Download as PDF, PPTX







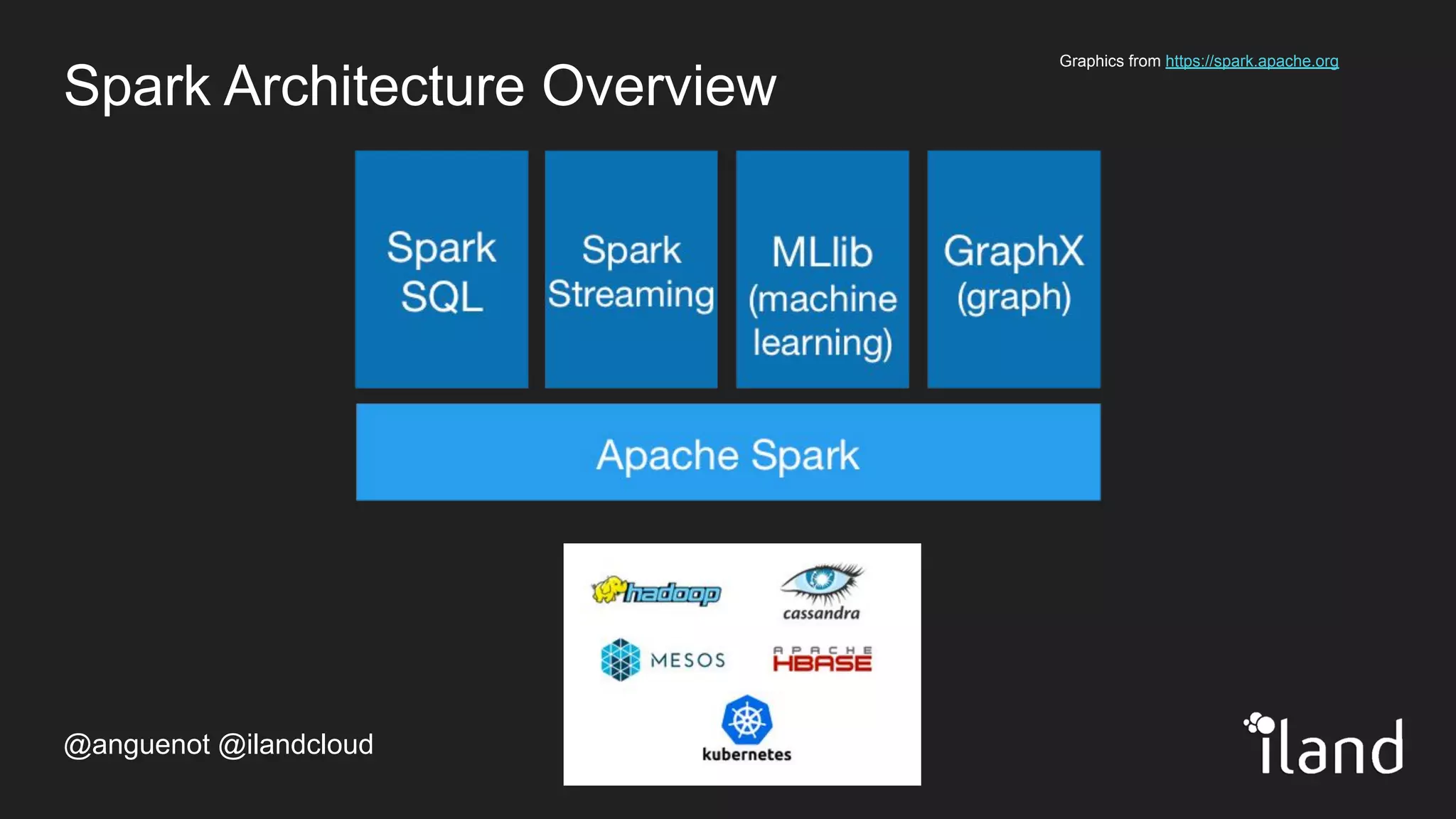



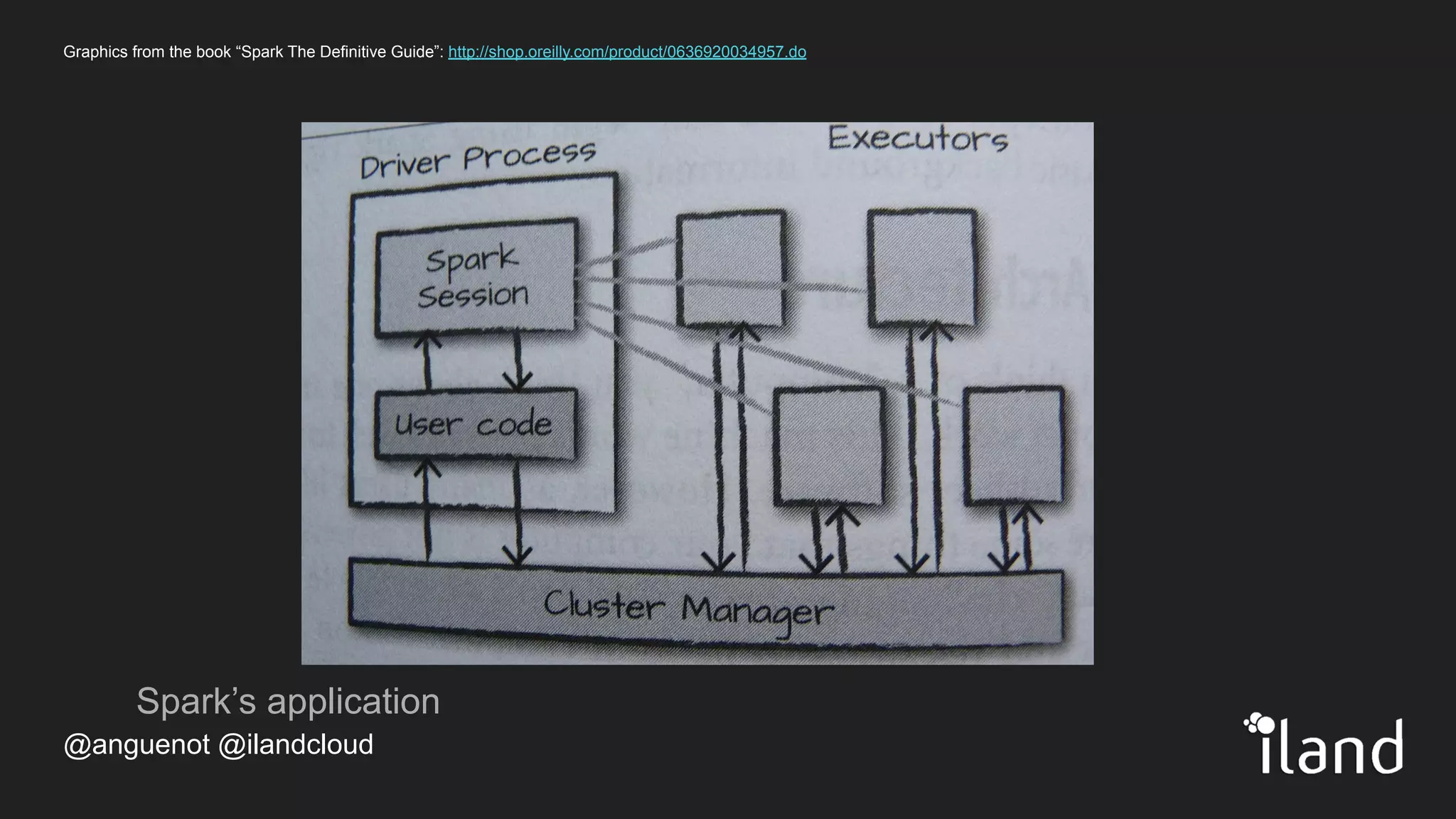
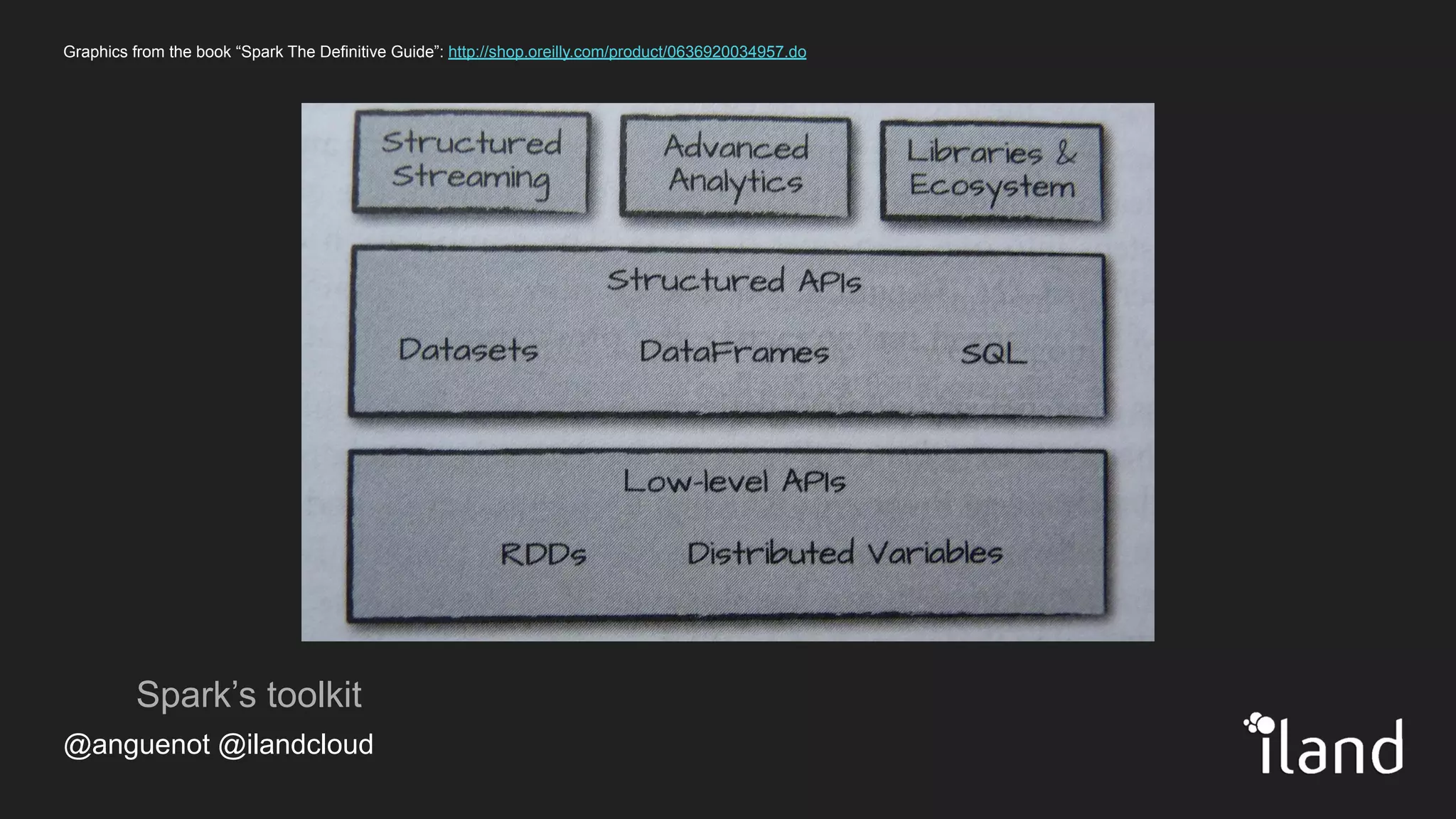
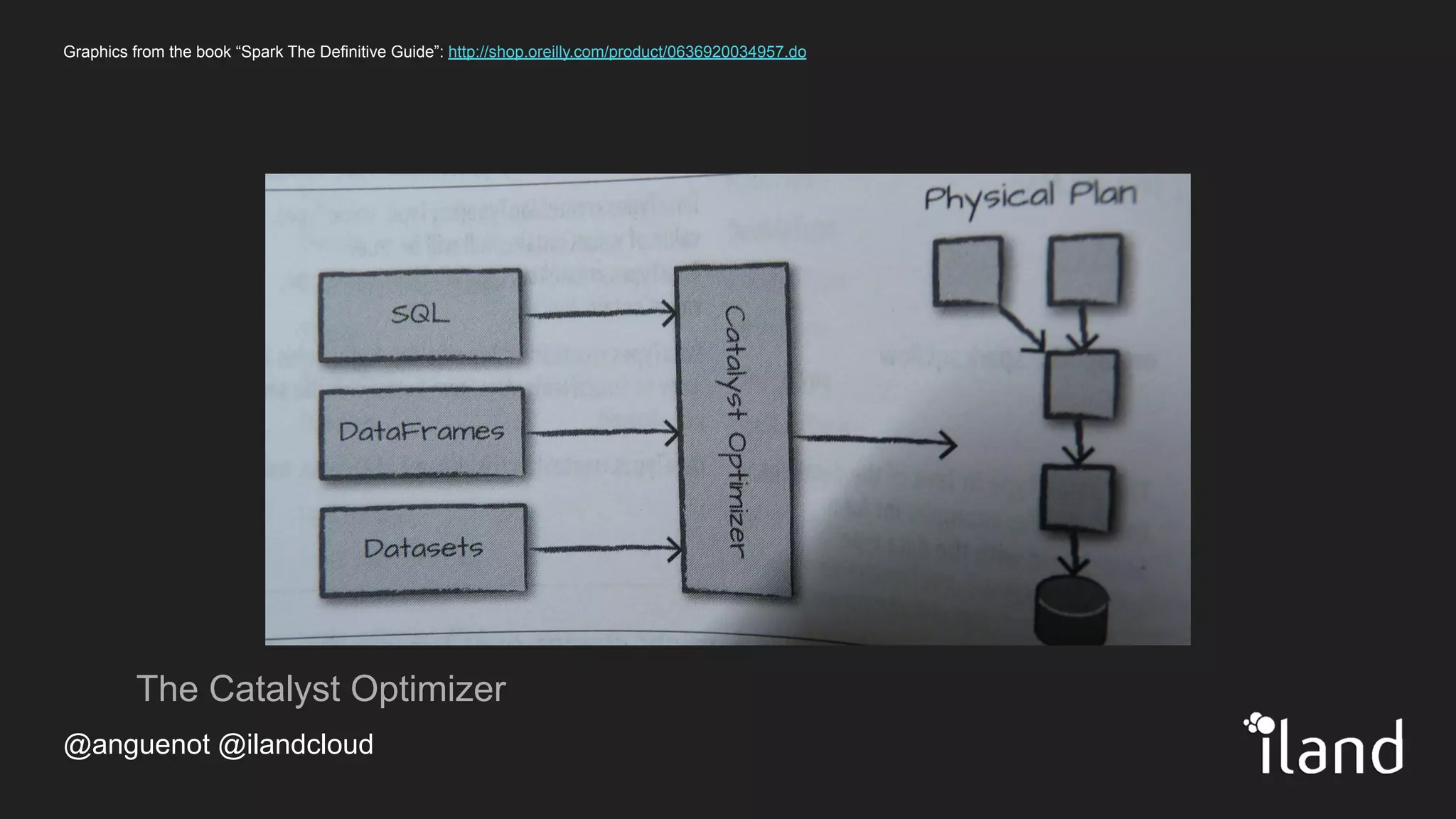





The document provides an overview of Apache Spark, highlighting its unified computing engine for big data analytics, the support for multiple programming languages, and its community and ecosystem. It discusses Spark's evolution since its inception at UC Berkeley in 2009, its architecture, and APIs including PySpark for data analysis and machine learning. Additionally, it addresses the challenges posed by big data and emphasizes the benefits of in-memory processing and real-time analytics as part of Spark's capabilities.