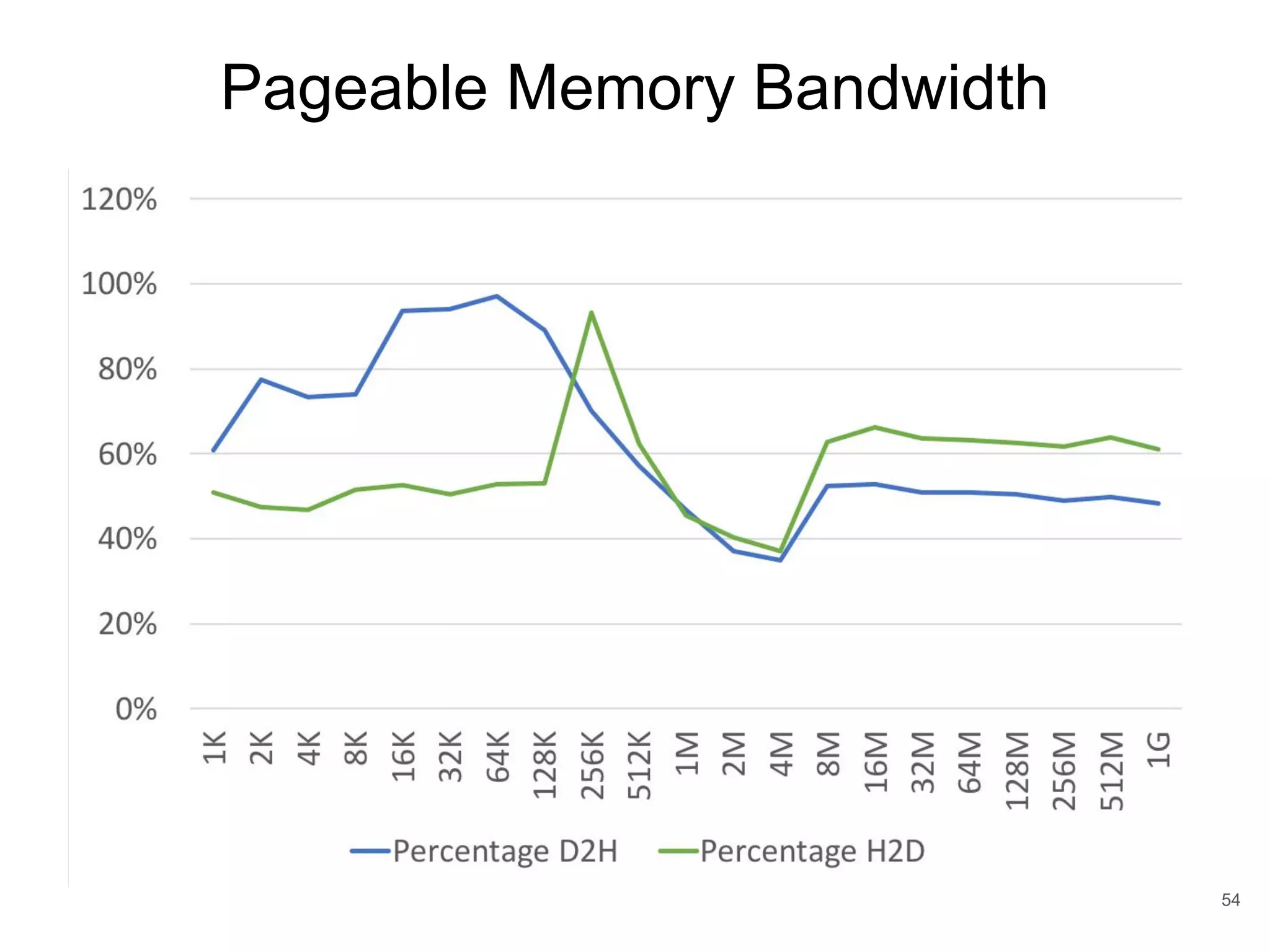
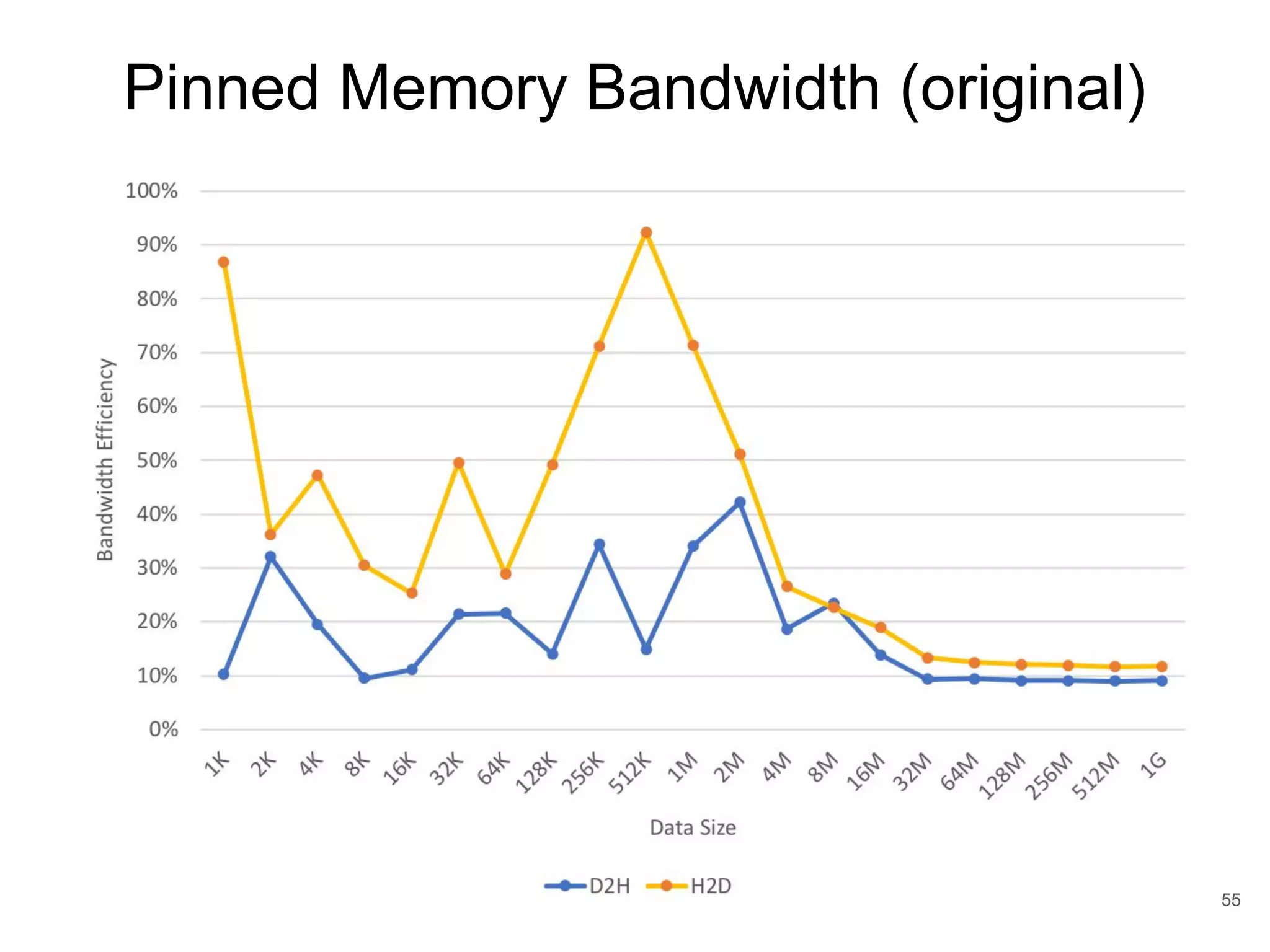
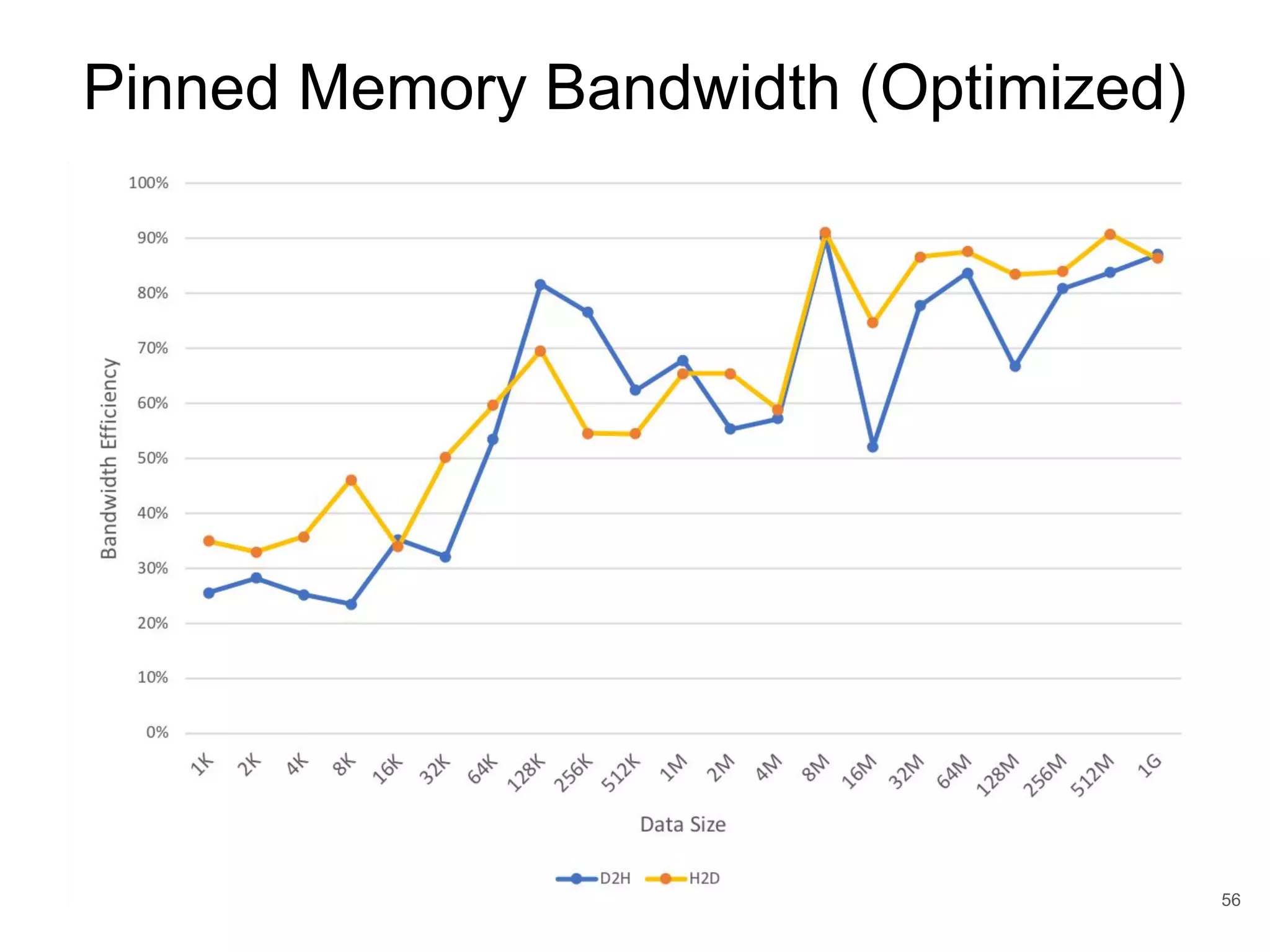
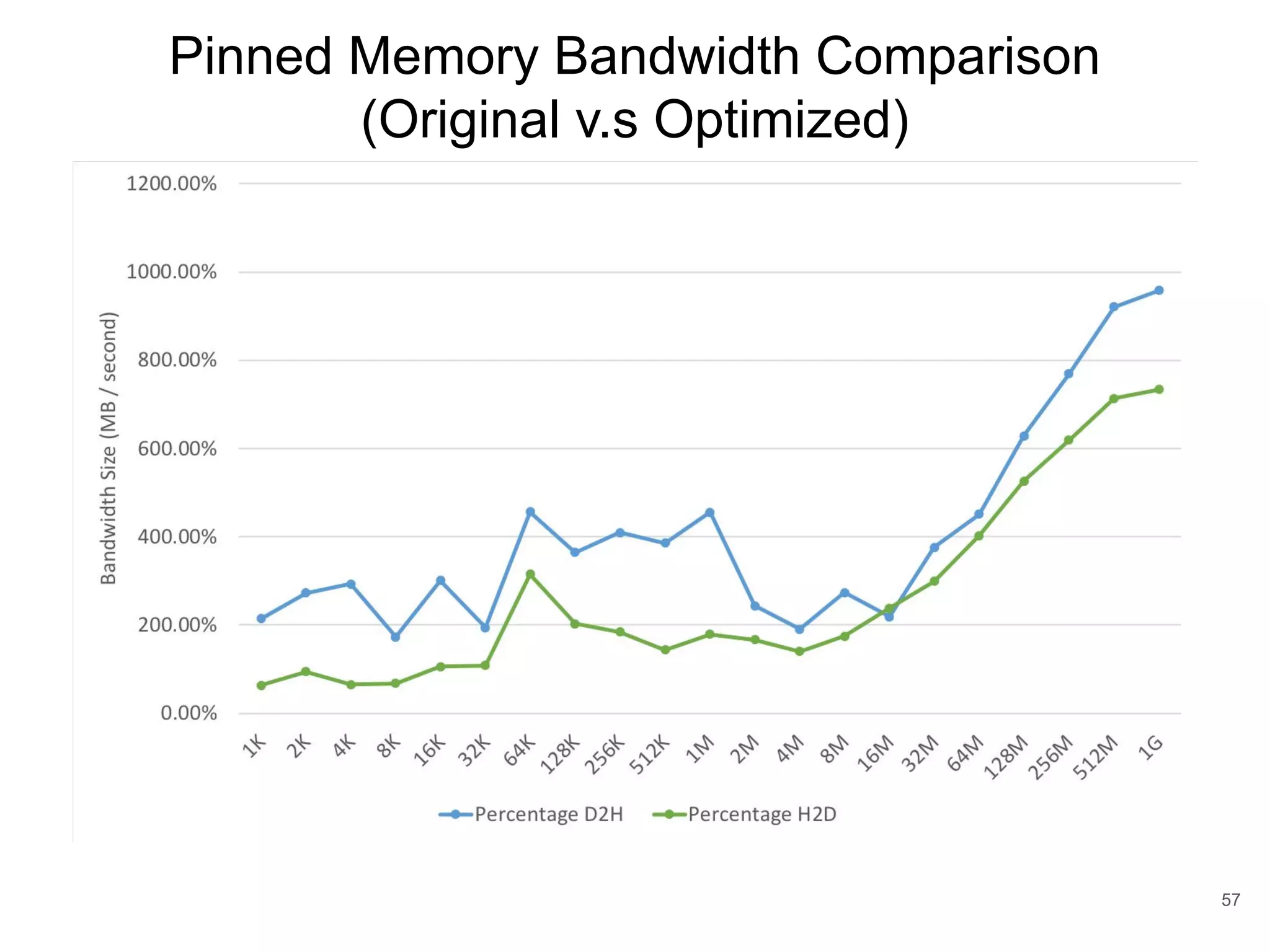
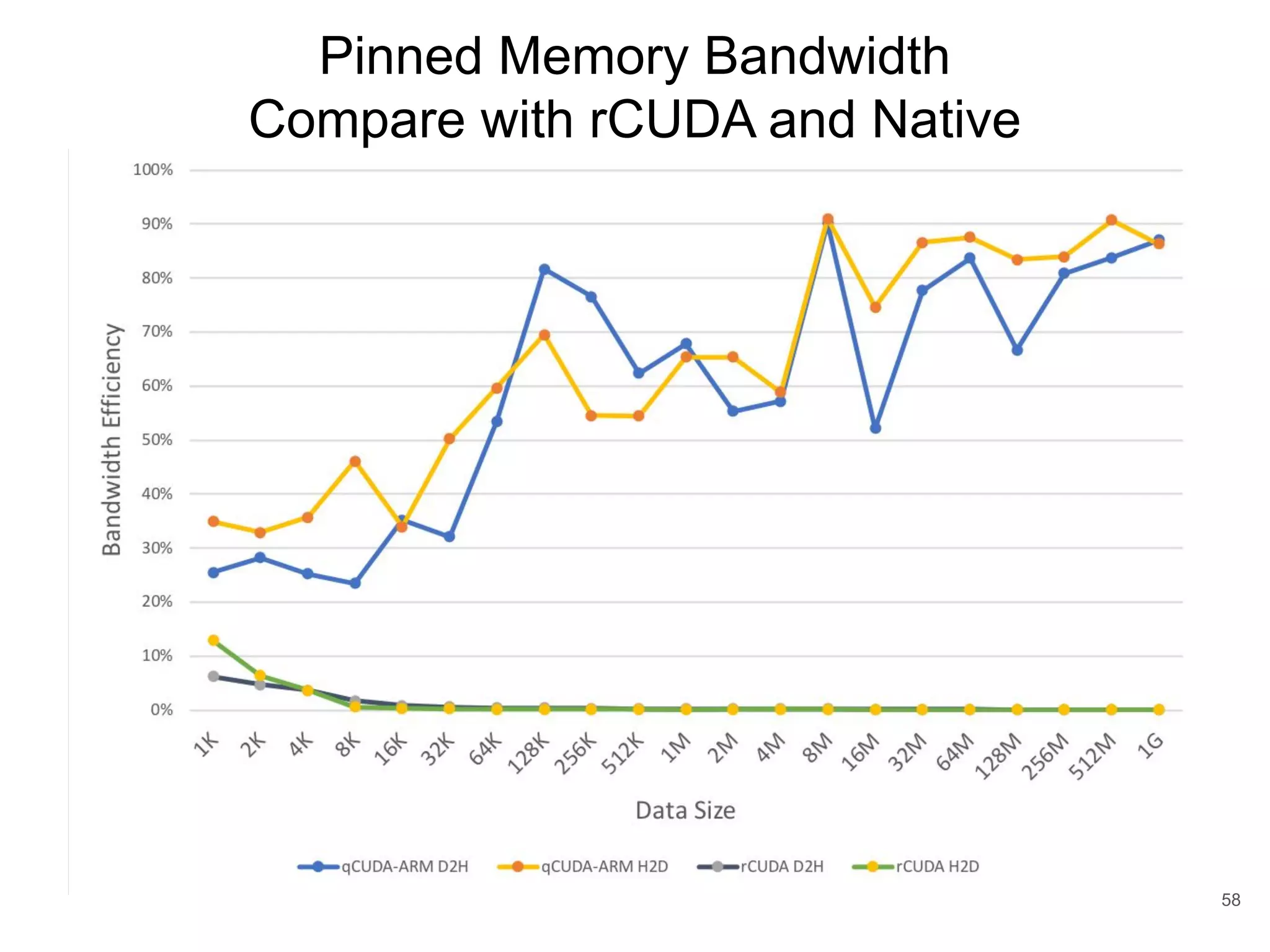
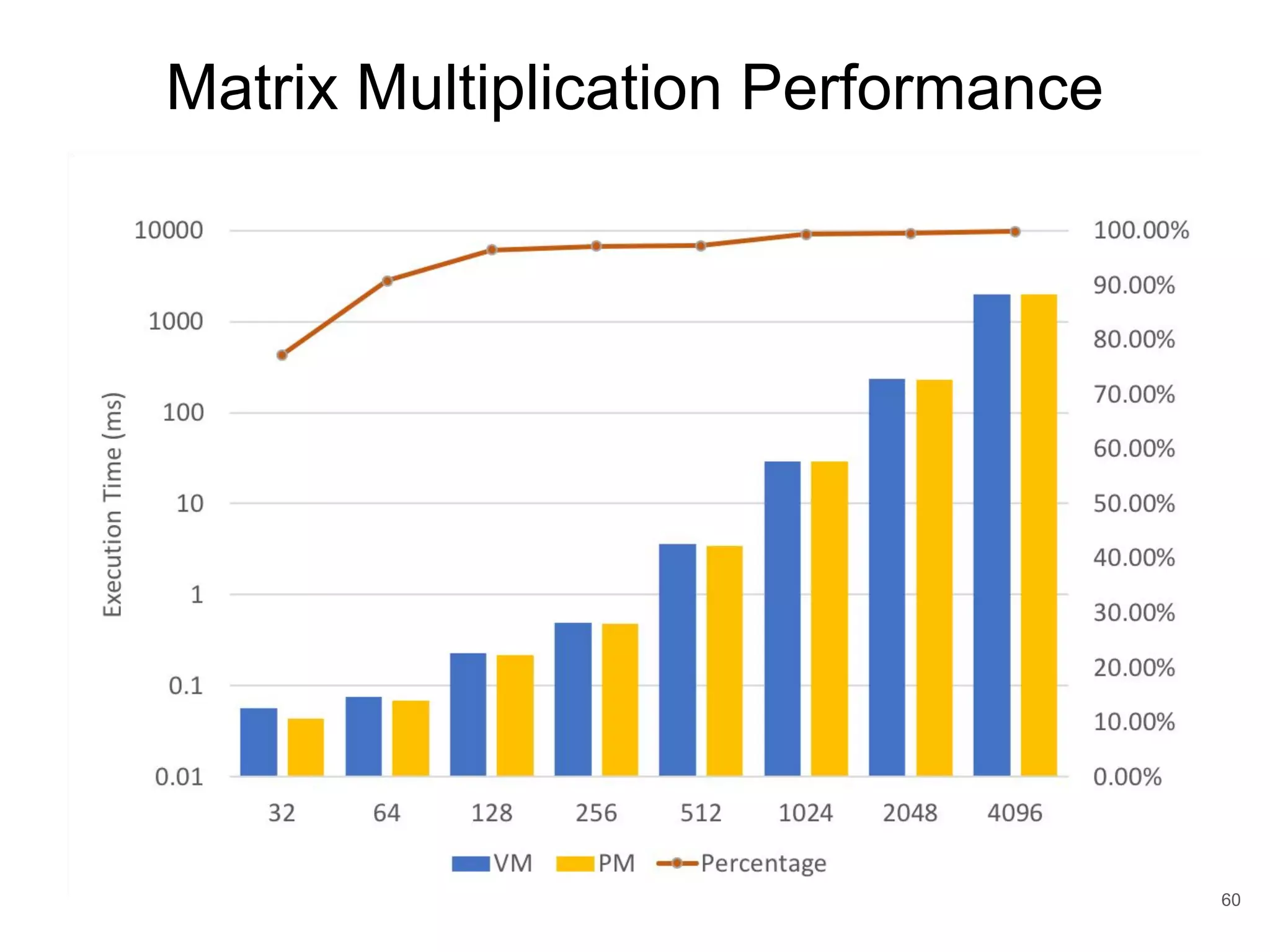
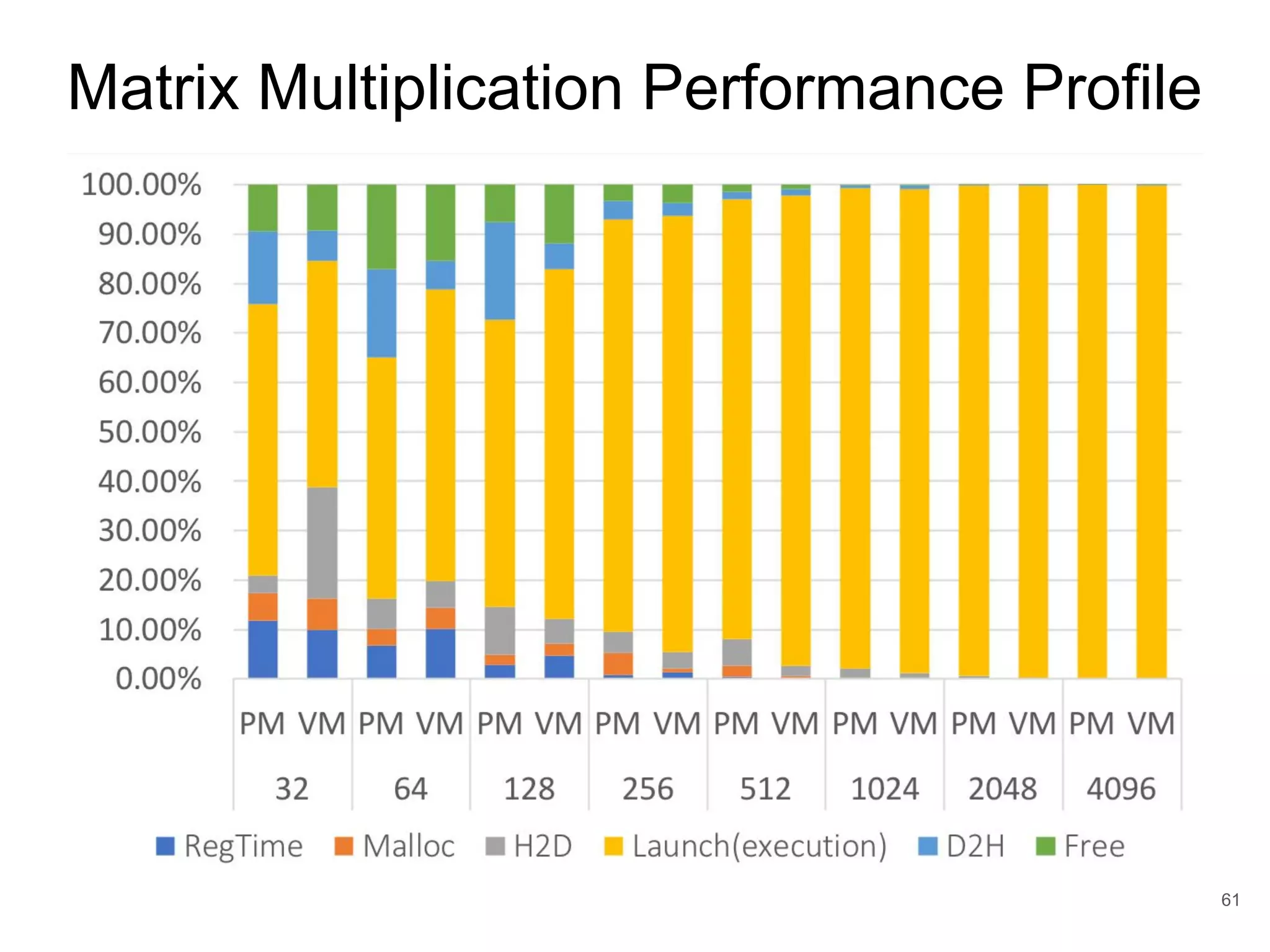
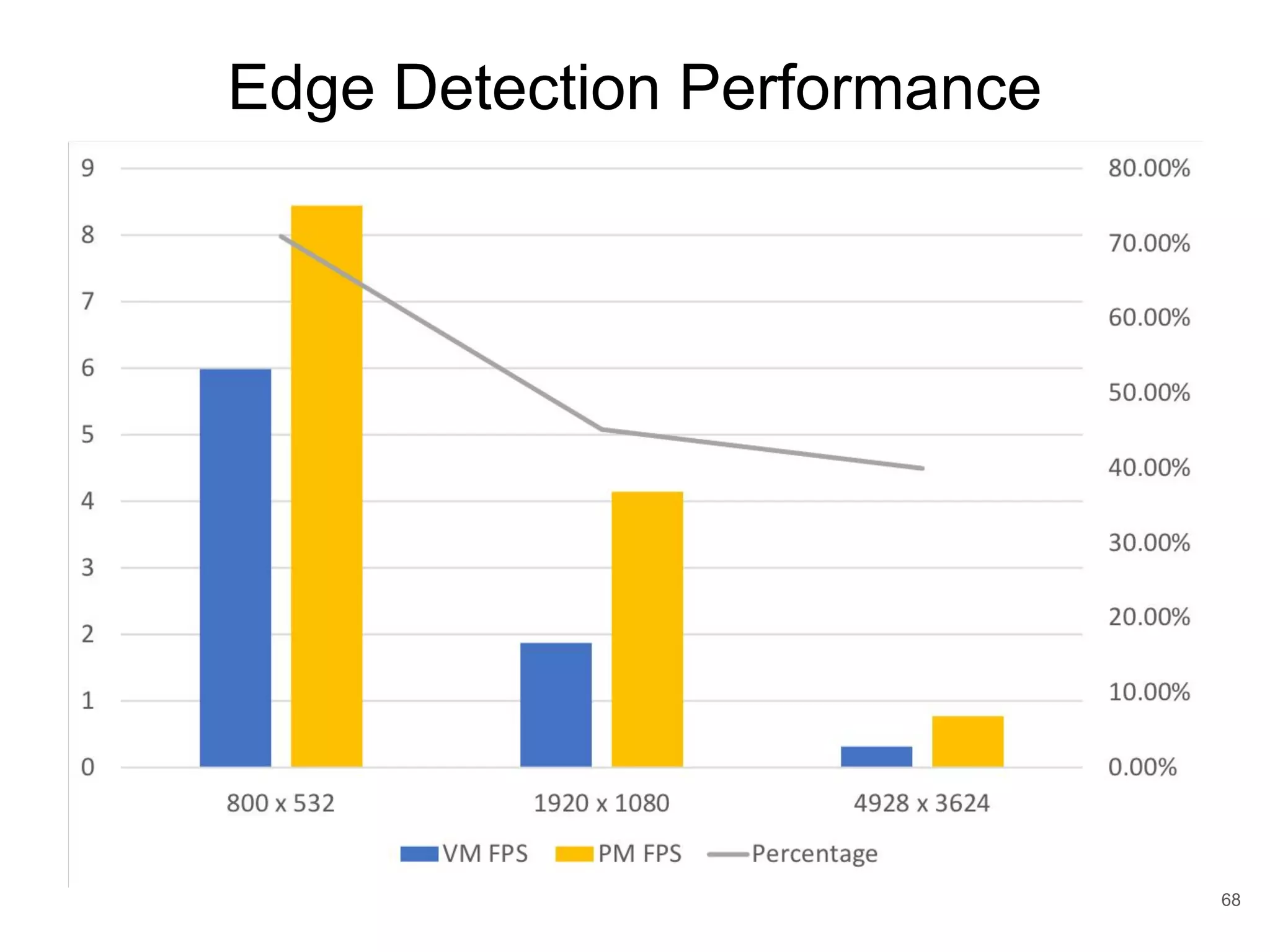
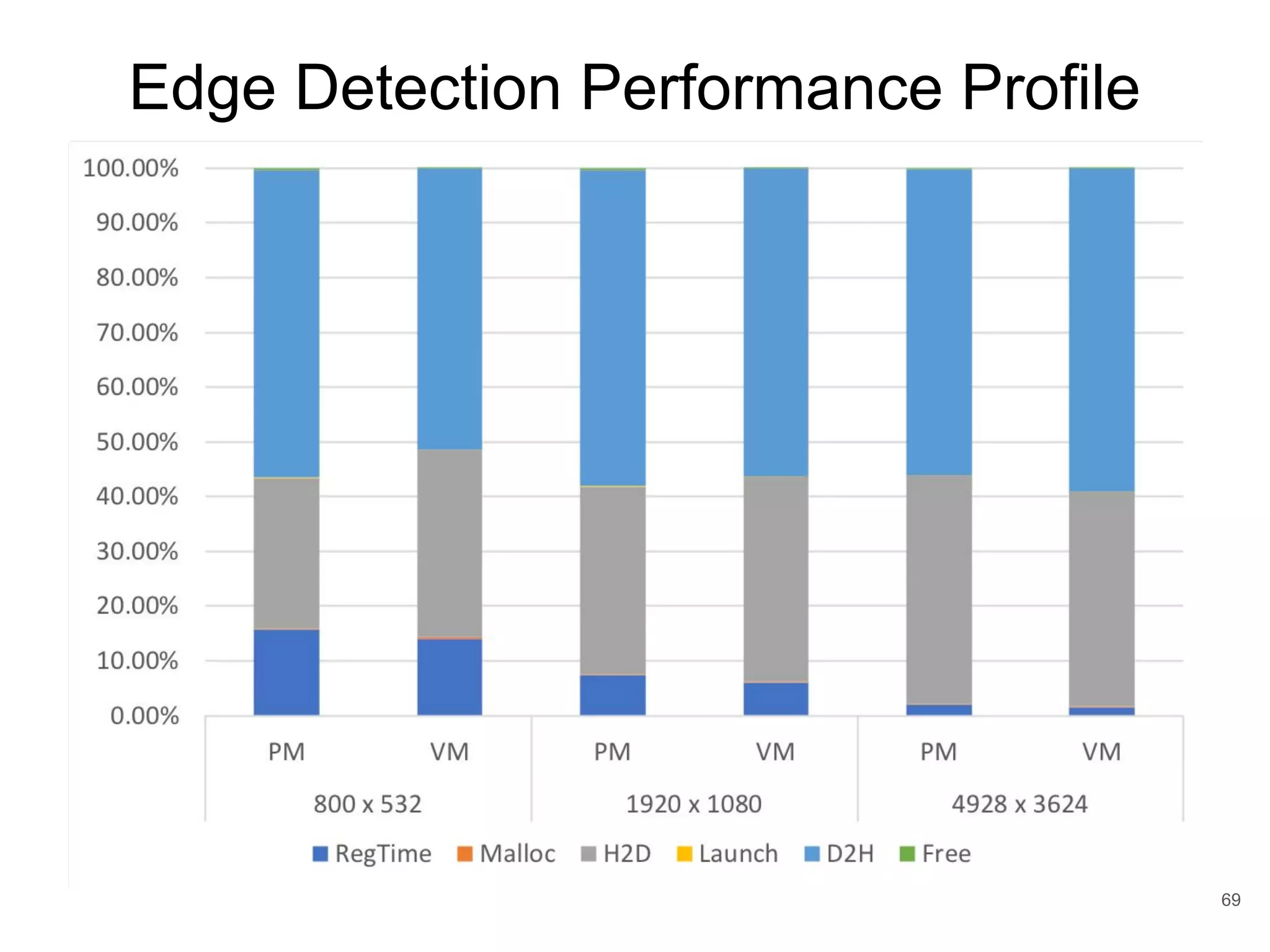
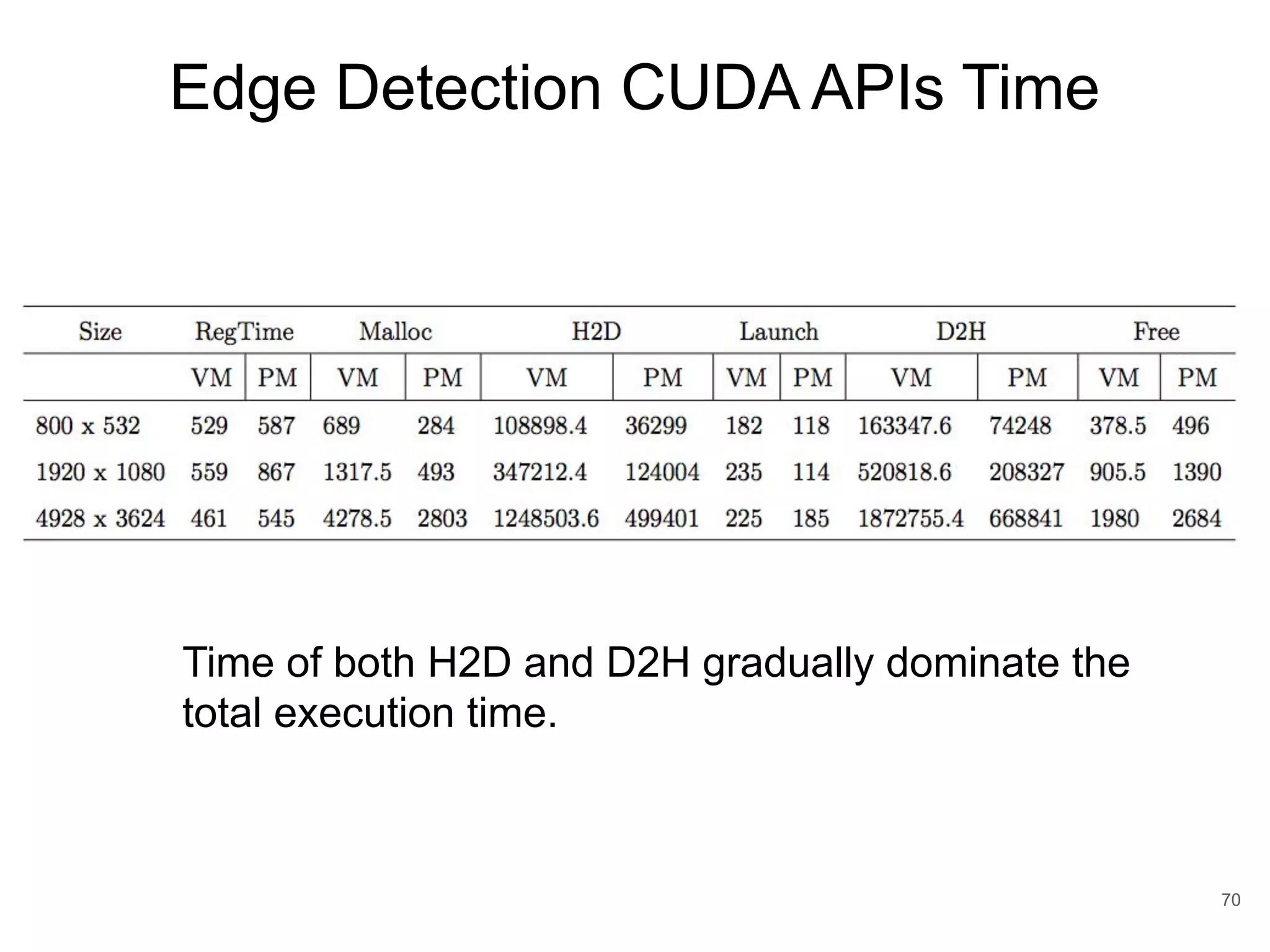
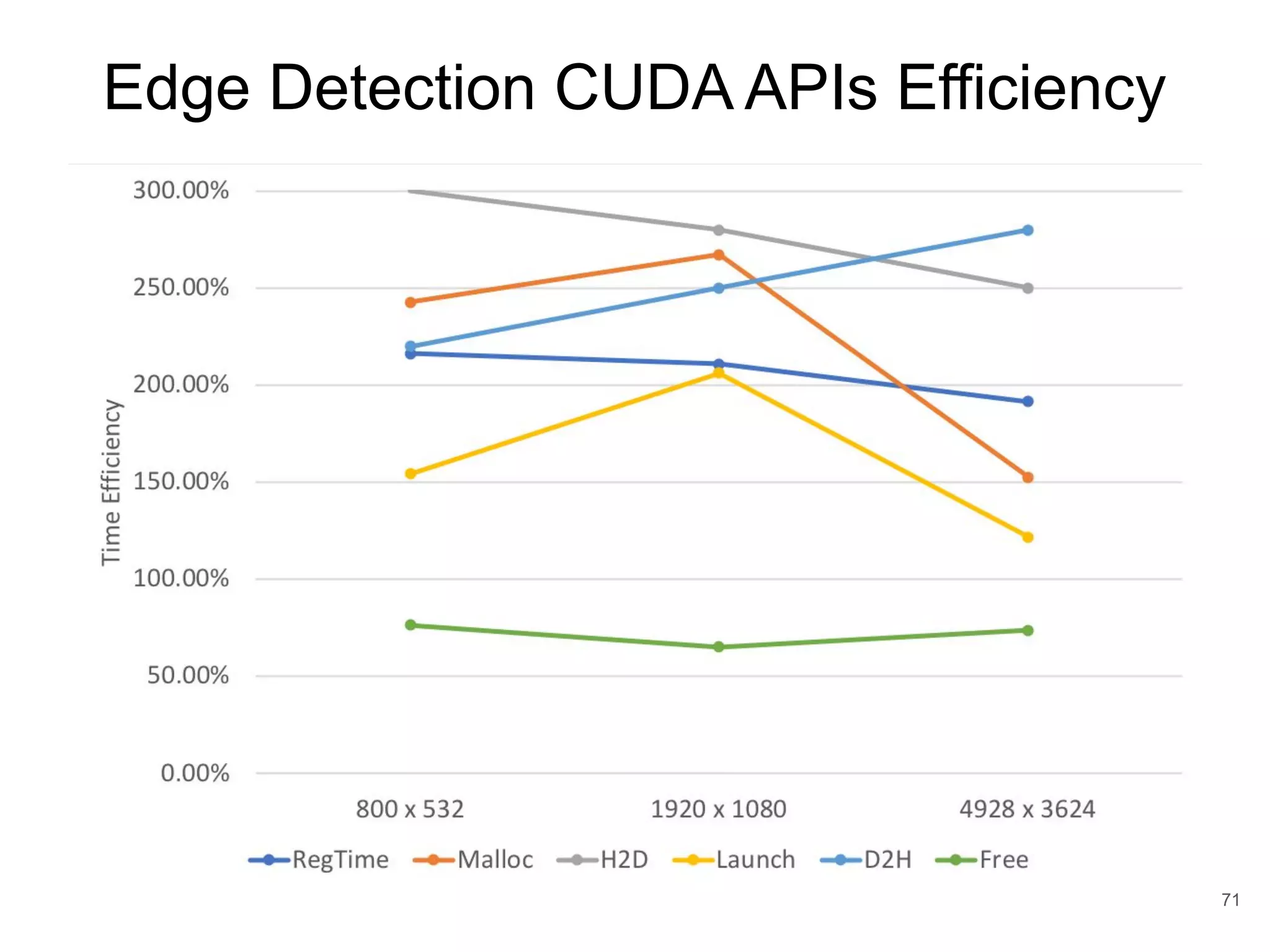
This document discusses qCUDA-ARM, a virtualization solution for embedded GPU architectures. It provides an overview of edge computing challenges, GPU virtualization methods like API remoting, and the design and implementation of qCUDA-ARM. Key aspects