Downloaded 33 times



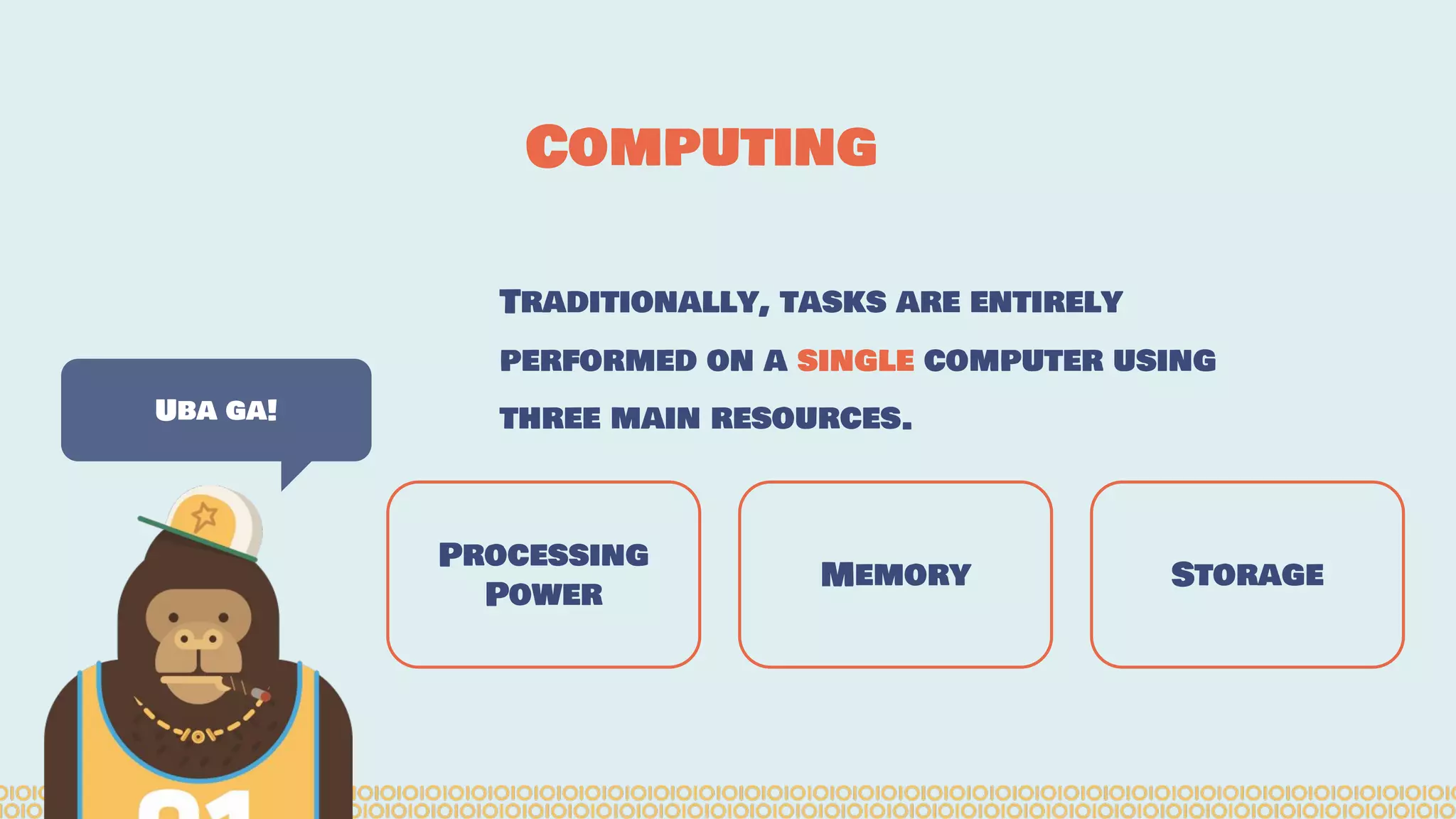
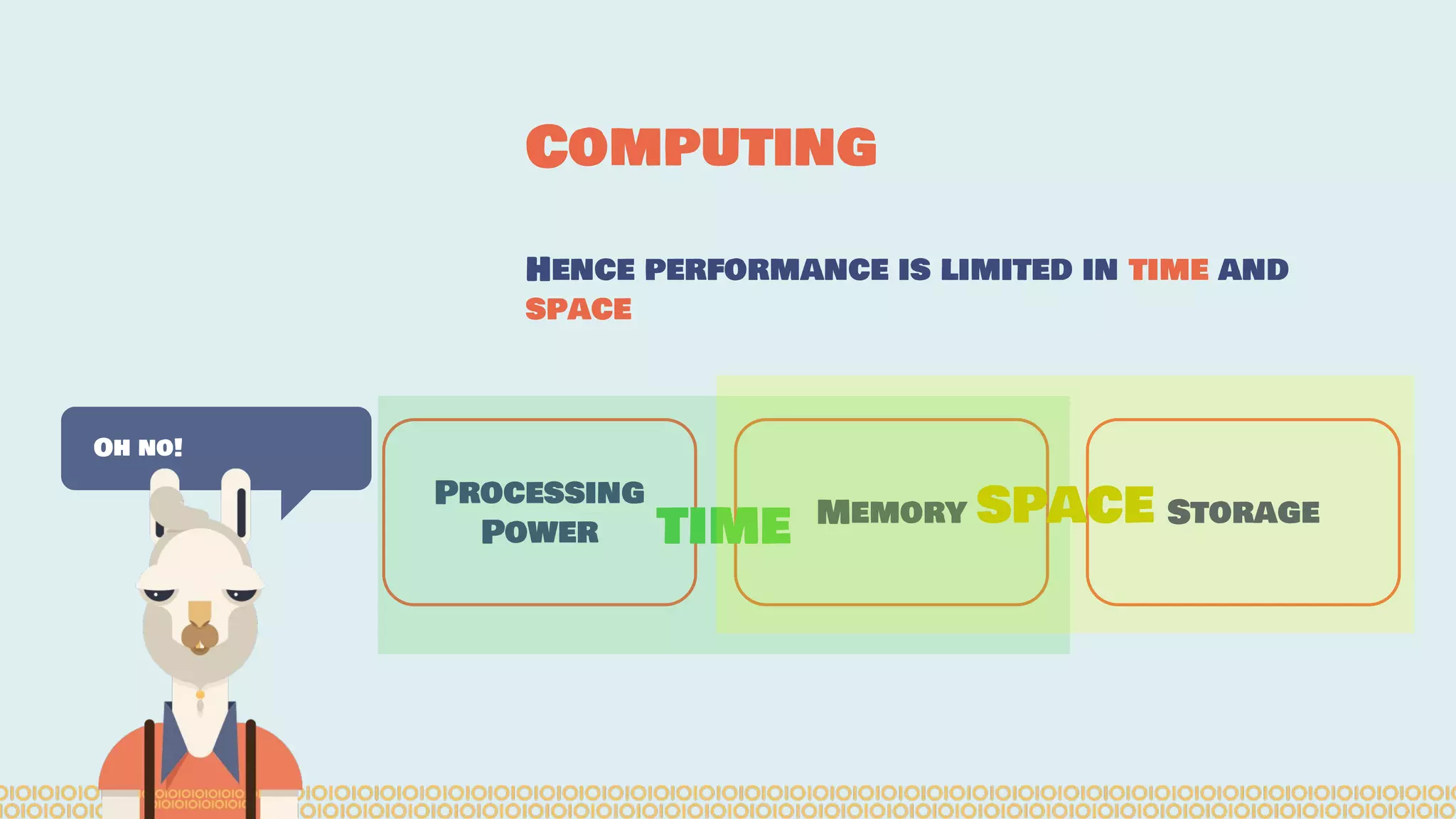
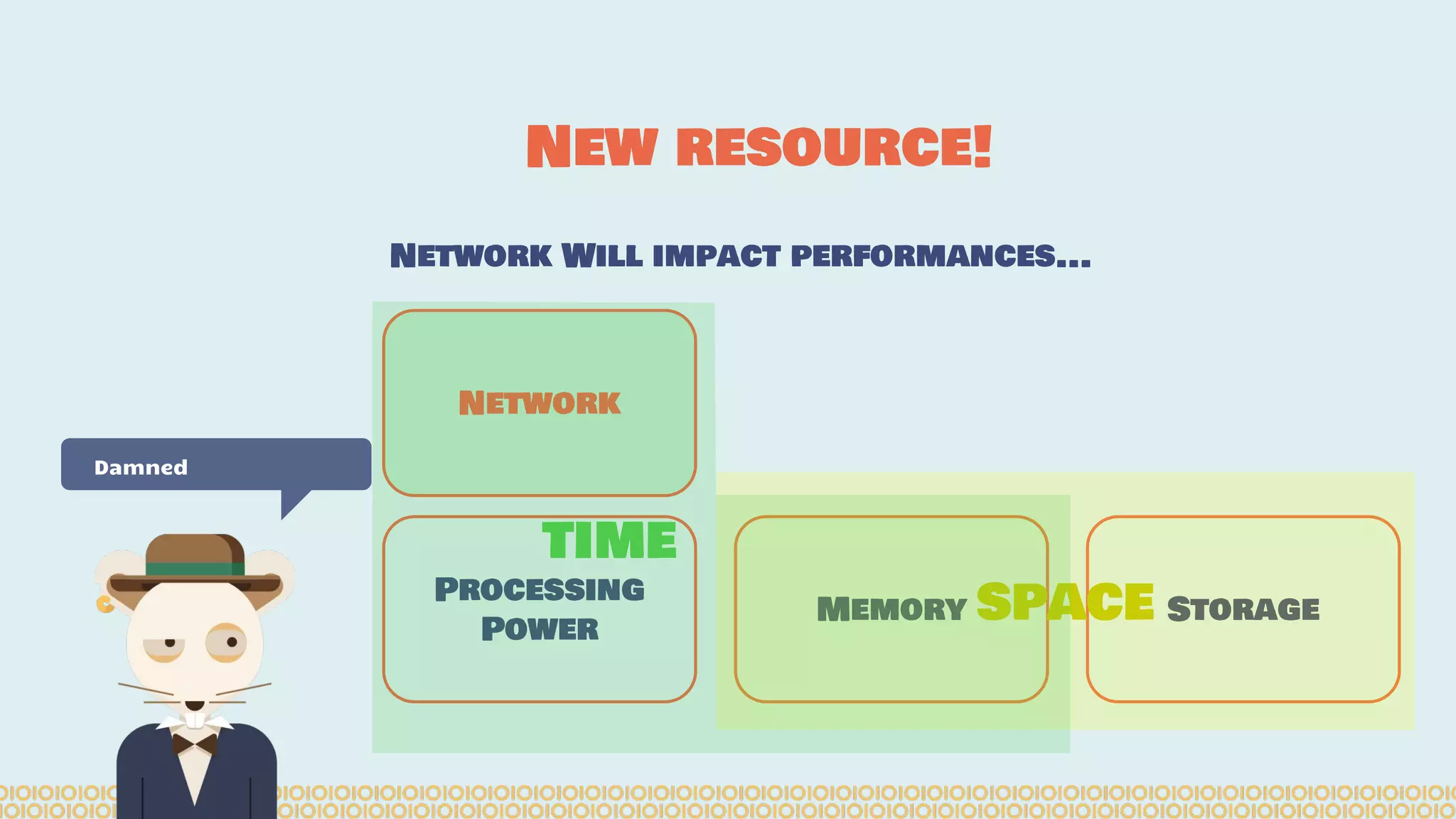
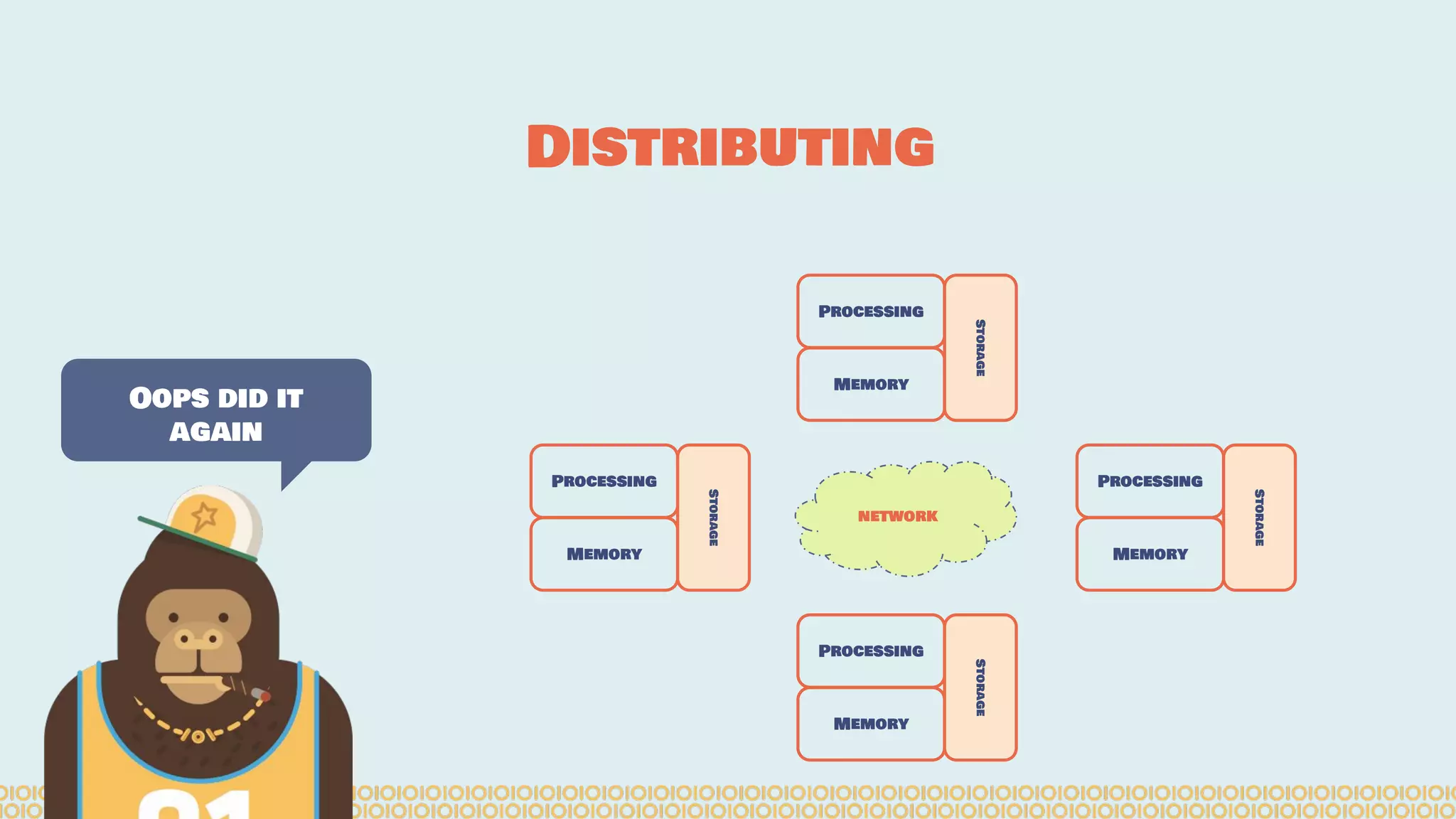
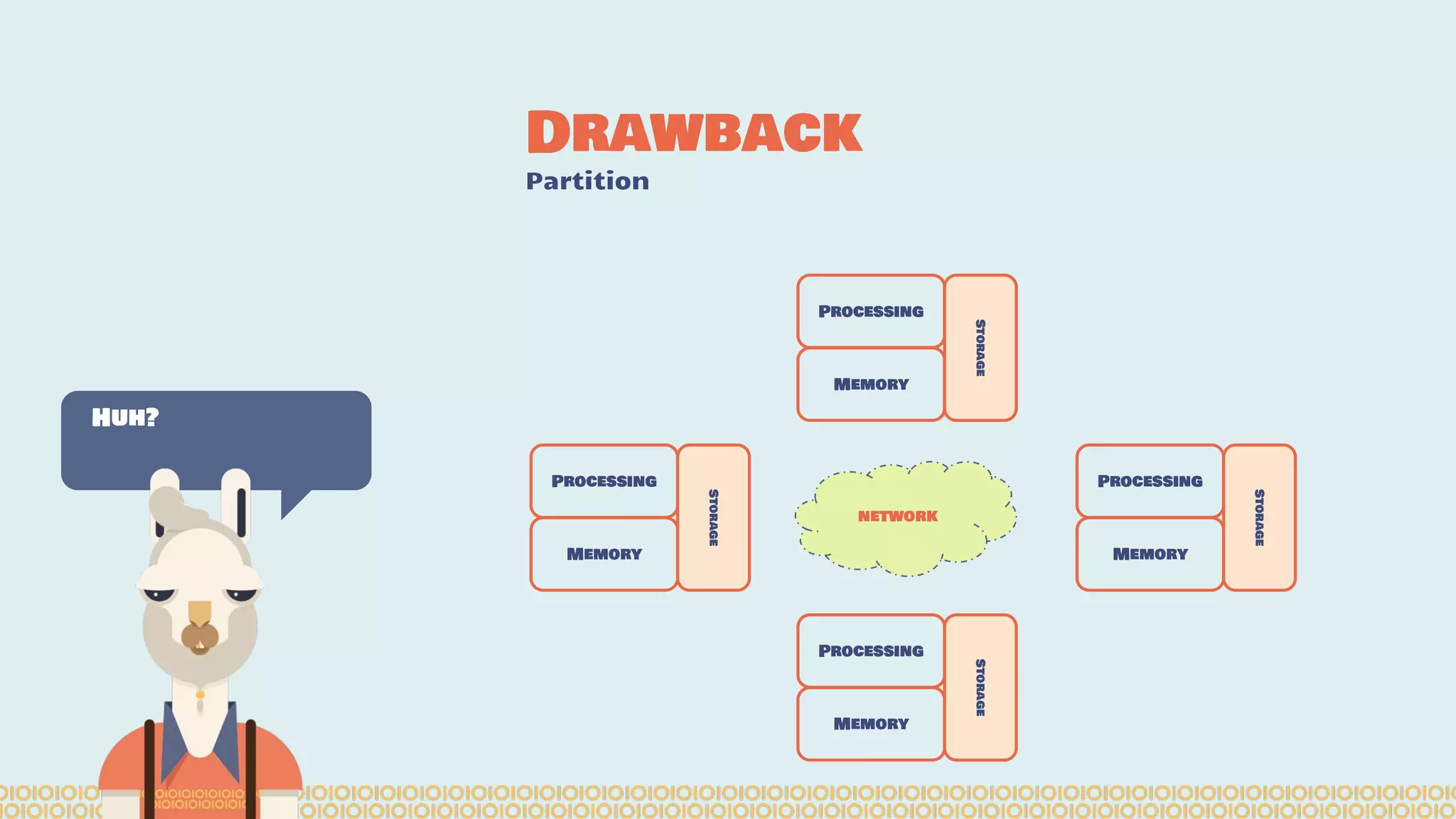
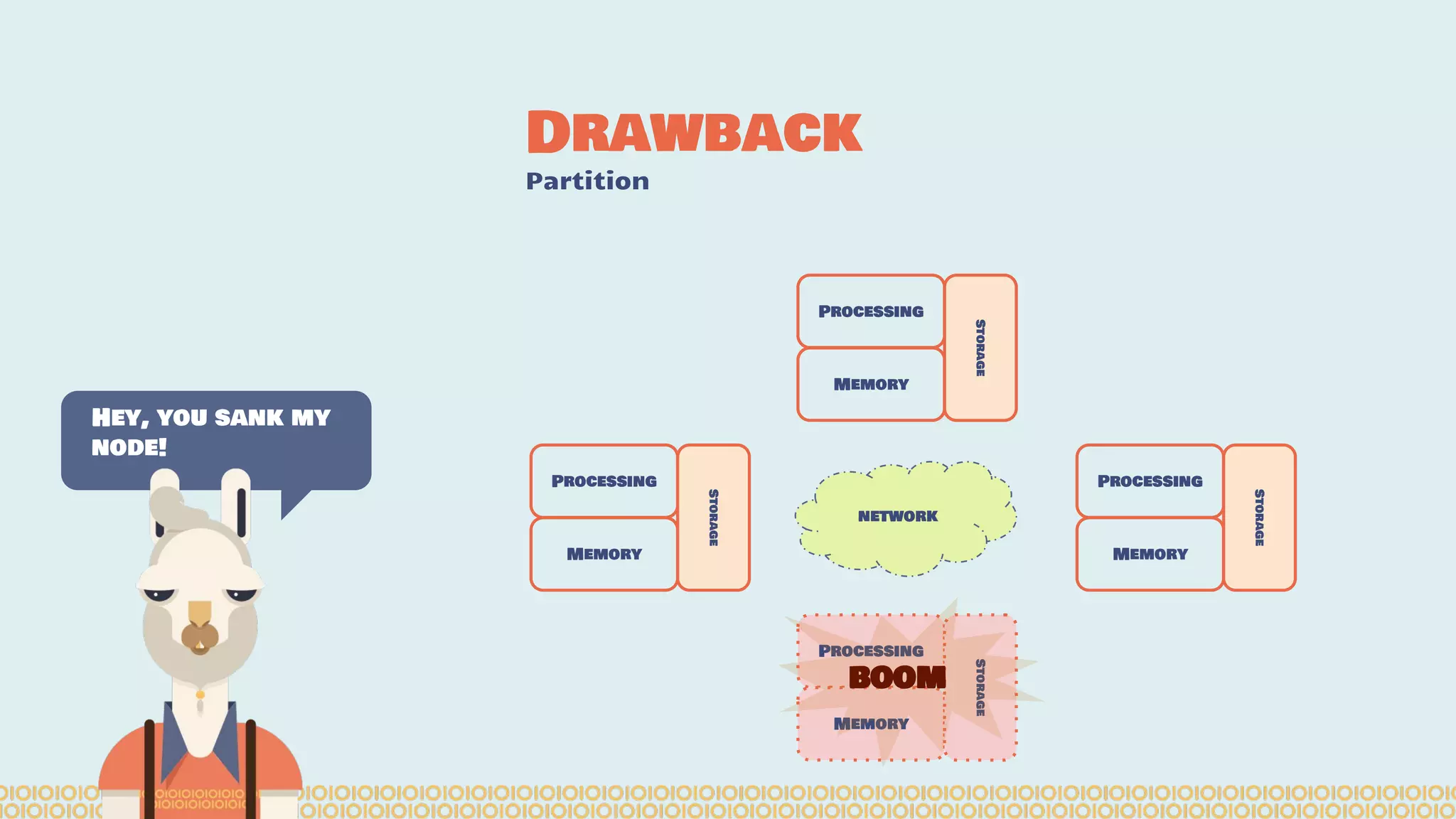
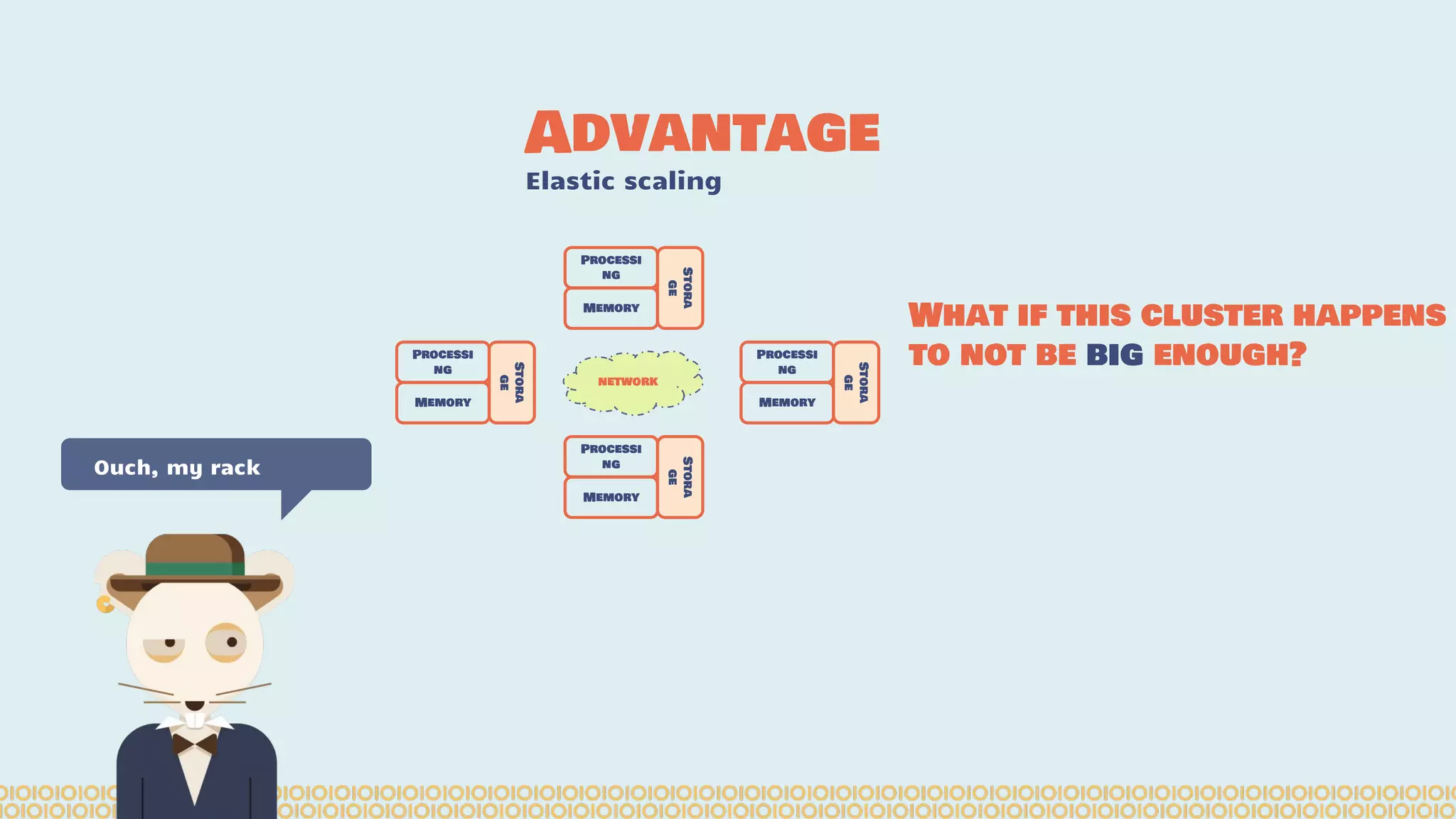
![Distribute computing: [...] A distributed system is a software system in which components located on networked computers communicate and coordinate their actions by passing messages. The components interact with each other in order to achieve a common goal. [...]. Ref: https://en.wikipedia. org/wiki/Distributed_computing Distributing Interesting](https://image.slidesharecdn.com/distributedmachinelearning101usingapachesparkfromabrowser-devoxx-151109170914-lva1-app6892/75/Distributed-machine-learning-101-using-apache-spark-from-a-browser-devoxx-be2015-7-2048.jpg)






