Download to read offline


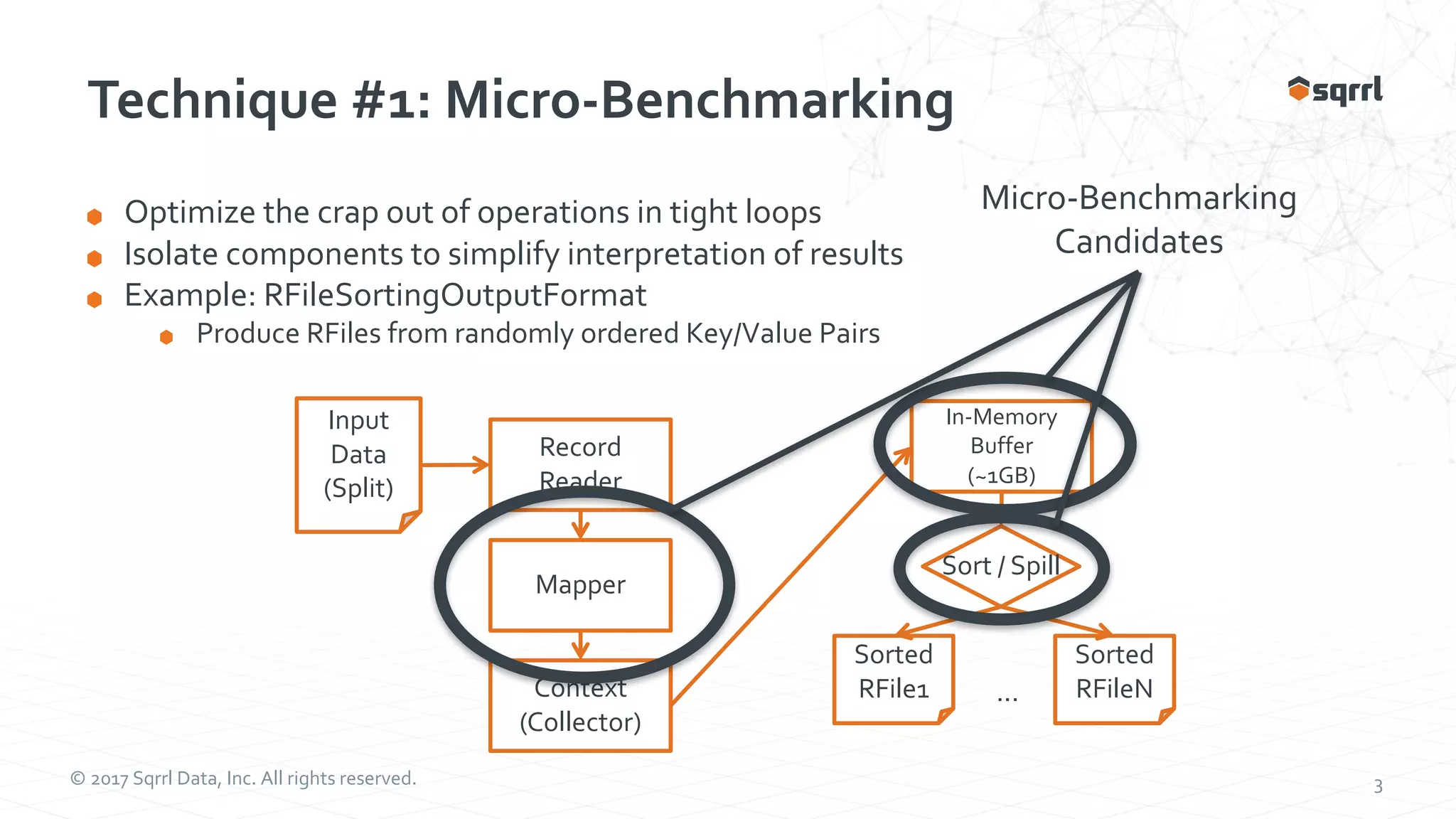


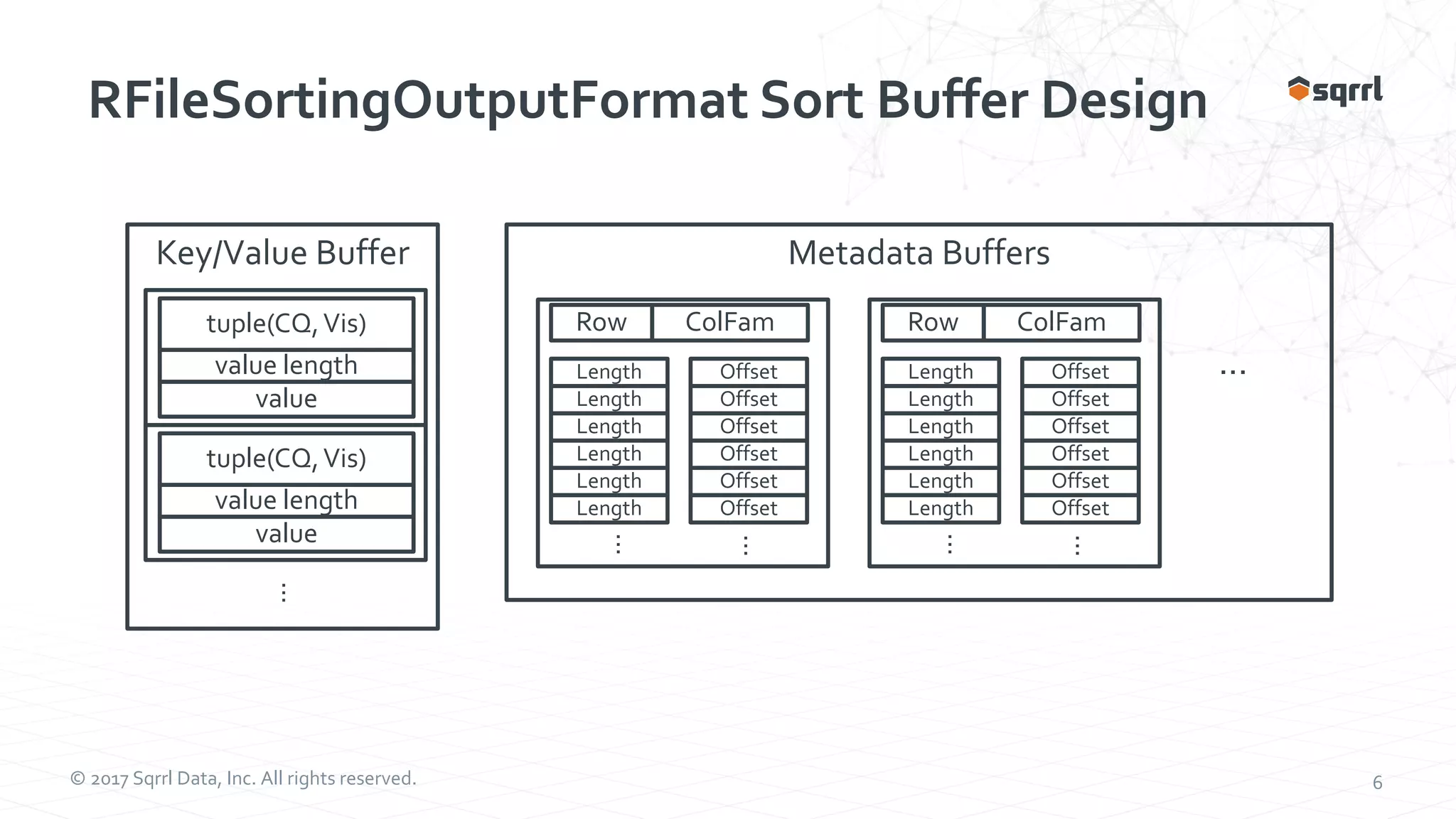

