Downloaded 172 times








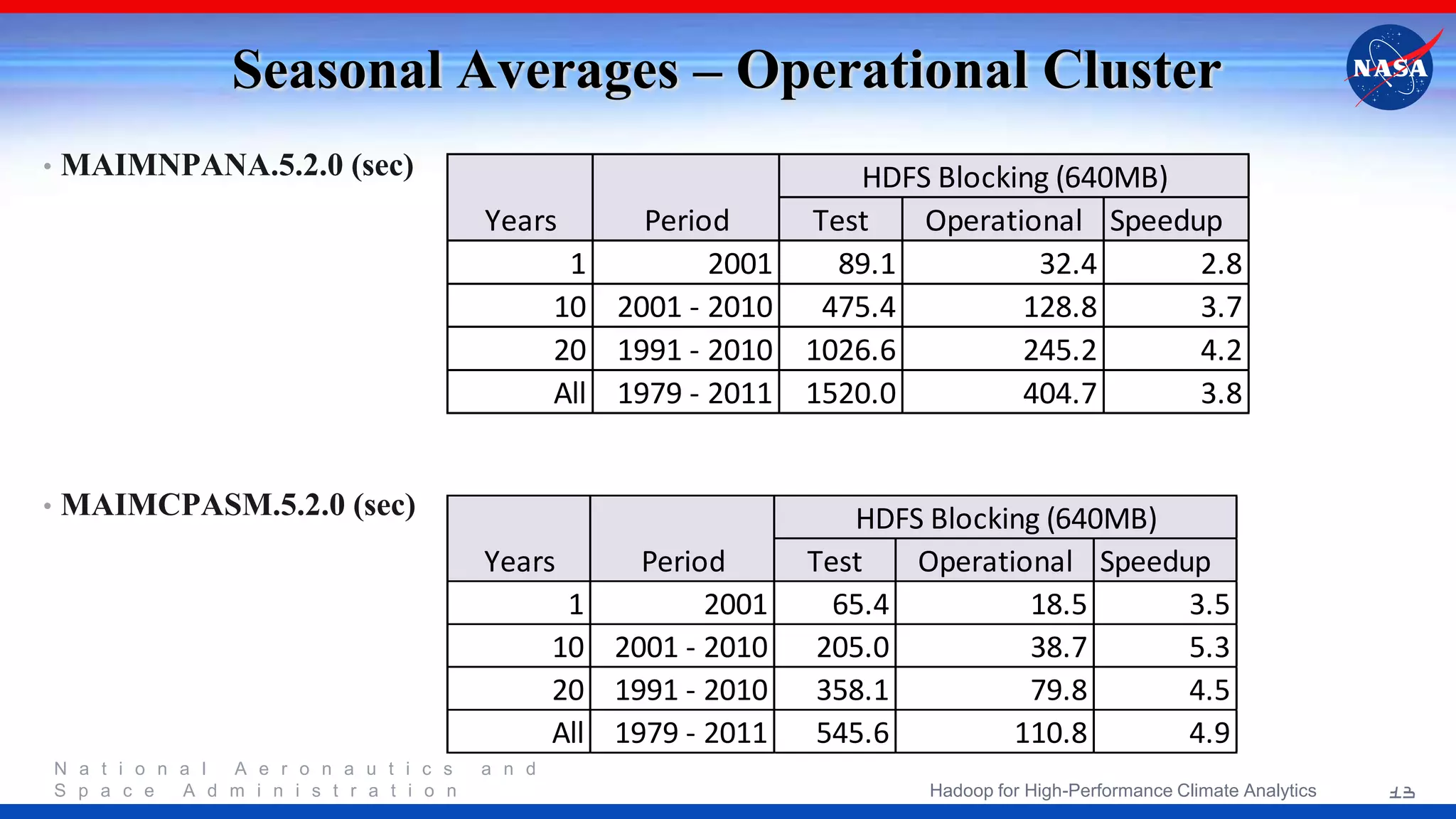

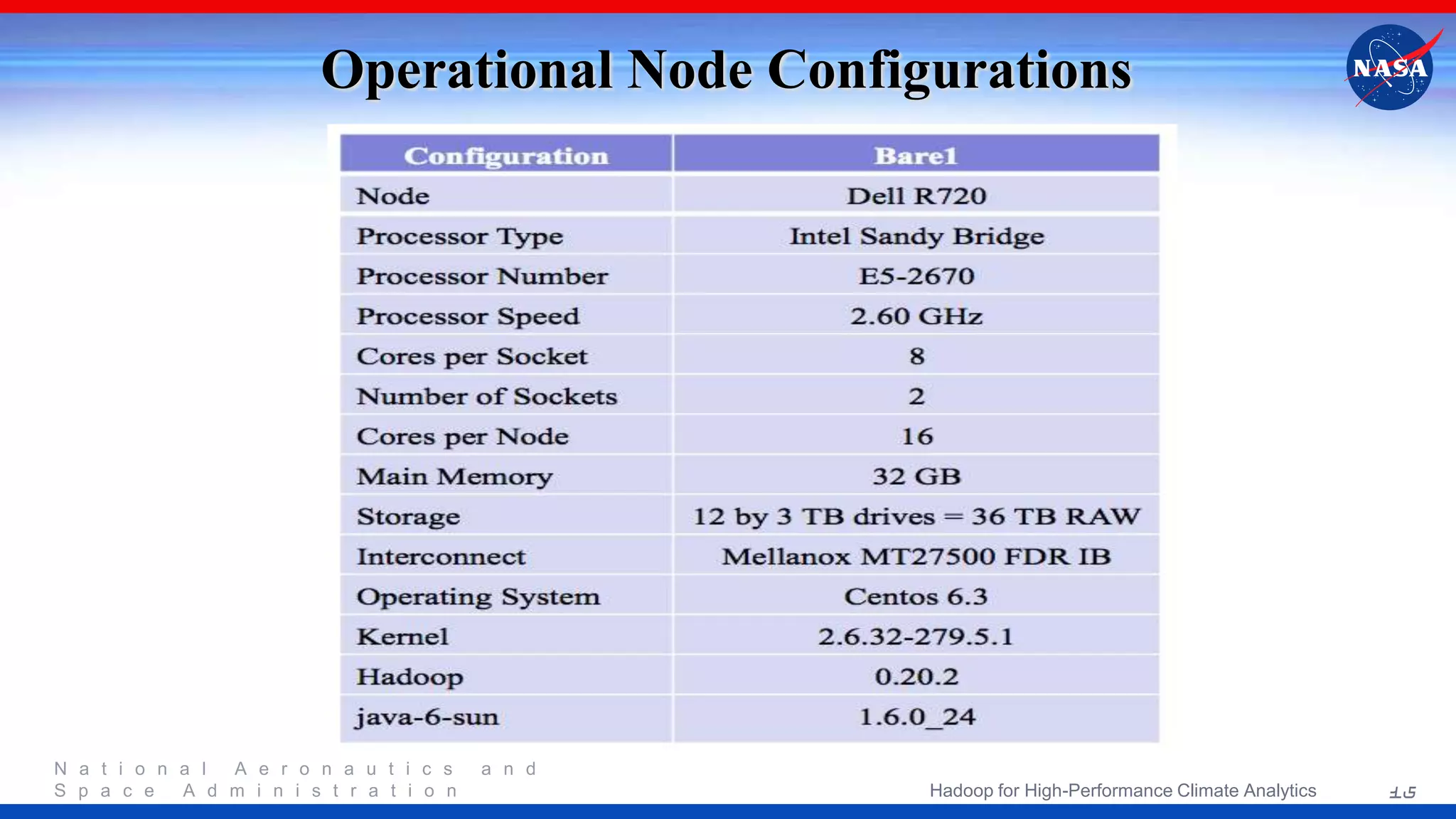


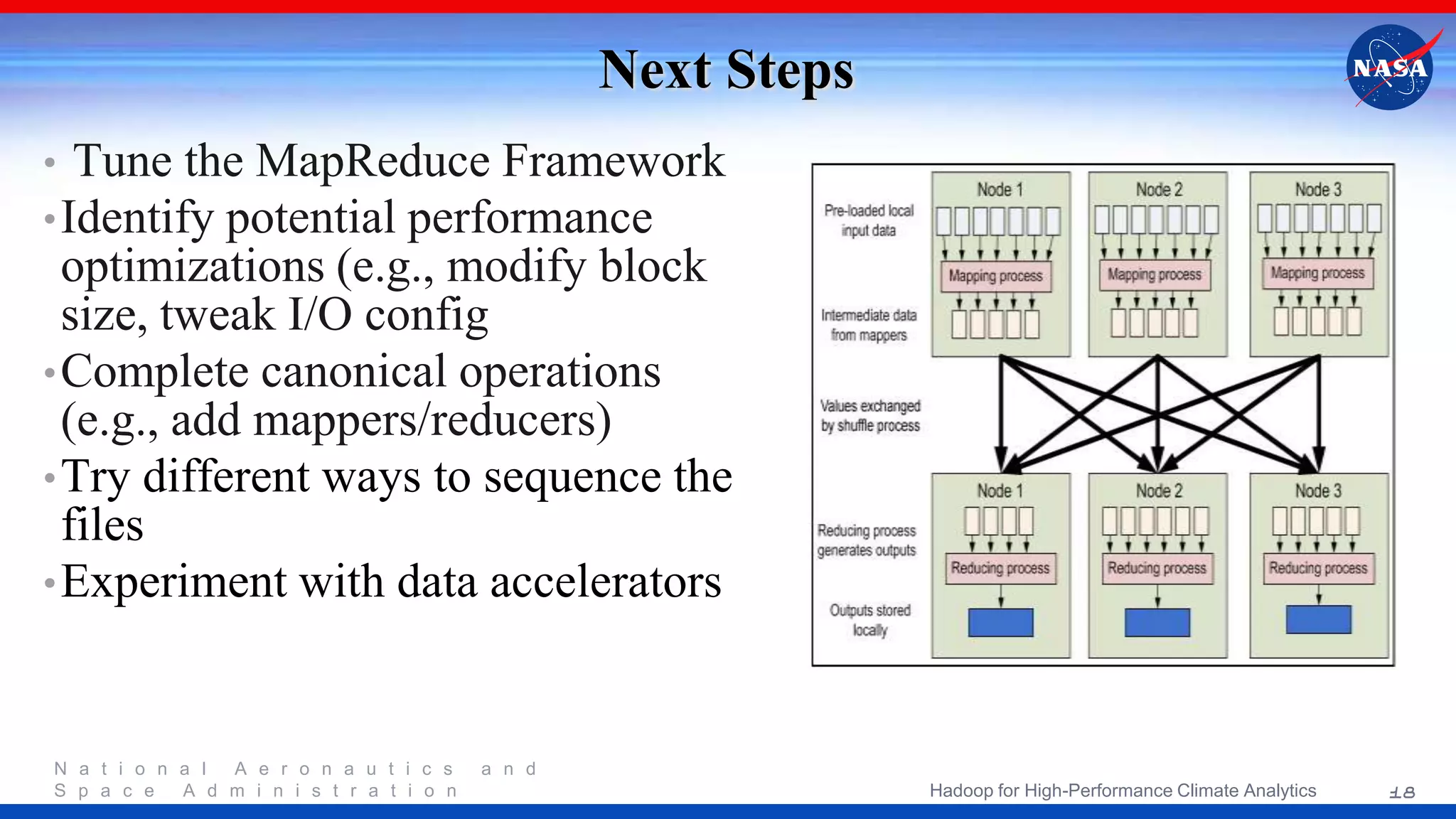


NASA's project focuses on utilizing Hadoop for high-performance climate analytics, aiming to enhance climate data analysis capabilities through a parallel storage-computation model. The initiative evaluates the effectiveness of MapReduce and the Hadoop Distributed File System for processing extensive climate data, specifically MERRA datasets. Future steps include performance optimization and refining the data processing framework based on lessons learned during the implementation.