covered include using address space conversion to enable zero-copy memory between guest and host, a pinned memory allocation mechanism for ARM, and improvements to memory bandwidth when copying data. The document evaluates qCUDA-ARM's performance on various benchmarks and applications compared to rCUDA and native CUDA.









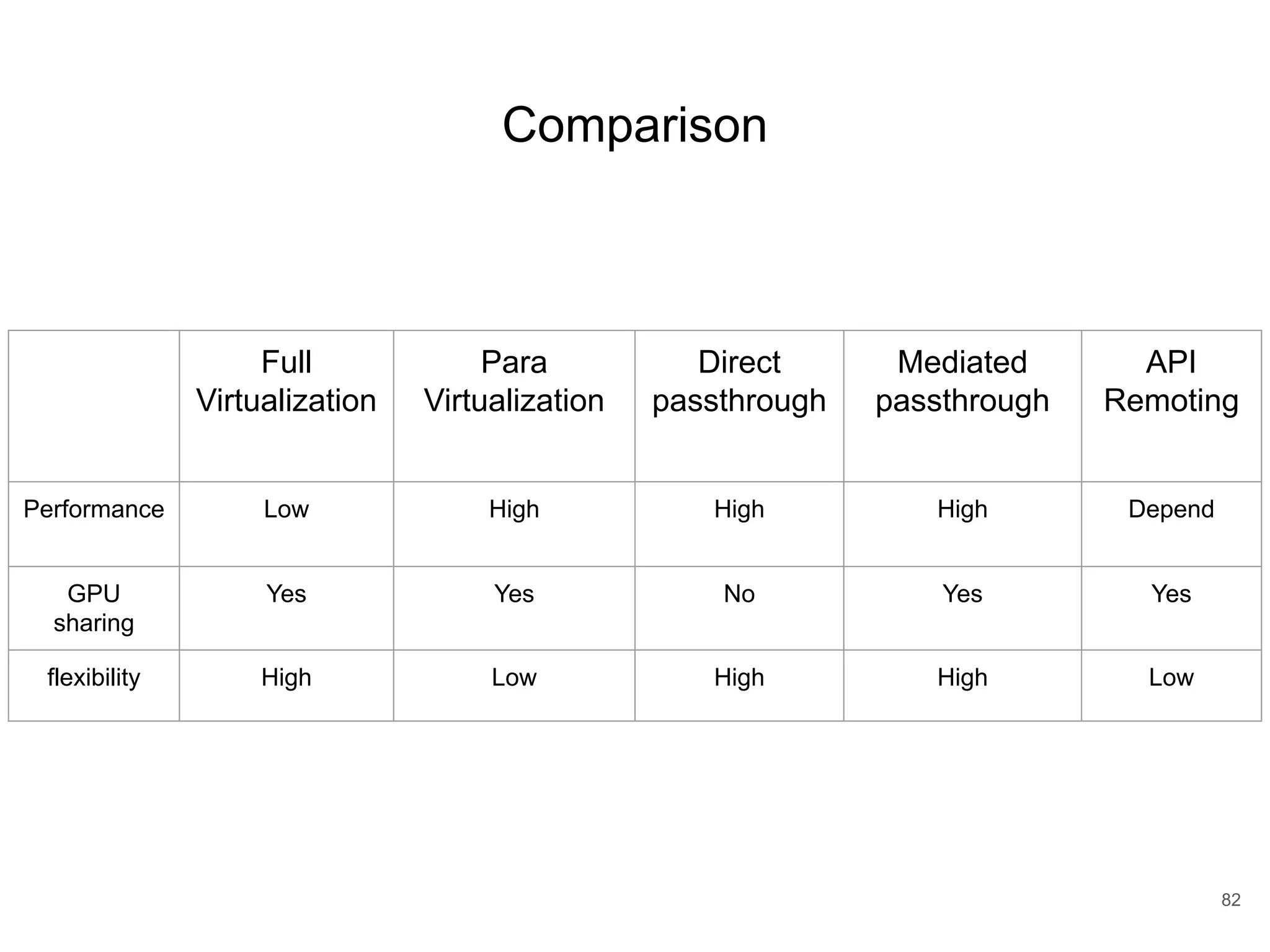
![Direct Pass-through ● Guest OS directly access GPUs with hardware extension features provided by either motherboard chipset or GPU manufacturers. ● Limitation ○ Cannot share one single GPU to multiple VM. ● Ex: ○ Intel VT-d [Abramson et al. 2006] ○ AMD-Vi [Van Doorn 2006] 14 