Download as PDF, PPTX














![Embedded and Parallel Systems Lab 28 Example: thread.c #include <stdio.h> #include <pthread.h> char message[]="Example:create new thread"; void *thread_function(void *arg){ pthread_t tid = pthread_self(); printf("thread_function is runningn"); printf("new ID:%u Argument is %sn", tid, (char*)arg); pthread_exit("new thread endn"); } int main(void){ pthread_t new_thread; pthread_t master_thread = pthread_self(); void *thread_result; pthread_create(&new_thread, NULL, thread_function, (void*)message); pthread_join(new_thread, &thread_result); printf("nmaster ID:%u the new thread return valus is:%sn", master_thread,(char*)thread_result); return 0; }](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-28-2048.jpg)








![Embedded and Parallel Systems Lab 37 OpenMP ■ OpenMP 2.5 ■ Multi-threaded & Share memory ■ Fortran、C / C++ ■ 基本語法 ● #pragma omp directive [clause] ■ OpenMP 需求及支援環境 ● Windows ◆ Virtual studio 2005 standard ◆ Intel ® C++ Compiler 9.1 ● Linux ◆ gcc 4.2.0 ◆ Omni ● Xbox 360 & PS3](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-37-2048.jpg)





![Embedded and Parallel Systems Lab 45 Sections Working Share int main(int argc, char* argv[]) { #pragma omp parallel sections { #pragma omp section { toPNG(); } #pragma omp section { toJPG(); } #pragma omp section { toTIF(); } } } Input image toPNG toJPG toTIF](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-45-2048.jpg)
![Embedded and Parallel Systems Lab 46 OpenMP notice int Fe[10]; Fe[0] = 0; Fe[1] = 1; #pragma omp parallel for num_threads(2) for( i = 2; i < 10; ++ i ) Fe[i] = Fe[i-1] + Fe[i-2]; ■Data dependent #pragma omp parallel { #pragma omp for for( int i = 0; i < 1000000; ++ i ) sum += i; } ■Race conditions](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-46-2048.jpg)

![Embedded and Parallel Systems Lab 48 OpenMP example:matrix(1) #include <omp.h> #include <stdio.h> #include <stdlib.h> #define RANDOM_SEED 2882 //random seed #define VECTOR_SIZE 4 //sequare matrix width the same to height #define MATRIX_SIZE (VECTOR_SIZE * VECTOR_SIZE) //total size of MATRIX int main(int argc, char *argv[]){ int i,j,k; int node_id; int *AA; //sequence use & check the d2mce right or fault int *BB; //sequence use int *CC; //sequence use int computing; int _vector_size = VECTOR_SIZE; int _matrix_size = MATRIX_SIZE; char c[10];](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-48-2048.jpg)
![Embedded and Parallel Systems Lab 49 OpenMP example:matrix(2) if(argc > 1){ for( i = 1 ; i < argc ;){ if(strcmp(argv[i],"-s") == 0){ _vector_size = atoi(argv[i+1]); _matrix_size =_vector_size * _vector_size; i+=2; } else{ printf("the argument only have:n"); printf("-s: the size of vector ex: -s 256n"); return 0; } } } AA =(int *)malloc(sizeof(int) * _matrix_size); BB =(int *)malloc(sizeof(int) * _matrix_size); CC =(int *)malloc(sizeof(int) * _matrix_size);](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-49-2048.jpg)
