PostgreSQL on Kubernetes: Realizing High Availability with PGO (Postgres Ibiza 2023)
The document discusses PostgreSQL Operator (PGO) and its features aimed at achieving high availability within PostgreSQL environments managed via Kubernetes. It covers basic functionalities, installation, configuration, backup/restore processes, disaster recovery options, and challenges faced while implementing PGO. The presentation aims to provide an overview of these elements to enhance understanding of PostgreSQL management in high availability contexts.
Introduction to PostgreSQL on Kubernetes focusing on high availability with PGO. Presentation overview and speaker introduction.
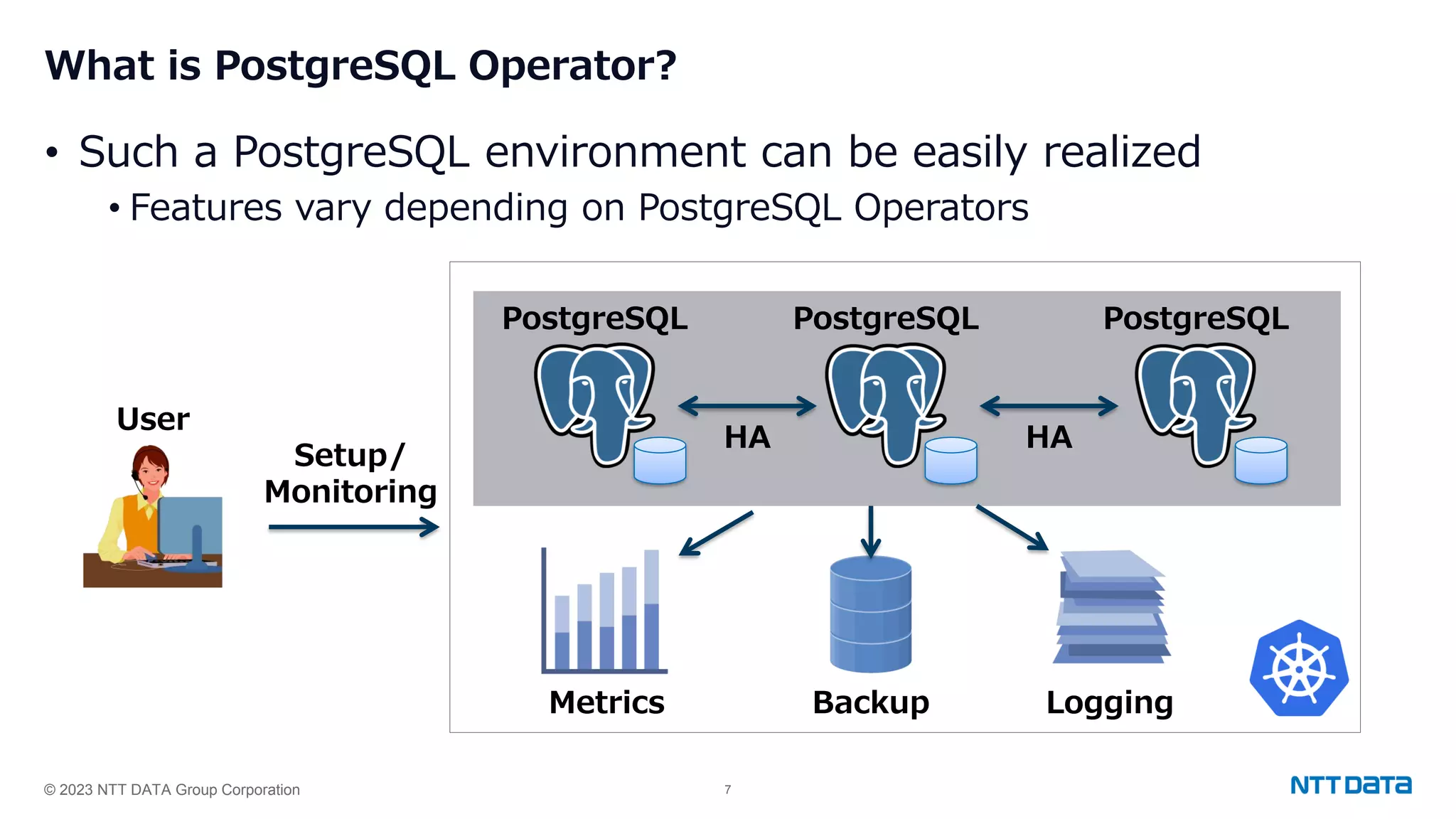
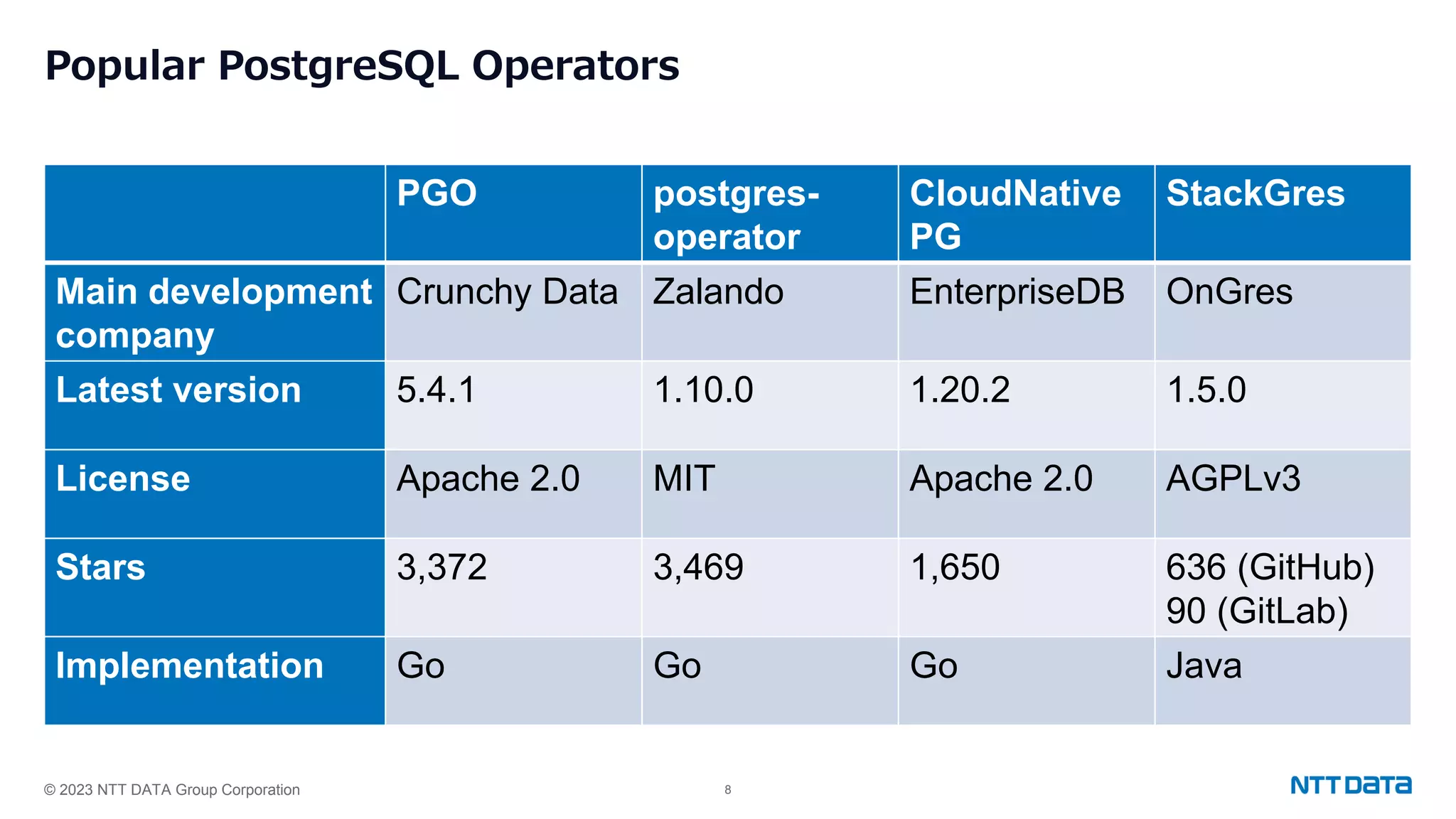
Discussion of PostgreSQL Operator, its key features, DBA tasks, and popular PostgreSQL operators with versioning details.
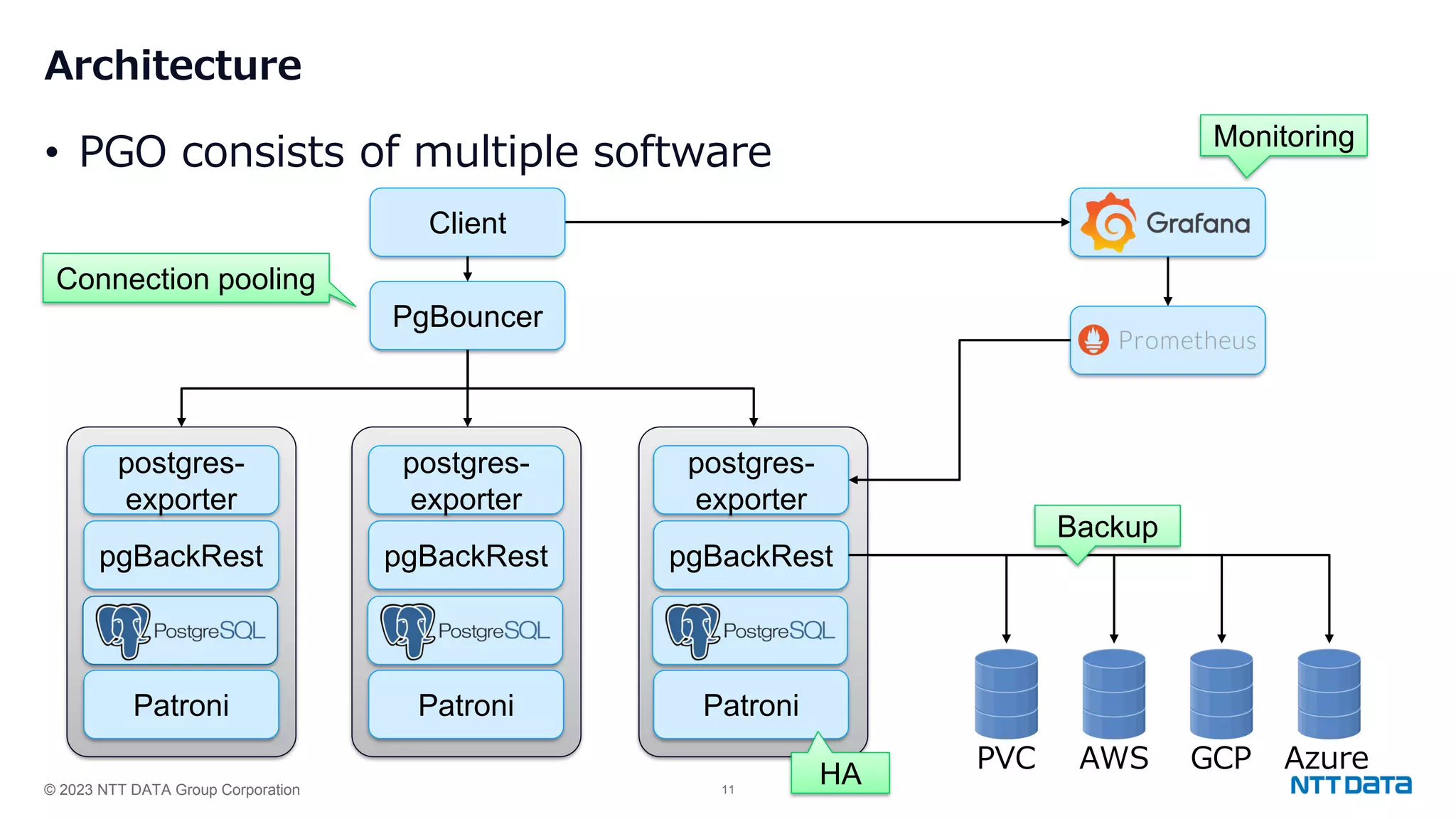
Insight into PGO as an OSS tool by Crunchy Data, along with its architecture and the Kubernetes version used.
