Download as PDF, PPTX









![Model representation On the wire syntax = “proto3”; // Description of the trained model. message ModelDescriptor { // Model name string name = 1; // Human readable description. string description = 2; // Data type for which this model is applied. string dataType = 3; // Model type enum ModelType { TENSORFLOW = 0; TENSORFLOWSAVED = 2; PMML = 2; }; ModelType modeltype = 4; oneof MessageContent { // Byte array containing the model bytes data = 5; string location = 6; } } Internal
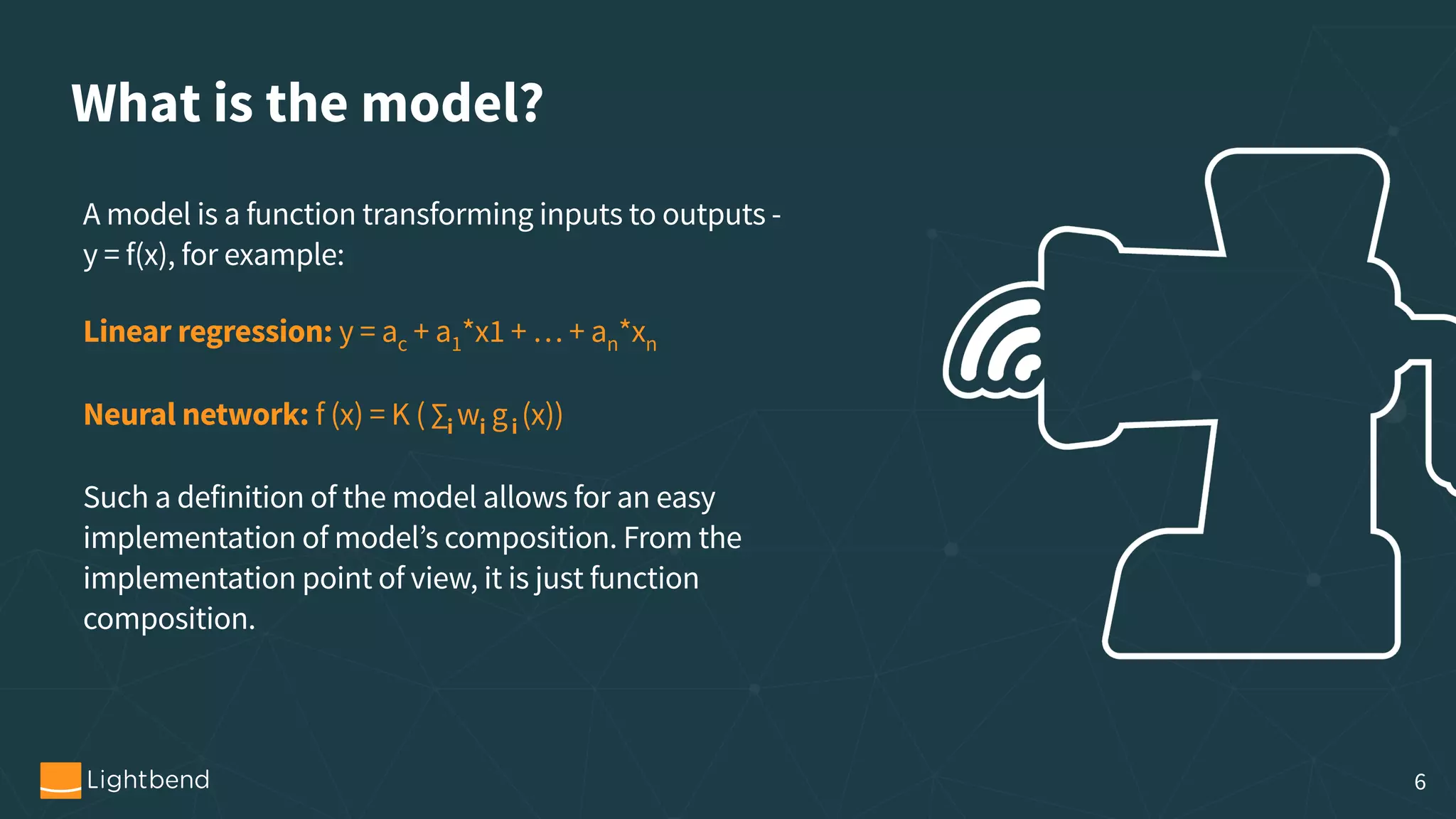
trait Model { def score(input : AnyVal) : AnyVal def cleanup() : Unit def toBytes() : Array[Byte] def getType : Long }
