Download as PDF, PPTX





![Af_Array An array of numbers is stored as an Af_Array object. This array is stored on GPU. [1] pry(main)> a = ArrayFire::Af_Array.new 2, [2,2],[1,2,3,4] No Name Array [2 2 1 1] Offsets: [0 0 0 0] Strides: [1 2 4 4] 1.0000 3.0000 2.0000 4.0000 => #<ArrayFire::Af_Array:0x000000020aeab8>](https://image.slidesharecdn.com/highperformancegpucomputingwithruby2-171101051115/75/High-performance-GPU-computing-with-Ruby-6-2048.jpg)
![[2] pry(main)> b = a + a No Name Array [2 2 1 1] Offsets: [0 0 0 0] Strides: [1 2 4 4] 2.0000 6.0000 4.0000 8.0000 => #<ArrayFire::Af_Array:0x000000020625c8>](https://image.slidesharecdn.com/highperformancegpucomputingwithruby2-171101051115/75/High-performance-GPU-computing-with-Ruby-7-2048.jpg)
![[3] pry(main)> b = a * a No Name Array [2 2 1 1] Offsets: [0 0 0 0] Strides: [1 2 4 4] 1.0000 9.0000 4.0000 16.0000 => #<ArrayFire::Af_Array:0x00000001fe6f90>](https://image.slidesharecdn.com/highperformancegpucomputingwithruby2-171101051115/75/High-performance-GPU-computing-with-Ruby-8-2048.jpg)
![VALUE arf_init(int argc, VALUE* argv, VALUE self) { afstruct* afarray; Data_Get_Struct(self, afstruct, afarray); dim_t ndims = (dim_t)NUM2LONG(argv[0]); dim_t* dimensions = (dim_t*)malloc(ndims * sizeof(dim_t)); dim_t count = 1; for (size_t index = 0; index < ndims; index++) { dimensions[index] = (dim_t)NUM2LONG(RARRAY_AREF(argv[1], index)); count *= dimensions[index]; } double* host_array = (double*)malloc(count * sizeof(double)); for (size_t index = 0; index < count; index++) { host_array[index] = (double)NUM2DBL(RARRAY_AREF(argv[2], index)); } af_create_array(&afarray->carray, host_array, ndims, dimensions, f64) return self; }](https://image.slidesharecdn.com/highperformancegpucomputingwithruby2-171101051115/75/High-performance-GPU-computing-with-Ruby-9-2048.jpg)


![=> #<ArrayFire::Af_Array:0x00000001591db0> [3] pry(main)> result = ArrayFire::BLAS.matmul(left, right, :AF_MAT_NONE, :AF_MAT_NONE) No Name Array [3 2 1 1] -39.0000 -74.0000 68.0000 -17.0000 86.0000 118.0000](https://image.slidesharecdn.com/highperformancegpucomputingwithruby2-171101051115/75/High-performance-GPU-computing-with-Ruby-12-2048.jpg)








![vadd_kernel_src = <<-EOS extern "C" { __global__ void matSum(int *a, int *b, int *c) { int tid = blockIdx.x; if (tid < 100) c[tid] = a[tid] + b[tid]; } } EOS f = compile(vadd_kernel_src) puts