https://blogs.vmware.com/apps/2018/05/machine-learning-using-virtualized- gpus-on-vmware-vsphere.html](https://image.slidesharecdn.com/copyofqcuda-armvirtualizationforembeddedgpuarchitecturespublic-191028173254/75/qCUDA-ARM-Virtualization-for-Embedded-GPU-Architectures-14-2048.jpg)
![Mediated Passthrough (1/2) ● Multiple Virtual GPU (vGPU) ● Each VM own a full-feature vGPU ● VMs can directly access performance-critical resources, without hypervisor intervention in most cases. ● Trap privileged operations from guest, provide secure isolation. ● Ex: ○ gVirt [Tian et al. 2014] ○ KVMGT [Song et al. 2014] ○ gScale [Xue et al. 2016] 15 https://projectacrn.github.io/latest/developer-guides/hld/hld-APL_GVT-g.htm l](https://image.slidesharecdn.com/copyofqcuda-armvirtualizationforembeddedgpuarchitecturespublic-191028173254/75/qCUDA-ARM-Virtualization-for-Embedded-GPU-Architectures-15-2048.jpg)
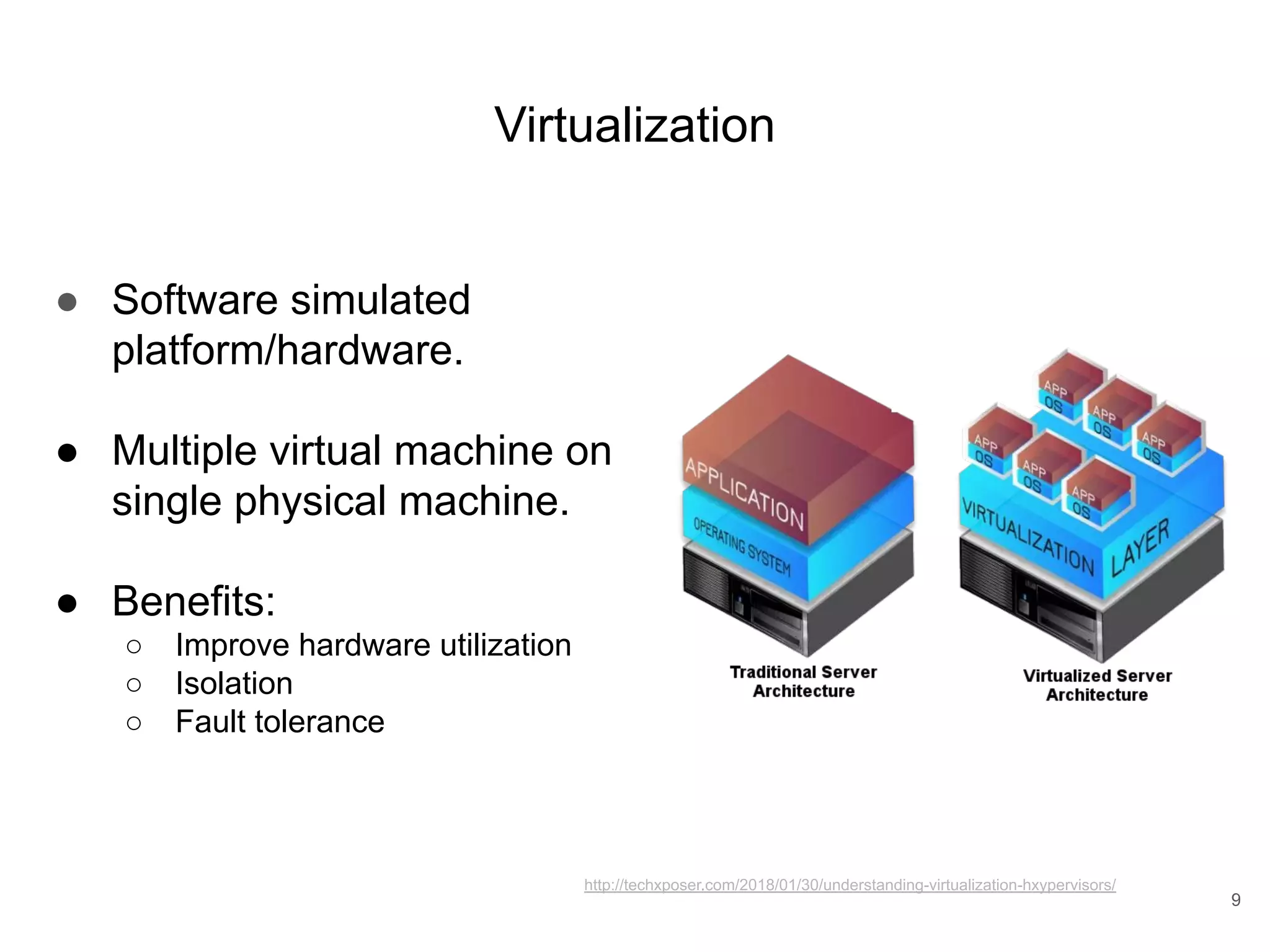
![Full-Virtualization ● Software simulation ● Native driver can be ran on the guest without any modification of GPU libraries and drivers. ● Performance overhead since software trap-and-emulated the hardware interface of existing ○ GPUvm [Suzuki et al. 2014] ○ G-KVM [Hong et al. 2016] 16](https://image.slidesharecdn.com/copyofqcuda-armvirtualizationforembeddedgpuarchitecturespublic-191028173254/75/qCUDA-ARM-Virtualization-for-Embedded-GPU-Architectures-16-2048.jpg)
