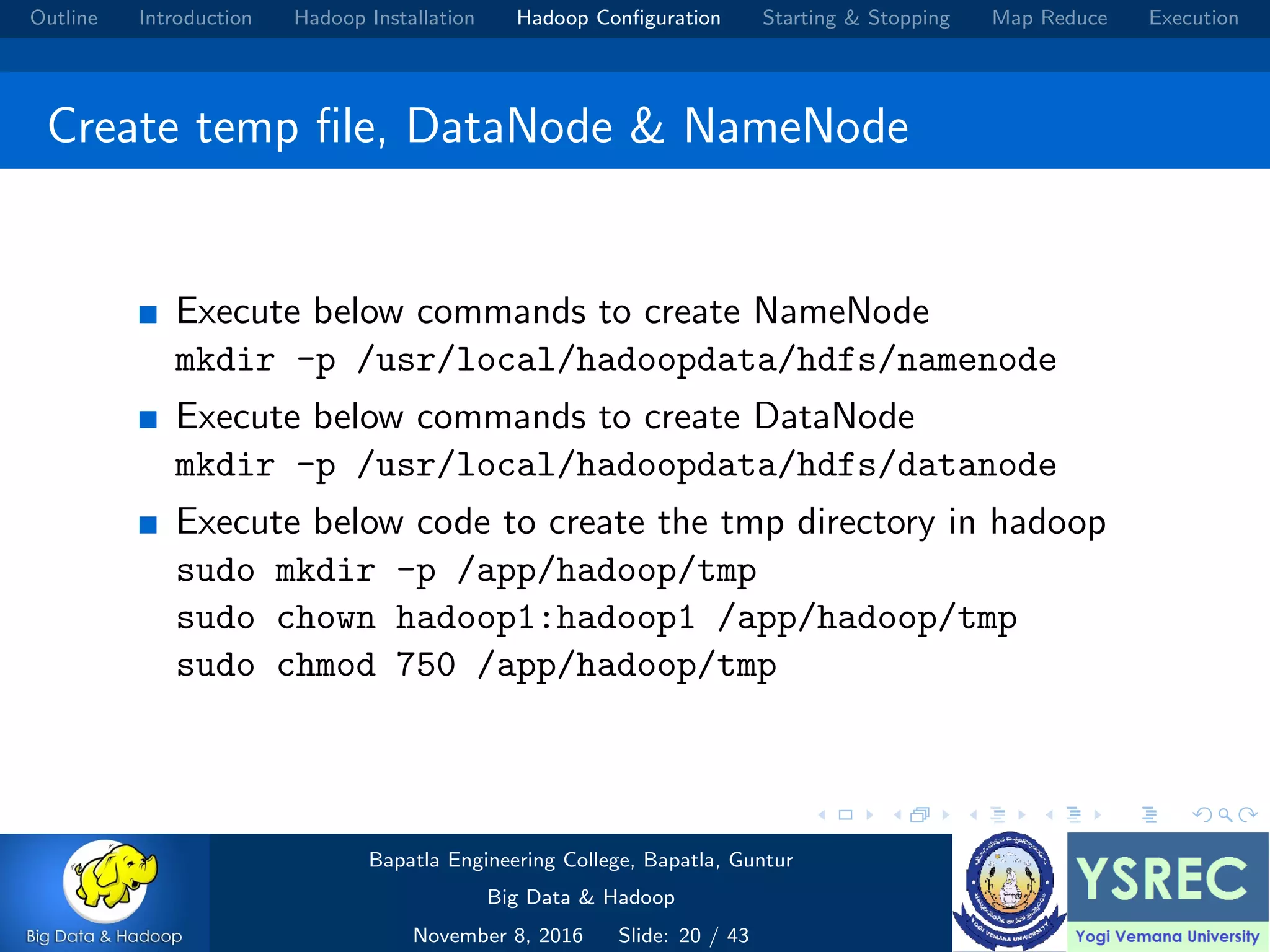
Downloaded 202 times





















![Outline Introduction Hadoop Installation Hadoop Configuration Starting & Stopping Map Reduce Execution