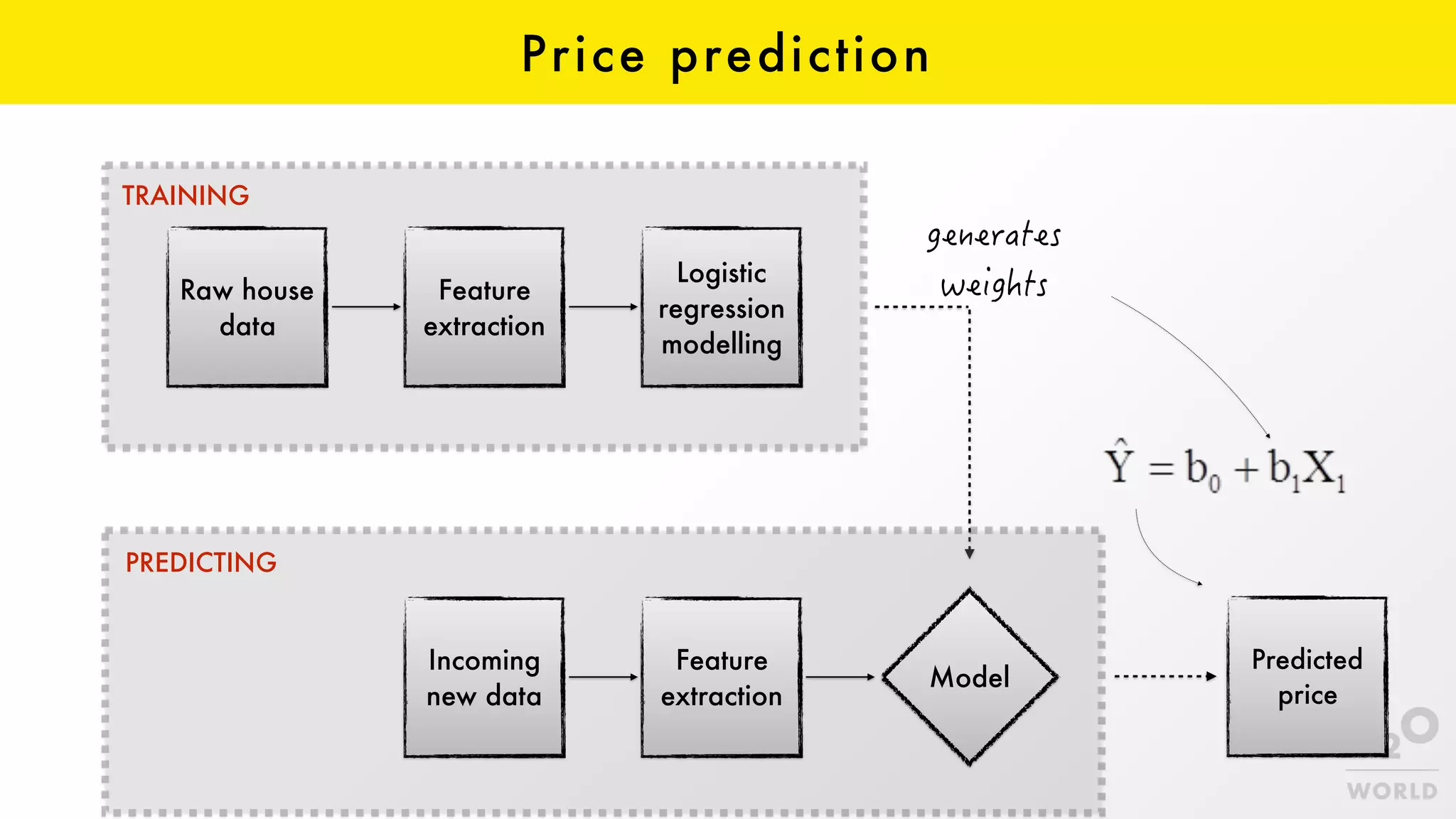
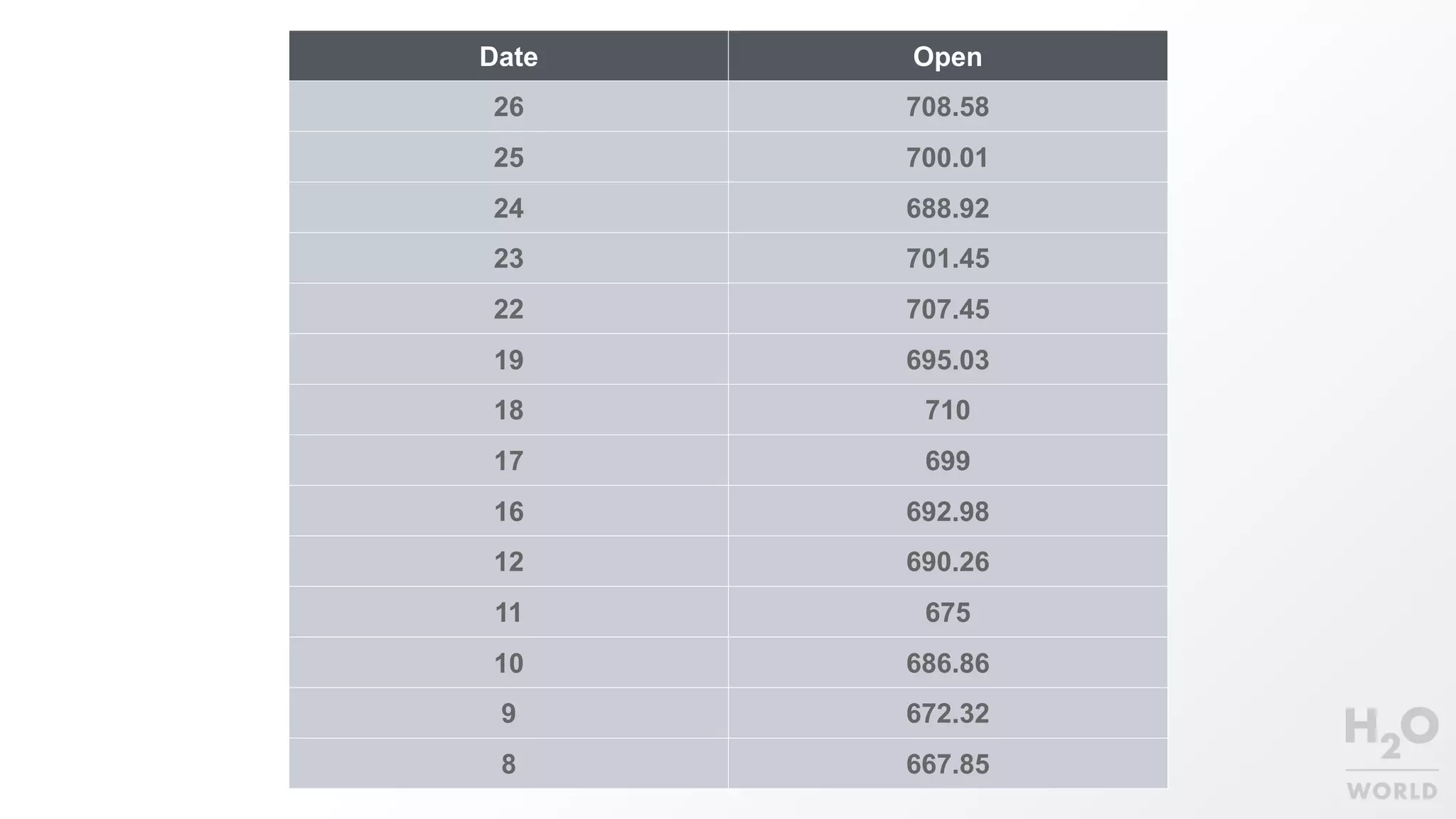
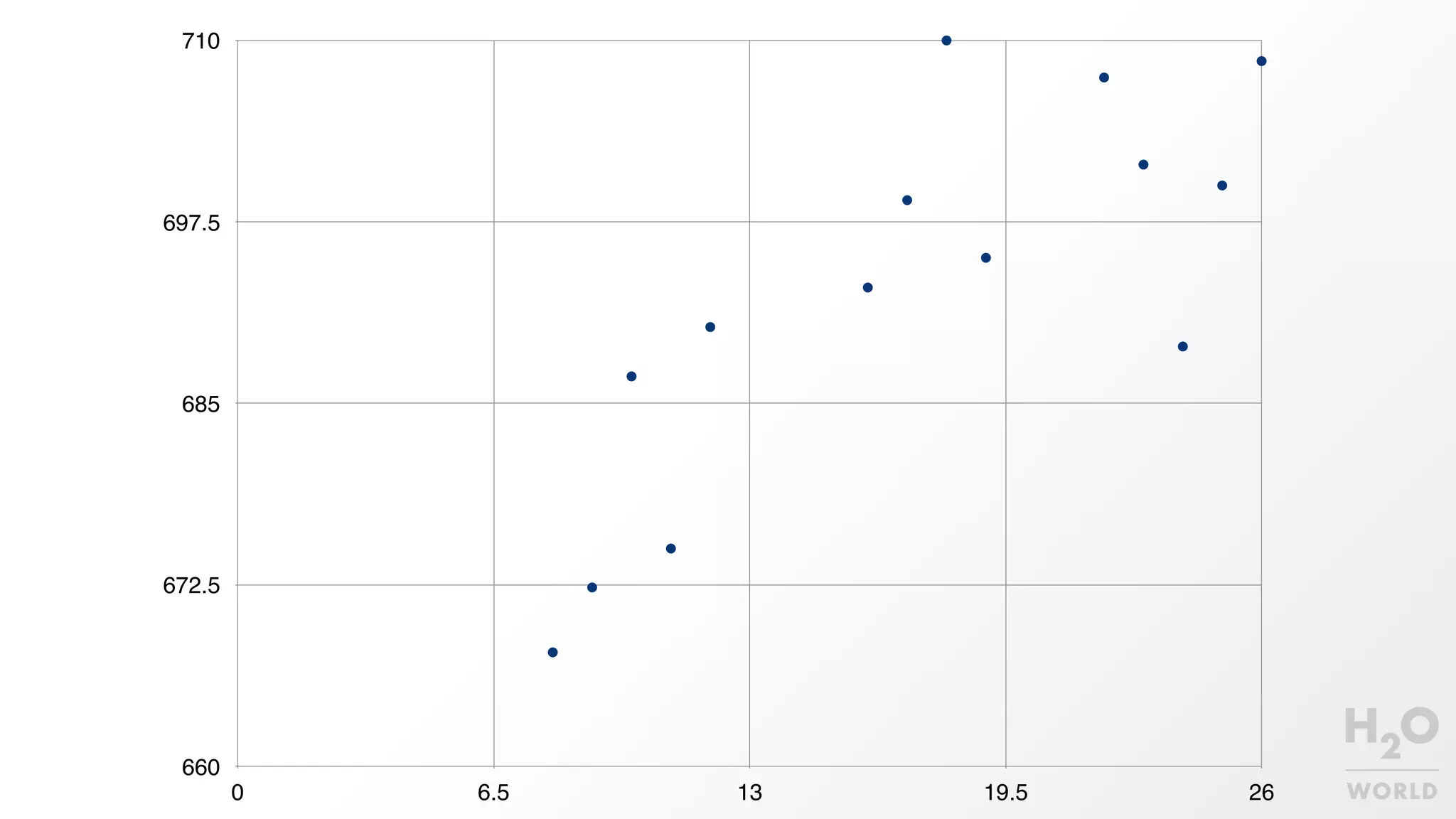
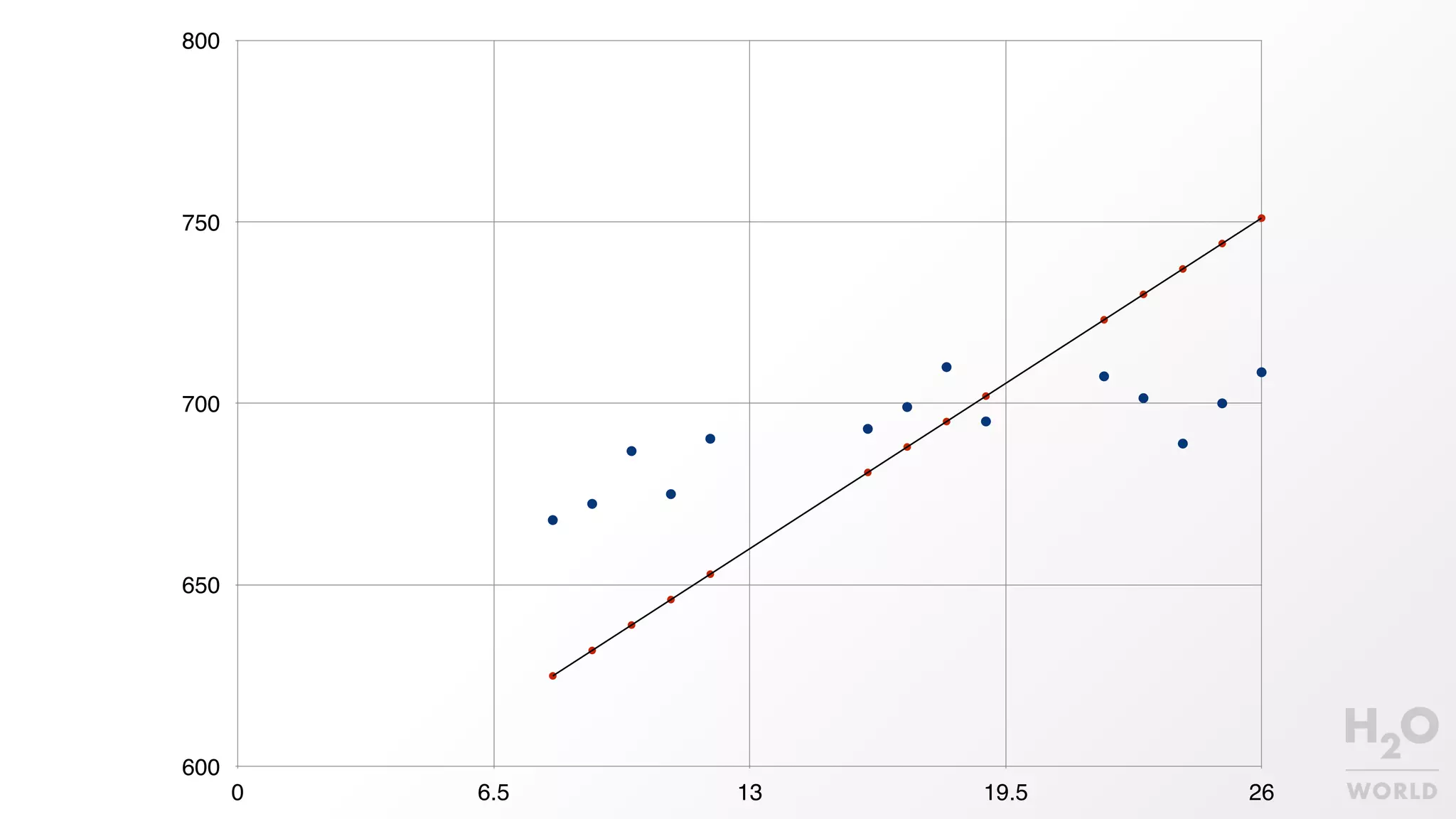