![Para-Virtualization ● Improve performance by slightly modifies the custom driver in the guest for delivering sensitive operations directly to the host driver , prevent hypervisor invention hence improve performance. ● EX: ○ LoGV [Gottschlag et al. 2013] 17](https://image.slidesharecdn.com/copyofqcuda-armvirtualizationforembeddedgpuarchitecturespublic-191028173254/75/qCUDA-ARM-Virtualization-for-Embedded-GPU-Architectures-17-2048.jpg)
![API-Remoting (1/3) 18 ● Wrapping the GPU APIs as a “front-end” in the guest. ● Mediating all accesses to the GPU as a “back-end” in the host through an transport layer. ● Challenge: minimize the communication overhead between backend and frontend. ● EX: ○ GVirtuS [Giunta et al. 2010] ○ vCUDA [Shi et al. 2009] ○ rCUDA [Duato et al. 2010b] ○ qCUDA [Yu-Shiang et al. 2017]](https://image.slidesharecdn.com/copyofqcuda-armvirtualizationforembeddedgpuarchitecturespublic-191028173254/75/qCUDA-ARM-Virtualization-for-Embedded-GPU-Architectures-18-2048.jpg)
![API-Remoting (2/3) ● rCUDA [Duato et al. 2010b] ○ Offloads CUDA computation to remote GPUs. ○ For HPC scenario. ○ Client / server architecture. ○ Suitable for InfiniBand, achieve native performance when under it. ○ Communicate by TCP/IP which may be the performance bottleneck. 19https://www.researchgate.net/figure/Overview-of-the-general-architecture-of-the-rCU