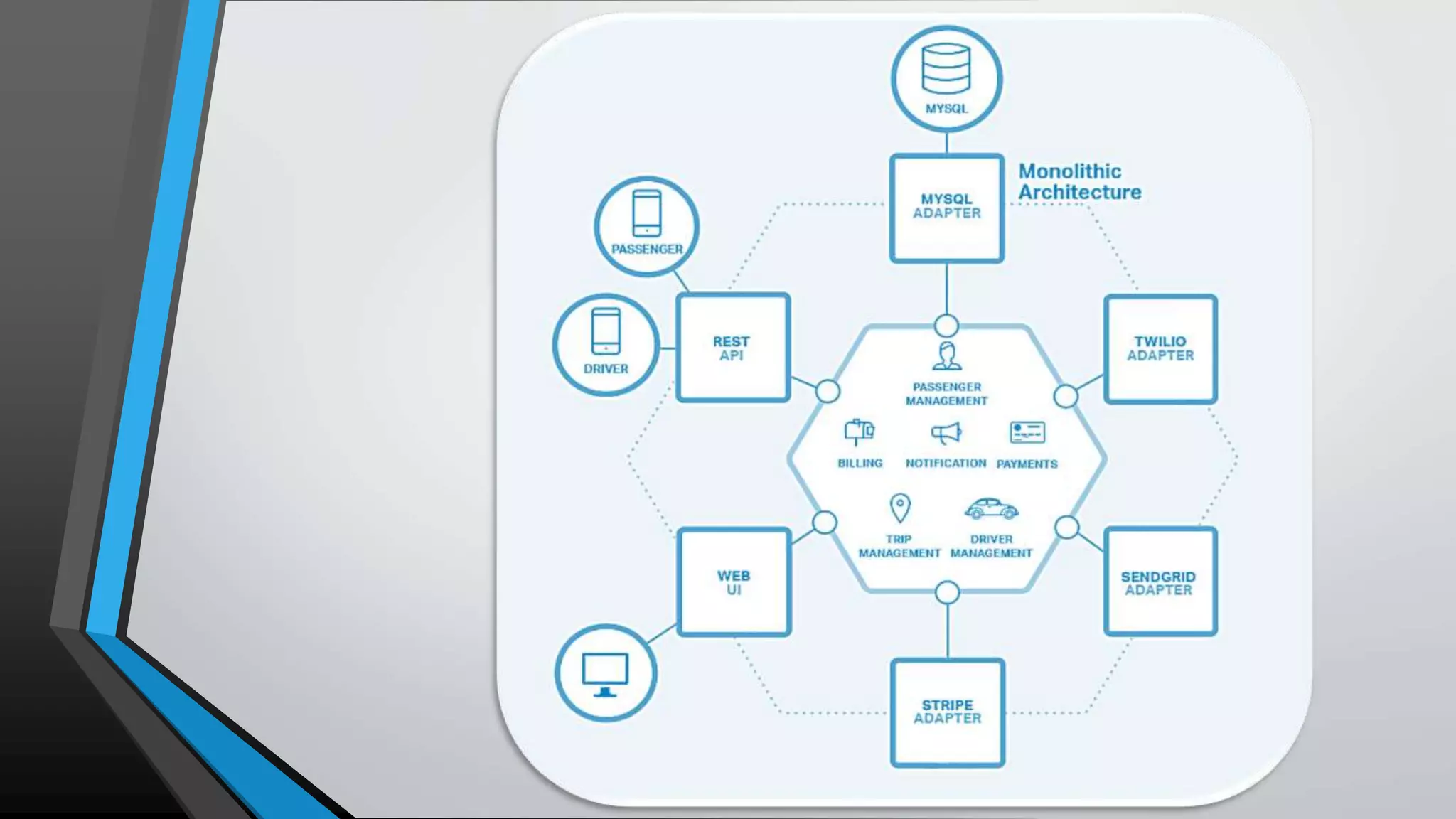
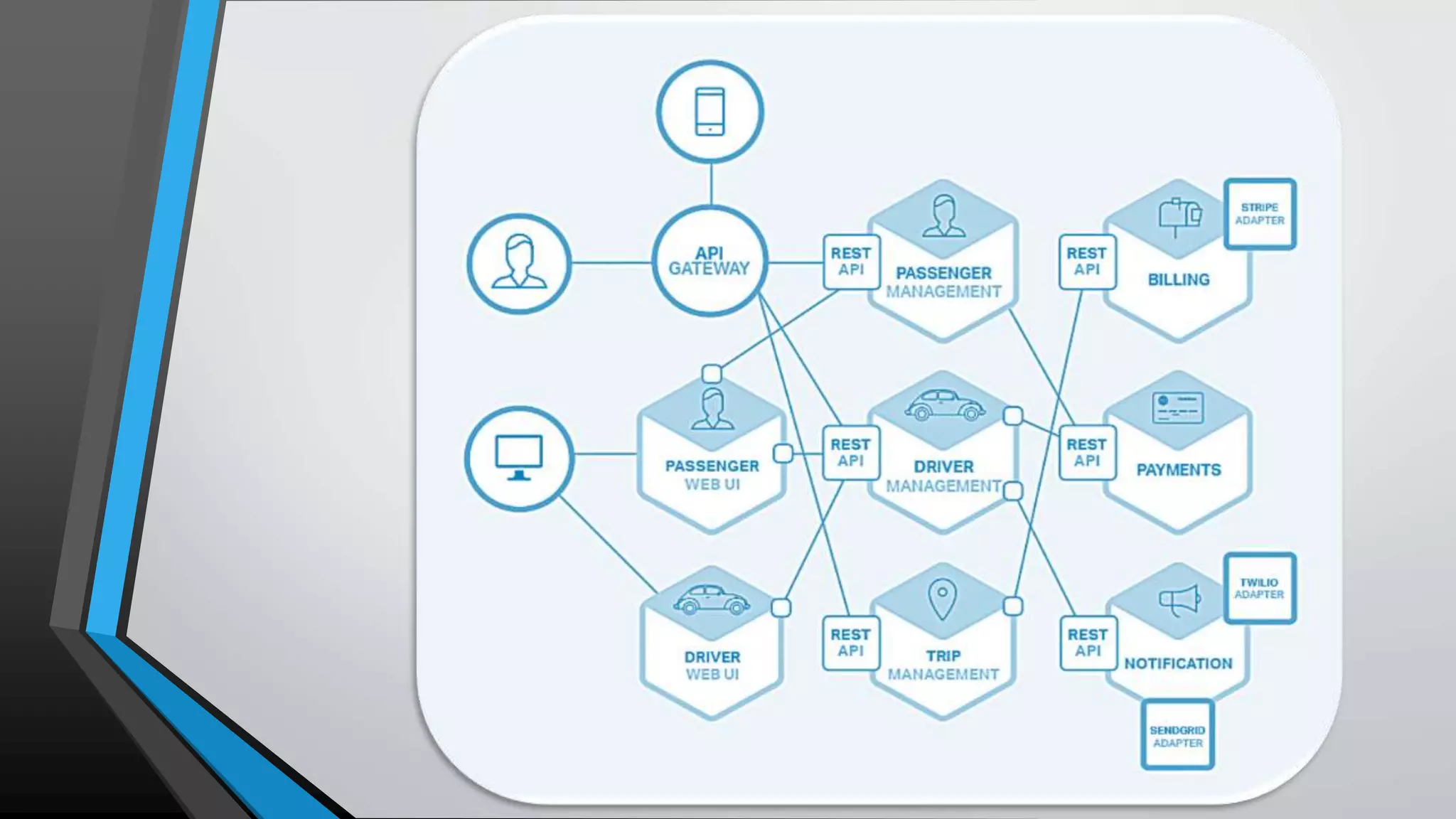
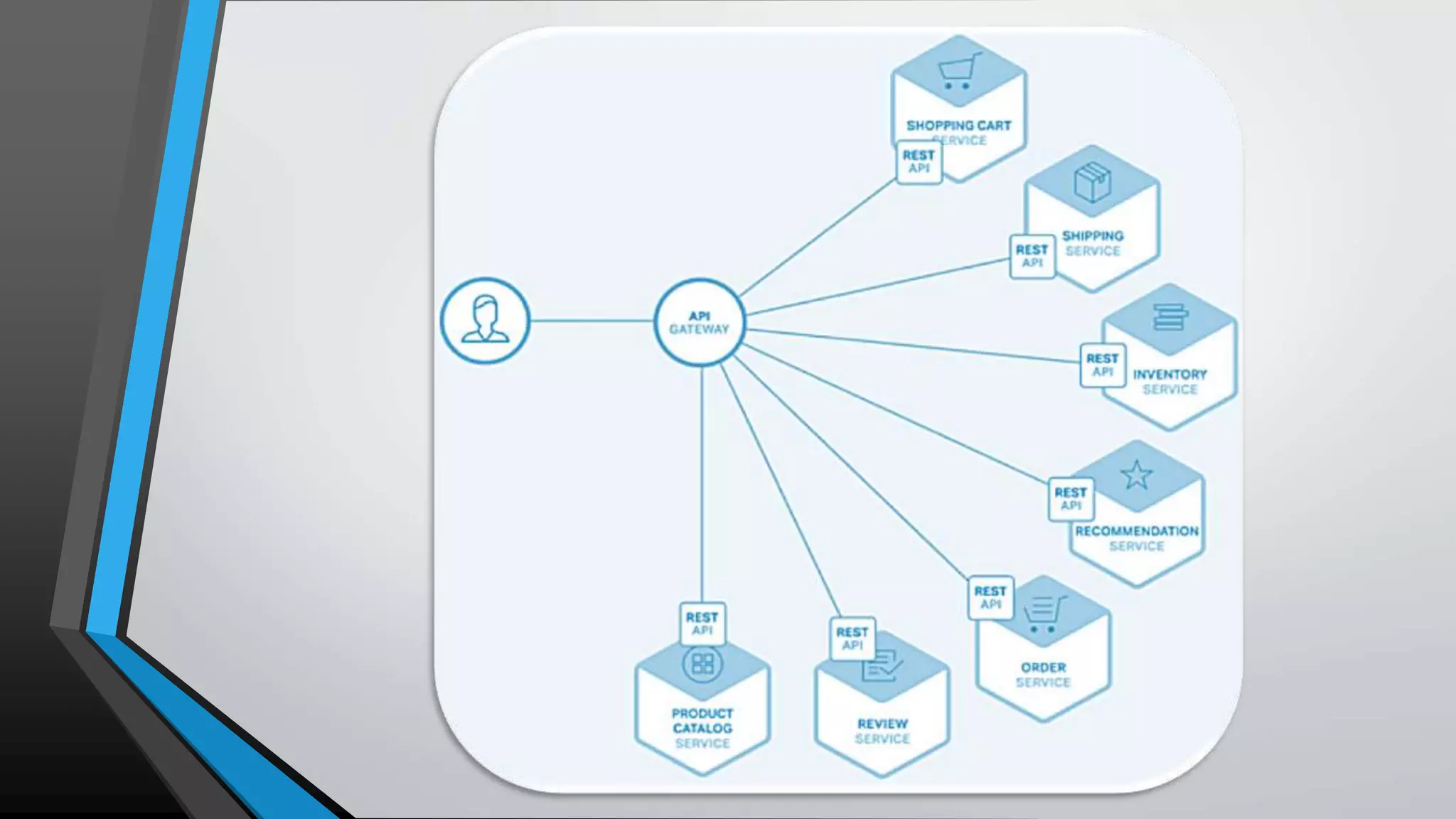
