Download as PDF, PPTX




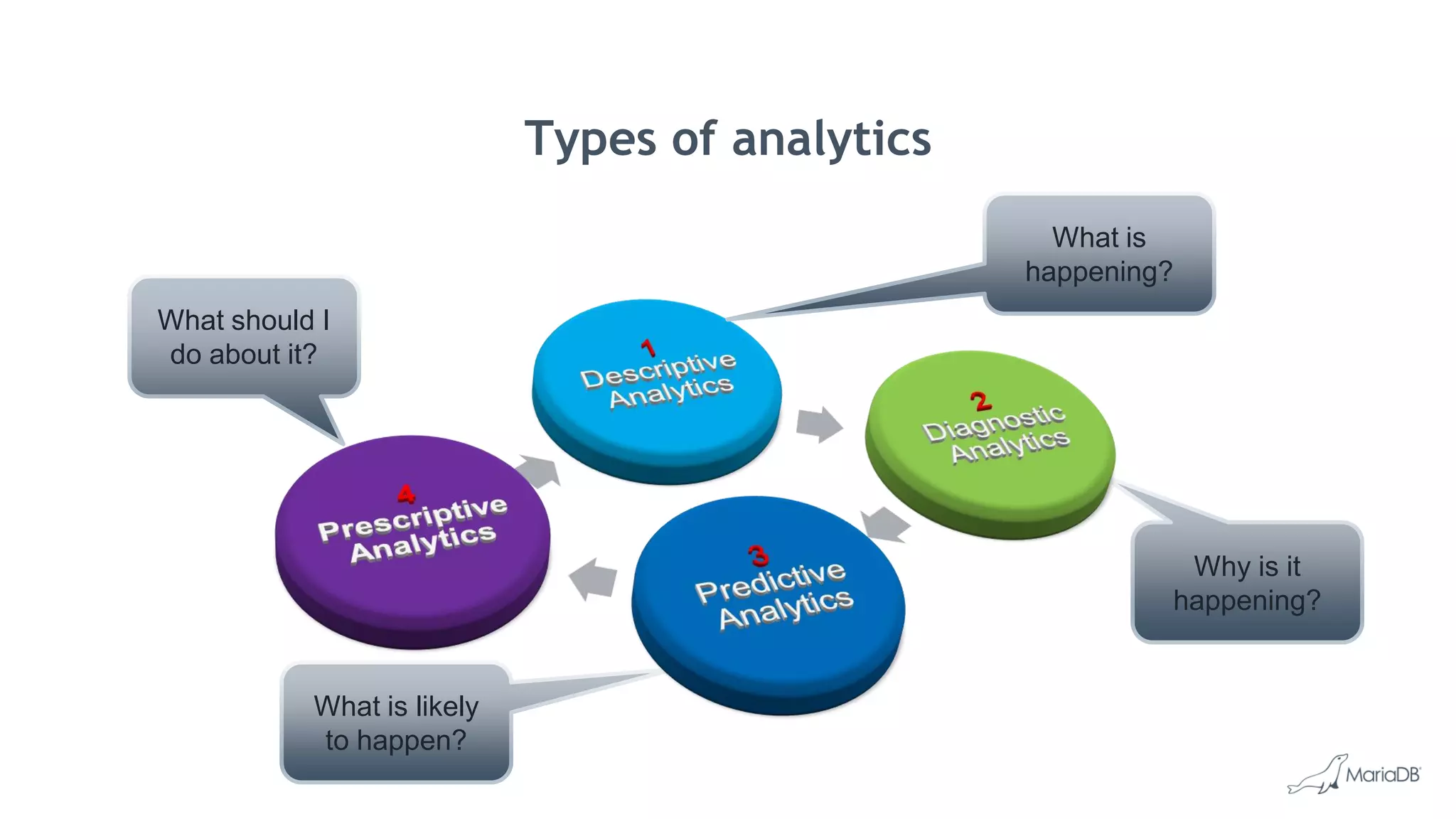
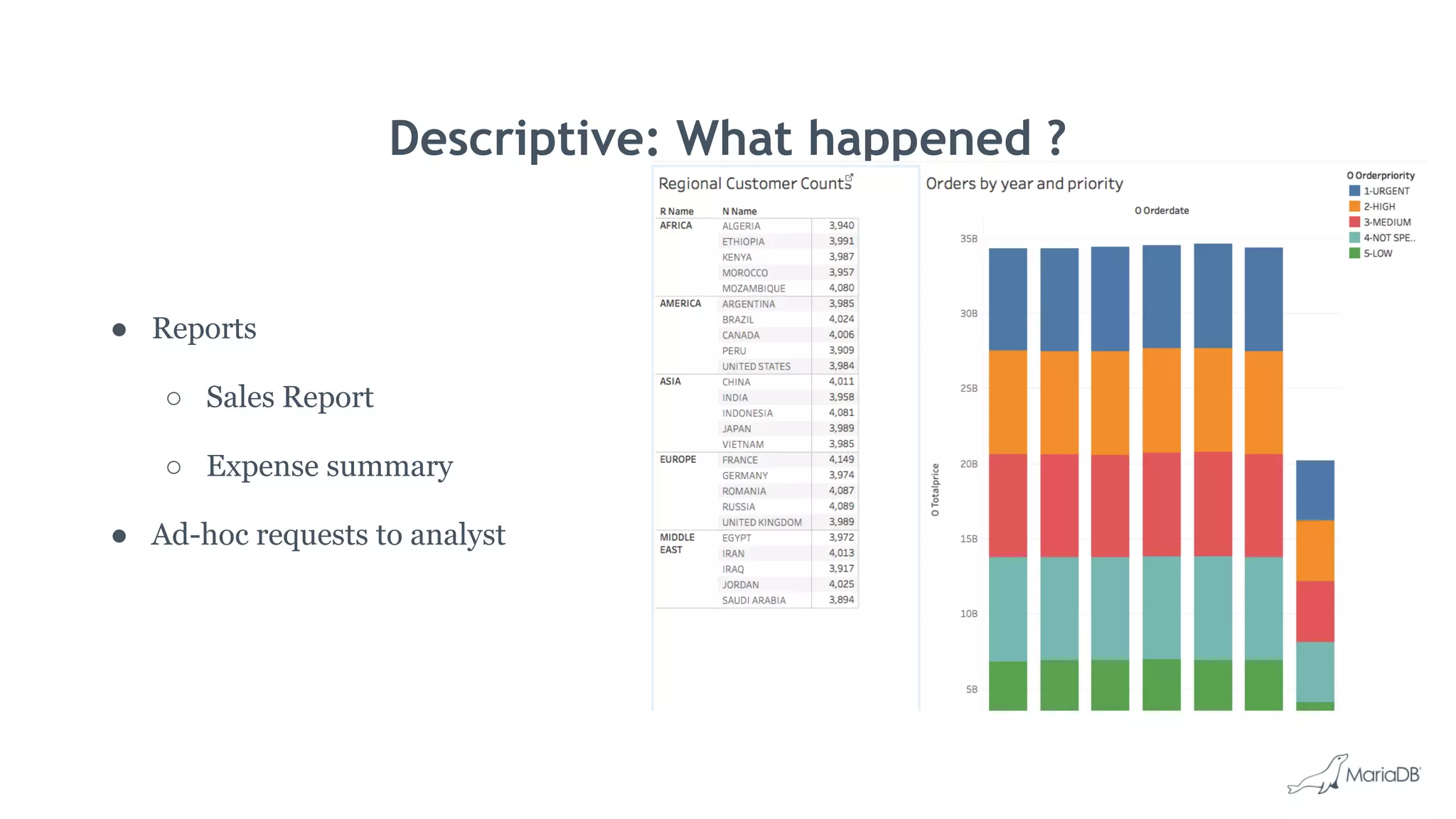