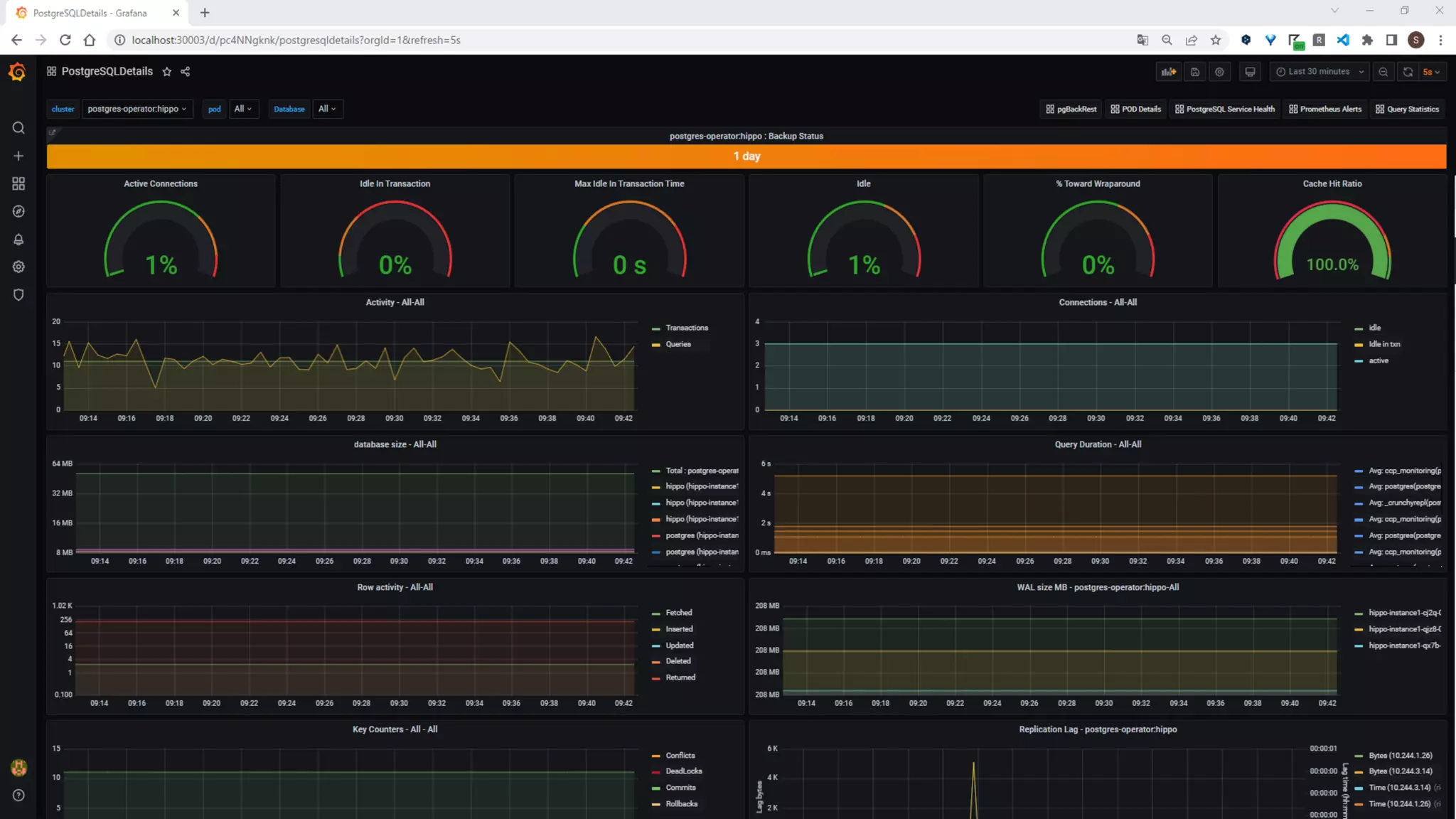
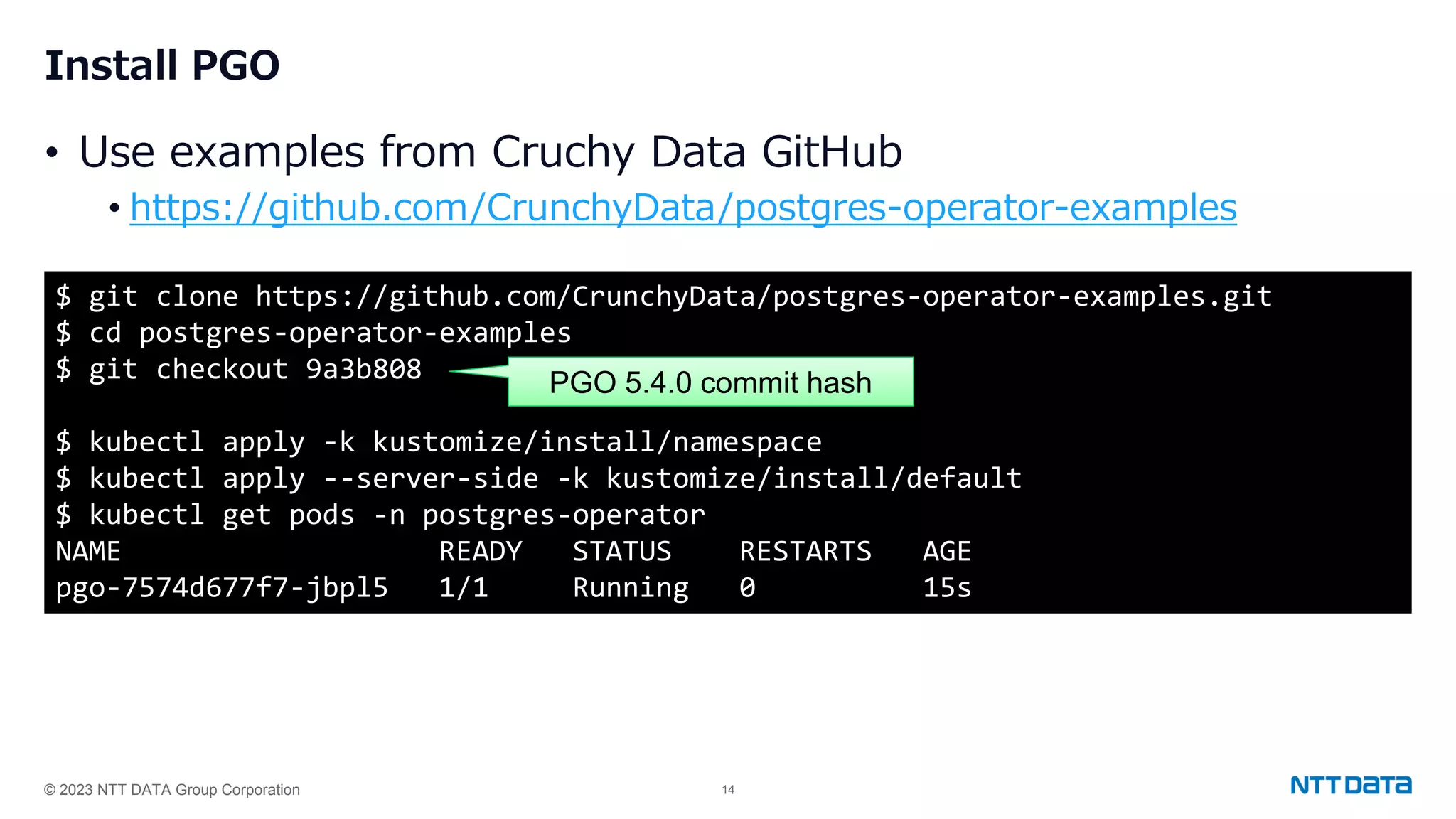
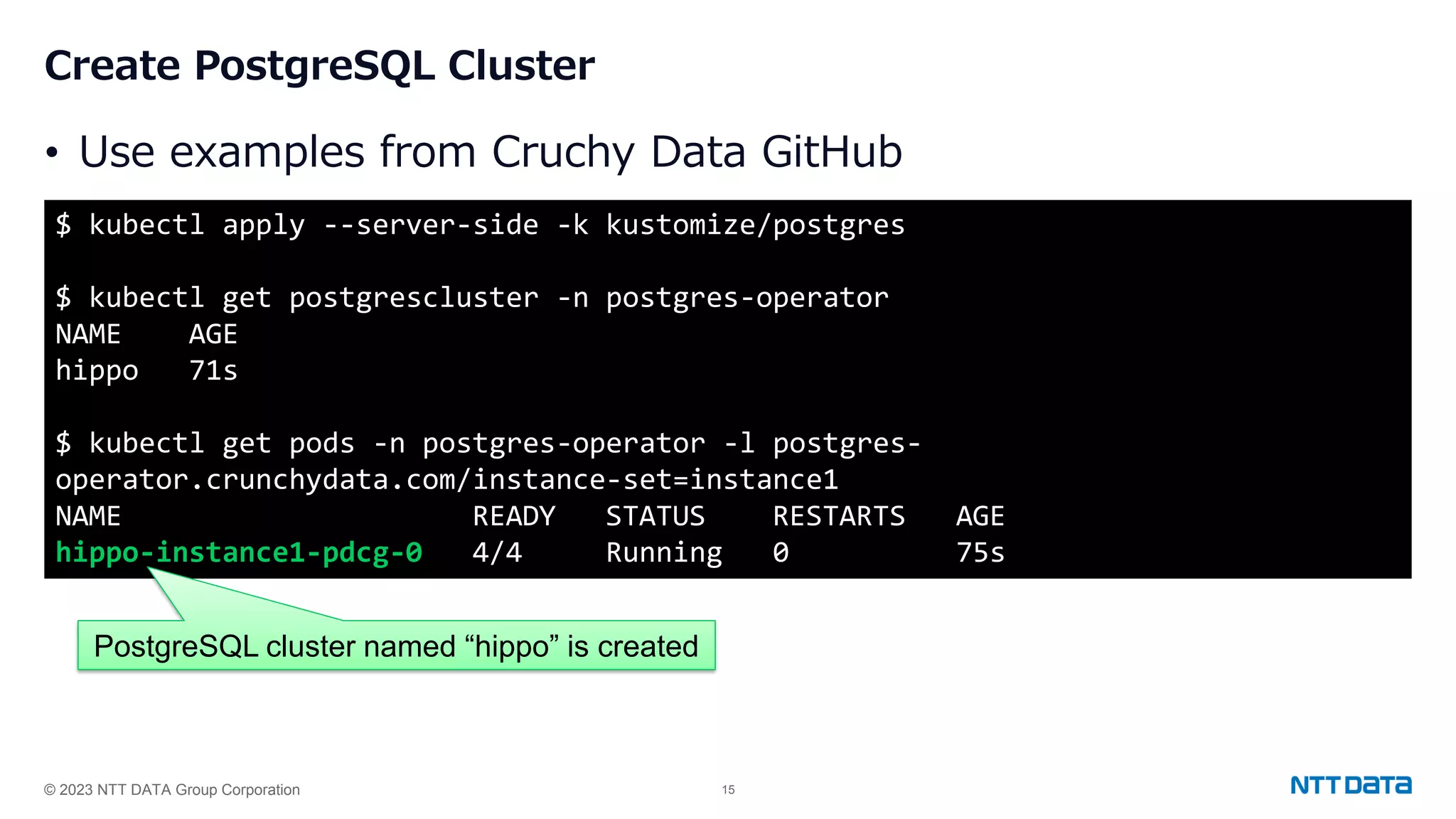
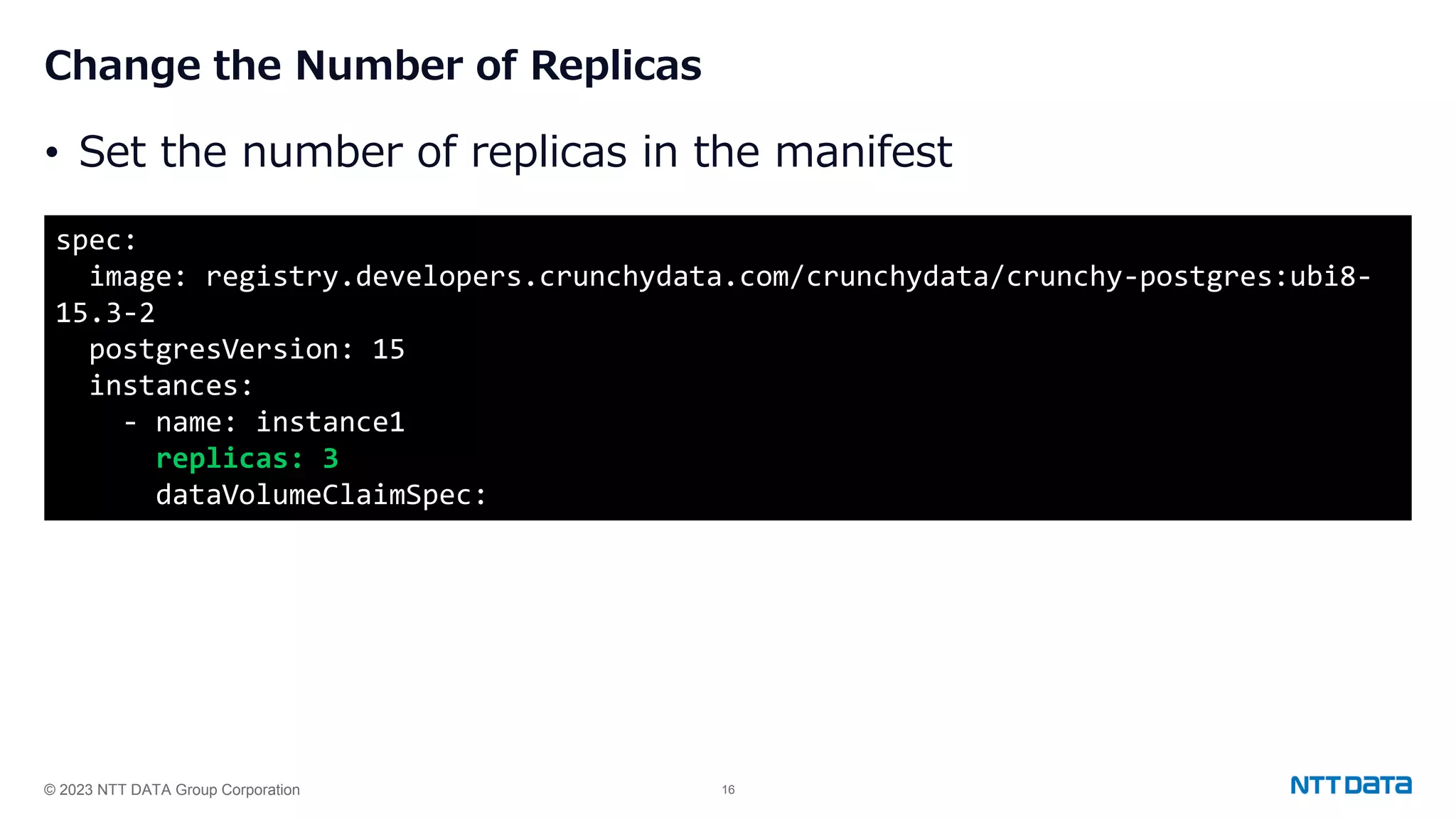
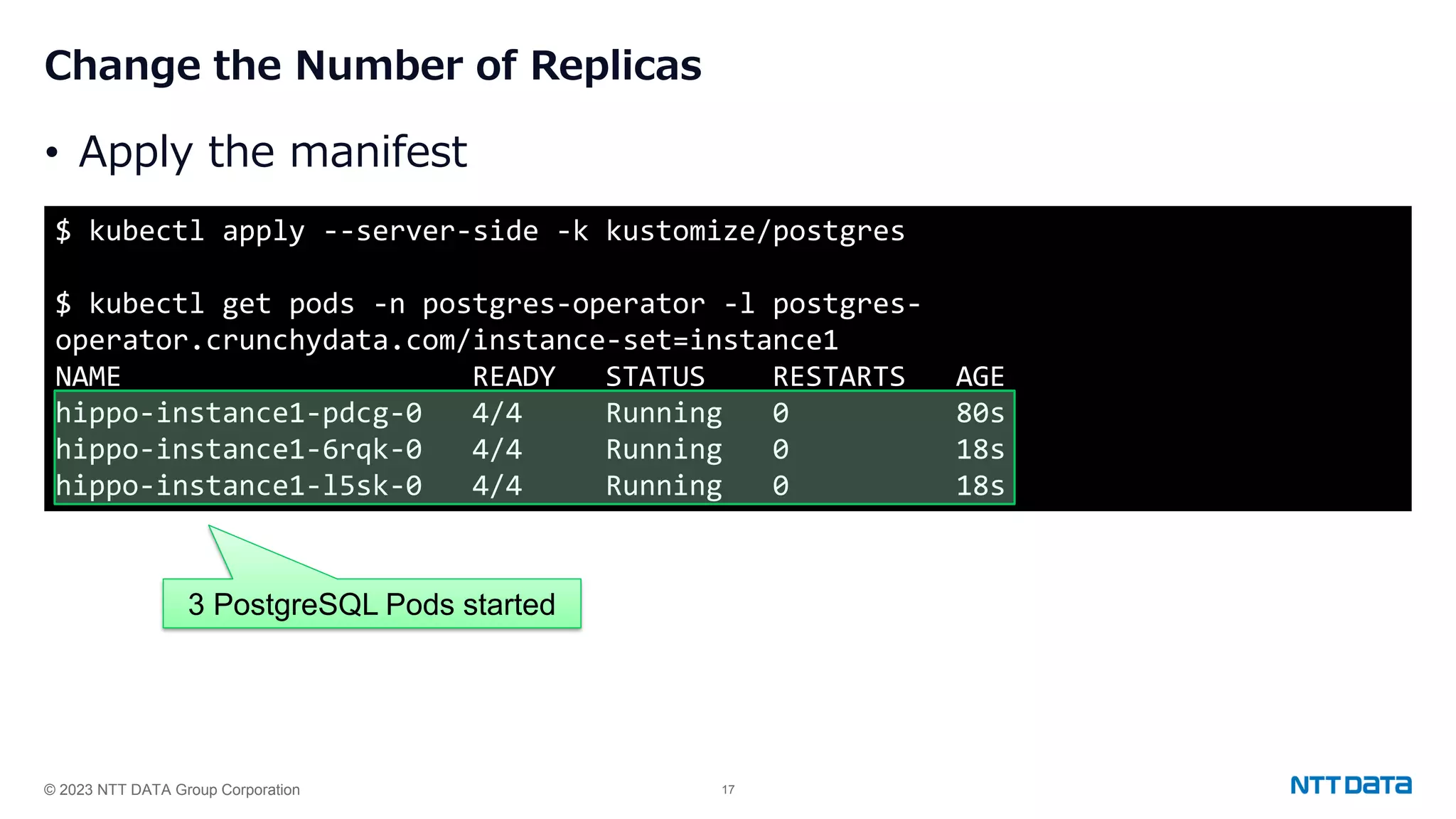
Steps for installing PGO, creating a PostgreSQL cluster, adjusting replicas, and handling failover and updates.