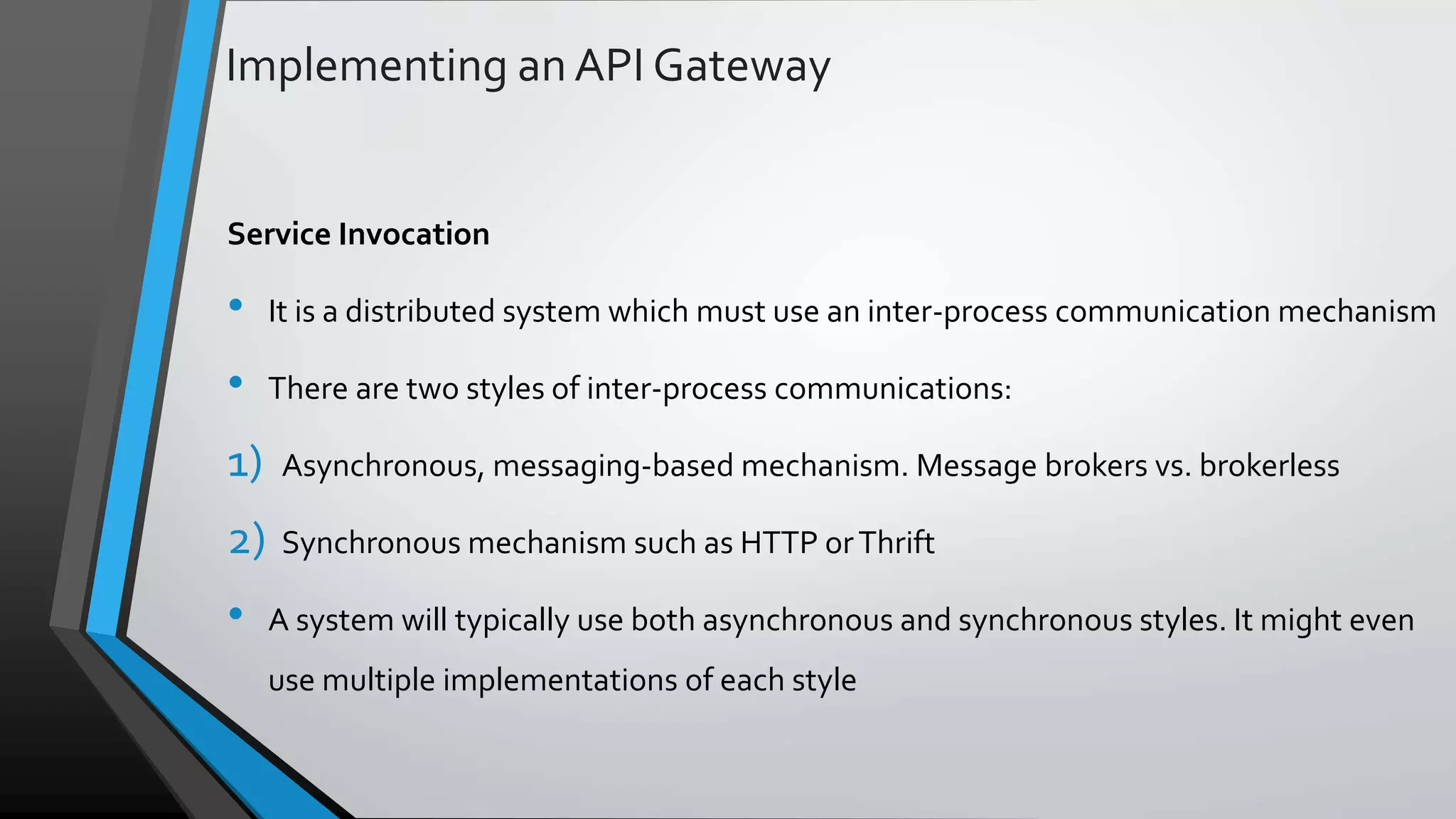
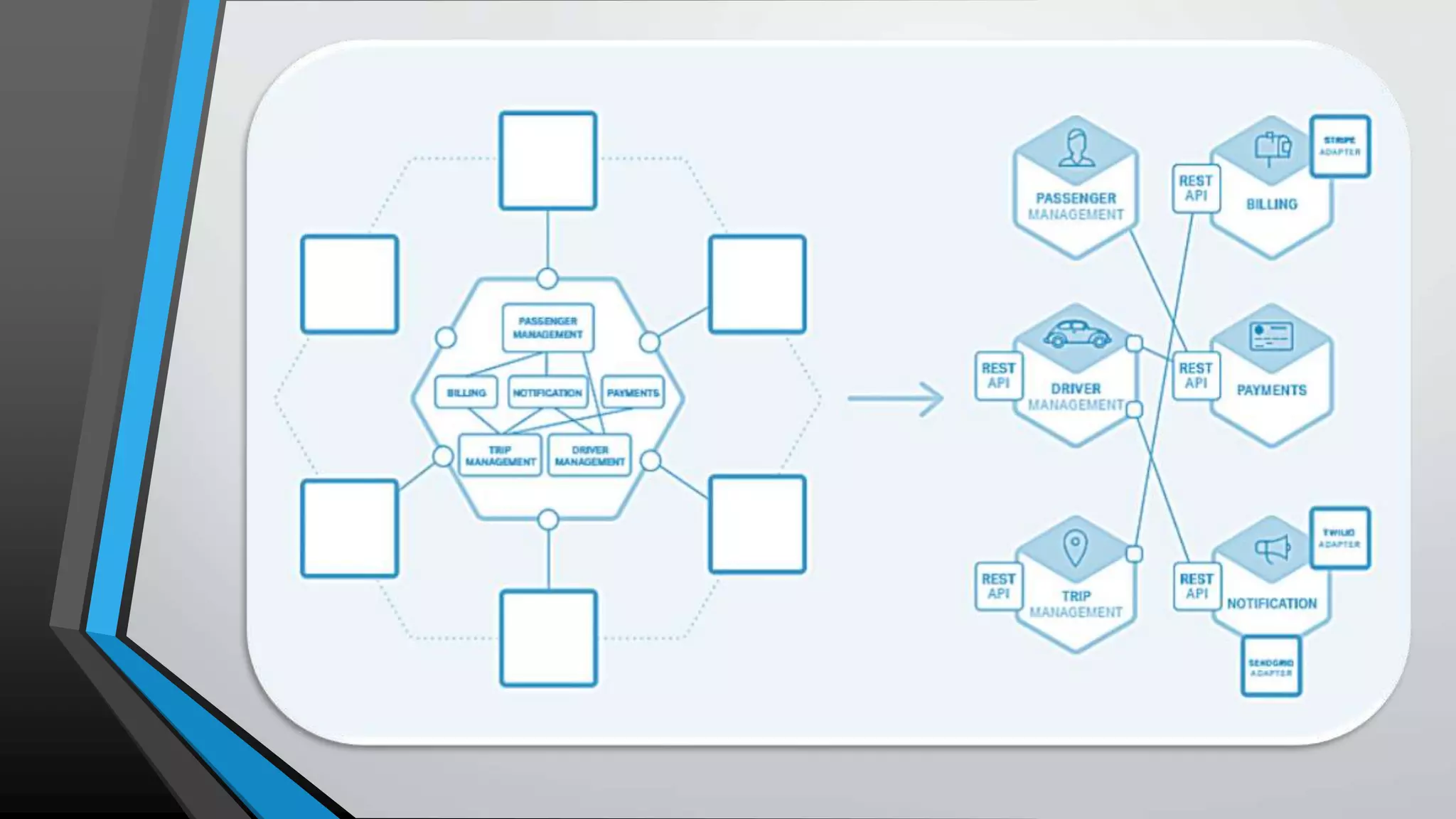
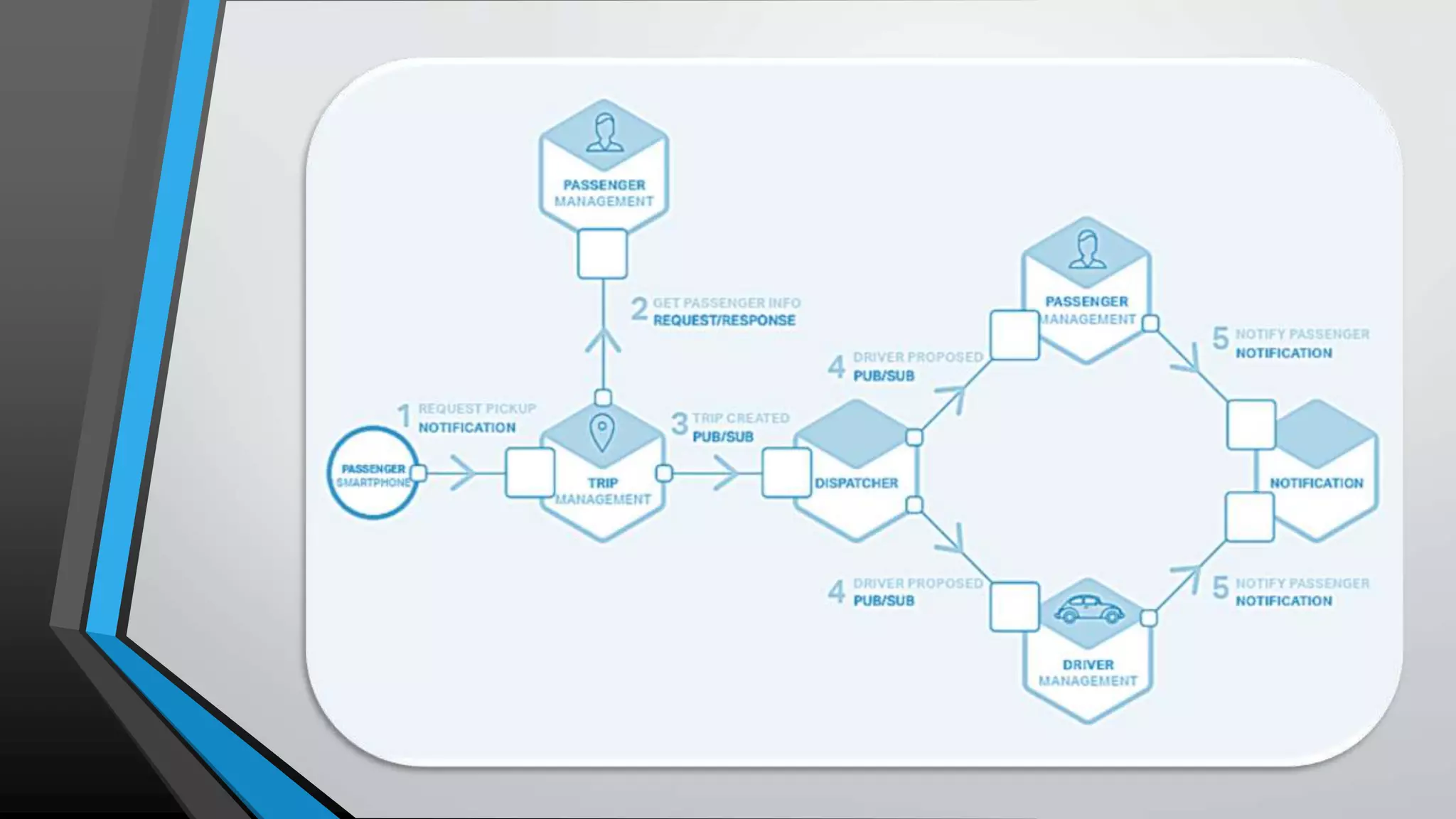