trait ModelFactoryl { def create(input : ModelDescriptor) : Model def restore(bytes : Array[Byte]) : Model } 17](https://image.slidesharecdn.com/operationalizingmachinelearning-servingmlmodels-180115095643/75/Operationalizing-Machine-Learning-Serving-ML-Models-17-2048.jpg)



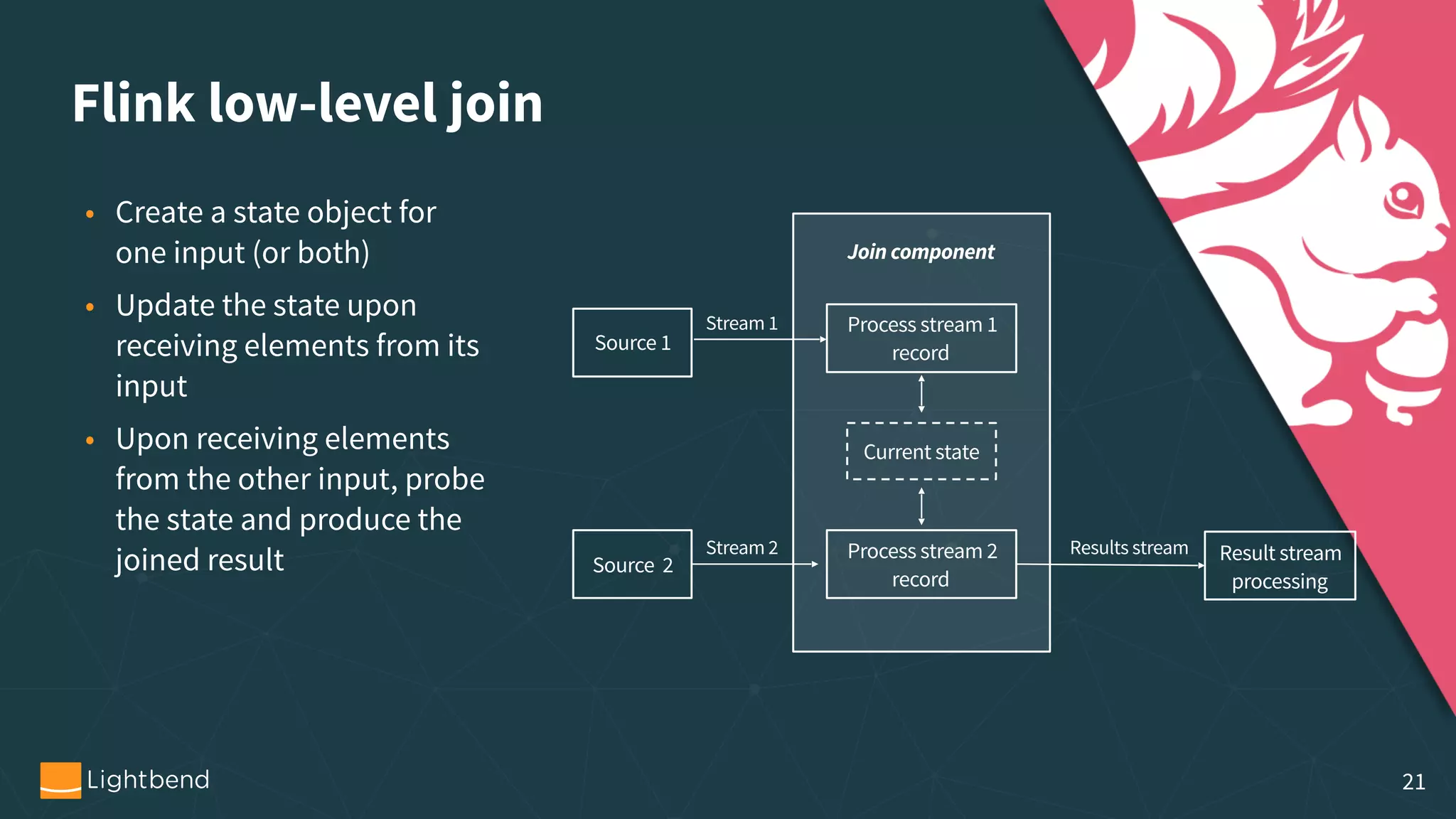
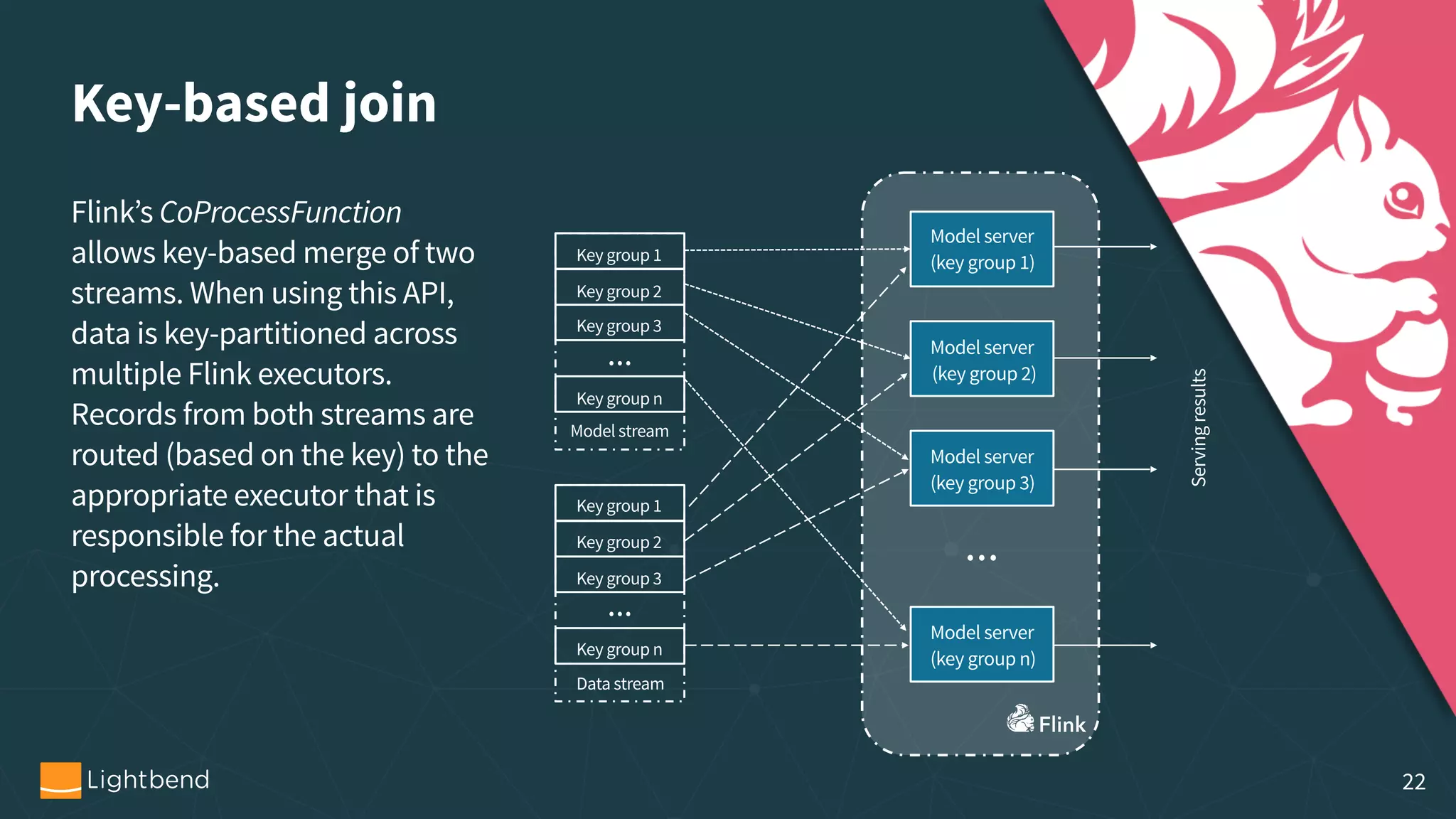
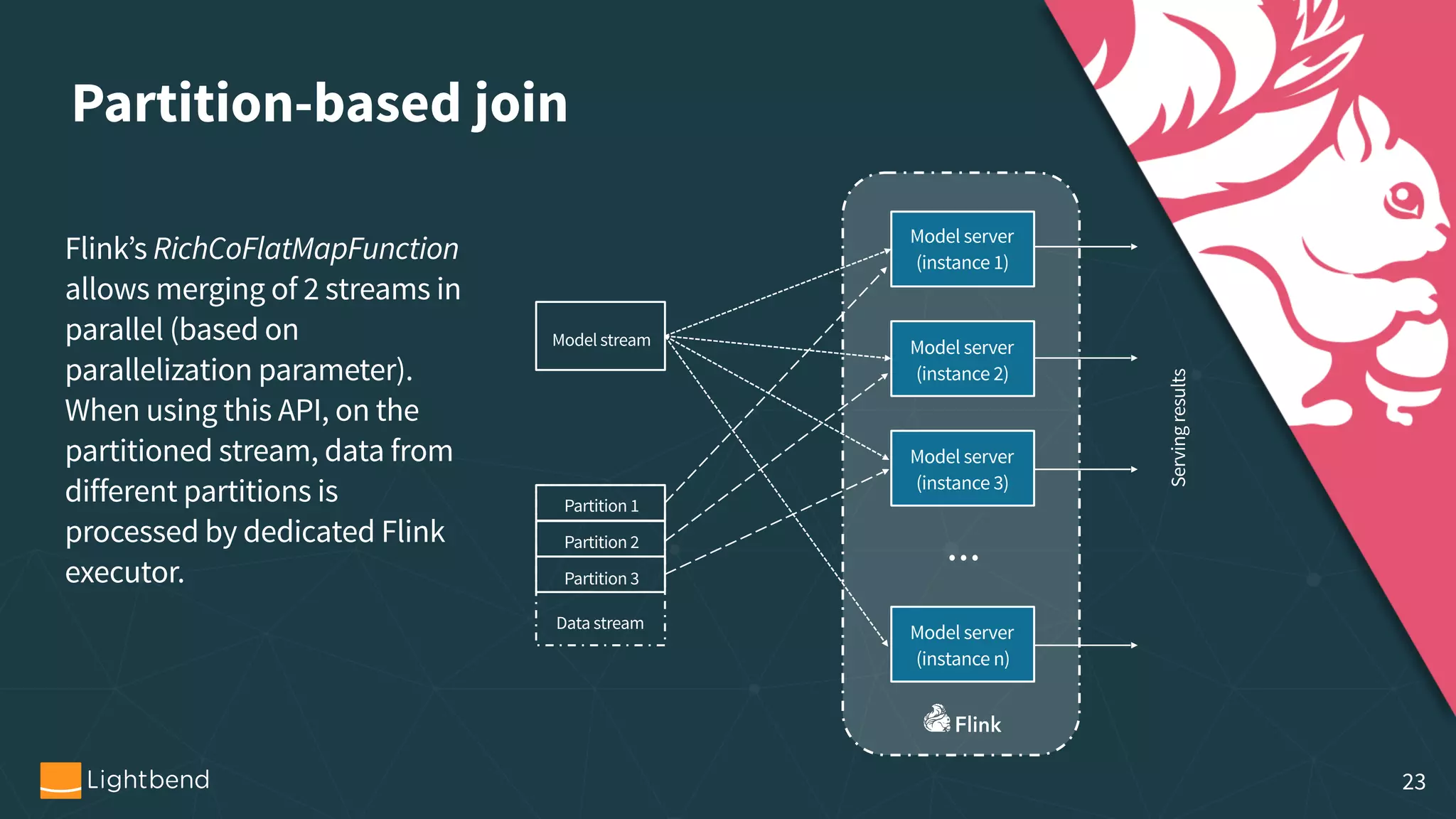

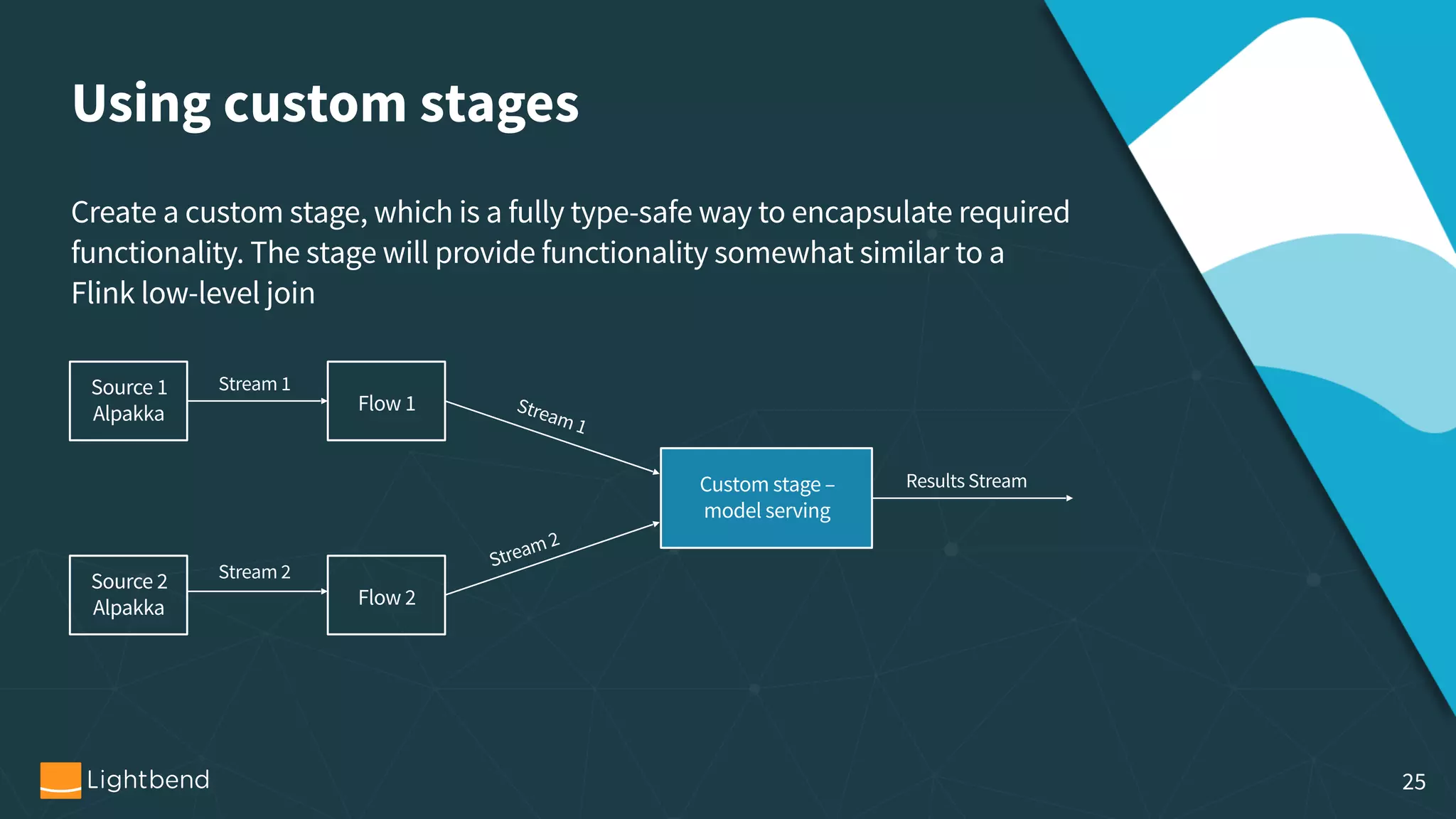
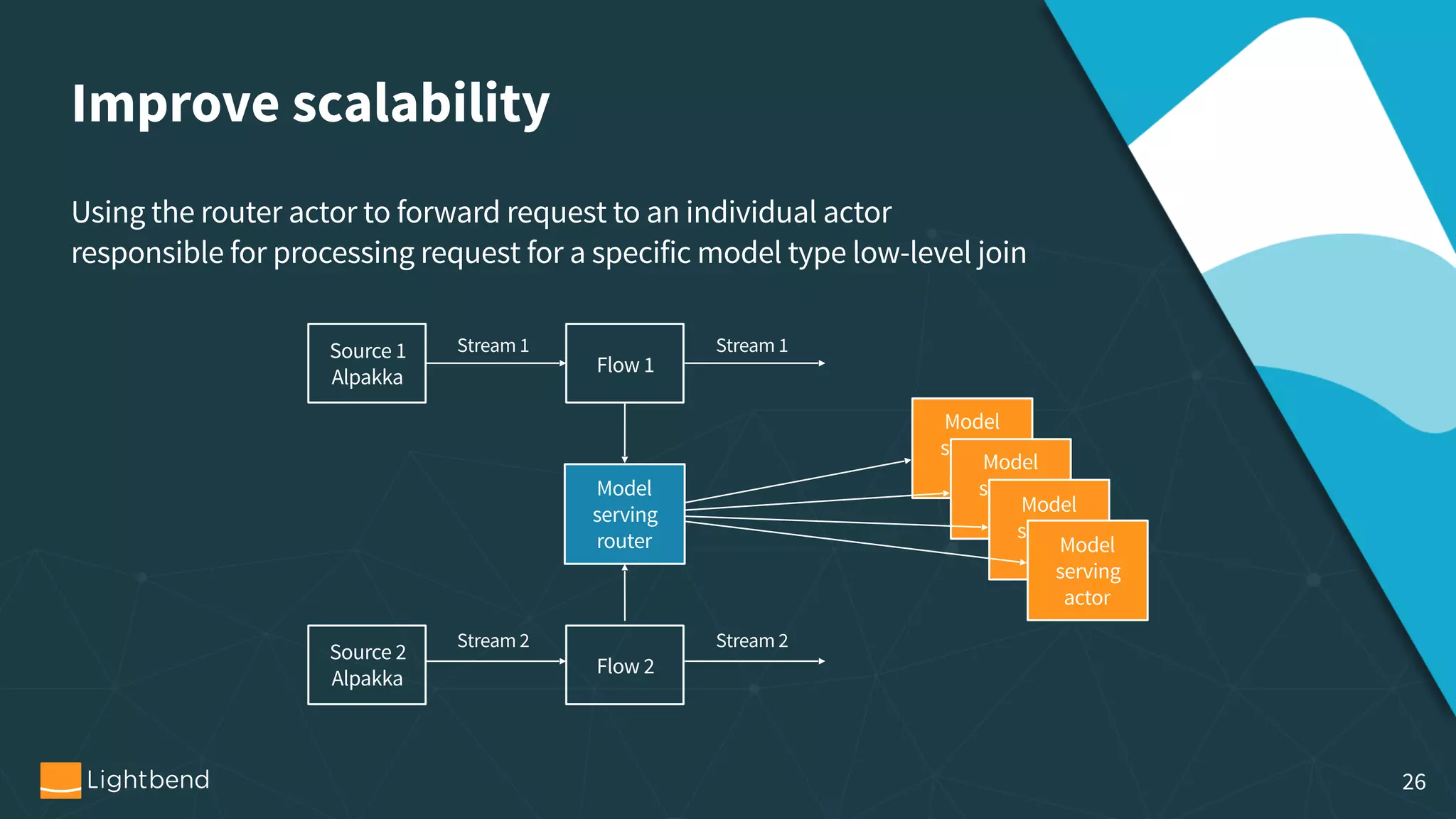