![Embedded and Parallel Systems Lab 50 OpenMP example:matrix(3) srand( RANDOM_SEED ); /* create matrix A and Matrix B */ for( i=0 ; i< _matrix_size ; i++){ AA[i] = rand()%10; BB[i] = rand()%10; } /* computing C = A * B */ #pragma omp parallel for private(computing, j , k) for( i=0 ; i < _vector_size ; i++){ for( j=0 ; j < _vector_size ; j++){ computing =0; for( k=0 ; k < _vector_size ; k++) computing += AA[ i*_vector_size + k ] * BB[ k*_vector_size + j ]; CC[ i*_vector_size + j ] = computing; } }](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-50-2048.jpg)






![Embedded and Parallel Systems Lab 58 MPI 安裝 http://www-unix.mcs.anl.gov/mpi/mpich/ 下載mpich2-1.0.4p1.tar.gz [shell]# tar –zxvf mpich2-1.0.4p1.tar.gz [shell]# mkdir /home/yourhome/mpich2 [shell]# cd mpich2-1.0.4p1 [shell]# ./configure –prefix=/home/yourhome/mpich2 //建議自行建立目錄安 裝 [shell]# make [shell]# make install 再來是 [shell]# cd ~yourhome //到自己home目錄下 [shell]# vi .mpd.conf //建立文件 內容為 secretword=<secretword> (secretword可以依自己喜好打) Ex: secretword=abcd1234](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-58-2048.jpg)
![Embedded and Parallel Systems Lab 59 MPI 安裝 [shell]# chmod 600 mpd.conf [shell]# vi .bash_profiles 將PATH=$PATH:$HOME/bin 改成PATH=$HOME/mpich2/bin:$PATH:$HOME/bin 重登server [shell]# vi mpd.hosts //在自己home目錄下建立hosts list文件 ex: cluster1 cluster2 cluster3 cluster4](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-59-2048.jpg)

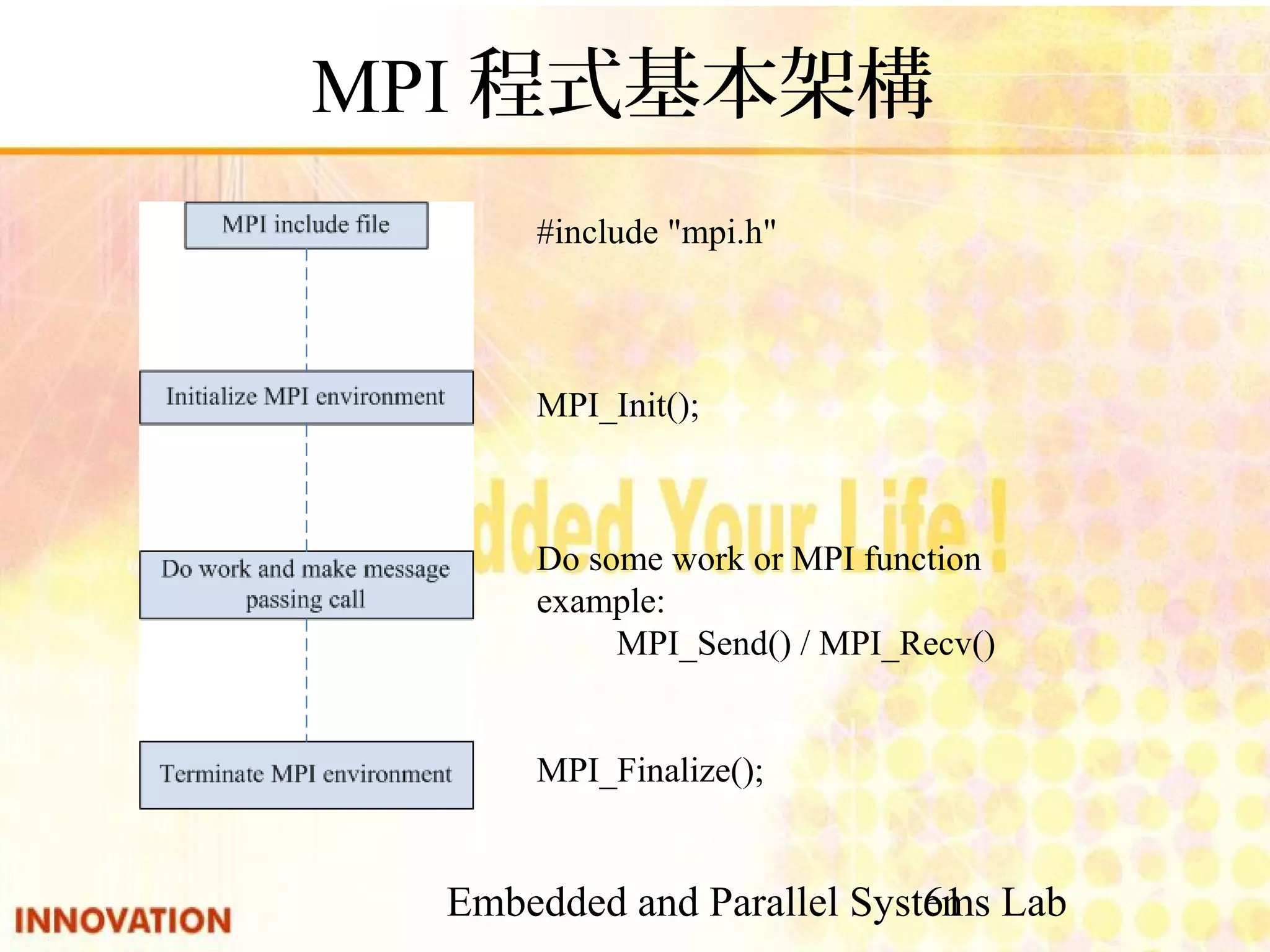
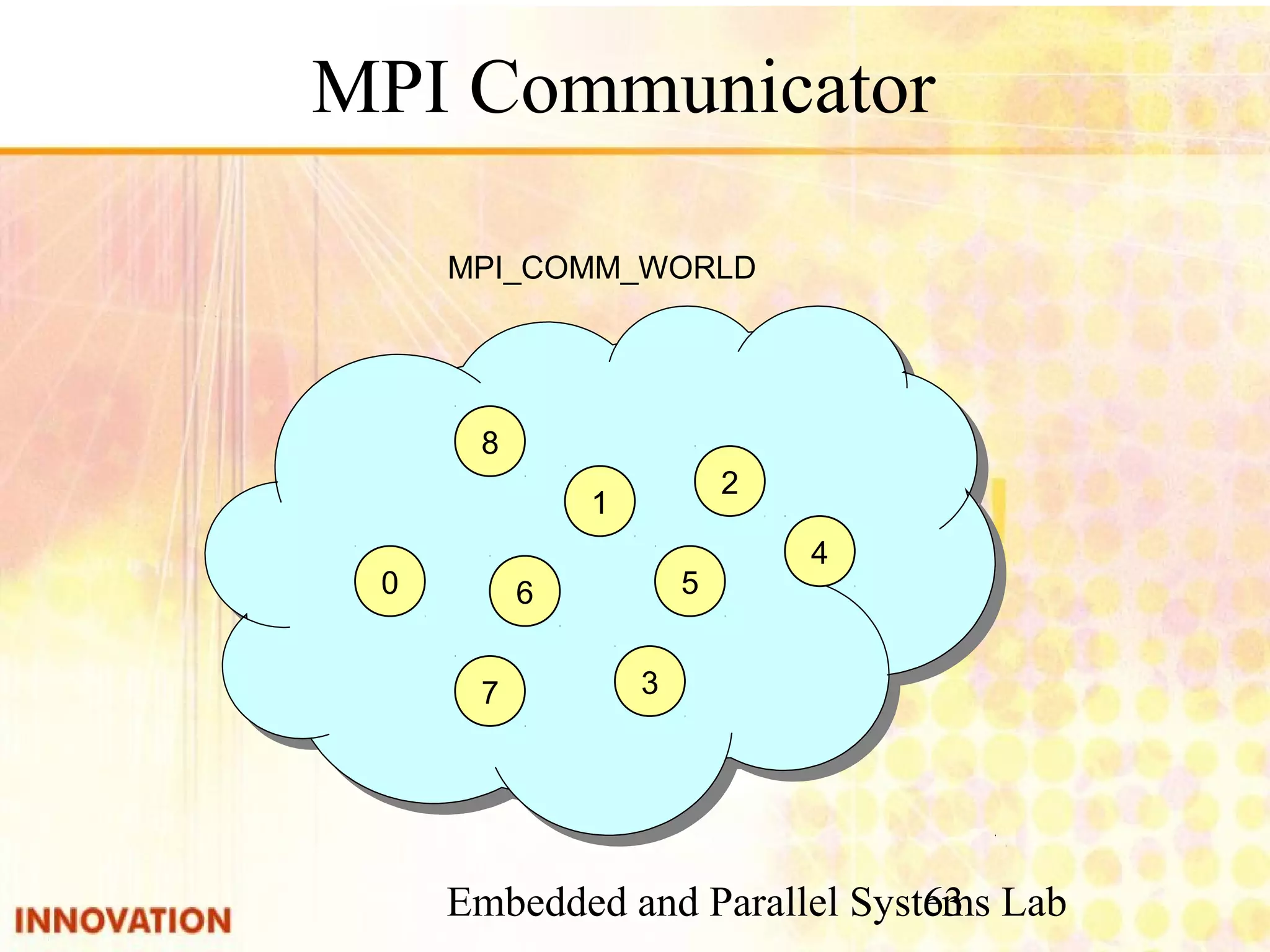
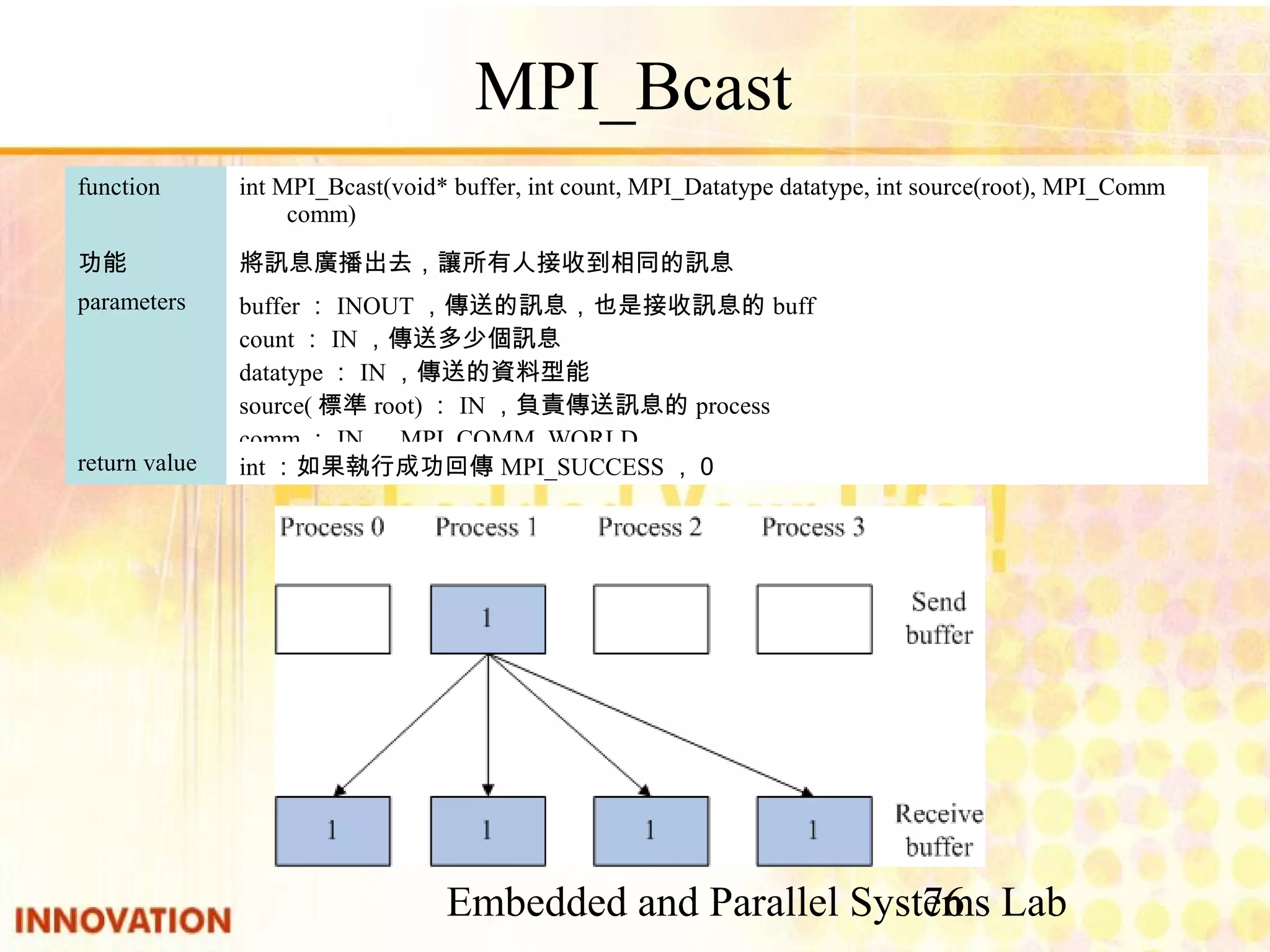
![Embedded and Parallel Systems Lab 64 MPI Function int:如果執行成功回傳MPI_SUCCESS,0return value int argc:參數數目 char* argv[]:參數內容 parameters 起始MPI執行環境,必須在所有MPI function前使用,並可以將main的指令參數 (argc, argv)傳送到所有process 功能 int MPI_Init( int *argc, char *argv[])function int:如果執行成功回傳MPI_SUCCESS,0return value parameters 結束MPI執行環境,在所有工作完成後必須呼叫功能 int MPI_Finzlize()function](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-64-2048.jpg)





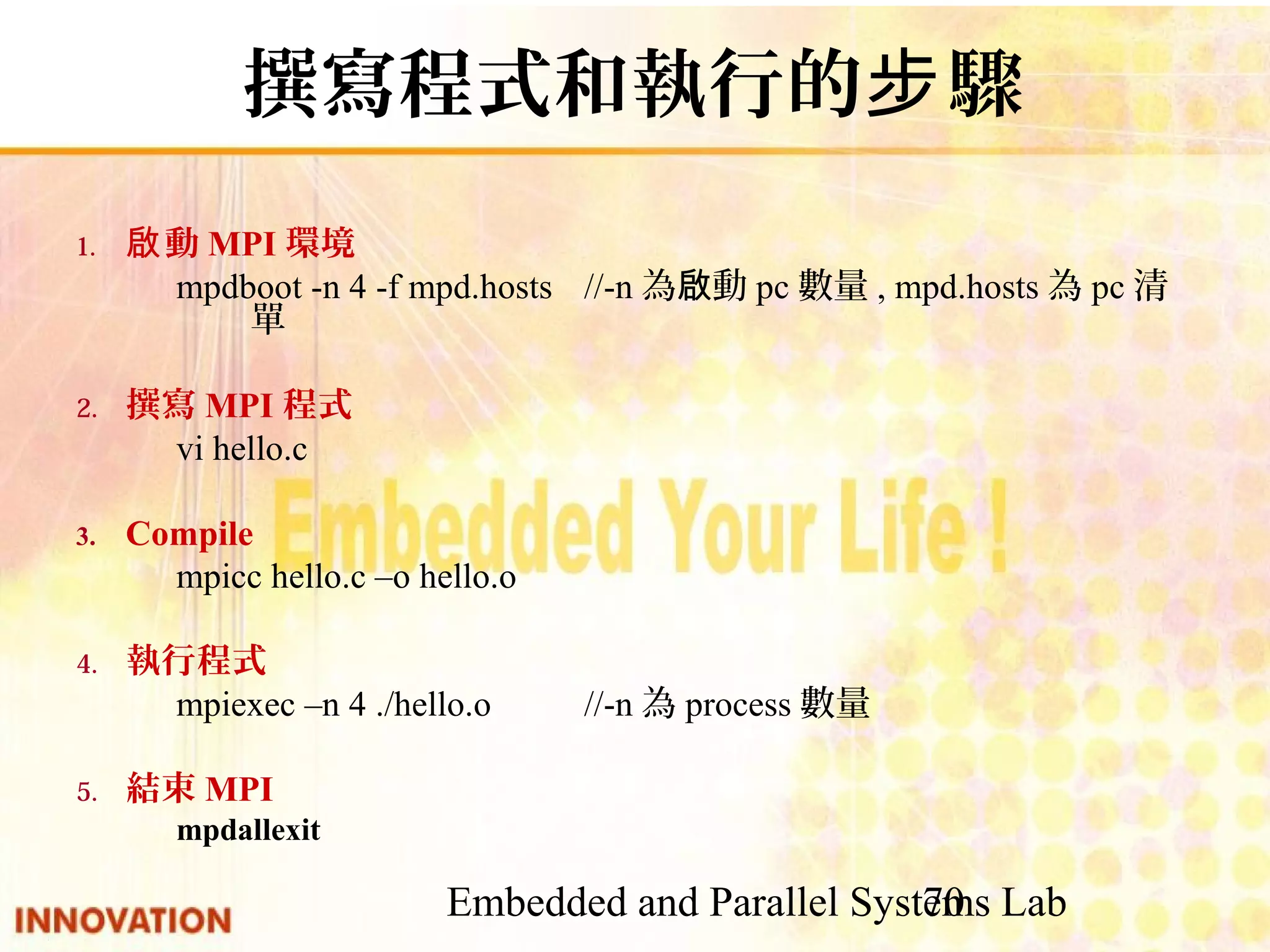
![Embedded and Parallel Systems Lab 71 MPI example : hello.c #include "mpi.h" #include <stdio.h> #define SIZE 20 int main(int argc,char *argv[]) { int numtasks, rank, dest, source, rc, count, tag=1; char inmsg[SIZE]; char outmsg[SIZE]; double starttime, endtime; MPI_Status Stat; MPI_Datatype strtype; MPI_Init(&argc,&argv); //起始MPI環境 MPI_Comm_rank(MPI_COMM_WORLD, &rank); //取得自己的process ID MPI_Type_contiguous(SIZE, MPI_CHAR, &strtype); //設定新的資料型態string MPI_Type_commit(&strtype); //建立新的資料型態string starttune=MPI_Wtime(); //取得目前時間](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-71-2048.jpg)








![Embedded and Parallel Systems Lab 83 MPI example : matrix.c(1) #include <mpi.h> #include <stdio.h> #include <stdlib.h> #define RANDOM_SEED 2882 //random seed #define MATRIX_SIZE 800 //sequare matrix width the same to height #define NODES 4//this is numbers of nodes. minimum is 1. don't use < 1 #define TOTAL_SIZE (MATRIX_SIZE * MATRIX_SIZE)//total size of MATRIX #define CHECK int main(int argc, char *argv[]){ int i,j,k; int node_id; int AA[MATRIX_SIZE][MATRIX_SIZE]; int BB[MATRIX_SIZE][MATRIX_SIZE]; int CC[MATRIX_SIZE][MATRIX_SIZE];](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-83-2048.jpg)