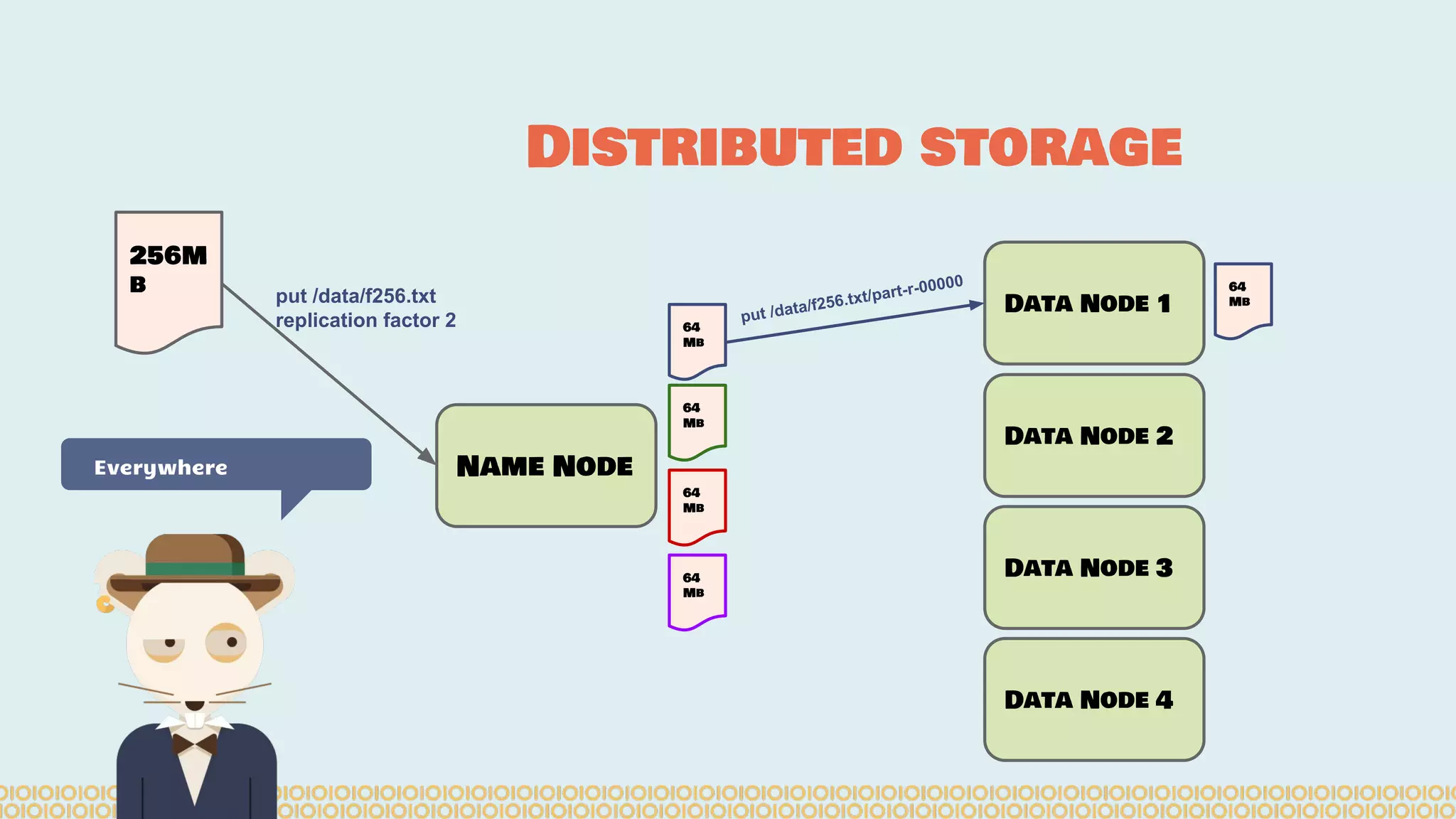
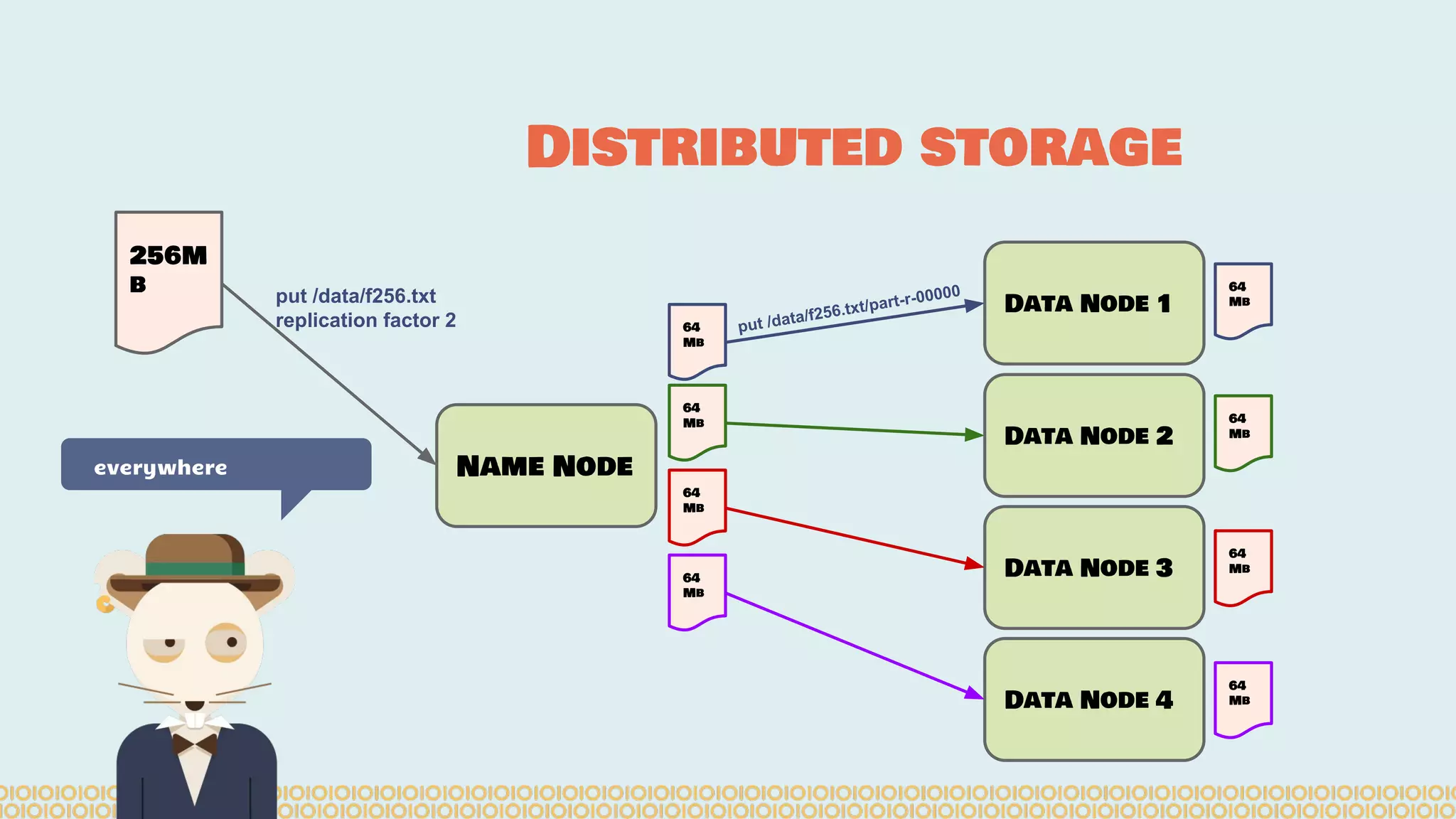
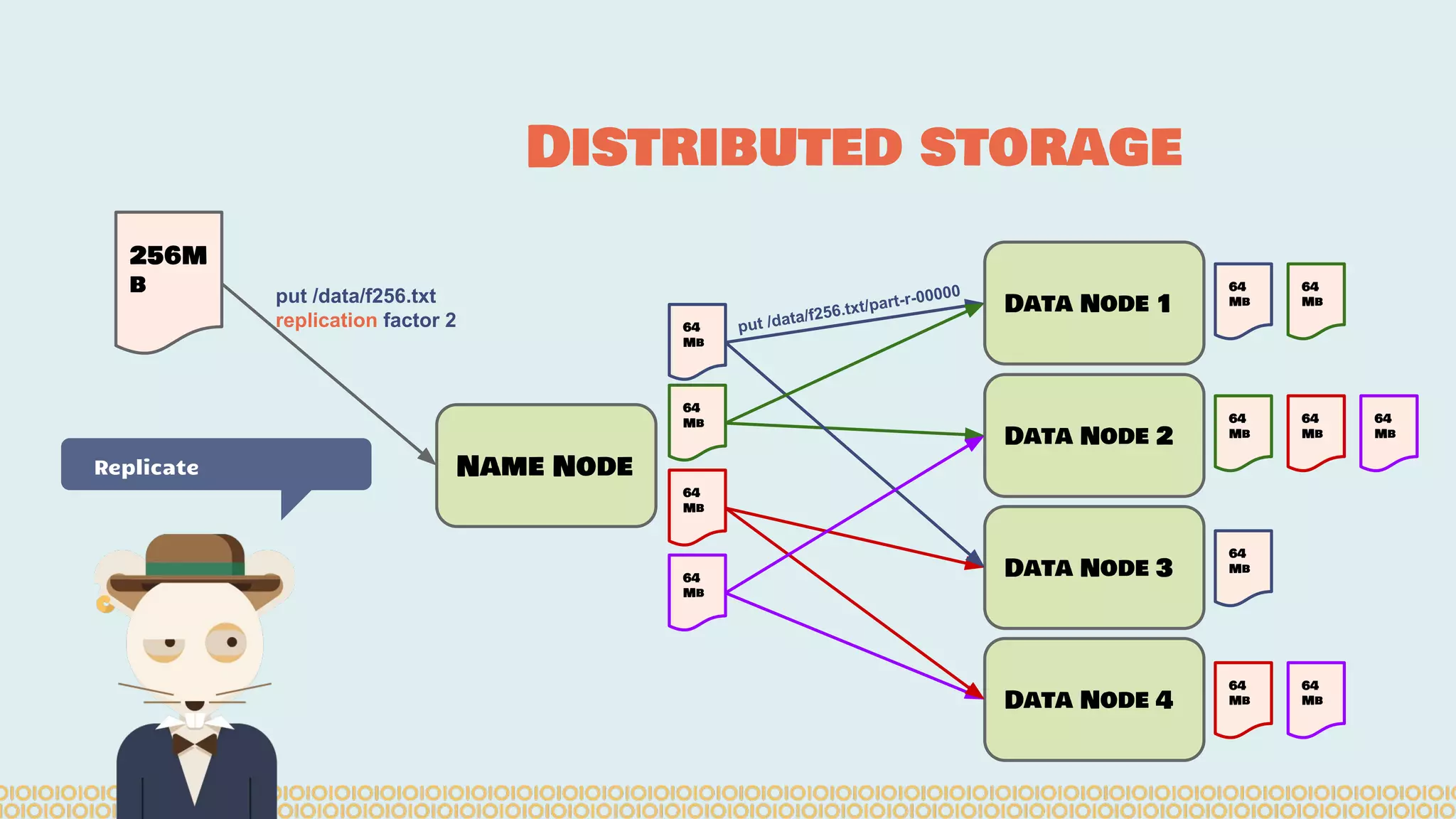