WordCountJob public class WordCountJob { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "word count"); job.setJarByClass(WordCountJob.class); job.setMapperClass(WordCountMapper.class); job.setCombinerClass(WordCountReducer.class); job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } Bapatla Engineering College, Bapatla, Guntur Big Data & Hadoop November 8, 2016 Slide: 37 / 43](https://image.slidesharecdn.com/hadoopinstallation-161115041420/75/Hadoop-installation-Configuration-and-Mapreduce-program-37-2048.jpg)




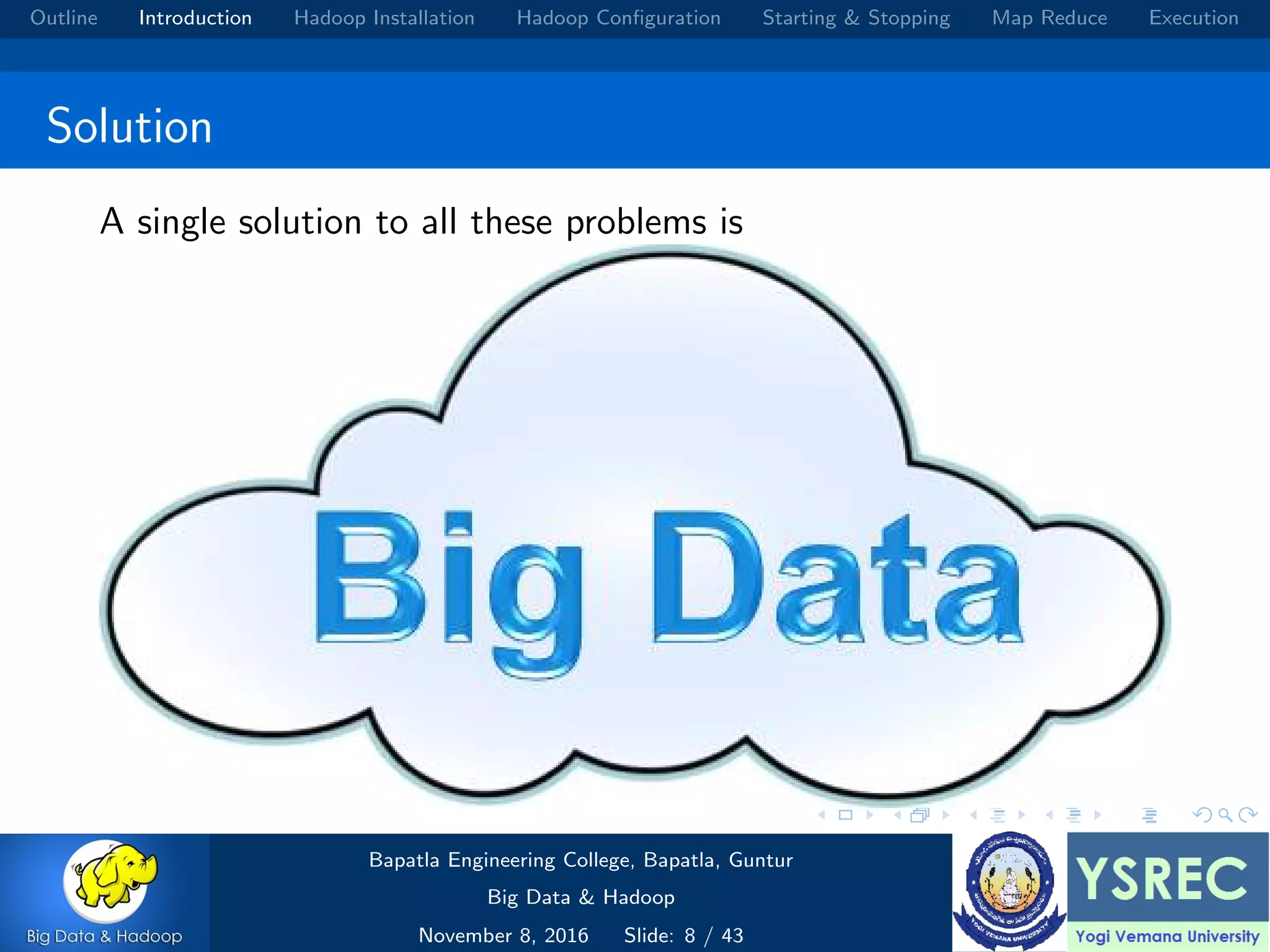