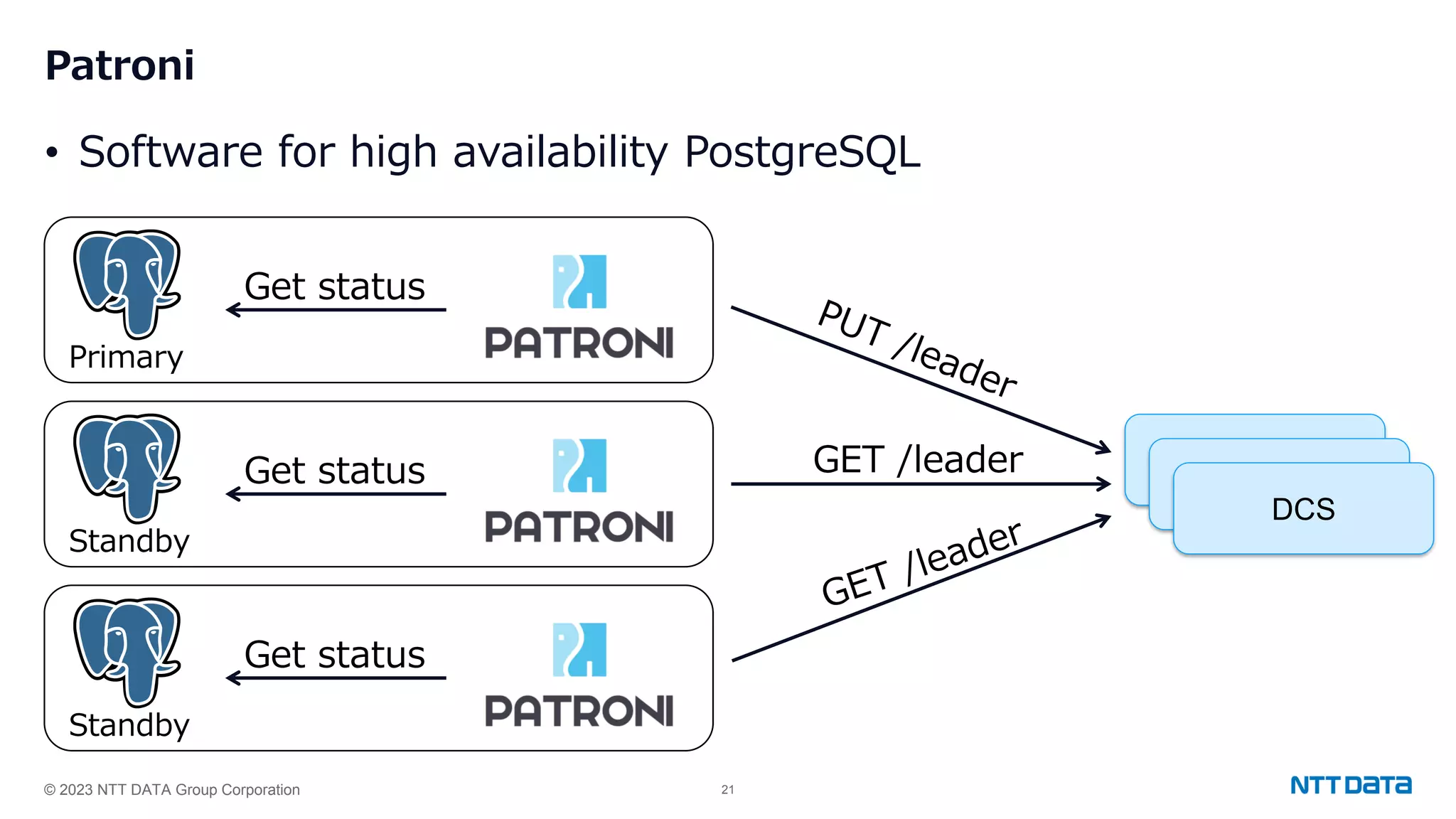
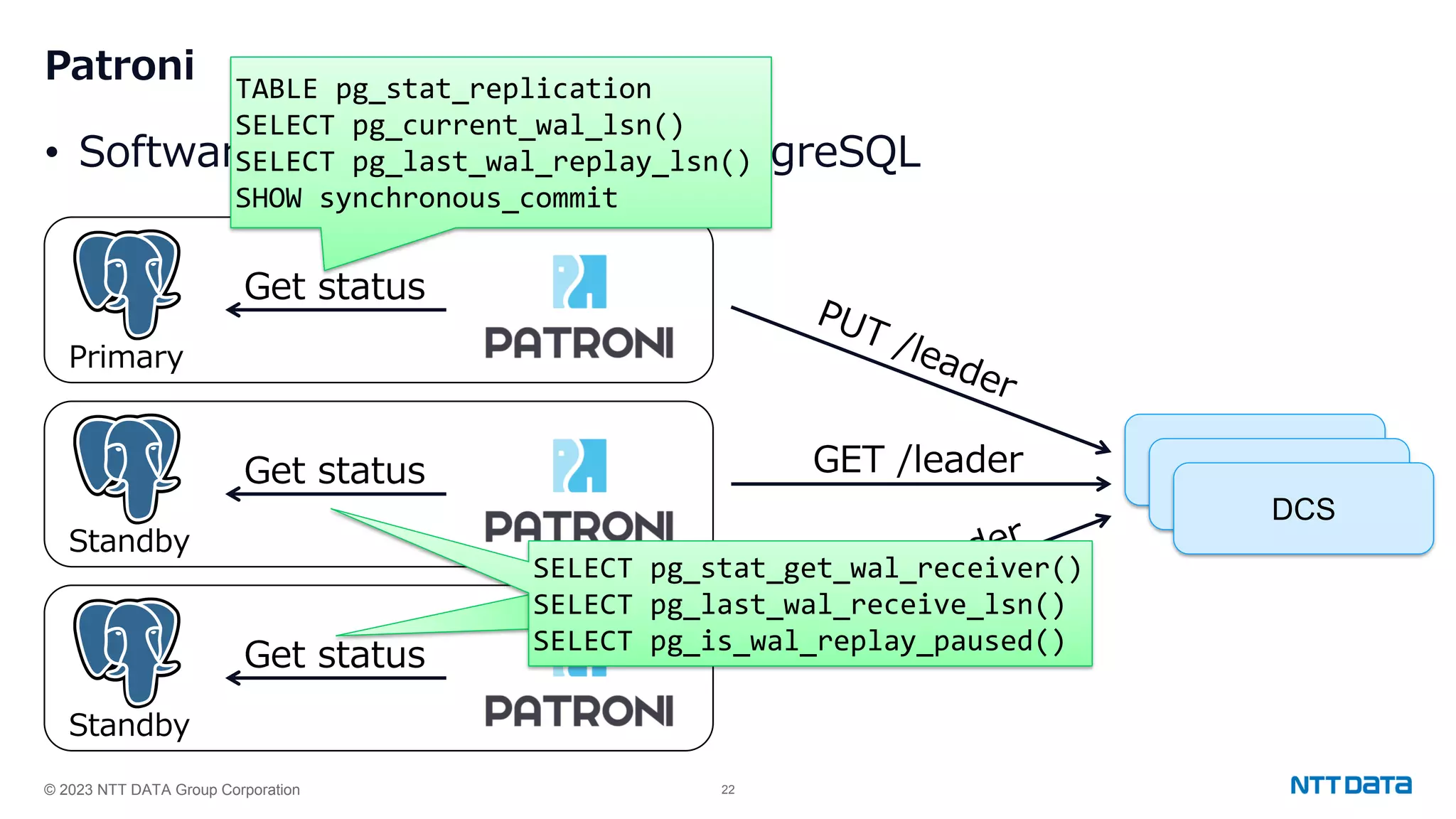
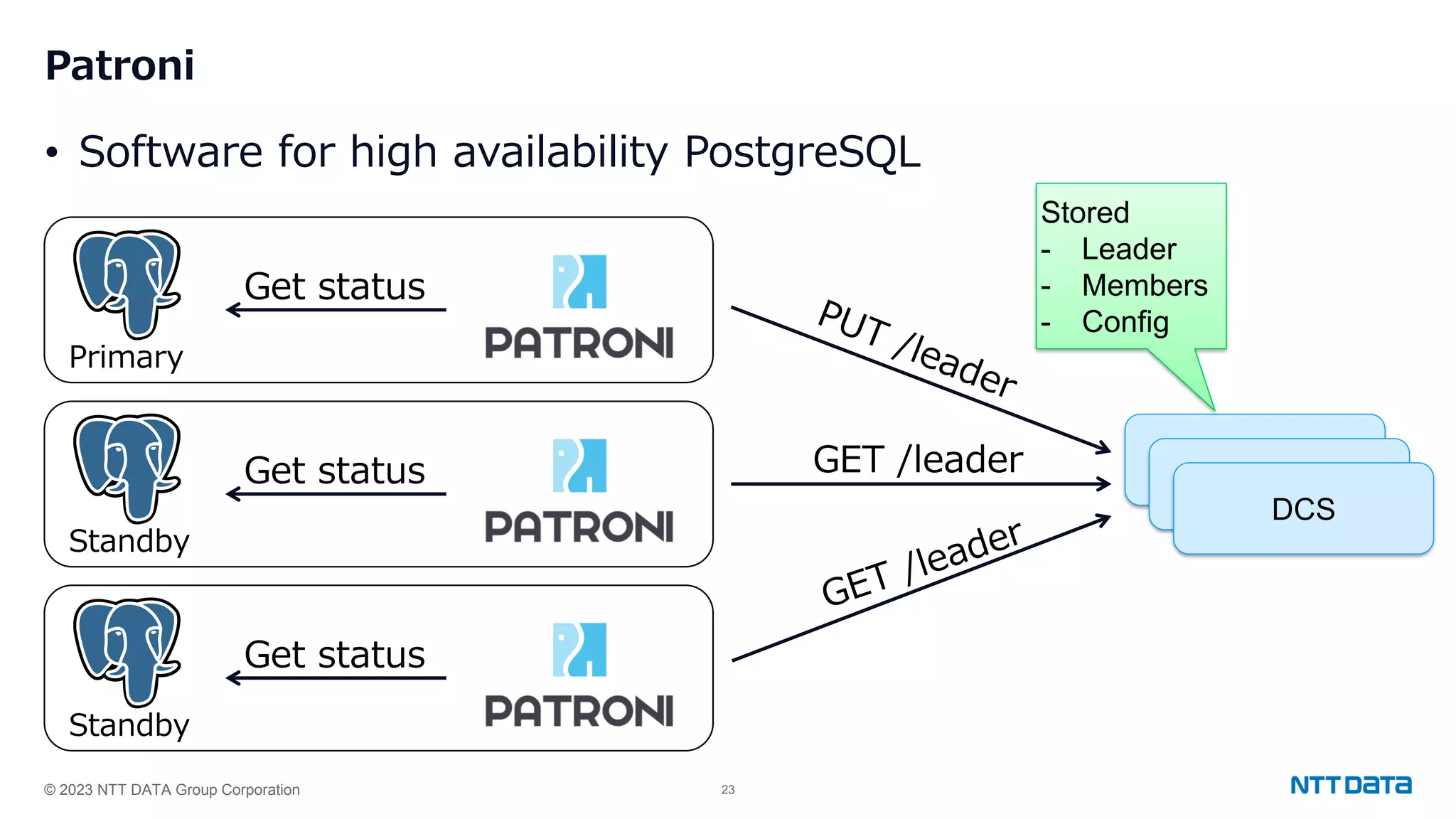
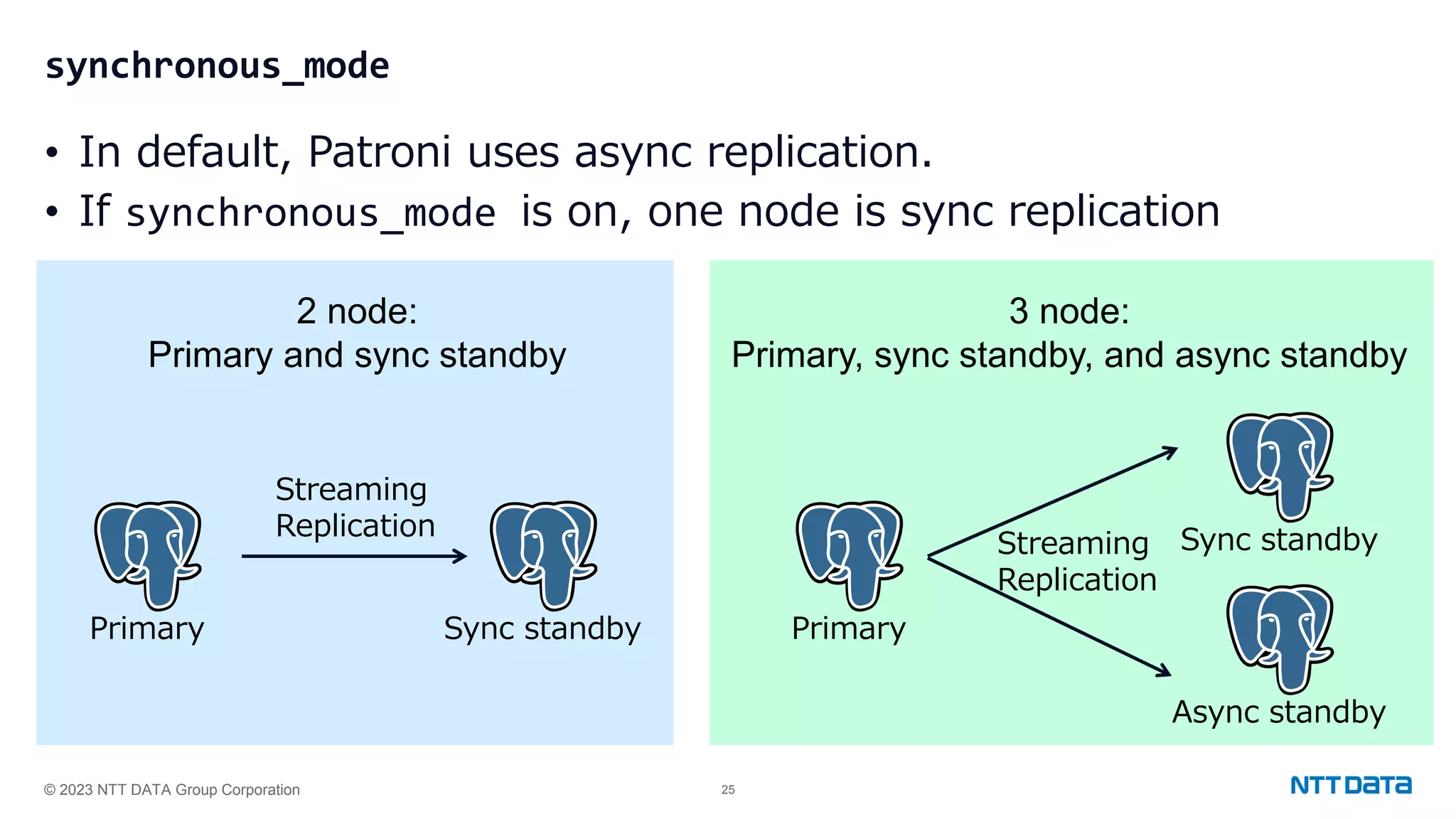
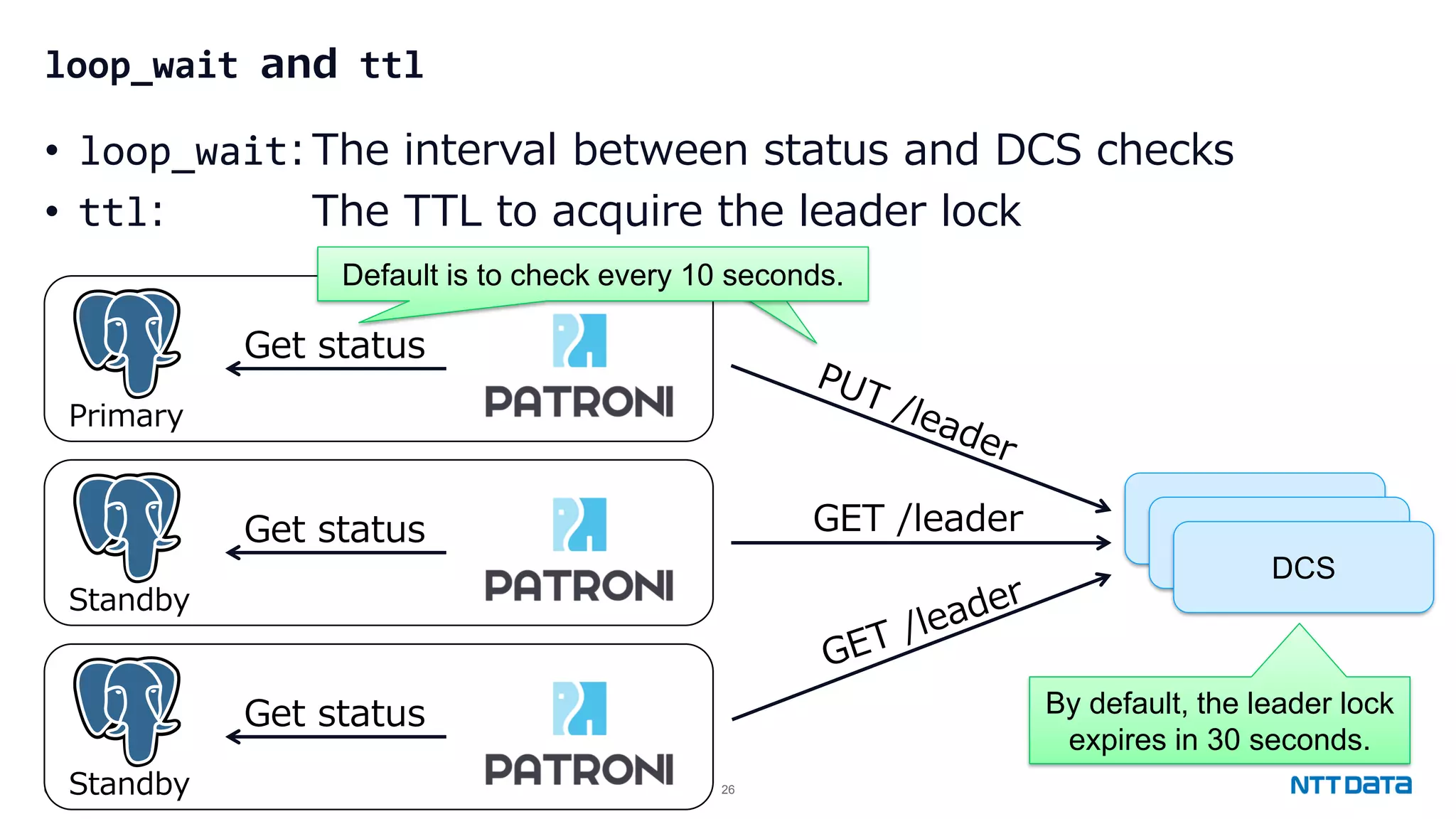
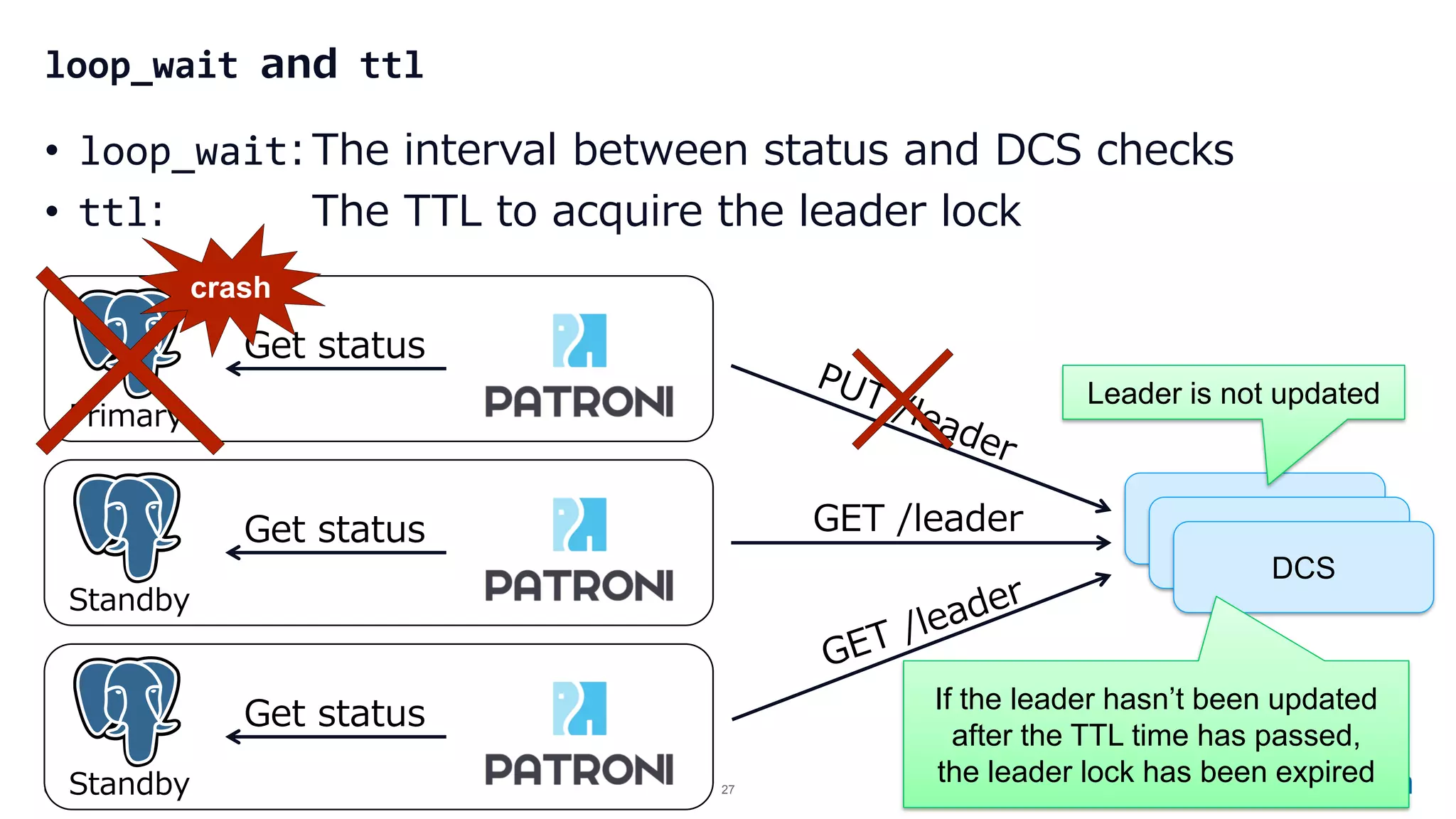
