




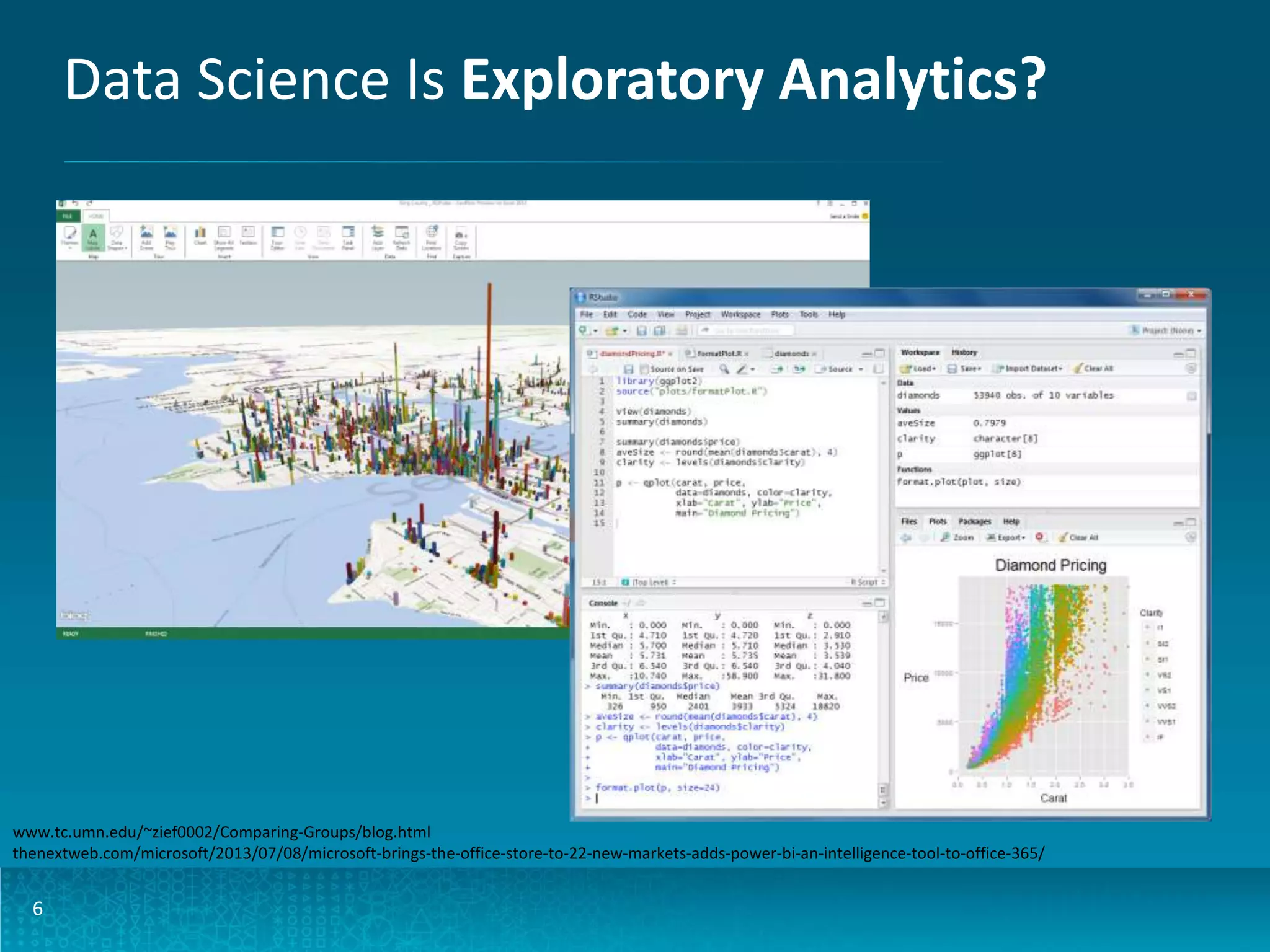

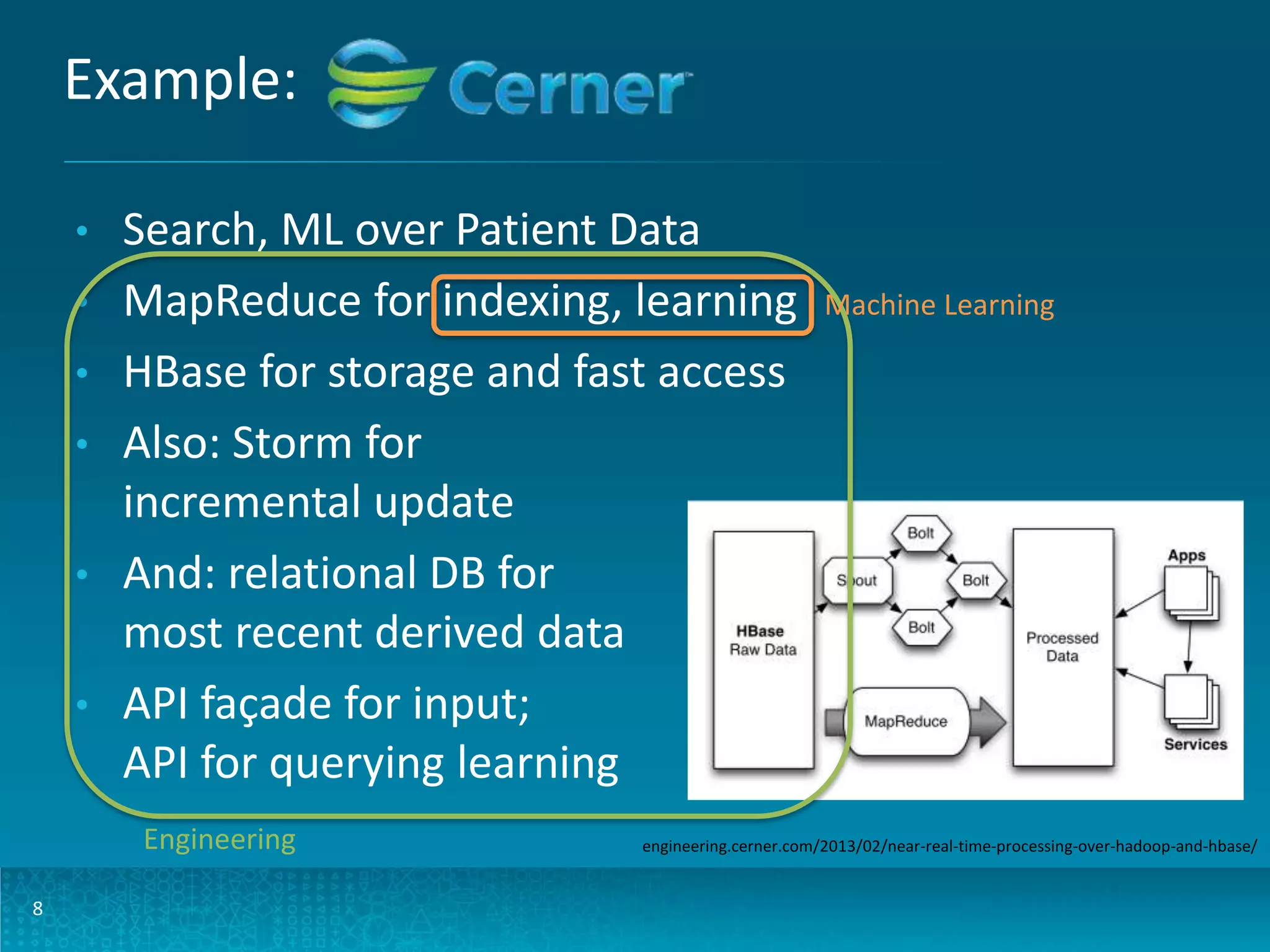


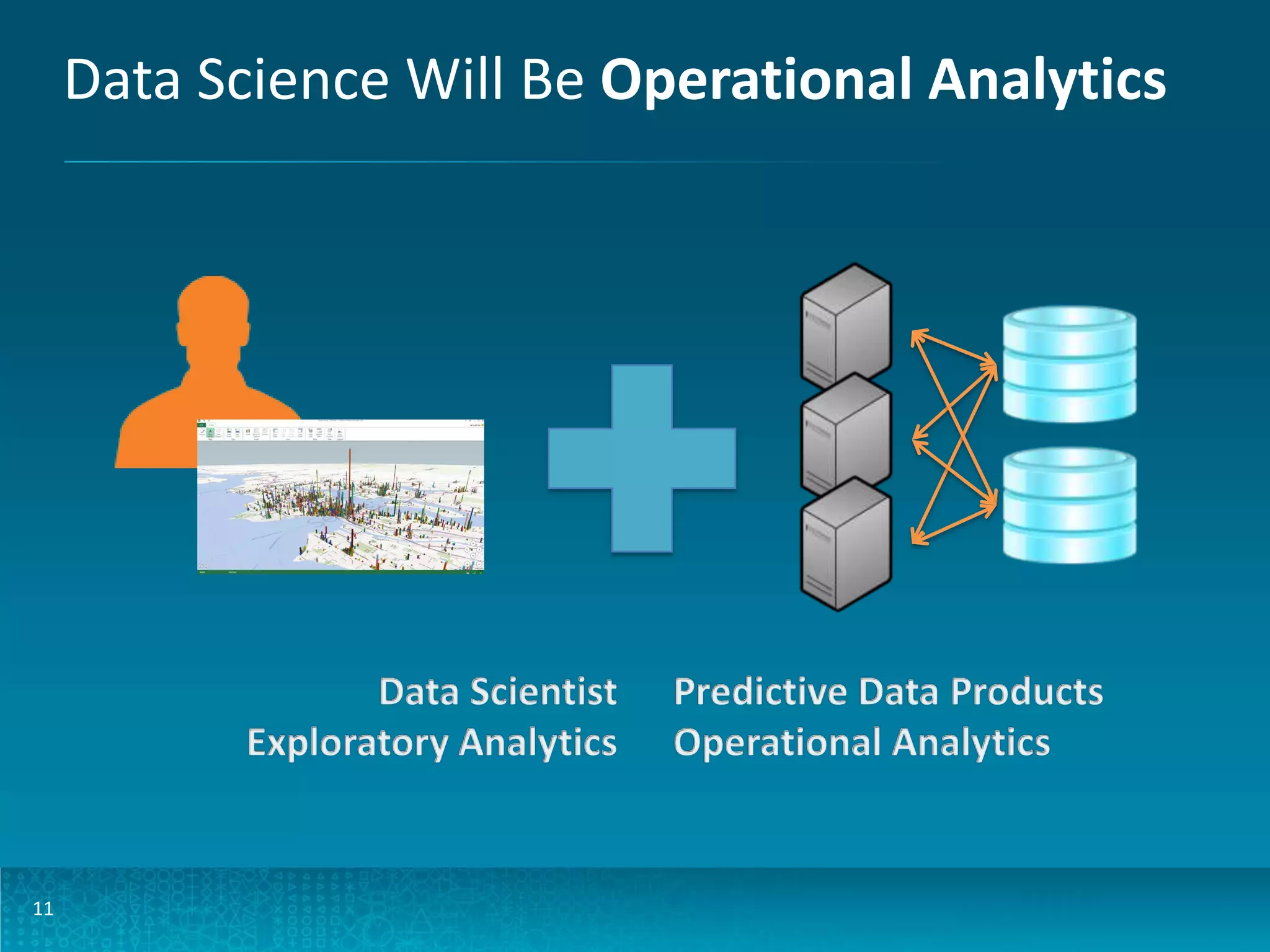
