Downloaded 38 times



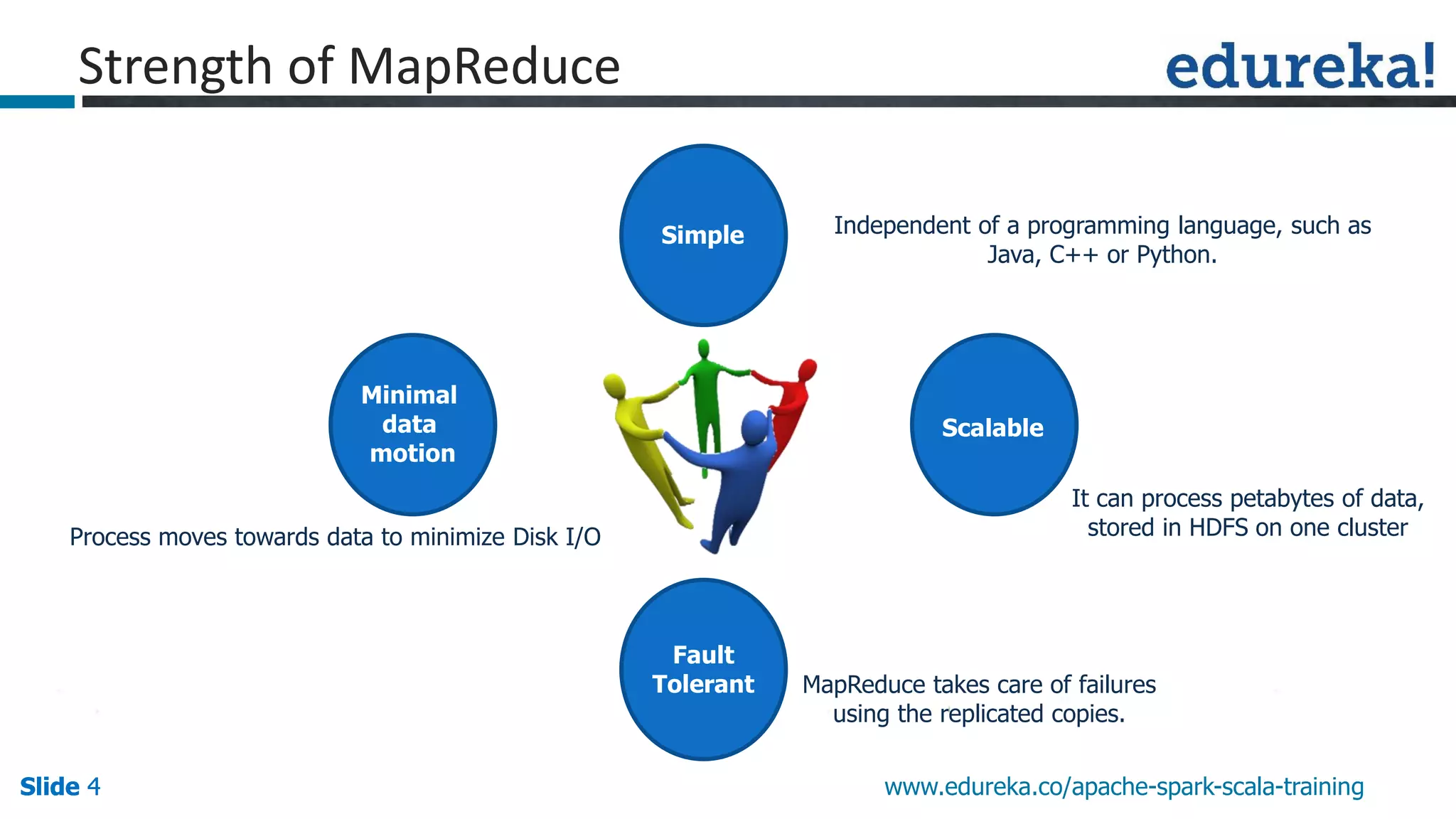

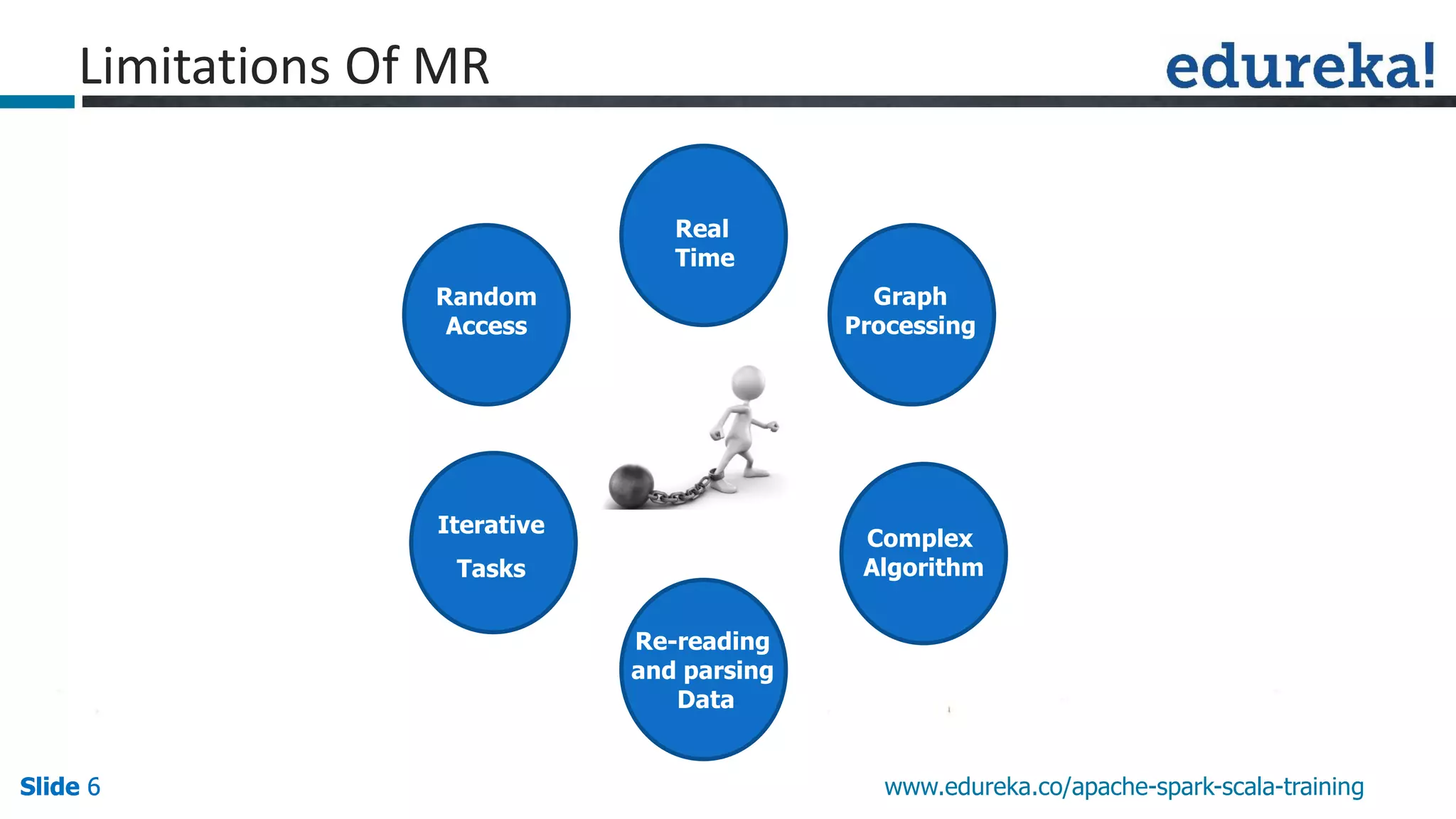