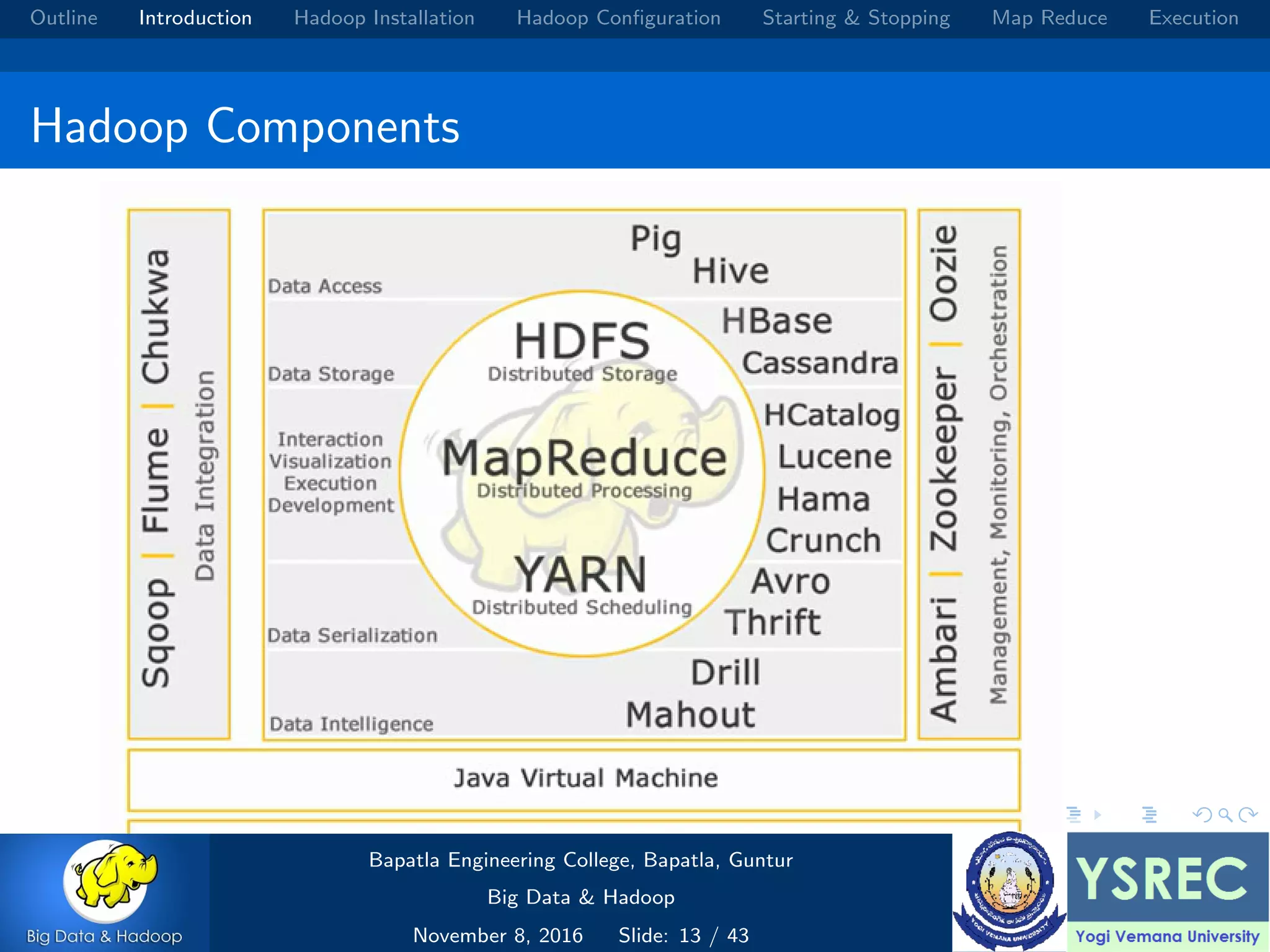
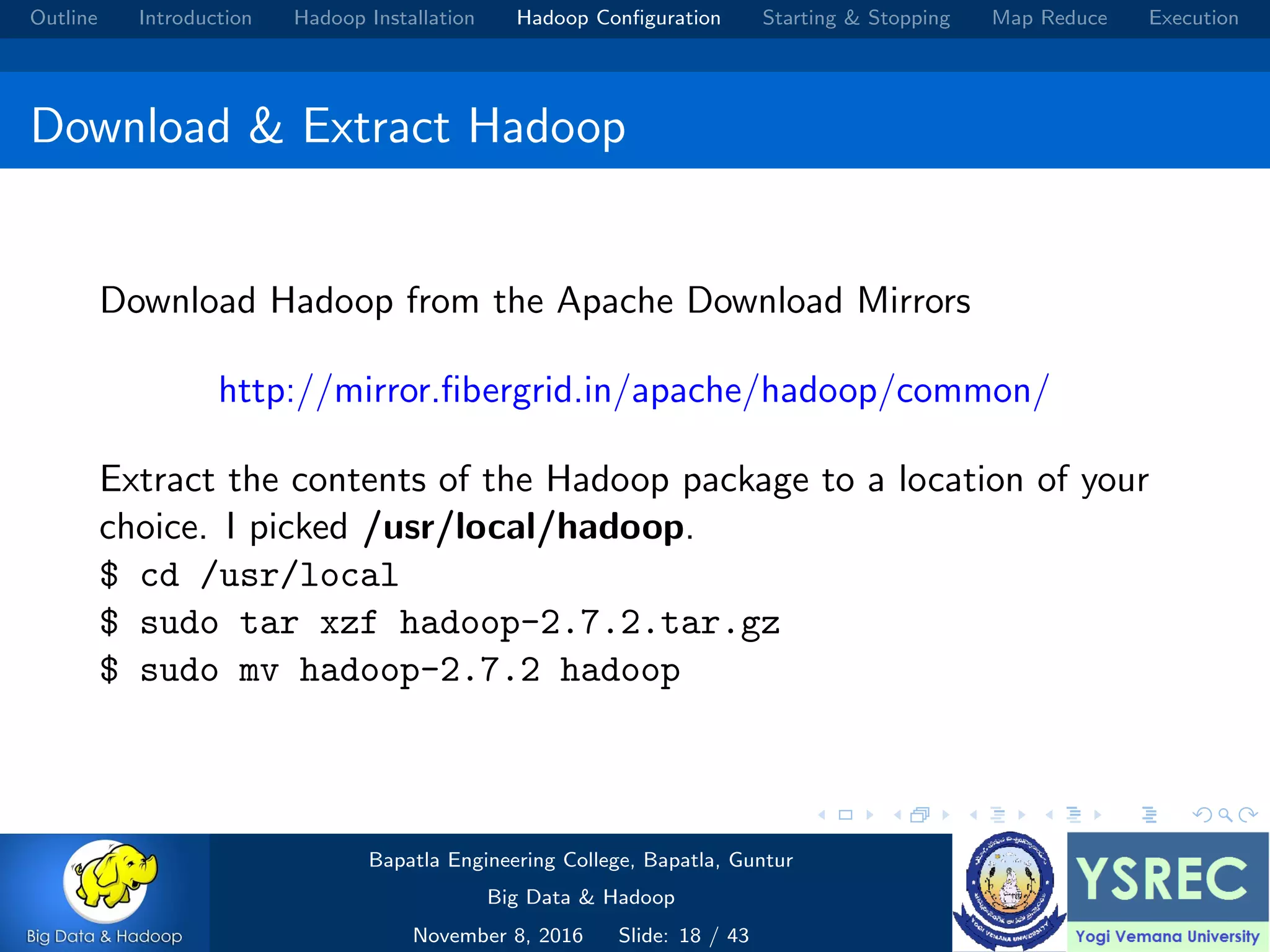
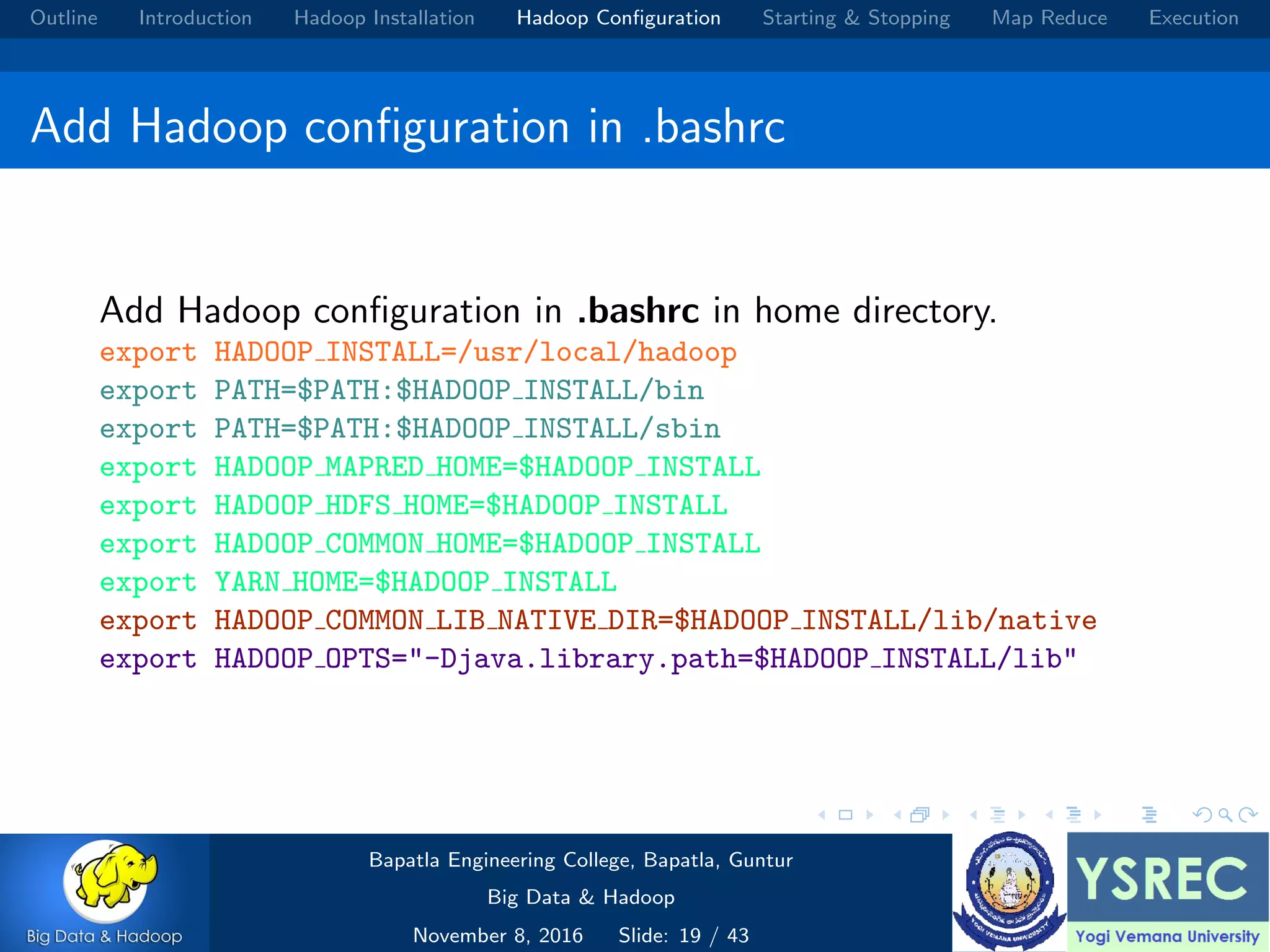
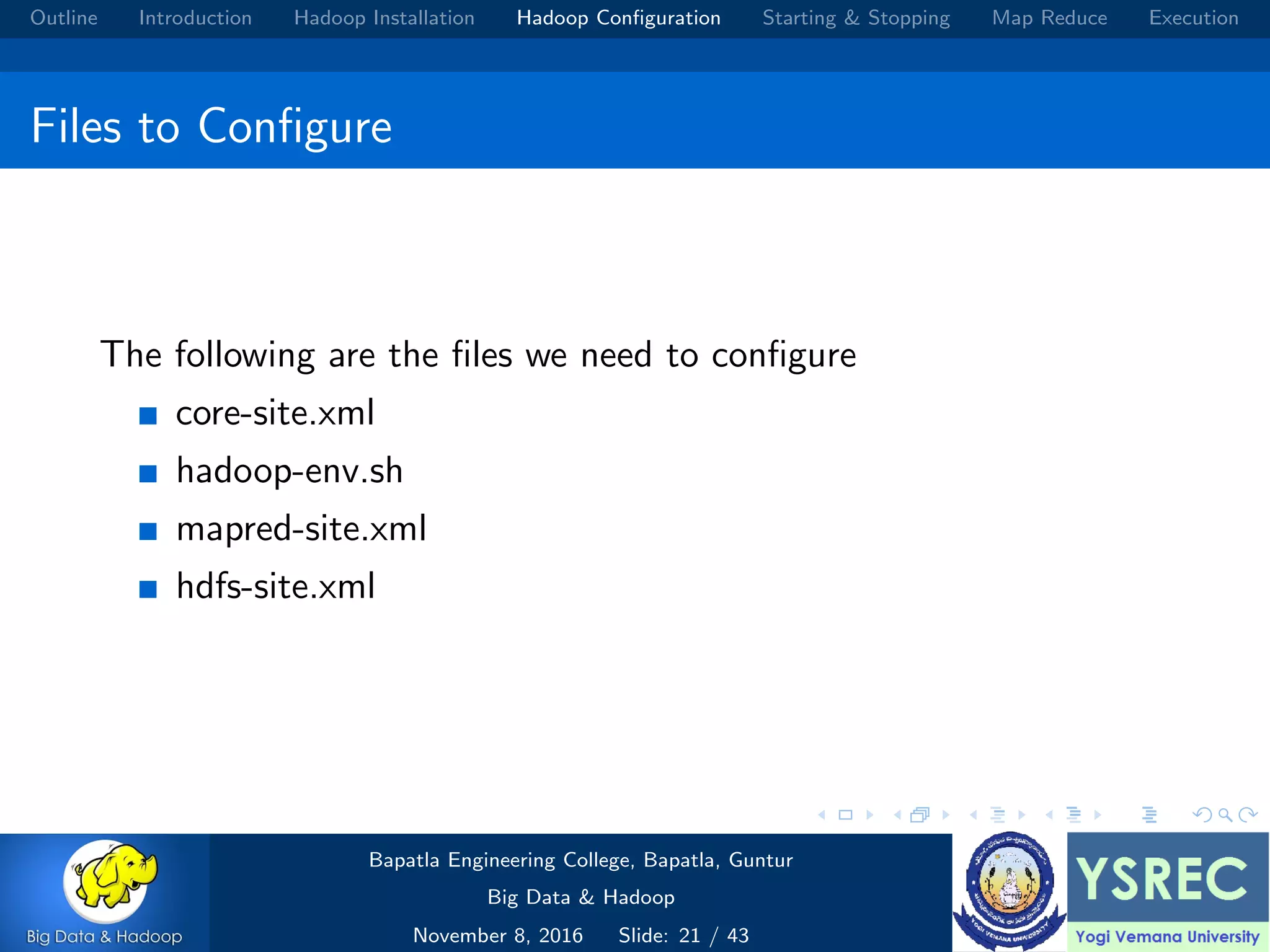
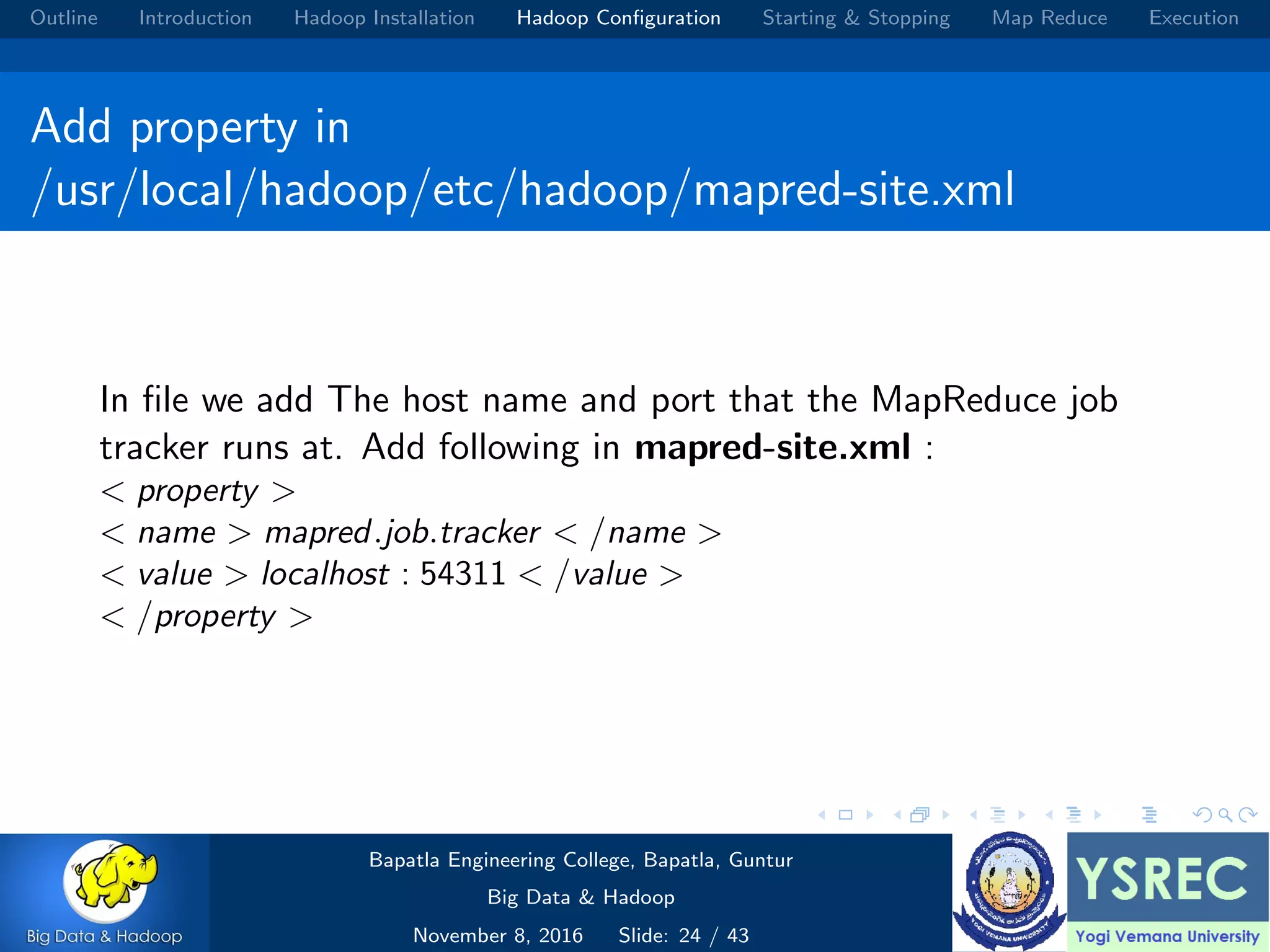