![Embedded and Parallel Systems Lab 84 MPI example : matrix.c(2) #ifdef CHECK int _CC[MATRIX_SIZE][MATRIX_SIZE]; //sequence user, use to check the parallel result CC #endif int check = 1; int print = 0; int computing = 0; double time,seqtime; int numtasks; int tag=1; int node_size; MPI_Status stat; MPI_Datatype rowtype; srand( RANDOM_SEED );](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-84-2048.jpg)

![Embedded and Parallel Systems Lab 86 MPI example : matrix.c(4) /*create matrix A and Matrix B*/ if(node_id == 0){ for( i=0 ; i<MATRIX_SIZE ; i++){ for( j=0 ; j<MATRIX_SIZE ; j++){ AA[i][j] = rand()%10; BB[i][j] = rand()%10; } } } /*send the matrix A and B to other node */ node_size = MATRIX_SIZE / NODES;](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-86-2048.jpg)
![Embedded and Parallel Systems Lab 87 MPI example : matrix.c(5) //send AA if (node_id == 0) for (i=1; i<NODES; i++) MPI_Send(&AA[i*node_size][0], node_size, rowtype, i, tag, MPI_COMM_WORLD); else MPI_Recv(&AA[node_id*node_size][0], node_size, rowtype, 0, tag, MPI_COMM_WORLD, &stat); //send BB if (node_id == 0) for (i=1; i<NODES; i++) MPI_Send(&BB, MATRIX_SIZE, rowtype, i, tag, MPI_COMM_WORLD); else MPI_Recv(&BB, MATRIX_SIZE, rowtype, 0, tag, MPI_COMM_WORLD, &stat);](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-87-2048.jpg)
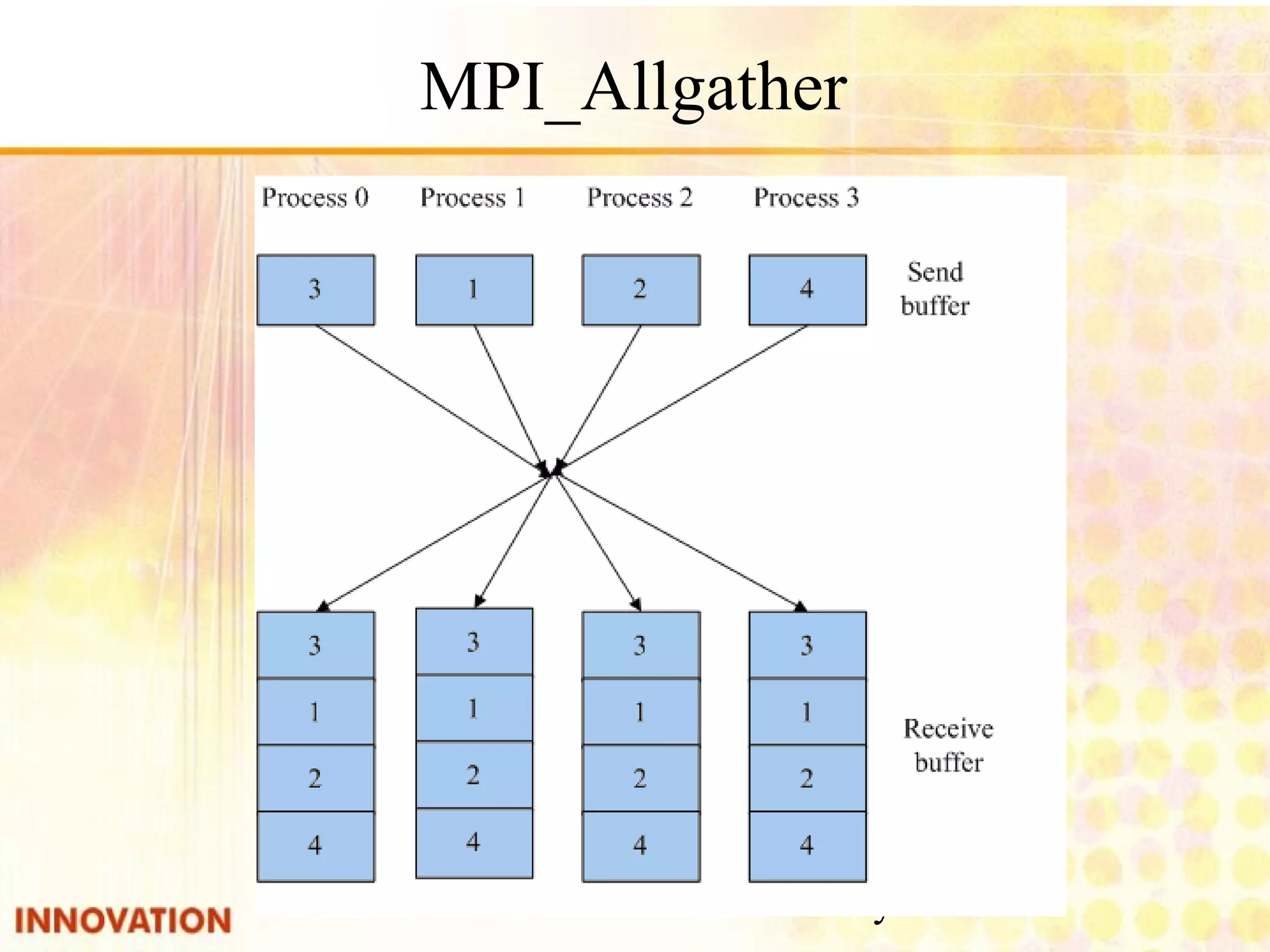
![Embedded and Parallel Systems Lab 88 MPI example : matrix.c(6) /*computing C = A * B*/ time = -MPI_Wtime(); for( i=node_id*node_size ; i<(node_id*node_size+node_size) ; i++){ for( j=0 ; j<MATRIX_SIZE ; j++){ computing = 0; for( k=0 ; k<MATRIX_SIZE ; k++) computing += AA[i][k] * BB[k][j]; CC[i][j] = computing; } } MPI_Allgather(&CC[node_id*node_size][0], node_size, rowtype, &CC, node_size, rowtype, MPI_COMM_WORLD); time += MPI_Wtime();](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-88-2048.jpg)
![Embedded and Parallel Systems Lab 89 MPI example : matrix.c(7) #ifdef CHECK seqtime = -MPI_Wtime(); if(node_id == 0){ for( i=0 ; i<MATRIX_SIZE ; i++){ for( j=0 ; j<MATRIX_SIZE ; j++){ computing = 0; for( k=0 ; k<MATRIX_SIZE ; k++) computing += AA[i][k] * BB[k][j]; _CC[i][j] = computing; } } } seqtime += MPI_Wtime();](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-89-2048.jpg)
![Embedded and Parallel Systems Lab 90 /* check result */ if(node_id == 0){ for( i=0 ; i<MATRIX_SIZE; i++){ for( j=0 ; j<MATRIX_SIZE ; j++){ if( CC[i][j] != _CC[i][j]){ check = 0; break; } } } }](https://image.slidesharecdn.com/parallelprogramdesignv1-140808100052-phpapp02/75/Parallel-program-design-90-2048.jpg)









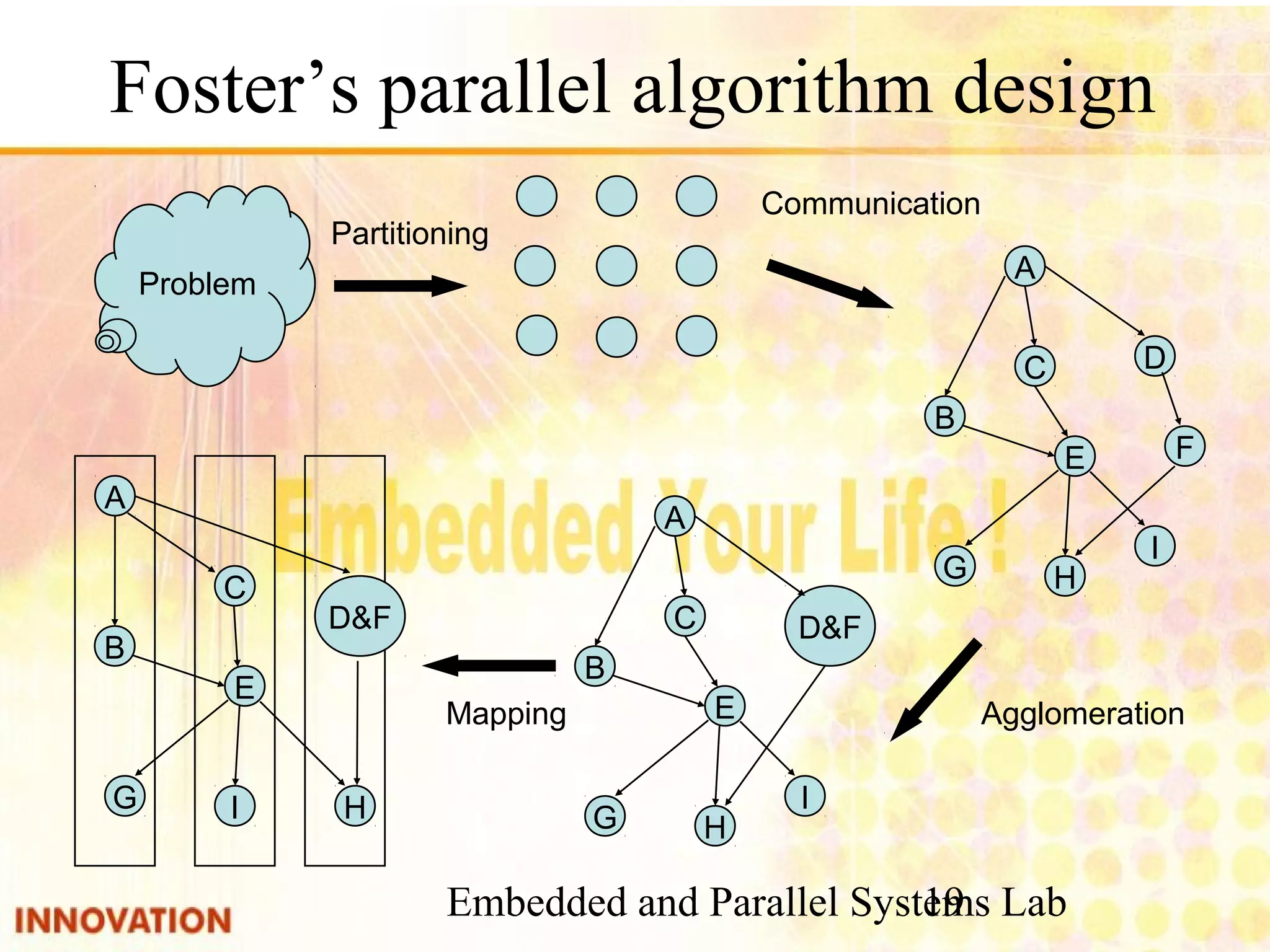
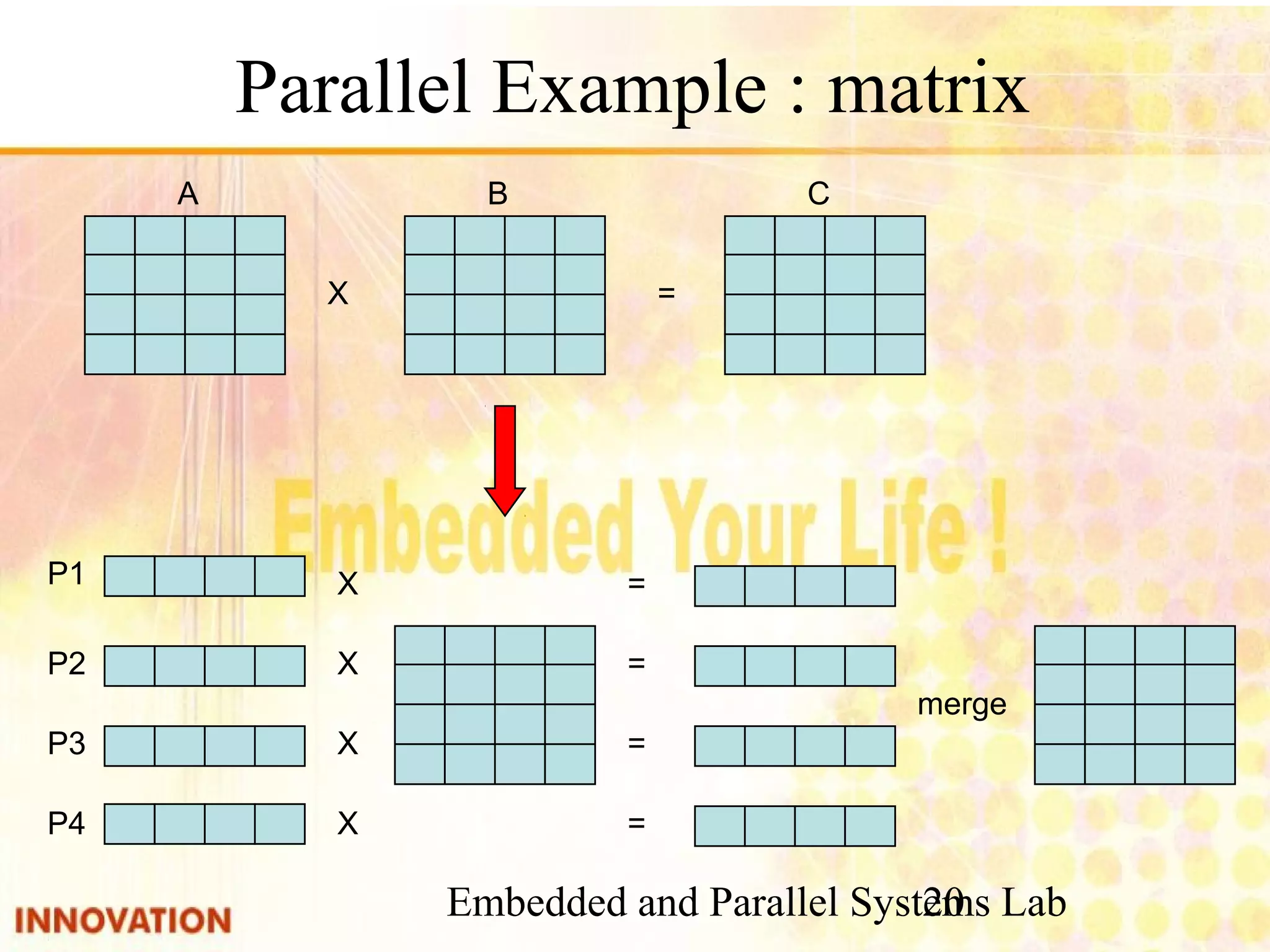
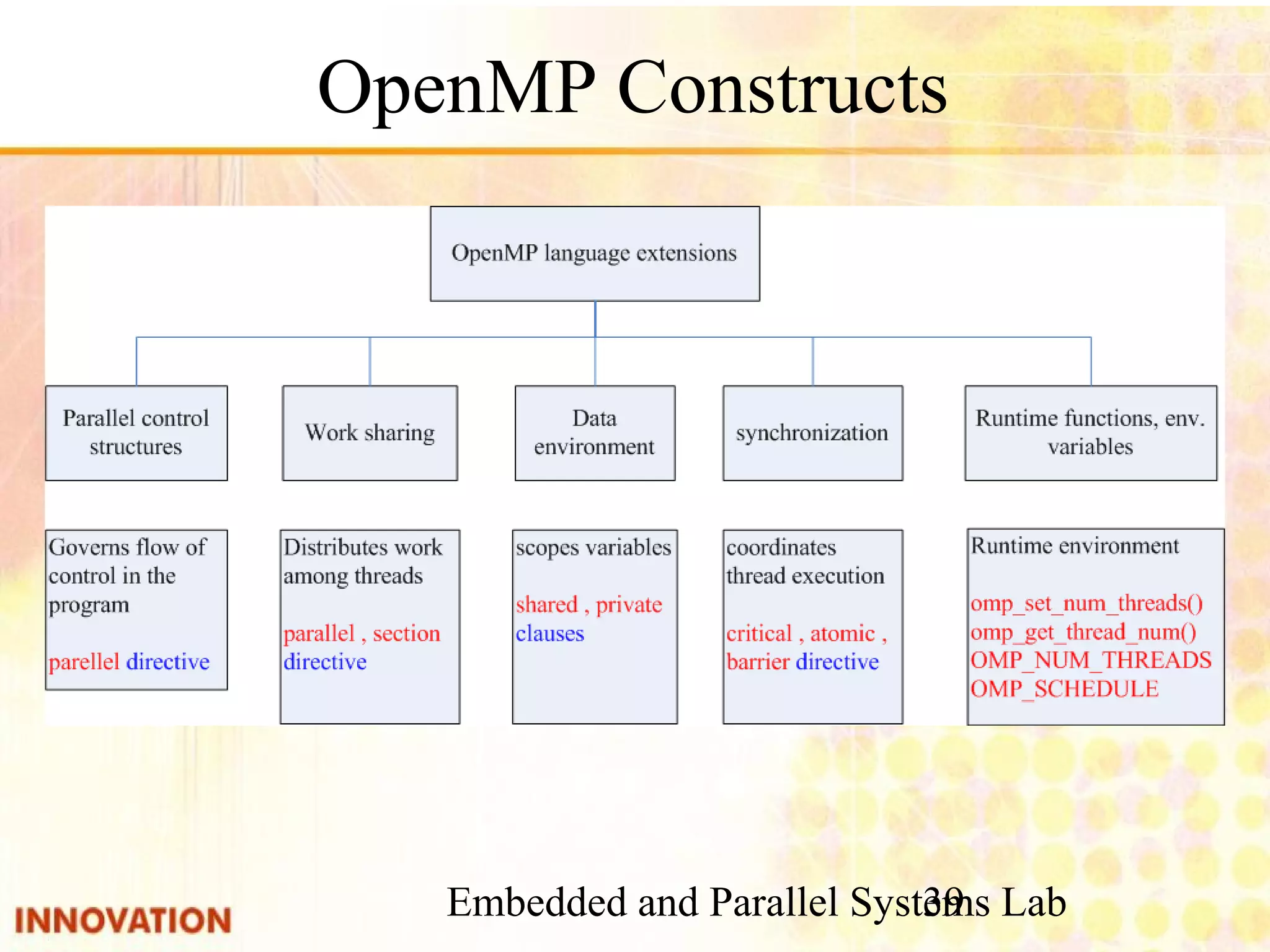
The document discusses parallel program design and parallel programming techniques. It introduces parallel algorithm design based on four steps: partitioning, communication, agglomeration, and mapping. It also covers parallel programming tools including pthreads, OpenMP, and MPI. Common parallel constructs like private, shared, barrier, and reduction are explained. Examples of parallel programs using pthreads and OpenMP are provided.
