Download to read offline


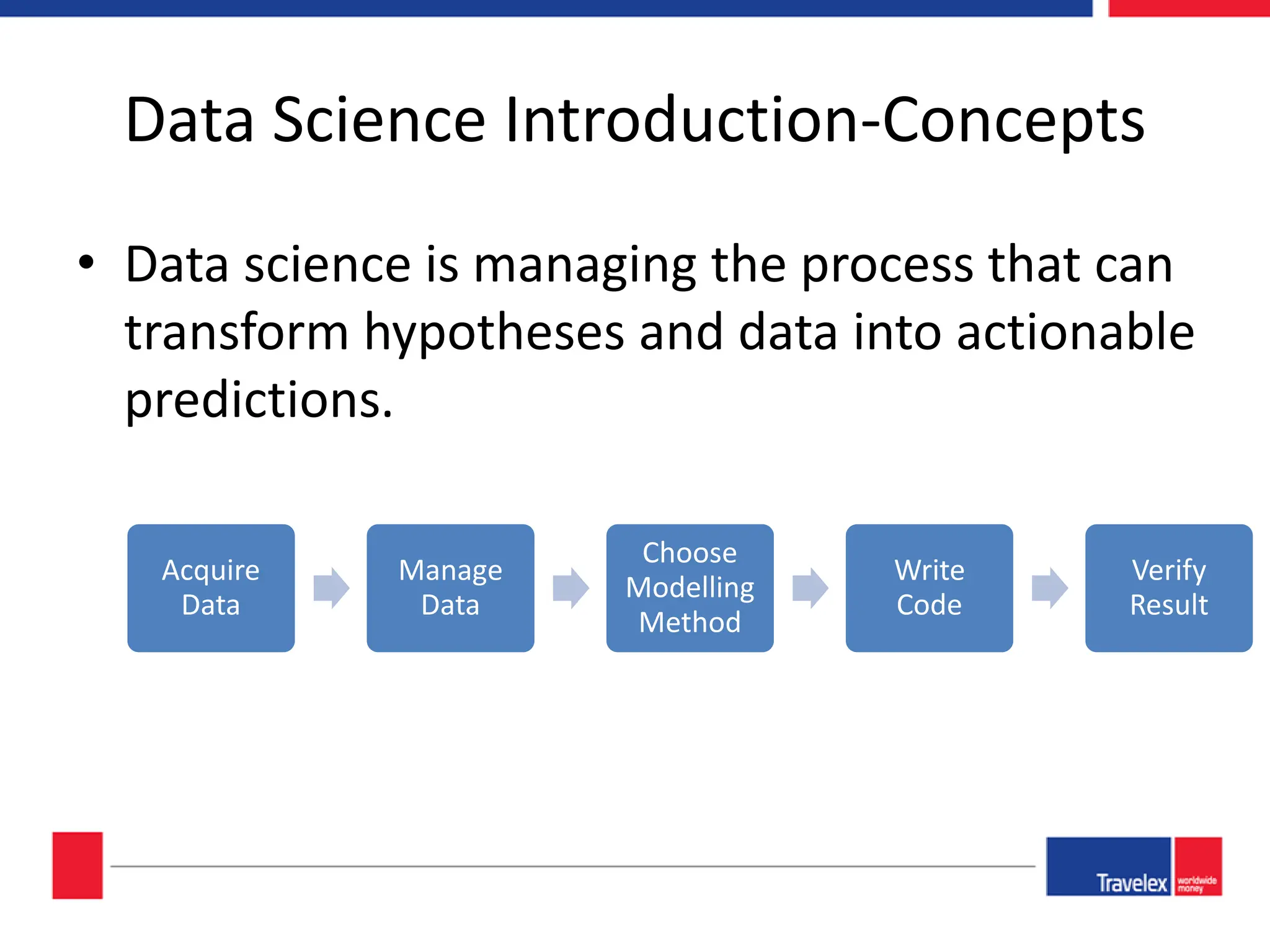

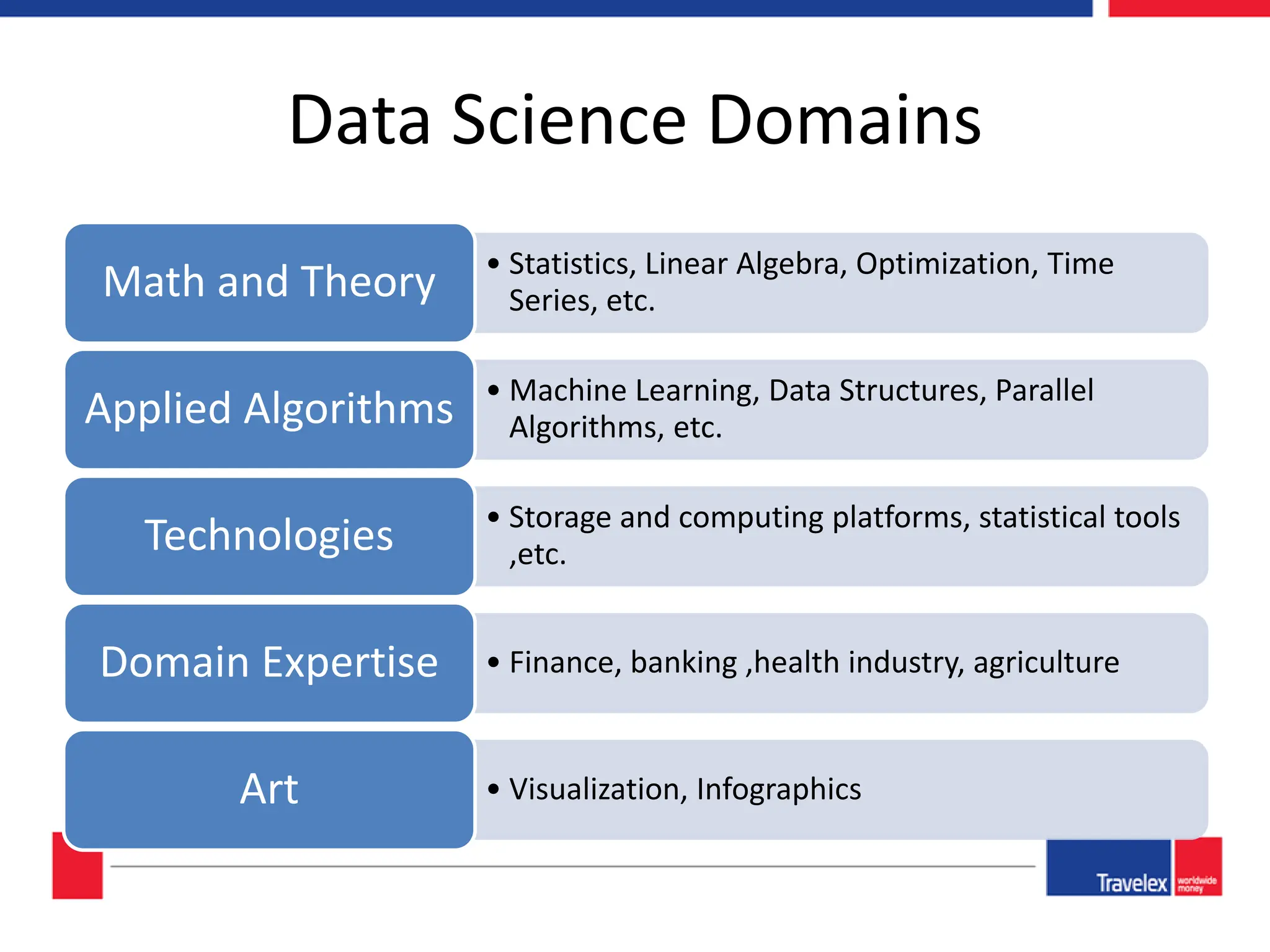
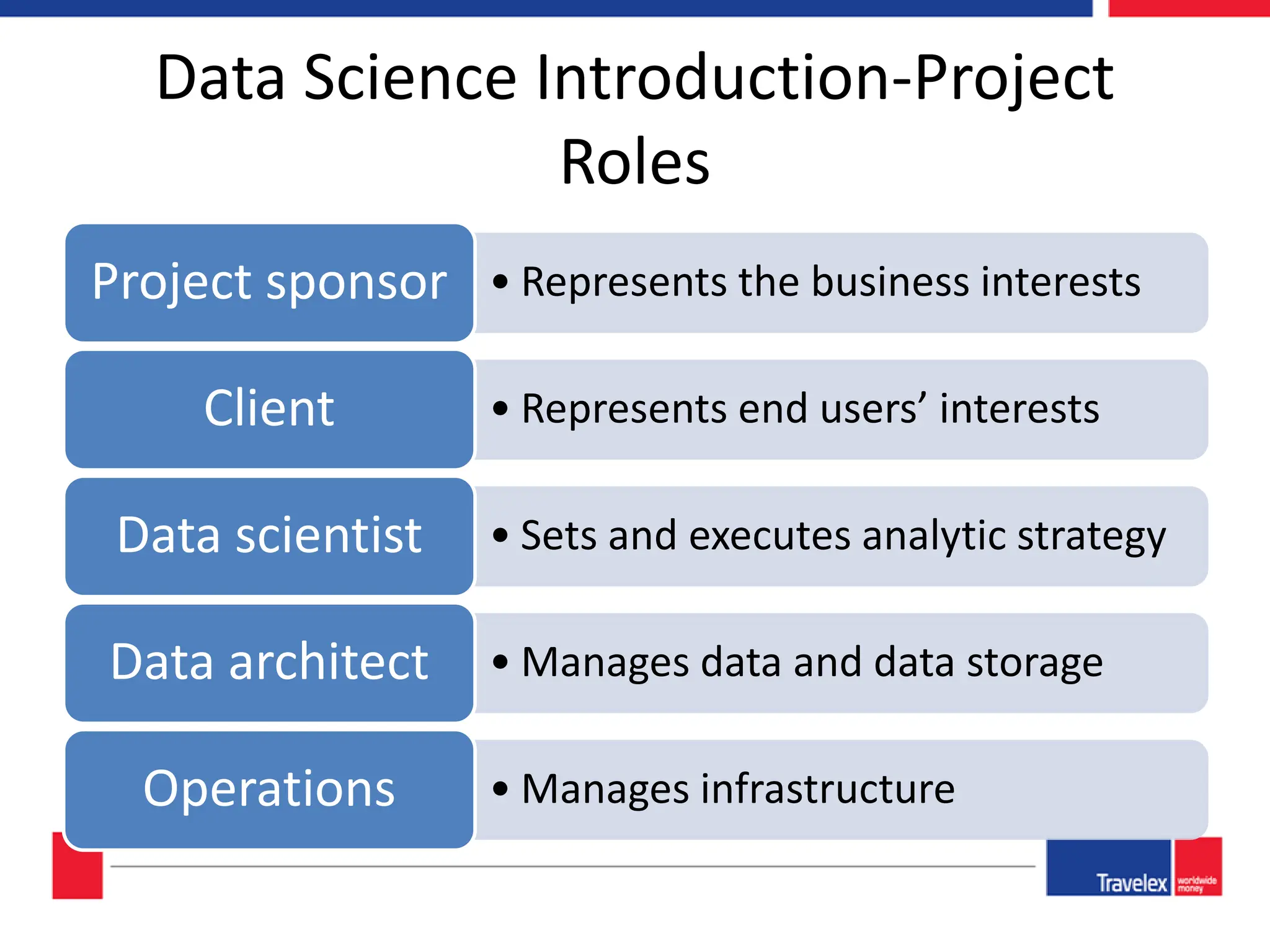