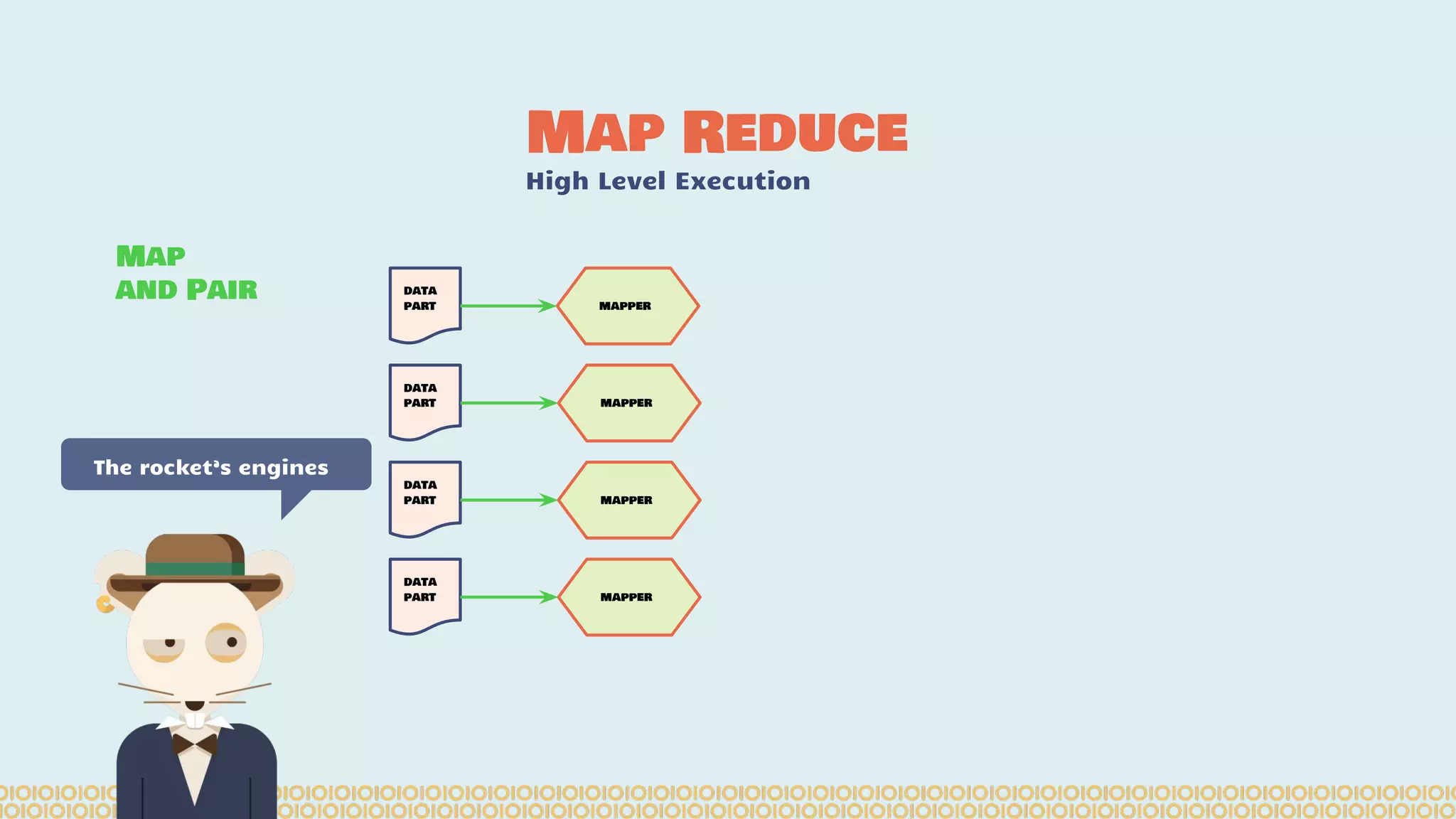
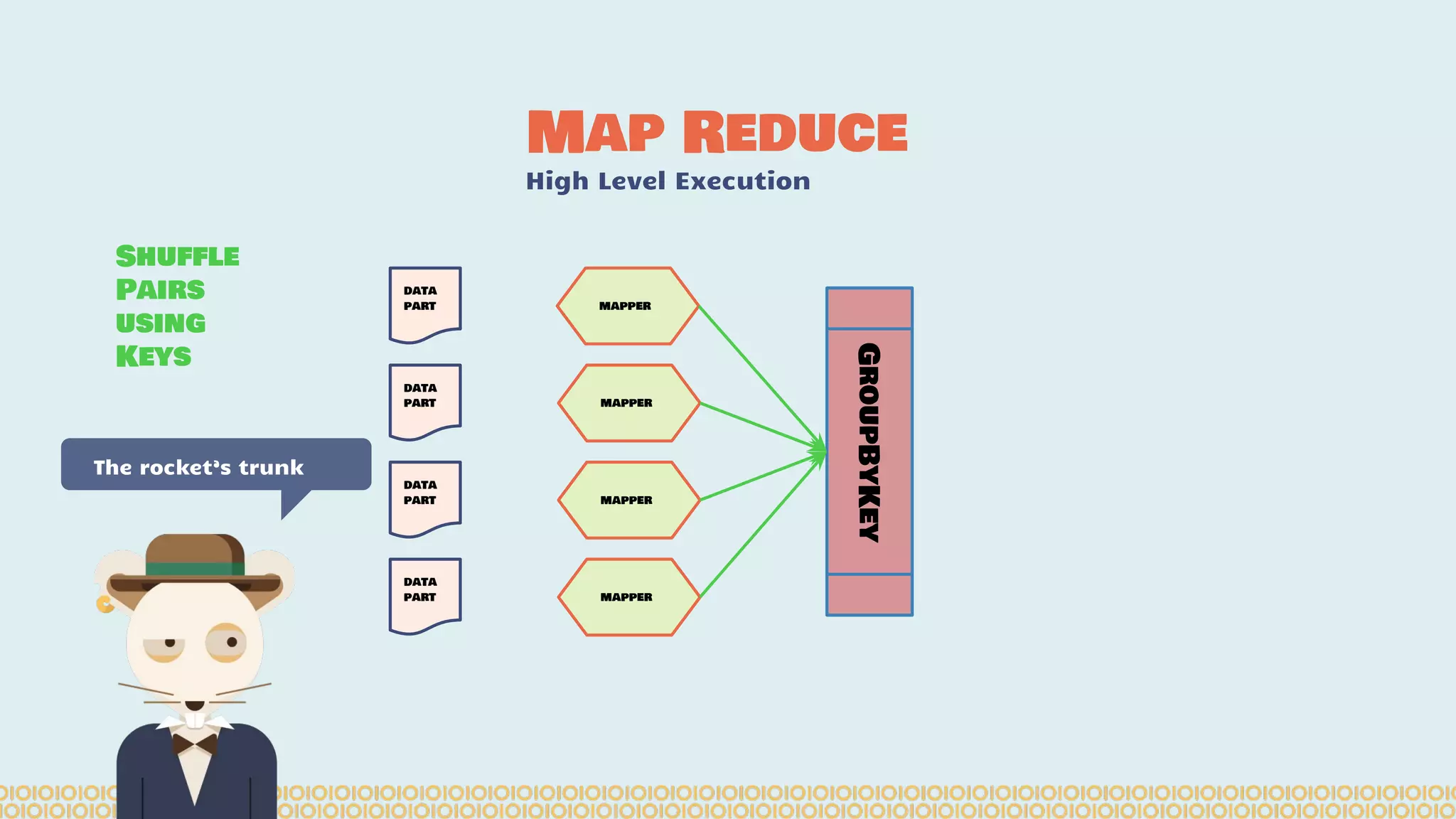
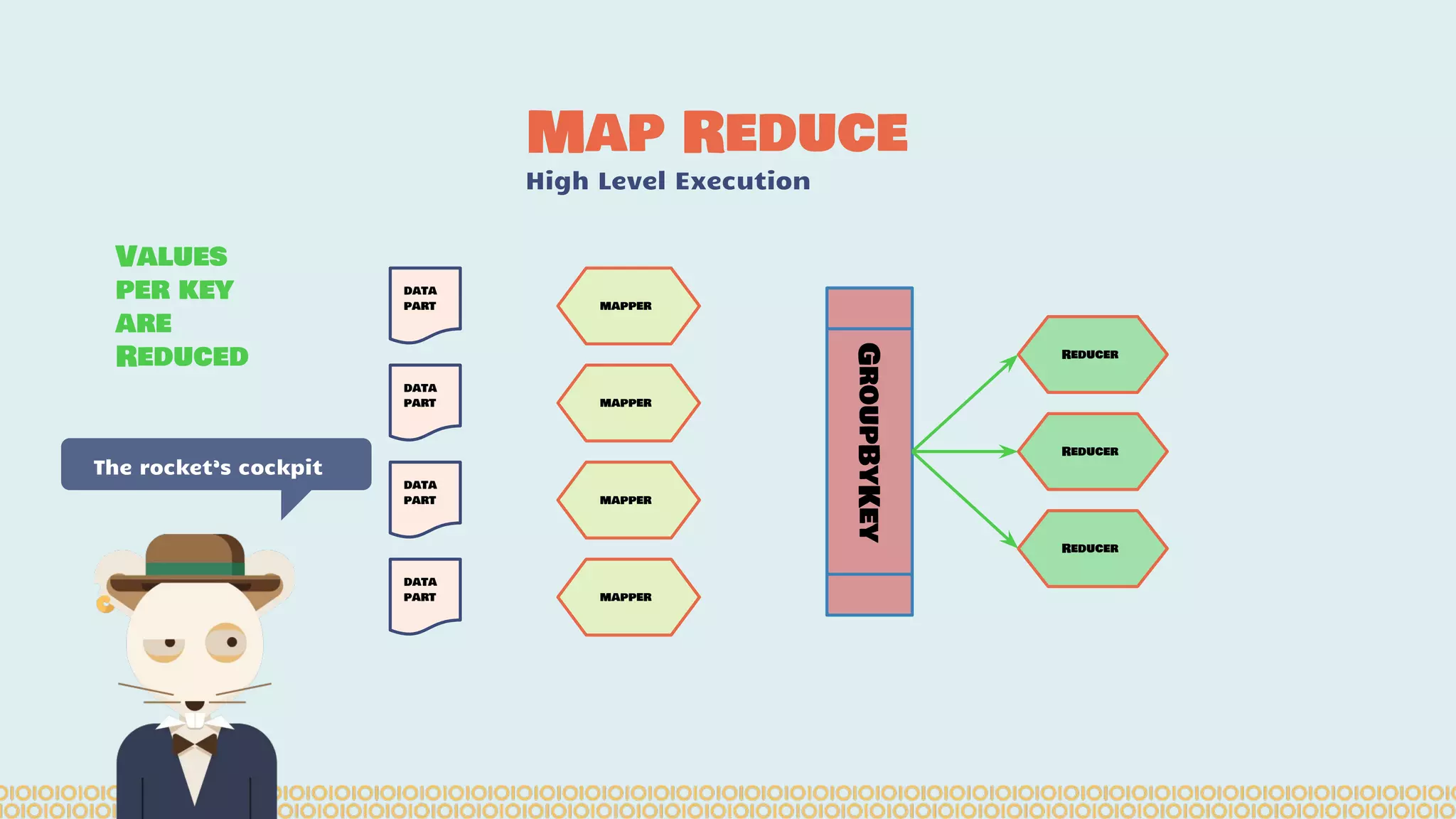
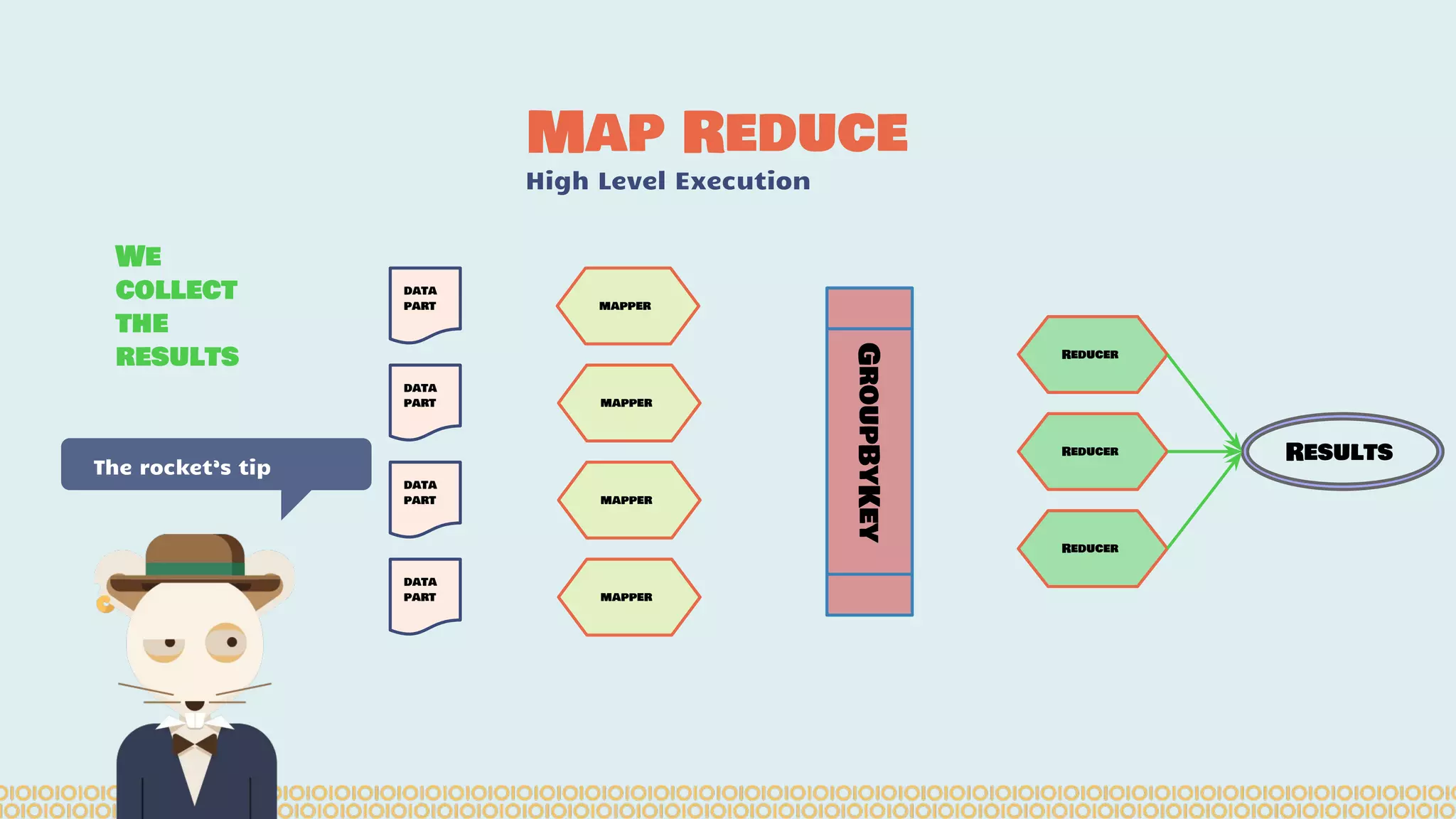
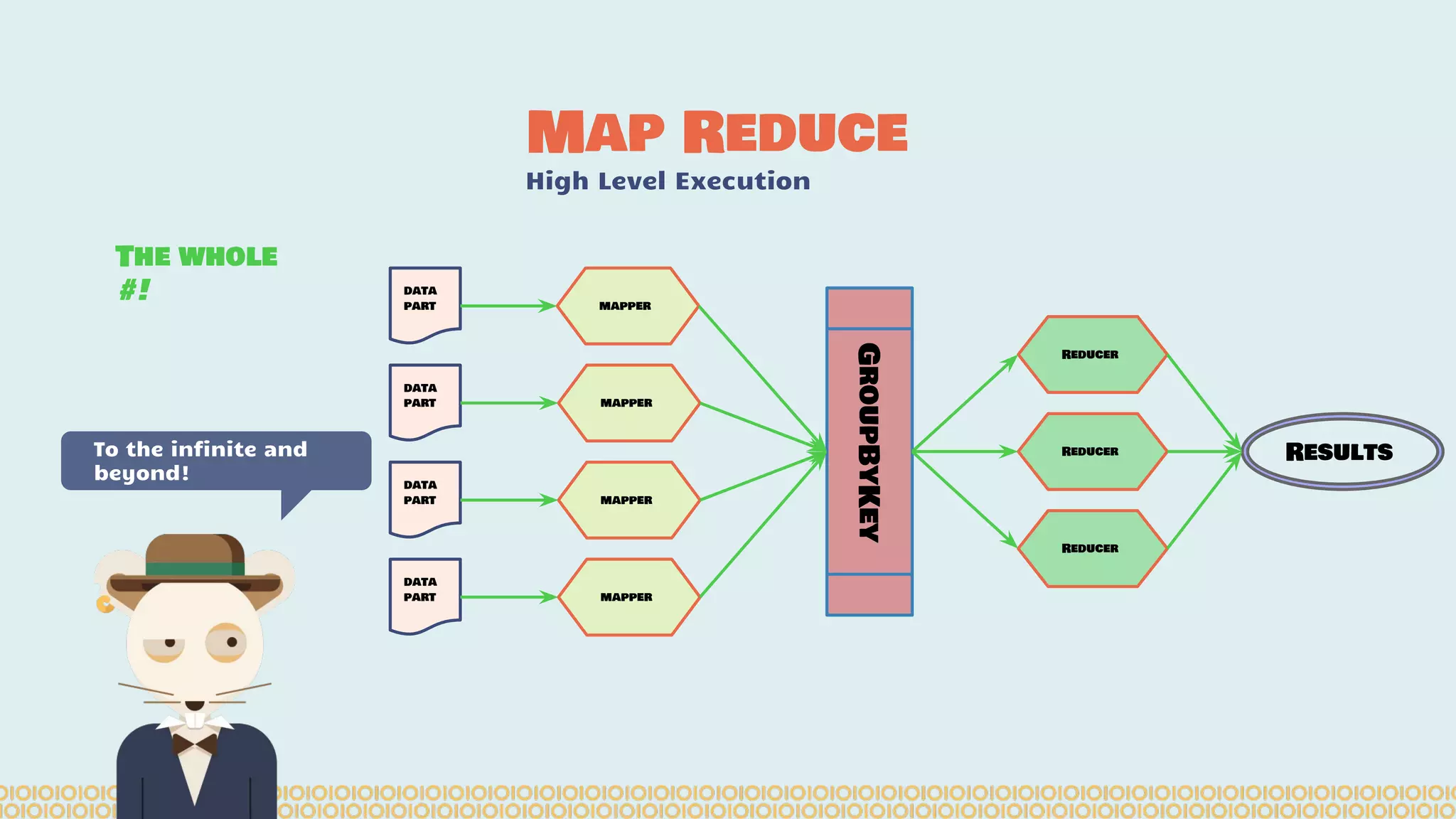
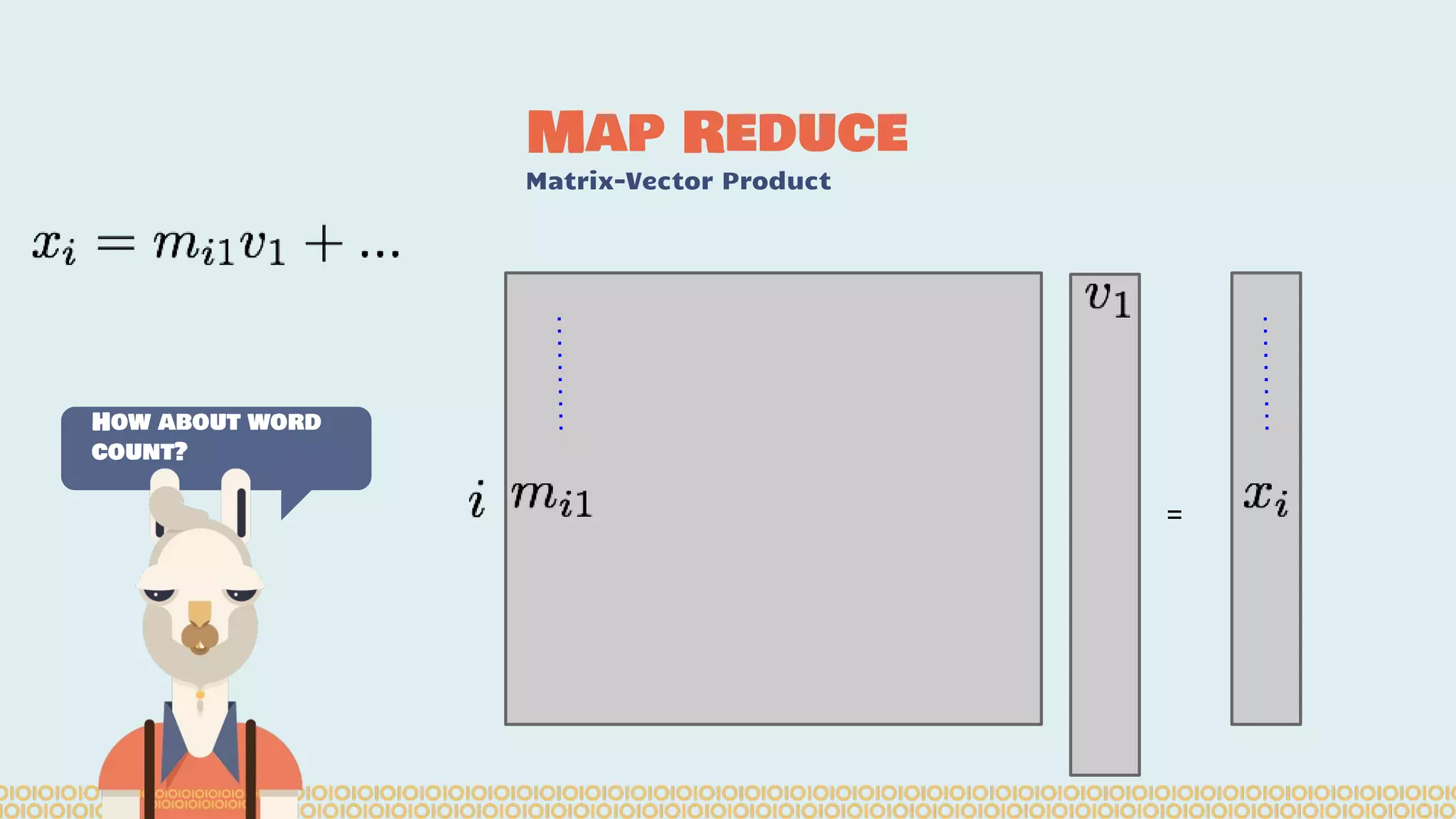
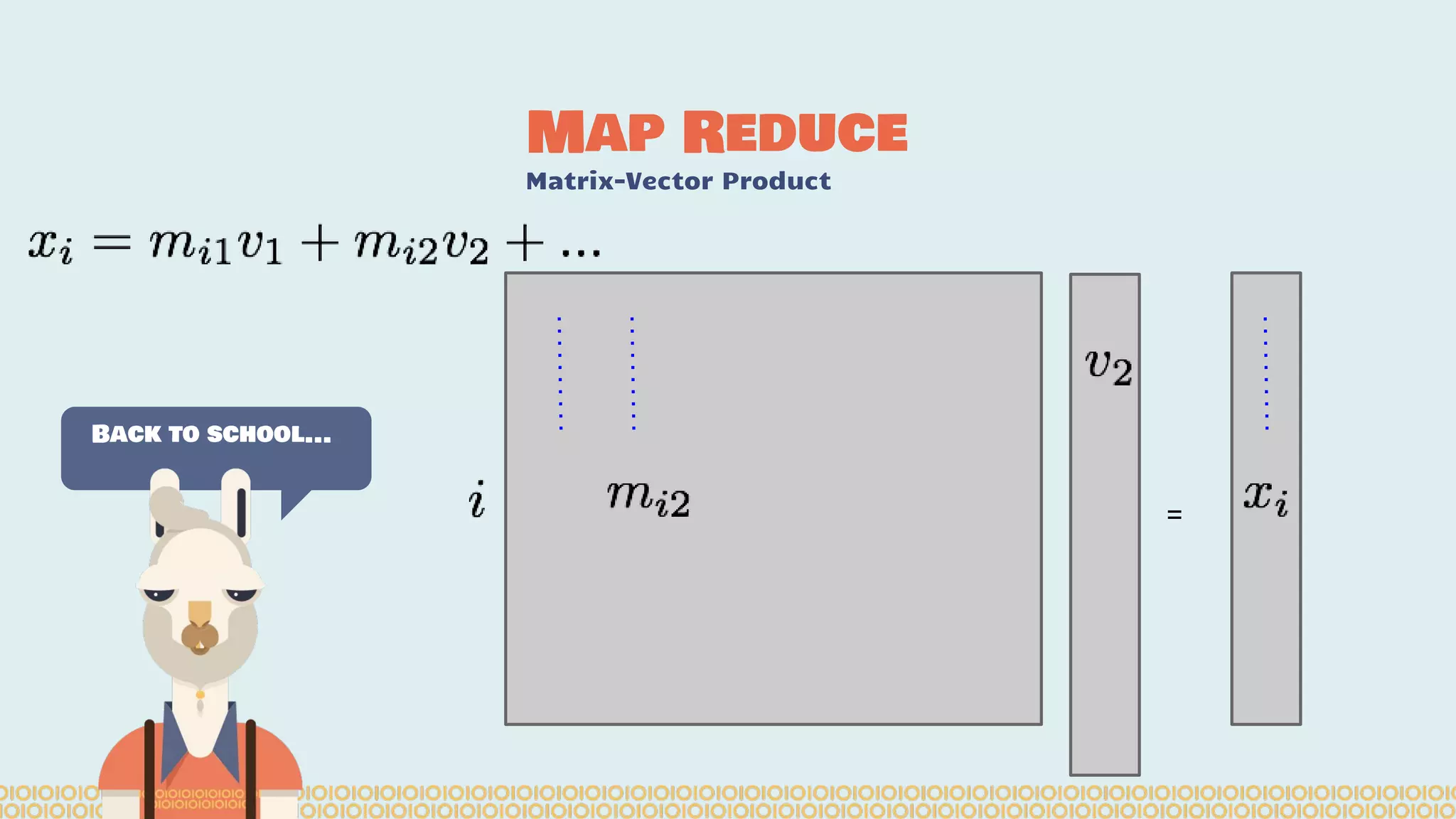
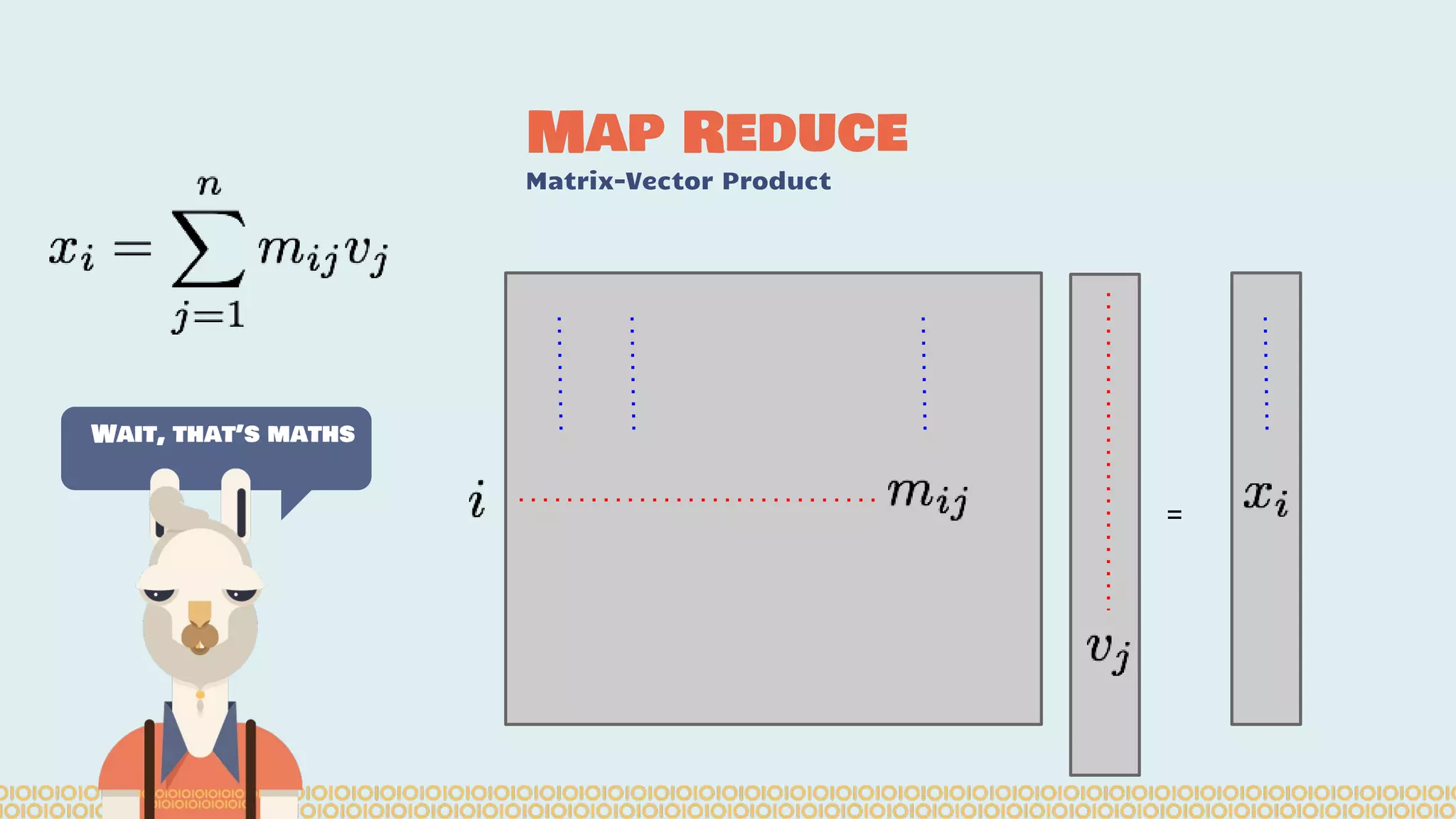