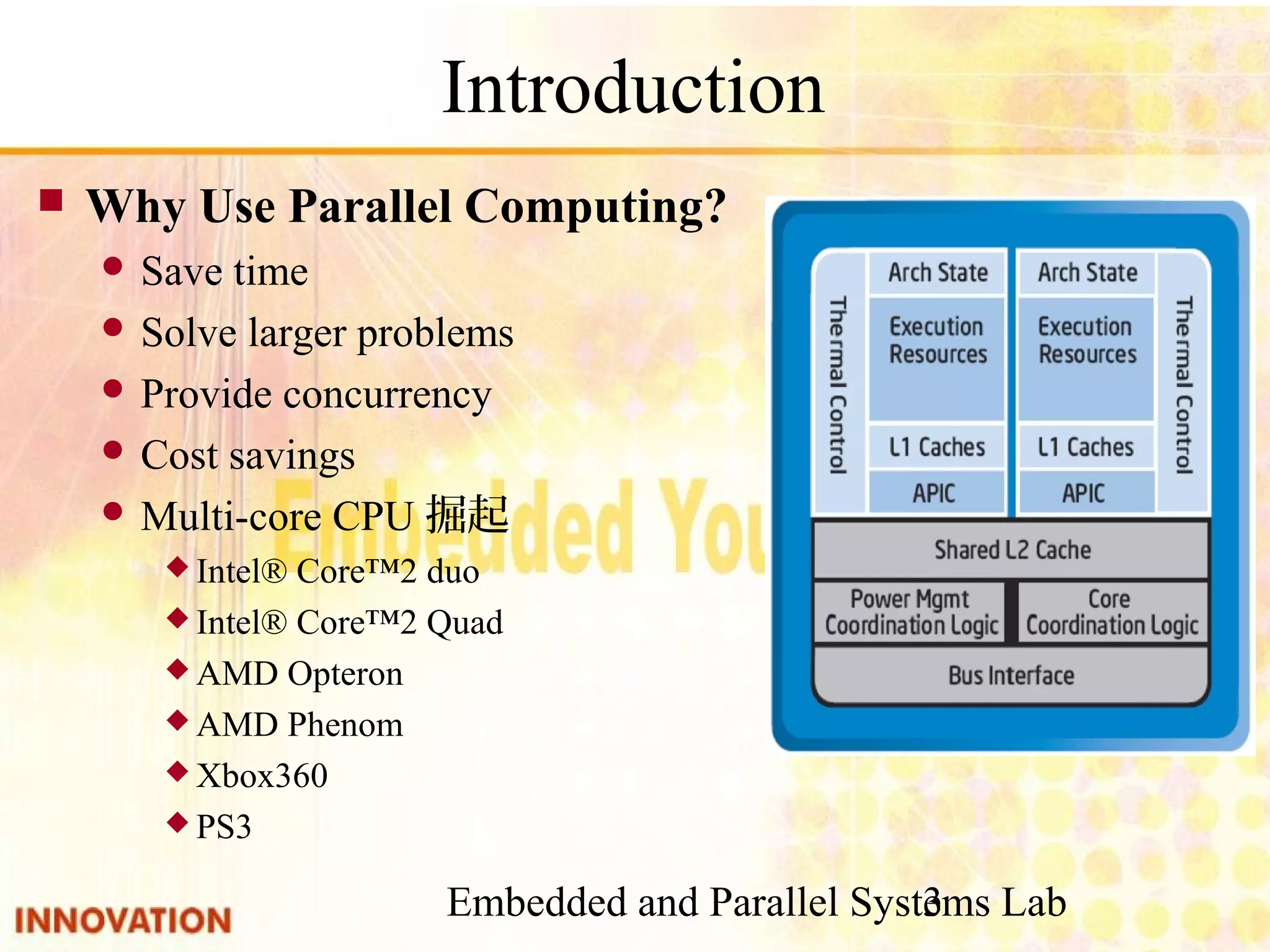
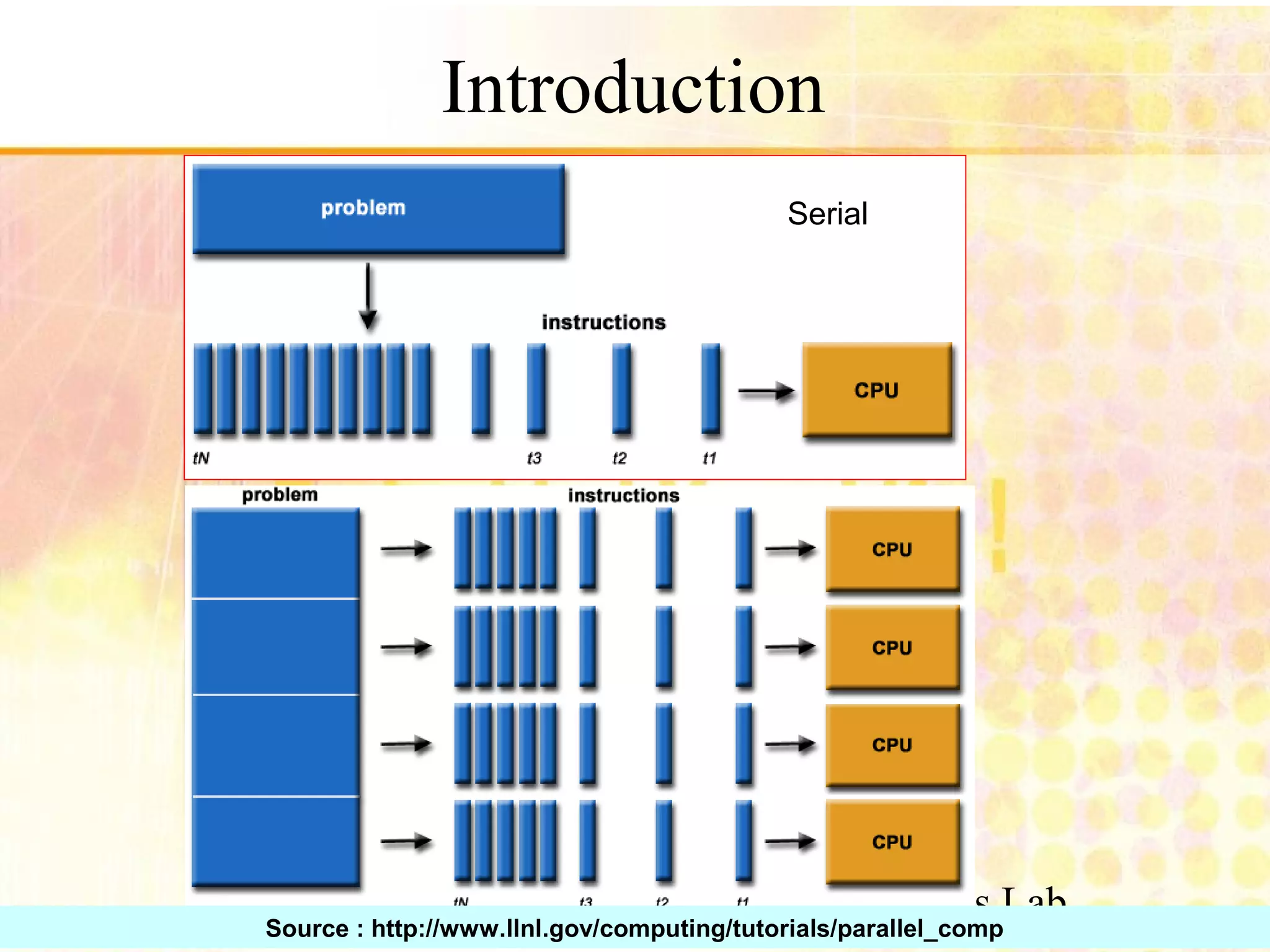
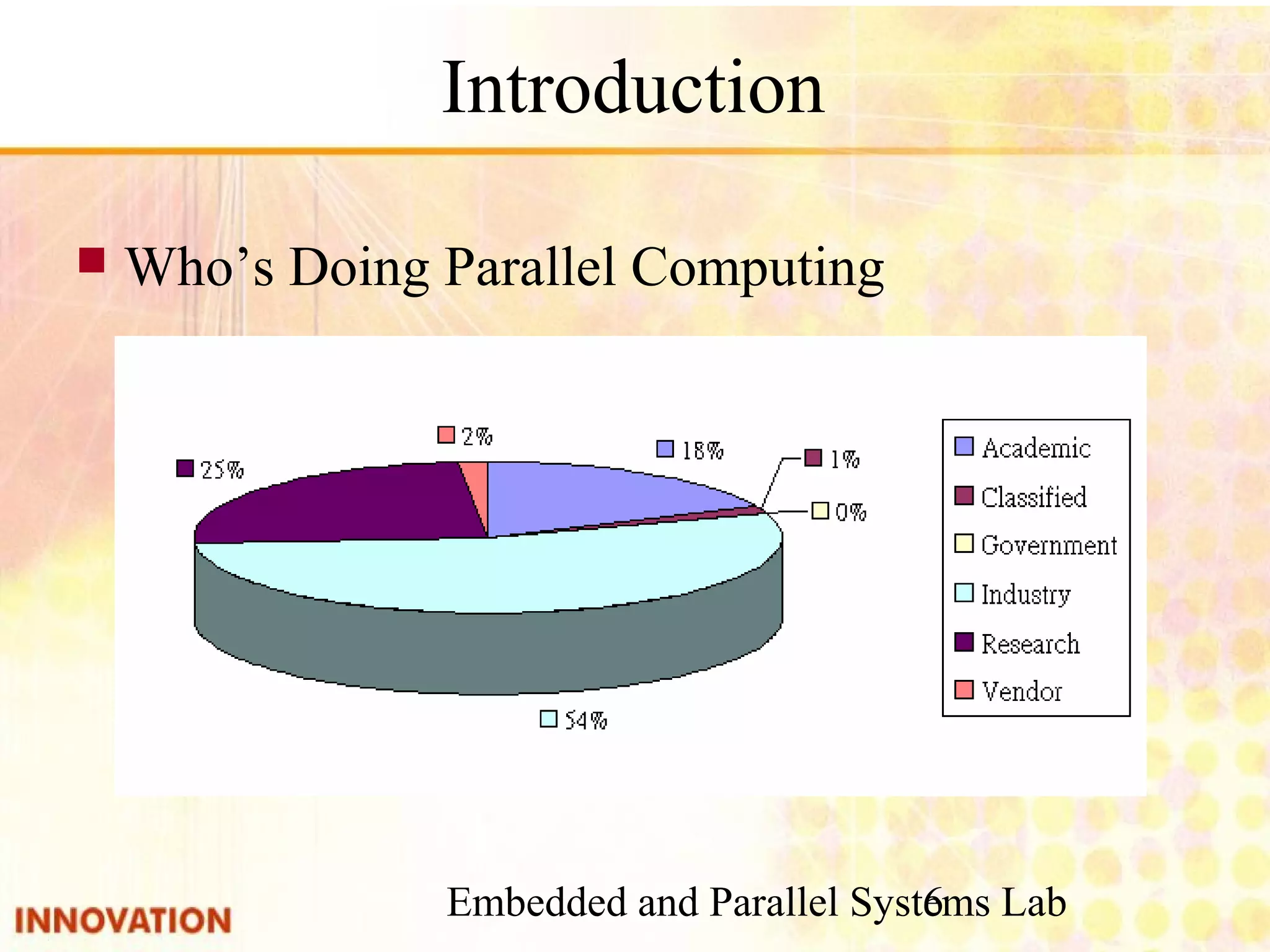
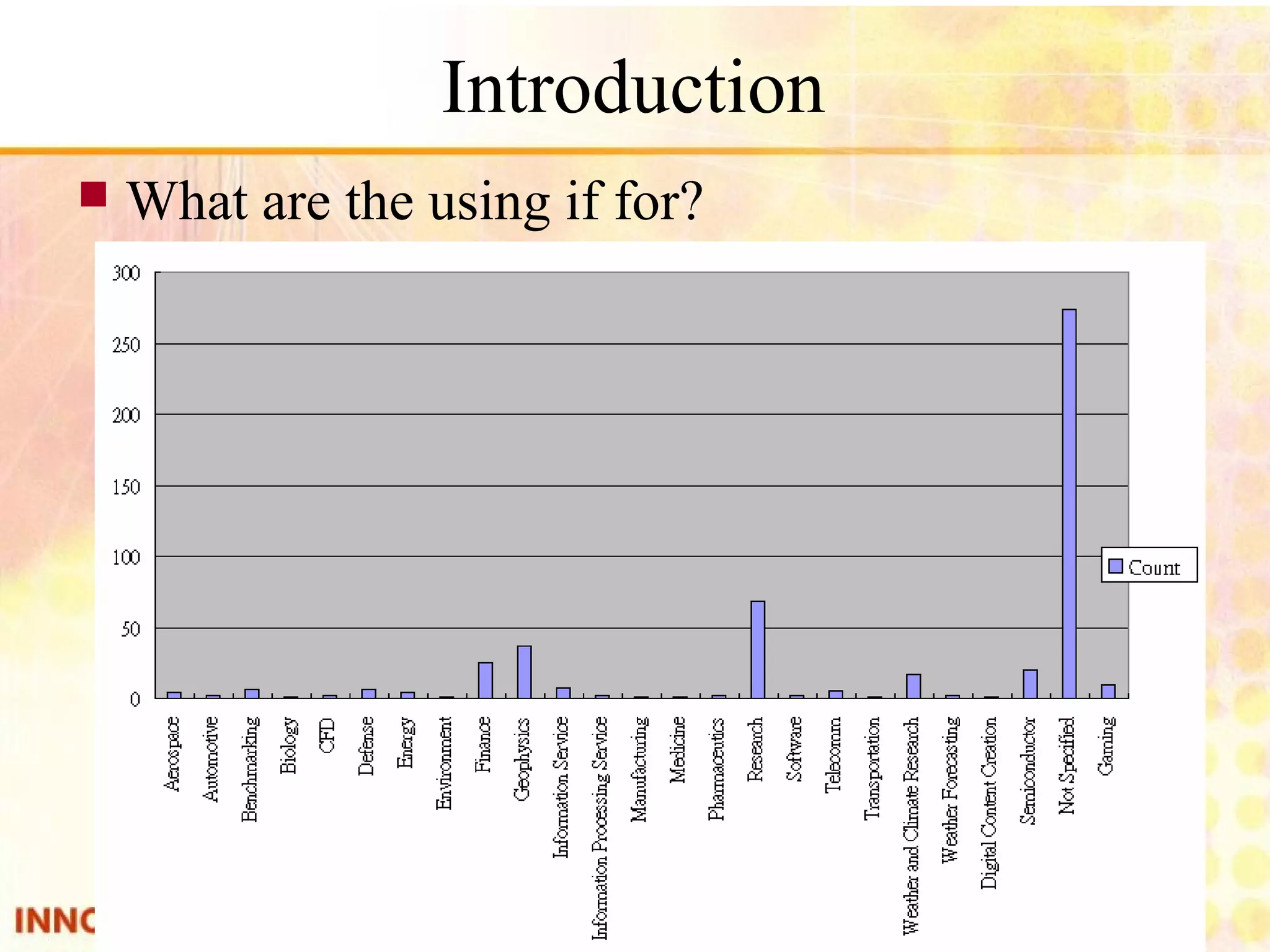
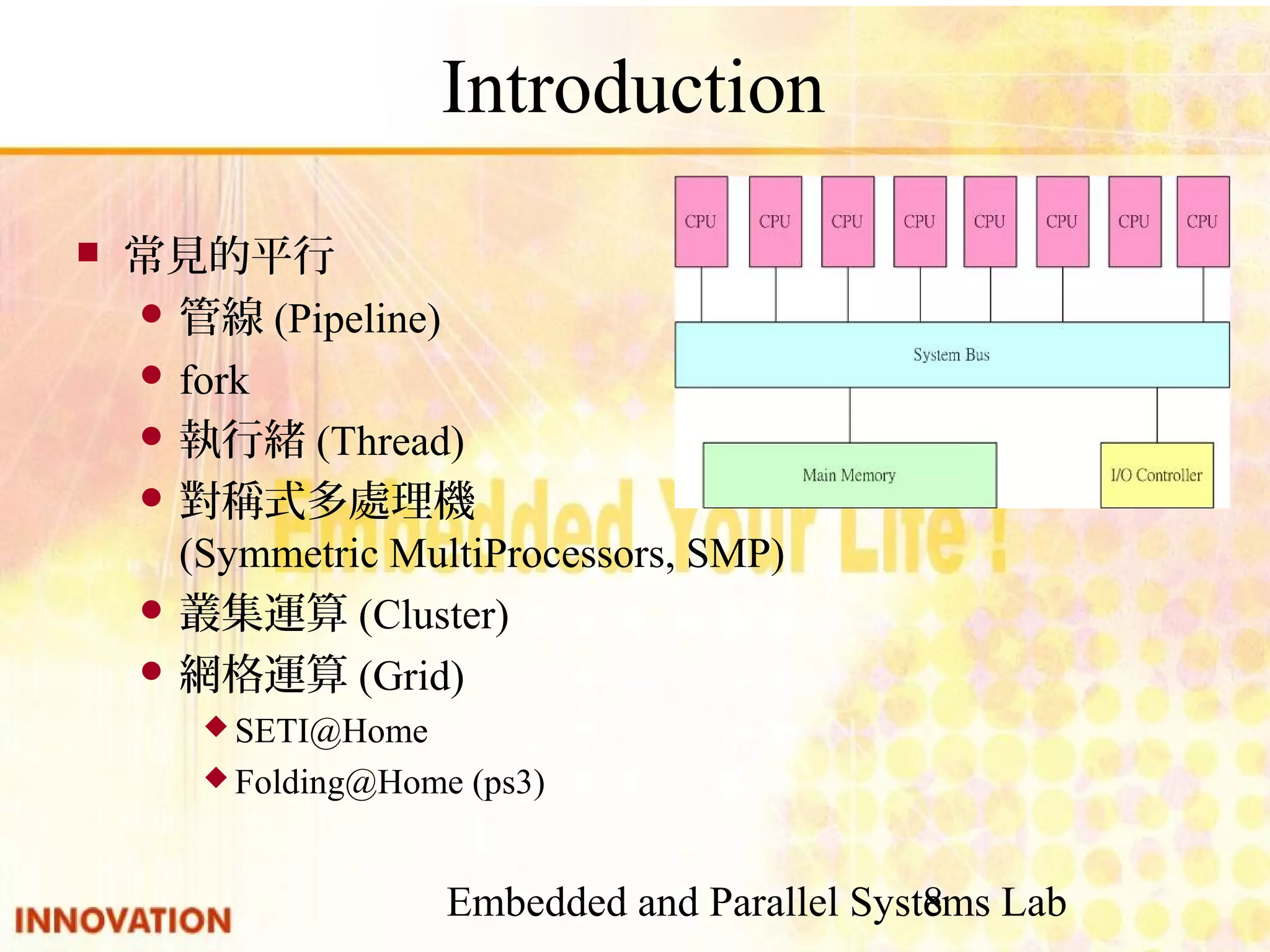