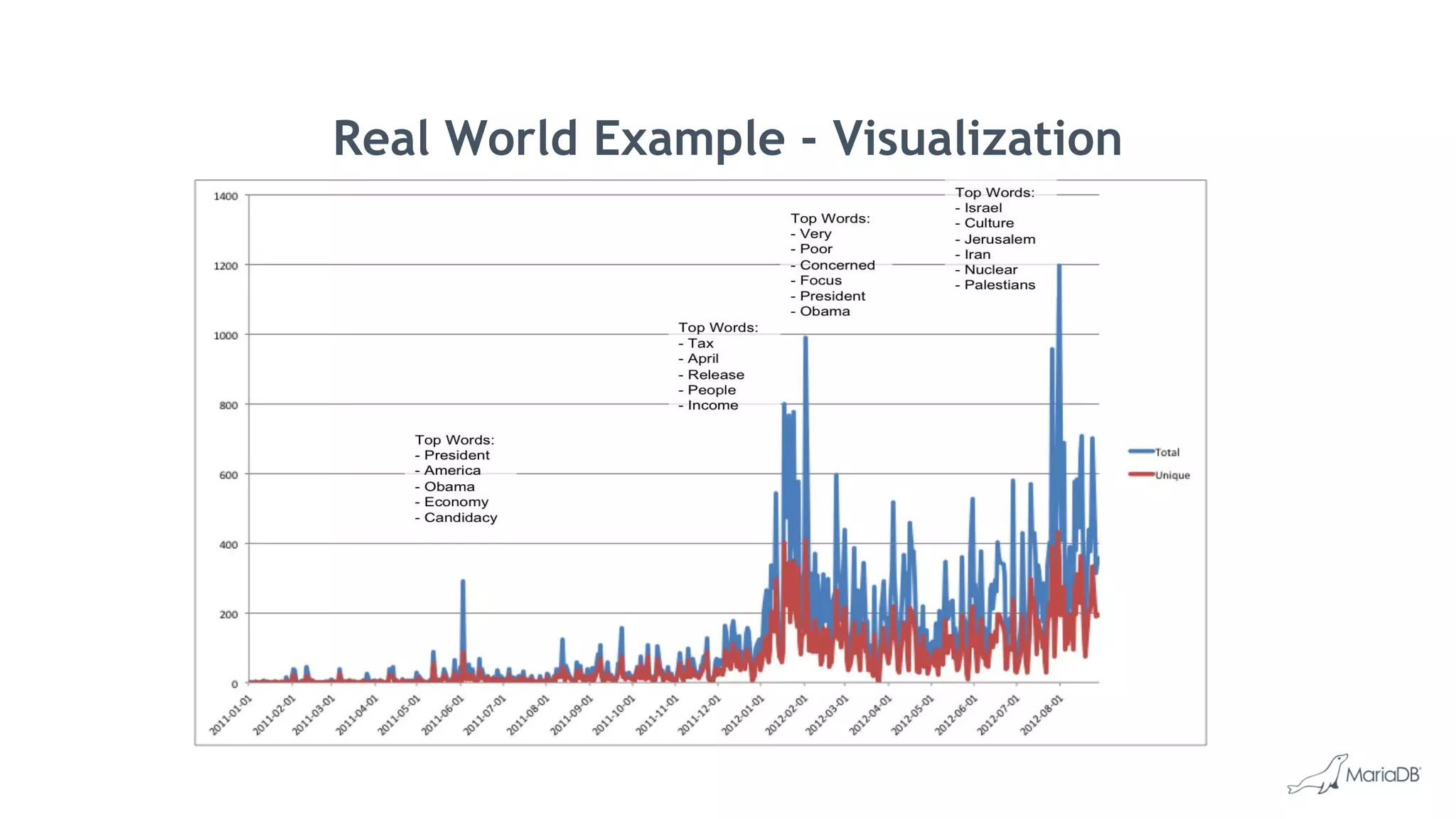

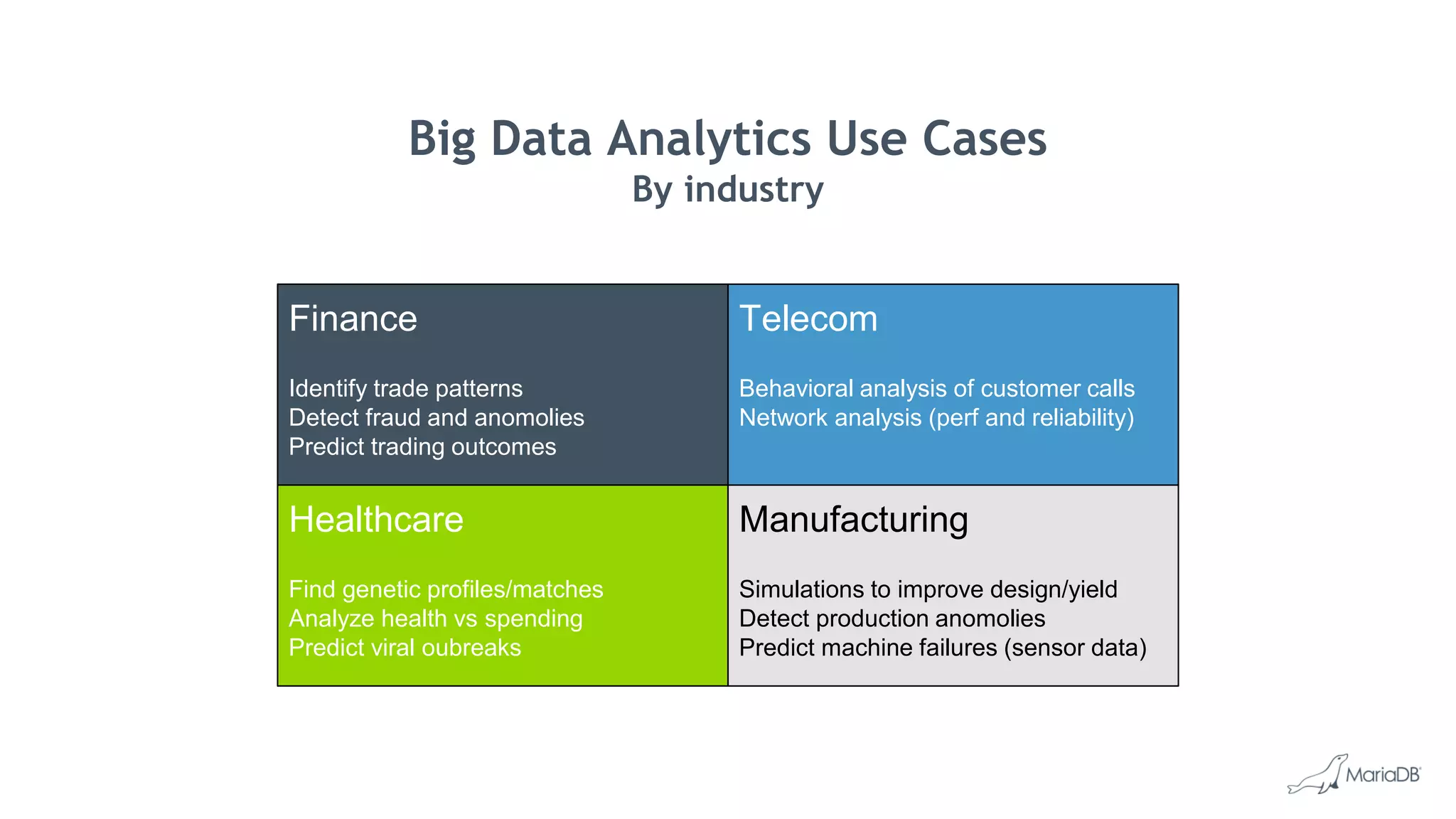




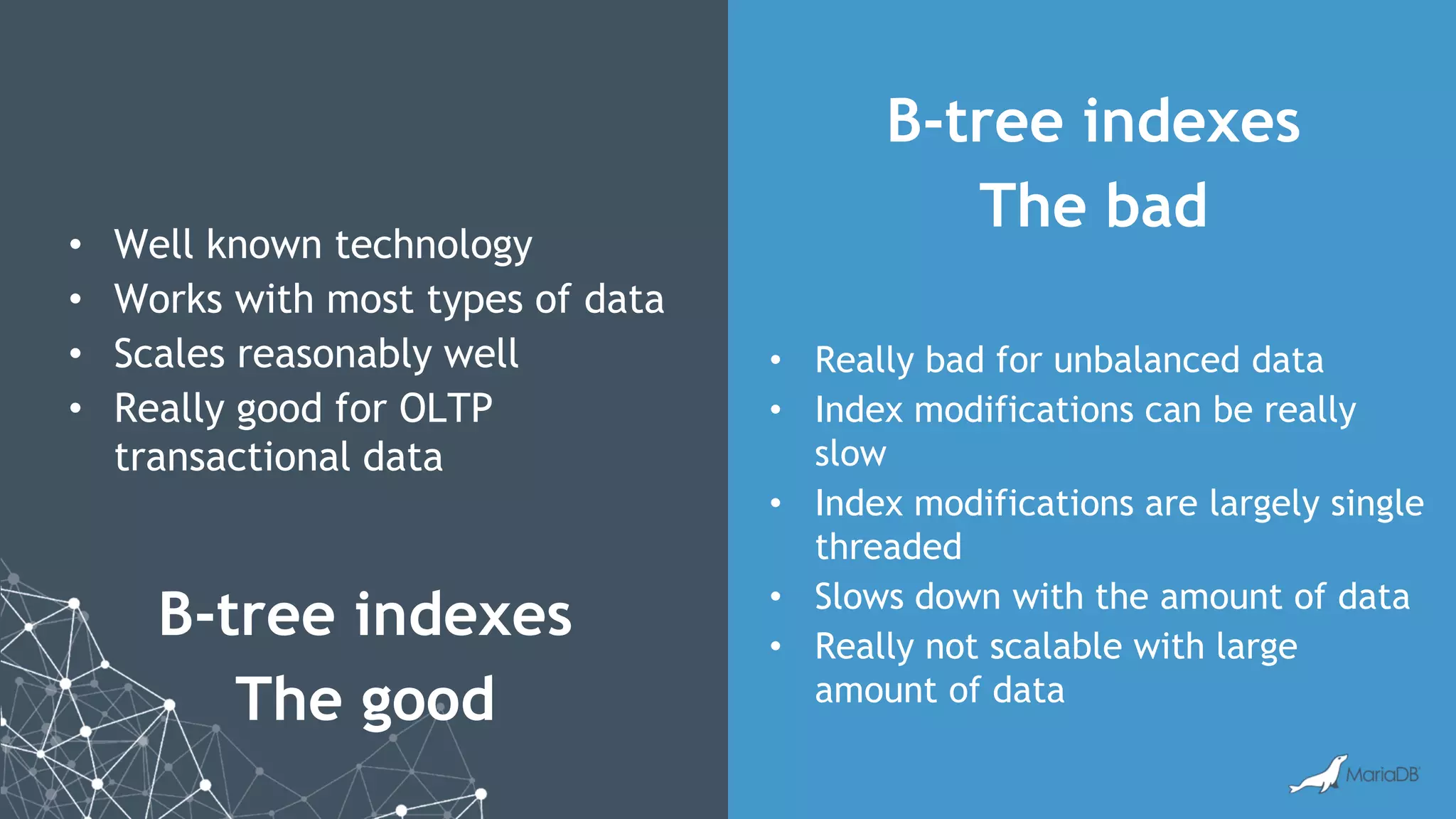