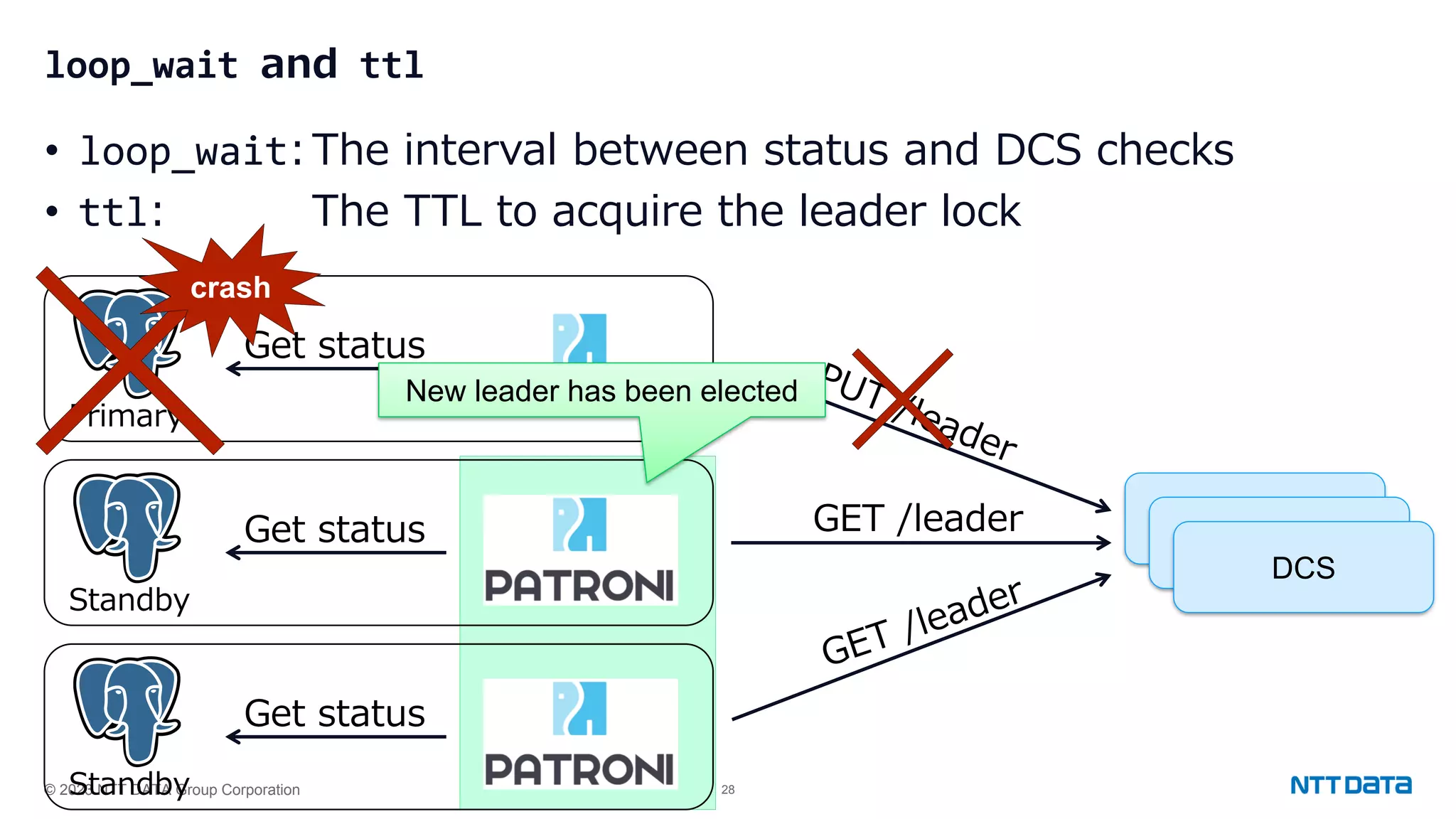
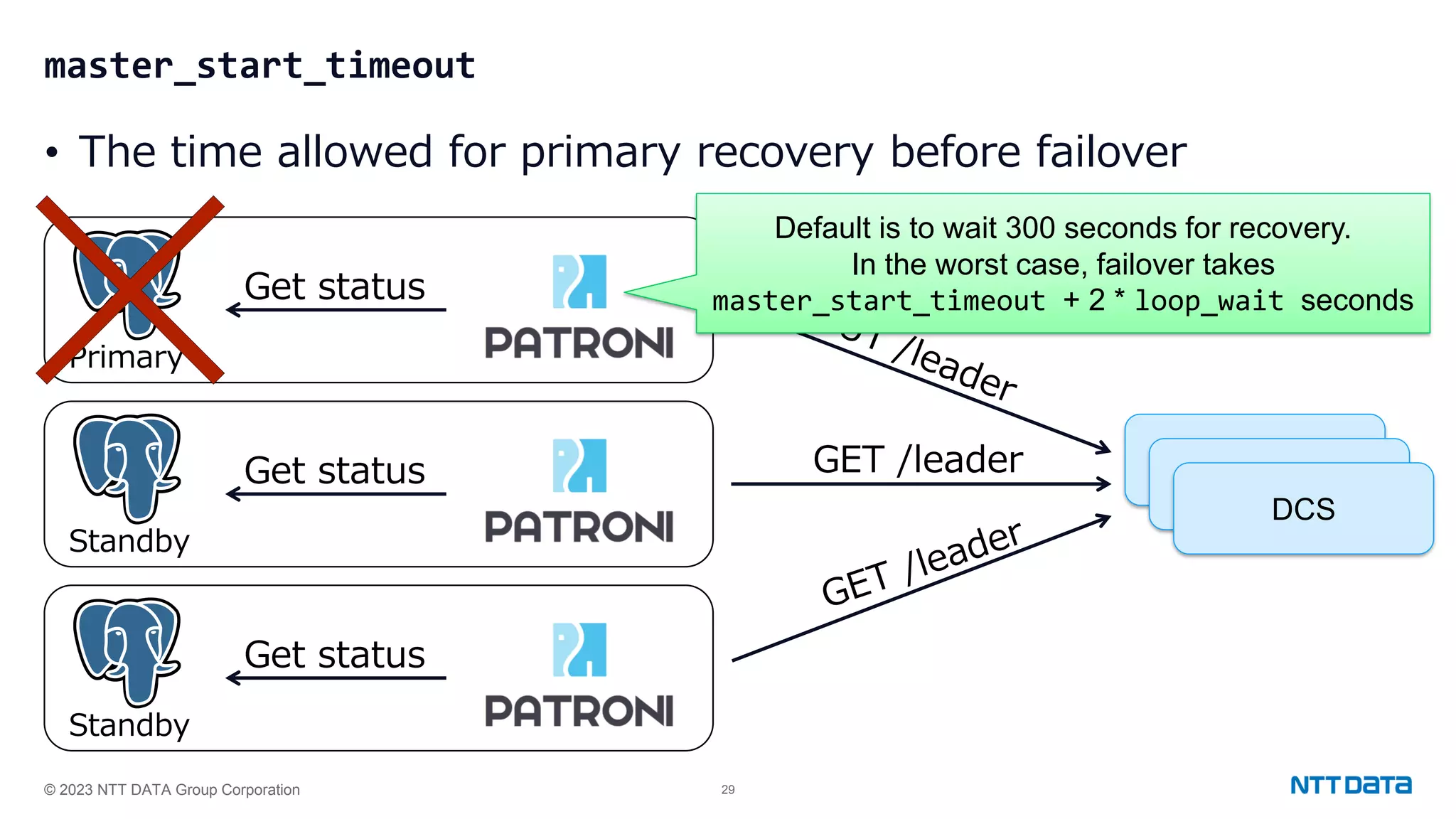
Configuration settings for high availability using Patroni, including synchronous modes, loop wait timings, and leader election criteria.