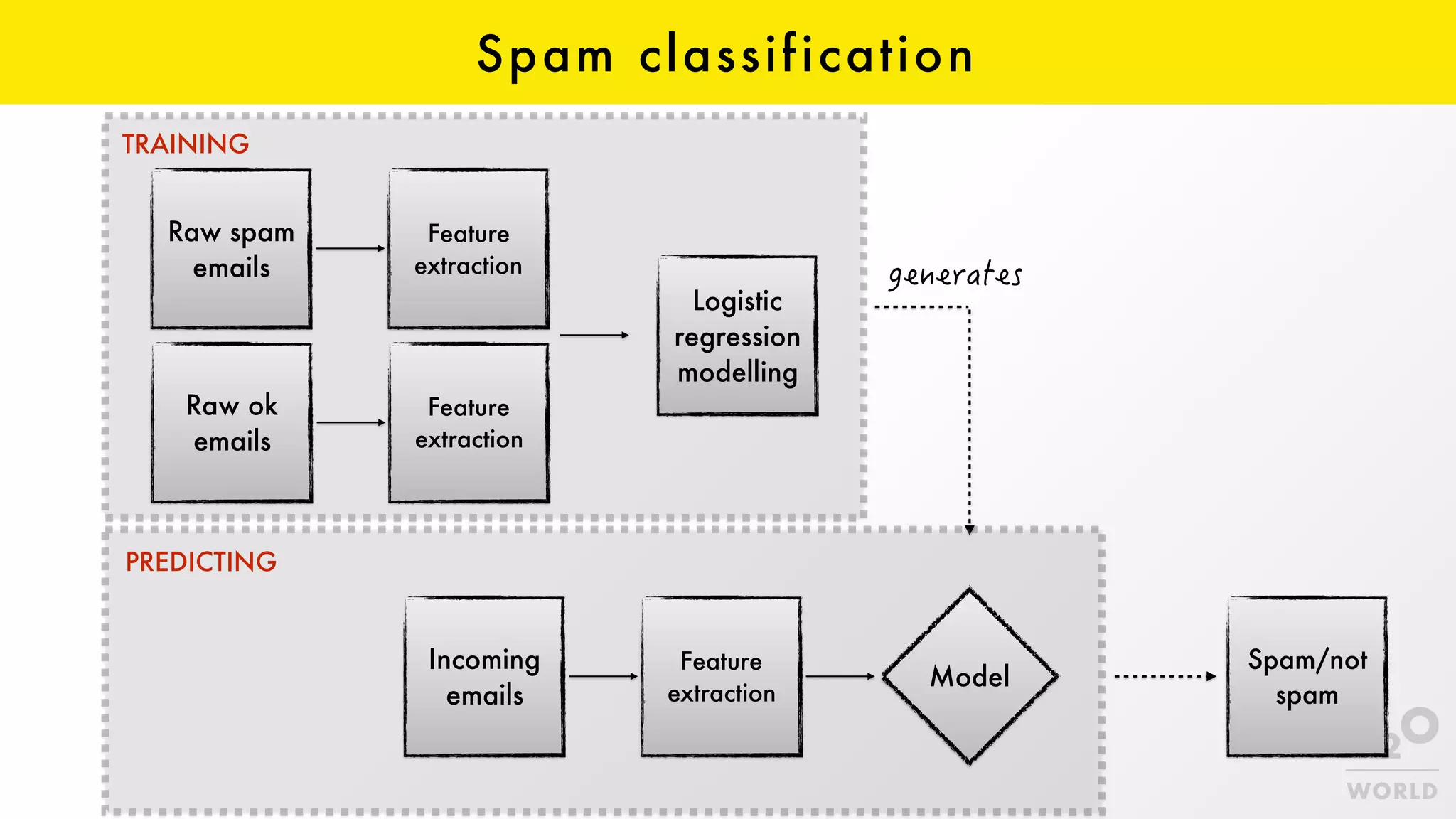
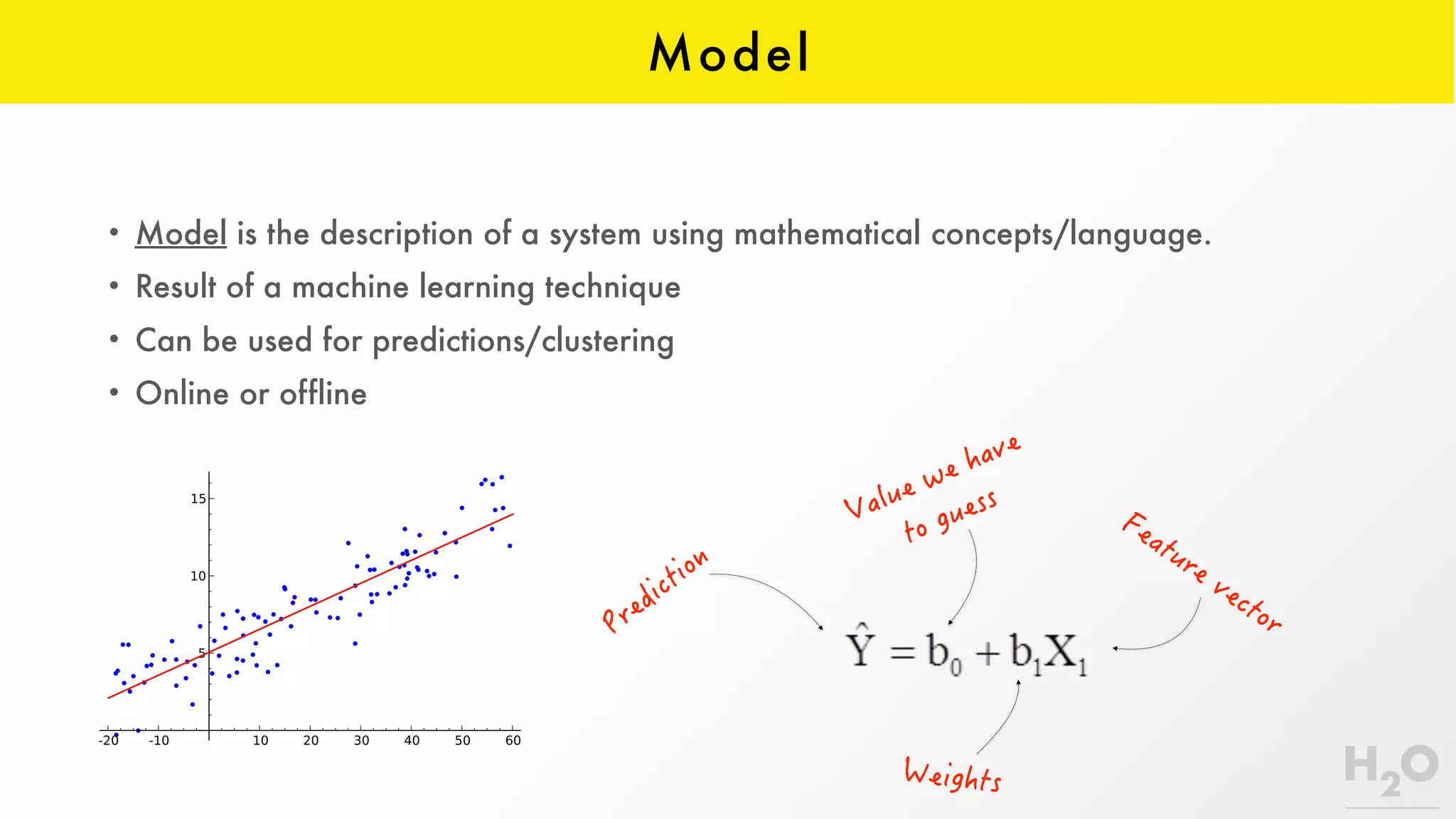
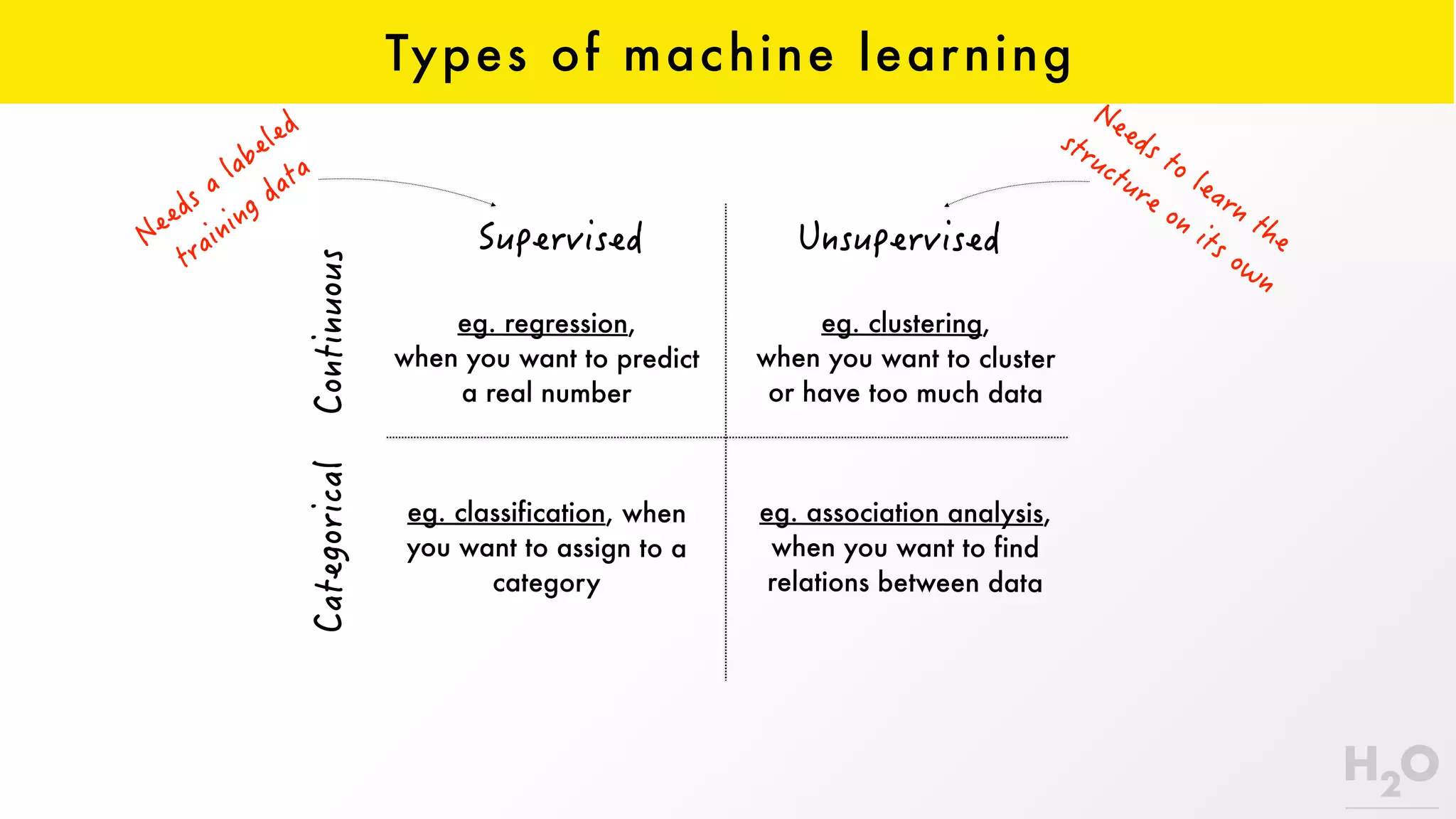
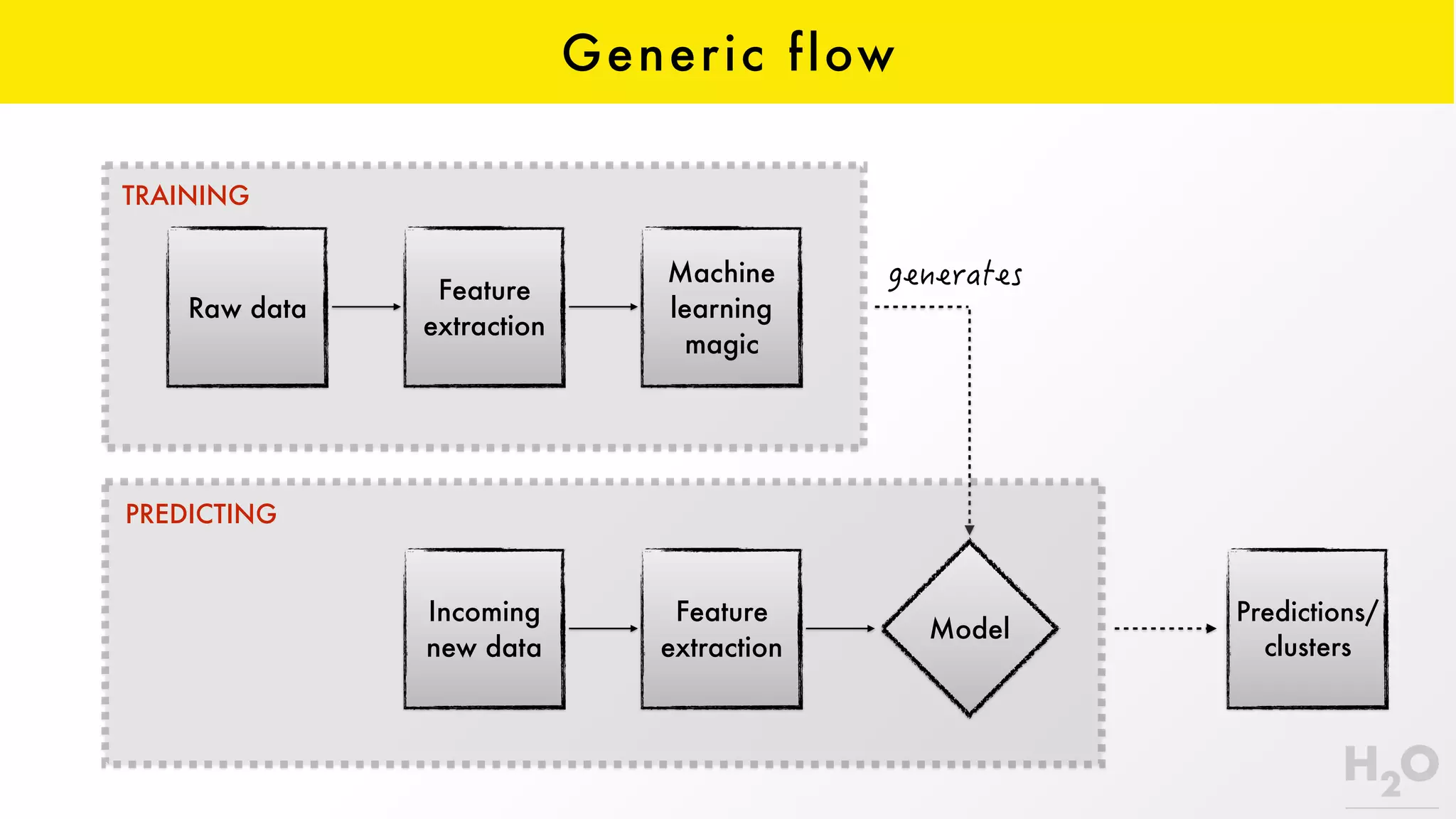