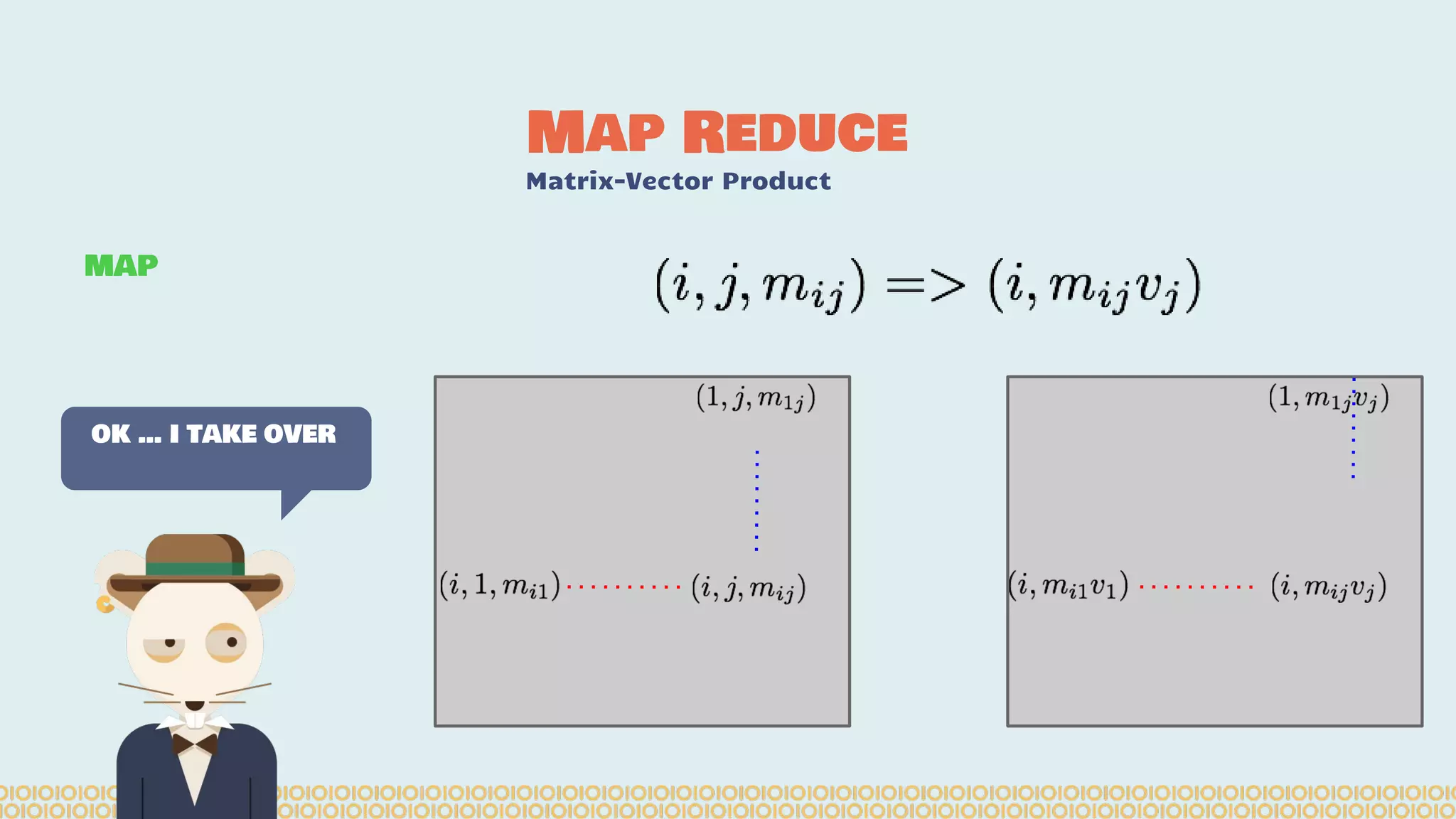



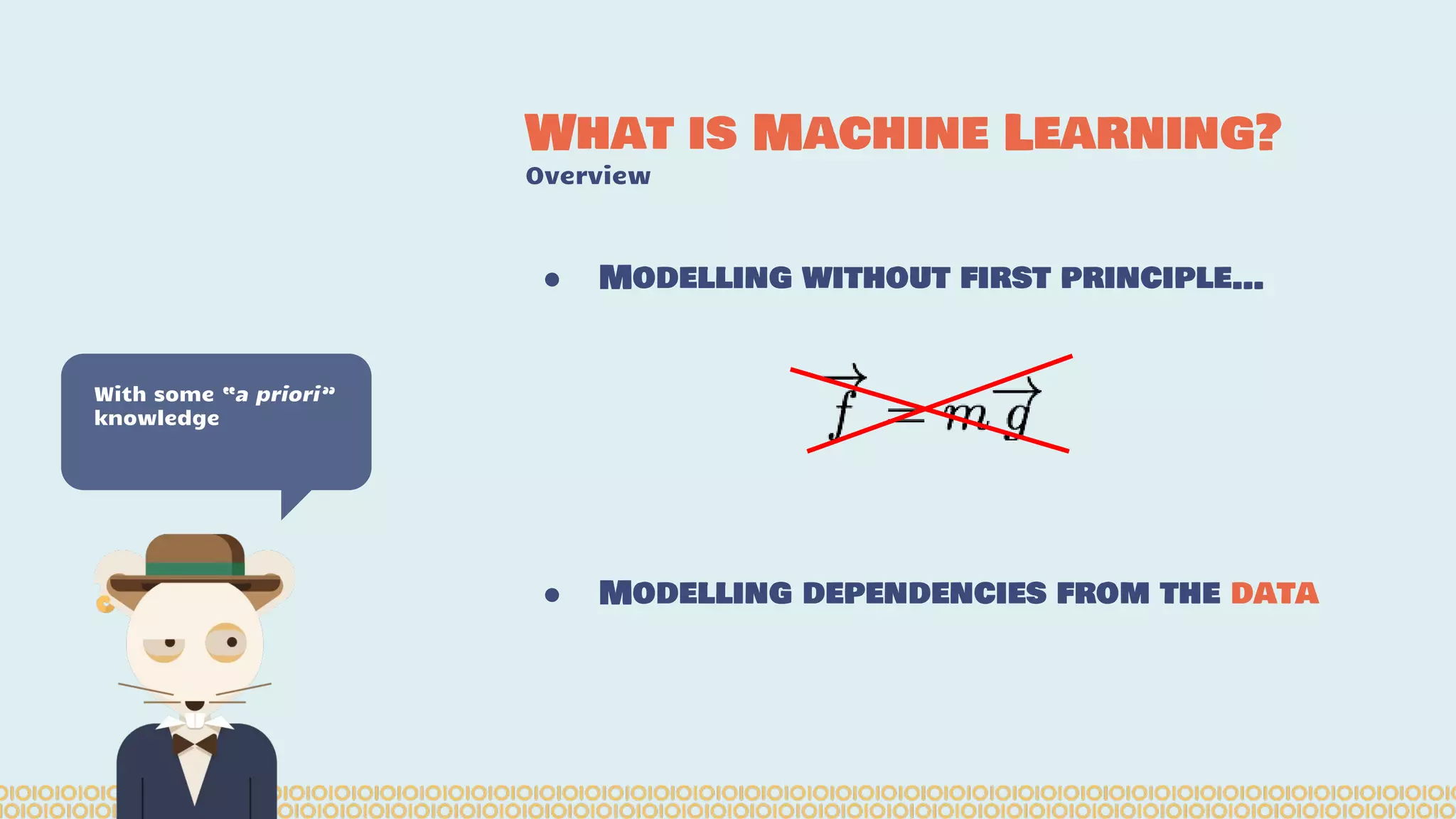
![you cannot prove a vague theory is wrong […] Also, if the process of computing the consequences is indefinite, then with a little skill any experimental result can be made to look like the expected consequences. —Richard Feynman [1964] What is Machine Learning? Science with data Surely You’re Joking Mr…](https://image.slidesharecdn.com/distributedmachinelearning101usingapachesparkfromabrowser-devoxx-151109170914-lva1-app6892/75/Distributed-machine-learning-101-using-apache-spark-from-a-browser-devoxx-be2015-43-2048.jpg)



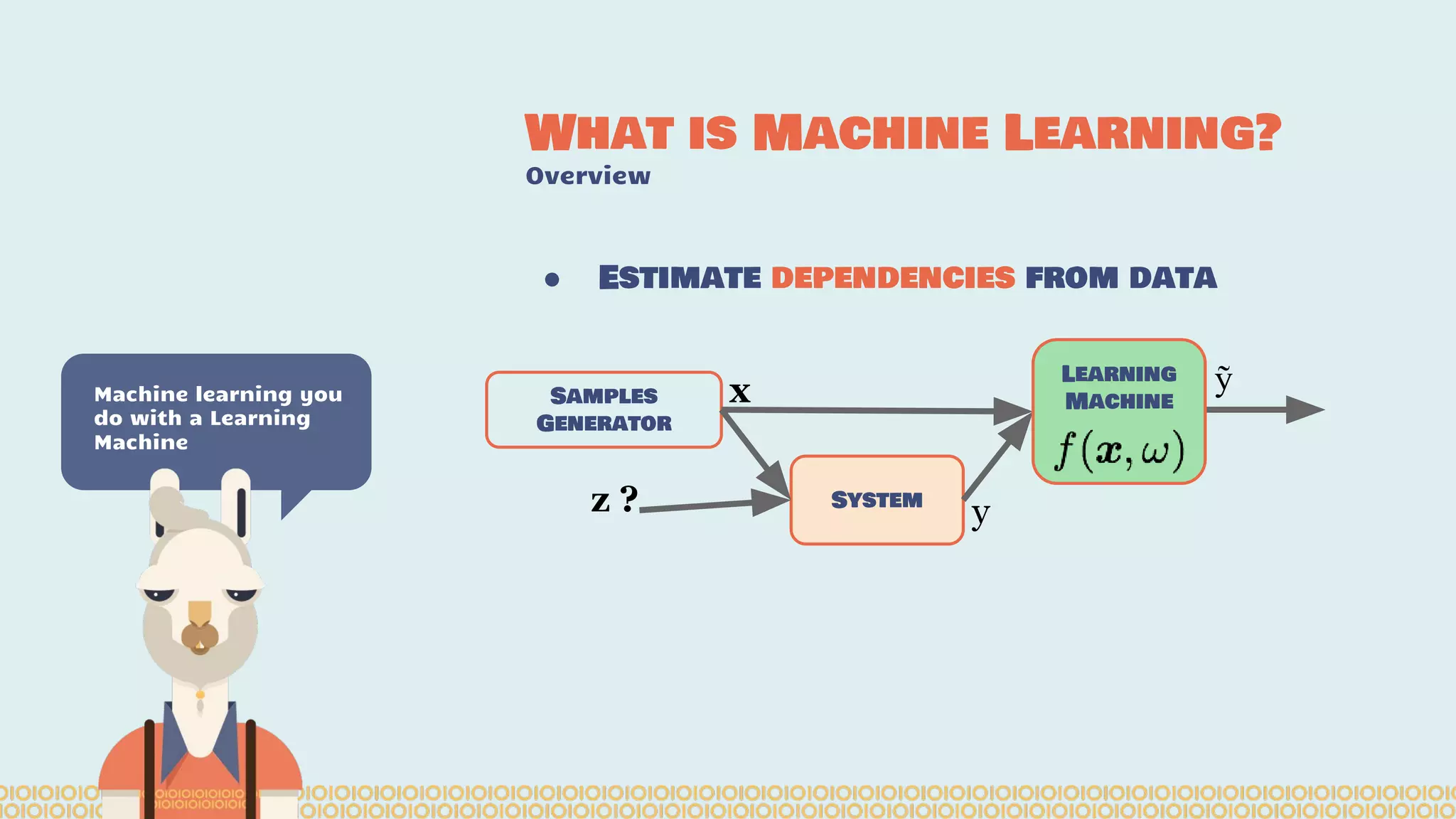
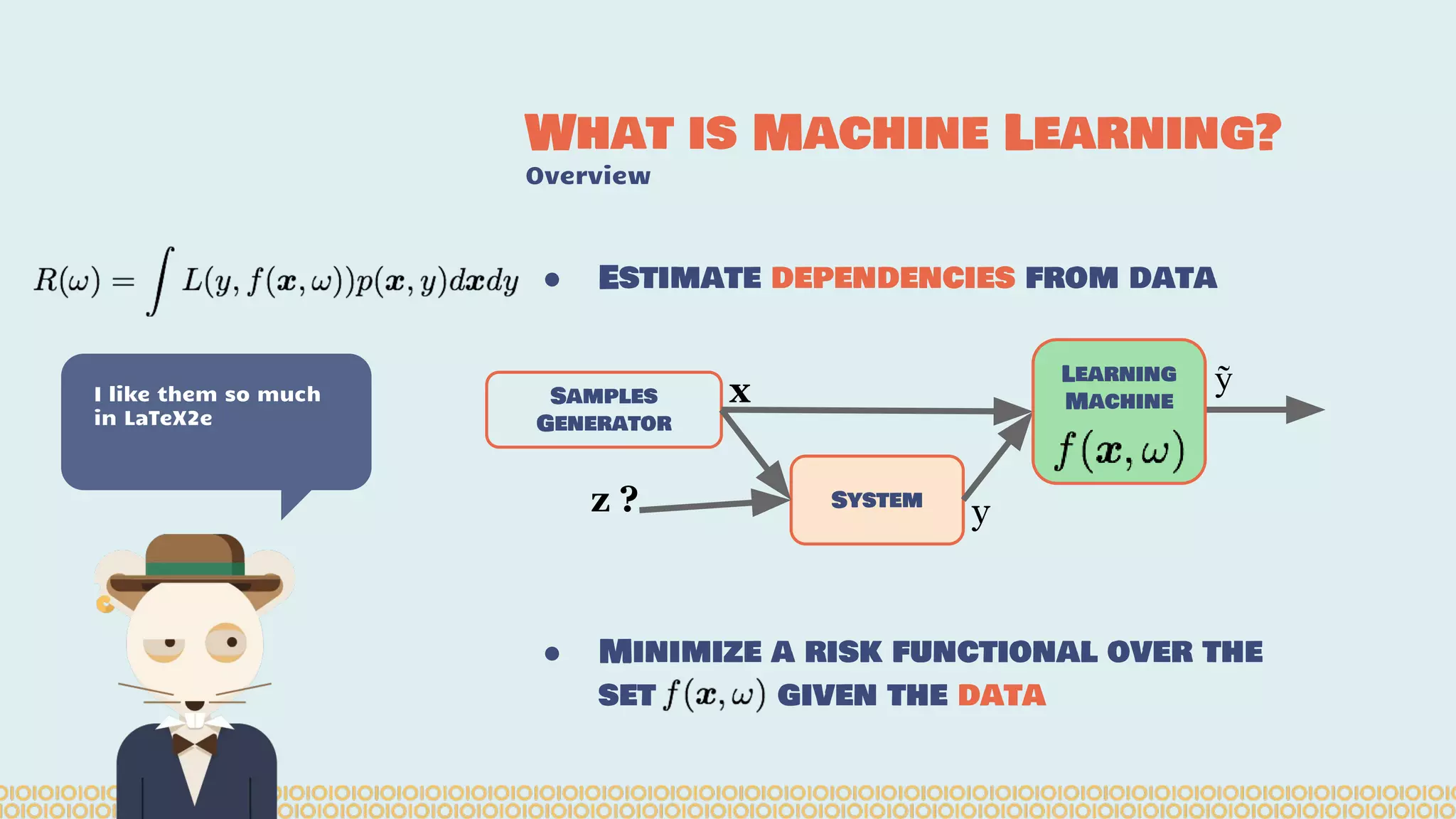