Configuration settings for high availability using Patroni, including synchronous modes, loop wait timings, and leader election criteria.
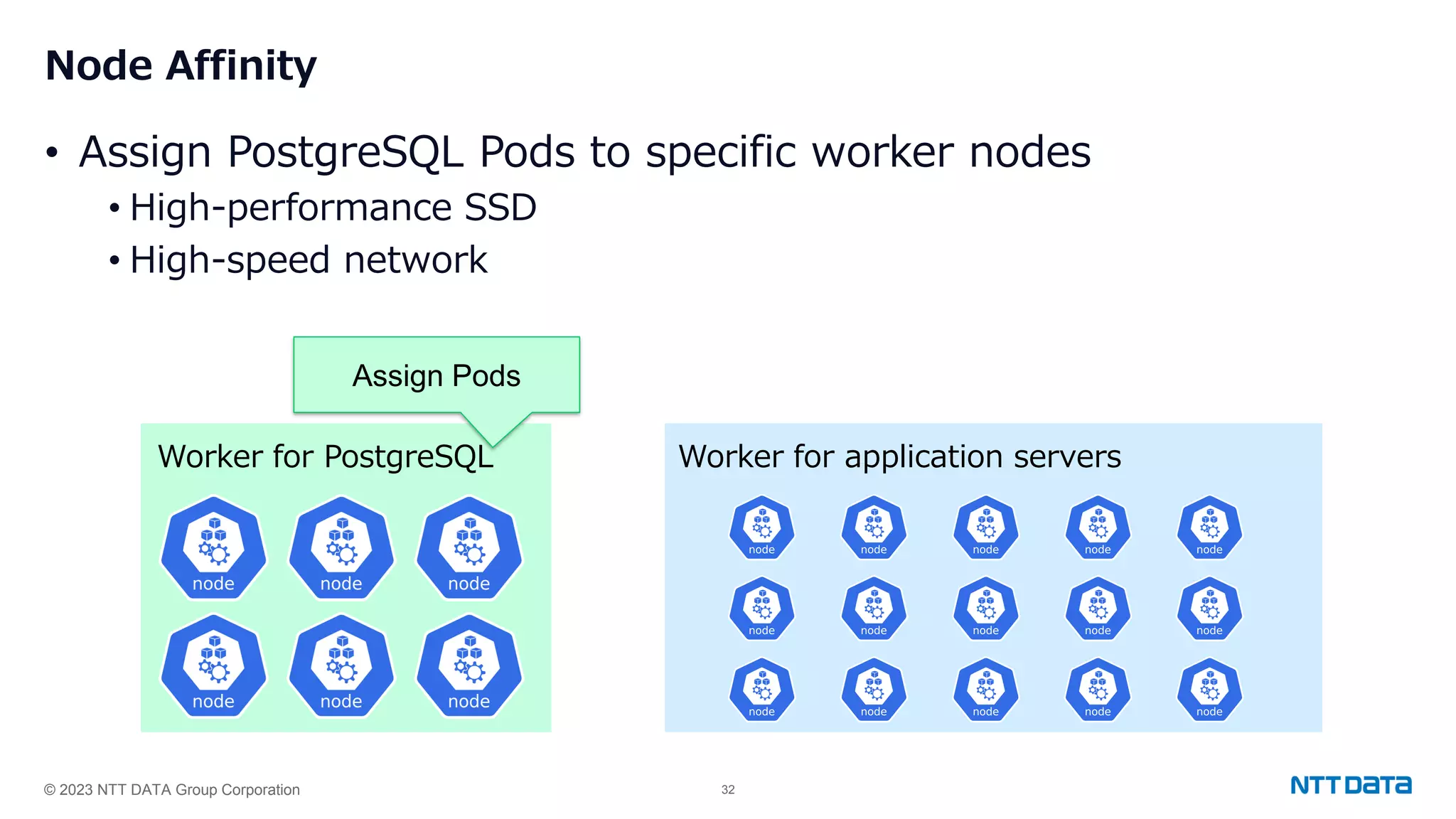
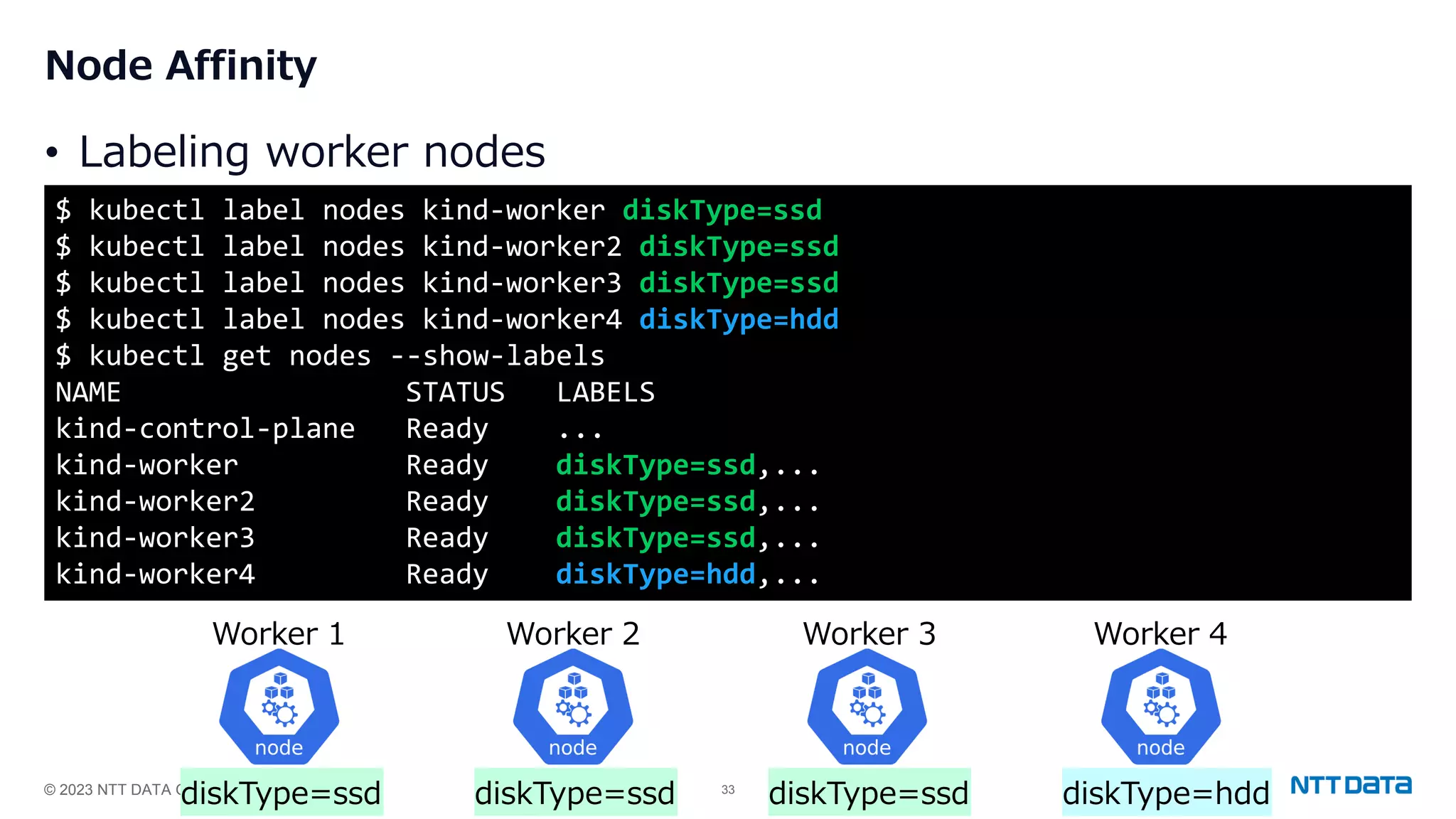
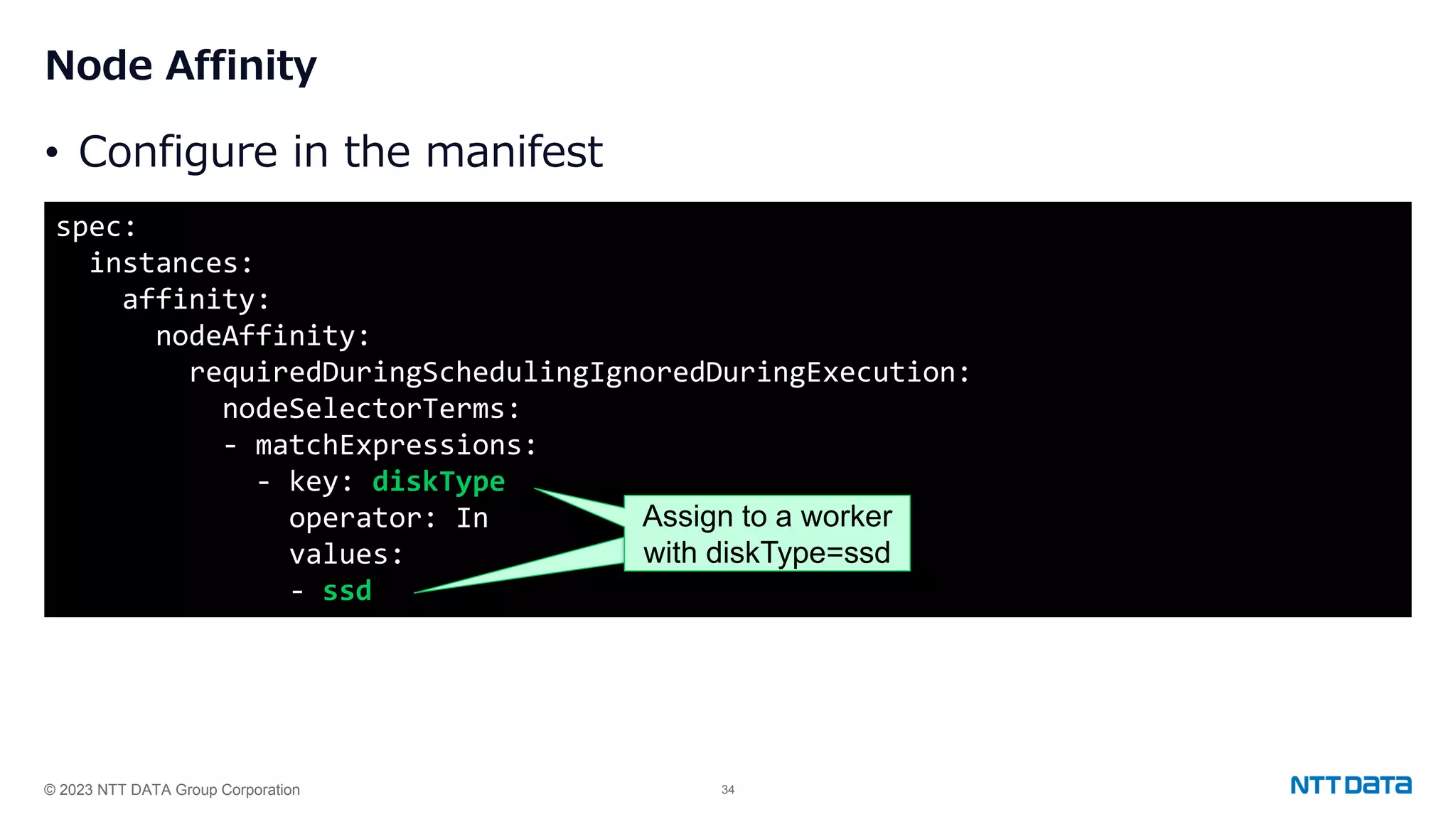
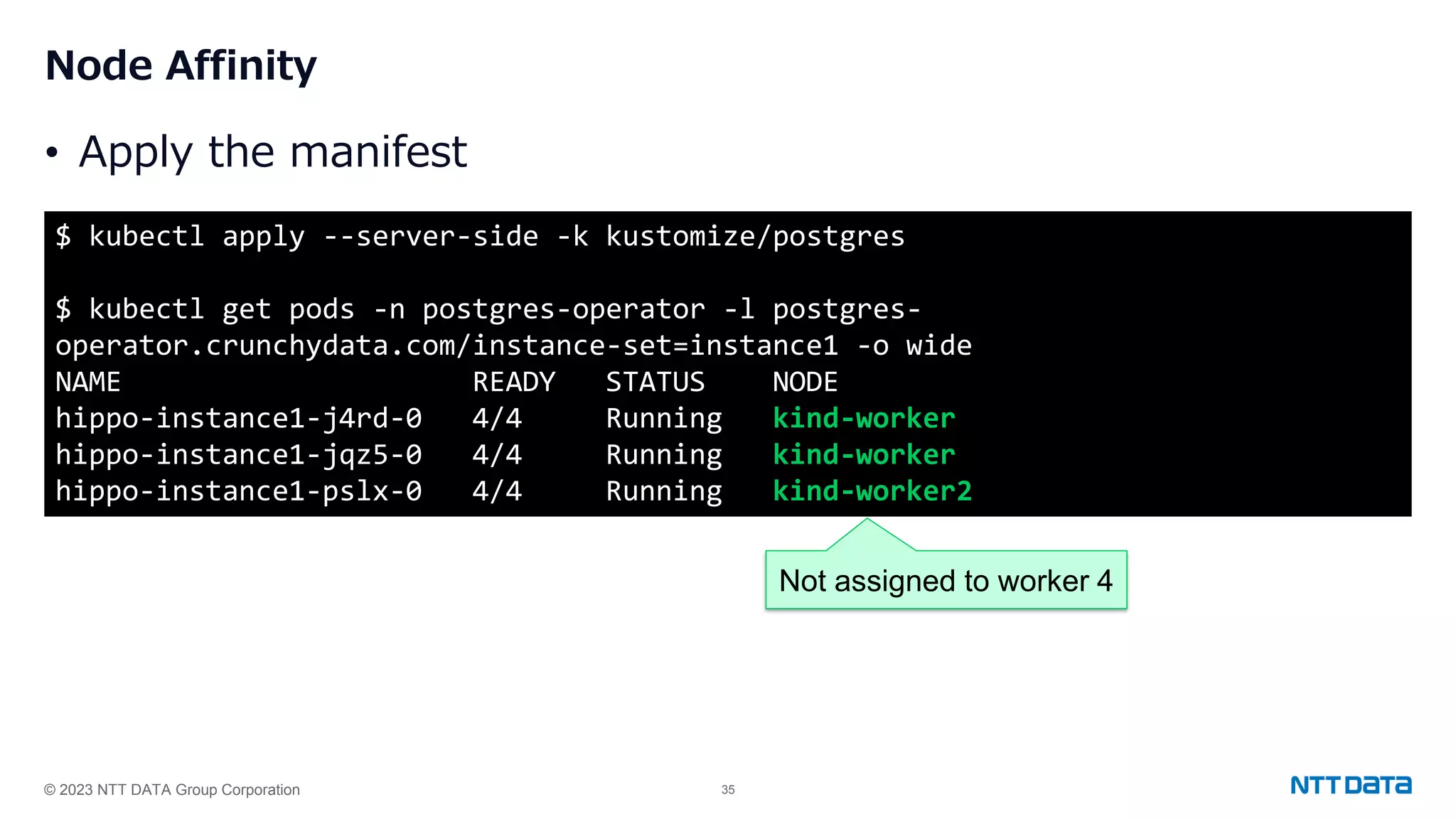
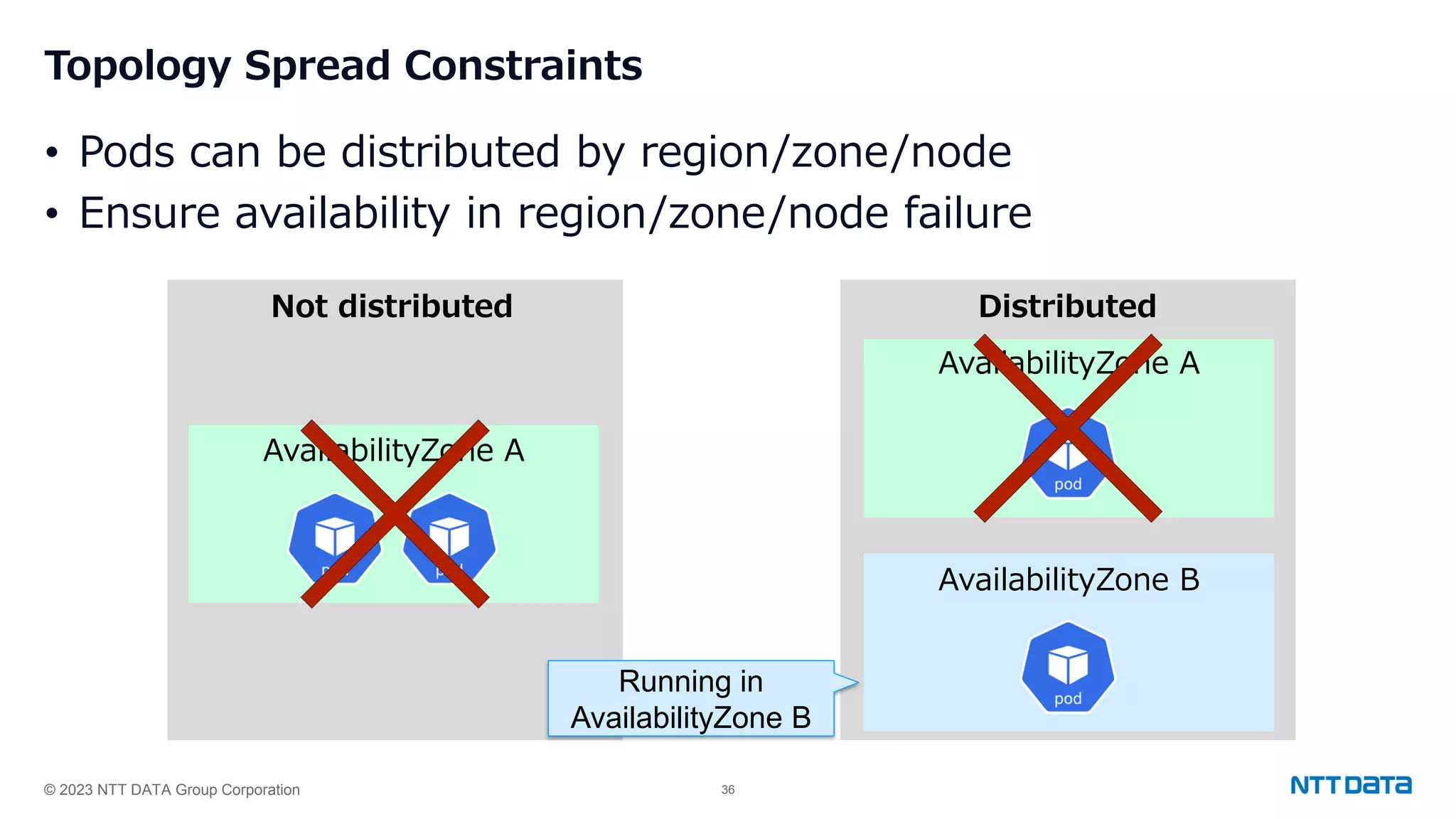
