Downloaded 37 times







![hstore continues…. CREATE TABLE my_store ( id character varying(1024) NOT NULL, doc hstore, CONSTRAINT my_store_pkey PRIMARY KEY (id) ); CREATE INDEX my_store_doc_idx_gist ON my_store USING gist(doc) ; SELECT doc -> ‘text’ as merchant, doc -> ‘created_at’ as created_at FROM my_store WHERE doc @> ‘created_at=>23/12/2013’; SELECT doc -> ‘text’ as merchant, doc -> ‘created_at’ as created_at FROM my_store WHERE doc @> ‘is_active=>:t’ AND doc ? ‘has_address’ ORDER BY doc -> ‘created_at’ DESC; SELECT doc -> ‘text’ as merchant, doc -> ‘created_at’ as created_at FROM my_store WHERE doc @> ‘is_active=>:t’ AND doc ?| ARRAY[‘has_address’, ‘has_payoption’] ;](https://image.slidesharecdn.com/pgsql-nosql-final1-140517091139-phpapp01/75/PostgreSQL-as-NoSQL-8-2048.jpg)




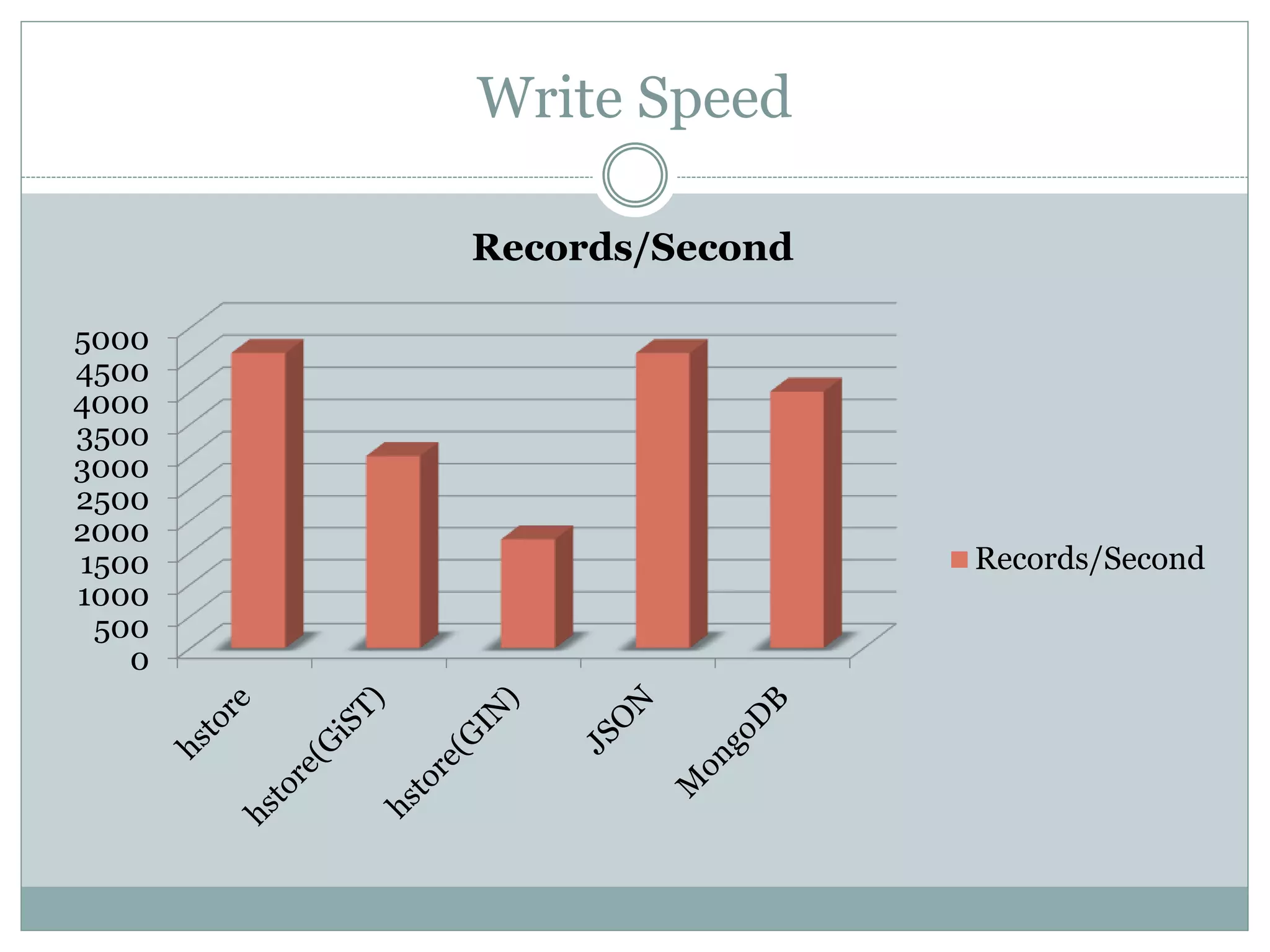
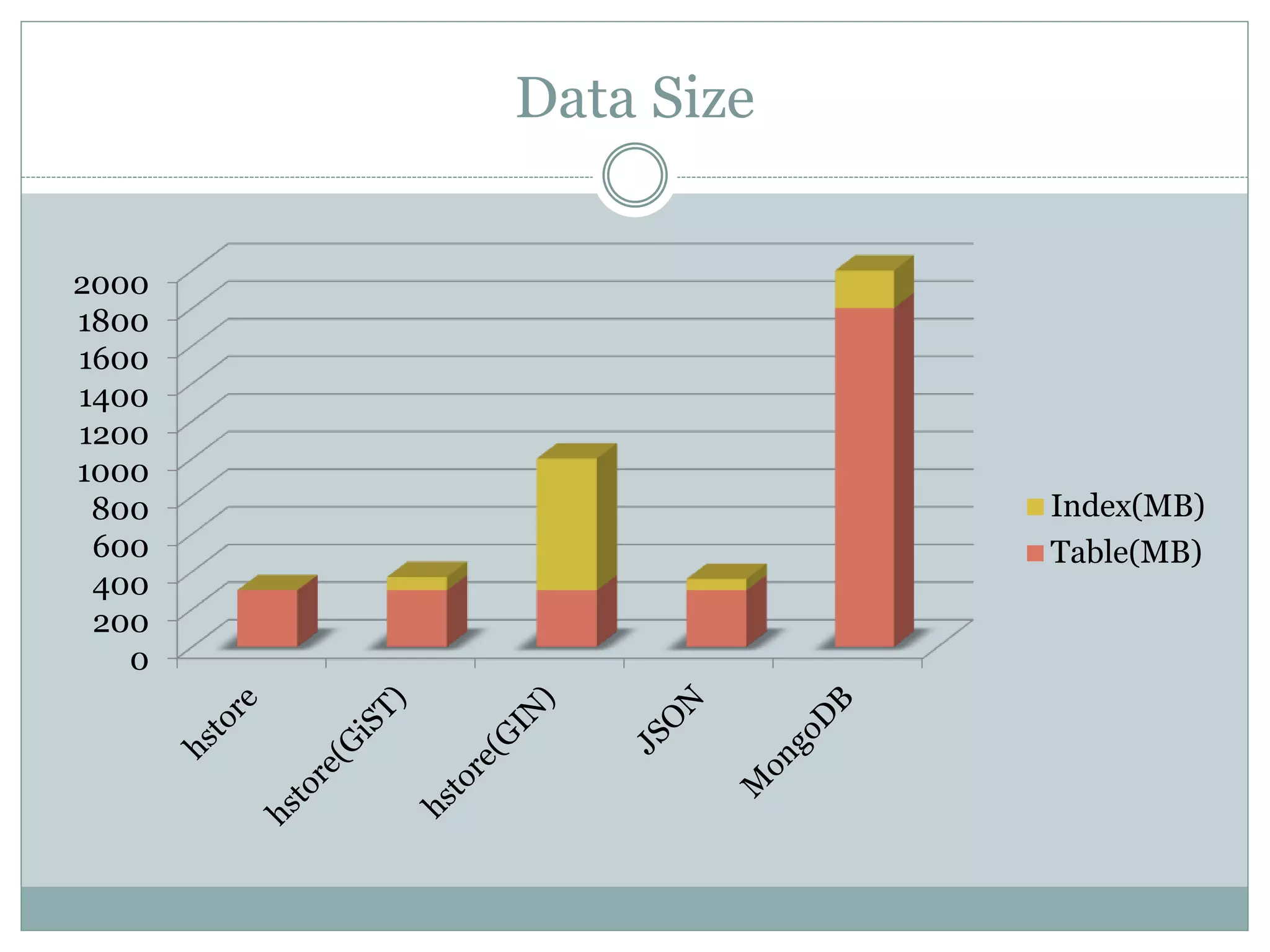
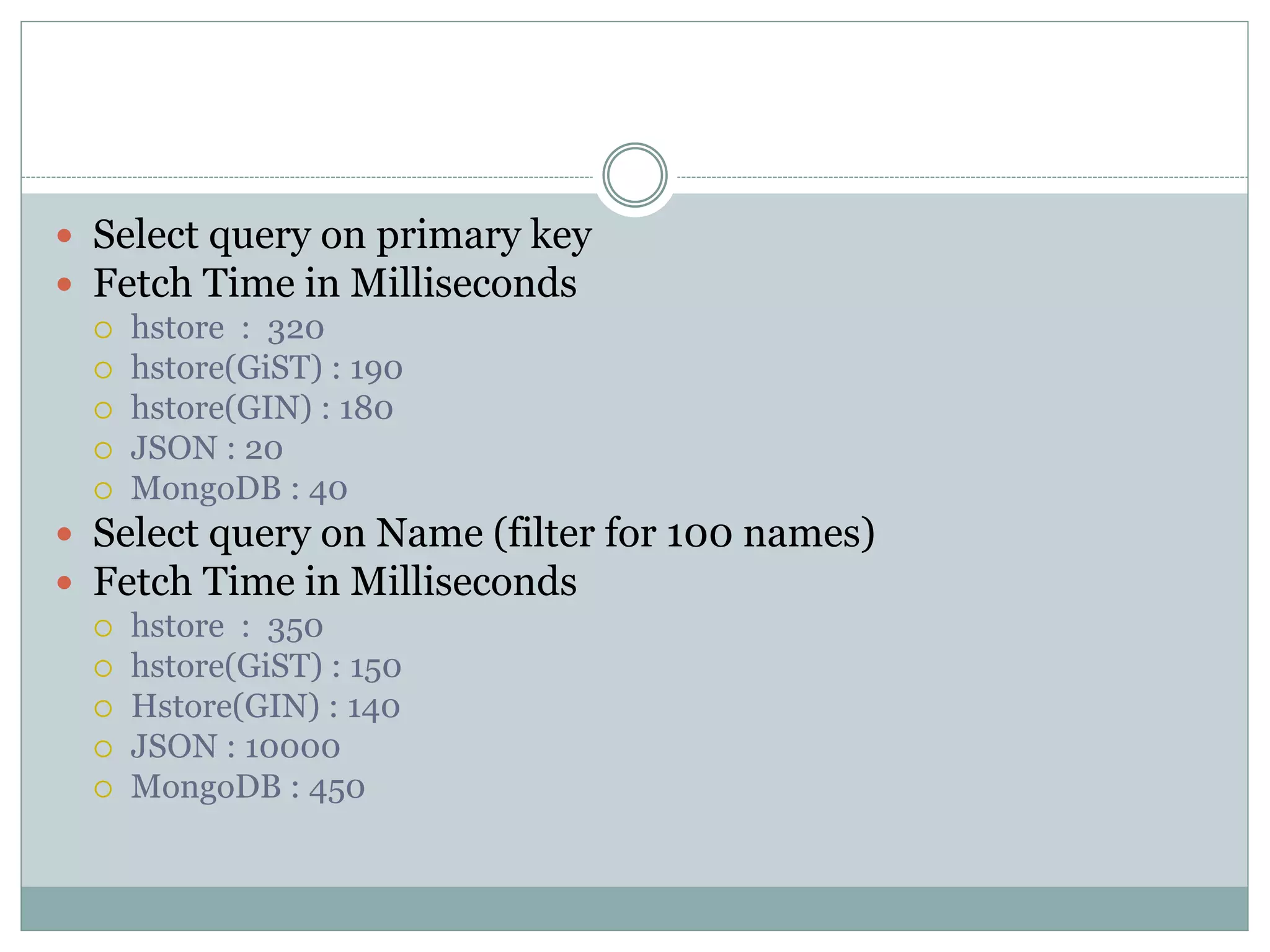