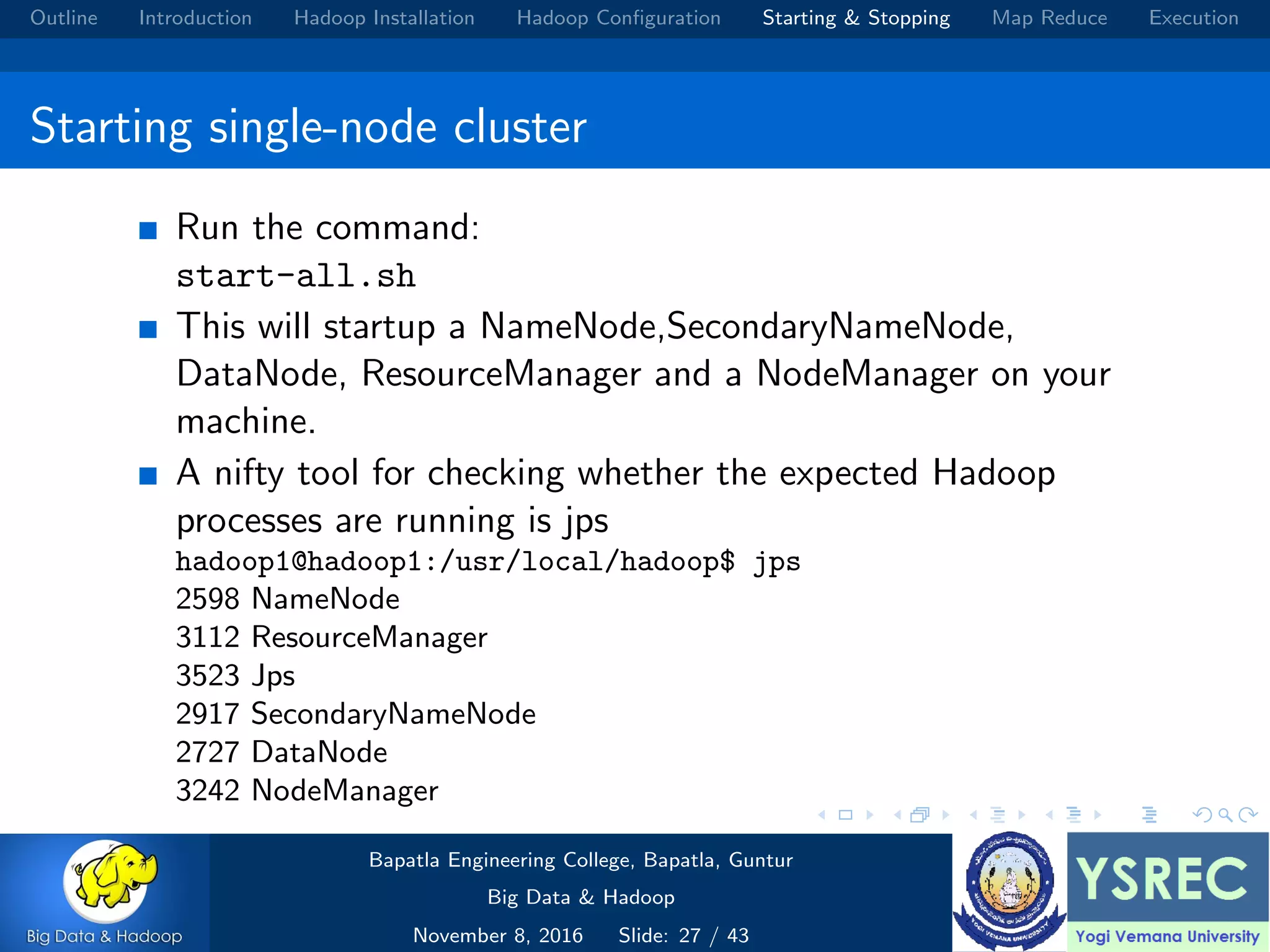
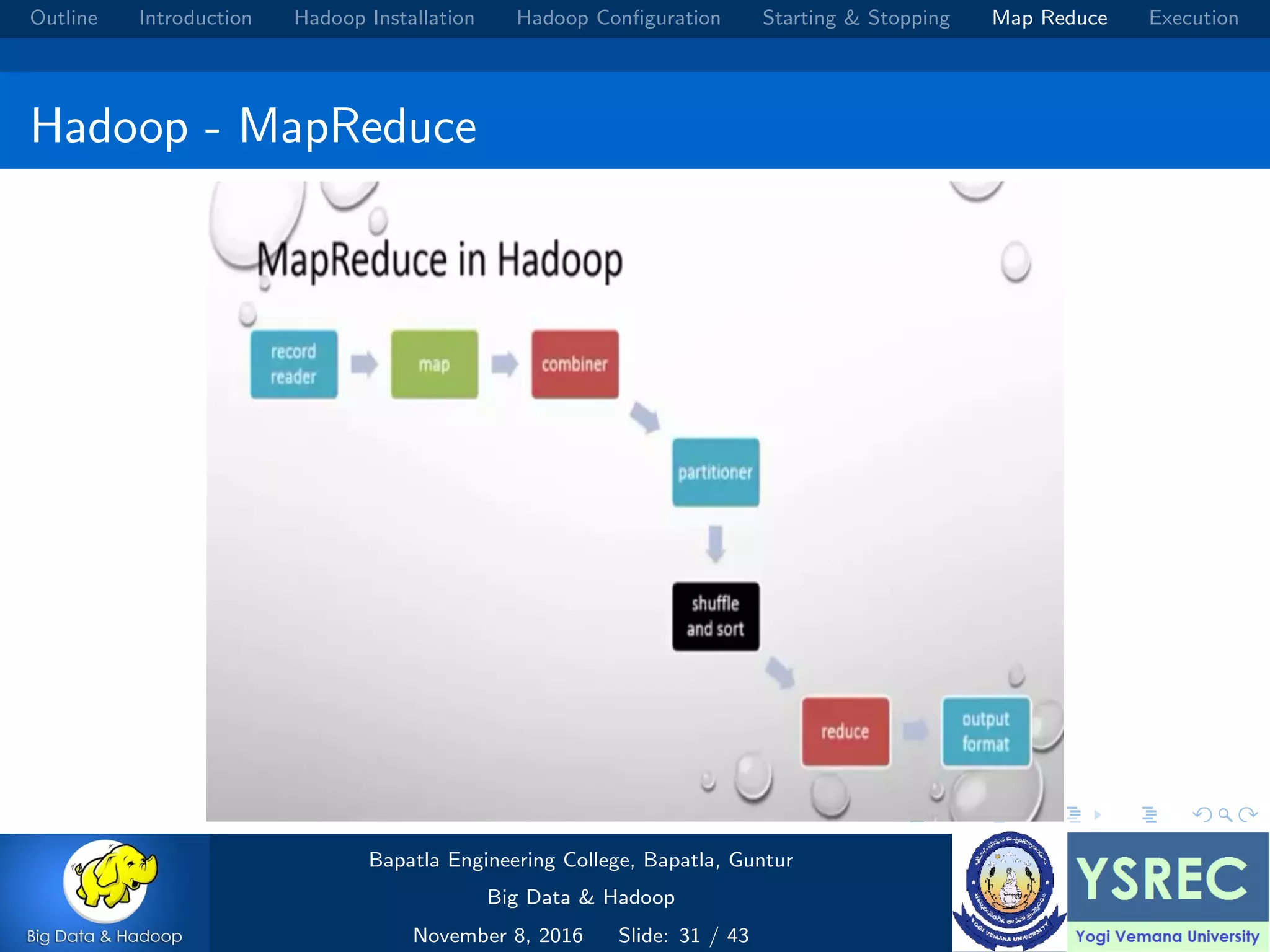
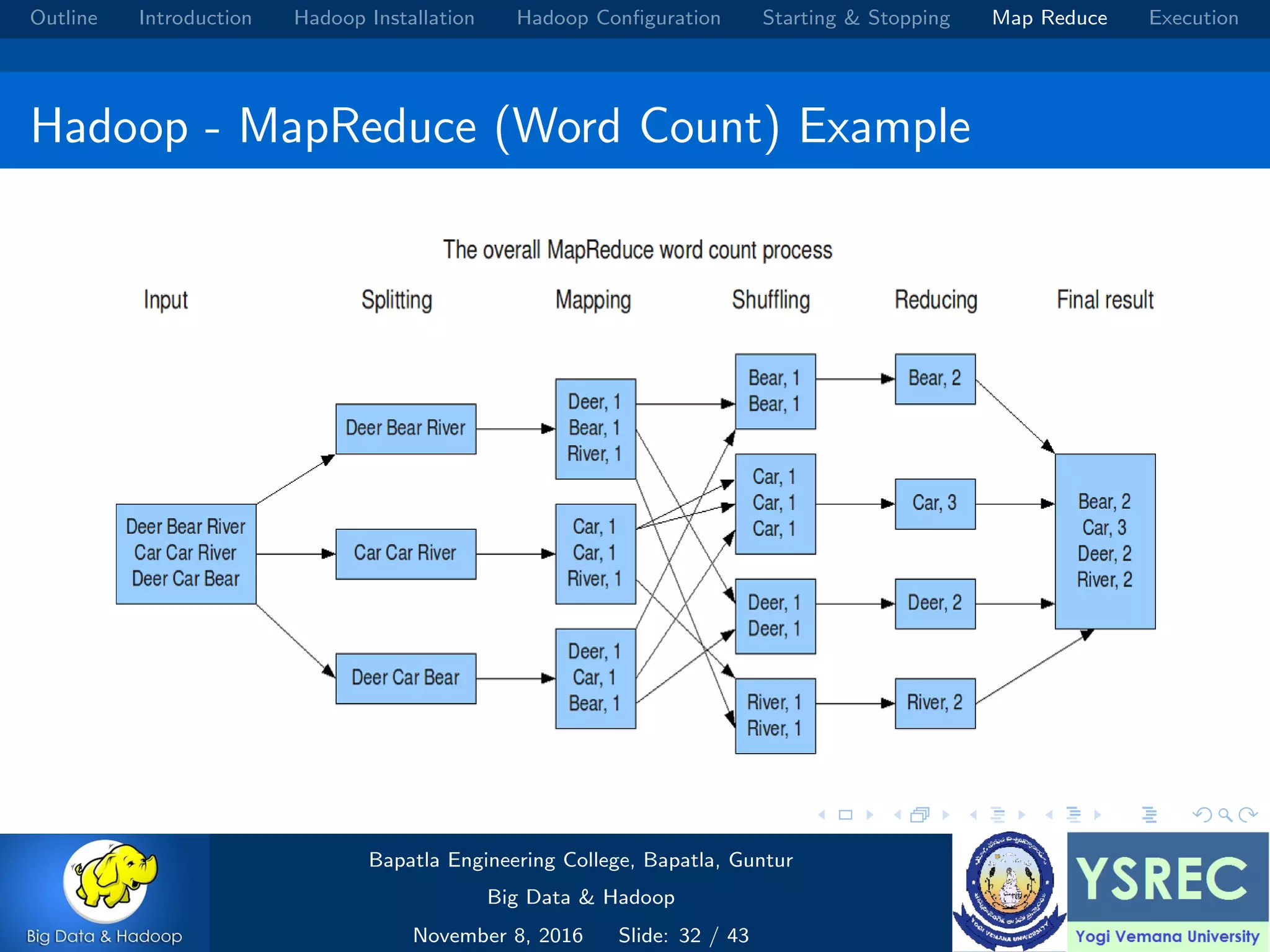
The document outlines the process and components involved in the Hadoop framework for handling big data, including installation, configuration, and execution in a MapReduce environment. It details steps for setting up Hadoop, including Java installation, configuring system properties, and starting and stopping the cluster. Additionally, it offers a brief overview of the MapReduce programming paradigm, including examples like a word count implementation.