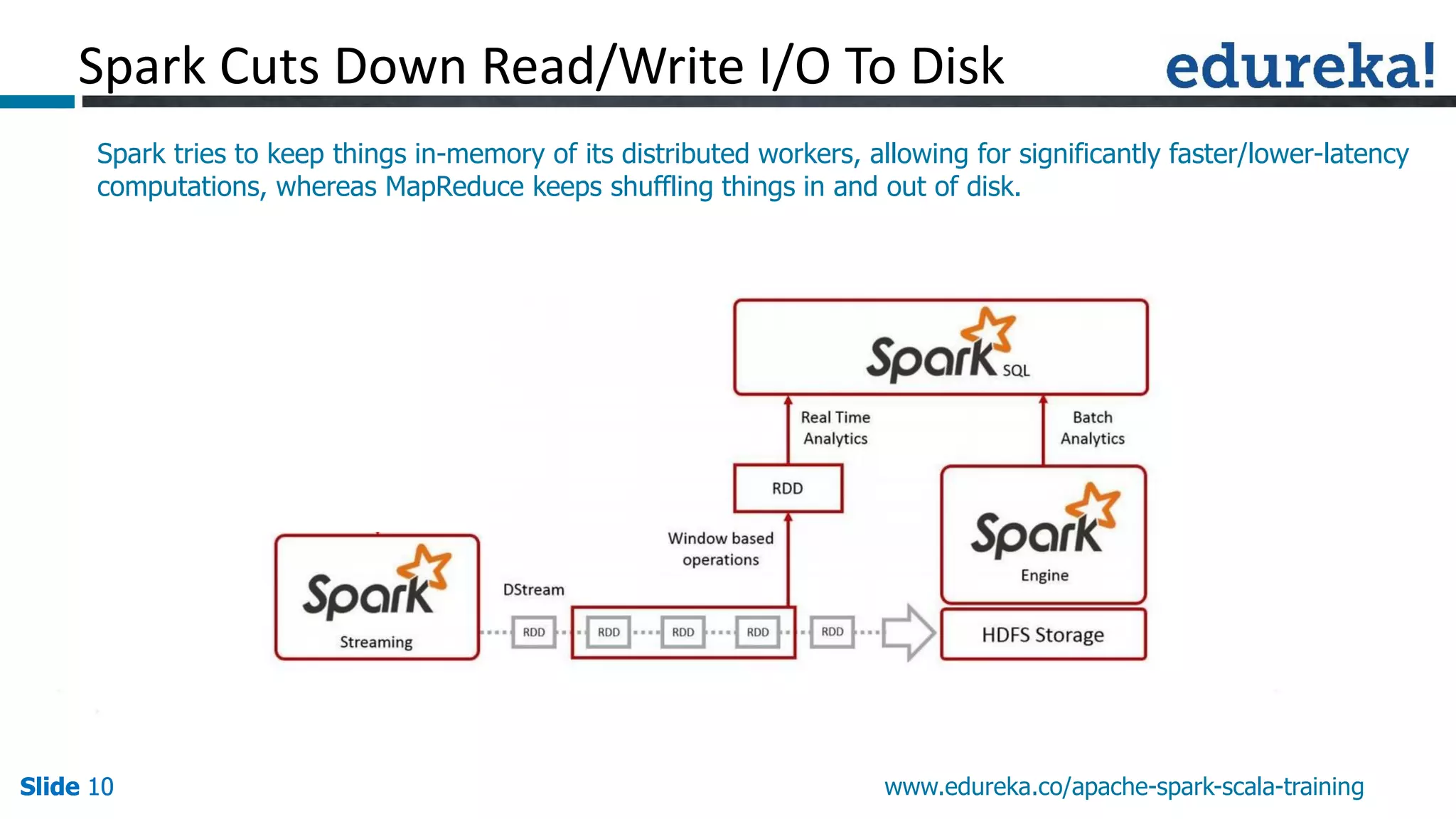
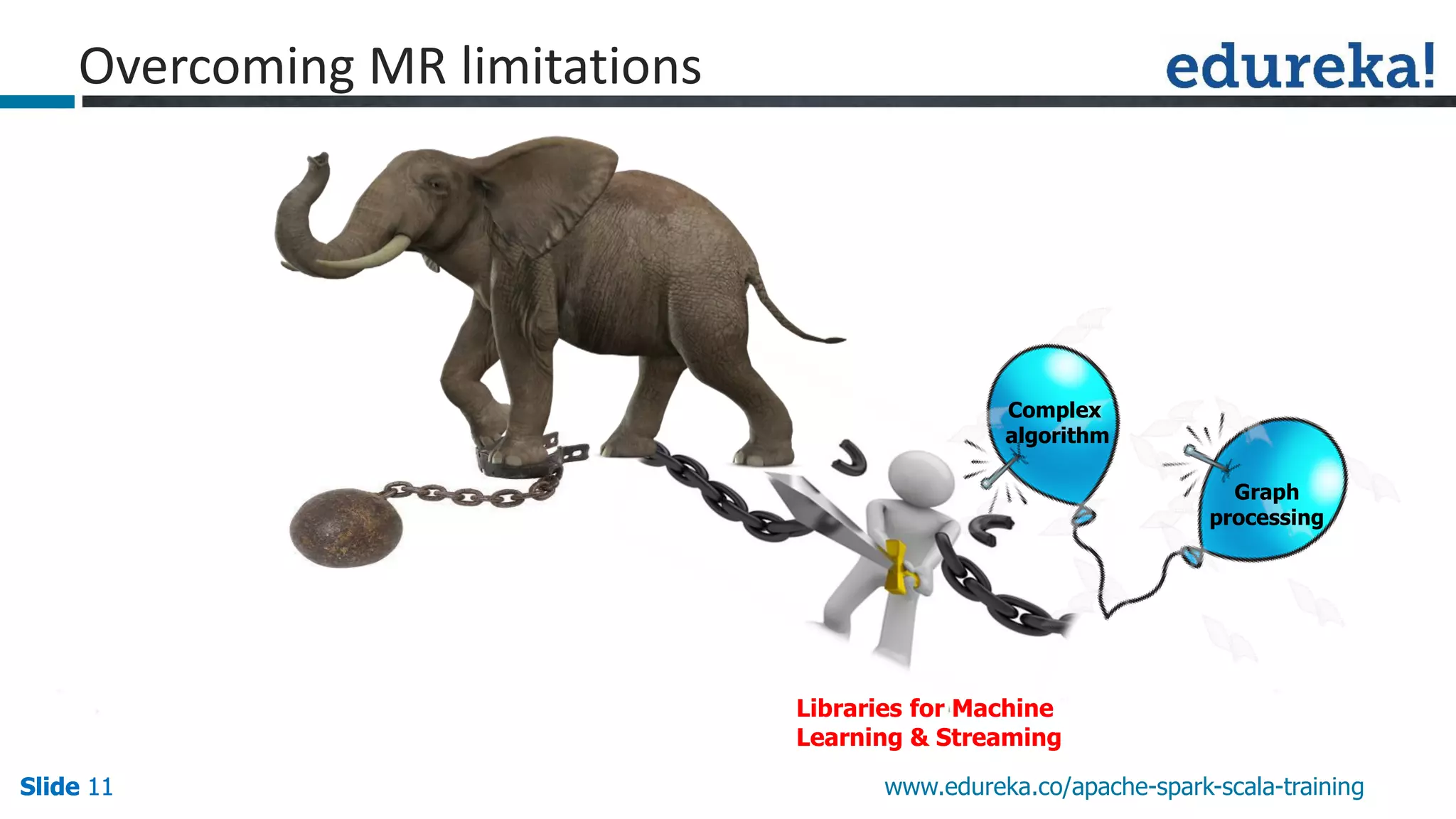
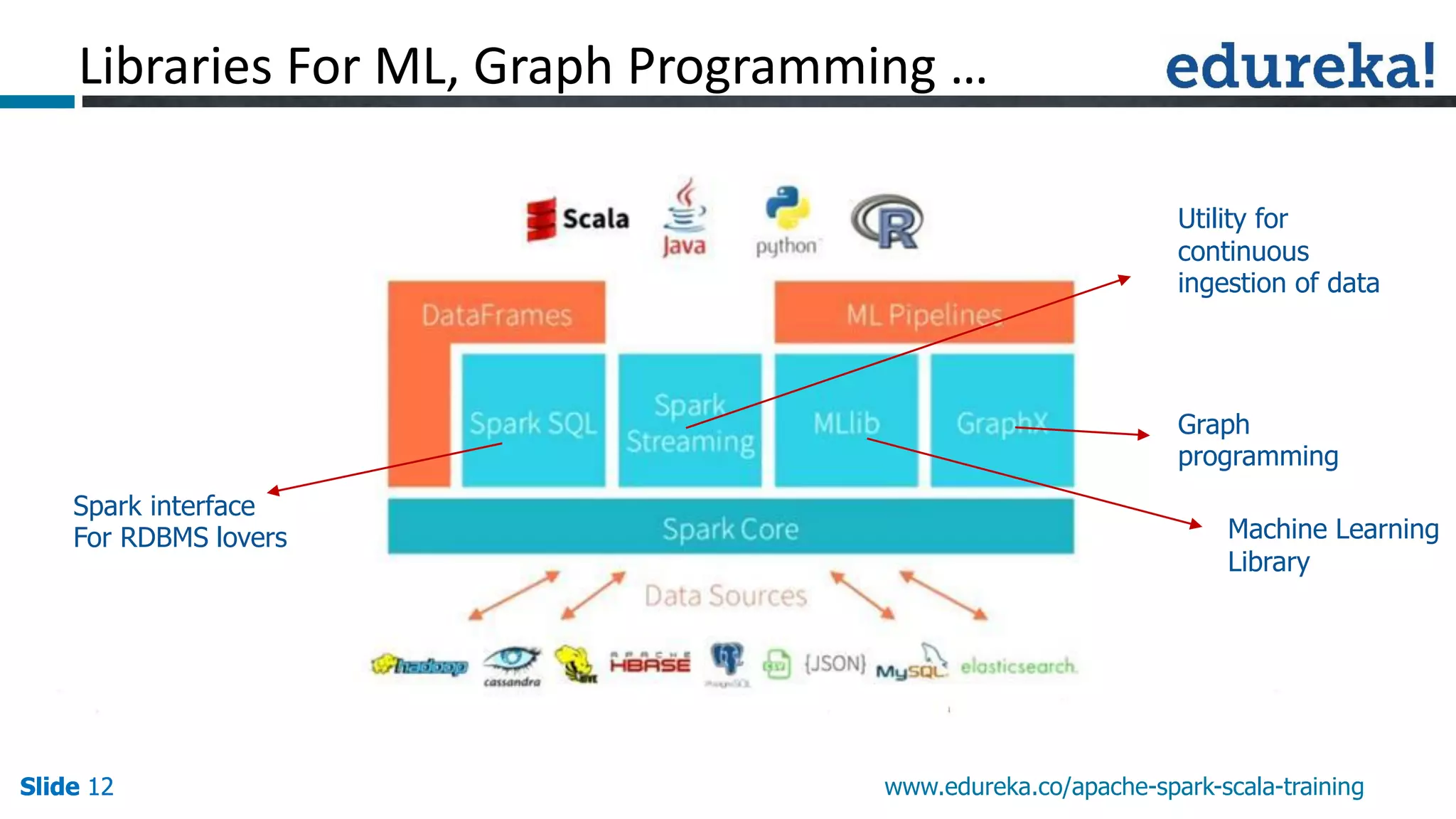