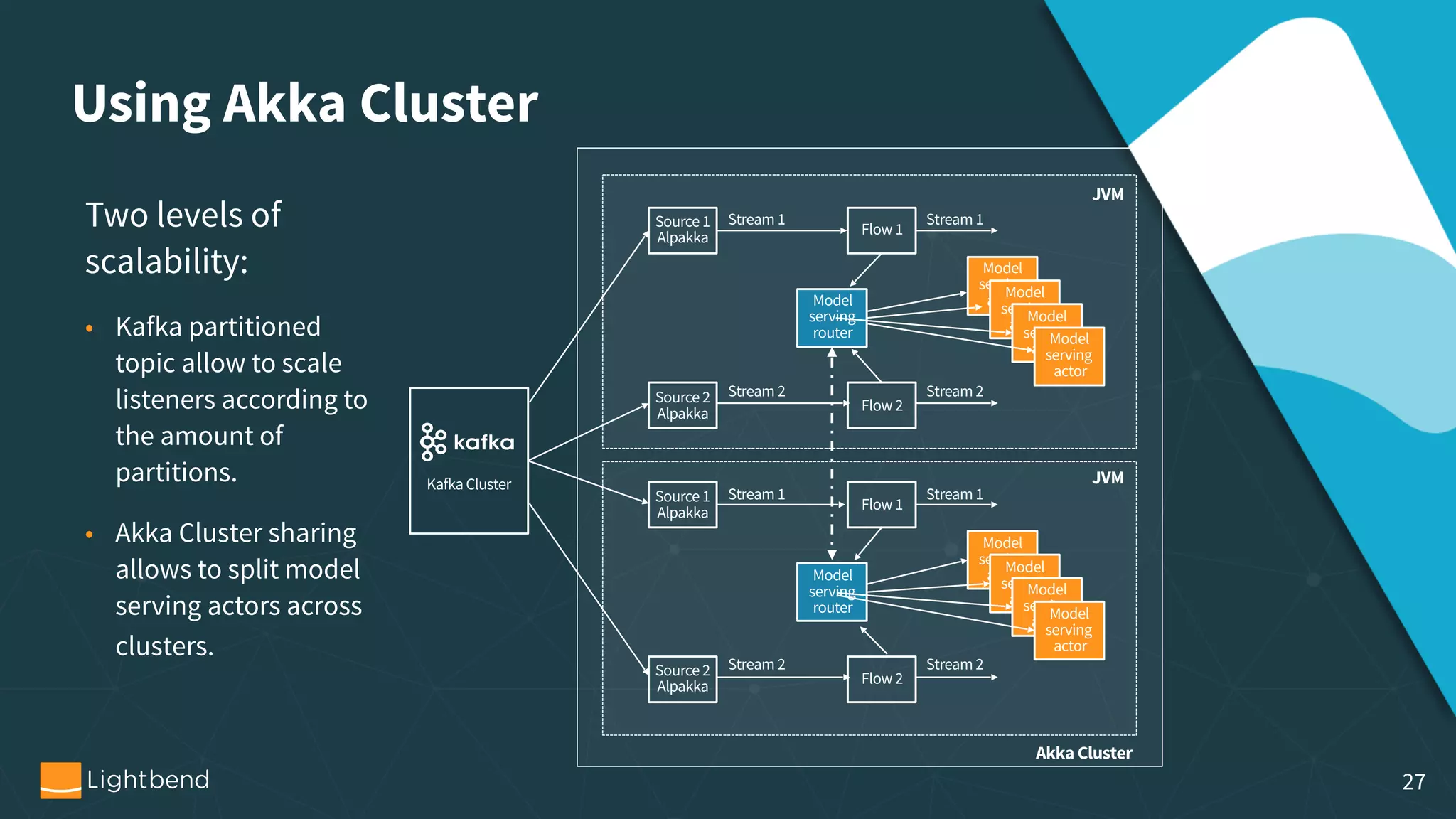

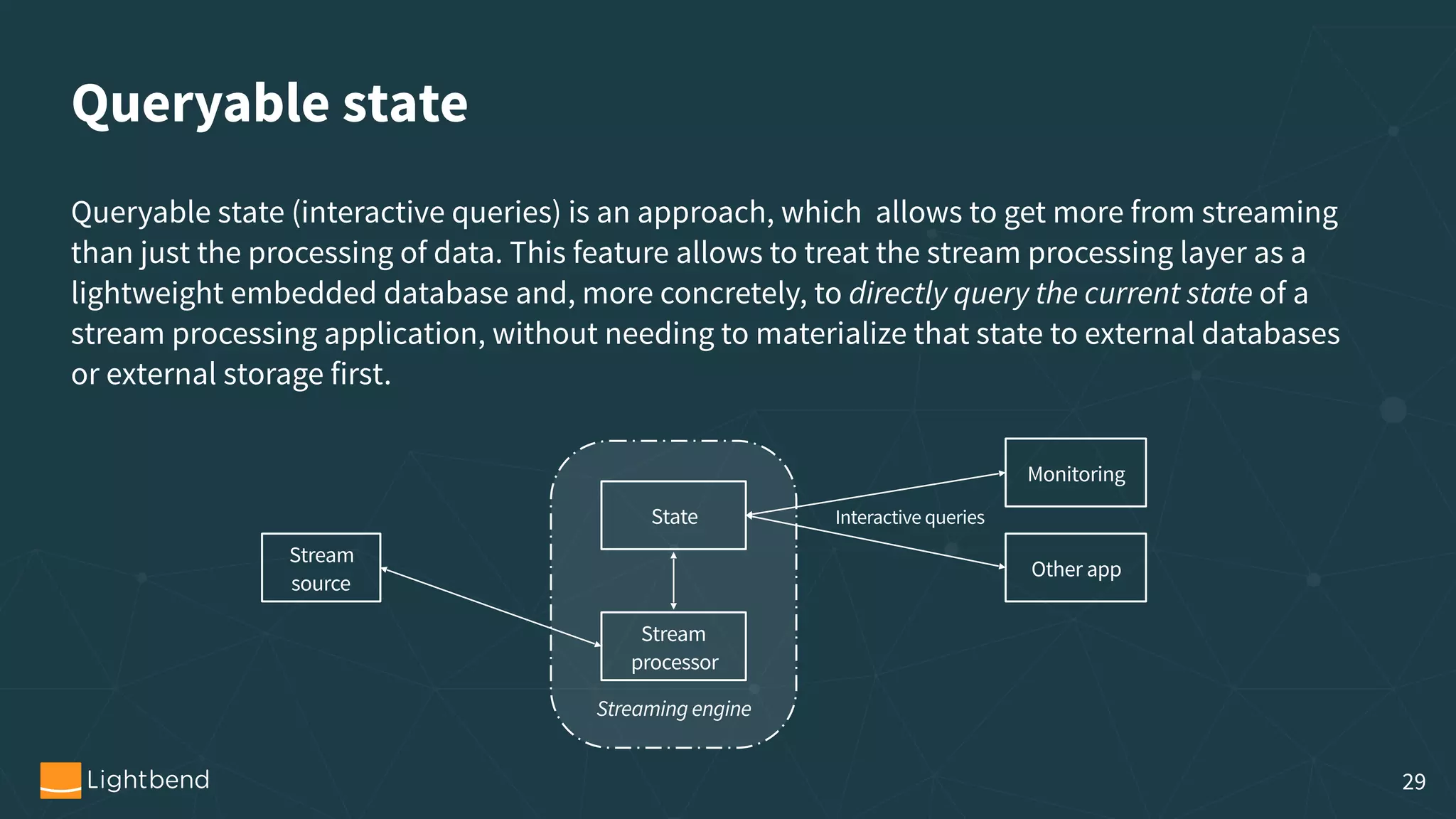



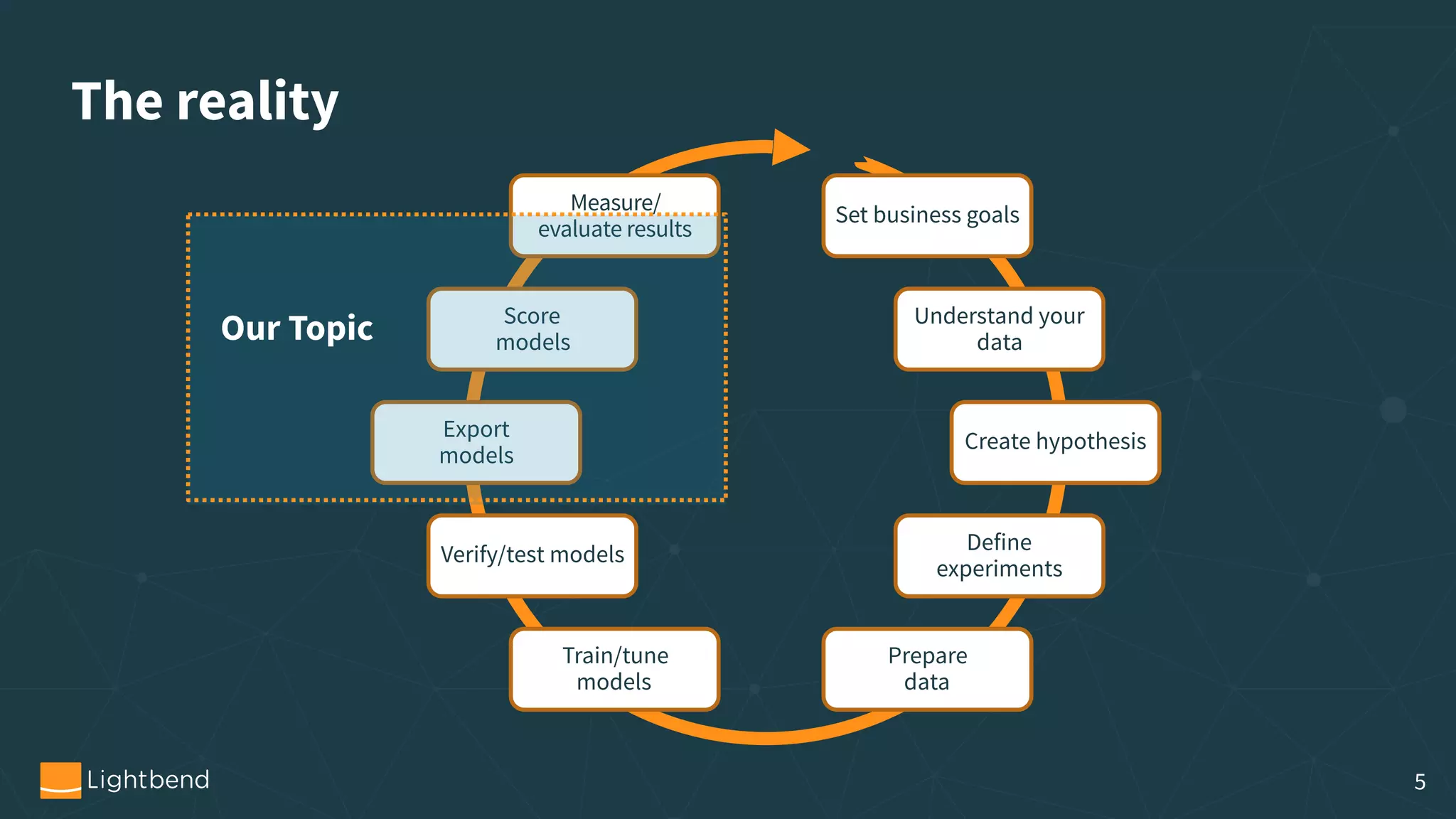
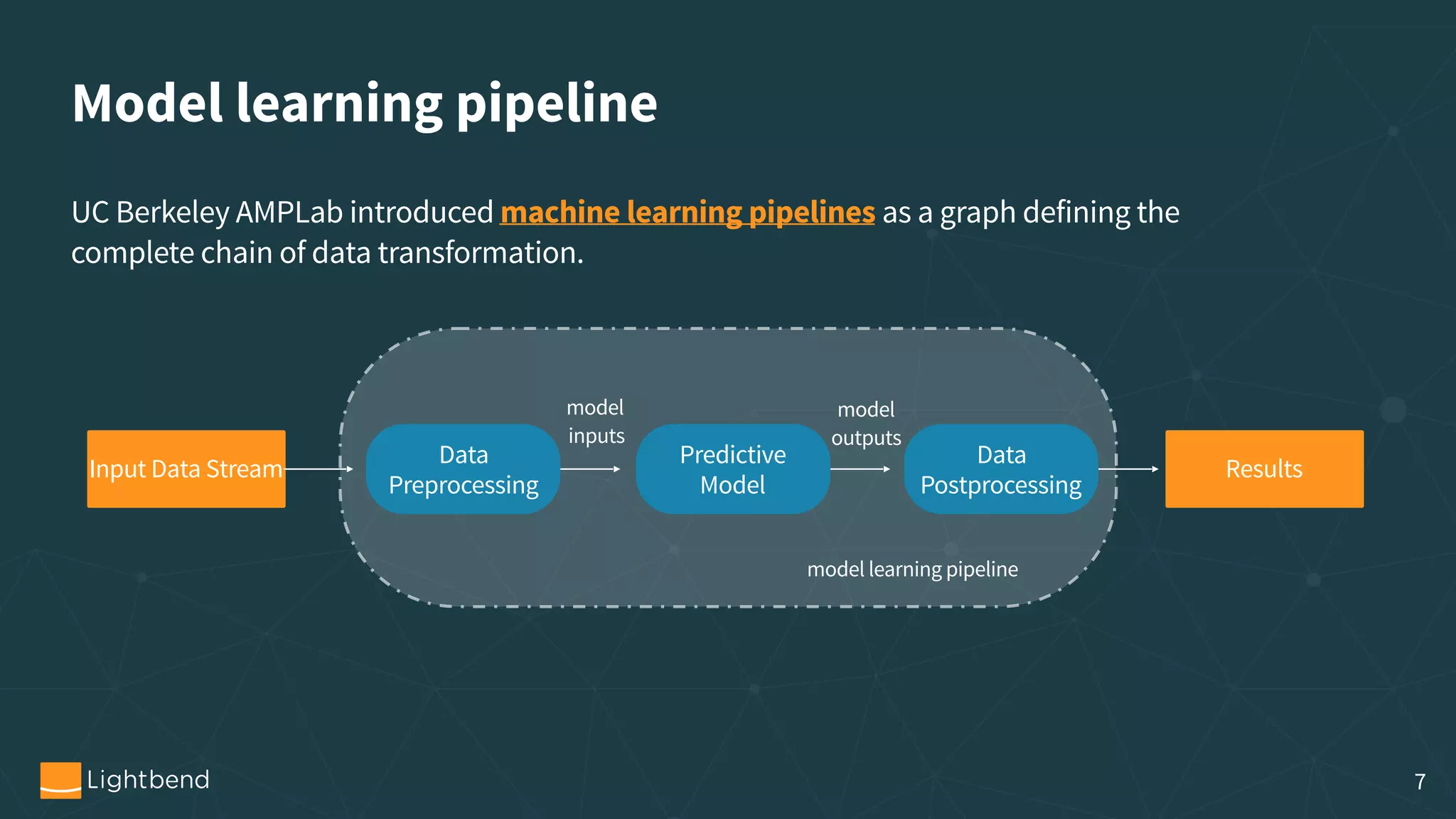
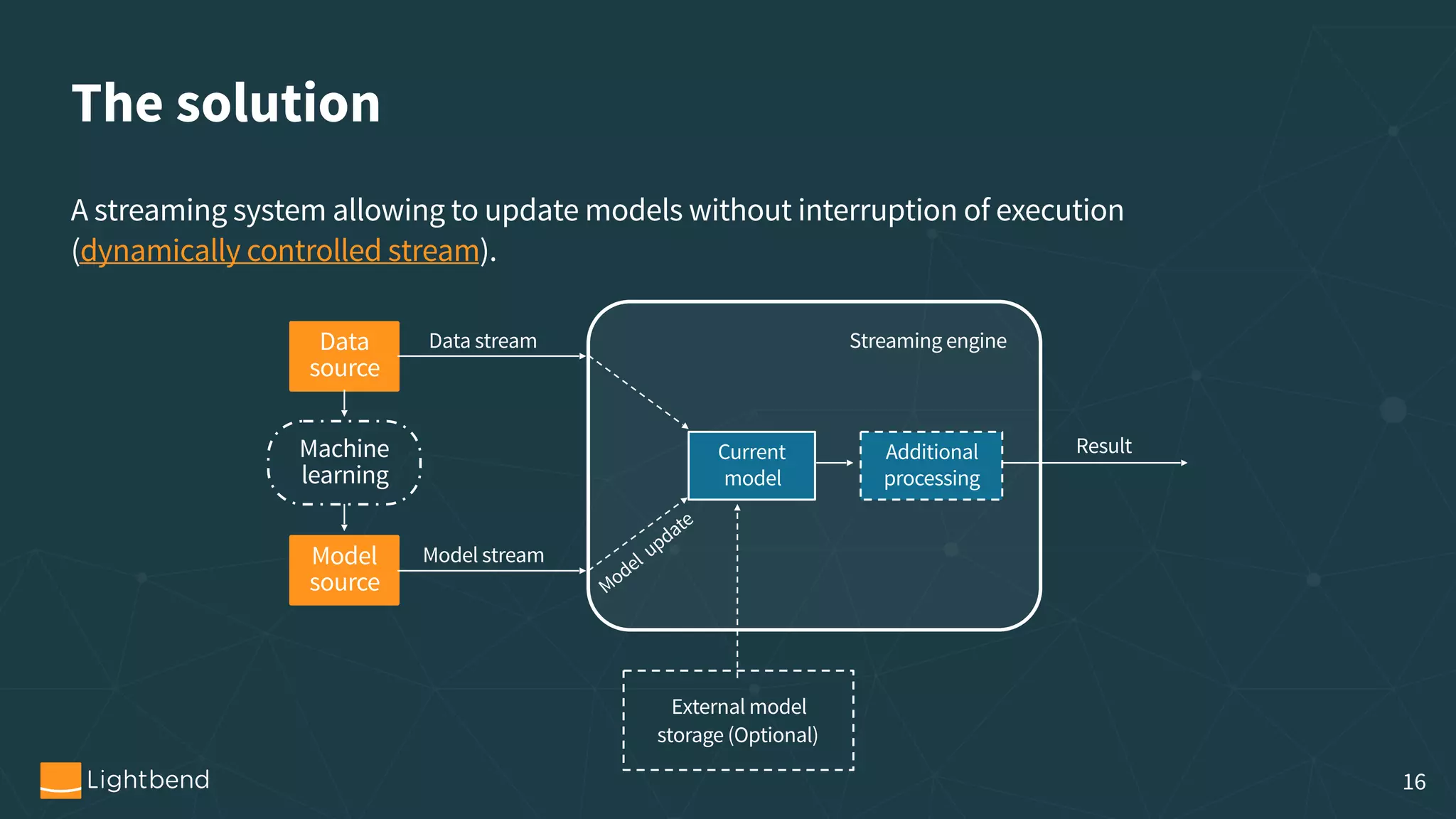
The document outlines the process of machine learning model serving, highlighting the importance of model representation and the use of streaming systems for dynamic updates. It covers various topics including model pipelines, different model export standards like PMML and TensorFlow, as well as specific implementations using stream processing engines such as Apache Flink and Akka. Additionally, it discusses considerations for scalability, monitoring, and querying state within streaming applications.