


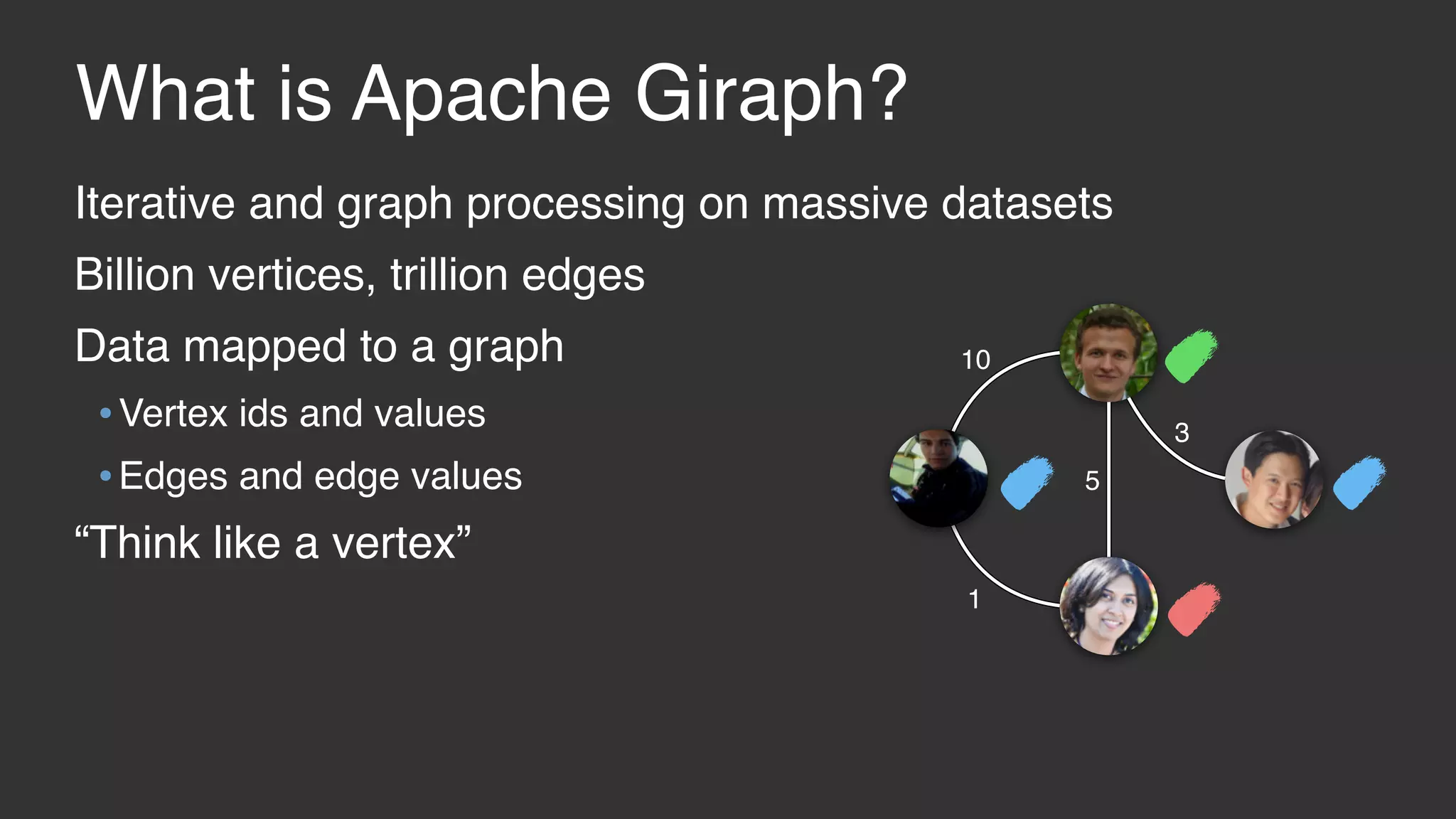

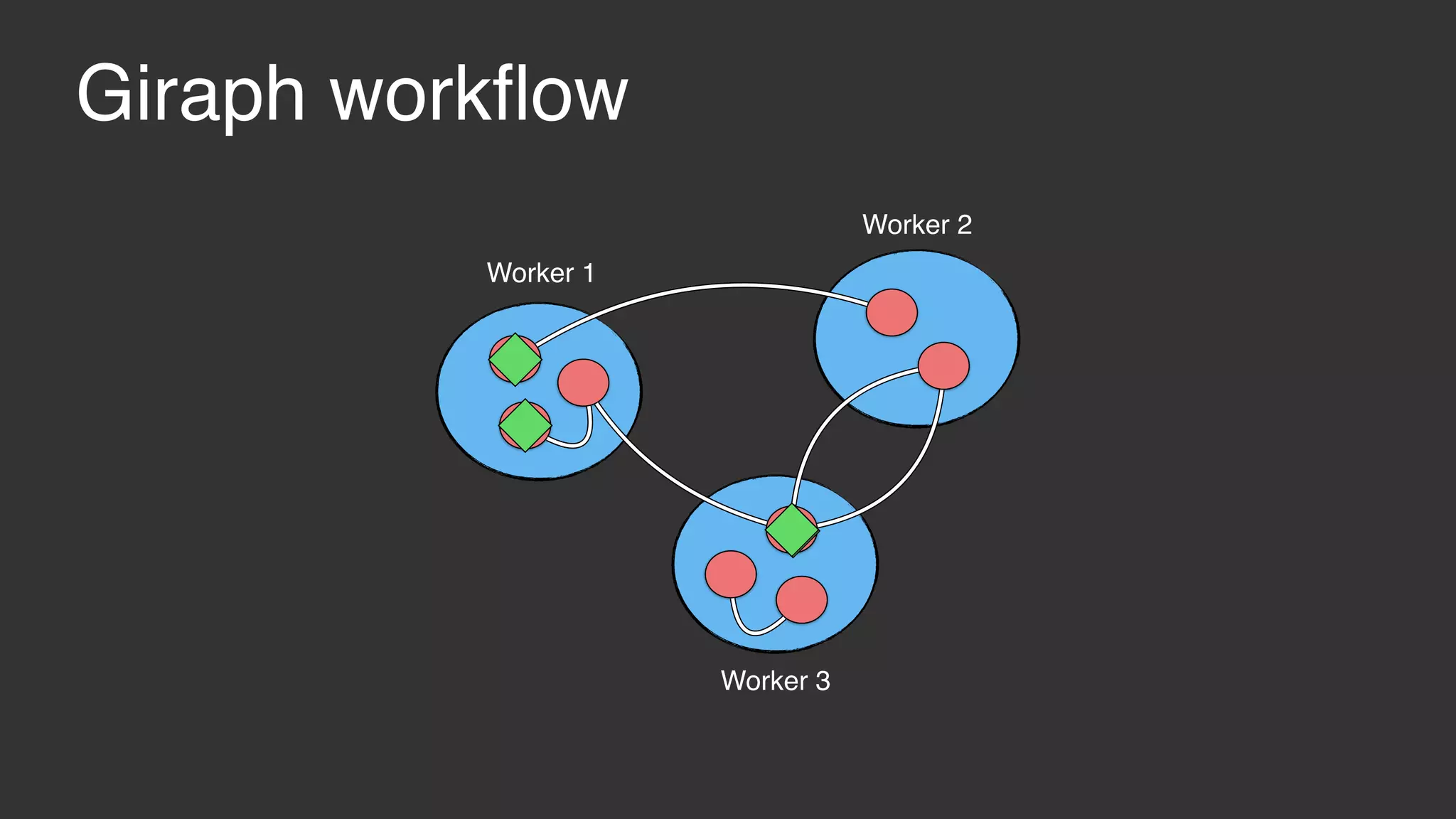

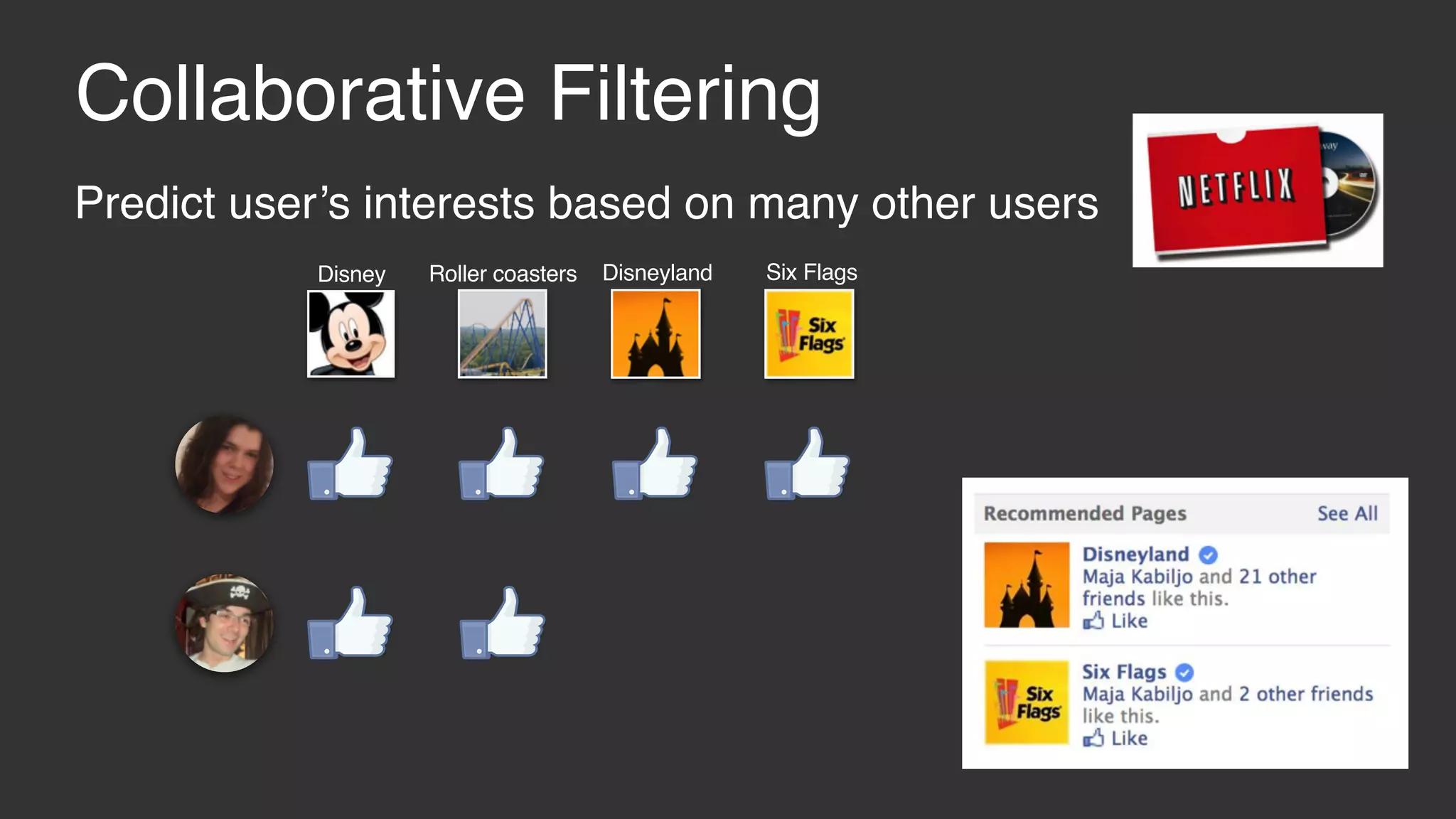