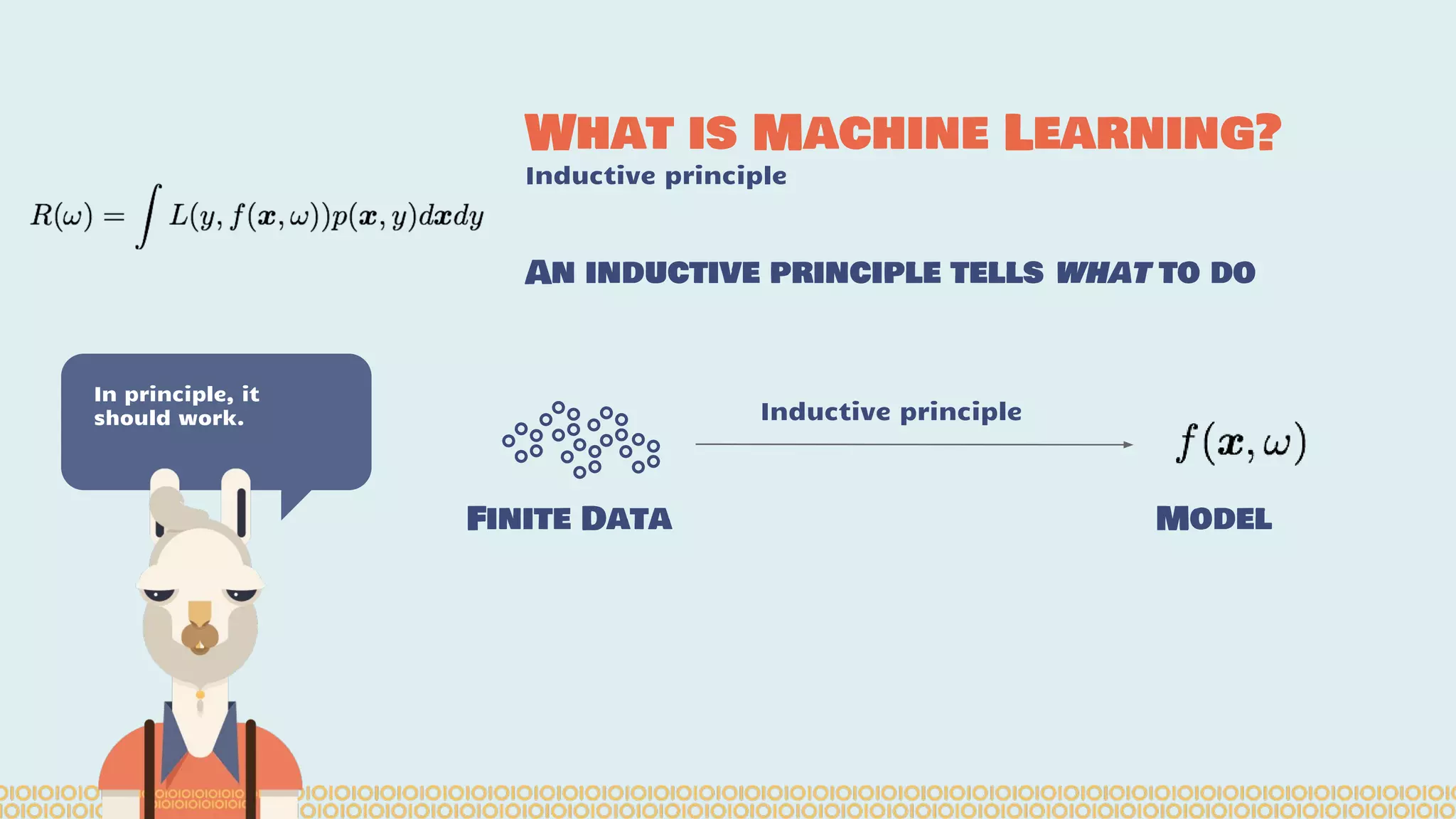






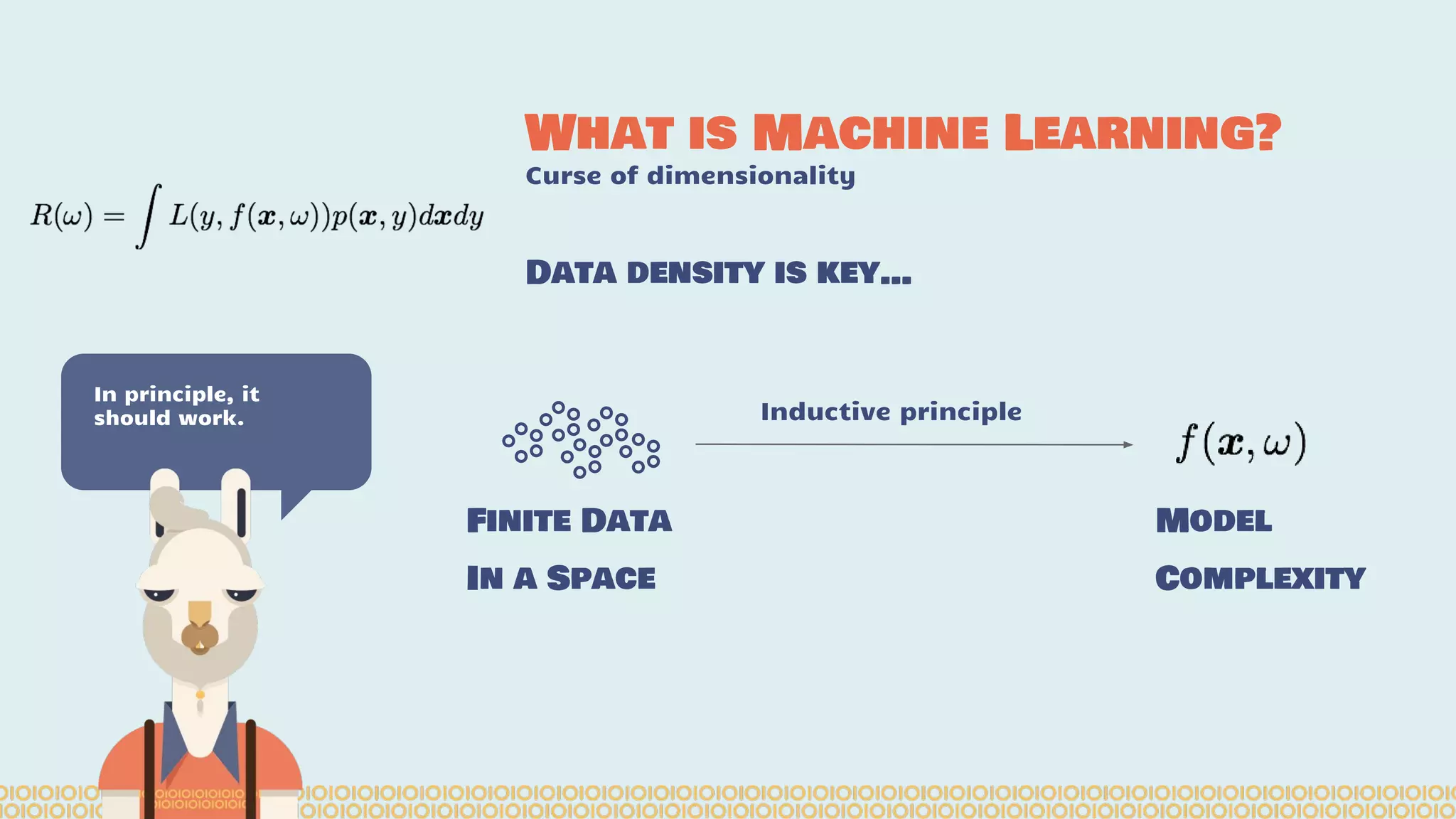














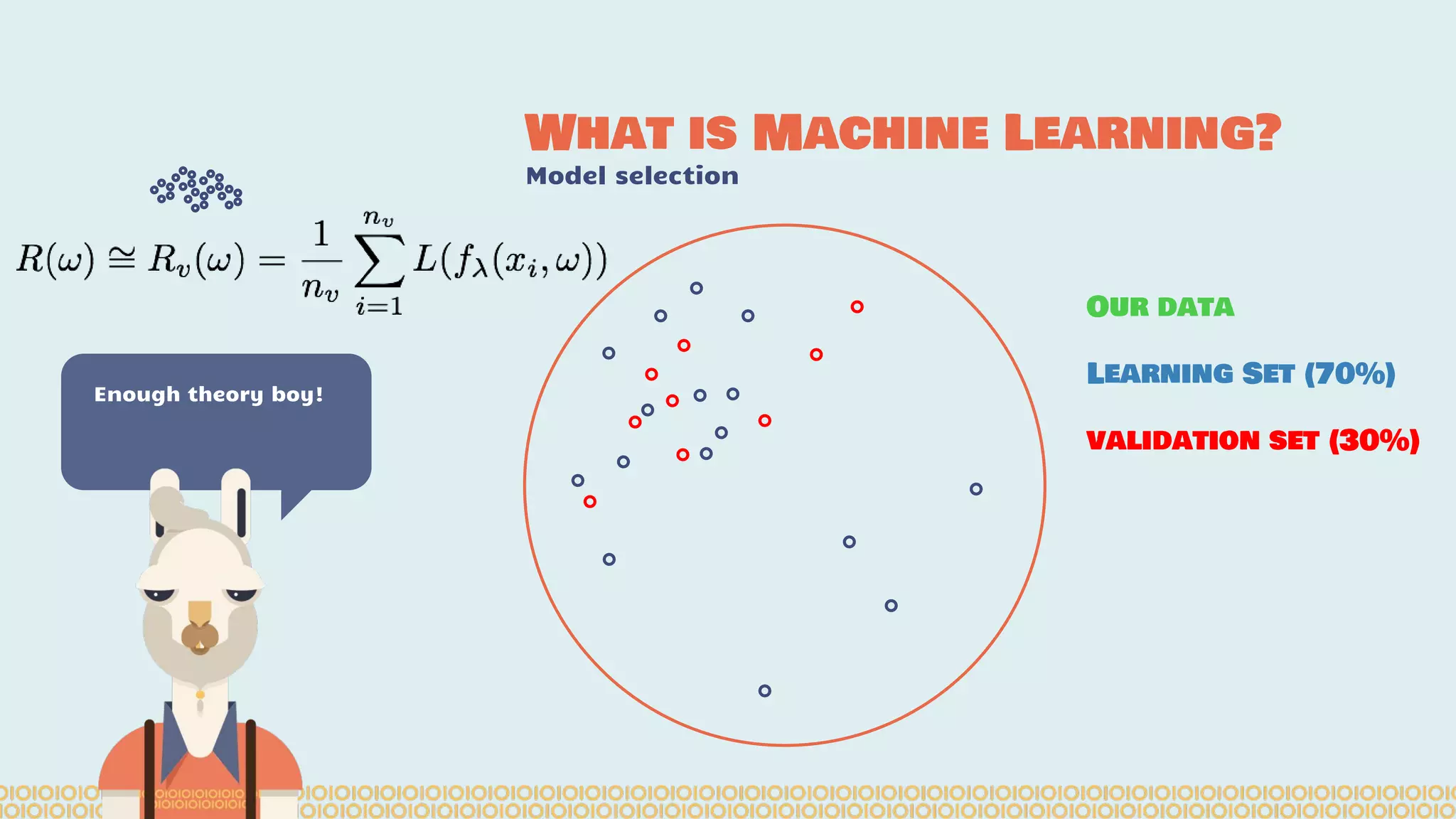
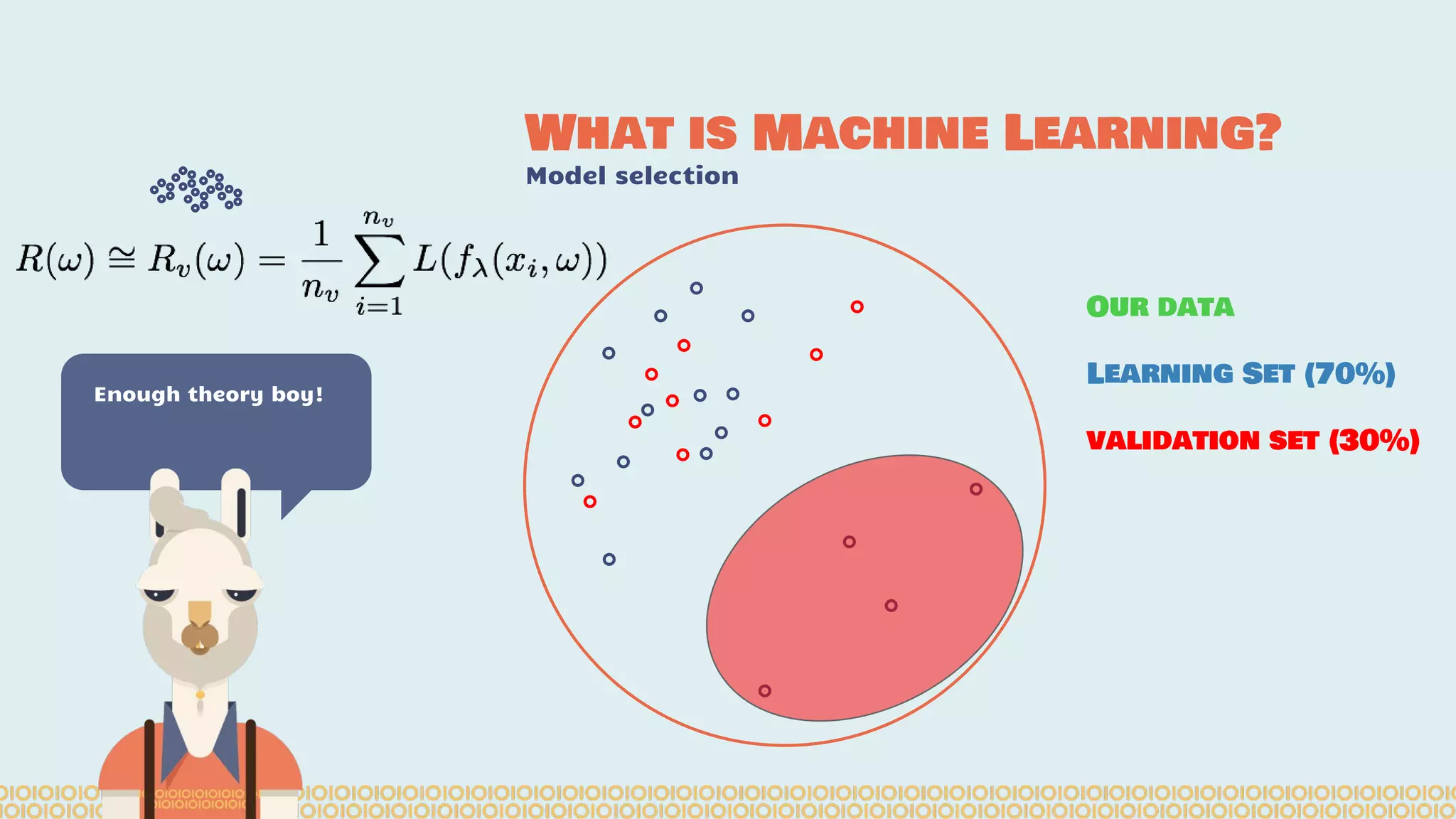
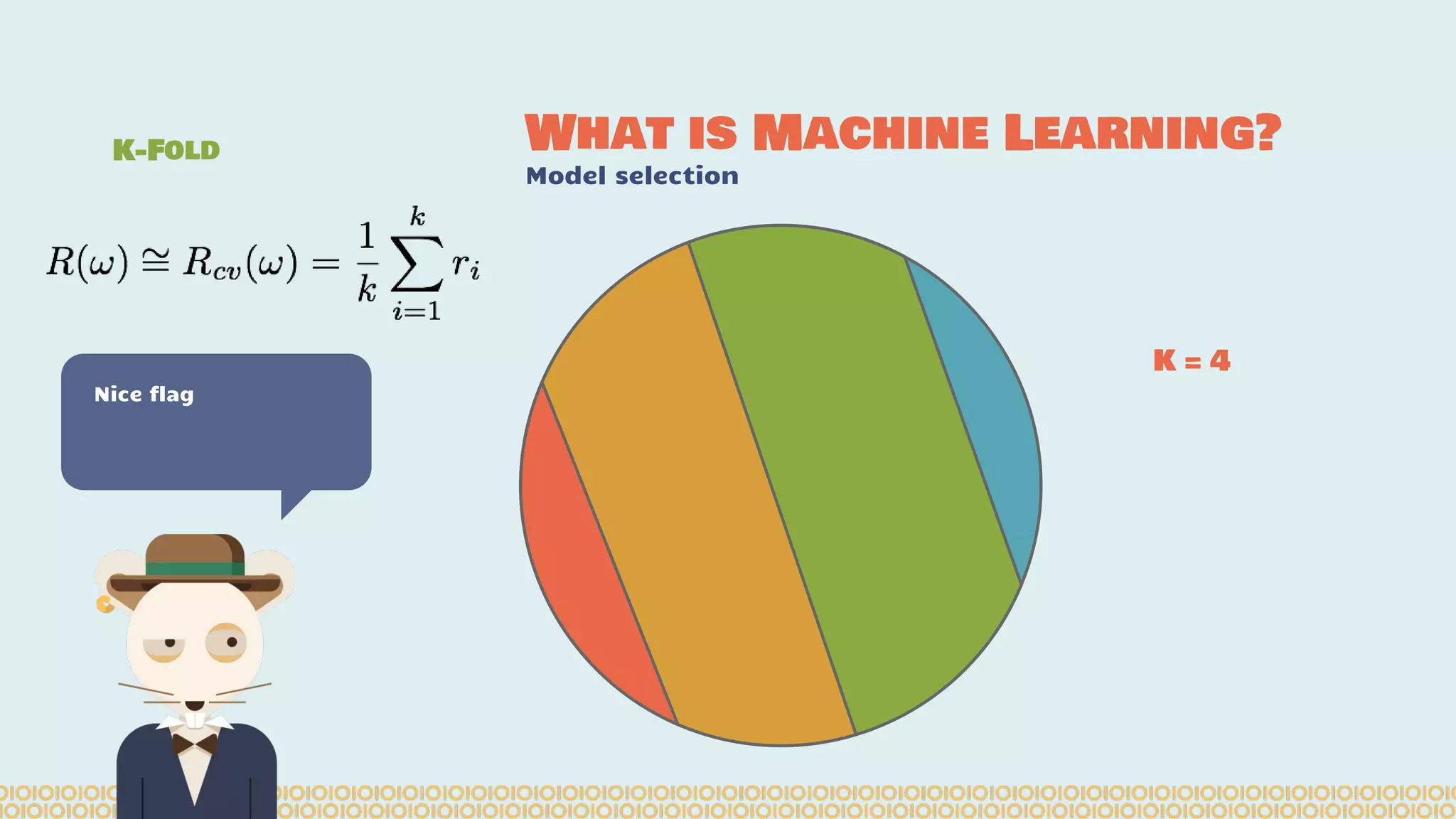