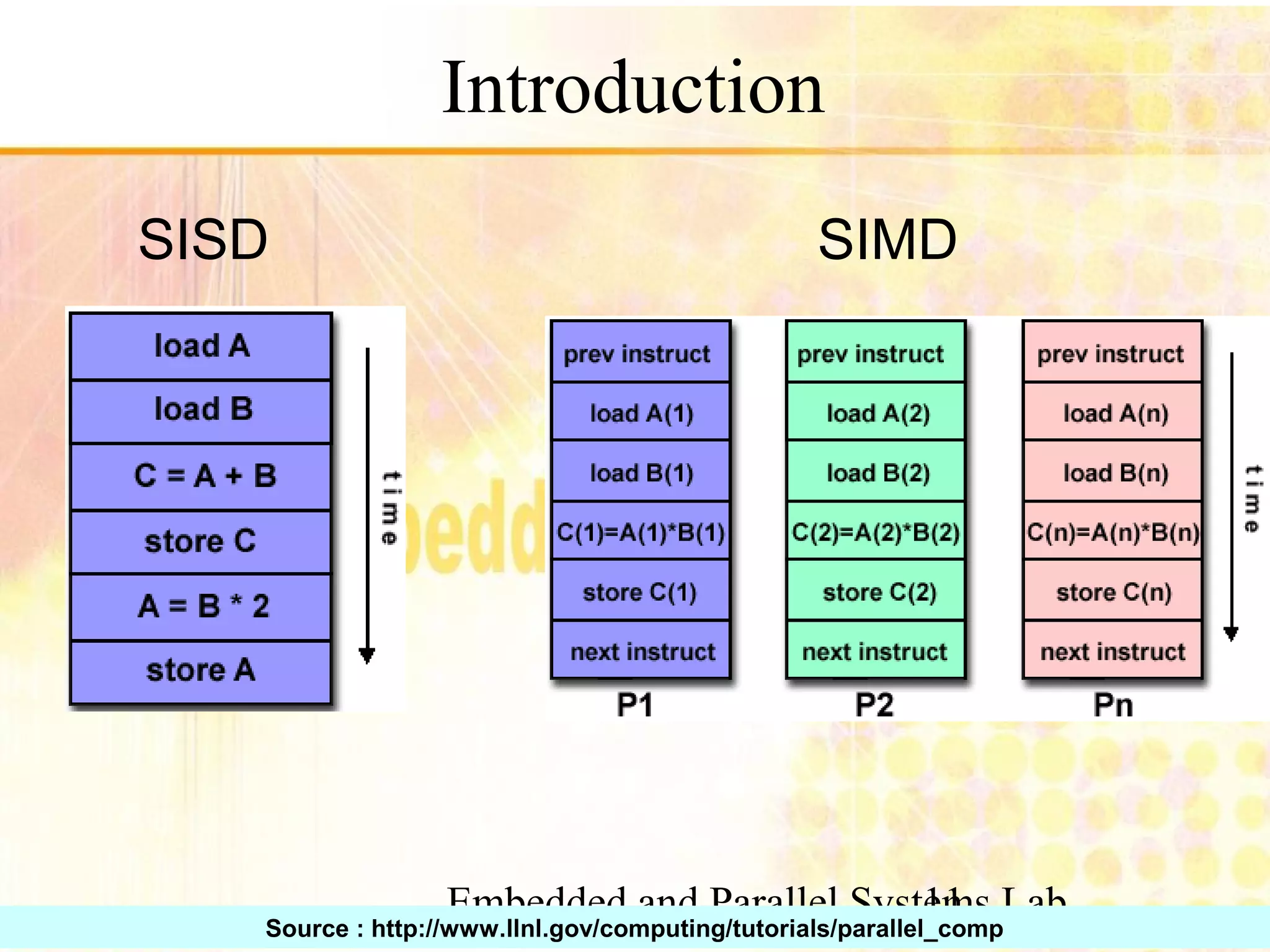
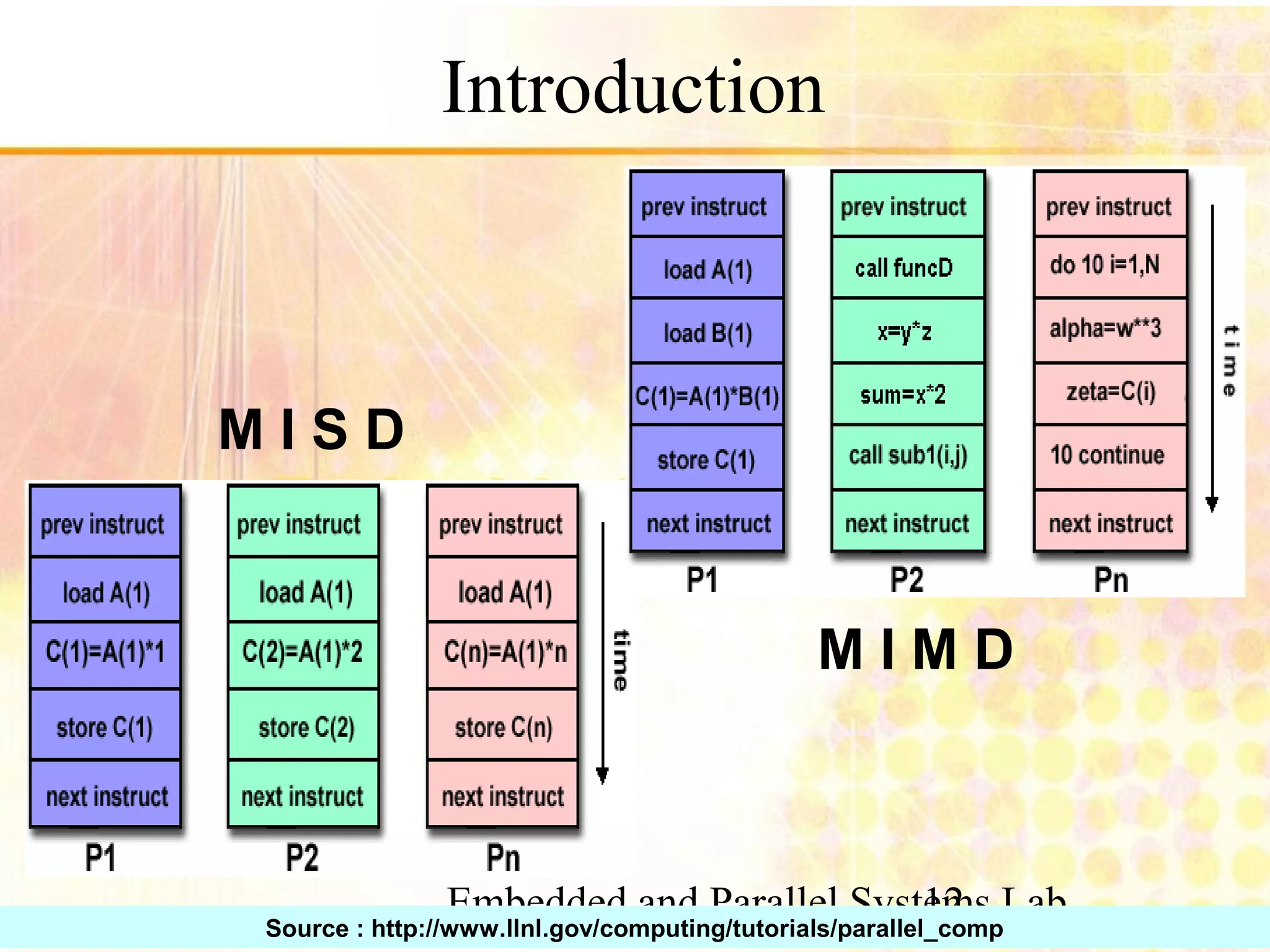
Overview of parallel computing, benefits, and common types. Mention of multi-core CPUs and usage scenarios.