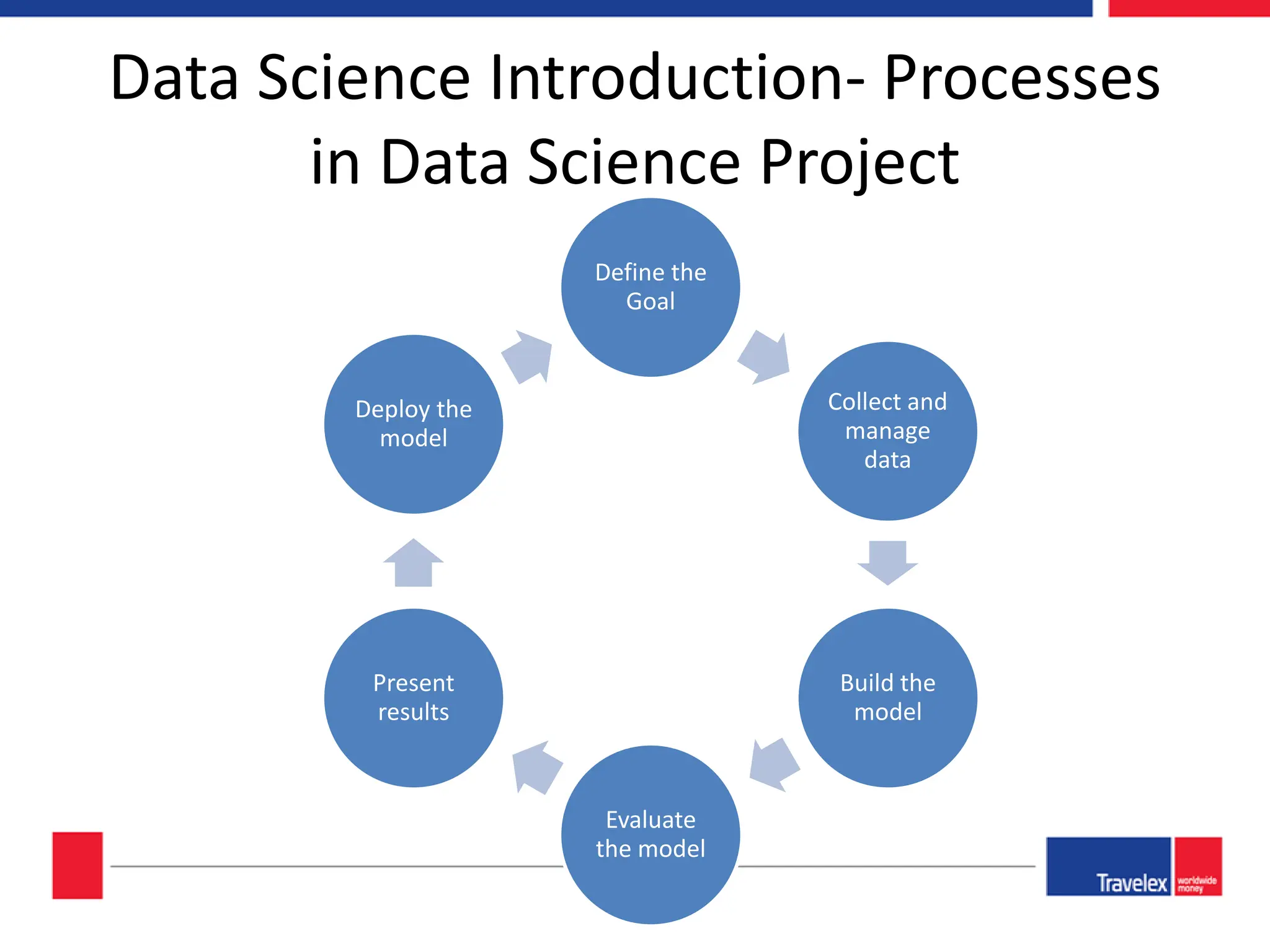


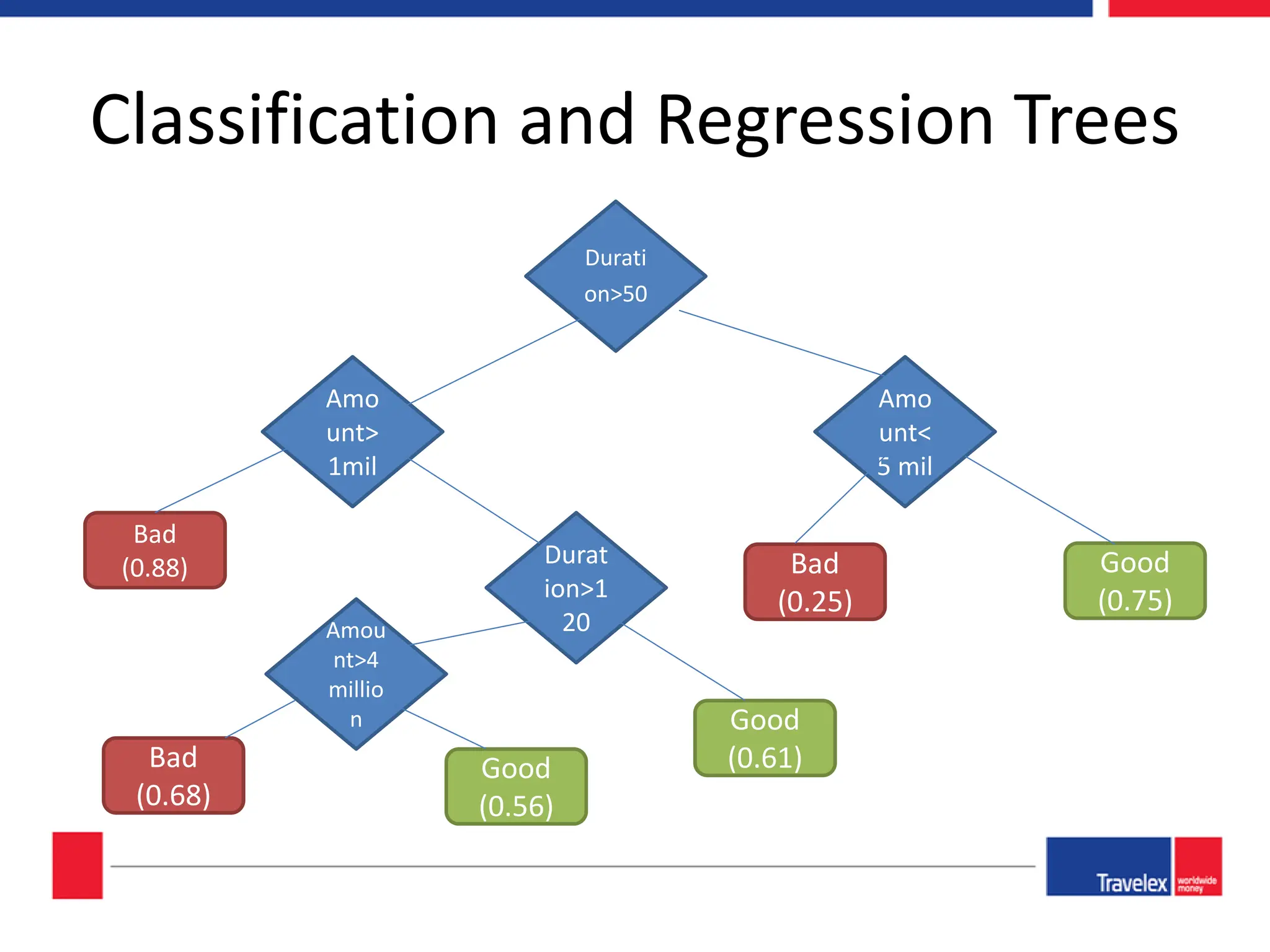
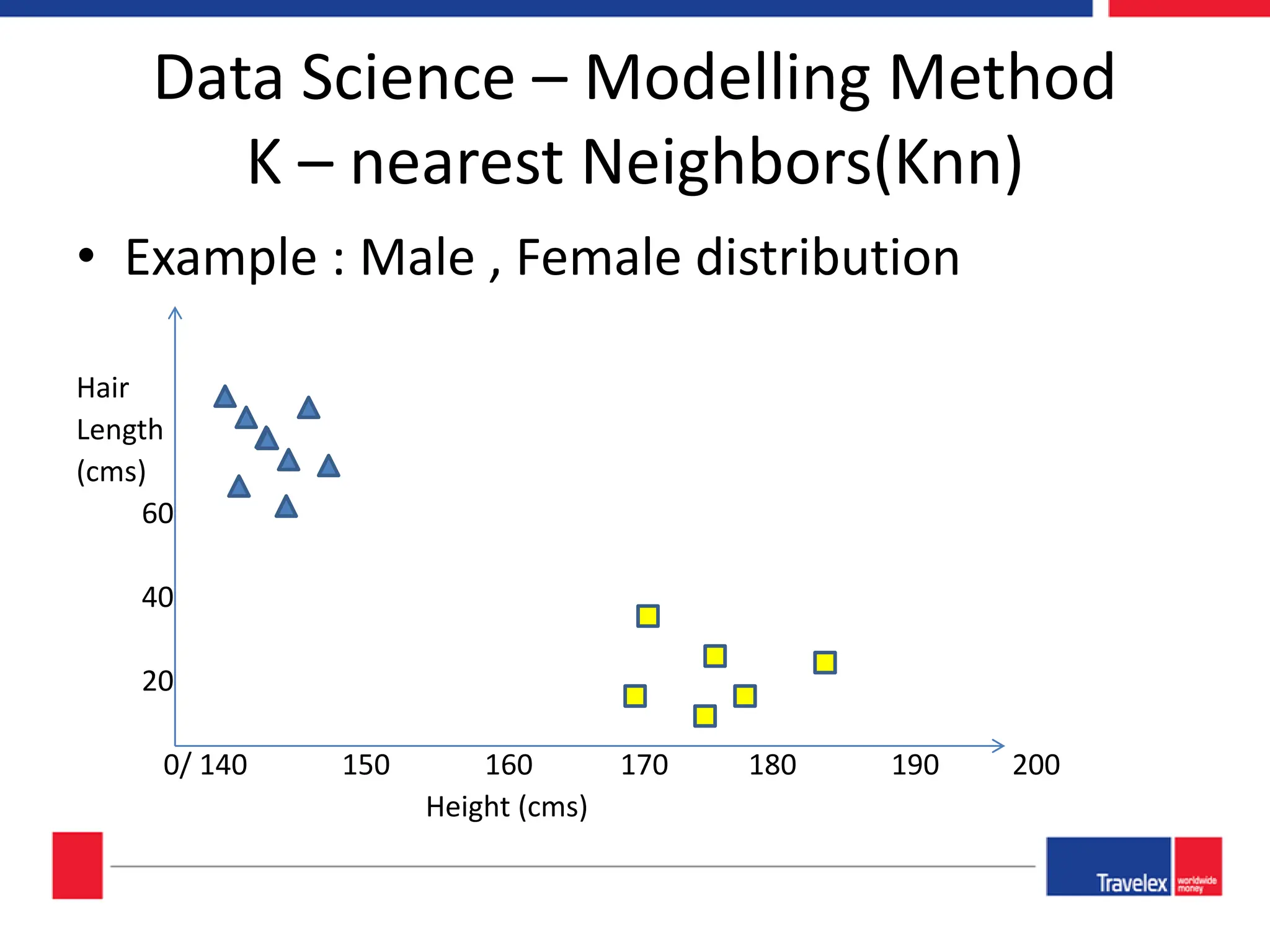