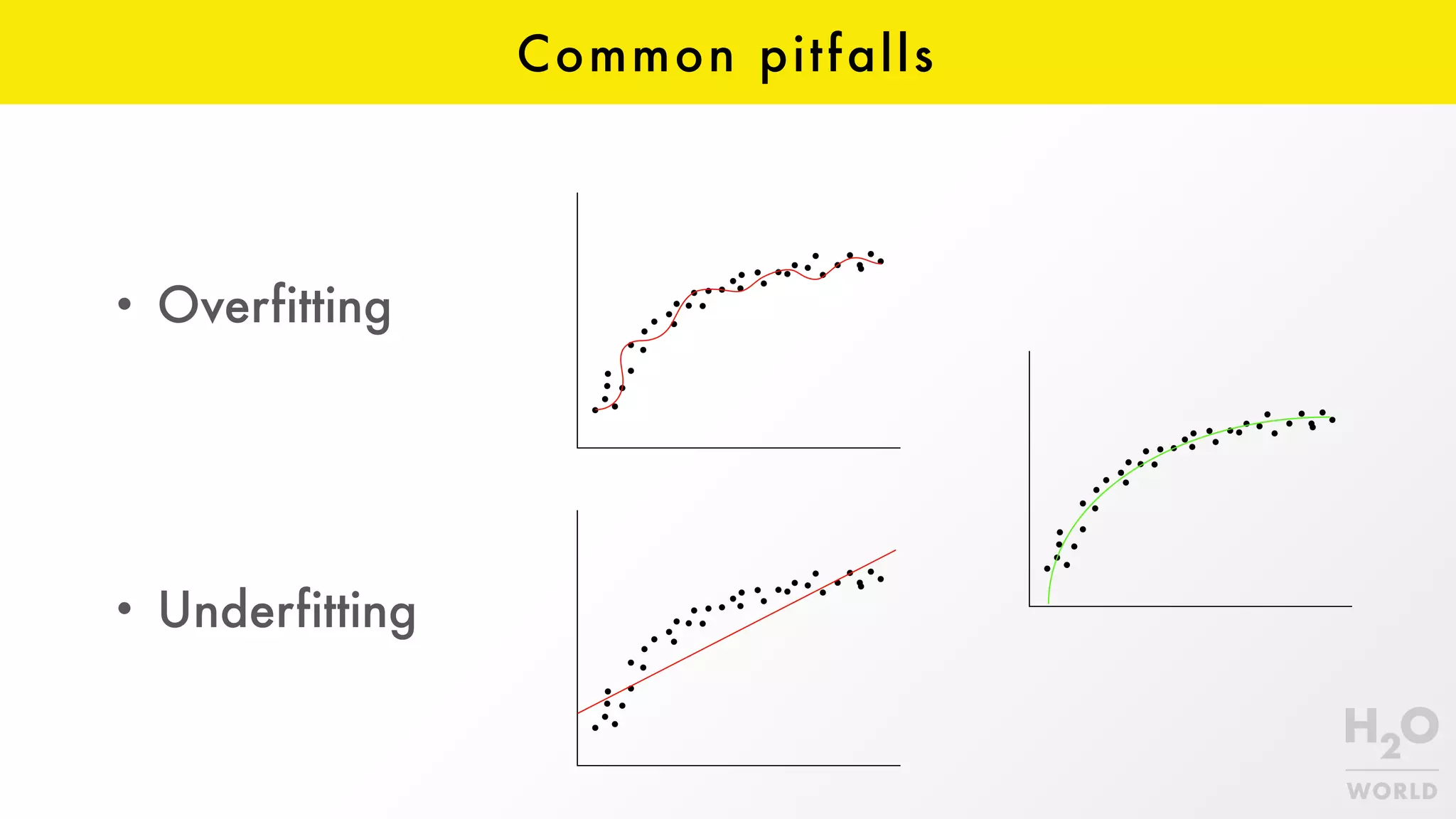
This document provides an overview of machine learning for Java Virtual Machine (JVM) developers. It begins with introductions to the speaker and topics to be covered. It then discusses the growth of data and opportunities for machine learning applications. Key machine learning concepts are defined, including observations, features, models, supervised vs. unsupervised learning, and common algorithms like classification, regression, and clustering. Popular JVM machine learning tools are listed, with Spark/MLlib highlighted for its community support and implementation of standard algorithms. Example machine learning demos on price prediction and spam classification are described. The document concludes with recommendations for further learning resources.