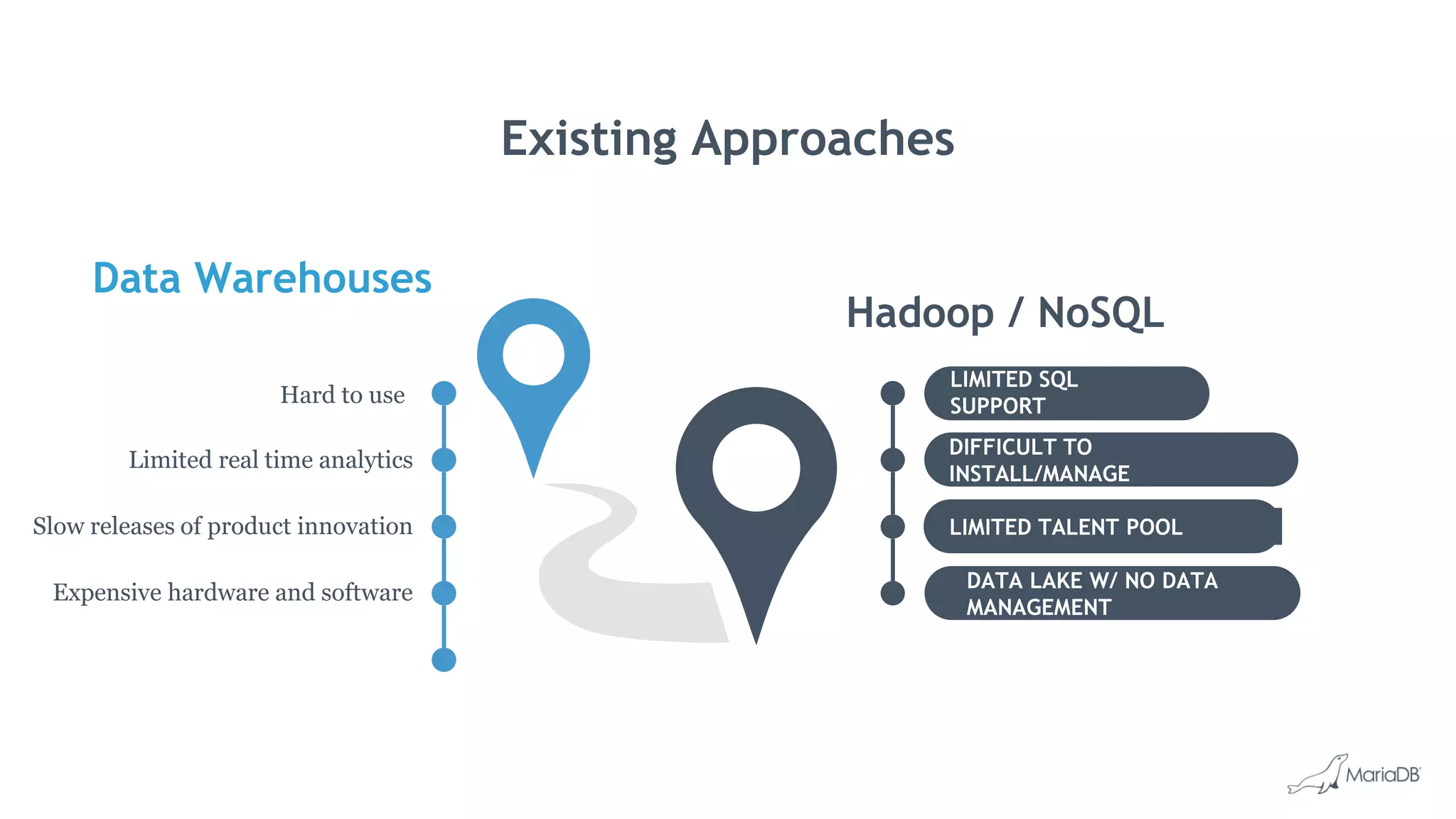
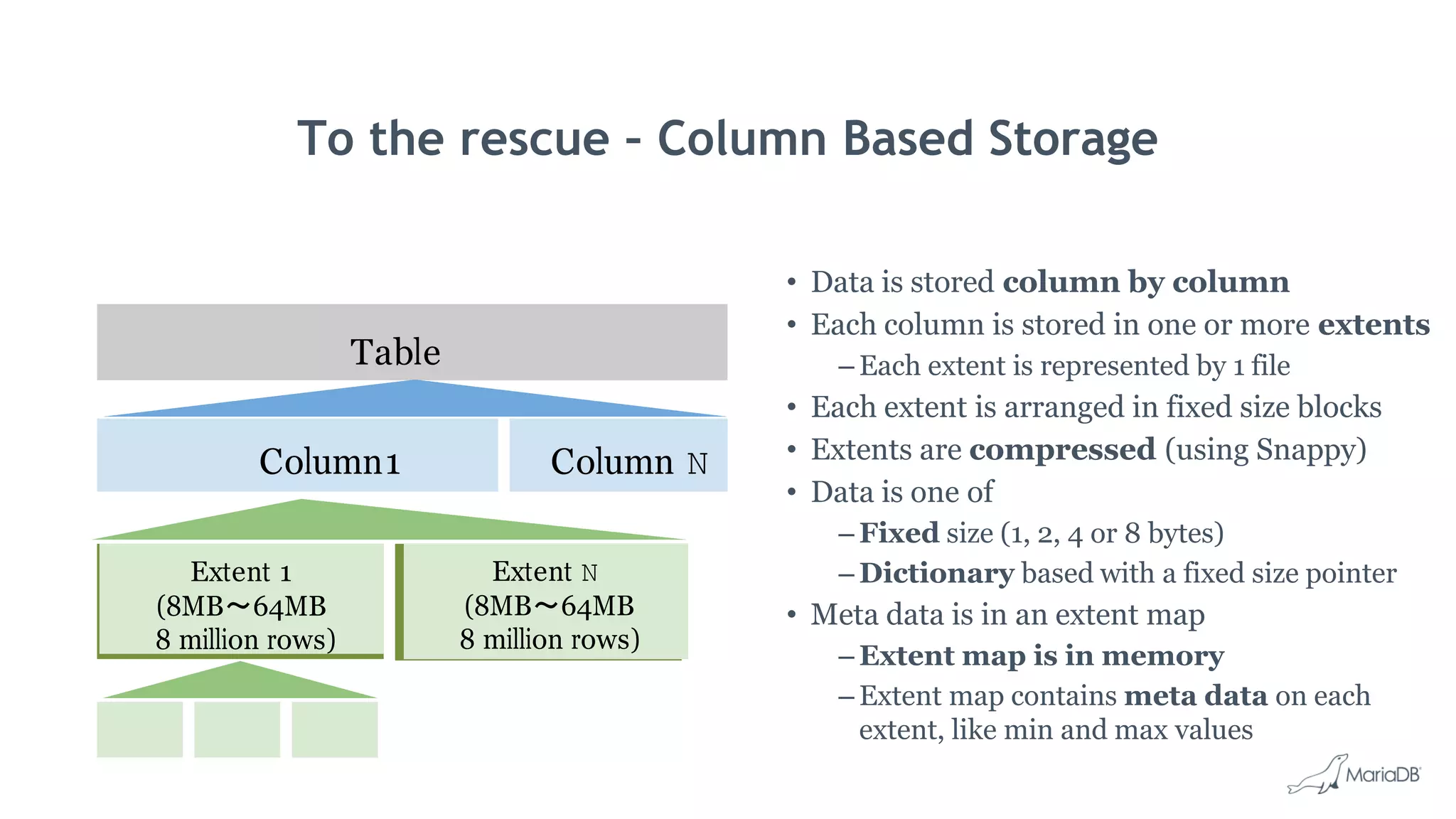