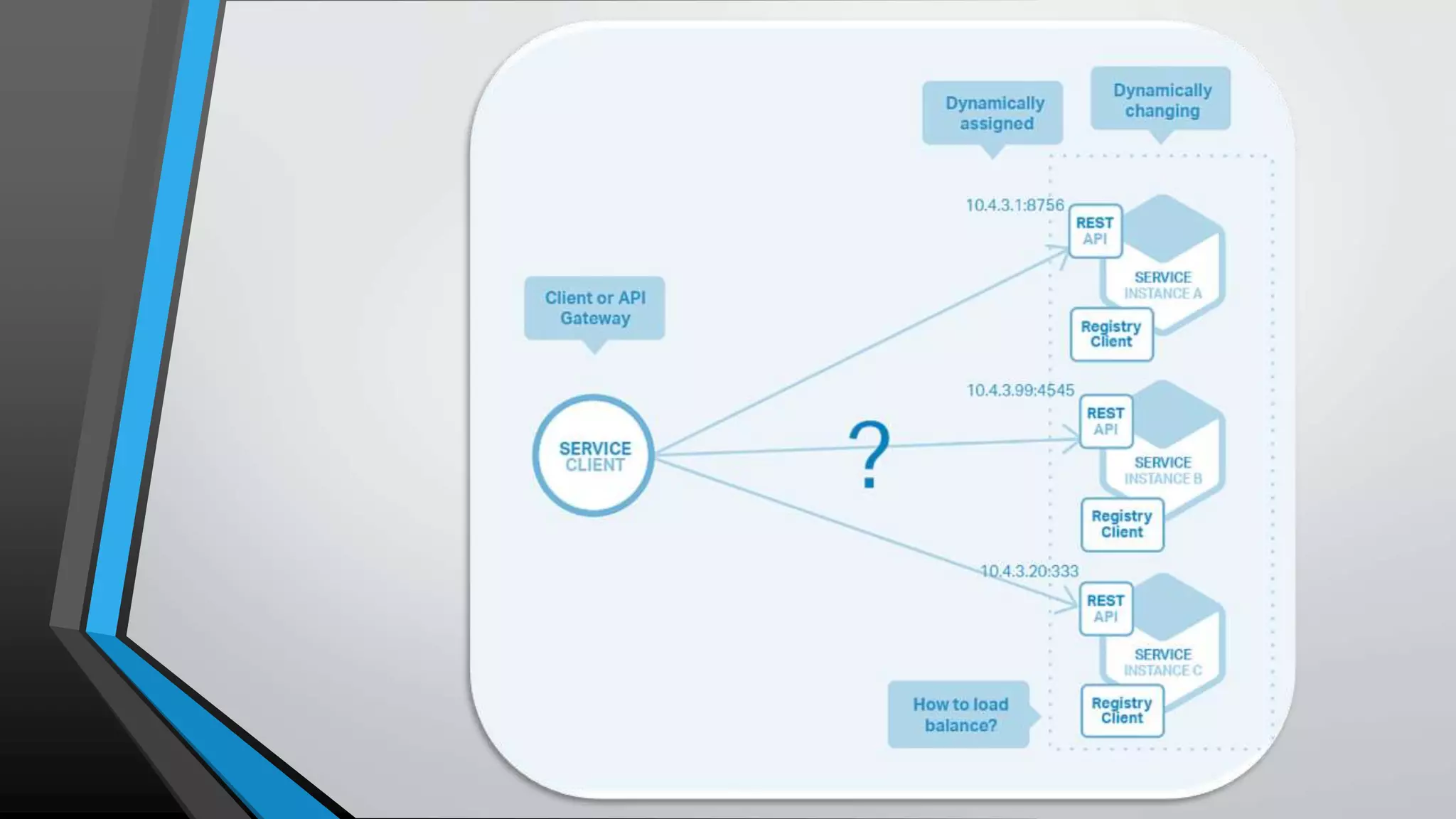
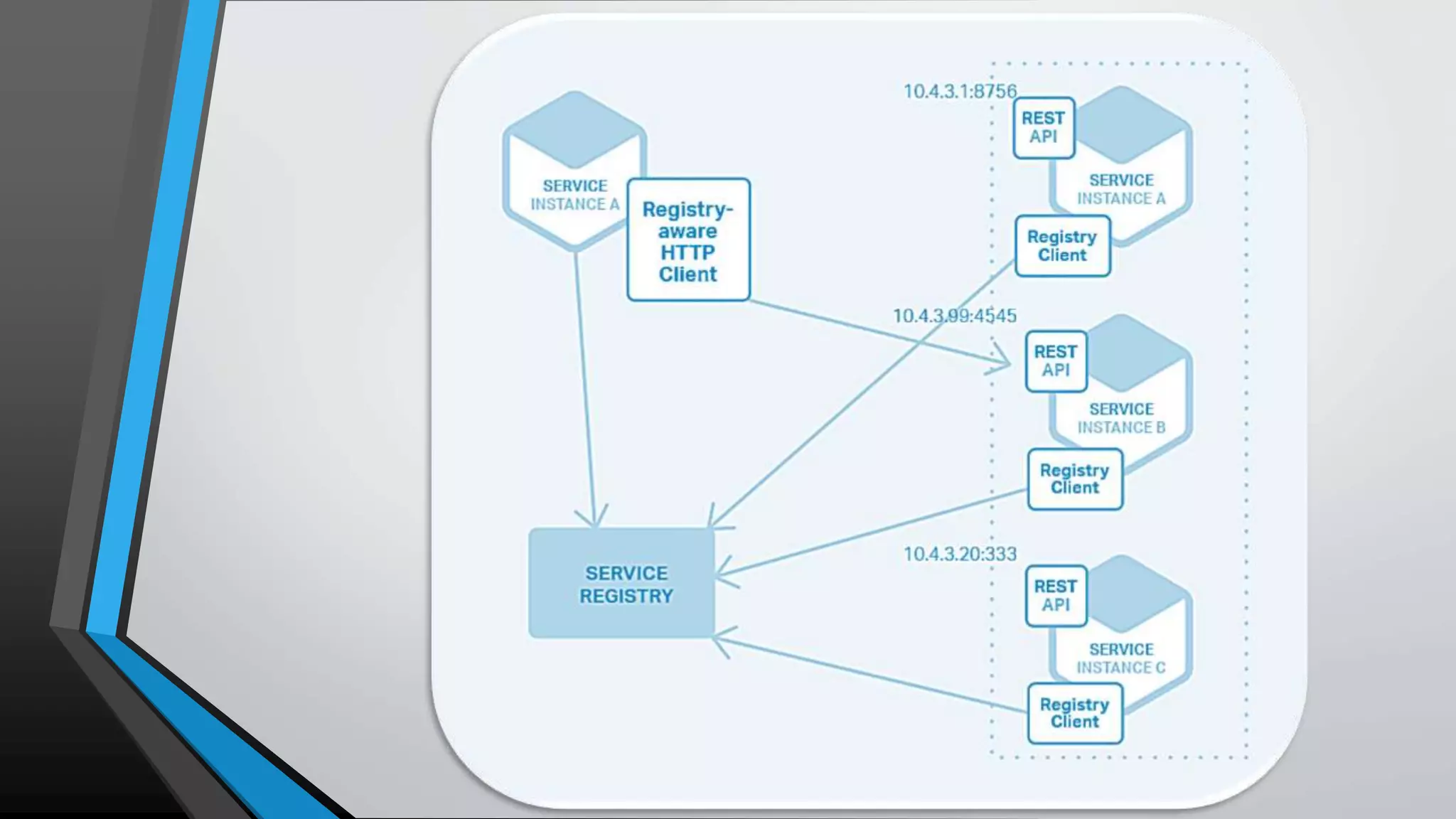
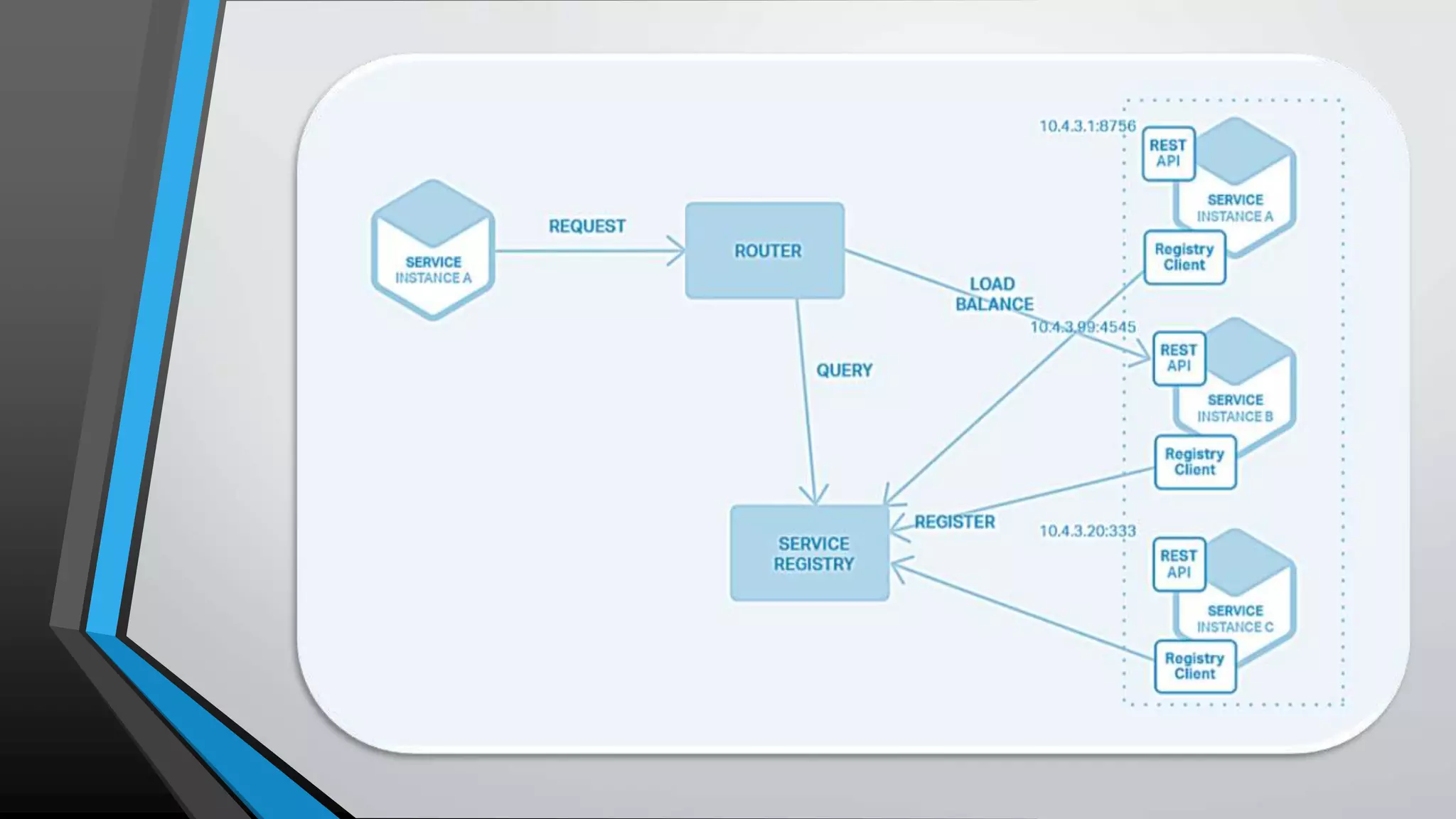