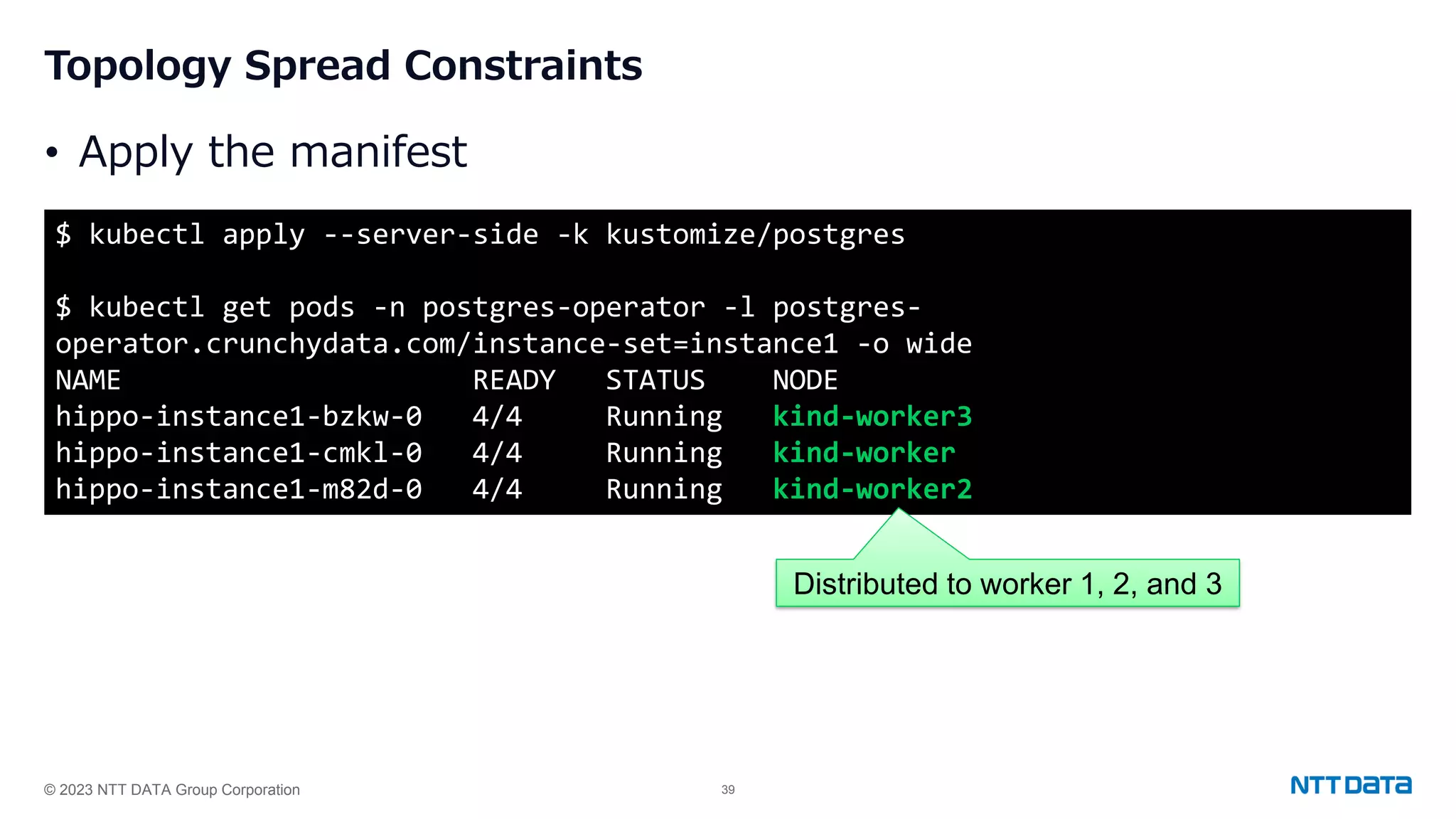
Use of Node Affinity and Topology Spread Constraints for distributing PostgreSQL Pods across Kubernetes nodes for high availability.
Use of Node Affinity and Topology Spread Constraints for distributing PostgreSQL Pods across Kubernetes nodes for high availability.