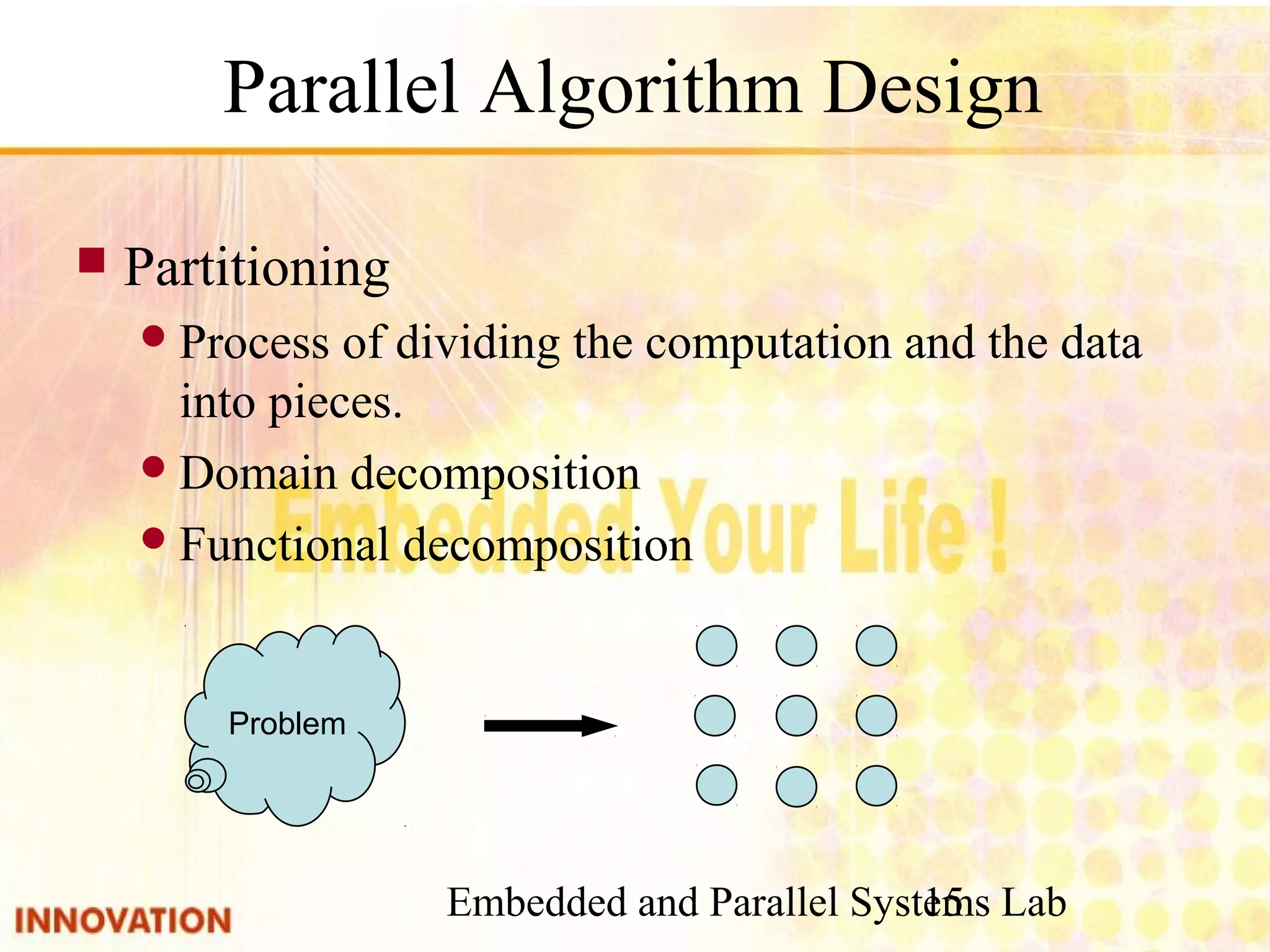
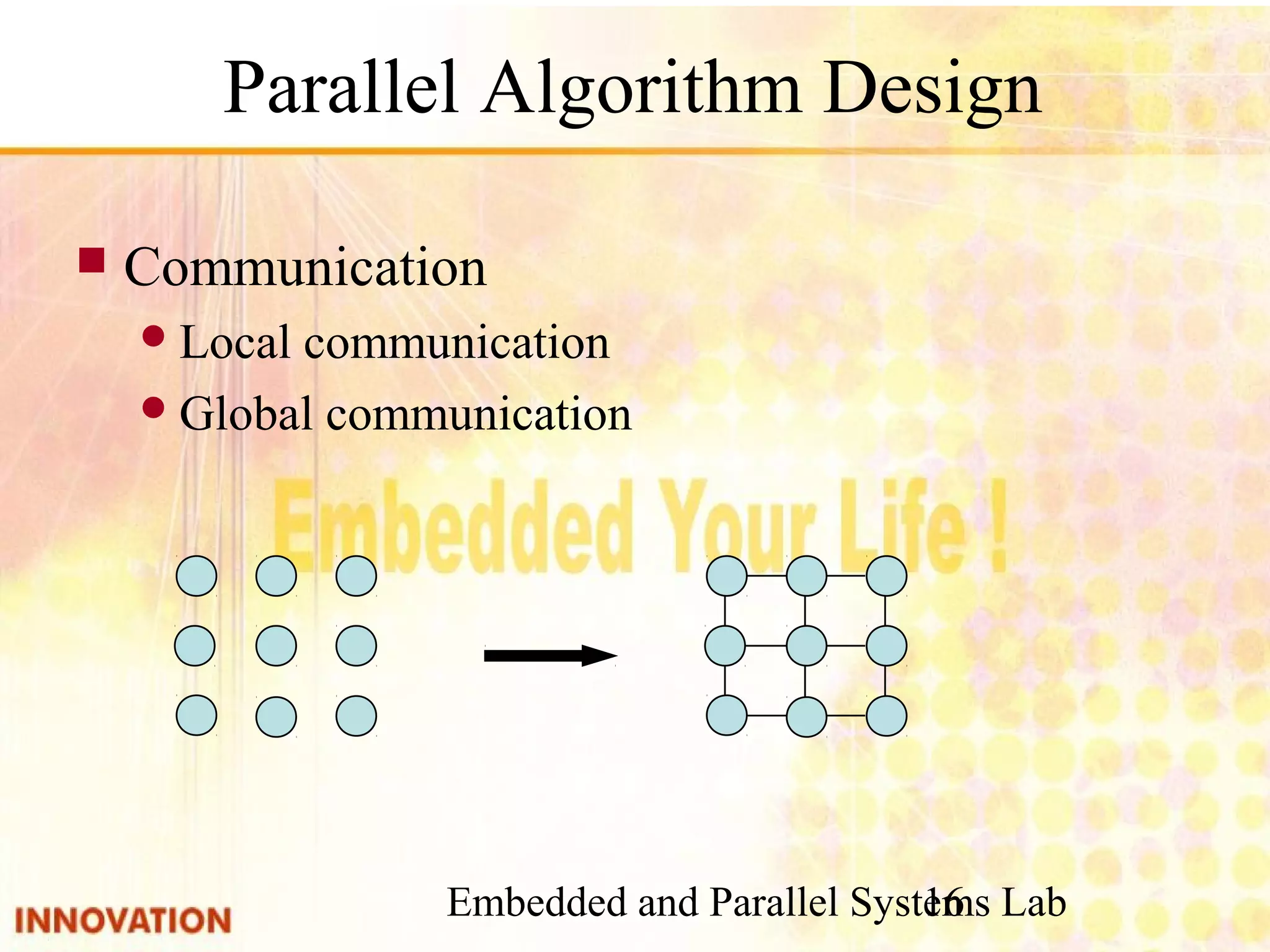
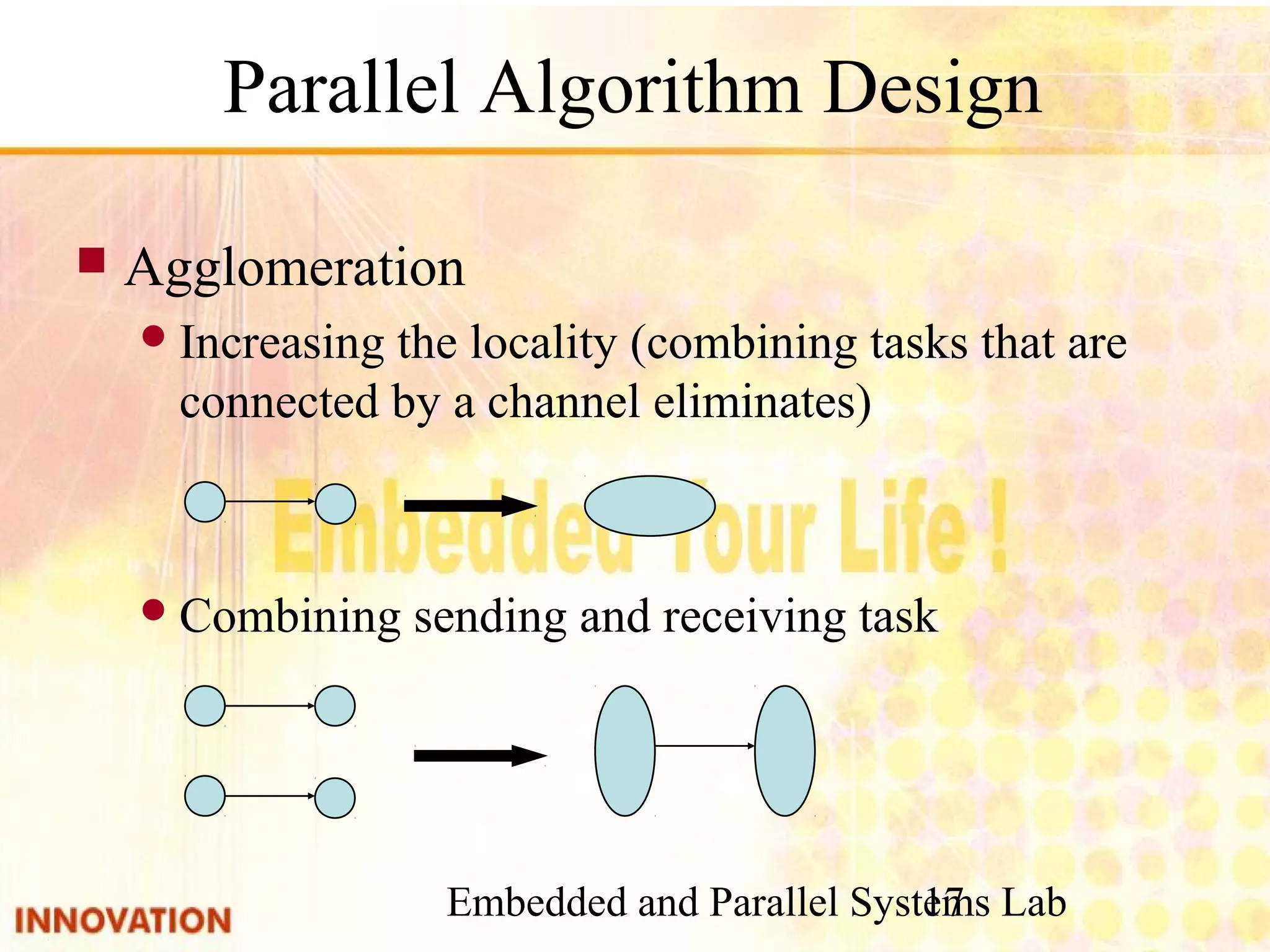
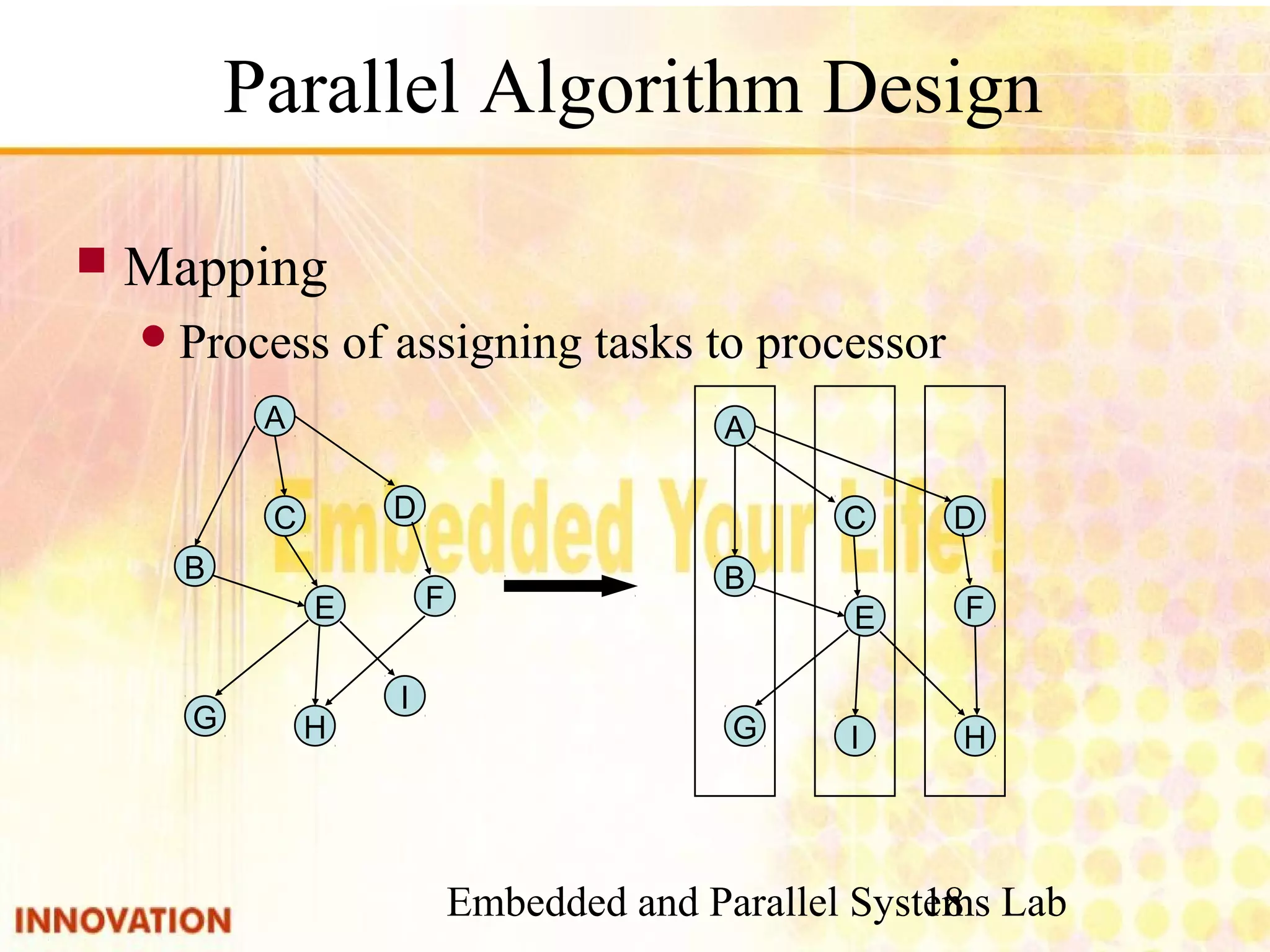
Steps for designing parallel algorithms including partitioning, communication, agglomeration, and mapping.