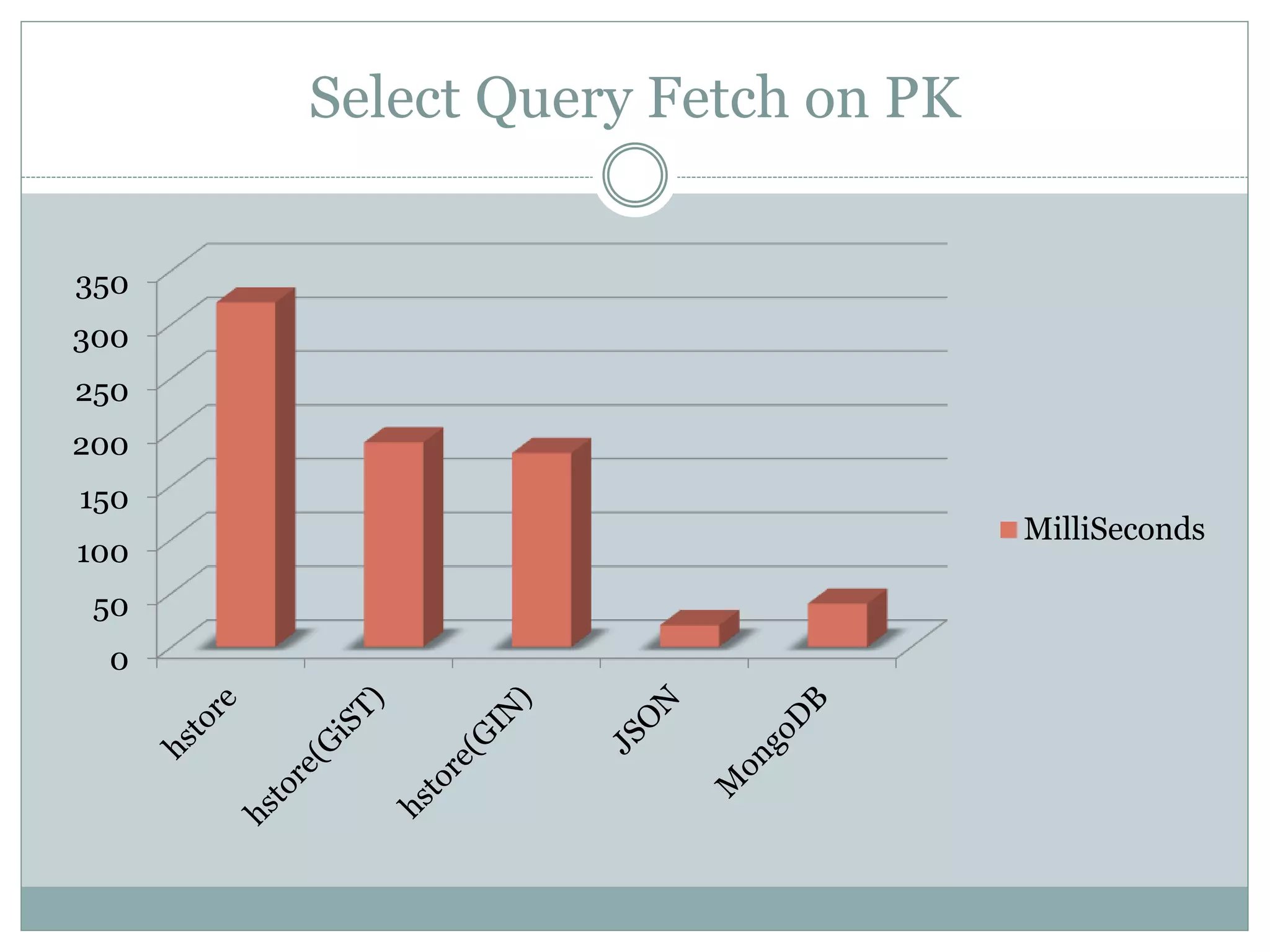
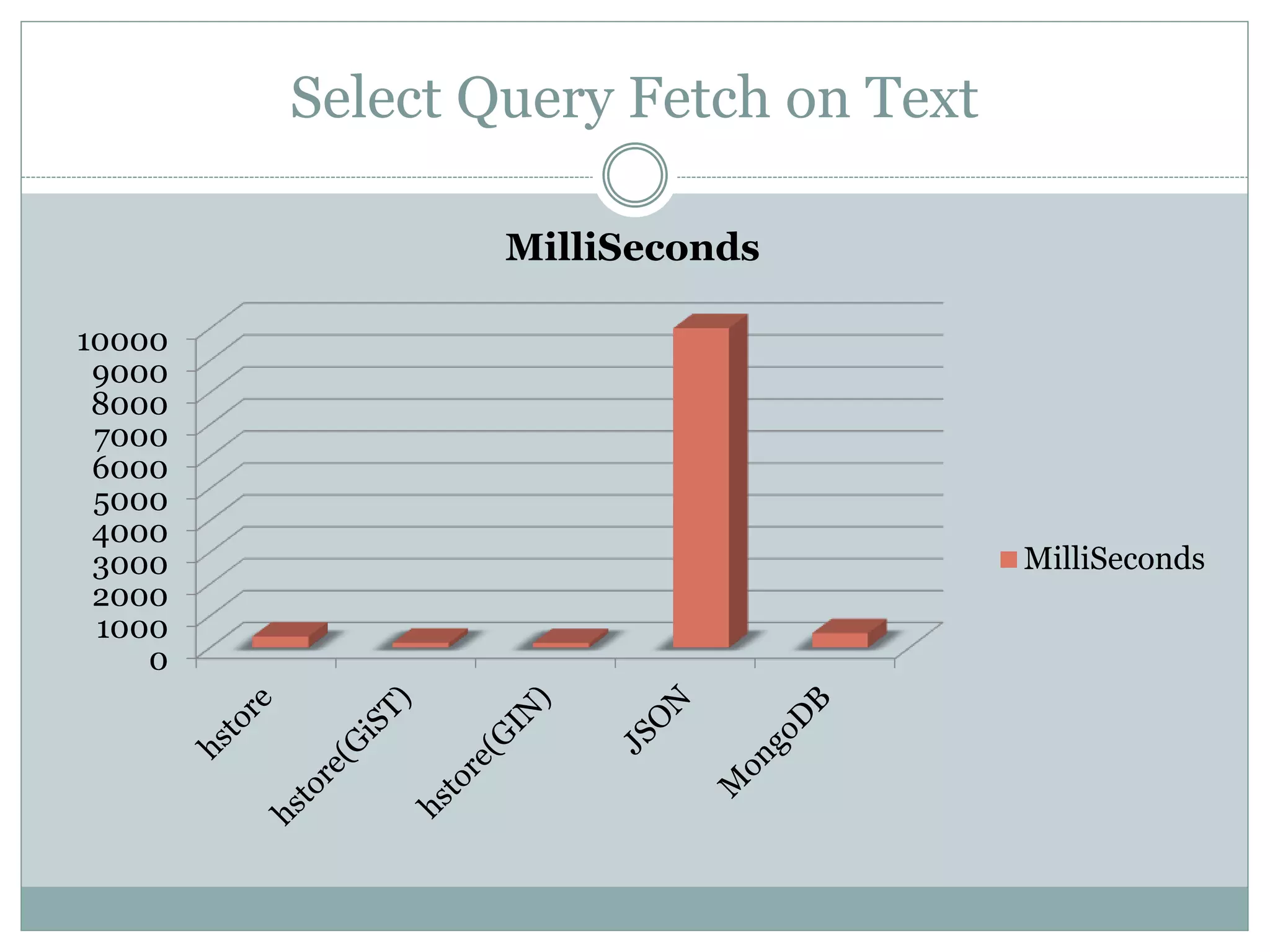



This document discusses using PostgreSQL as a schemaless database to store unstructured or semi-structured data. It describes how PostgreSQL supports schemaless data through data types like hstore and JSON. Performance tests show that while MongoDB is faster for writes, PostgreSQL with GiST indexes performs comparably to MongoDB for reads and offers benefits like transactions and constraints that MongoDB lacks. The document concludes that PostgreSQL can fulfill schemaless data requirements while avoiding the costs of migrating to a new database.