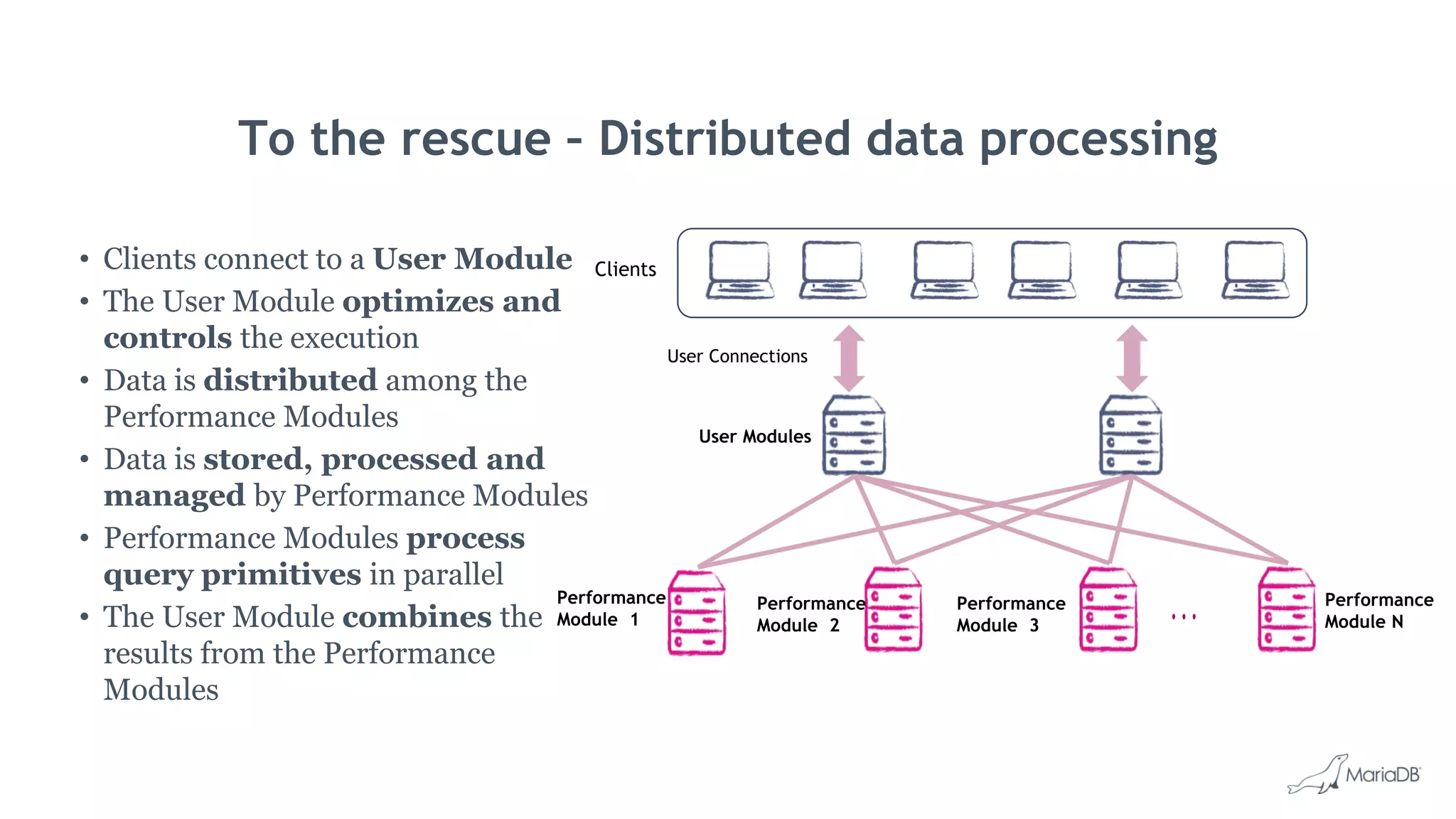


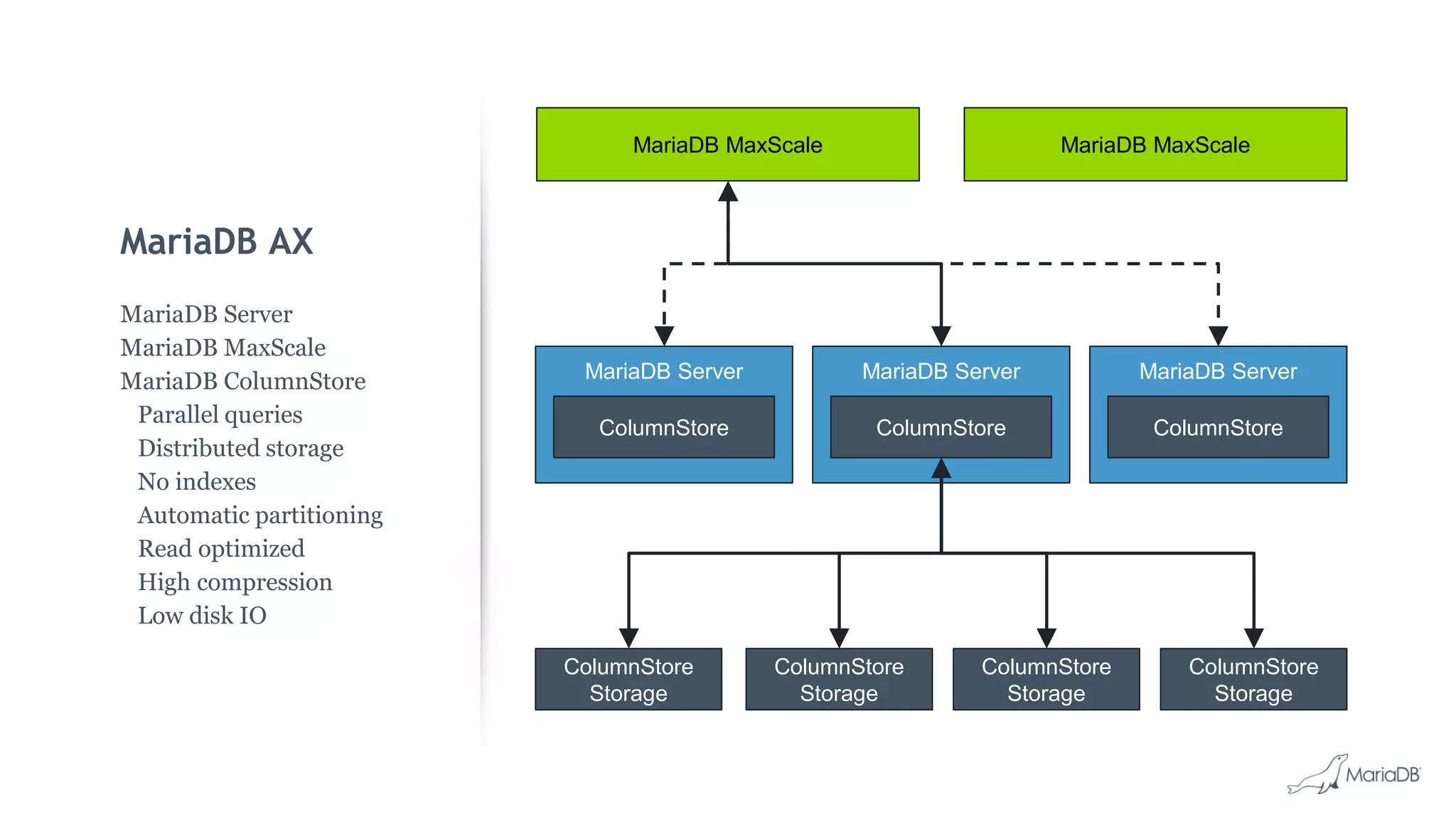








MariaDB ColumnStore is a high performance columnar storage engine that provides fast and efficient analytics on large datasets in distributed environments. It stores data column-by-column for high compression and read performance. Queries are processed in parallel across nodes for scalability. MariaDB ColumnStore is used for real-time analytics use cases in industries like healthcare, life sciences, and telecommunications to gain insights from large datasets.