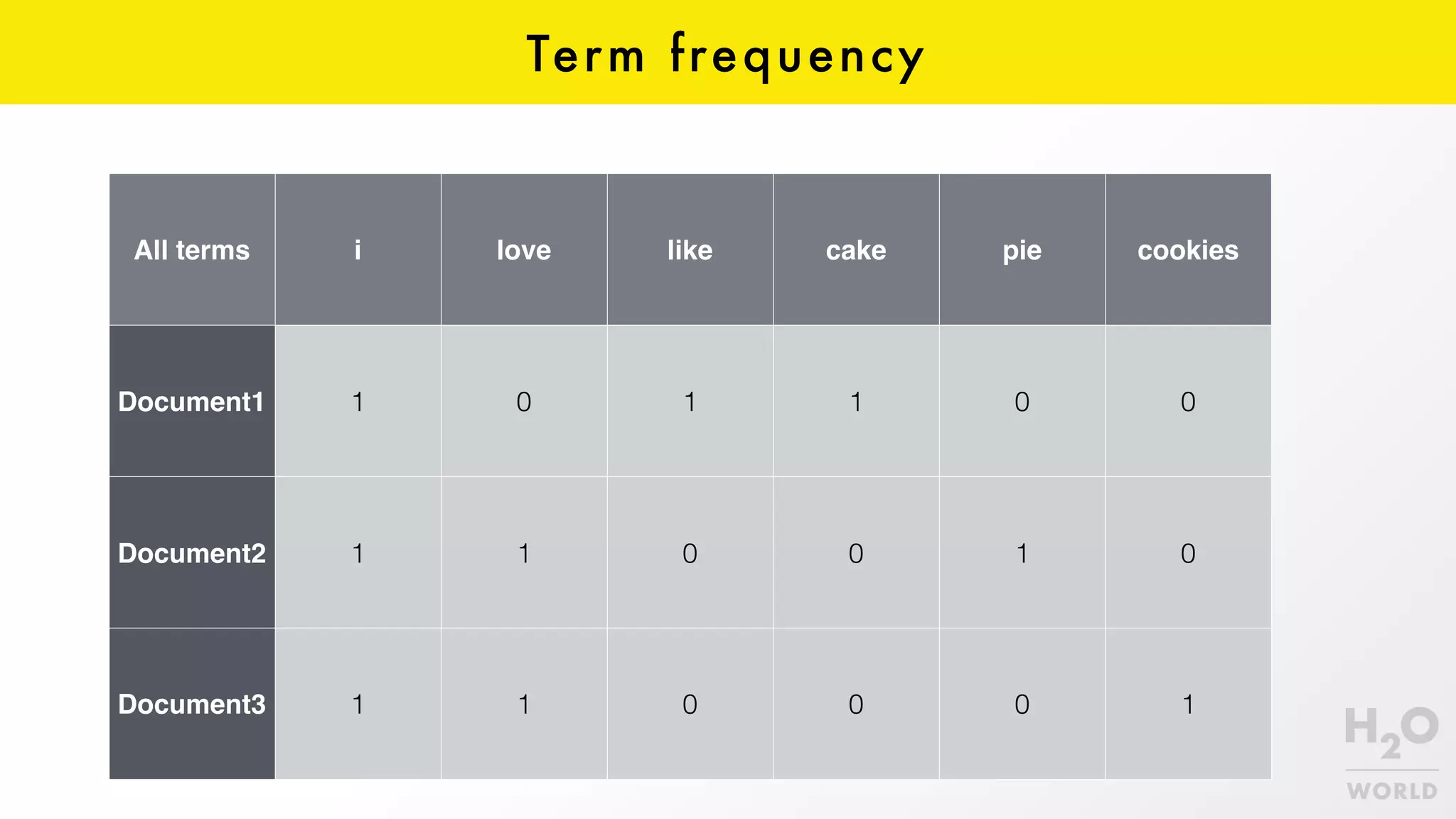
![Feature is a quantitative trait that (partially) represents an observation. Feature vector is an n-dimentional vector of features that represents an observation. Feature extraction vs. feature selection Feature { "title": "Email schema", "type": "object", "properties": { "age": { "type": "float" }, "rooms": { "type": "int" }, "size": { "type": "float" }, "location": { "type": "string" } } } [5, 3, 60.5]](https://image.slidesharecdn.com/geecon2016-160512093239/75/Machine-Learning-for-JVM-Developers-13-2048.jpg)










![Spark? val conf = new SparkConf().setAppName("Spark App") val sc = new SparkContext(conf) val textFile: RDD[String] = sc.textFile("hdfs://...") val counts: RDD[(String, Int)] = textFile .flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) println(s"Found ${counts.count()}") counts.saveAsTextFile("hdfs://...")](https://image.slidesharecdn.com/geecon2016-160512093239/75/Machine-Learning-for-JVM-Developers-28-2048.jpg)