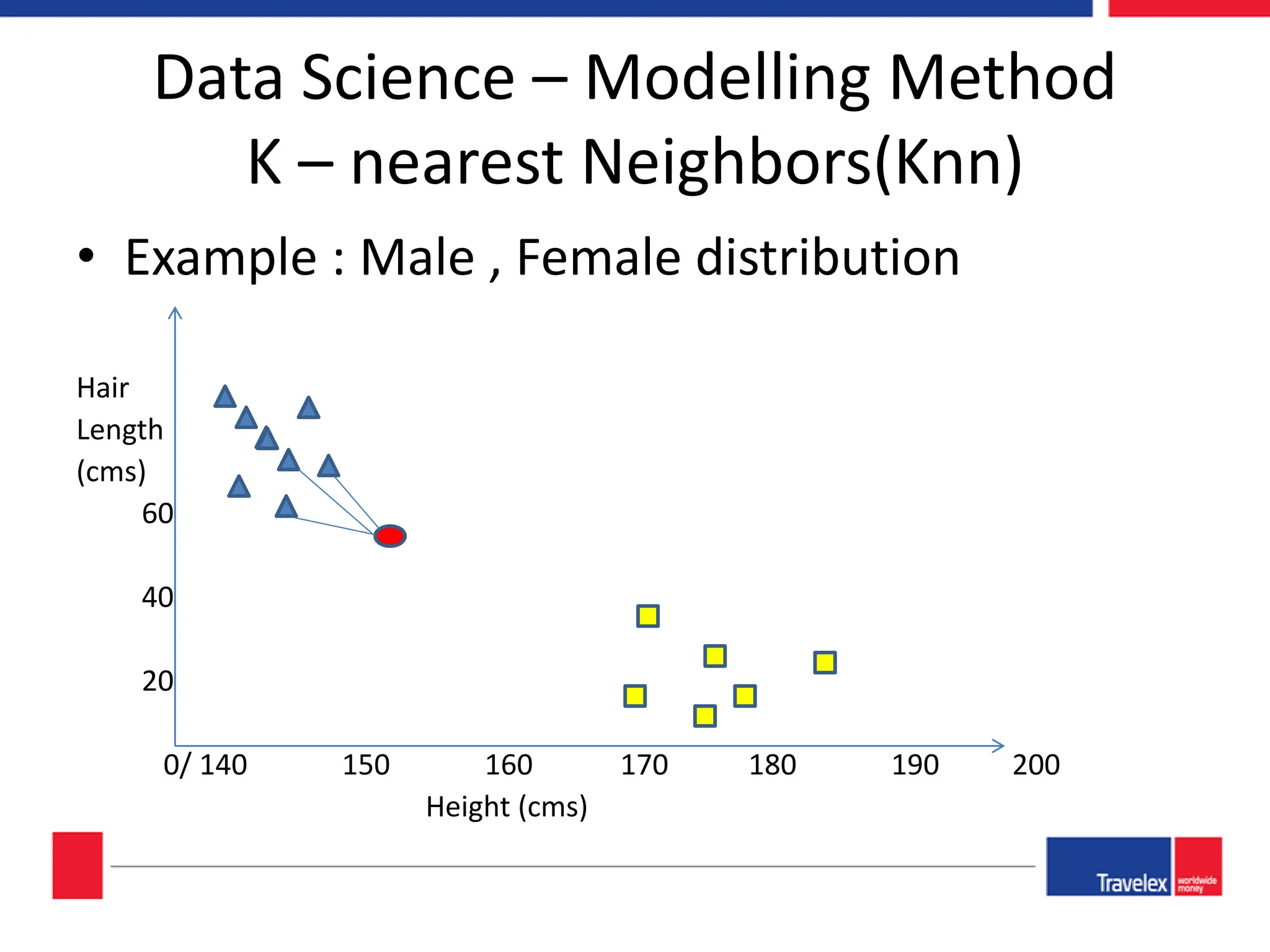
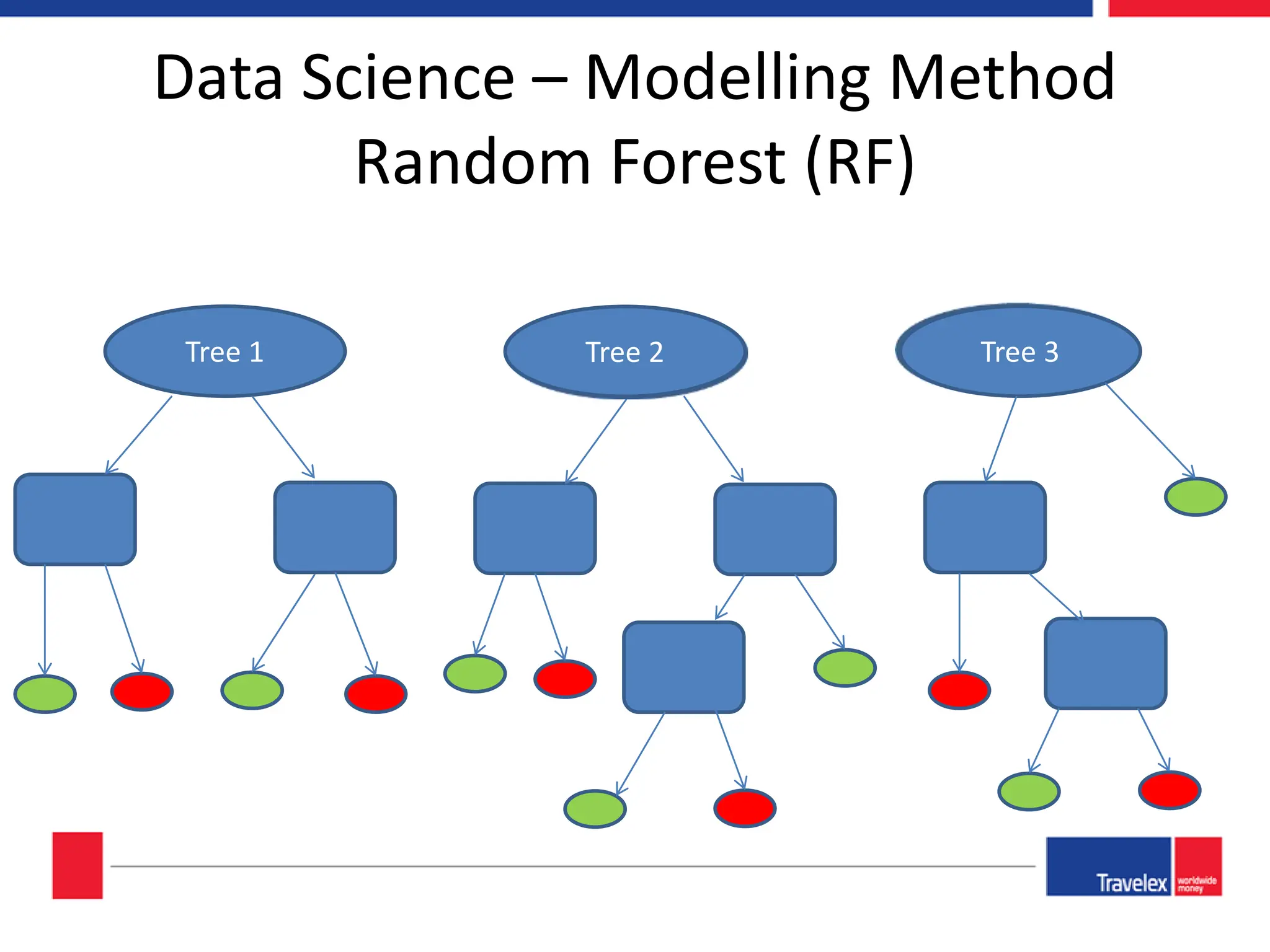
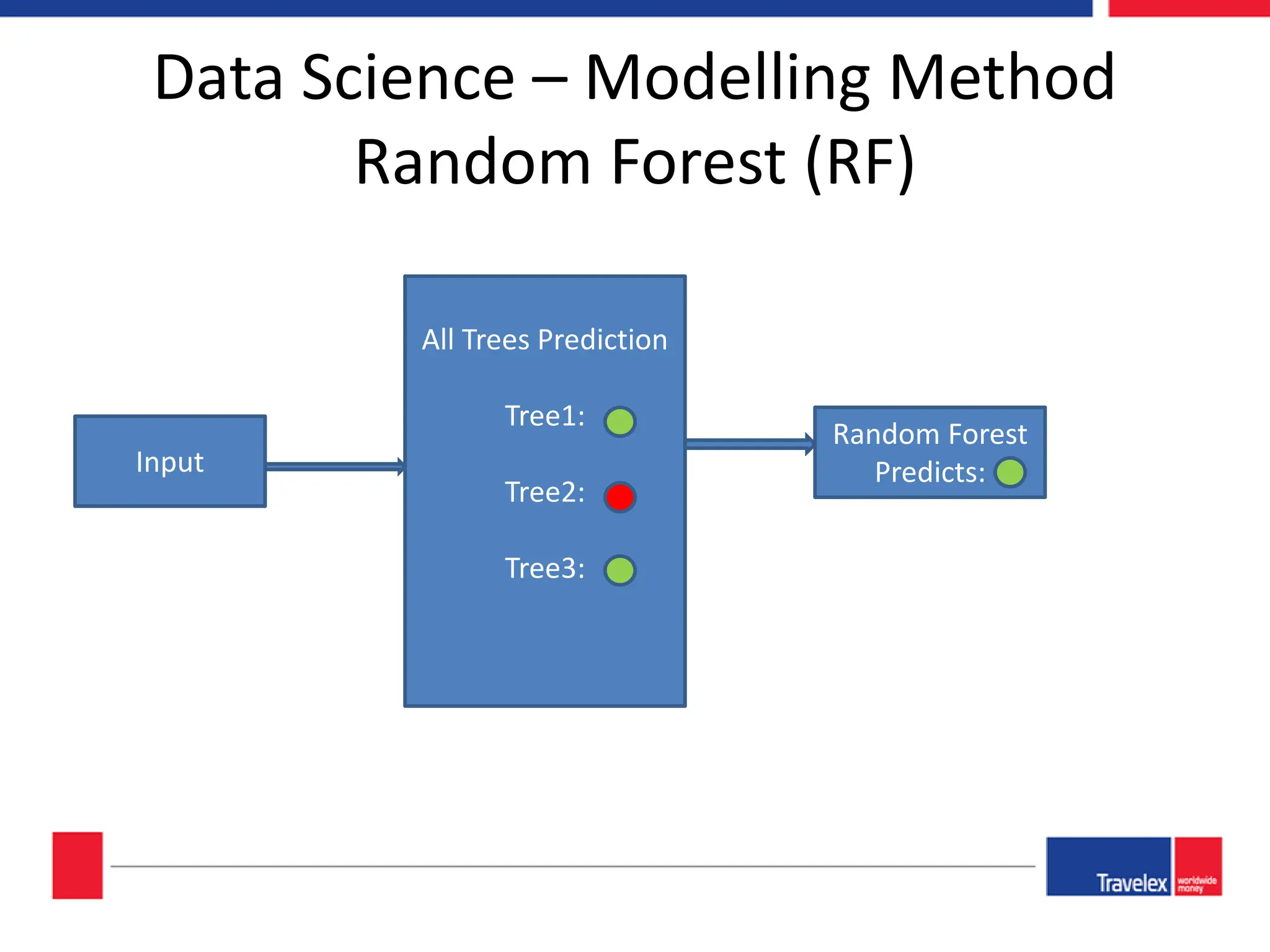