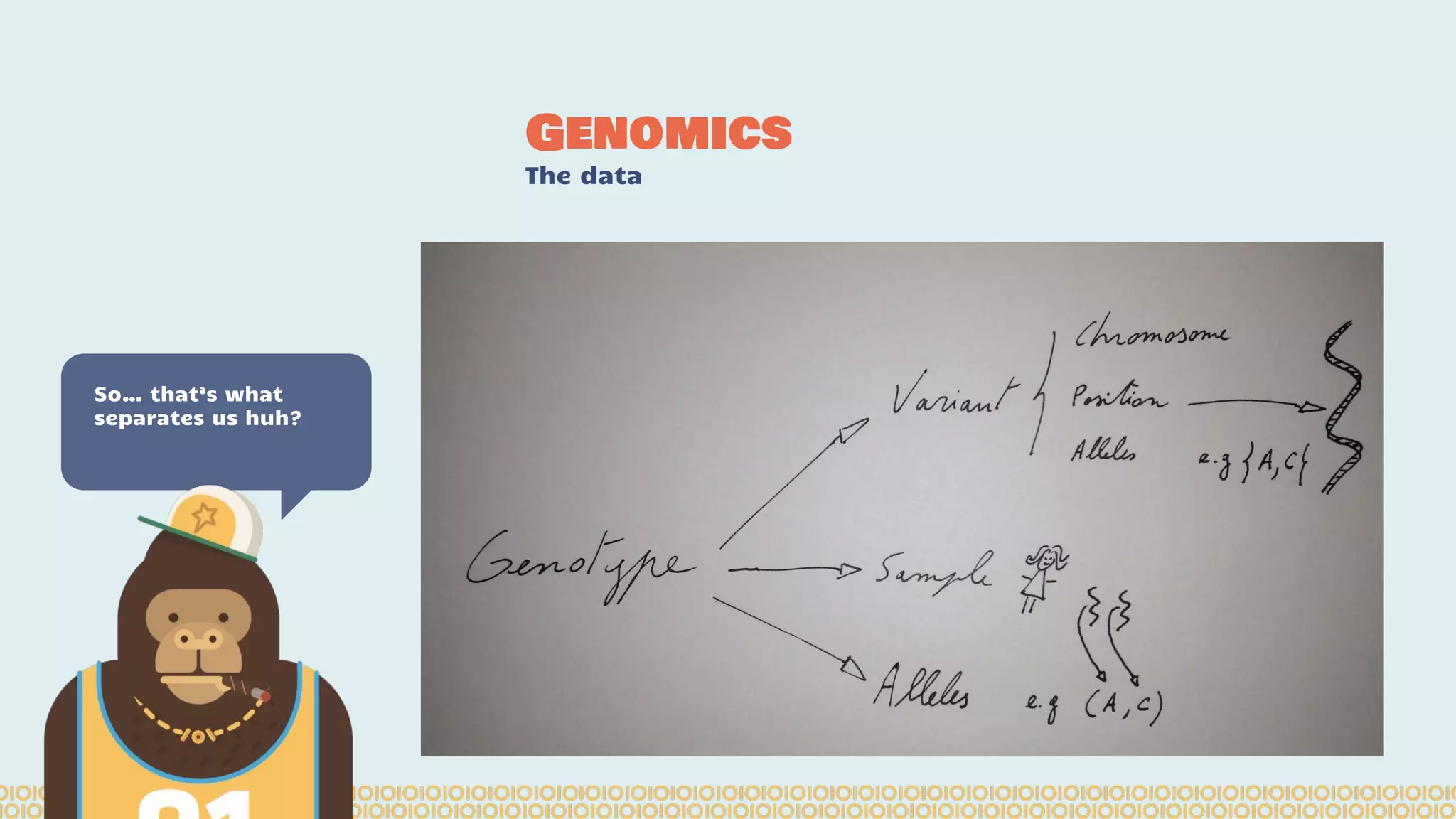
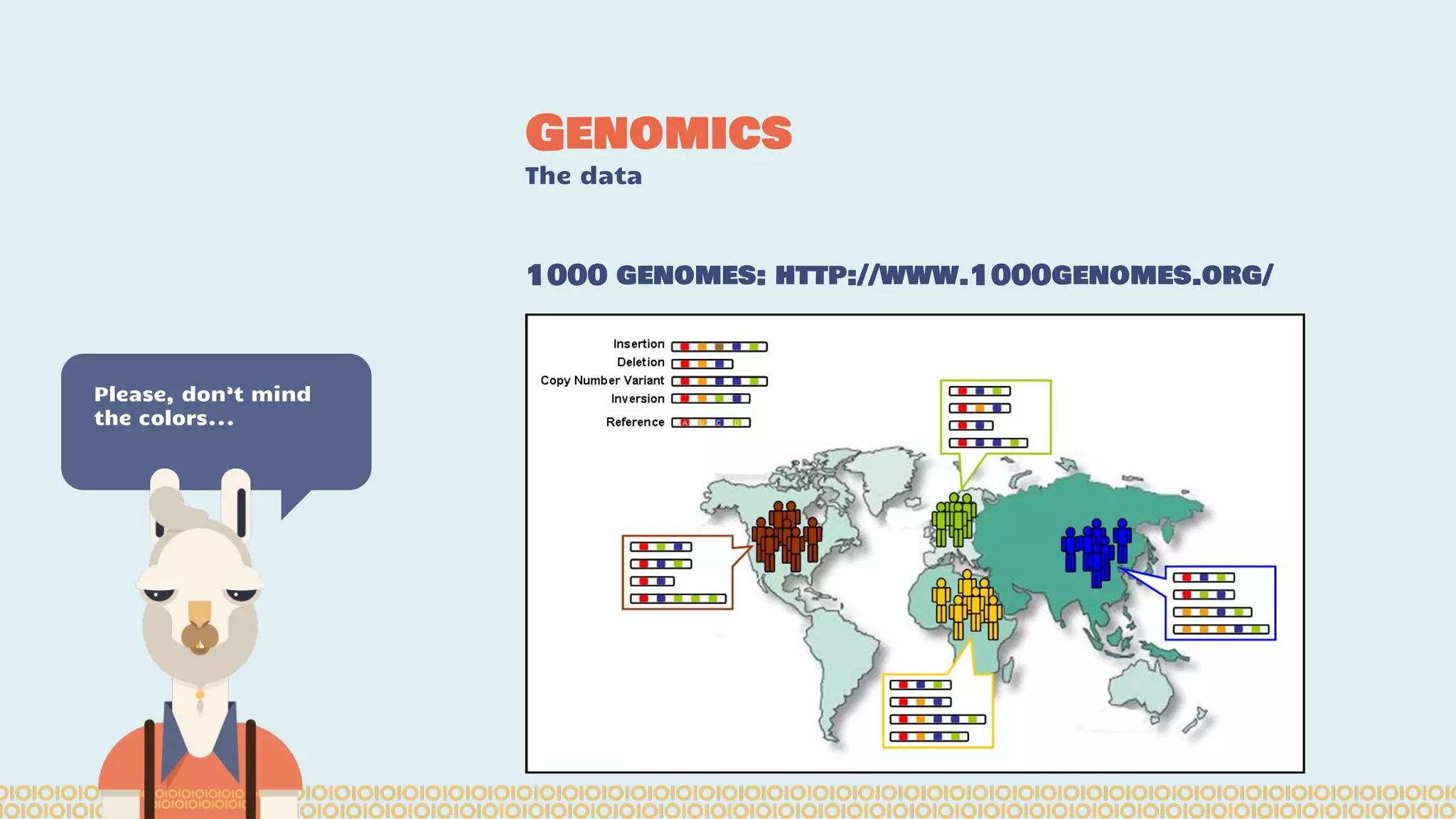