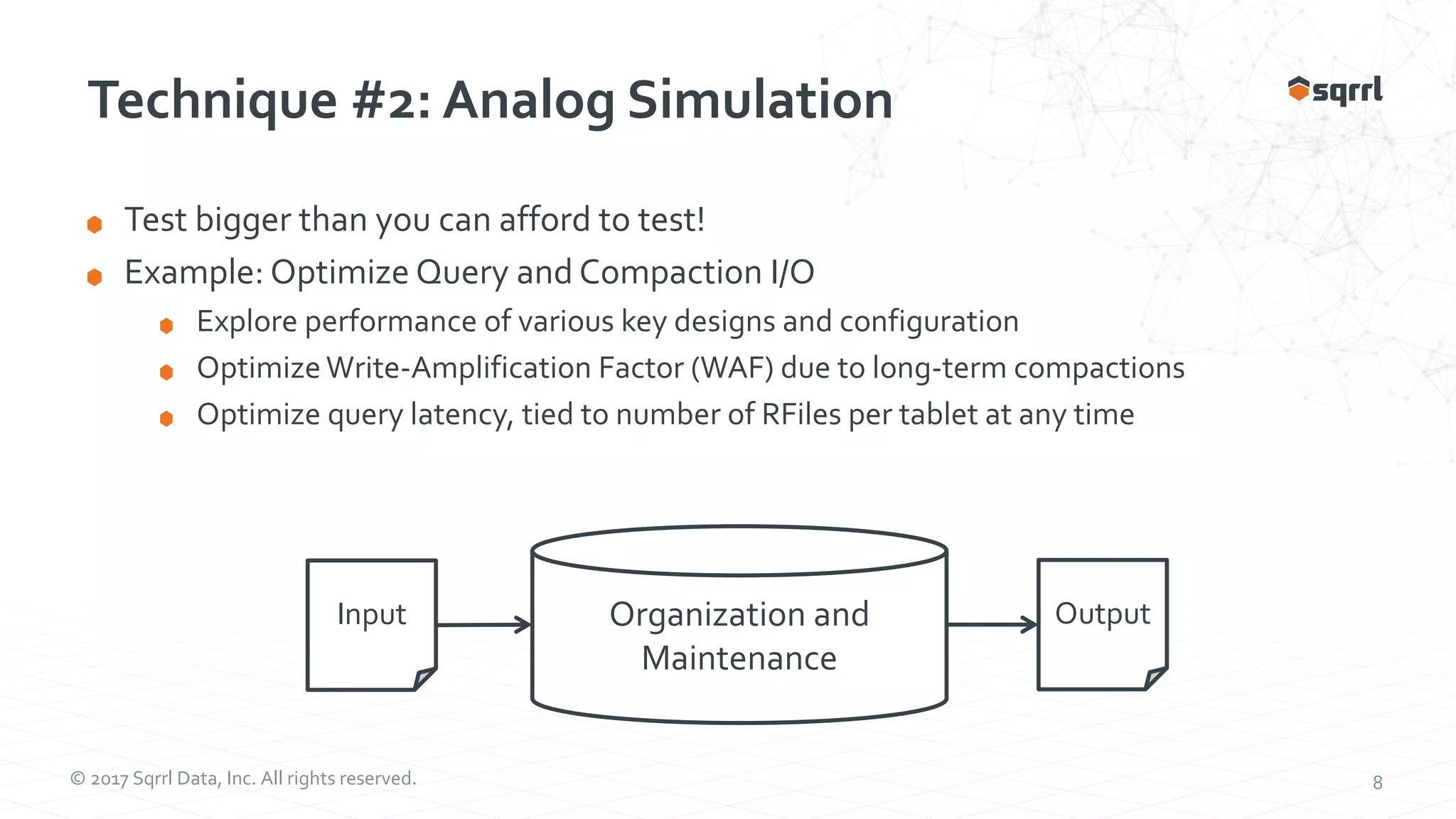
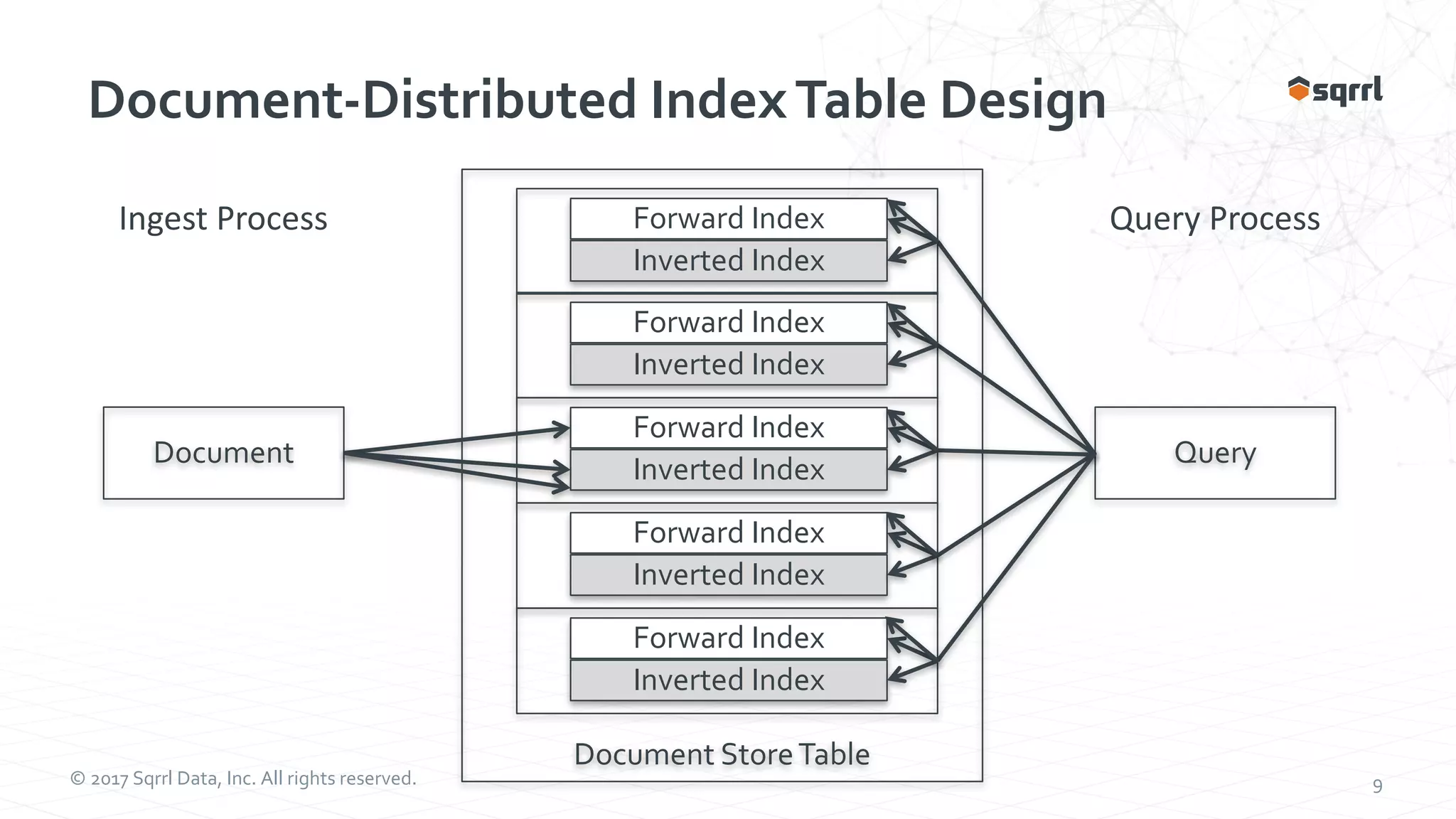
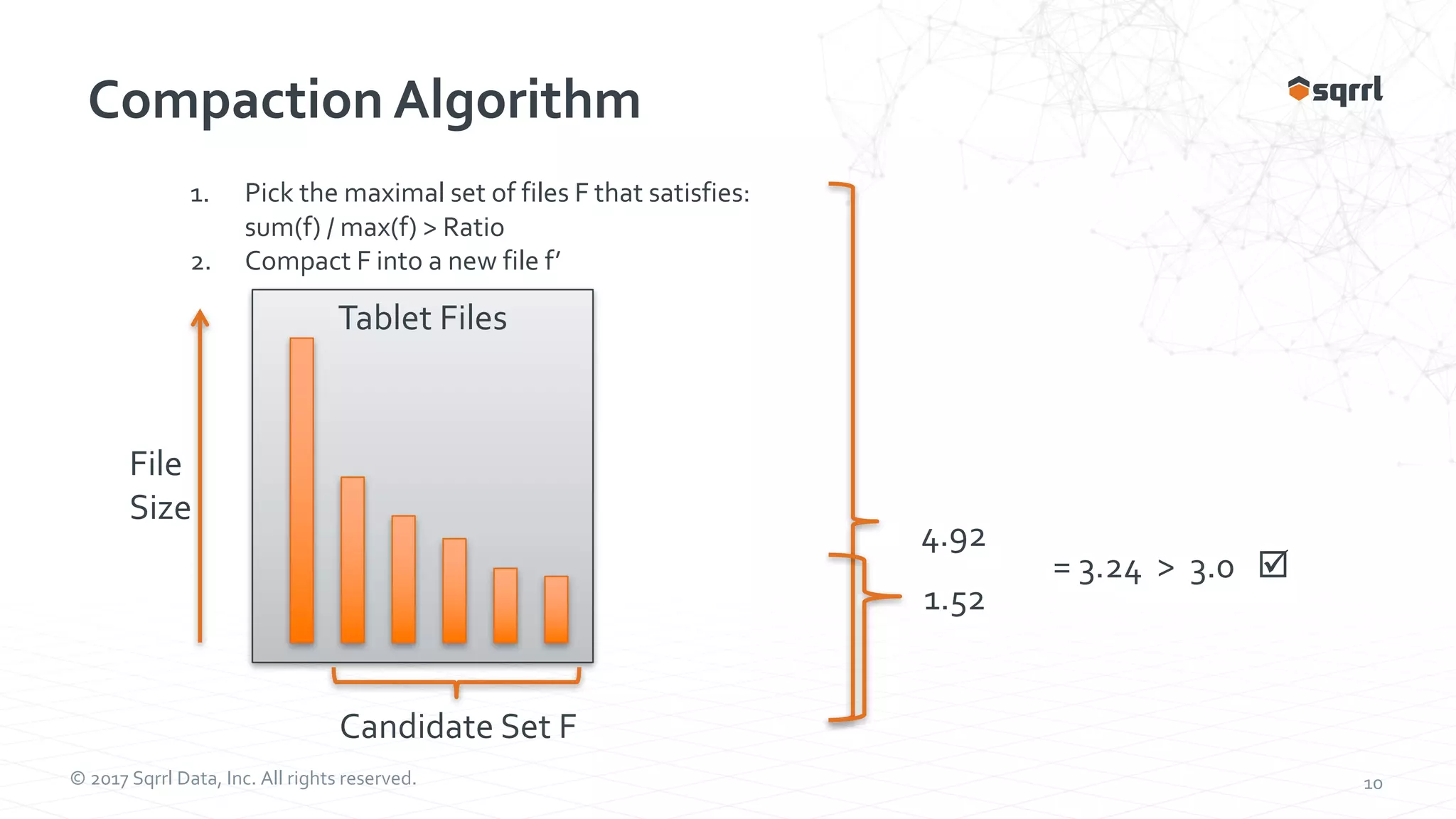