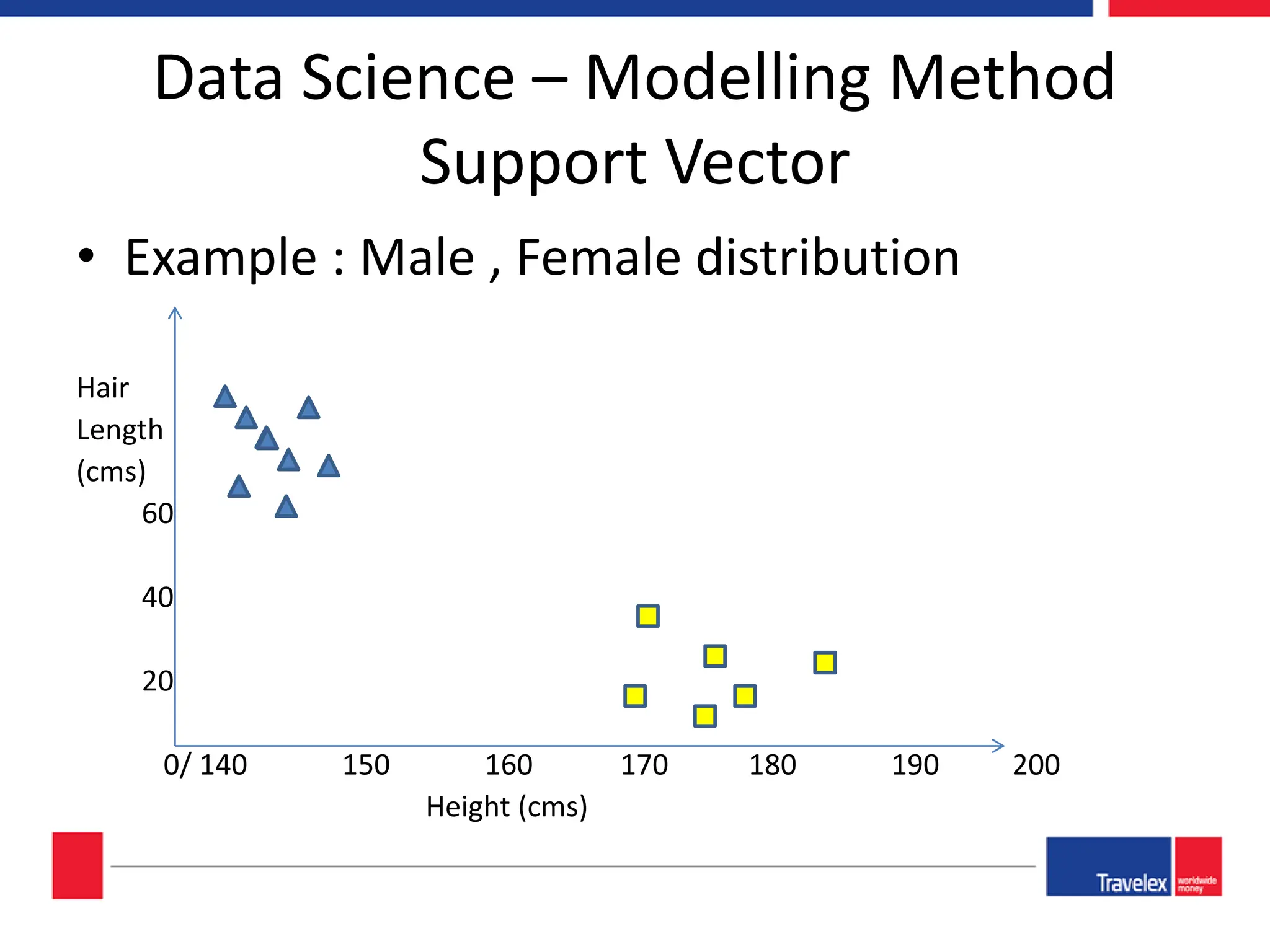
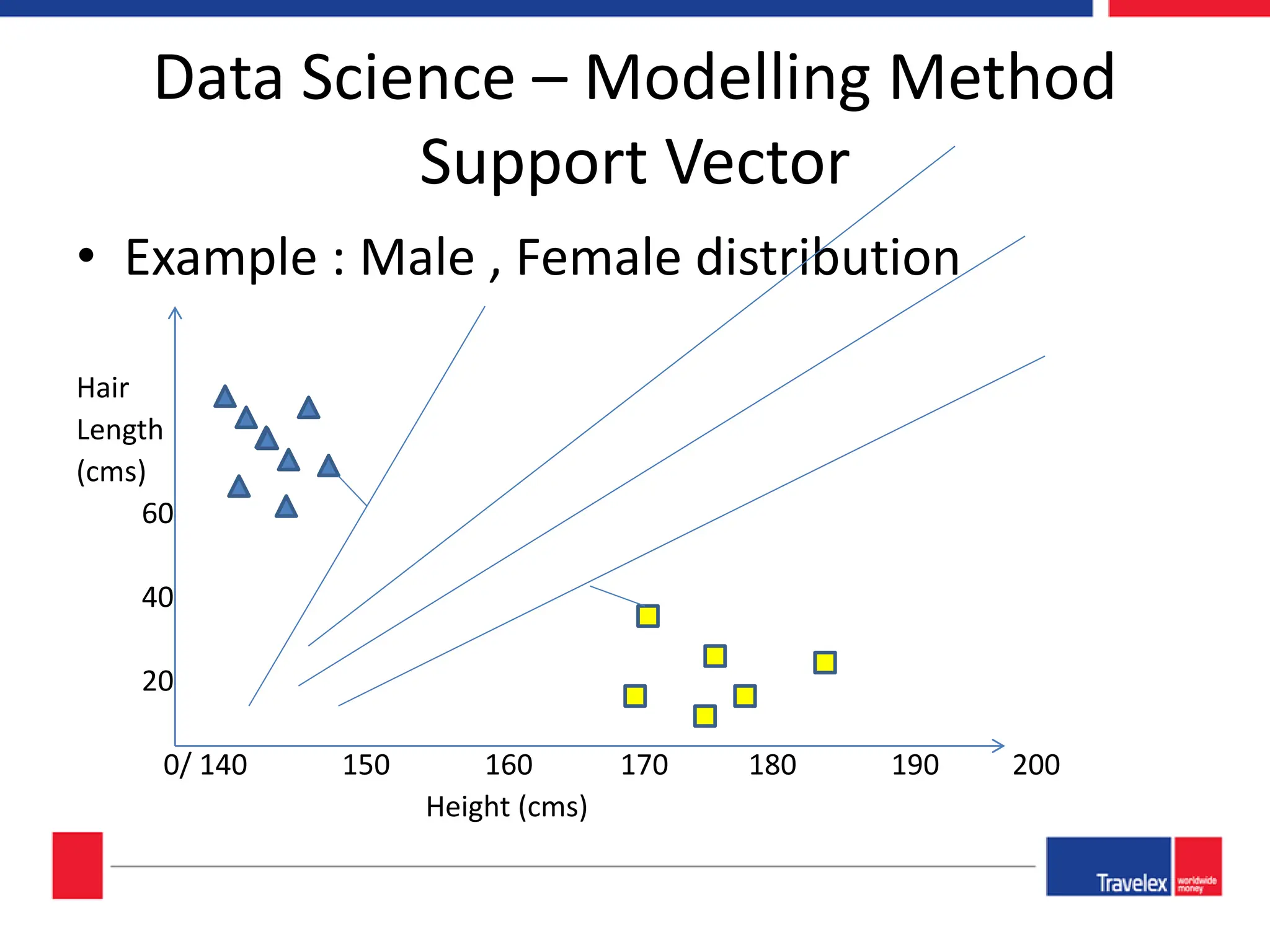
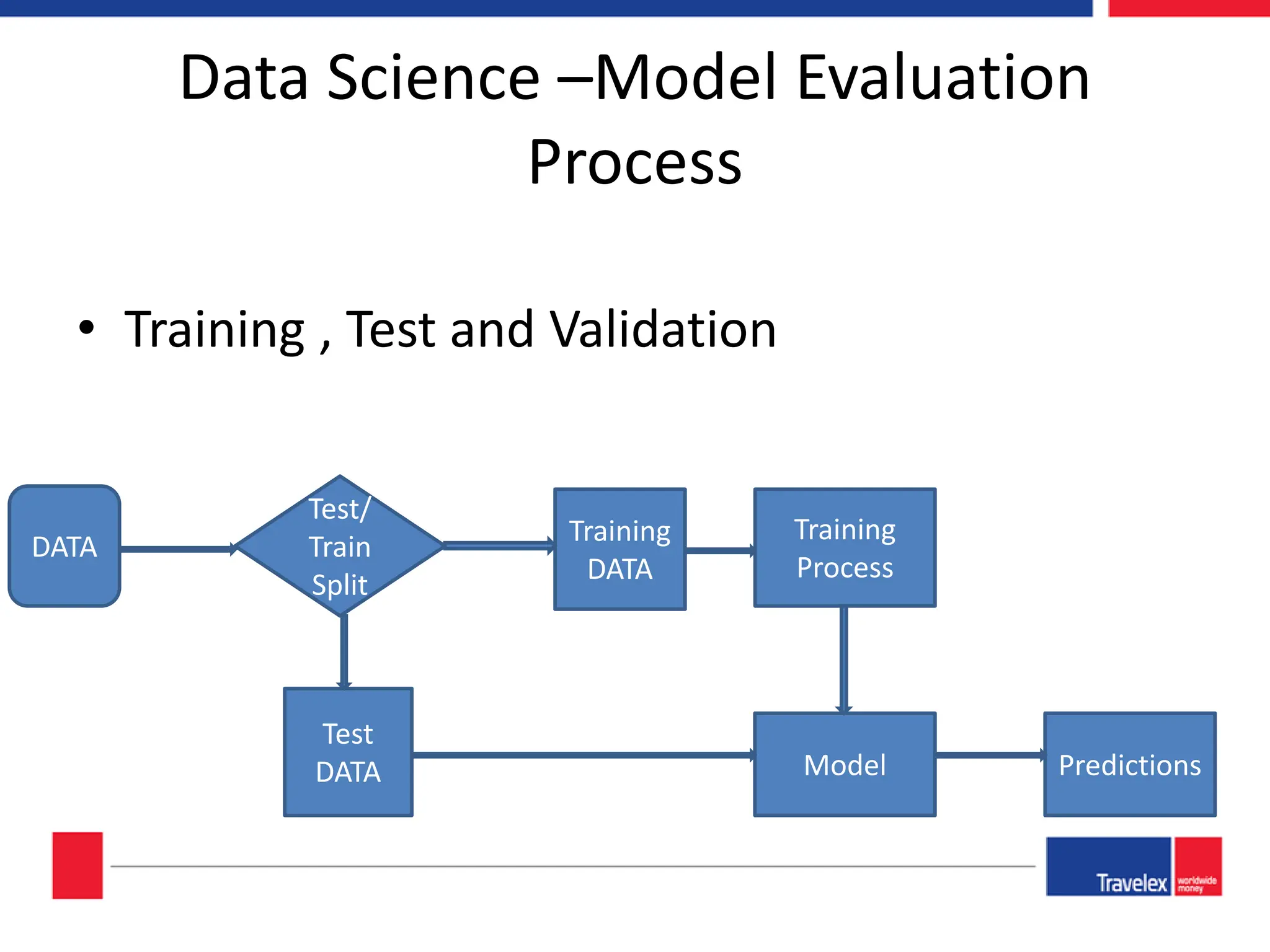

