




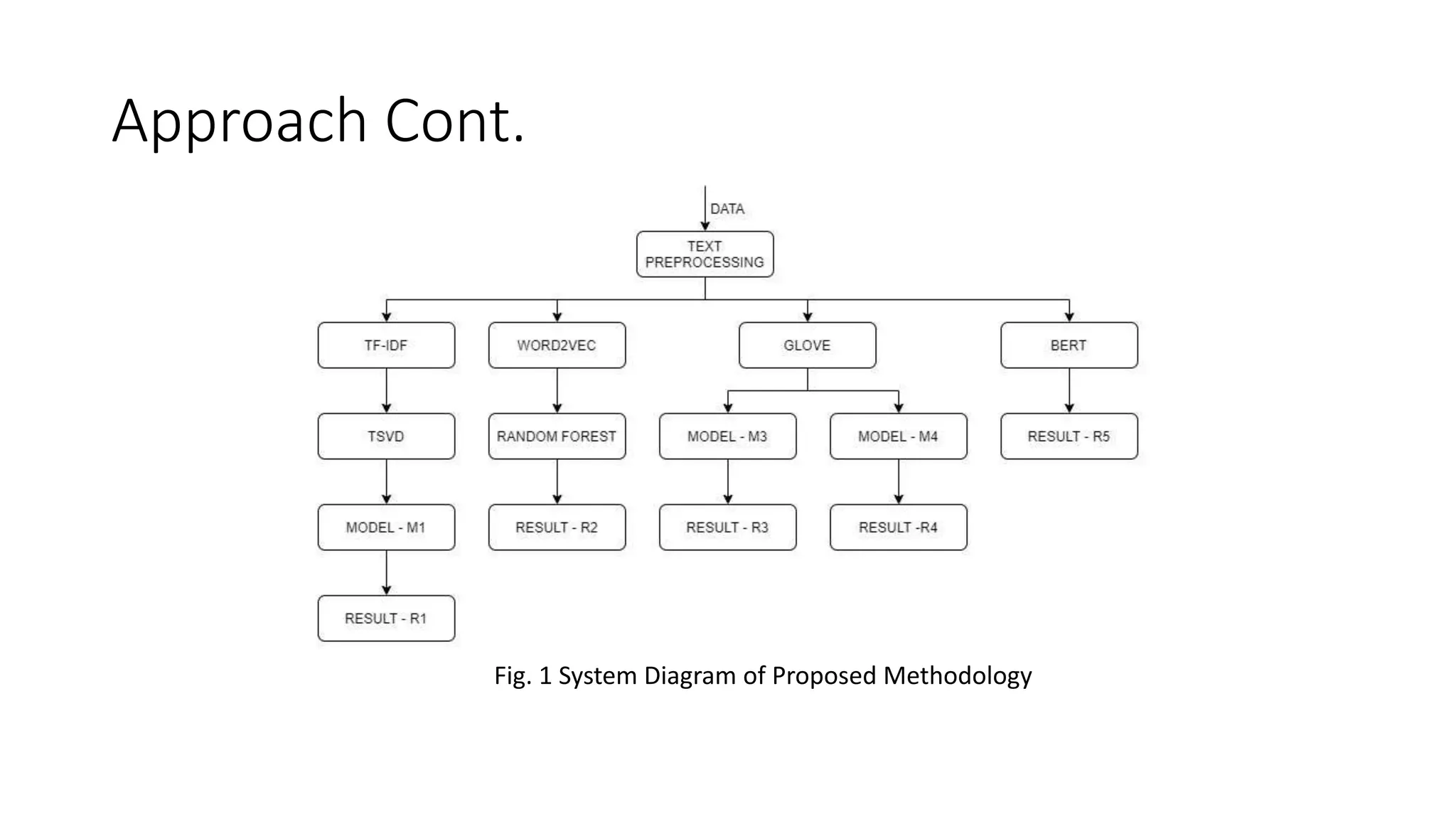




The document discusses multi-class sentiment classification of tweets using machine learning and deep learning techniques, emphasizing the challenges of identifying diverse sentiments like sadness, anger, and love within text data. Various preprocessing and vectorization methods are applied, and models such as random forests and BERT are utilized, achieving an overall accuracy of 40% with the BERT model. The findings enhance decision-making for businesses by providing detailed insights into user opinions beyond traditional positive, negative, and neutral classifications.