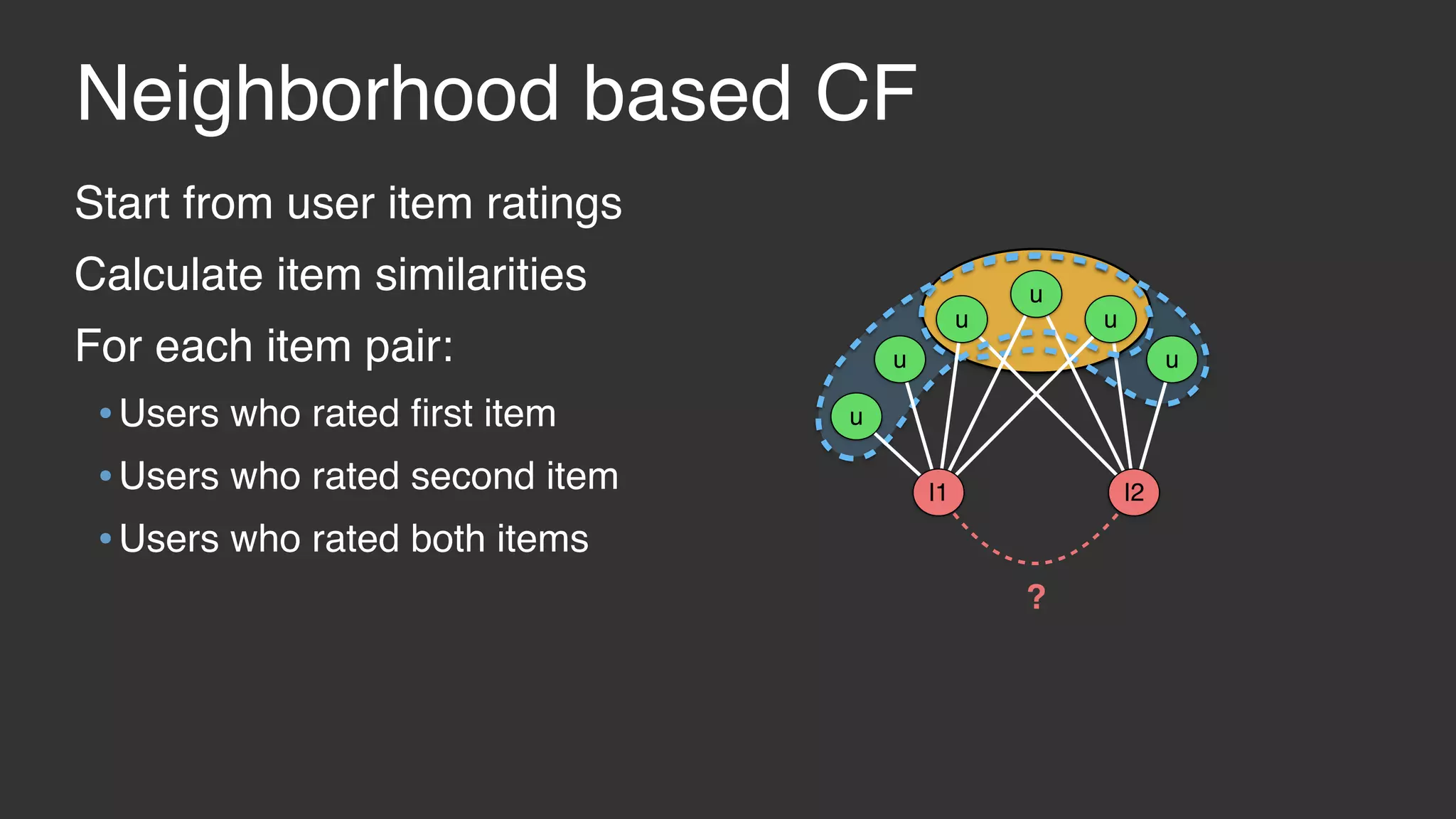
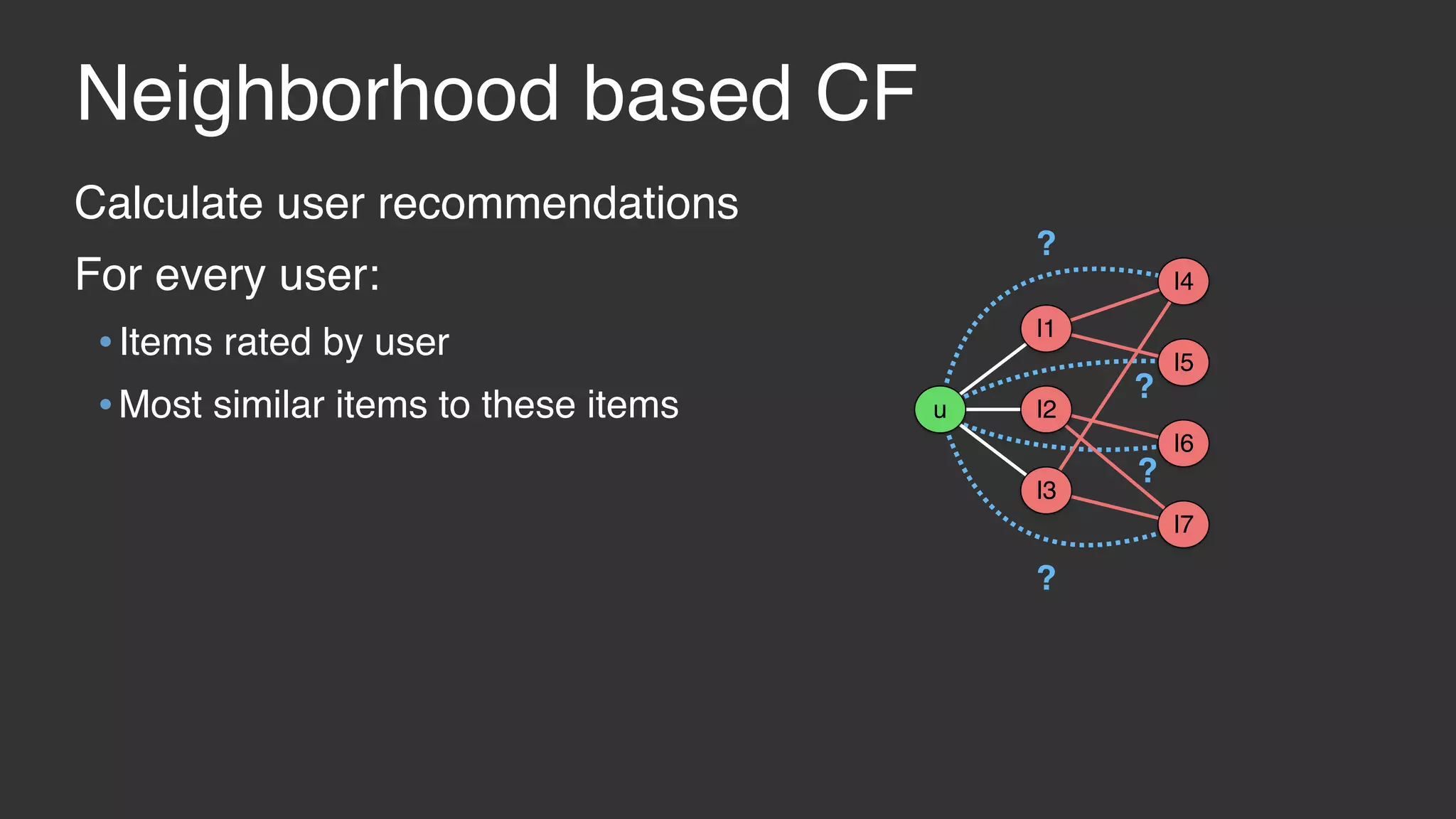

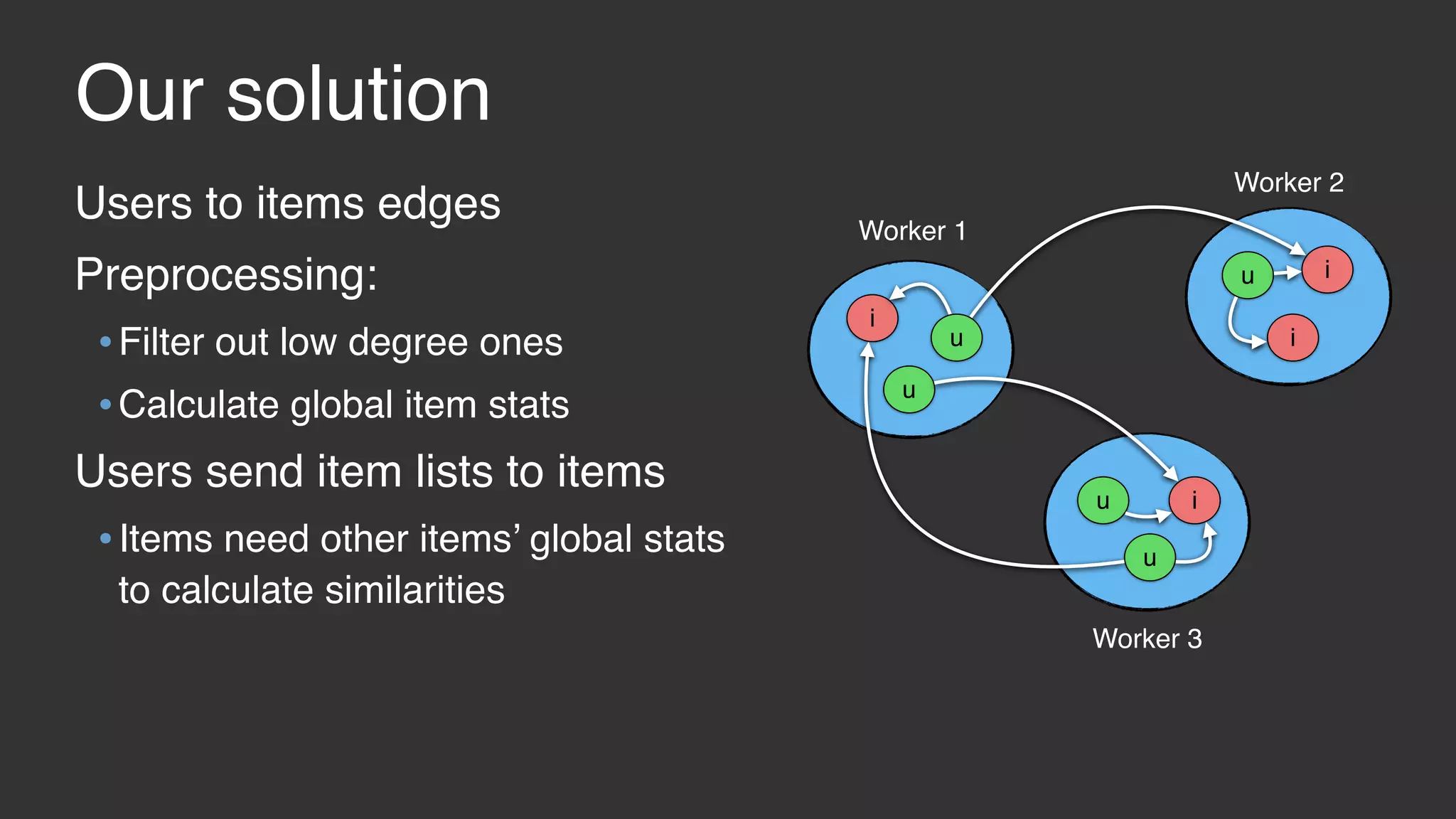