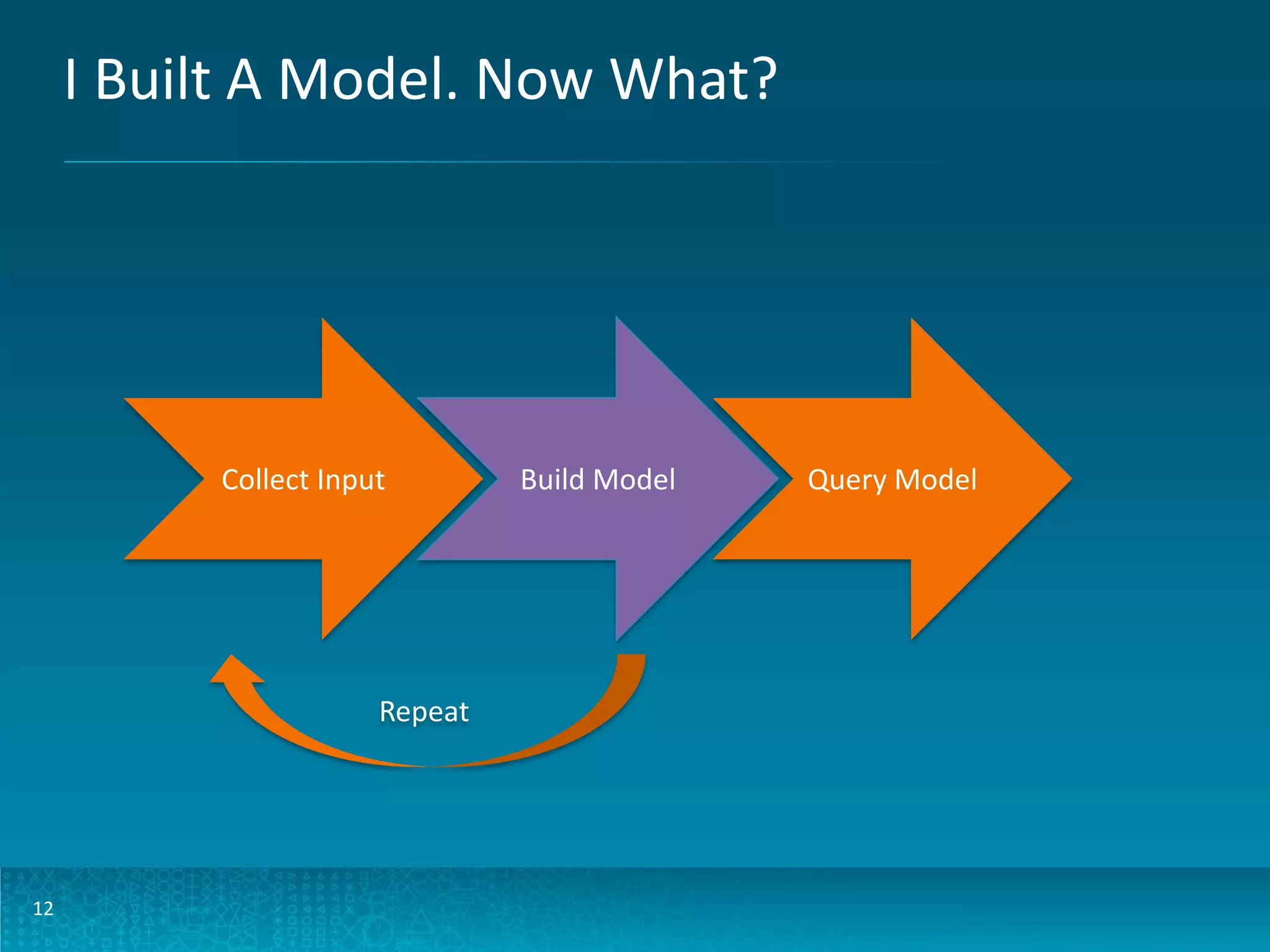




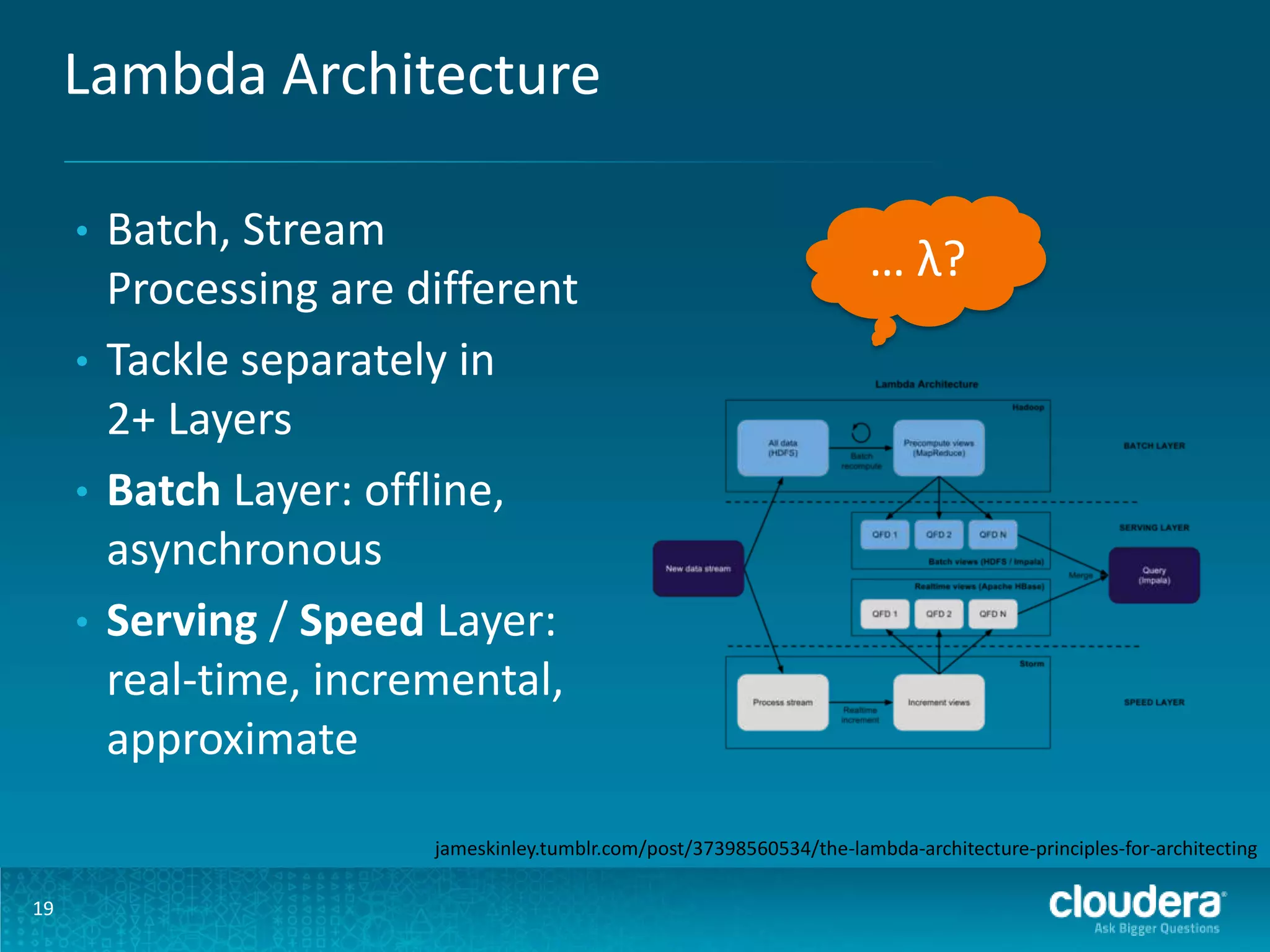