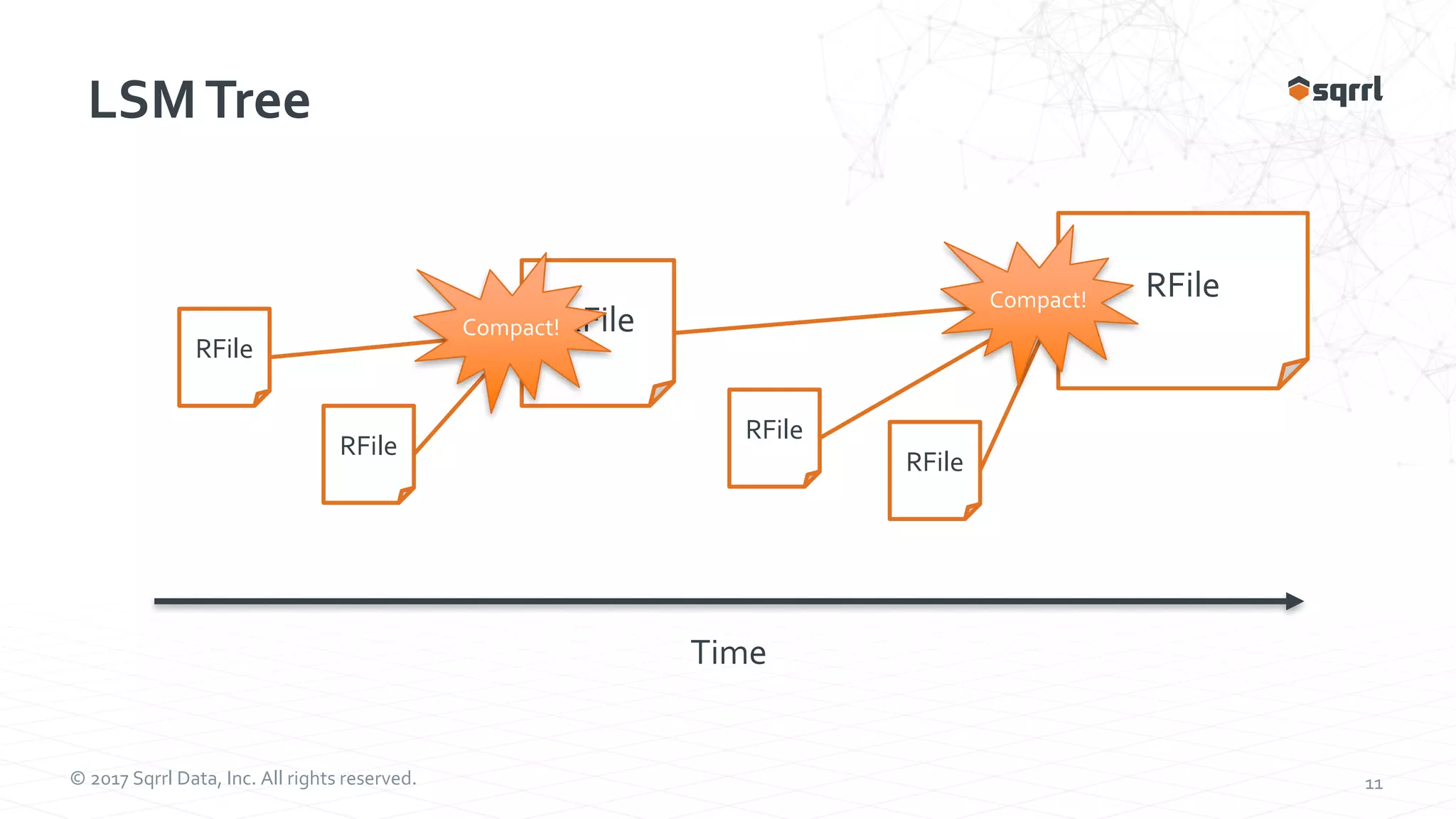
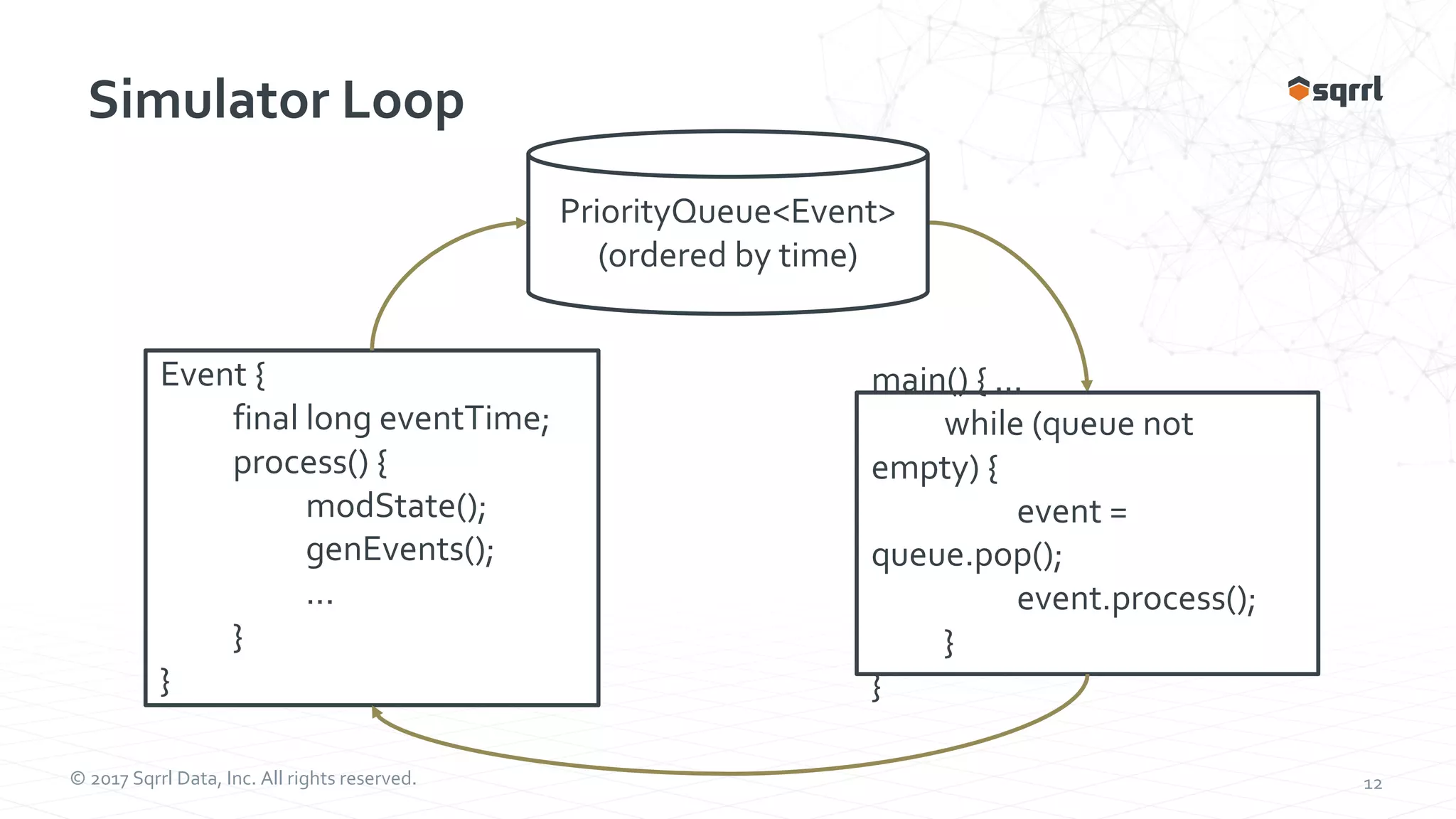