Discussion on threads, pthread, and how they differ from processes in programming.
Explanation of OpenMP directives, clauses, and work-sharing constructs.
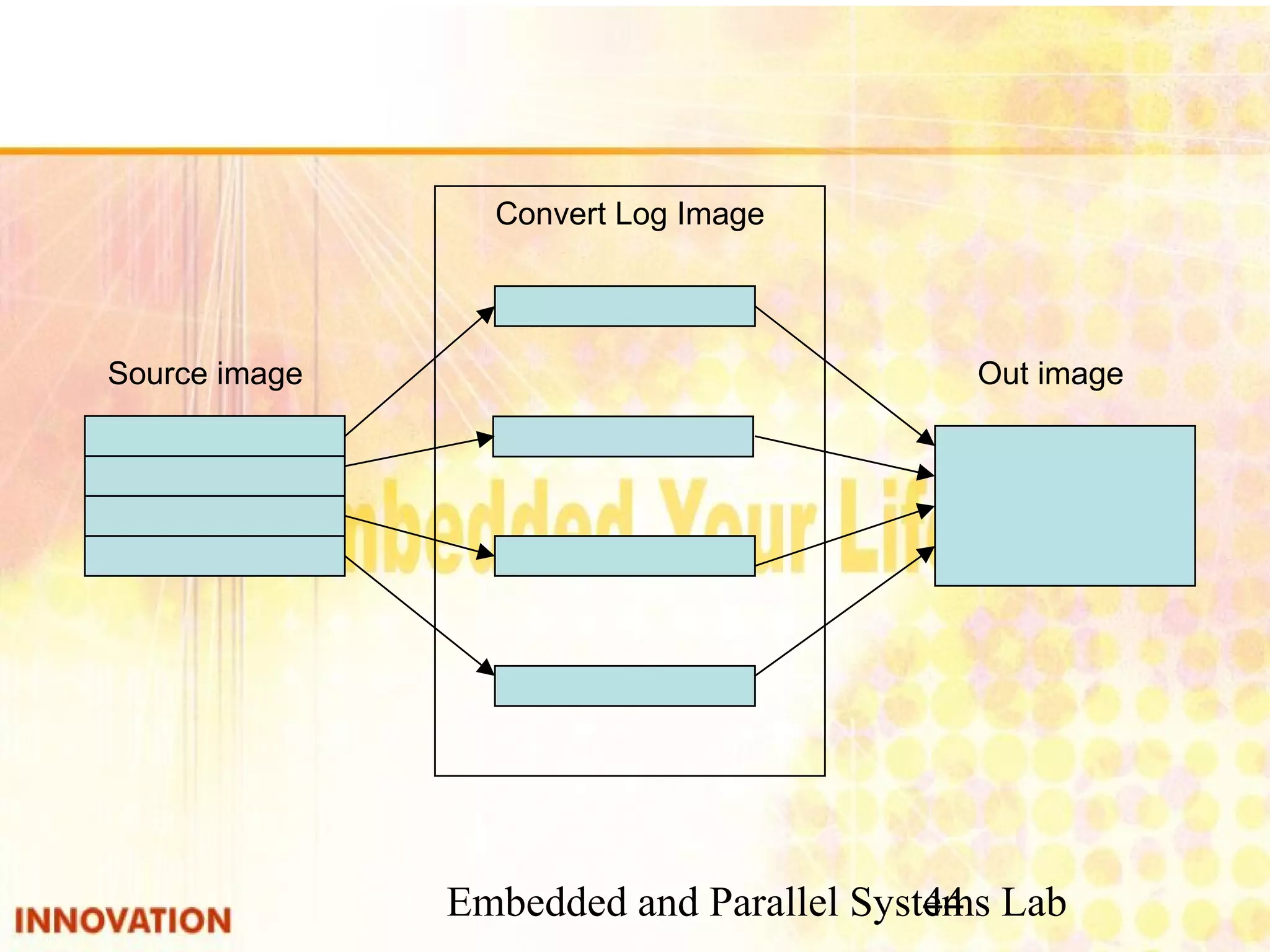
Implementation examples of OpenMP in image processing and matrix multiplication.