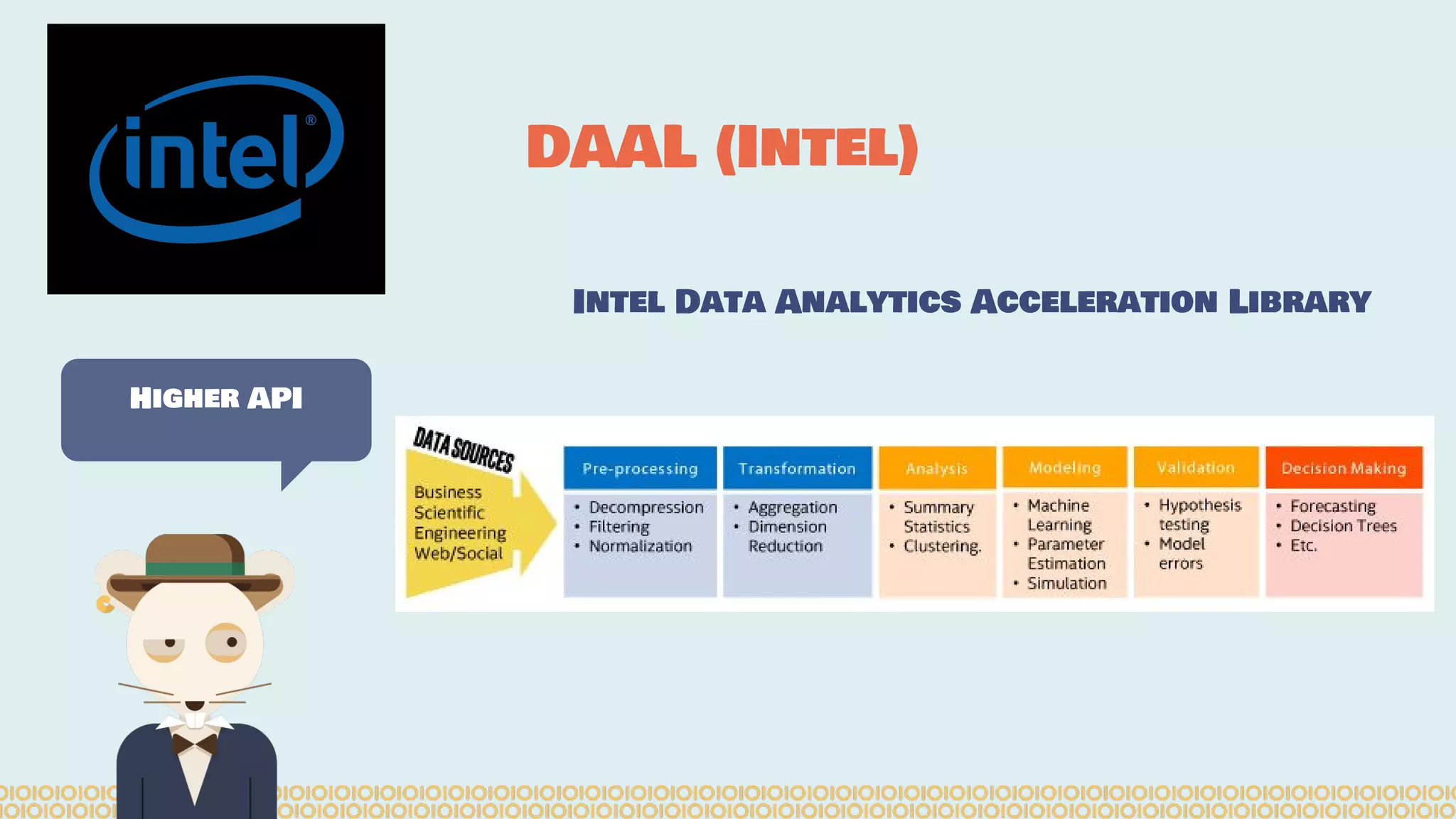



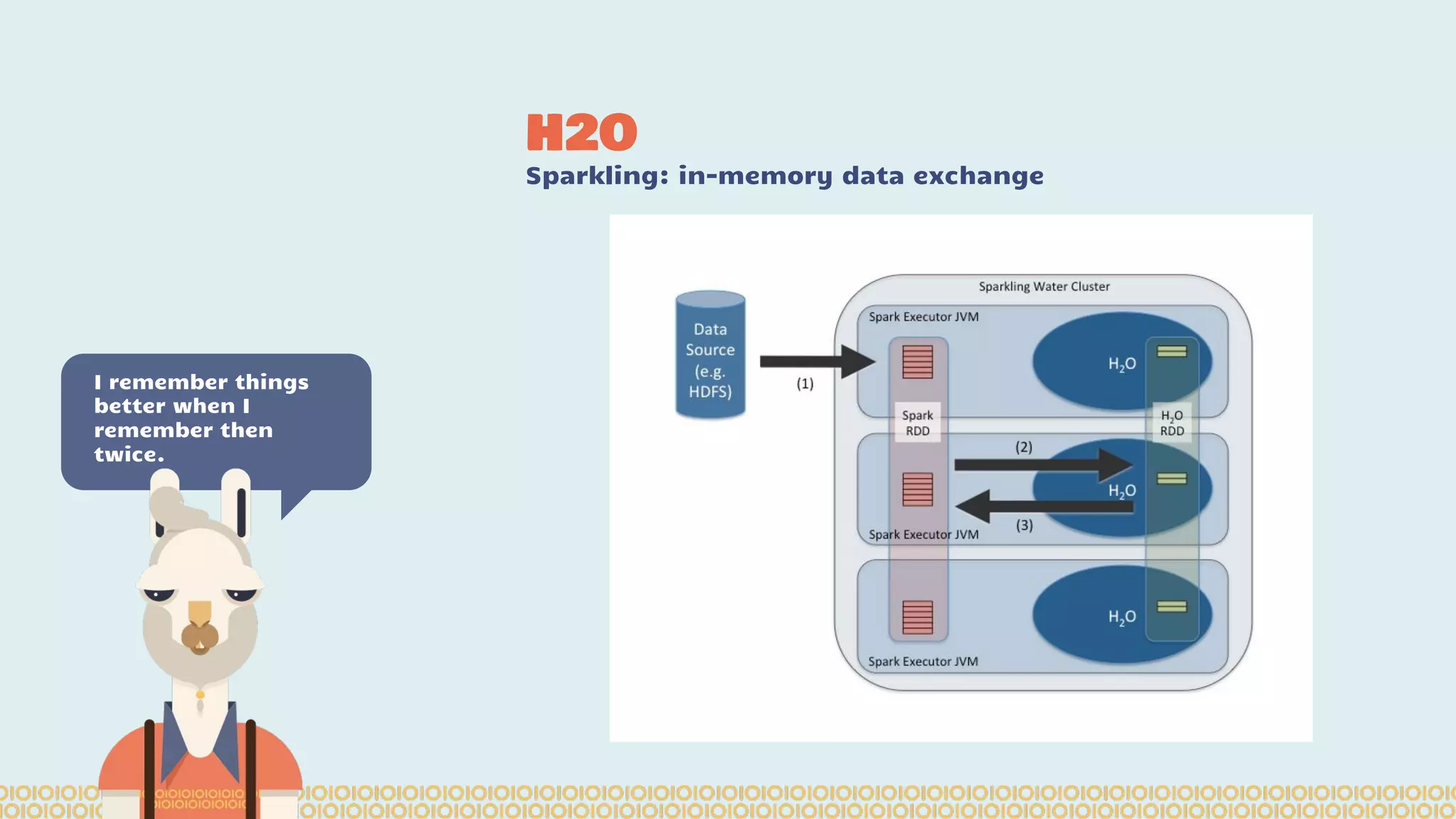


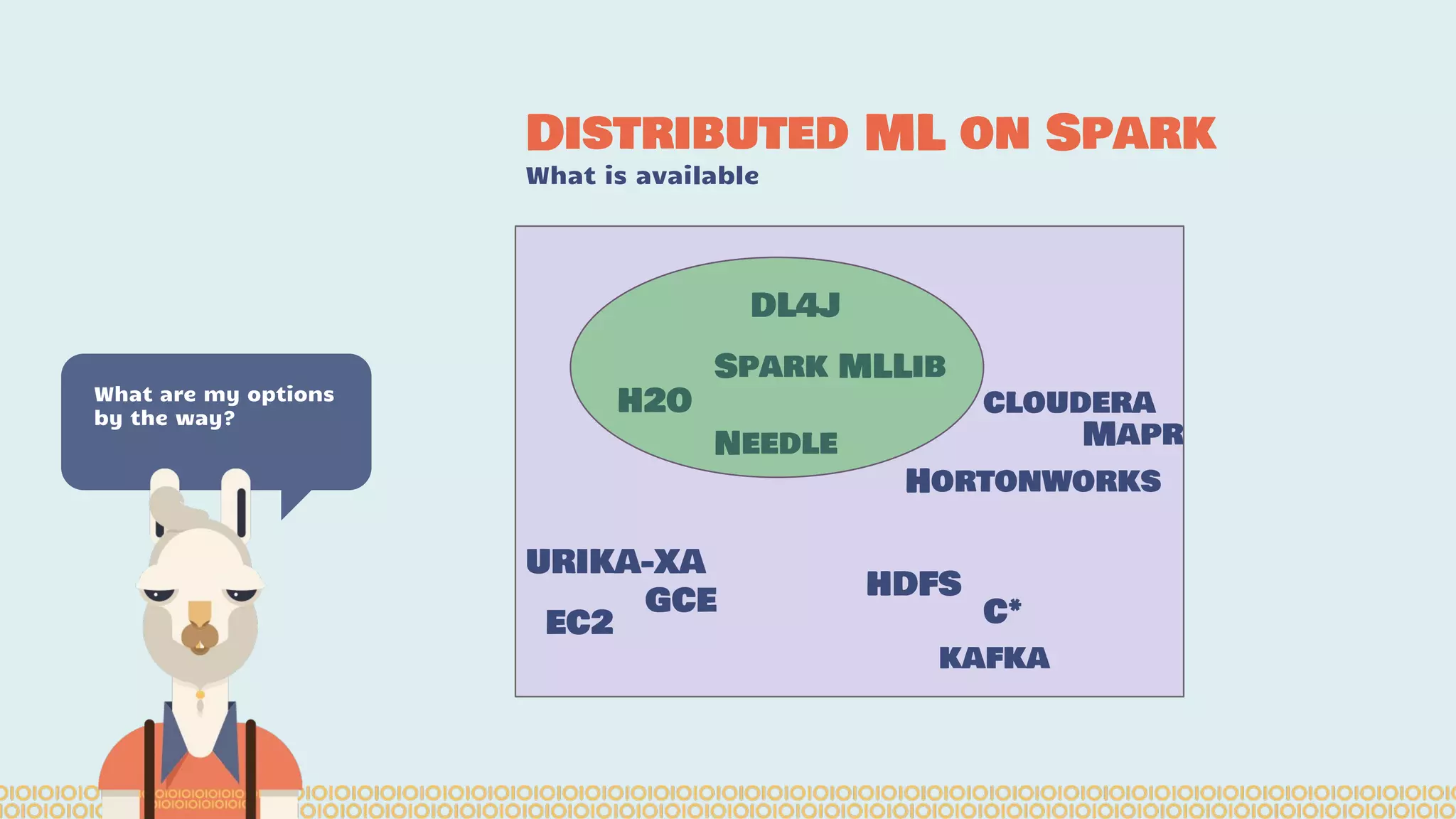

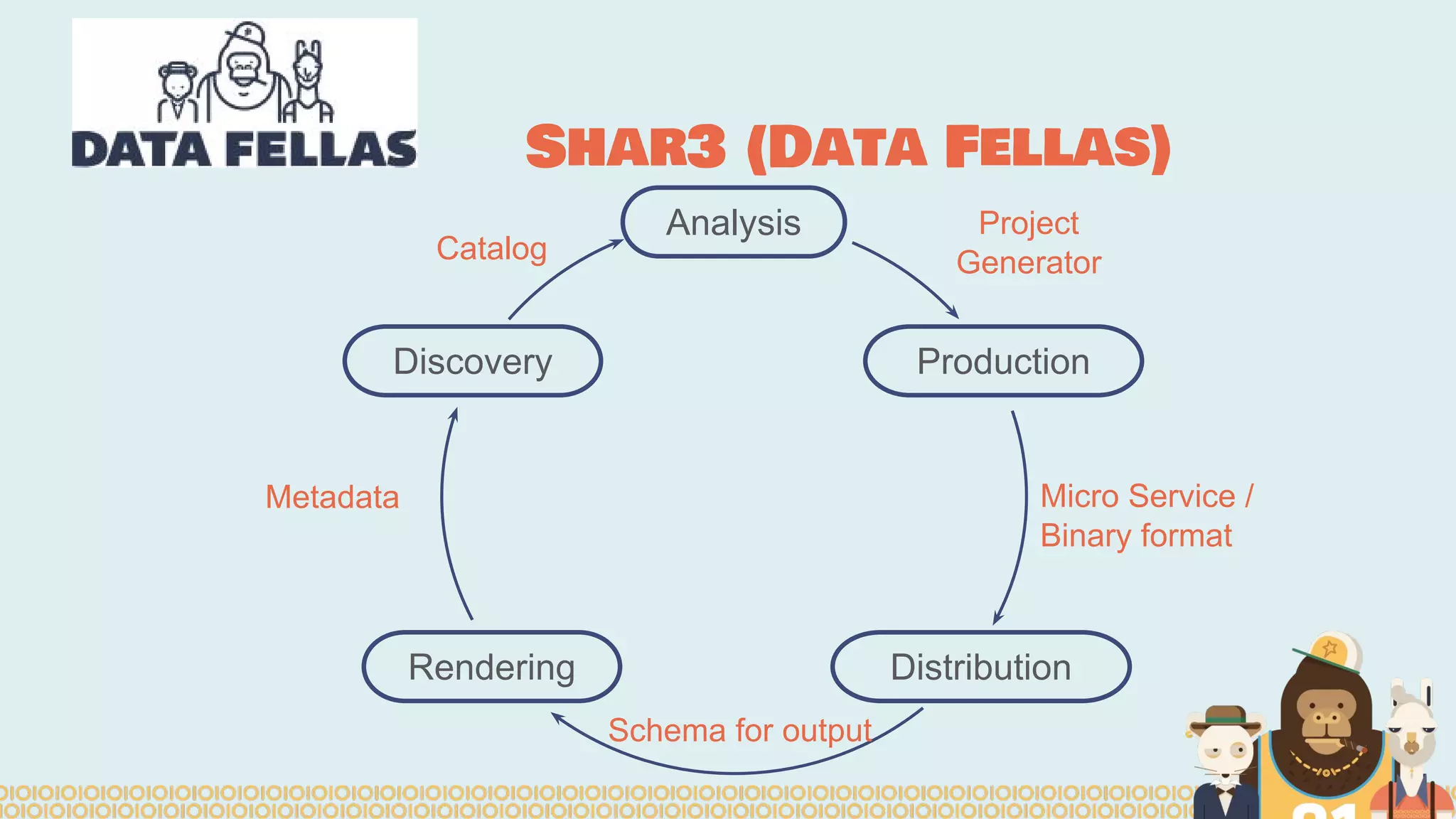


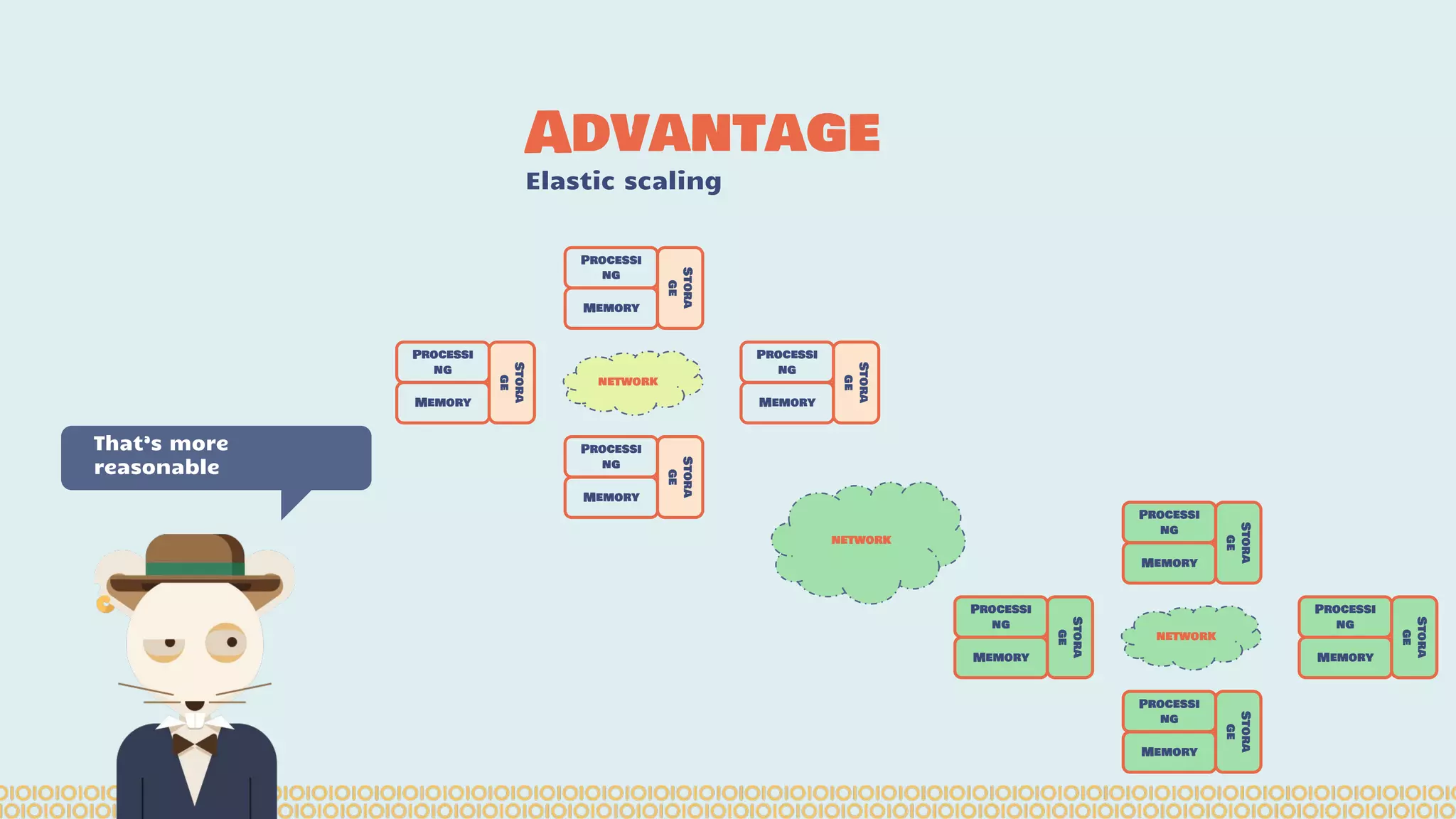
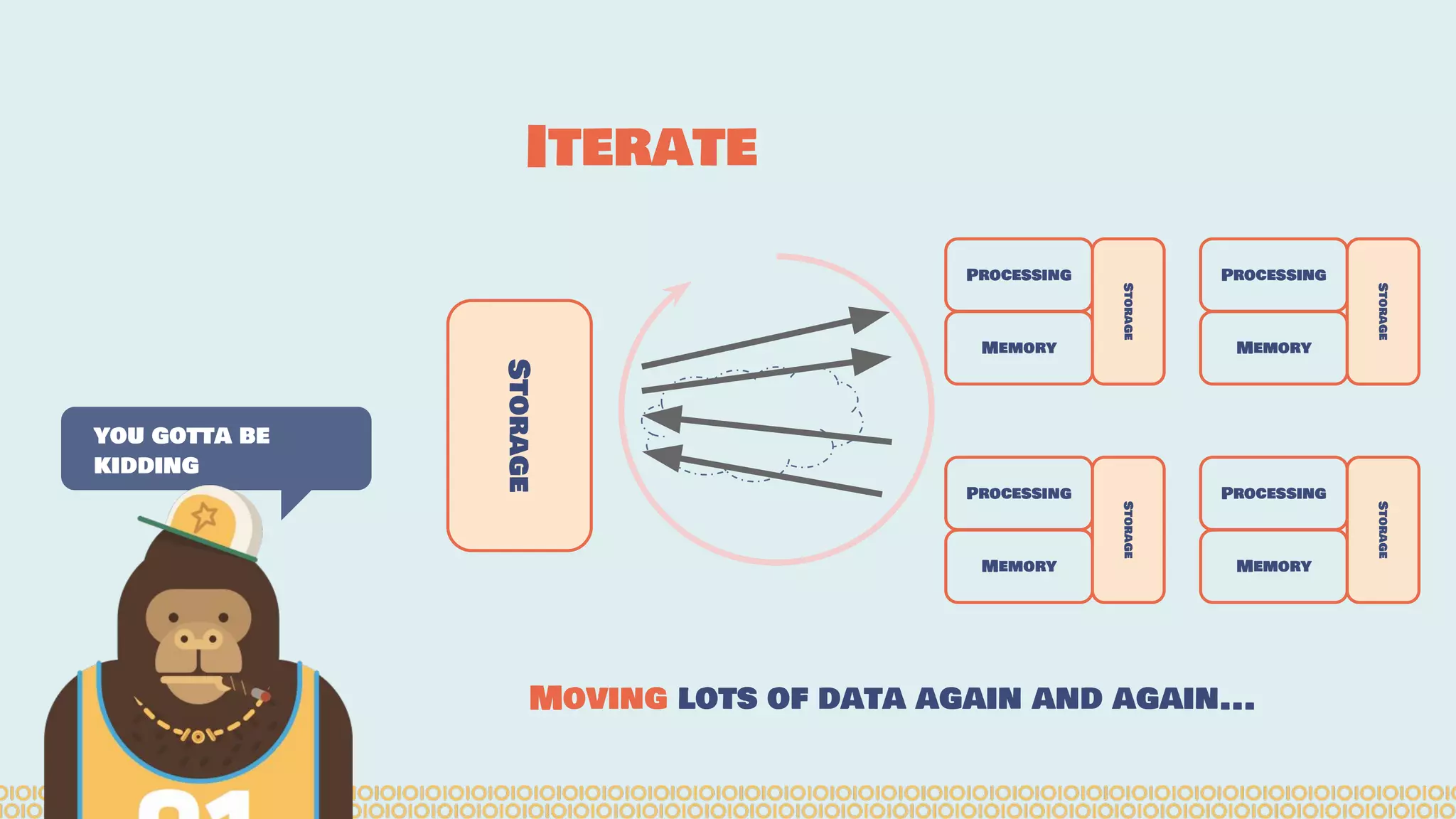
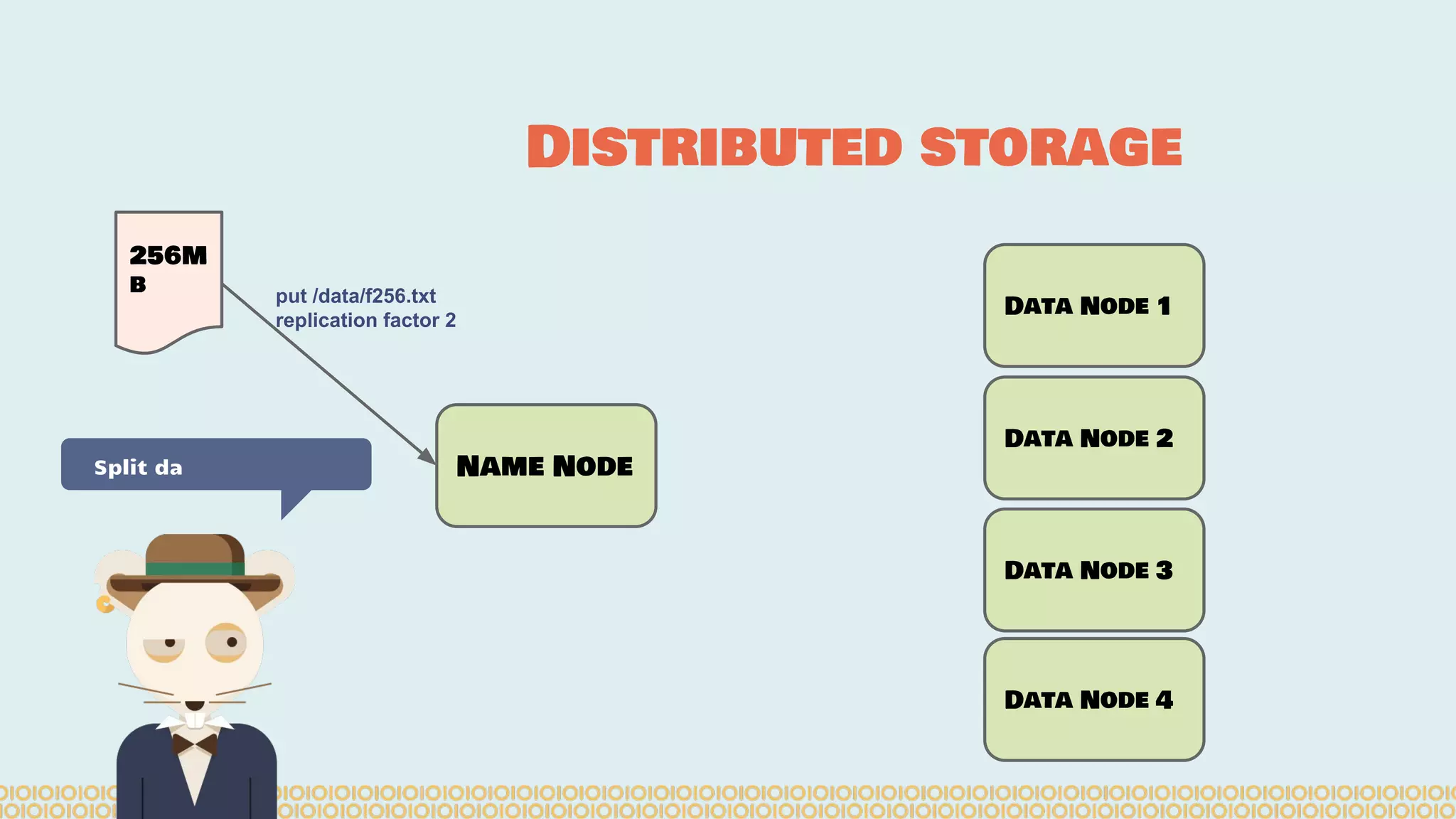
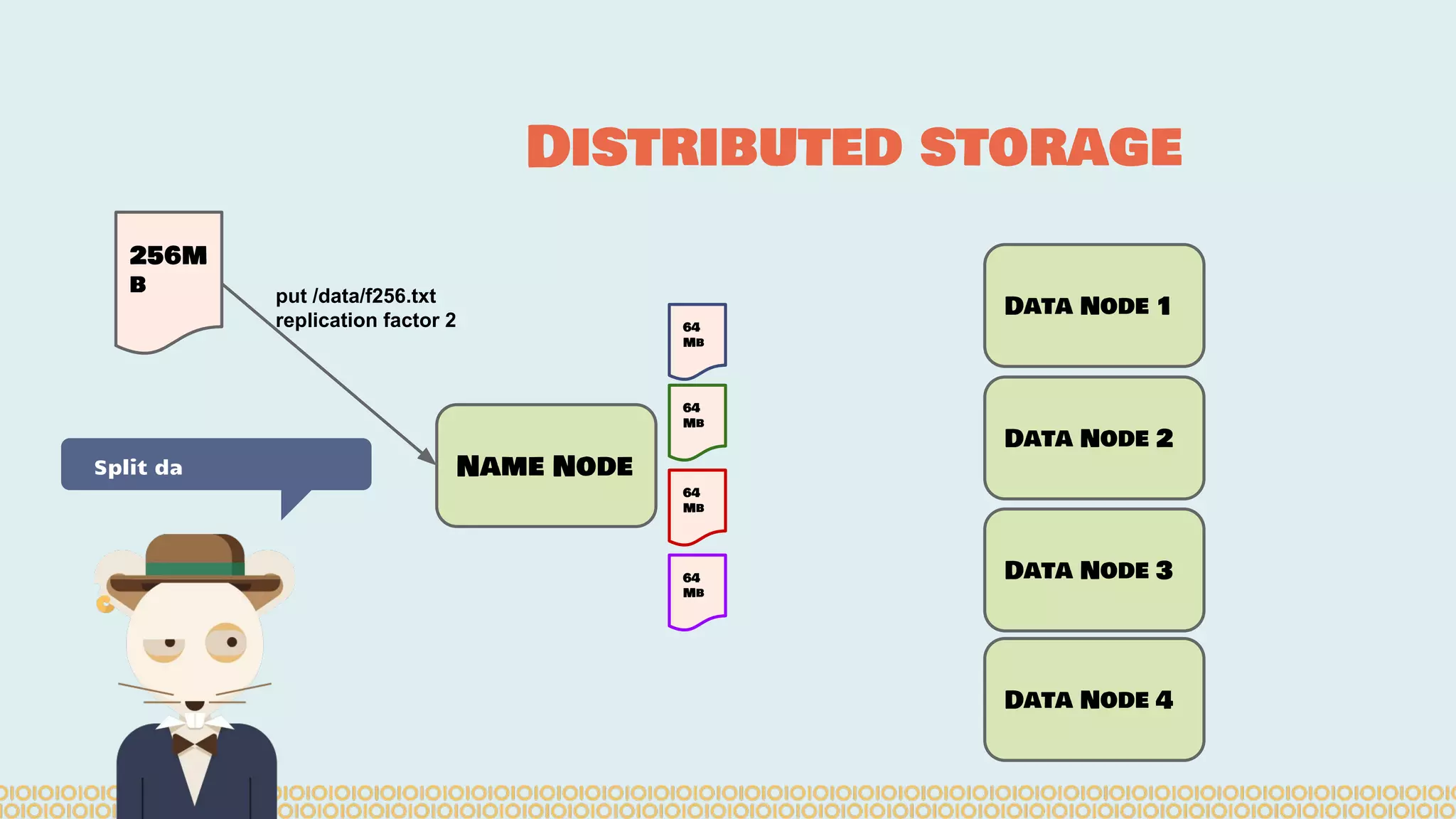
The document discusses distributed machine learning using Apache Spark, highlighting the advantages of parallel processing through distributed computing and the challenges associated with data partitioning. It provides an overview of machine learning concepts such as supervised and unsupervised learning, regularization, and model selection, alongside examples of algorithms and their applications. Additionally, it explores various tools and frameworks within the Spark ecosystem that facilitate large-scale data processing and machine learning tasks.