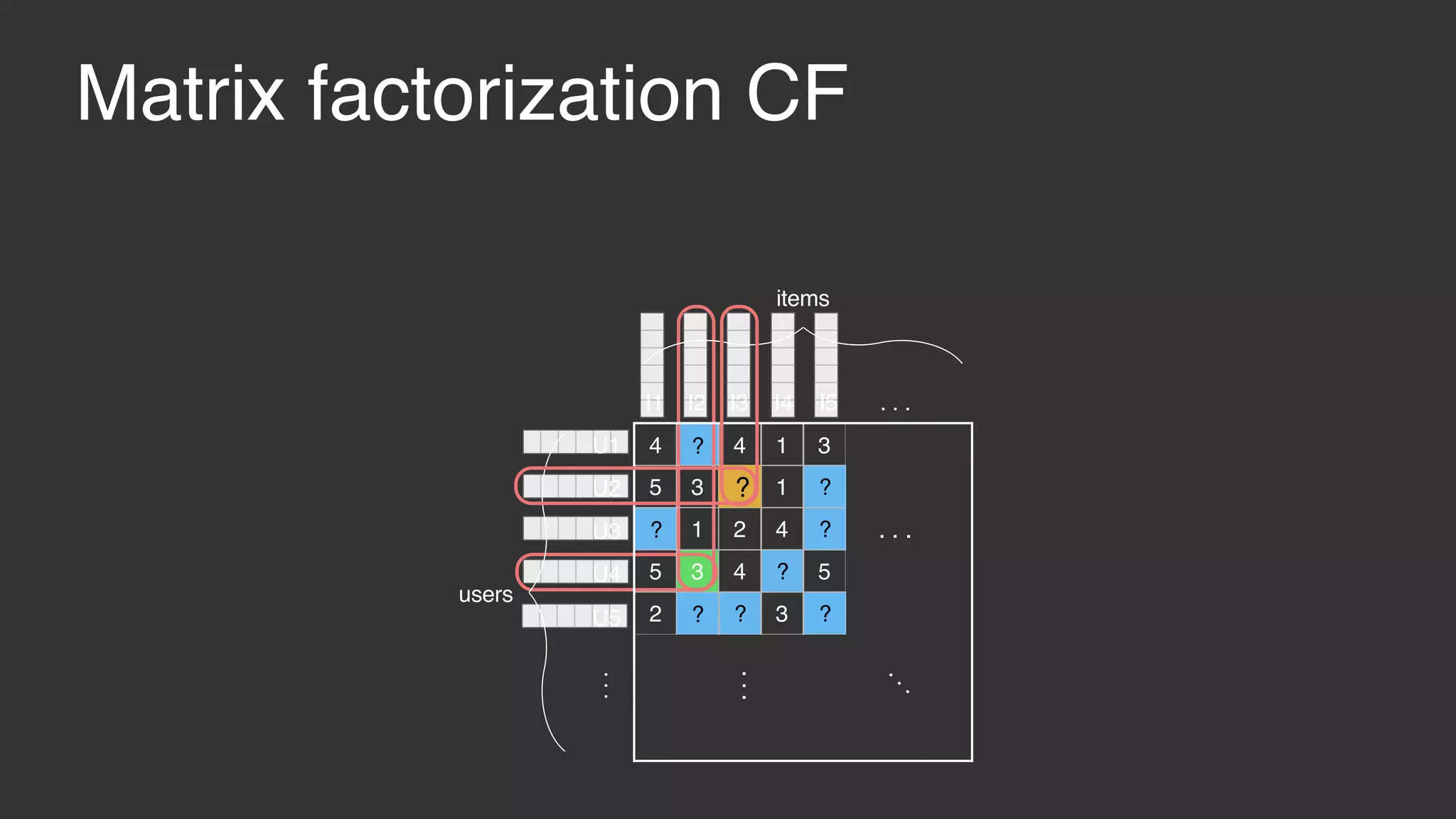

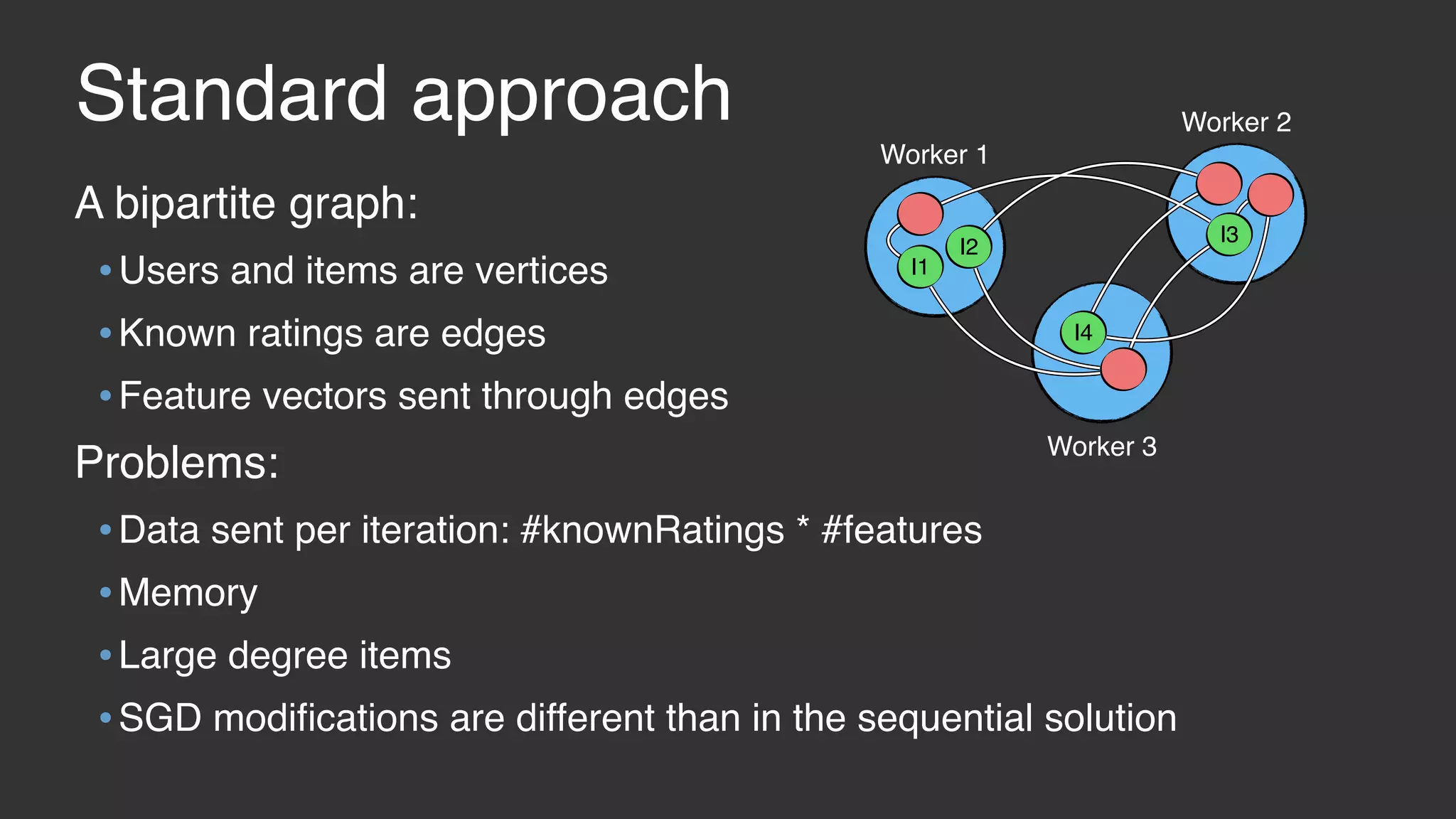

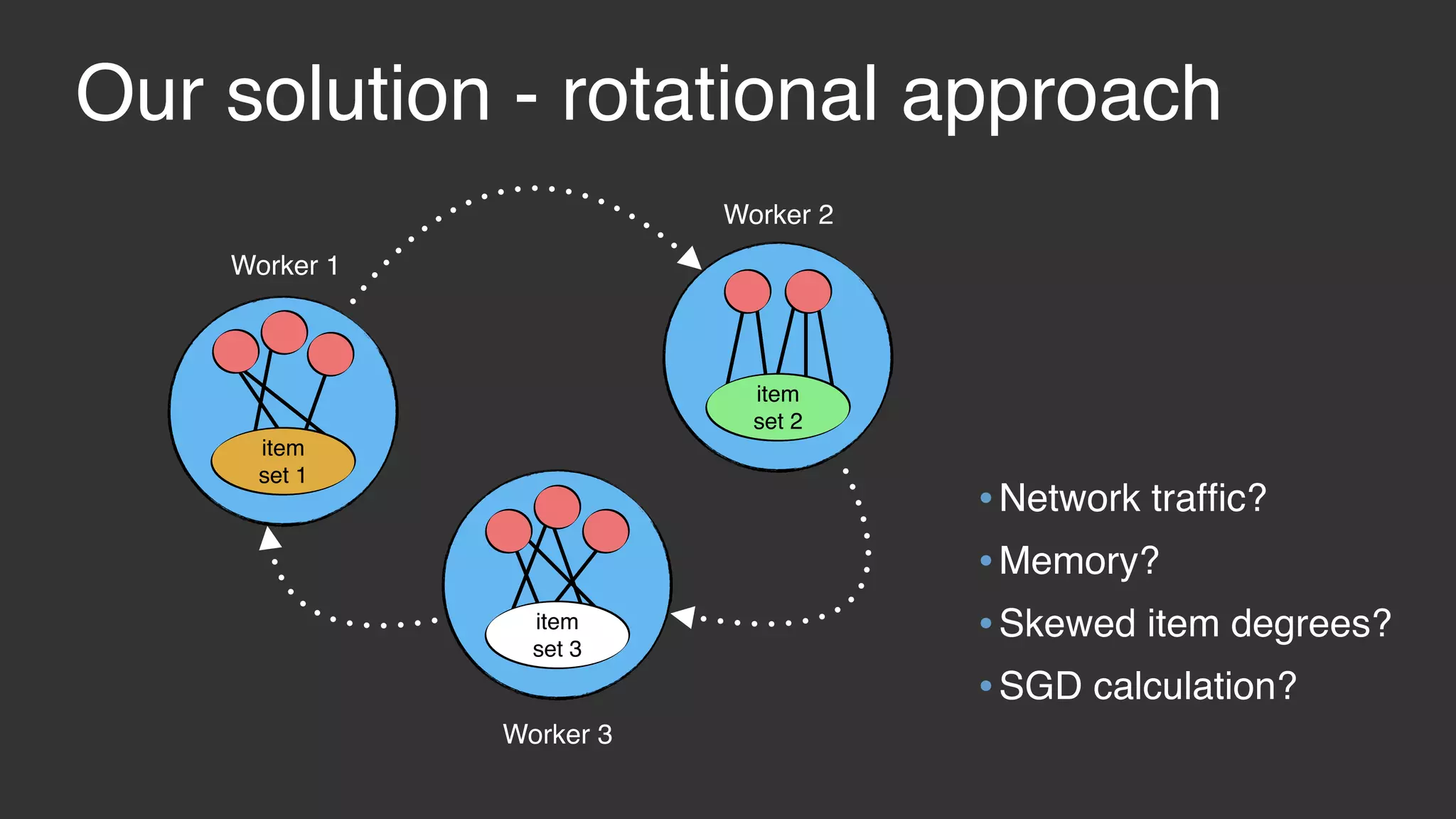