f.path](https://image.slidesharecdn.com/highperformancegpucomputingwithruby2-171101051115/75/High-performance-GPU-computing-with-Ruby-26-2048.jpg)



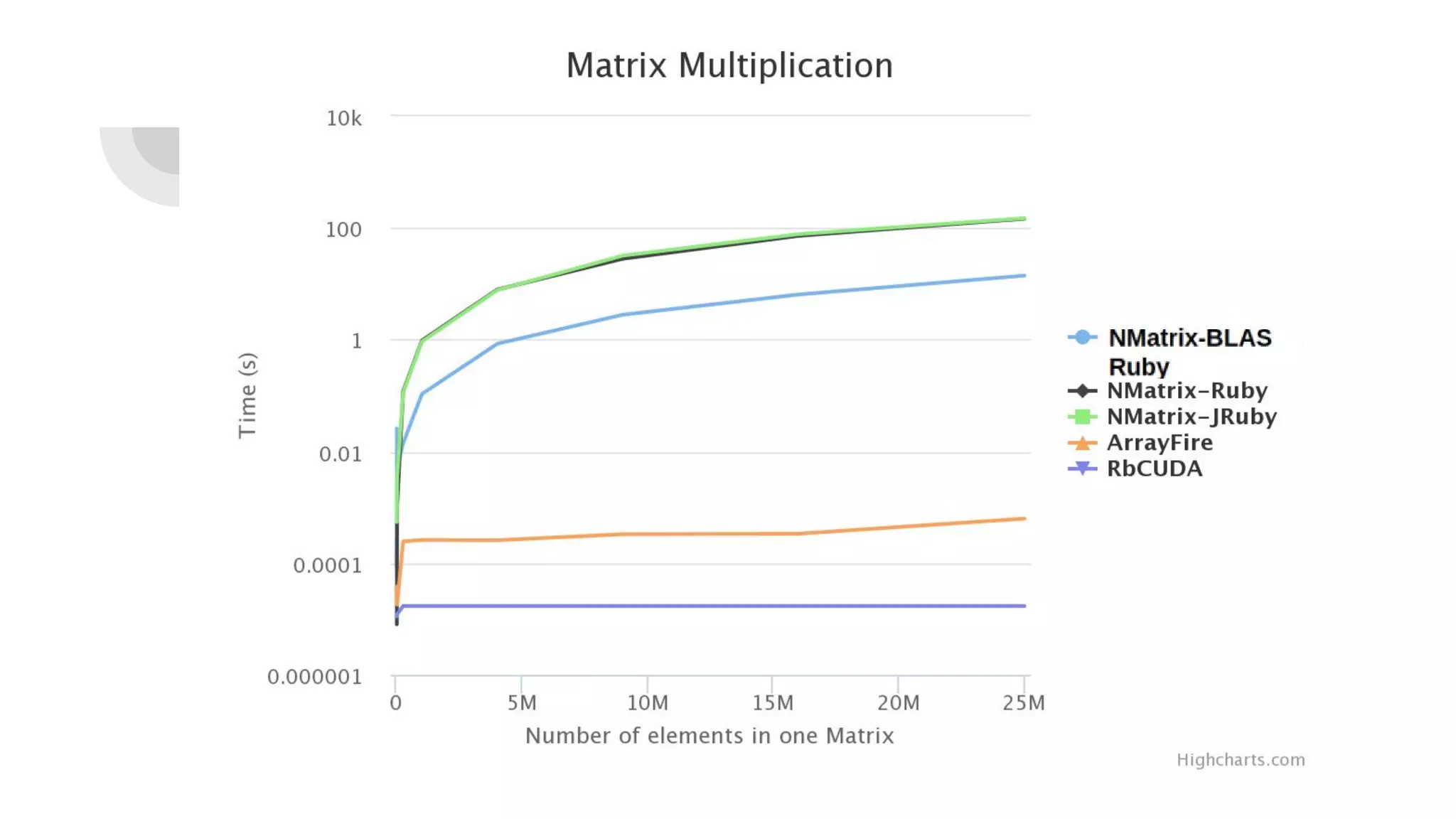





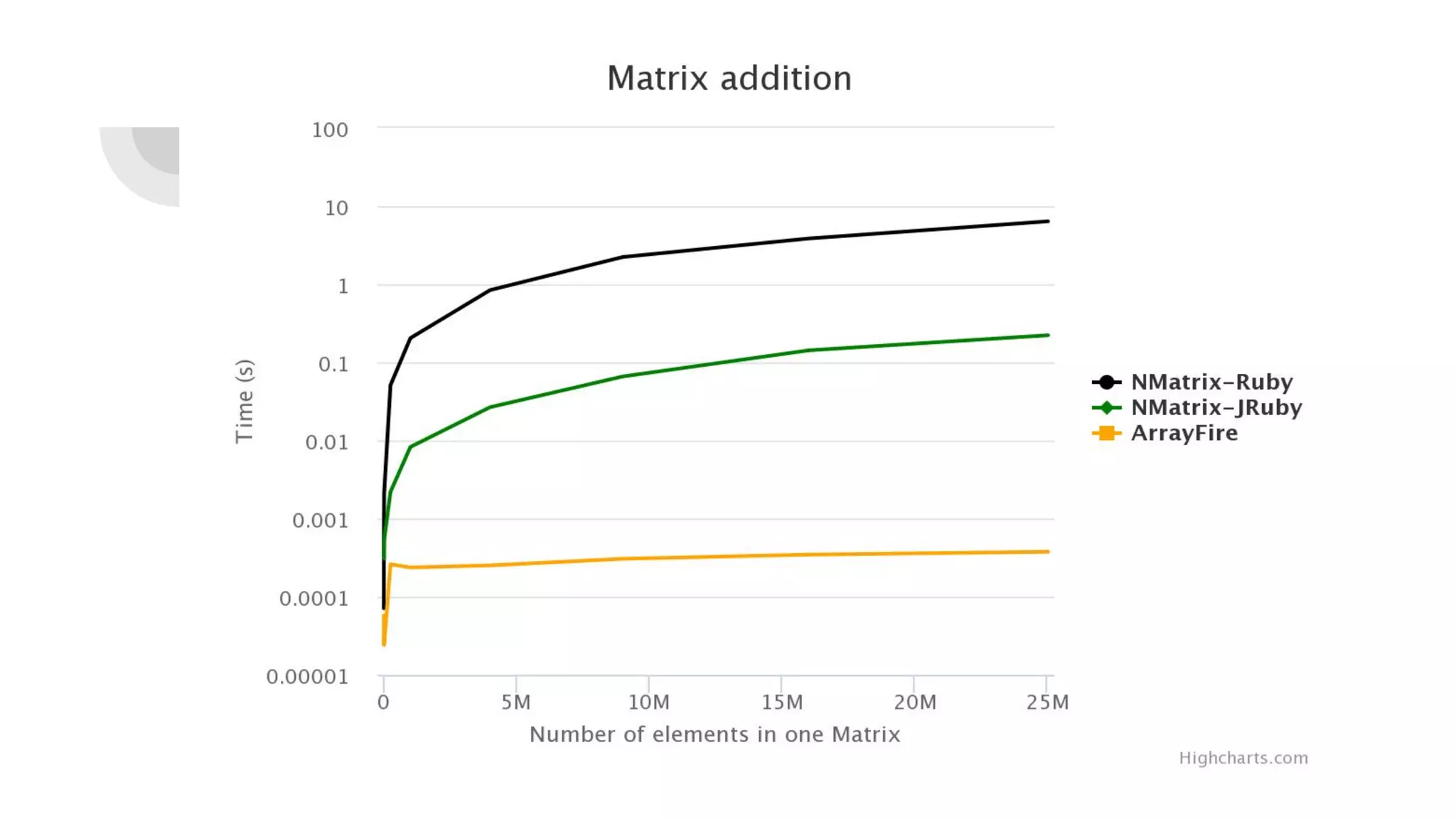
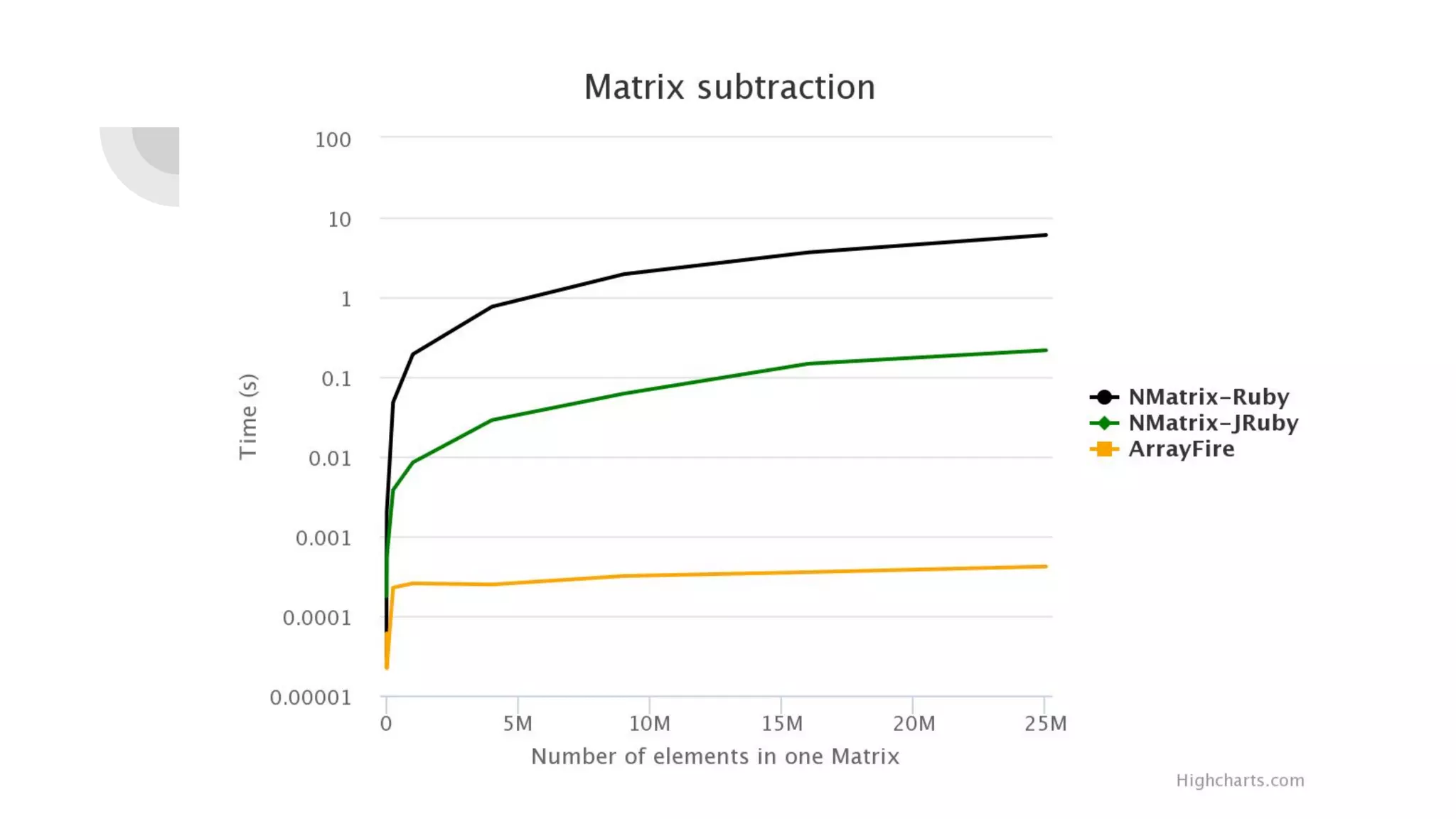
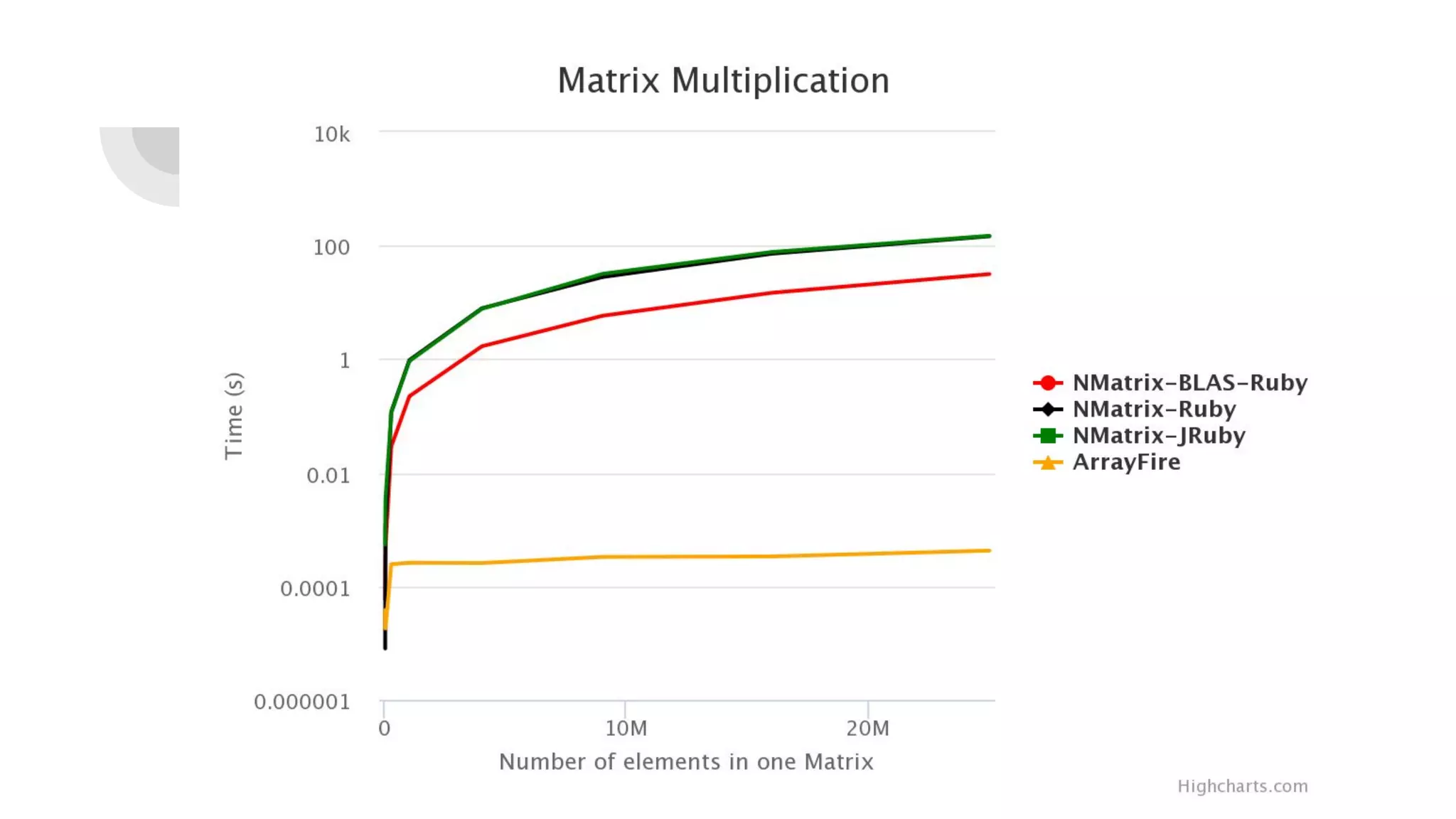
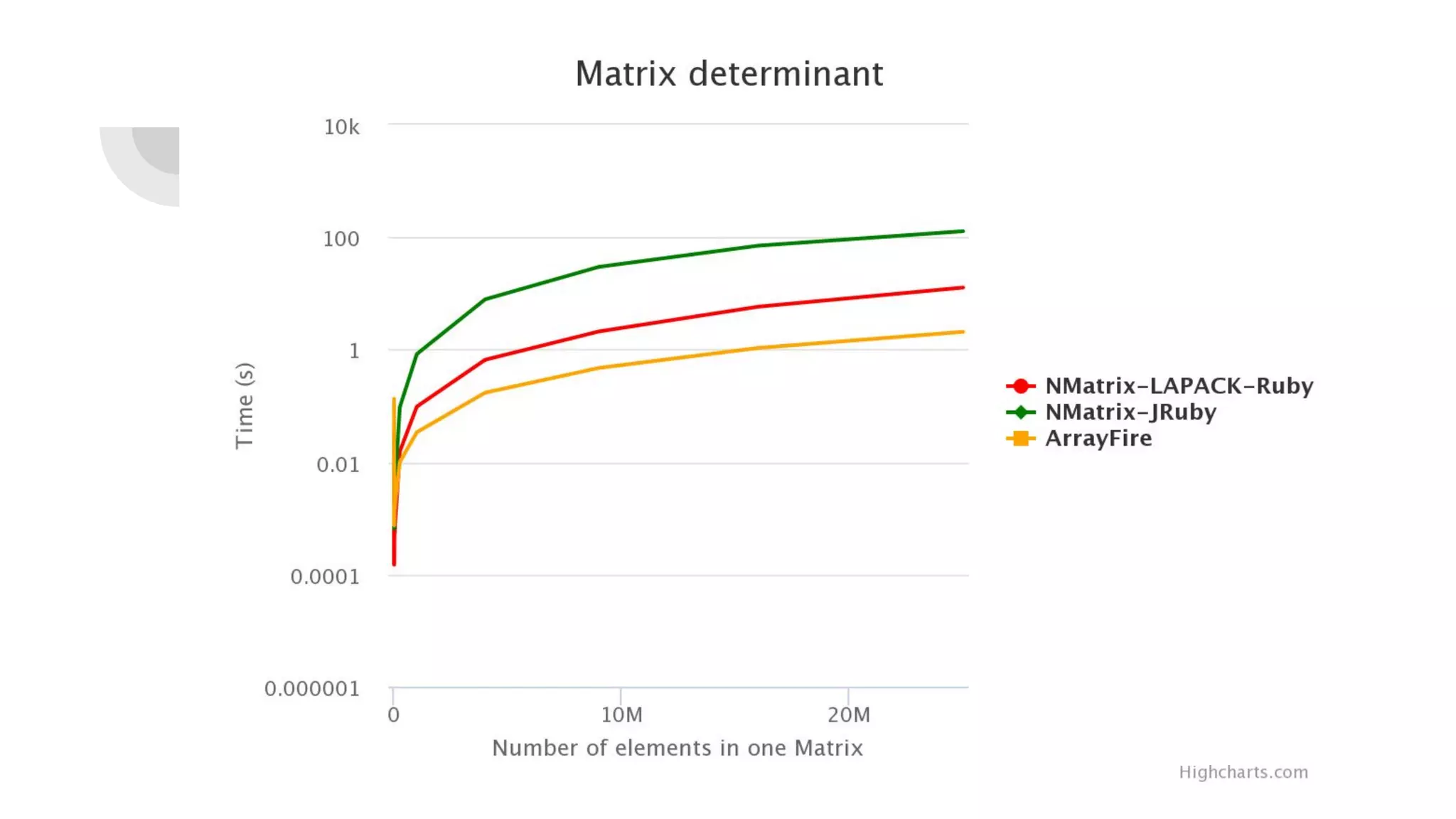
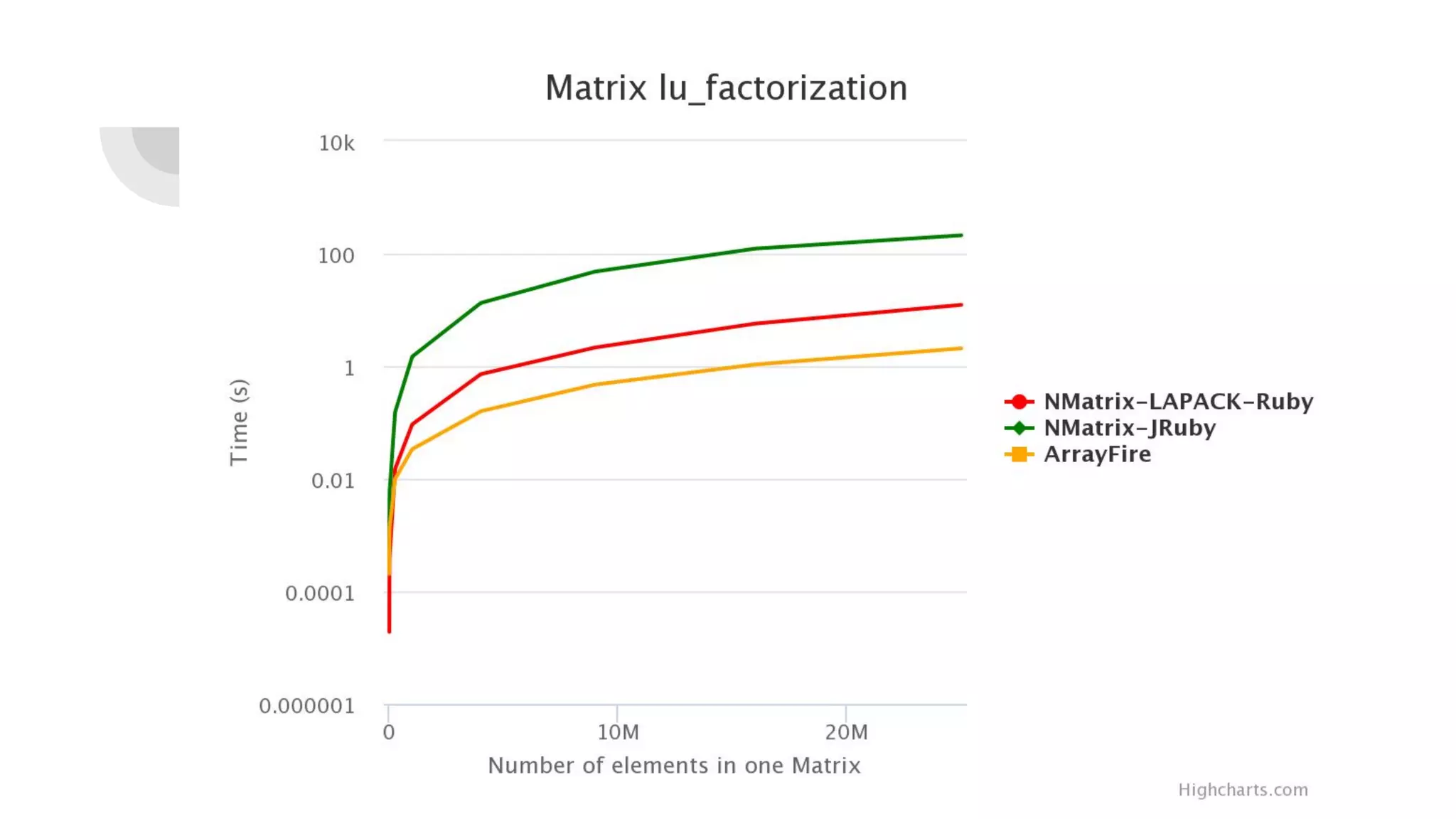
Prasun Anand presented on using Ruby for high performance GPU computing. He discussed SciRuby's efforts to push Ruby for scientific computing and popular Ruby gems like NMatrix. He explained CUDA and OpenCL for parallel computing on GPUs and demonstrated ArrayFire's Af_Array for storing arrays on the GPU. He also covered BLAS, LAPACK, statistics, random number generation, and benchmarks comparing GPU performance to CPU. Finally, he discussed RbCUDA for running custom kernels, GPU arrays, and interfaces to CuBLAS, CuSolver and CuRand.