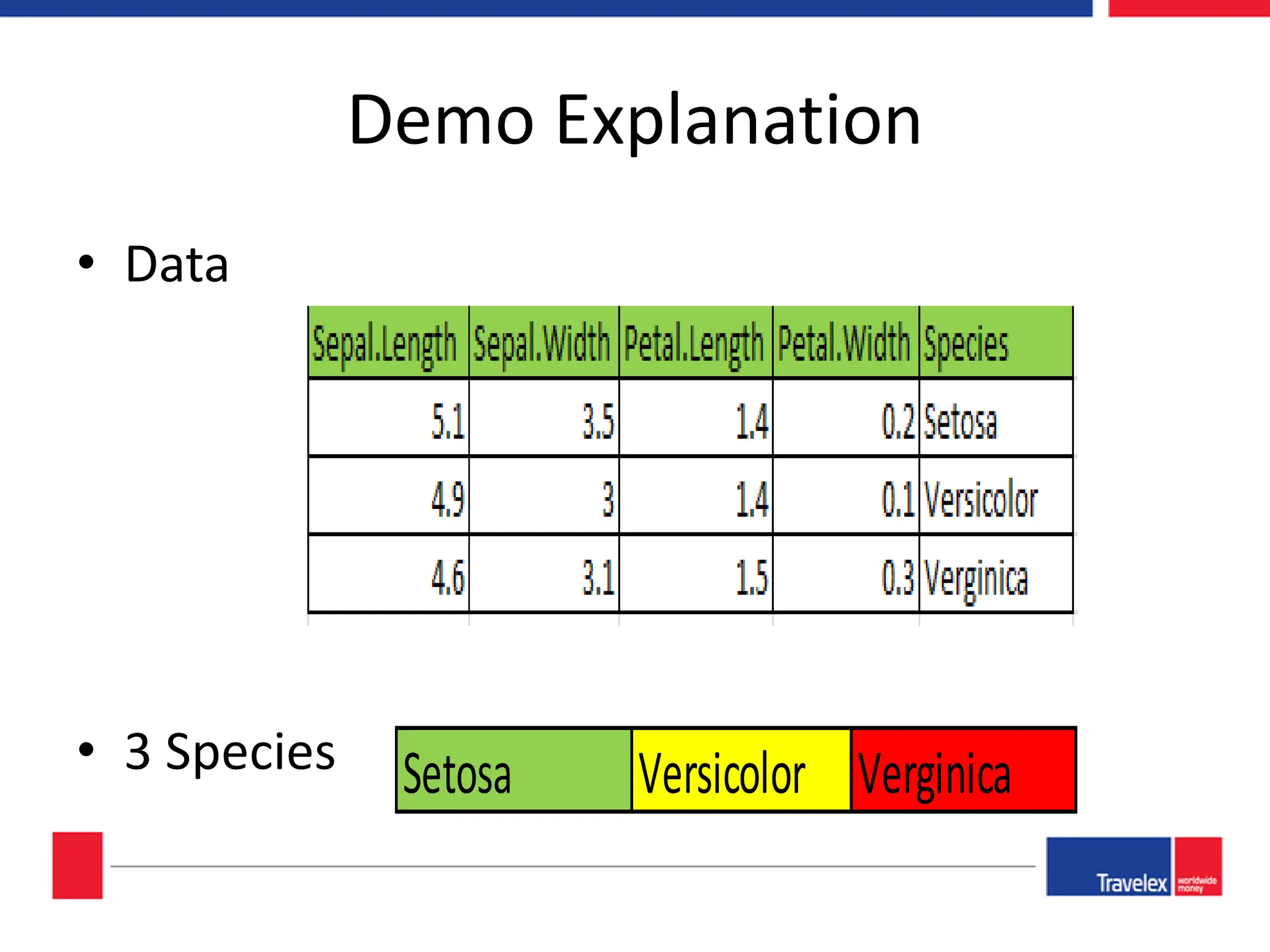






The document outlines an April 2018 agenda for a data science session covering its applications, stages, methodologies, and project roles. It discusses various modeling methods like classification trees, k-nearest neighbors, random forests, and support vector machines, alongside practical examples of their use in domains such as finance, healthcare, and e-commerce. Additionally, it emphasizes the data science process including data management, model evaluation, and offers resources for further learning.