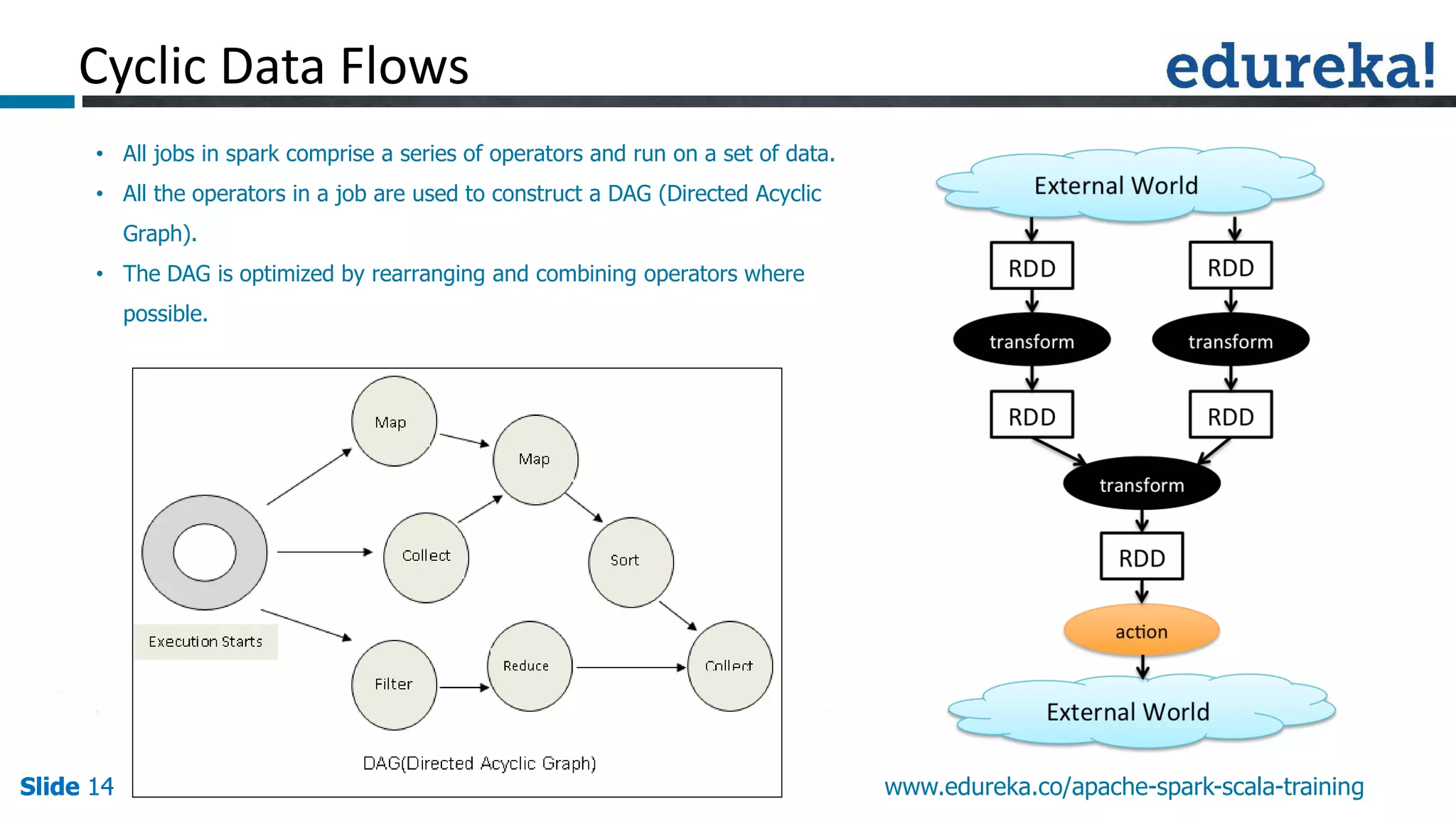


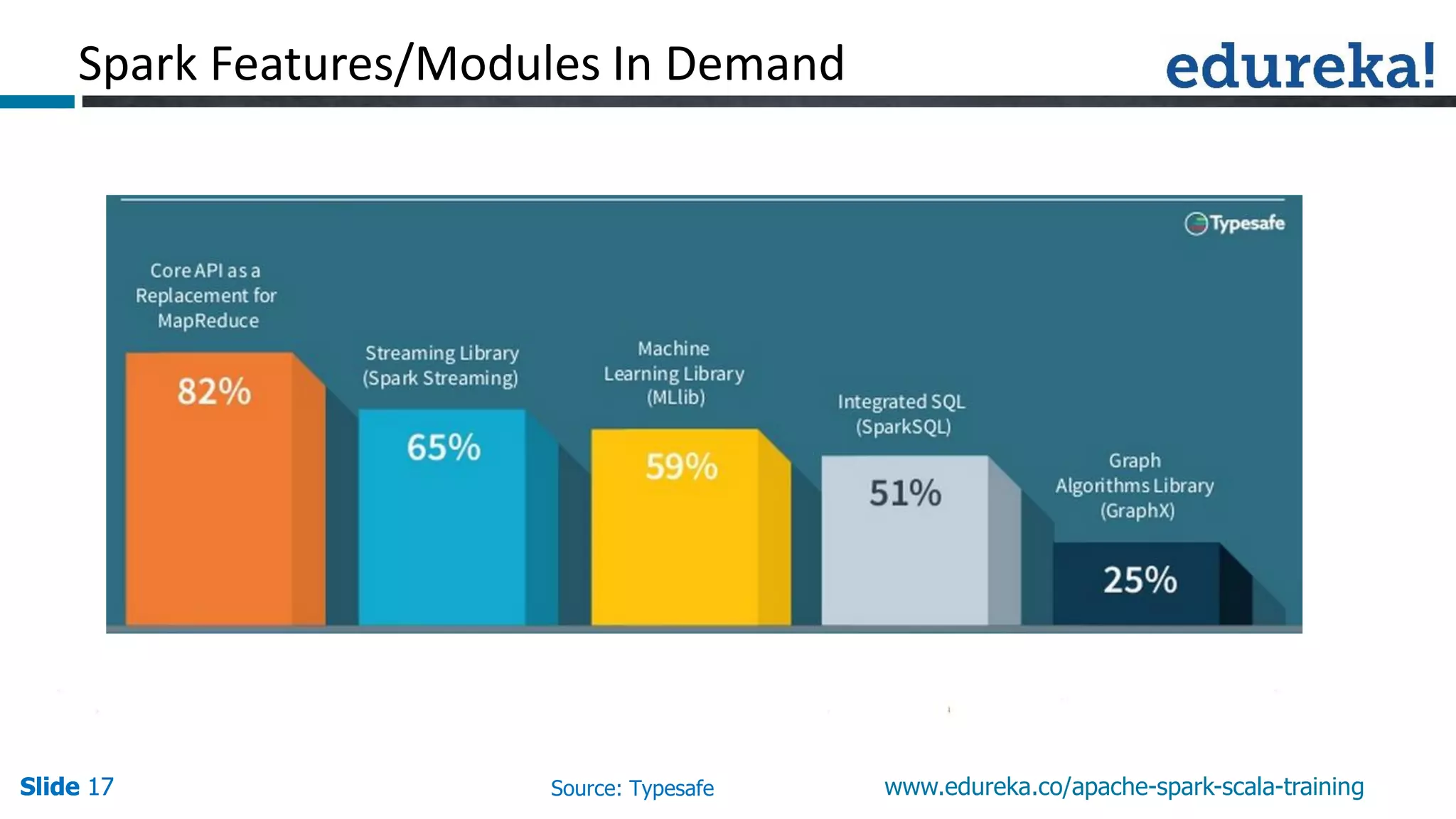



This presentation discusses Apache Spark and how it overcomes limitations of MapReduce. It begins by describing strengths of MapReduce like scalability and fault tolerance. It then covers limitations of MapReduce like lack of support for real-time and iterative processing. The presentation explains how Spark addresses these limitations by keeping data in-memory and supporting features like machine learning libraries. It highlights other Spark features such as DataFrames and SparkSQL and concludes by advertising an Apache Spark training course from Edureka.