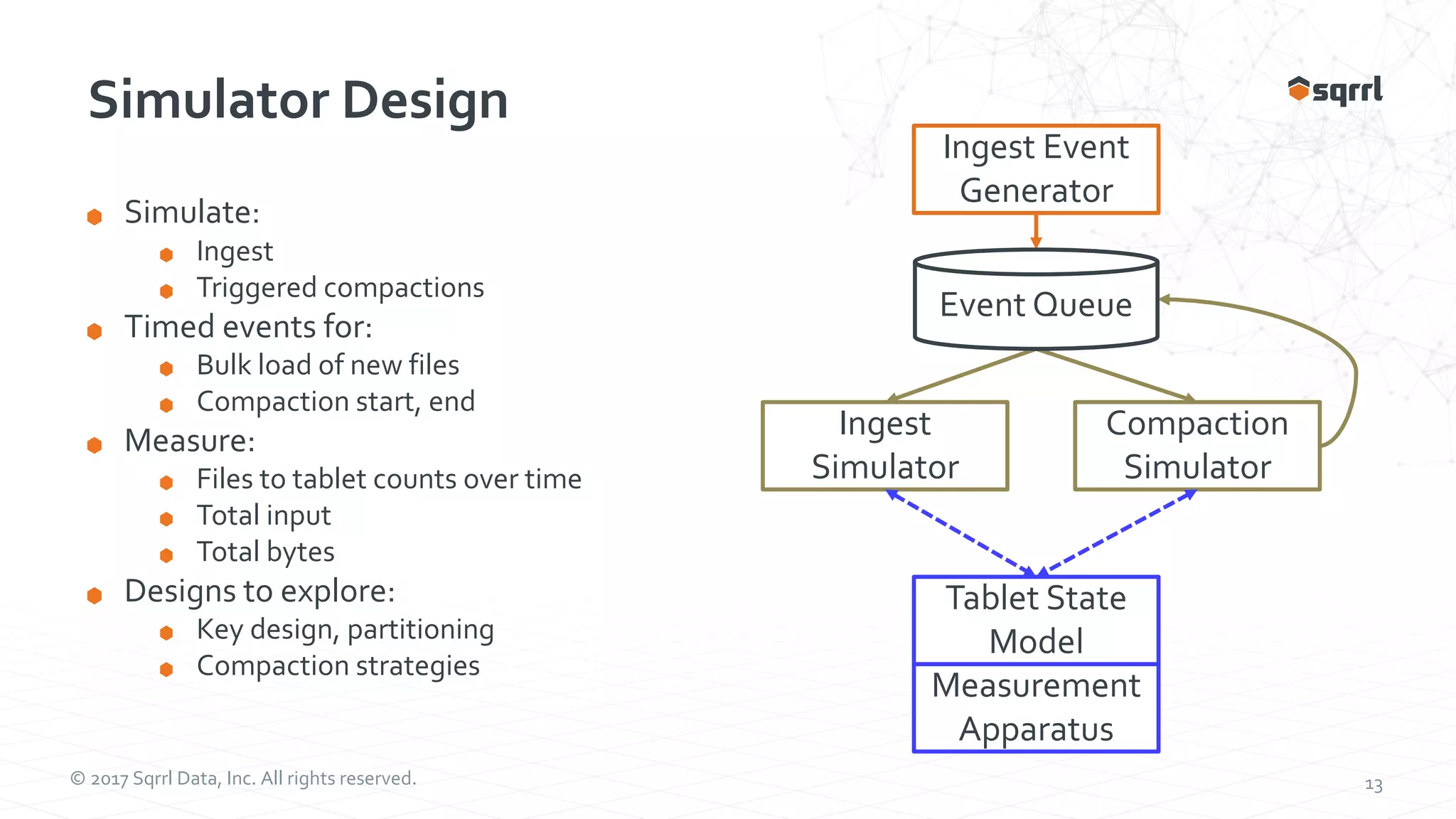



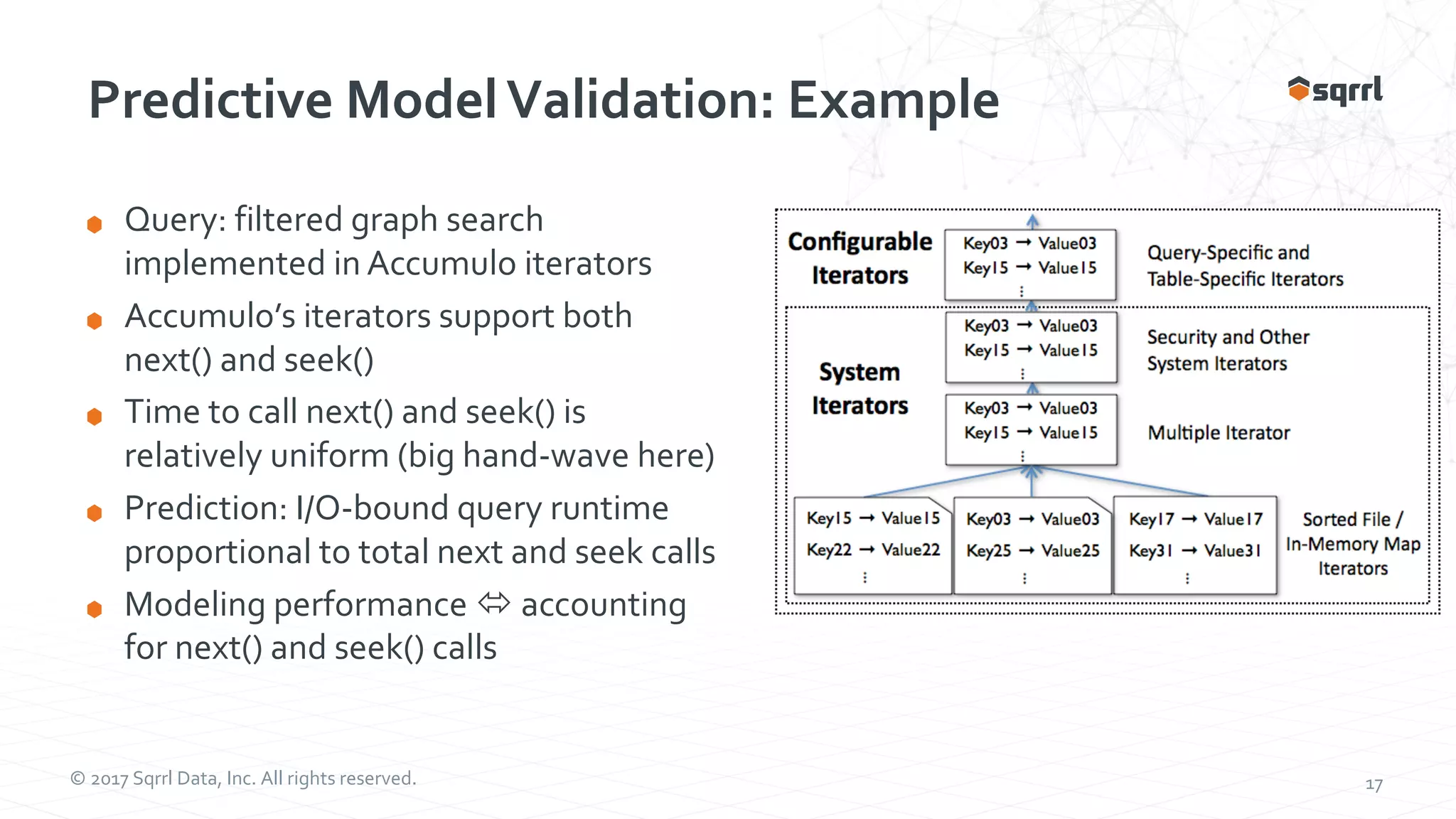

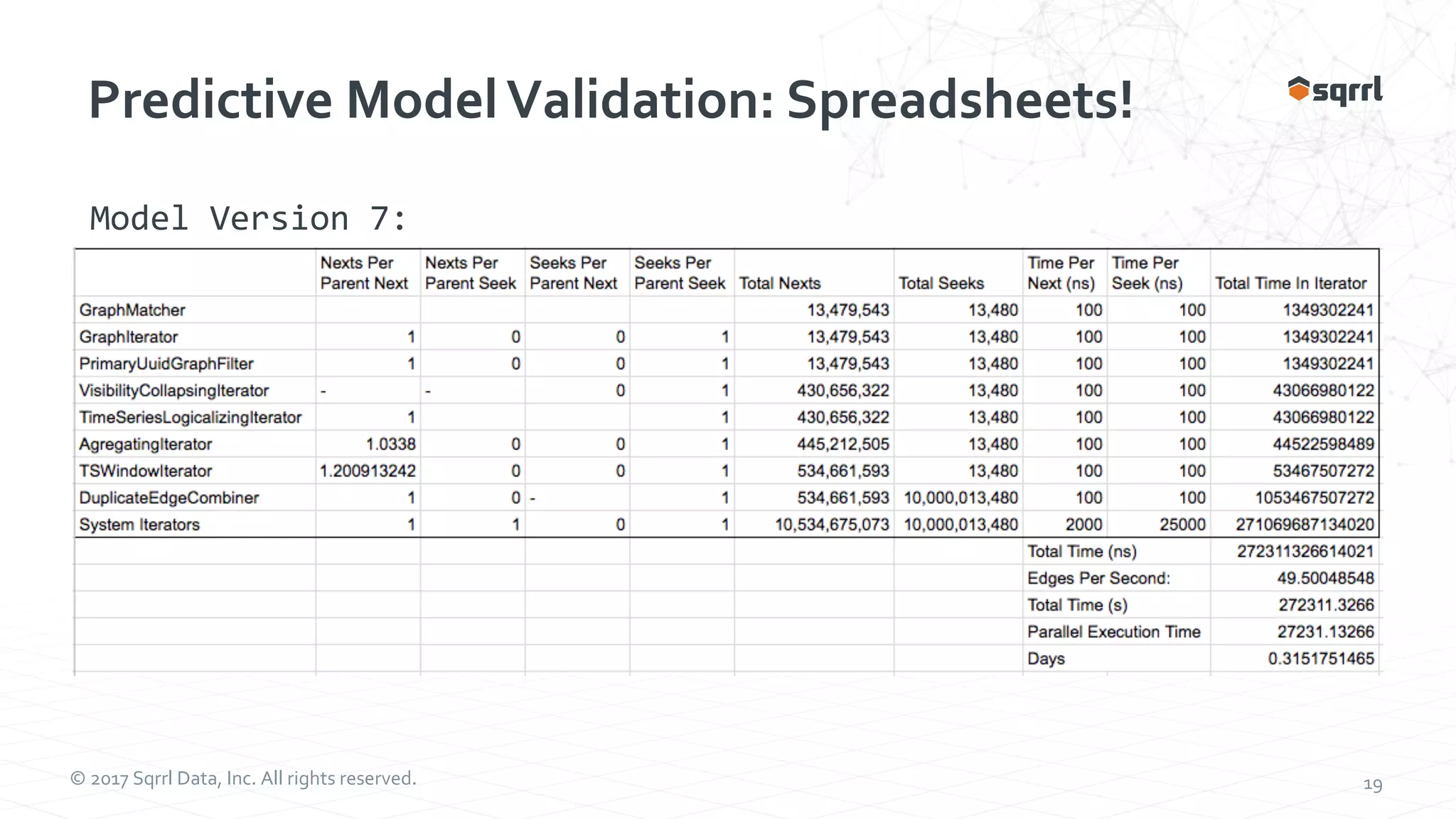




The document outlines performance modeling and simulation techniques for Apache Accumulo applications, focusing on optimizing code and configuration to enhance performance and scalability. It covers methods such as micro-benchmarking, analog simulation, and predictive model validation to identify and mitigate performance bottlenecks. Key insights include the importance of iterative measurement and testing in improving system efficiency over time.