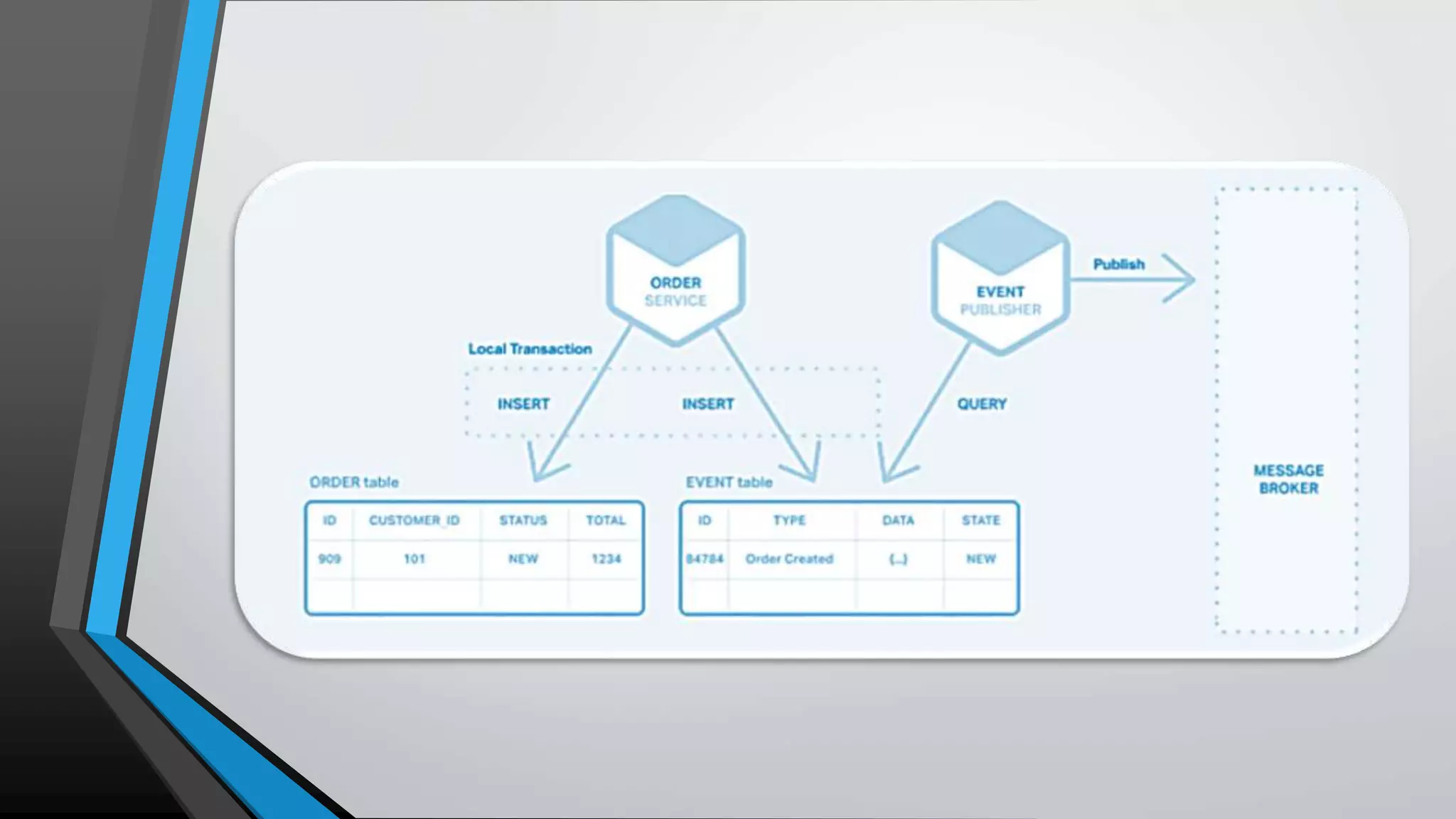
The document provides an overview of microservices architecture, highlighting the transition from monolithic applications to microservices for improved modularity, scalability, and independent deployment. It discusses the benefits and drawbacks of microservices, the necessity of inter-process communication, service discovery, and event-driven data management in this architecture. Key considerations such as API gateways, managing complexity, and handling partial failures are also addressed to illustrate the operational challenges faced when implementing microservices.