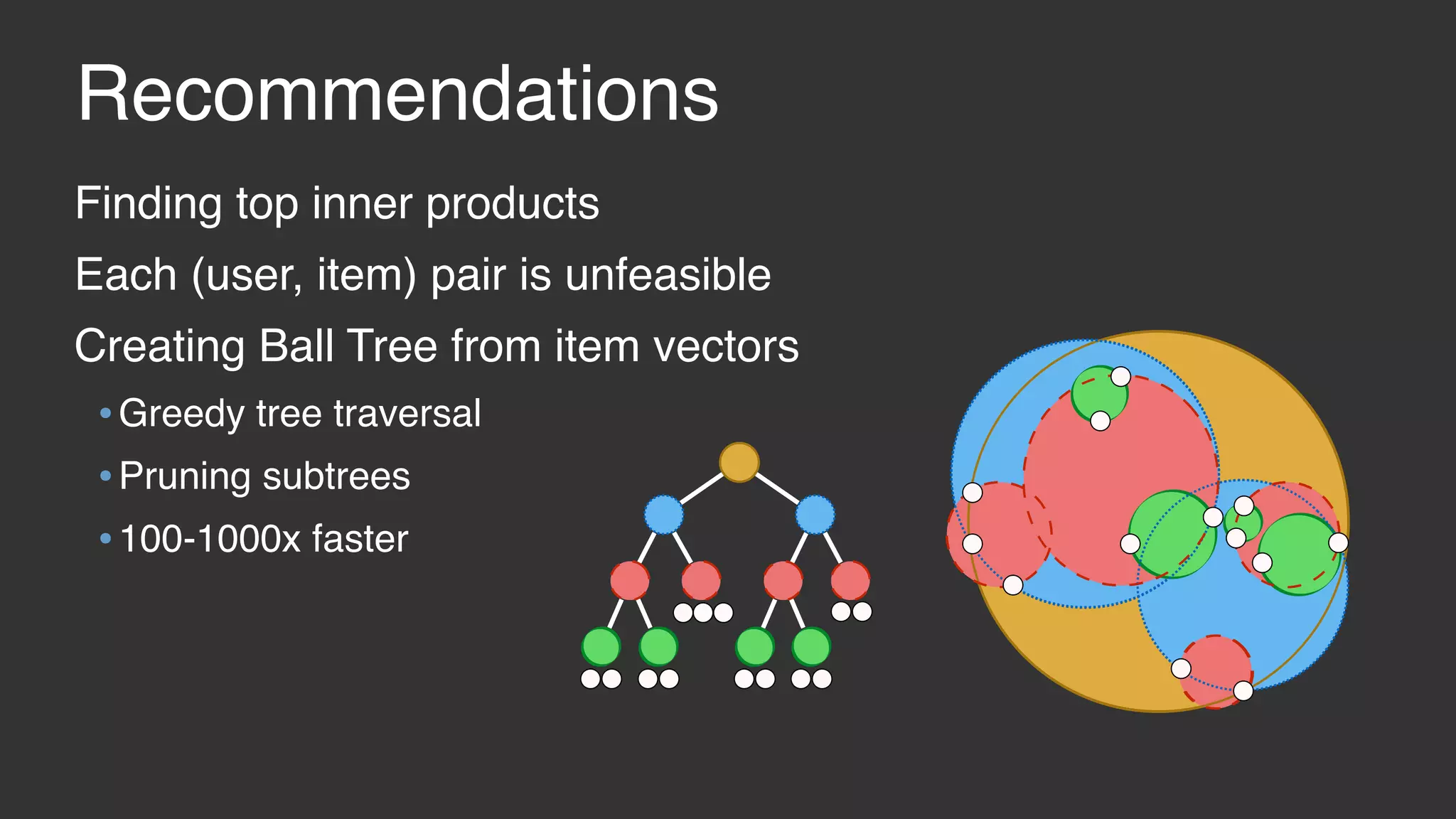


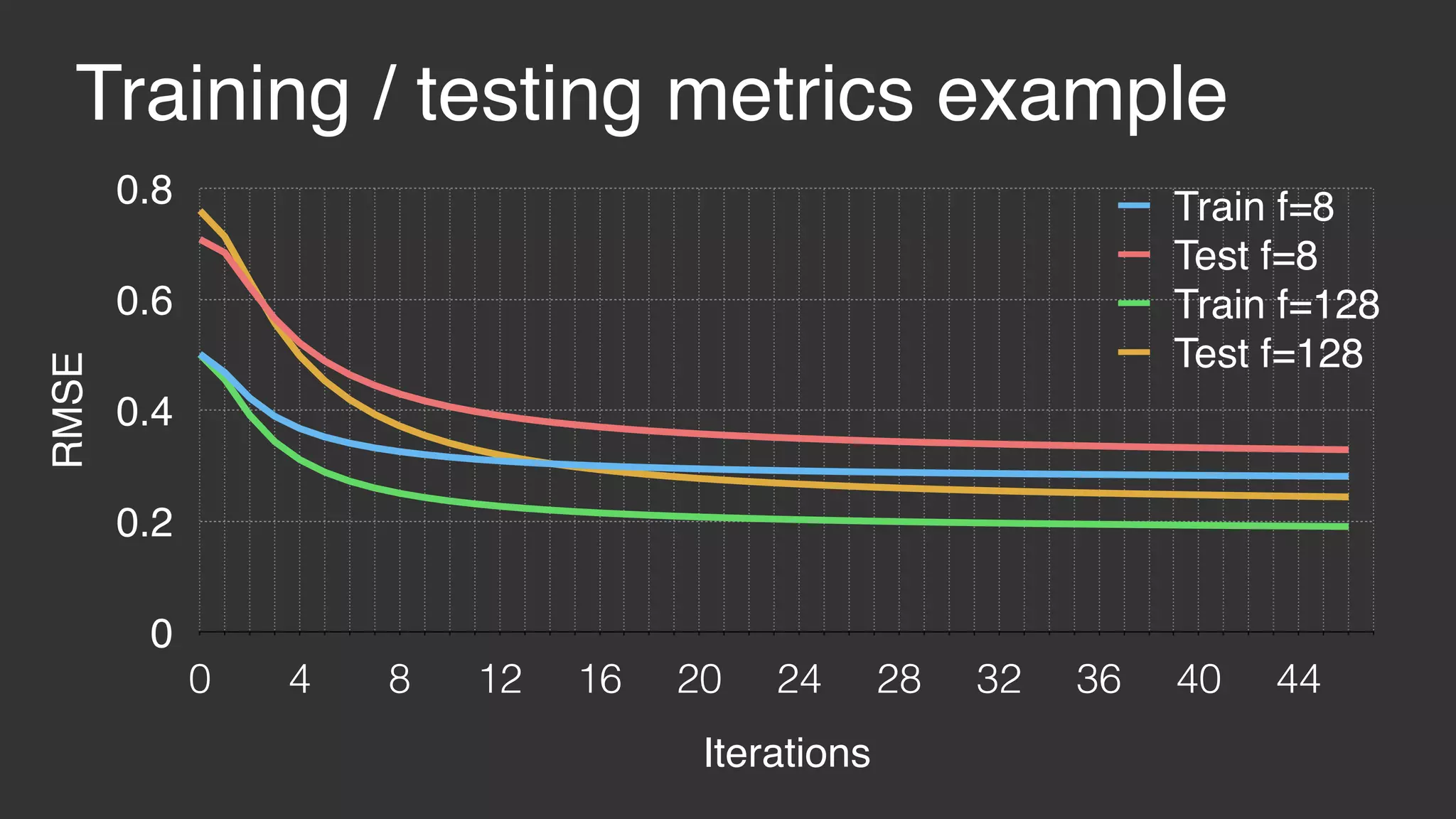
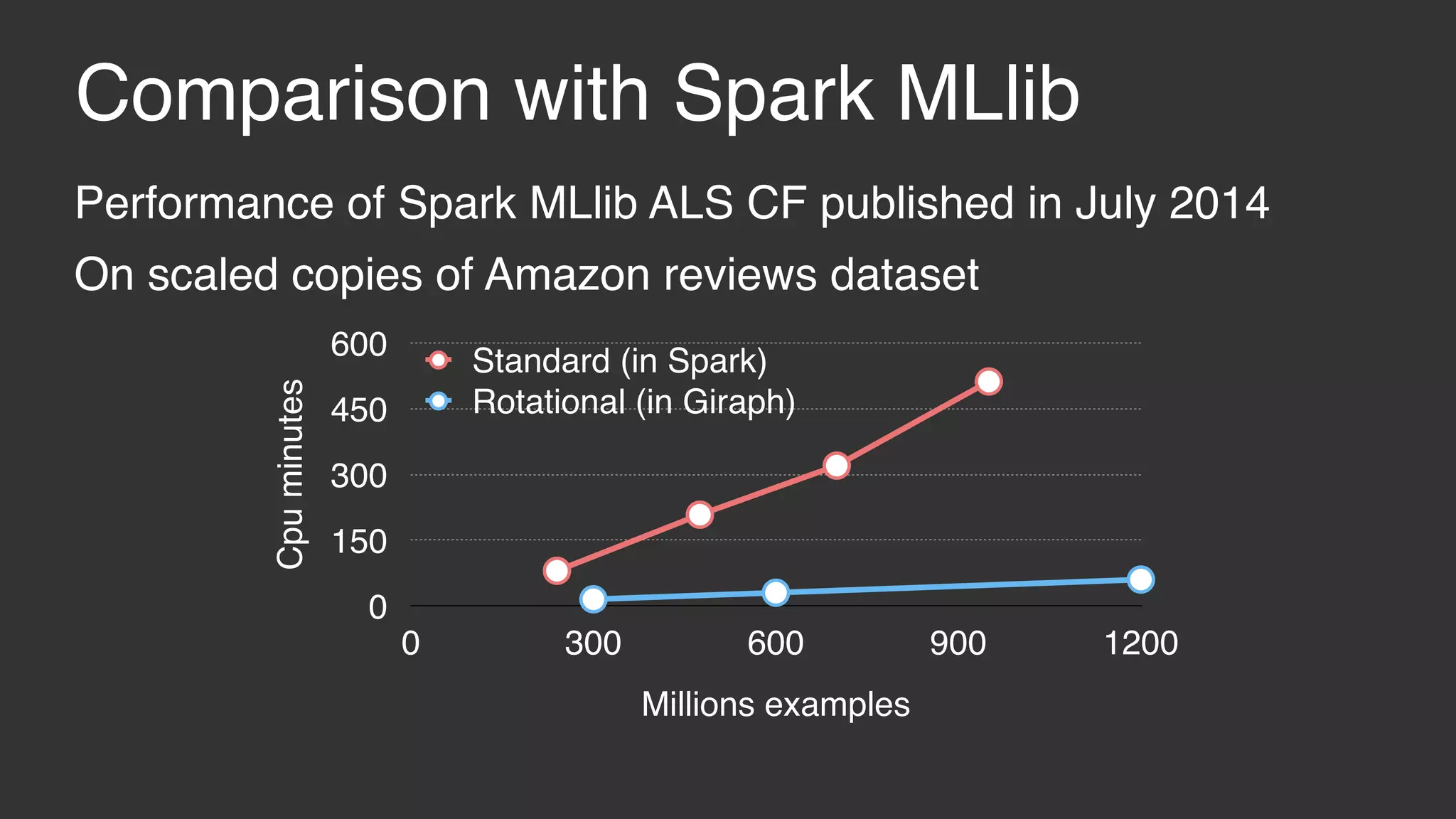





This document discusses large scale collaborative filtering using Apache Giraph. It describes neighborhood-based models and matrix factorization for collaborative filtering. It also details how these techniques were implemented and optimized in Giraph to provide recommendations for billions of Facebook users and ratings. Key optimizations included a rotational approach for matrix factorization to reduce network traffic and memory usage for skewed item degrees.