DA-virtualization-solution_fig1_267514566](https://image.slidesharecdn.com/copyofqcuda-armvirtualizationforembeddedgpuarchitecturespublic-191028173254/75/qCUDA-ARM-Virtualization-for-Embedded-GPU-Architectures-19-2048.jpg)



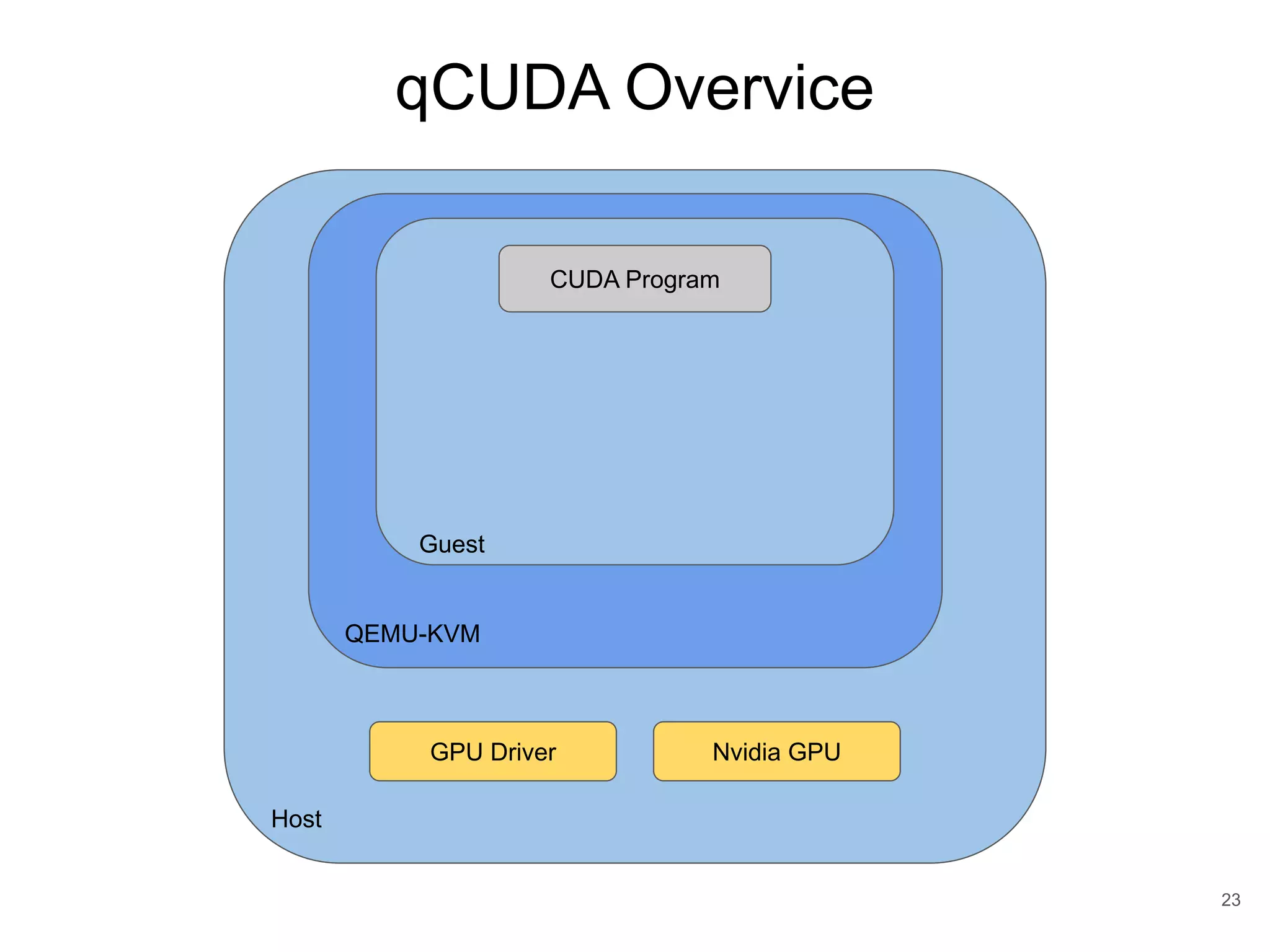
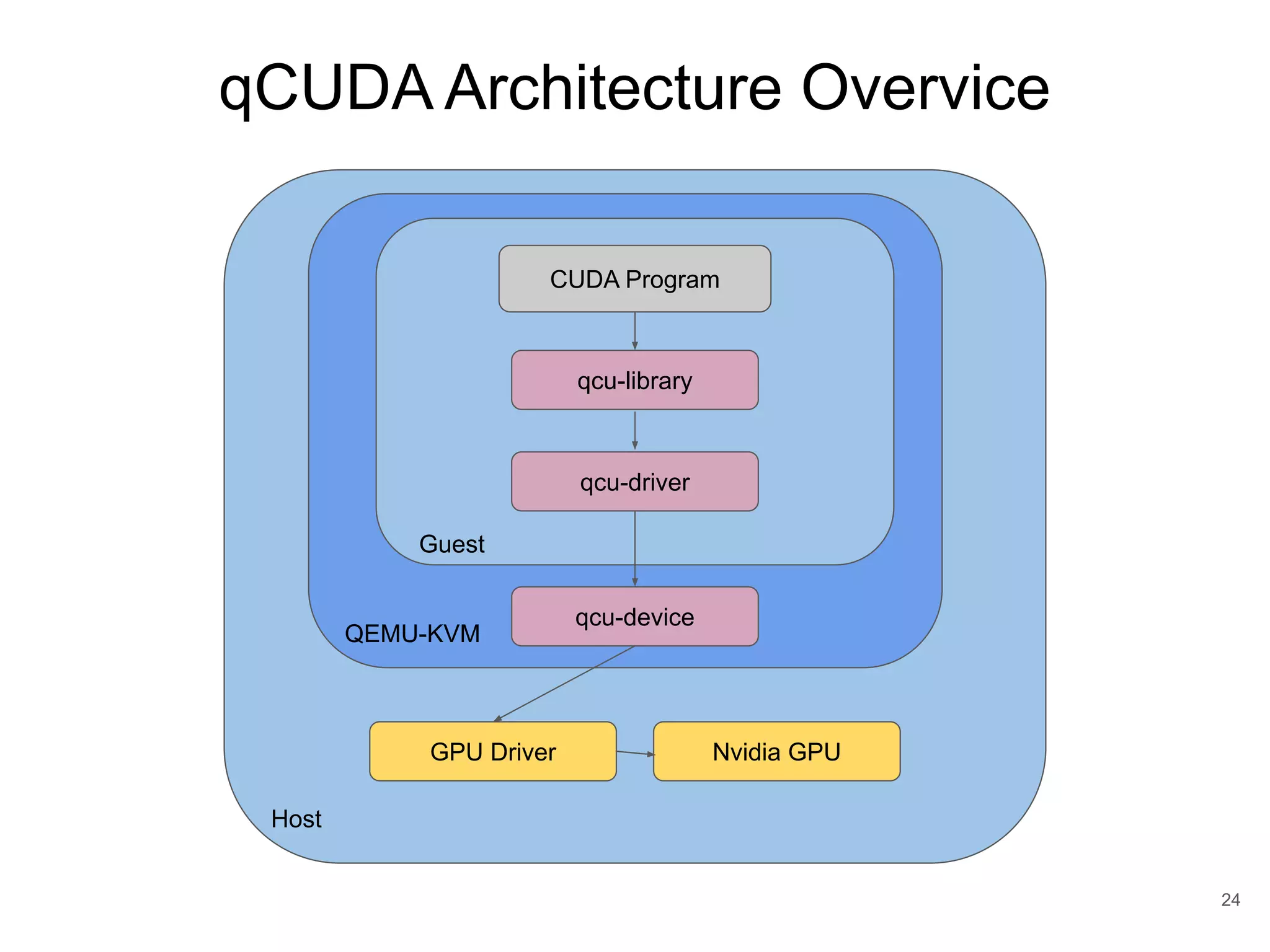




























![Full-Virtualization ● Software simulation ● Native driver can be ran on the guest without any modification of GPU libraries and drivers. ● Performance overhead since software trap-and-emulated the hardware interface of existing ○ GPUvm [Suzuki et al. 2014] ○ G-KVM [Hong et al. 2016] 84](https://image.slidesharecdn.com/copyofqcuda-armvirtualizationforembeddedgpuarchitecturespublic-191028173254/75/qCUDA-ARM-Virtualization-for-Embedded-GPU-Architectures-84-2048.jpg)
![API-Remoting (2/4) ● GVirtuS [Giunta et al. 2010] ○ Virtualize CUDA ○ Support Xen, KVM and VMware. ○ Try to minimize communication overhead by leveraging on high performance communication channel provided by hypervisors. 85 ● vCUDA [Shi et al. 2009] ○ Virtualize CUDA ○ Support Xen and KVM ○ vGPU per application ○ Prevent frequent context switching between the guest OS and the hypervisor and improves communication performance. ○ Batch CUDA call by Lazy RPC that performs batching specific CUDA calls that can be delayed.](https://image.slidesharecdn.com/copyofqcuda-armvirtualizationforembeddedgpuarchitecturespublic-191028173254/75/qCUDA-ARM-Virtualization-for-Embedded-GPU-Architectures-85-2048.jpg)