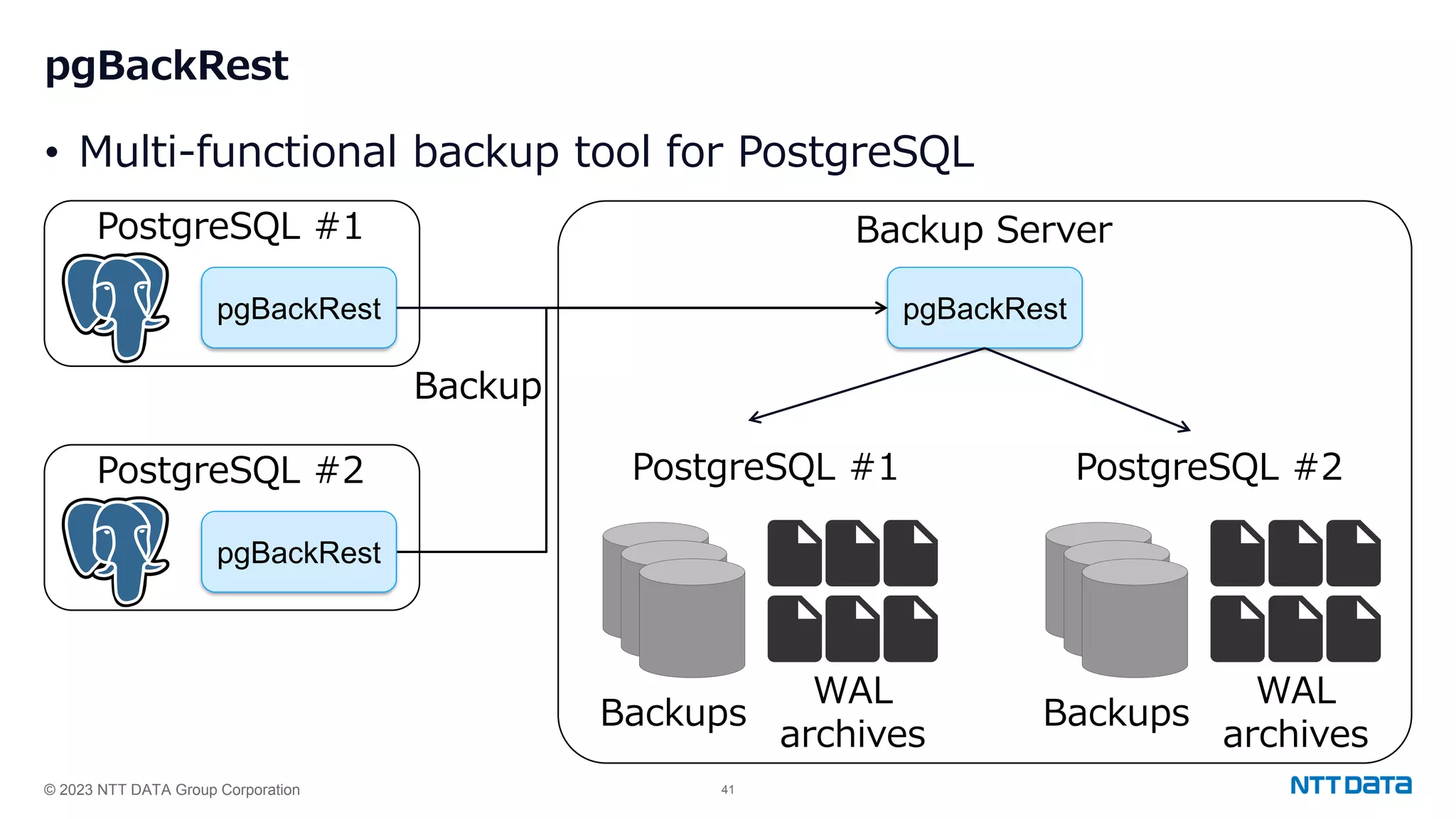
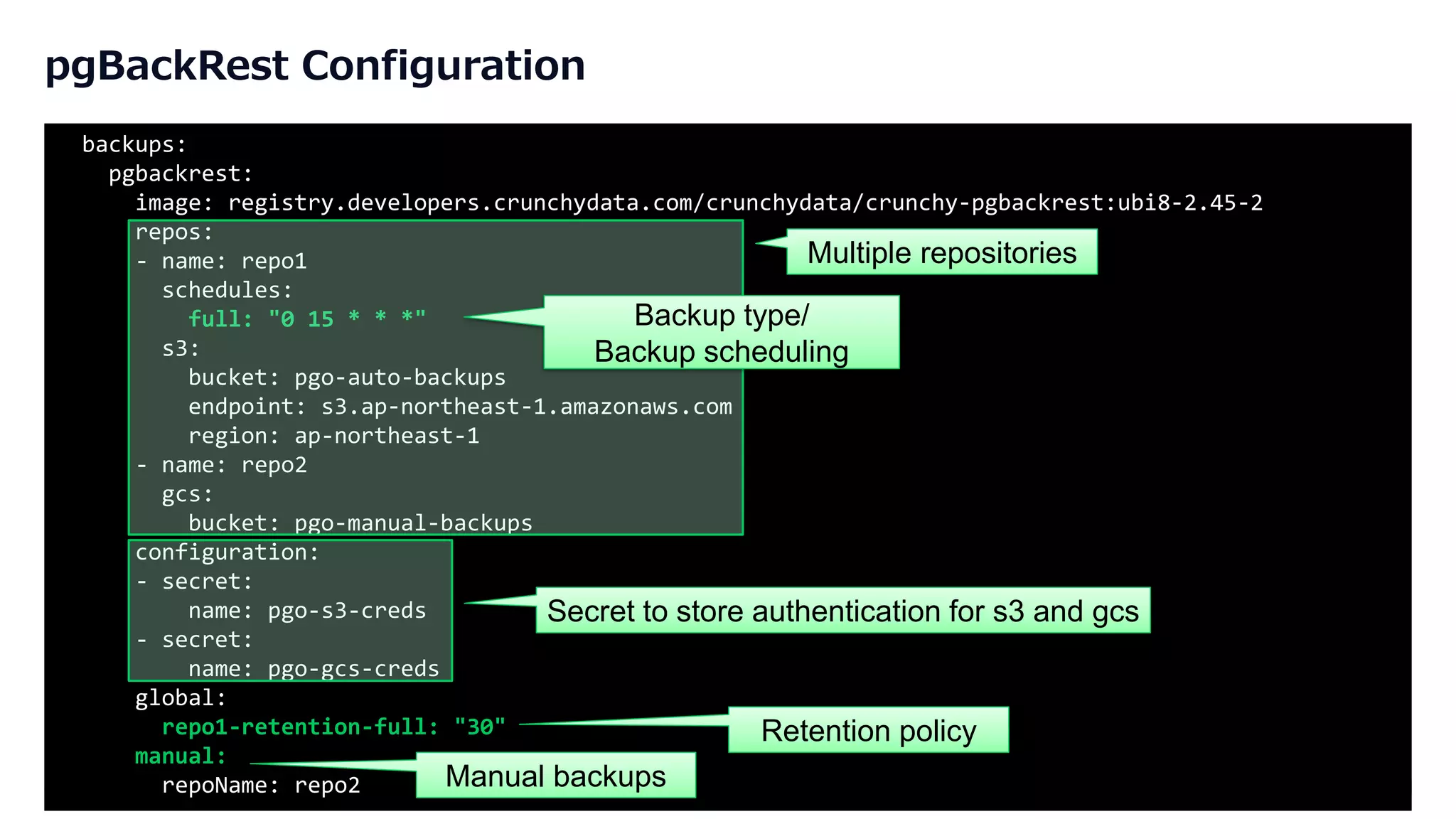
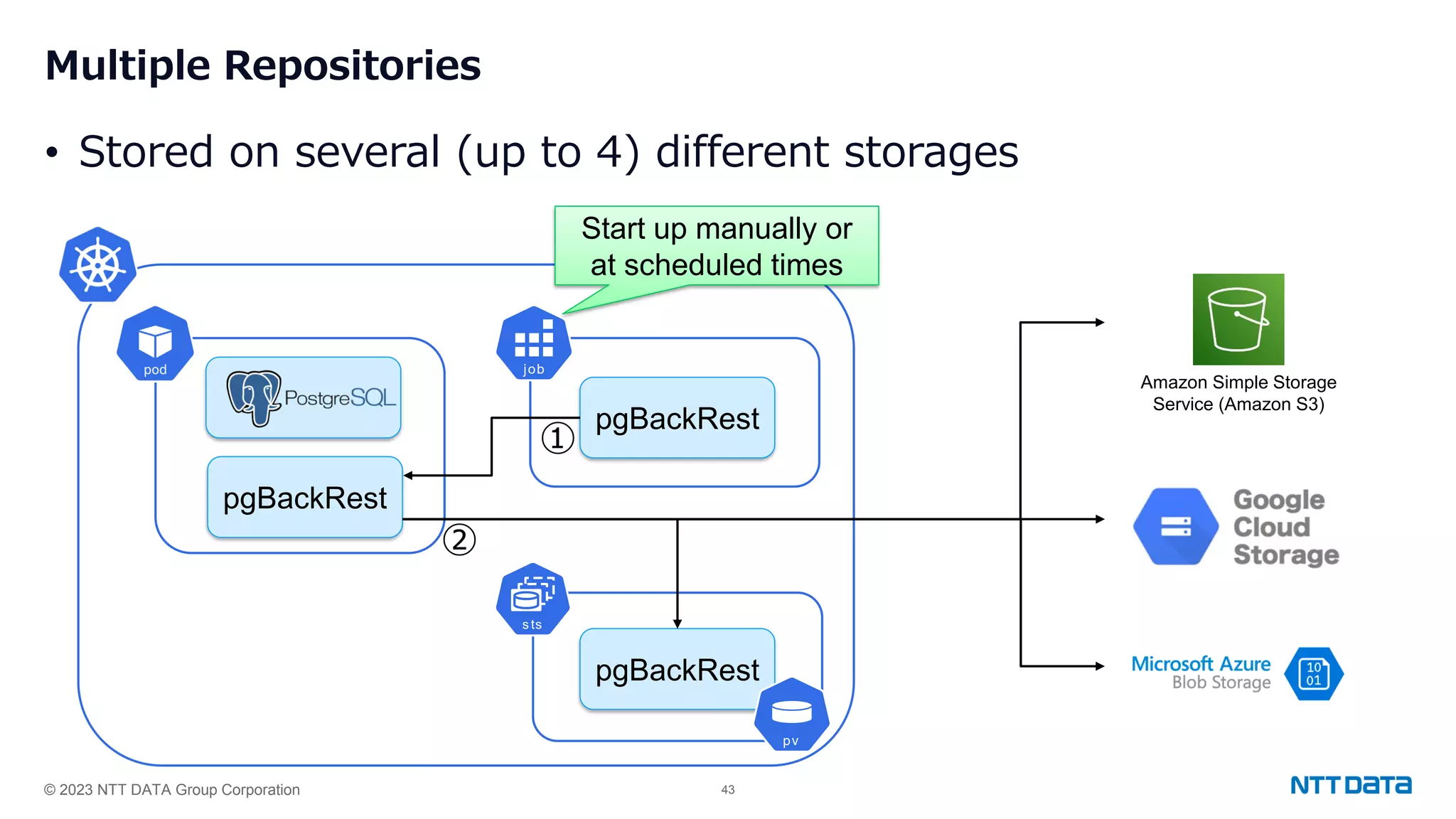
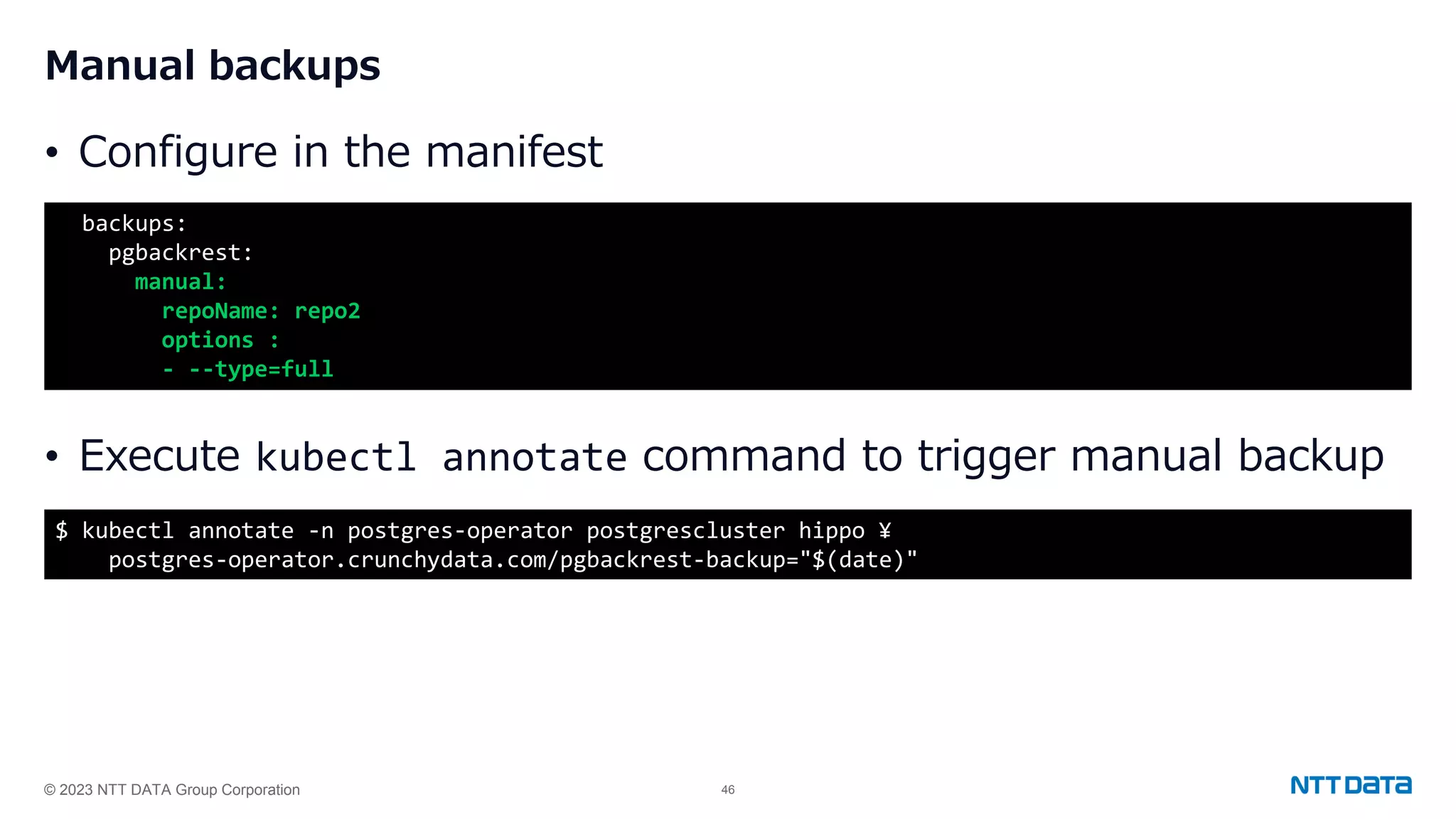
Overview of pgBackRest features for backing up PostgreSQL, including repositories, scheduling, and retention policies.