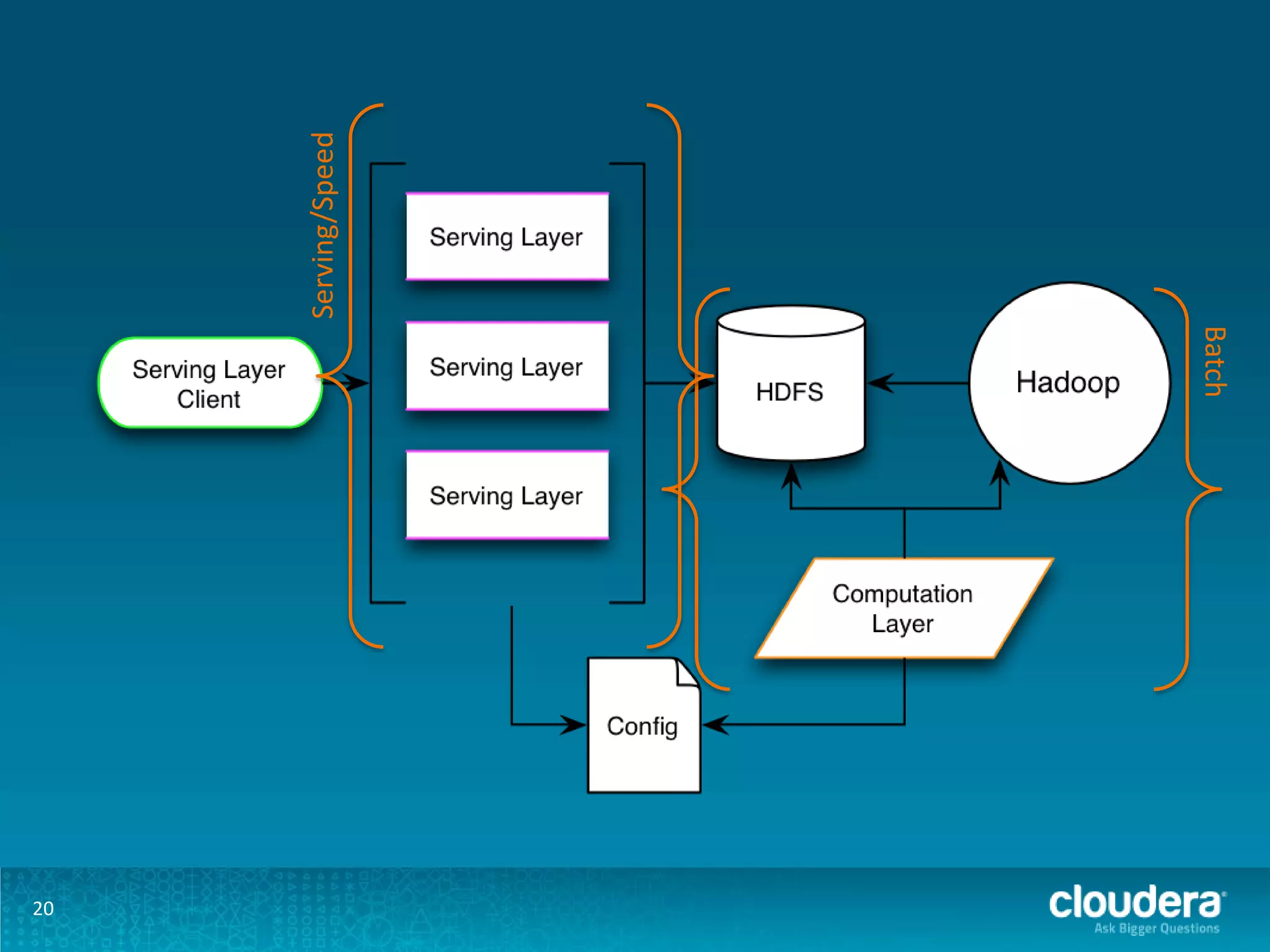









The document discusses design patterns for large-scale real-time learning using technologies like Apache Hadoop and HBase. It emphasizes the importance of operational analytics, machine learning models, and the distinction between batch and real-time processing through a Lambda architecture. Key components include model building, serving, and the use of PMML for standardized predictive modeling.