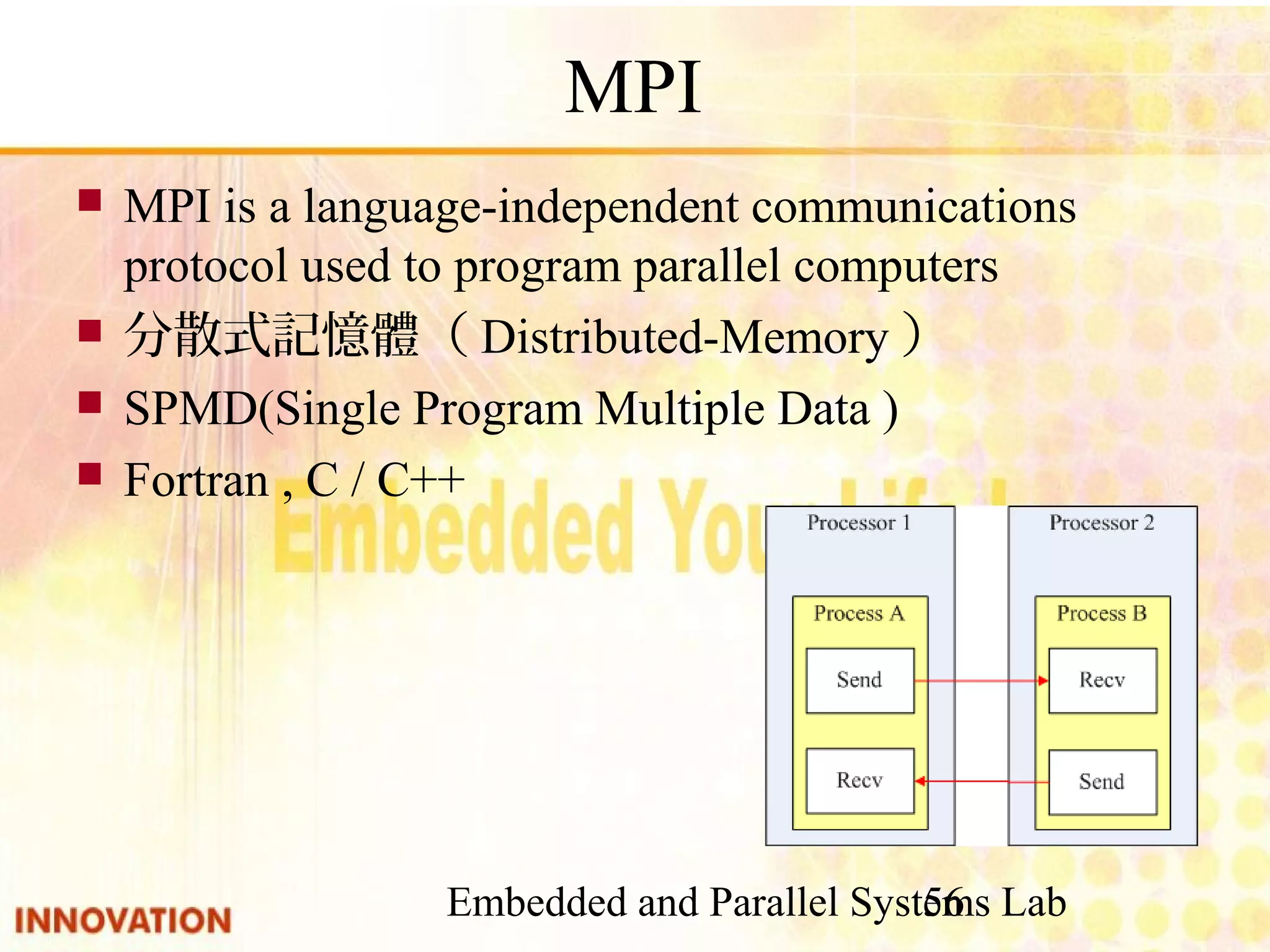
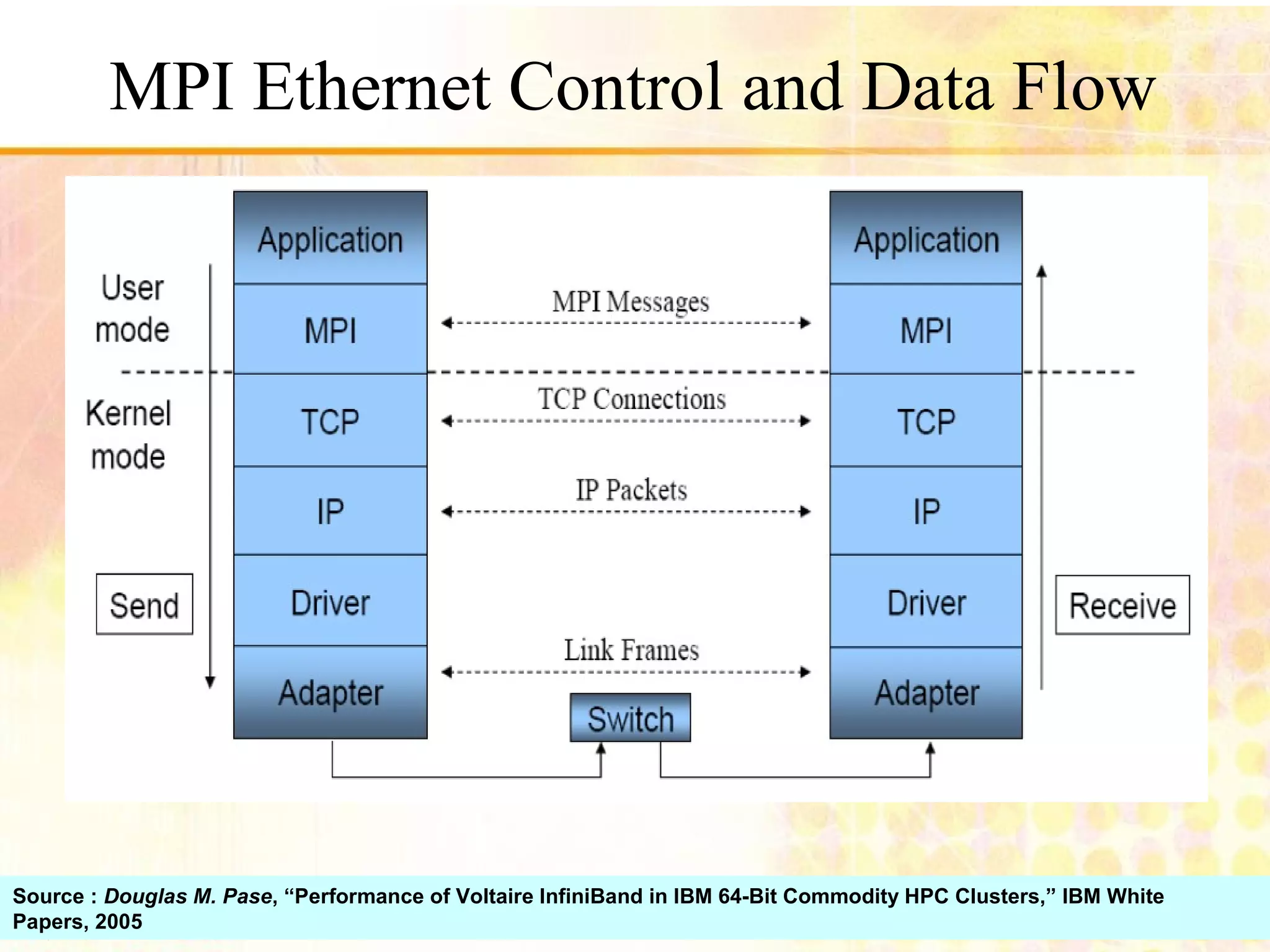
Introduction to MPI (Message Passing Interface), its features and setup requirements.
Description of basic MPI functions, their usage in sending and receiving messages.
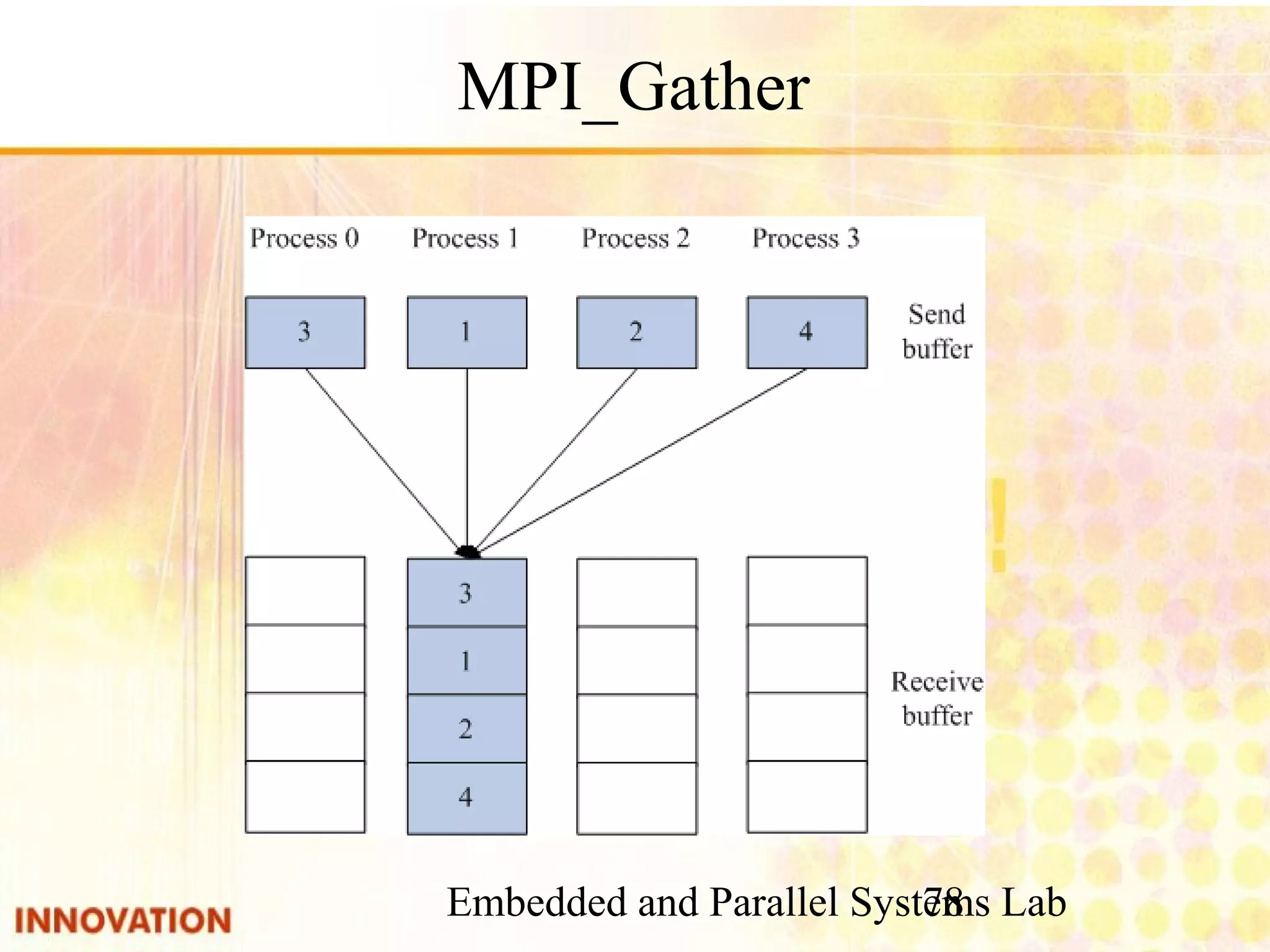
Explanation of collective operations in MPI such as MPI_Bcast, MPI_Gather, and MPI_Reduce.
Detailed example of matrix multiplication using MPI, including setup and communication.
Challenges in parallel algorithm development, introduction of new programming languages for parallelism.
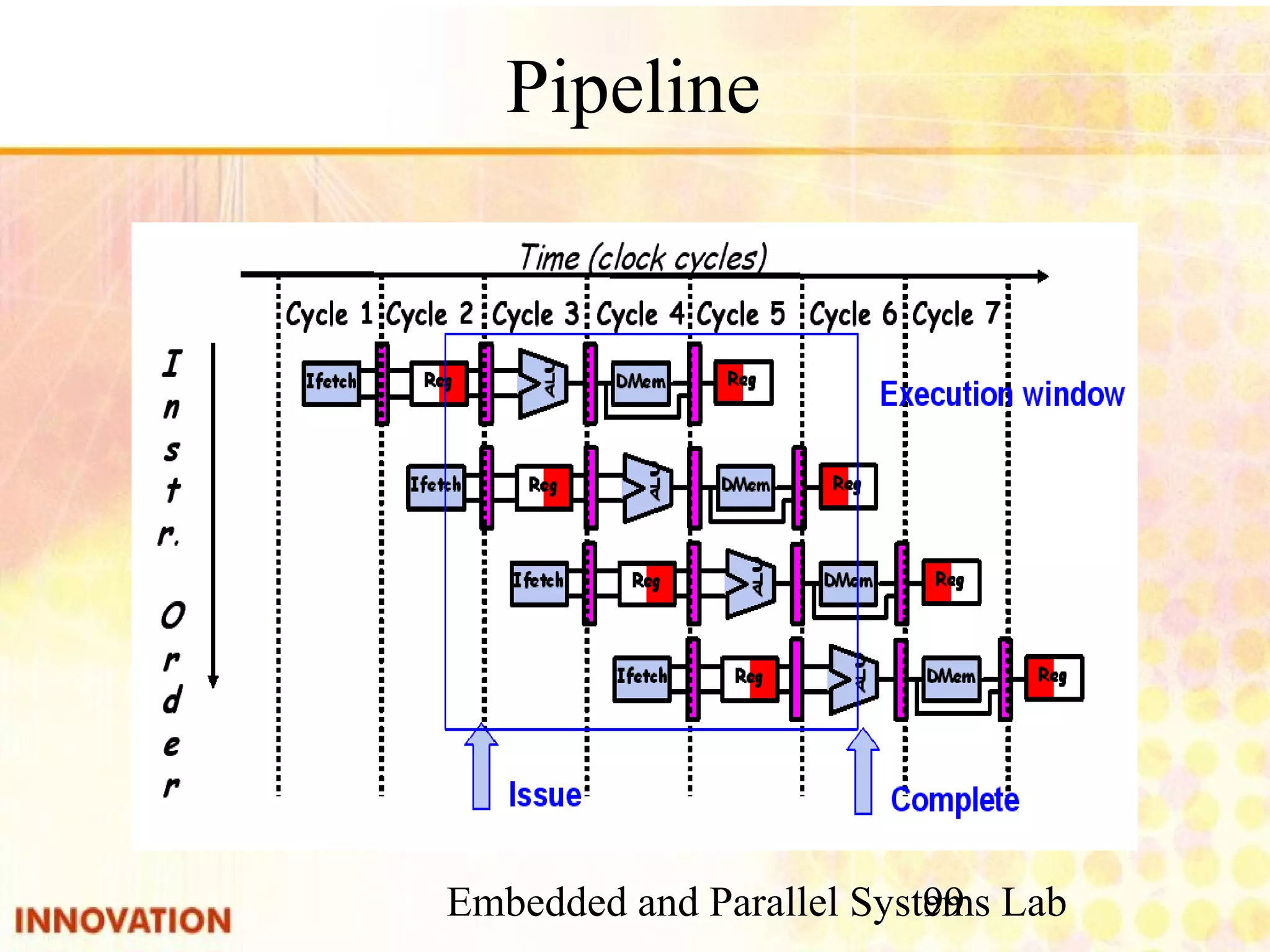
Definition and application of pipeline in parallel computing.