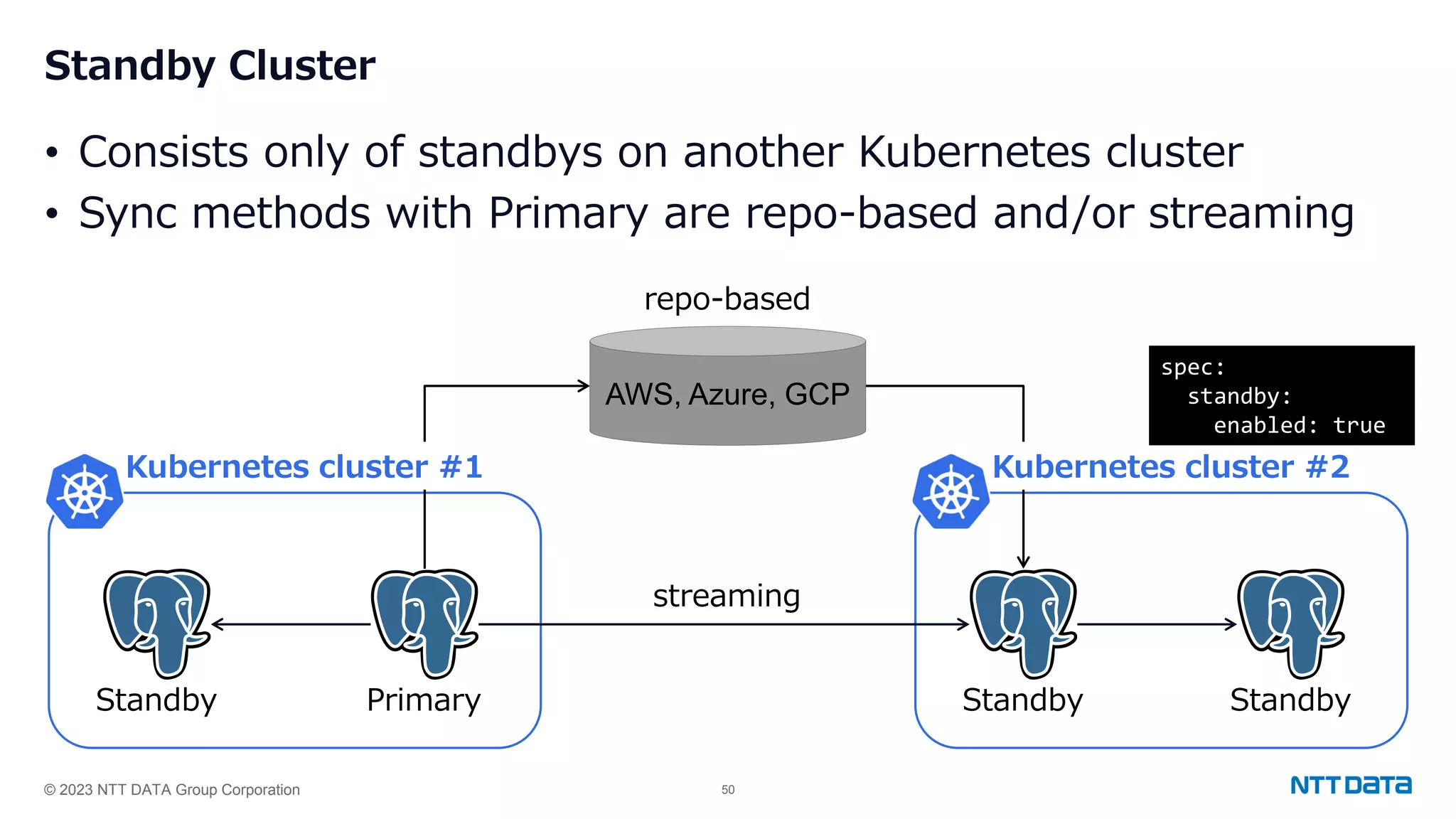
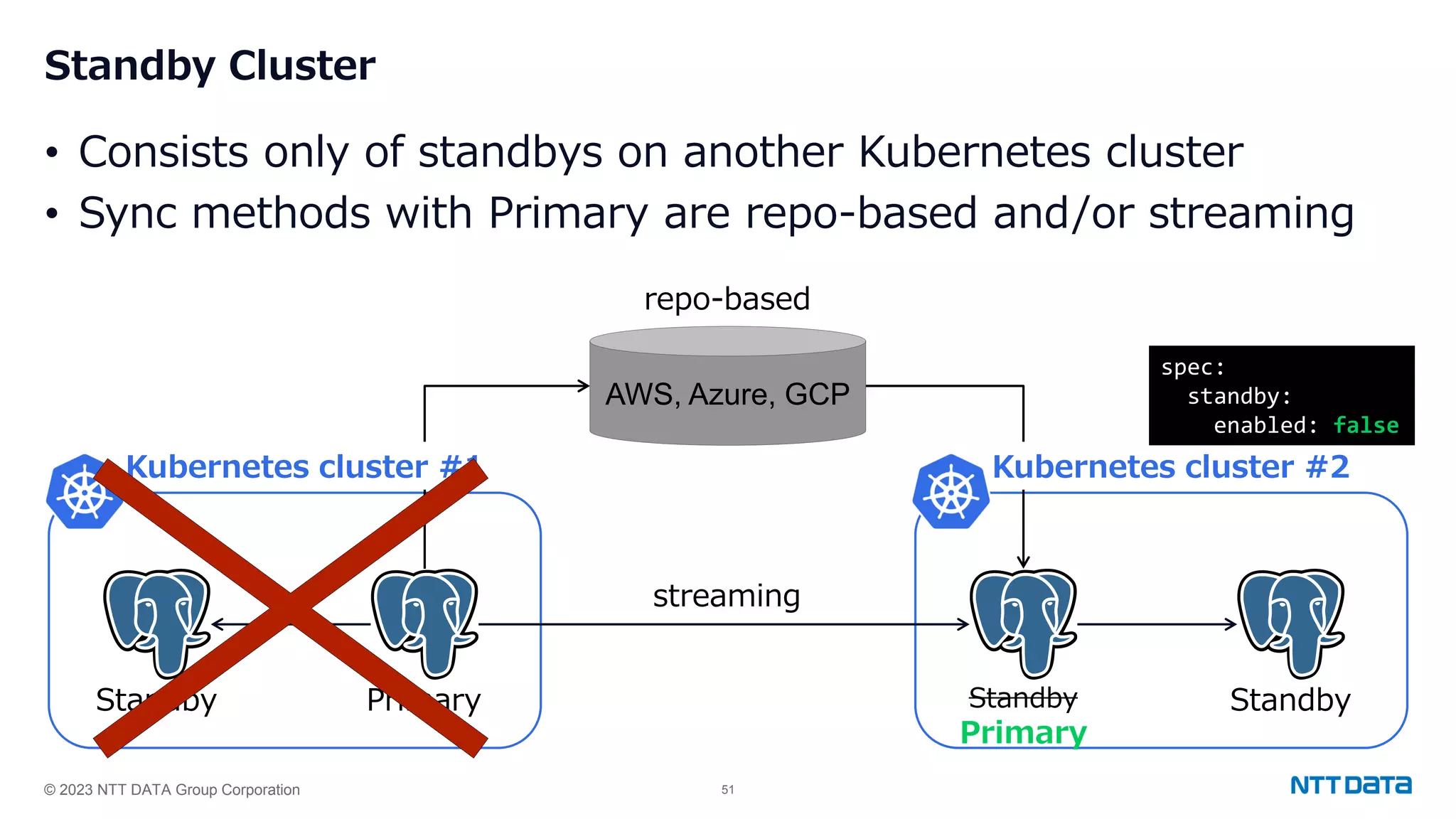
Implementation of standby clusters in different Kubernetes environments and syncing methods with the primary database.
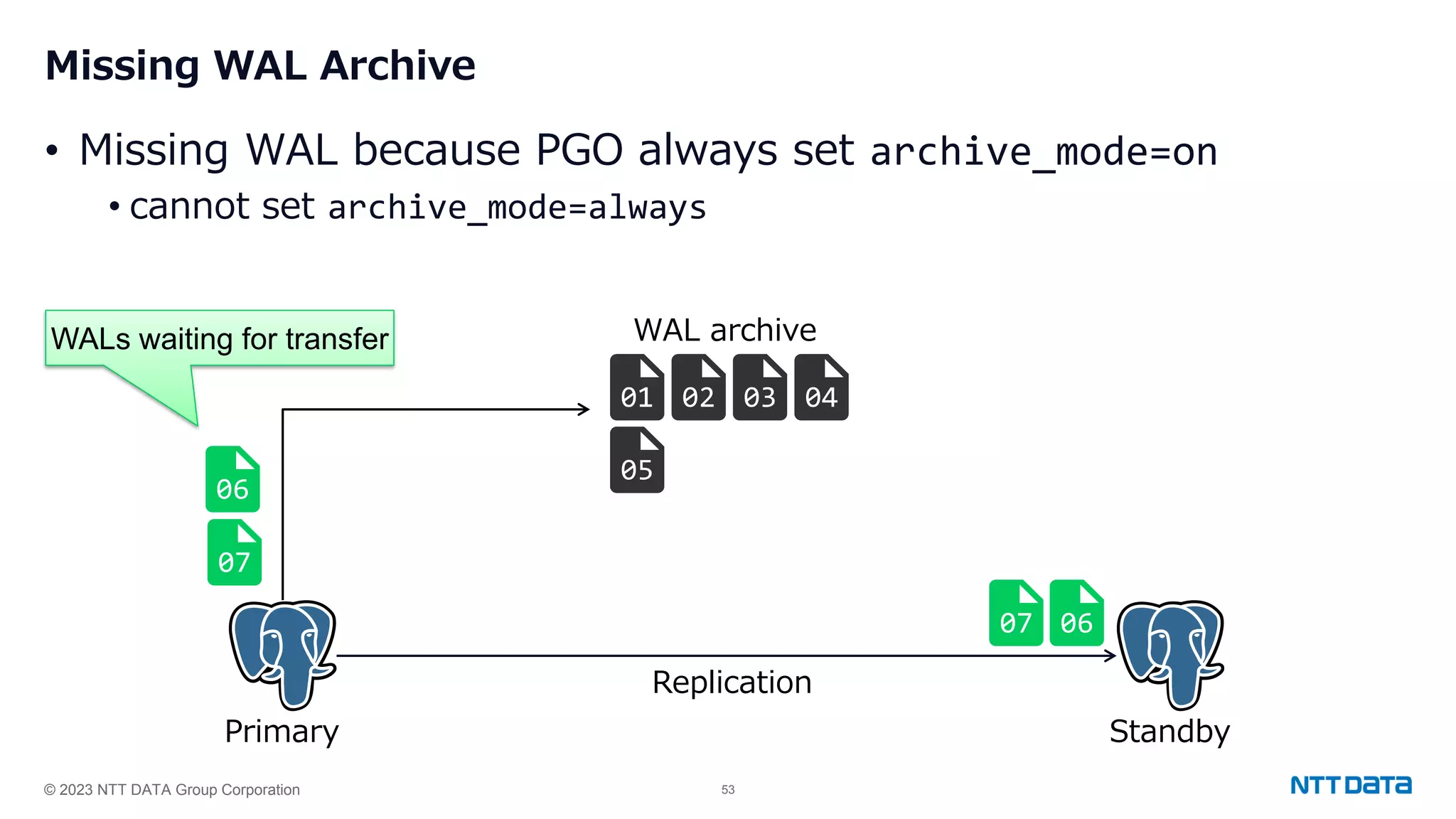
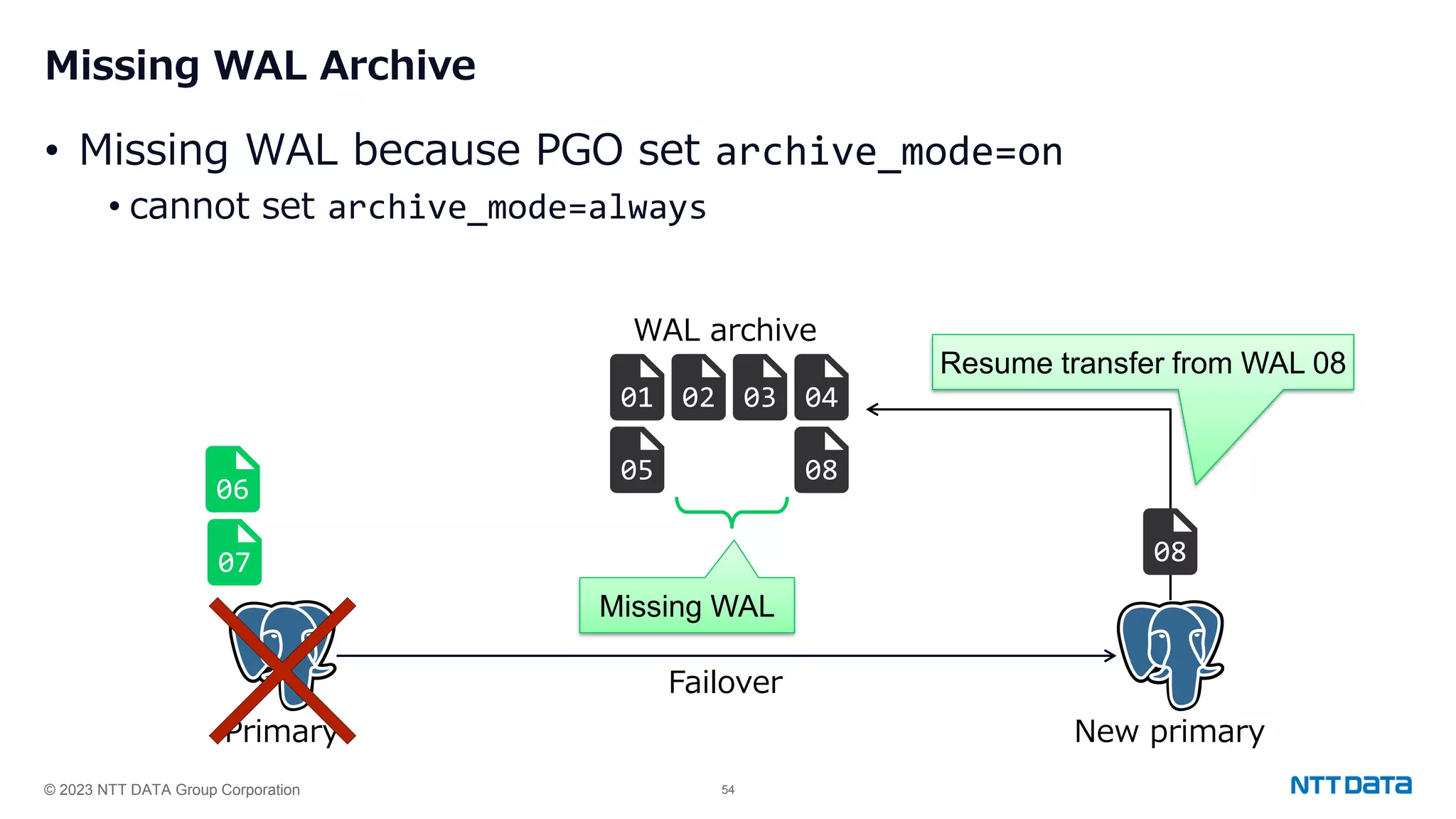
Discusses key challenges faced such as WAL archive issues and limitations of pg_rewind during standby recovery.Recap of the PostgreSQL Operator capabilities and the challenges associated with achieving high availability.
List of references for further information on PostgreSQL Operator, its documentation, and related tools.